
編集者注:著者が母親に LLM を使って仕事を完了するように教えようとしたとき、プロンプトワードの最適化が想像ほど簡単ではないことに気づきました。プロンプト ワードの自動最適化は、モデルに提供されるプロンプト ワードを調整および改善するための十分な経験がない、経験の浅いプロンプト ワード作成者にとって価値があり、自動プロンプト ワード最適化ツールのさらなる検討のきっかけとなっています。
この記事の著者は、プロンプト ワード エンジニアリングの性質を 2 つの観点から分析しています。プロンプト ワード エンジニアリングは、ハイパーパラメータの最適化の一部とみなすことも、継続的な試行と調整を必要とする探索、試行錯誤、修正のプロセスとみなすこともできます。 。
著者は、数学的問題の解決、感情の分類、SQL ステートメントの生成など、モデルの入出力が比較的明確なタスクの場合に適していると考えています。この場合のプロンプトワードエンジニアリングは、機械学習におけるハイパーパラメータの調整と同じように、「パラメータ」の最適化に近いと著者は考えています。自動化された方法を使用して、さまざまなプロンプト単語を常に試して、どれが最も効果的かを確認できます。電子メール、詩、記事の要約などを書くなど、比較的主観的で曖昧なタスクの場合。出力が「正しい」かどうかを判断する白黒の基準がないため、プロンプトワードの最適化を単純かつ機械的に実行することはできません。
元の記事のリンク: https://towardsdatascience.com/automated-prompt-engineering-78678c6371b9
LinkedIn プロフィールリンク: https://linkedin.com/in/ianhojy
サブスクリプション用の Medium プロフィールのリンク: https://ianhojy.medium.com/
著者 | イアン・ホー
編集済み | ユエ・ヤン
過去数か月間、私は LLM を利用したさまざまなアプリを構築しようと試みてきました。正直に言うと、私は LLM から必要な出力を取得するために Prompt の改善にかなりの時間を費やしています。
自分はただの美化されたプロンプトエンジニアなのだろうかと、虚しさと混乱に陥ったことが何度もありました。 LLM (大規模言語モデル) と人間の対話の現状を考えると、私は依然として「まだ」と結論付ける傾向があり、ほとんどの夜はインポスター症候群を克服できています。 (訳者注:これは、自分自身の業績や能力に懐疑的な個人を指す心理現象です。彼らはしばしば自分が嘘つきであると感じ、自分が達成した業績を達成したり達成したりする価値がないと信じており、暴露されるのではないかと心配しています。) 現時点では、この問題については深く議論しません。
しかし、私は今でも、いつか Prompt を書くプロセスを基本的に自動化できるのではないかと思うことがよくあります。この質問にどう答えるかは、プロンプトエンジニアリングの本質を理解できるかどうかにかかっています。
広大なインターネット上にはプロンプト エンジニアリングのプレイブックが無数にありますが、プロンプト エンジニアリングが芸術なのか科学なのか、私にはまだ判断できません。
一方で、モデルの出力から観察したことに基づいて作成したプロンプトを繰り返し学習して磨き上げる必要があるとき、それは芸術のように感じられます。時間が経つにつれ、プロンプトの単語の途中ではなく末尾に「すべき」の代わりに「しなければならない」を使用したり、ガイドラインの推奨事項や仕様を追加したりするなど、小さな詳細が重要であることがわかりました。タスクによっては、一連の指示やガイドラインを表現する方法が非常にたくさんあるため、試行錯誤と間違いが絶えないように感じることがあります。
一方で、プロンプトワードは単なるハイパーパラメータであると考える人もいるかもしれません。結局のところ、LLM (大規模言語モデル) は、すべてのハイパーパラメーターと同様に、実際に作成したプロンプト ワードのみを埋め込みとして扱います。機械学習モデルのトレーニングとテスト用に準備され承認されたデータセットがあれば、プロンプトの言葉を調整し、そのパフォーマンスを客観的に評価できます。最近、HuggingFace[1] の ML エンジニア、Moritz Laurer による投稿を目にしました。
データに対して異なるプロンプトをテストするたびに、LLM が実際に目に見えないデータに一般化しているかどうか確信が持てなくなります。別の検証分割を使用して LLM のメイン ハイパーパラメータ (プロンプト) を調整することは、train-val-test と同じくらい重要です。微調整のための分割。唯一の違いは、トレーニング データセットがもう存在しないことです。トレーニングやパラメーターの更新がないため、どういうわけか違ったように感じられます。実際にはプロンプトをデータにオーバーフィットさせているにもかかわらず、LLM がタスクでうまく機能すると自分を騙すのは簡単です。優れた「ゼロショット」論文はすべて、最終テストの前にプロンプトを見つけるために検証分割を使用したことを明確にする必要があります。
これらのデータ セットでさまざまなプロンプト ワード (プロンプト) をテストすると、LLM が本当に目に見えないデータに一般化できるかどうかがますます不確実になります... データ セットの一部を分離する 検証セットとして設定し、主要なハイパーパラメータを調整するLLM の (プロンプト) を使用し、train-val-test 分割 (翻訳者注: 利用可能なデータ セットをトレーニング セット、検証セット、テスト セットの 3 つの部分に分割します) メソッドを使用して、微調整を進めることも同様に重要です。唯一の違いは、このプロセスにはモデルのトレーニング (トレーニングなし) やモデル パラメーターの更新 (パラメーターの更新なし) は含まれず、検証セット上のさまざまなプロンプト ワードのパフォーマンスの評価のみが含まれることです。実際には、調整されたキューワードがこの現在のデータセットでは非常に優れたパフォーマンスを発揮する可能性がありますが、より広範囲のデータセットや適用できない未確認のデータセットでは適切なパフォーマンスを発揮しない可能性があるにもかかわらず、LLM がターゲット タスクで適切にパフォーマンスを発揮すると思い込むのは簡単です。すべての優れた「ゼロショット」論文には、最終テストの前に最適なプロンプトを見つけるために検証セットを使用していることを明確に記載する必要があります。
少し考えてみると、答えはその中間にあると思います。プロンプト エンジニアリングが科学であるか芸術であるかは、LLM に何をしてもらいたいかによって決まります。私たちはこの 1 年間、LLM が多くの素晴らしいことを行っているのを見てきましたが、私は大規模なモデルを使用する人々の意図を、問題の解決と創造的なタスクの完了 (作成) という 2 つの大きなカテゴリに分類する傾向があります。
問題解決側では、数学的問題の解決、感情の分類、SQL ステートメントの生成、テキストの翻訳などを行う LLM が存在します。一般的に言えば、これらのタスクは比較的明確な入出力ペア (訳者注: 入力データと対応するモデル出力データの間の関連性) を持つことができるため、すべてグループ化できると思います (したがって、少数のプロンプトだけで目的のタスクを十分に達成できます)。明確に定義されたトレーニング データ (翻訳者注: トレーニング データ セットの入力と出力の関係は明確です) を使用したこの種のタスクでは、プロンプト エンジニアリングの方が私には科学のように思えます。したがって、この記事の前半では、 ハイパーパラメータとしてのプロンプト について説明し、特に自動化されたプロンプト エンジニアリングの研究の進歩について検討します (翻訳者注: 自動化された手法またはテクノロジを使用してプロンプト ワードを設計、最適化、調整する)。
クリエイティブなタスクに関して言えば、LLM に要求されるタスクはより主観的で曖昧です。電子メール、レポート、詩、要約を書きます。ここでさらに曖昧な点に遭遇します。ChatGPT の記述内容は非個人的なものなのでしょうか? (これについて私が書いた何千もの記事に基づくと、私の現在の意見は「はい」です) また、LLM にどのように対応してもらいたいかについてのより客観的な基準が欠けていることが多いため、クリエイティブなタスクの性質や要求は適切ではないことがよくあります。キューワードを、ハイパーパラメータのように調整および最適化できるパラメータとして考えること。
この時点で、クリエイティブな作業については常識を働かせればよい、と言う人もいるかもしれません。正直に言うと、私も母親に仕事用メールの作成に役立つ ChatGPT の使い方を教えようとするまではそう思っていました。このような場合、プロンプト エンジニアリングは依然として 1 回限りの完成ではなく、継続的な実験と調整による改善が主であるため、独自のアイデアを使用して Prompt を改善し、かつ Prompt の普遍性を維持するにはどうすればよいでしょうか (前の引用で述べたように)。 )、必ずしも明らかではありません。
とにかく、大規模なモデルで生成されたサンプルに対するユーザーのフィードバックに基づいてプロンプトを自動的に改善できるツールを探しましたが、何も見つかりませんでした。そこで、実現可能な解決策が存在するかどうかを検討するために、そのようなツールのプロトタイプを構築しました。この記事の後半では、リアルタイムのユーザー フィードバックに基づいてプロンプト ワードを自動的に改善する、私が実験したツールを紹介します。
01 パート 1 - ソルバーとしての LLM: プロンプト エンジニアリングをハイパーパラメーター最適化の一部として扱う
業界の多くの人は、記事「Large Language Models are Zero-Shot Reasoner」[2] の有名な「Zero-Shot-COT」用語に精通しています (翻訳者注: モデルは、特定のタスクの明示的なトレーニング データを学習していません)次に、既存の知識を組み合わせて新しい問題を解決します。 Zhou et al. (2022) は、「大規模言語モデルは人間レベルのプロンプト エンジニアである」という記事でさらに詳しく調査することにしました [3] その改良版とは何ですか? —— 「正しい答えが得られることを確認するために、段階的に解決していきましょう。」以下は、彼らが提案した自動プロンプト エンジニア手法の概要です。
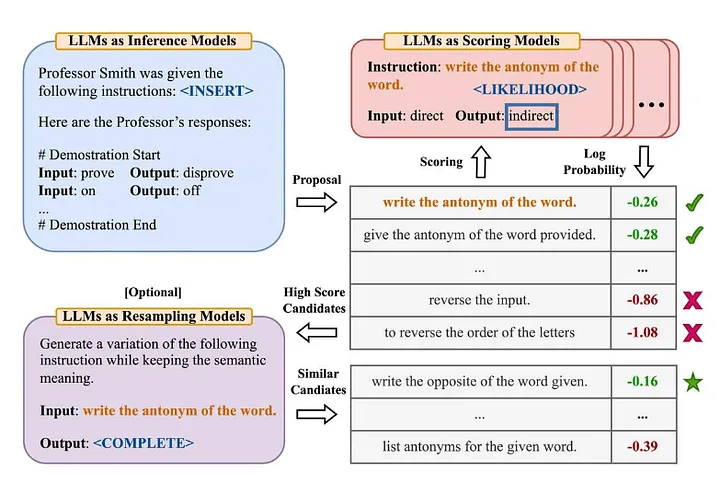
出典: 大規模言語モデルは人間レベルのプロンプト エンジニアです[3]
この文書を要約すると、次のようになります。
- LLM を使用して、指定された入出力ペア (翻訳者注: 入力データと対応するモデル出力データの間の関連付け) に基づいて候補ガイダンス プロンプトを生成します。
- LLM を使用して、指示を使用して生成された回答が期待される回答とどの程度一致するか、または対数確率を評価するために取得されたモデル応答に基づいて、各指示プロンプトをスコア付けします。
- 新たな誘導促進語候補は、スコアの高い誘導促進語候補(指示)に基づいて繰り返し生成される。
いくつかの興味深い結論が見つかりました。
- (ヒューマン プロンプト エンジニア) および以前に提案されたアルゴリズムの優れたパフォーマンスを実証することに加えて、著者らは次のように述べています。サンプル数が少ない場合(ショット数が少ない場合)。
- ほとんどの場合、反復モンテカルロ検索アルゴリズム (Monte Carlo Search) の効果は徐々に弱まっていきますが、元の提案空間 (翻訳者注: モンテカルロ検索アルゴリズムを指す場合があります。最初は候補を生成するために使用されていました) が、問題の最初の範囲や解決策が適切ではないか、十分に効果的ではありません。
そして 2023 年に、Google DeepMind の一部の研究者が「Optimisation by Prompting (OPRO)」と呼ばれる手法を開始しました。前の例と同様に、メタプロンプトには一連の入出力ペア (翻訳者注: 特定のタスクまたは問題の出力の組み合わせを説明する入力と期待値) が含まれています。ここでの主な違いは、メタプロンプトには、事前にトレーニングされたプロンプト単語のサンプルとその正解または解決策、モデルがこれらのプロンプト単語にどれだけ正確に答えたか、さらにメタプロンプトのガイダンス単語のさまざまな部分の違いの詳細も含まれていることです。人間関係のために。
著者らが説明しているように、研究作業におけるキューワード最適化の各ステップでは、モデルが現在のタスクをよりよく理解し、より正確な出力結果を生成できるように、以前の学習軌跡を参照することを目的として、新しいキューワードが生成されます。
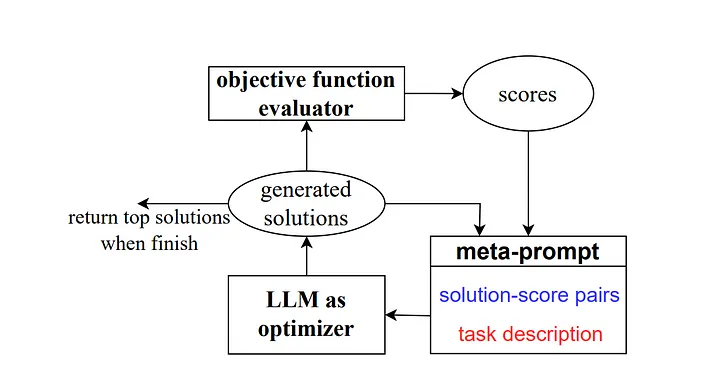
出典: オプティマイザーとしての大規模言語モデル[4]
Zero-Shot-COT シナリオでは、「深呼吸してこの問題に段階的に取り組む」というプロンプトワード最適化手法を提案し、良好な結果を達成しました。
これについてはいくつか考えがあります。
- 「さまざまな種類の言語モデルによって生成される指示プロンプトのスタイルは大きく異なります。PaLM 2-L-IT や text-bison などの一部のモデルは非常に簡潔で明確な指示プロンプトを生成しますが、GPT のような他のモデルでは指示が長く、 「これは注目に値します。現在、市場にあるプロンプト エンジニアリング手法の多くは、OpenAI の言語モデルを参照オブジェクトとして使用して記述されていますが、さまざまなソースからのモデルが使用され始めると、これらの一般的なプロンプト エンジニアリング ガイドラインが機能しなくなる可能性があることに注意する必要があります。それはまあ。例はこの論文のセクション 5.2.3 に示されており、命令の小さな変更に対するモデルのパフォーマンスの感度が高いことを示しています。私たちはこれにもっと注意を払う必要があります。
たとえば、PaLM 2-L を使用して GSM8K テスト セットでモデルを評価した場合、「ステップごとに考えてみましょう」の精度は 71.8% に達し、「一緒に問題を解決しましょう」の精度は 60.5% でした。一方、最初の 2 つの指示語の意味上の組み合わせ「一緒にこの問題を段階的に解決しましょう。」の精度はわずか 49.4% です。
この動作により、シングルステップ命令間の変動と、最適化プロセス中に発生する変動の両方が増加し、最適化プロセスの安定性を向上させるために、各ステップで複数のシングルステップ命令を生成するようになります。
もう一つの重要な点が論文の結論で言及されています:「現実世界の問題に対するアルゴリズムの現在の適用の限界の 1 つは、キューワードを最適化するために使用される大規模な言語モデルが、推論するためのトレーニング セット内の誤ったケースを効果的に利用していないことです。実験では、各最適化ステップでトレーニング セットからランダムにサンプリングするのではなく、メタ プロンプトでモデルがトレーニングまたはテストされたときに発生するエラー ケースを追加しようとしましたが、結果は同様で、唯一の結果が示されました。これらのエラーの場合の情報量は、オプティマイザー LLM (プロンプト単語を最適化するために使用される大規模な言語モデル) が誤った予測の理由を理解するには十分ではありません。プロンプトワードの最適化プロセス 従来の ML/AI のハイパーパラメータ最適化プロセスと似ていますが、LLM にどのような種類のコンテンツ入力を提供するか、LLM をどのように誘導するかにかかわらず、ポジティブでポジティブな例を使用することを好む傾向があります。即発的な言葉を改善します。ただし、従来の ML/AI では、通常、この優先順位はそれほど明白ではなく、エラー自体の方向や種類にあまり注意を払うのではなく、エラー情報を使用してモデルを最適化する方法に重点を置きます。 -5 エラーと +5 エラーはほとんど同等に扱われることに焦点を当てます)。
APE (Automated Prompt Engineering) に興味がある場合は、https://github.com/keirp/automatic_prompt_engineerにアクセスしてダウンロードして使用できます。
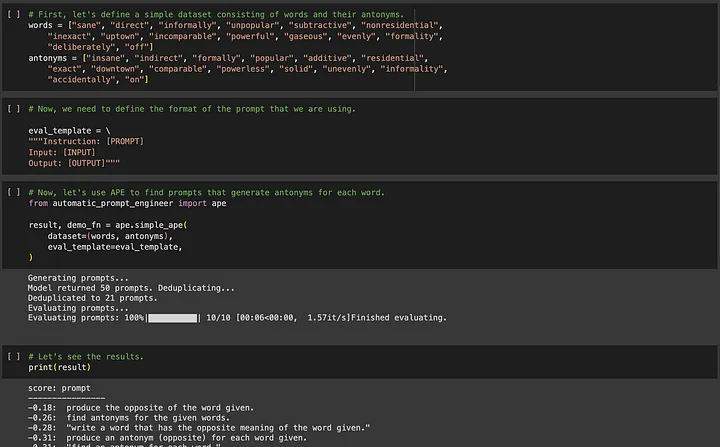
出典: APE のサンプル ノートブックのスクリーンショット[5]
APE と OPRO の両方の方法における重要な要件は、最適化に役立つトレーニング データが必要であり、データ セットが最適化されたキュー ワードの普遍性を保証するのに十分な大きさである必要があることです。
ここで、すぐに利用できるデータがない可能性がある別のタイプの LLM タスクについて話したいと思います。
02 パート 2 - クリエイターとしての LLM: プロンプト エンジニアリングを、常に試行し調整することによる段階的な改善のプロセスとして考える
今、いくつかの短い物語を思いついたとします。
単にモデルをトレーニングするための新しいテキストの例がありません。適格な新しいテキストの例を作成するには時間がかかりすぎます。さらに、受け入れられるモデル出力にはさまざまな種類がある可能性があるため、大規模なモデルに「いわゆる正解」を出力させることが意味があるかどうかはわかりません。したがって、このタイプのタスクでは、APE などの方法を使用してプロンプト ワード エンジニアリングを自動化することはほとんど非現実的です。
しかし、読者の中には、なぜプロンプトワードを書くプロセスを自動化する必要があるのかと疑問に思う人もいるかもしれません。 「 {{issue}} 〜 についての短編小説のアイデアを 3 つ教えてください」などの簡単なプロンプト ワードから始めて、 {{country}}{{issue}} を「不等式」で埋め、{{country}} を「Singapore」で置き換え、モデルの応答を観察します。結果を確認し、問題点を発見し、プロンプトの言葉を調整し、調整が効果的かどうかを観察するというプロセスを繰り返します。
しかしこの場合、キューワードエンジニアリングから最も利益を得るのは誰でしょうか?プロンプトワードを書くことに慣れていない初心者は、モデルに提供されるプロンプトワードを調整して改善するのに十分な経験がありません。私は母親に ChatGPT を使用して仕事を完了するように教えたときに、これを直接経験しました。
私の母は、ChatGPT の出力に対する不満を、プロンプト ワードのさらなる改善につなげるのがあまり得意ではないかもしれません。しかし、私たちのプロンプト ワード エンジニアリング スキルがどれほど優れていても、私たちが本当に得意なのは、問題を明確に表現することであることに気づきました。参照してください(つまり、不平を言う能力)。そこで、ユーザーが苦情を表明できるようにし、LLM にプロンプトの言葉を改善してもらうためのツールを構築しようとしました。私にとって、これは対話のより自然な方法のように見え、クリエイティブなタスクに LLM を使用しようとしている人にとっては簡単になるように思えます。
これは単なる概念実証であることを事前に述べておく必要があります。そのため、読者の皆様が何か良いアイデアをお持ちでしたら、お気軽に著者と共有してください。
まず、{{}} 変数を使用してプロンプト単語を記述します。このツールは、後で埋められるようにこれらのプレースホルダーを検出します。これも上記の例を使用して、シンガポールにおける不平等に関するいくつかの創造的なストーリーを出力するように大規模モデルに要求します。
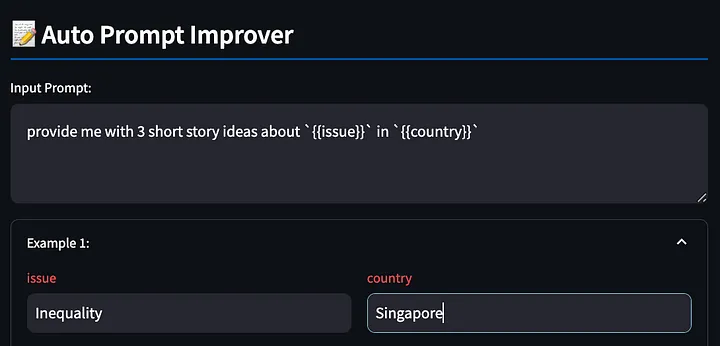
次に、ツールは、入力されたプロンプト単語に基づいてモデル応答を生成します。

次に、フィードバック (モデルの出力に関する苦情) を送信してください。
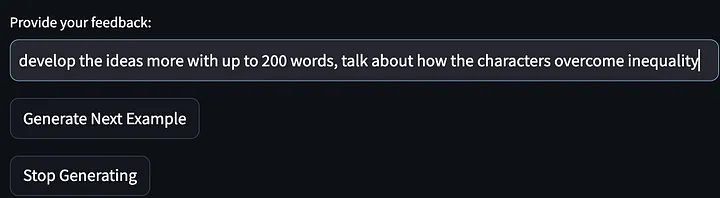
次にモデルは、ストーリーアイデアのさらなる例の生成を停止し、最初の反復から改善された合図の言葉を出力するように求められました。以下に示すプロンプトは、「これらの課題を克服または取り組むための戦略を説明する」ことを要求するために洗練され、一般化されていることに注意してください。そして、最初のモデル出力に対する私のフィードバックは、「物語の主人公が不平等をどのように解決するかについて話す」でした。

次に、修正されたプロンプトワードを使用して、大きなモデルに短編小説を再度考えるように依頼しました。
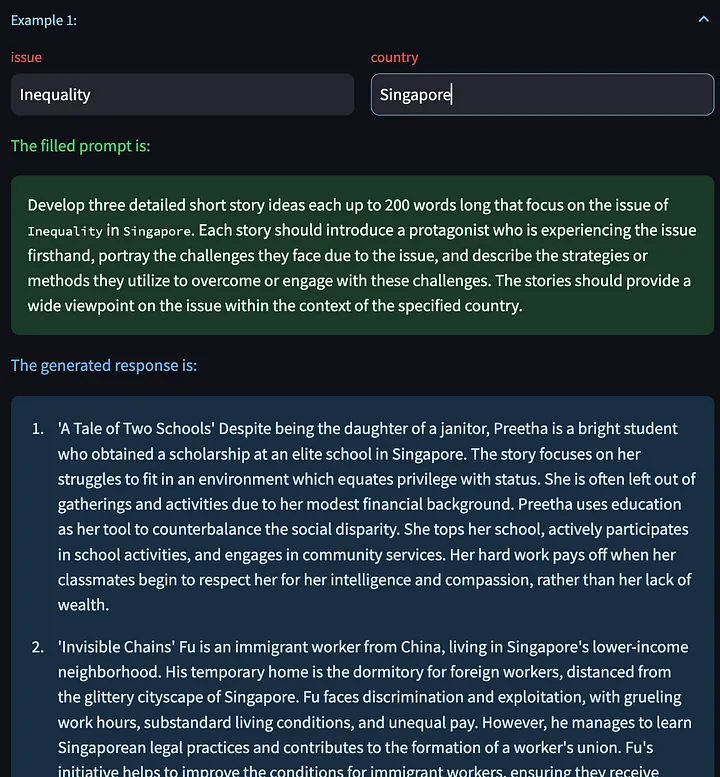
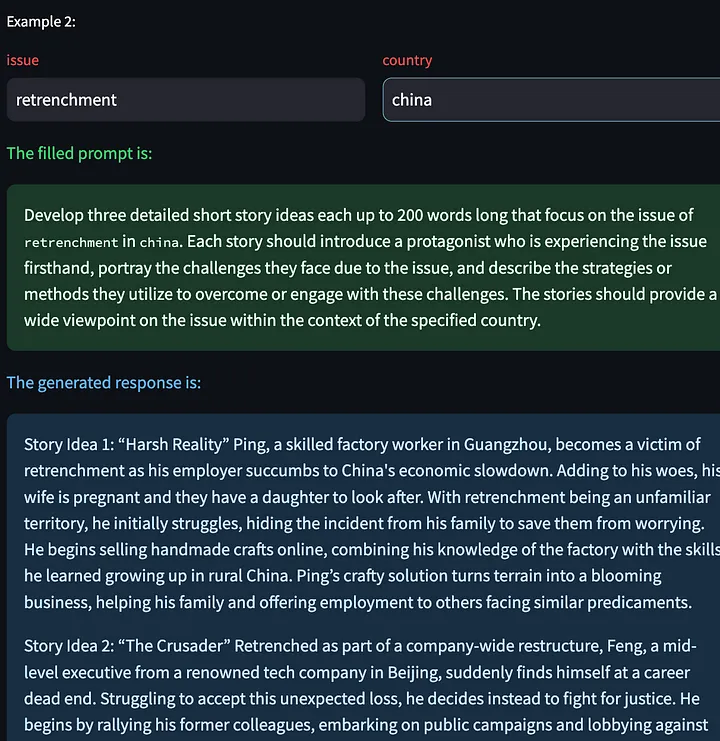
[次の例を生成] をクリックするオプションもあります。これにより、他の入力変数に基づいて新しいモデル応答を生成できます。ここでは、中国における解雇問題に関して生成されたいくつかのクリエイティブなストーリーを示します。
次に、上記のモデルの出力についてフィードバックを提供します。
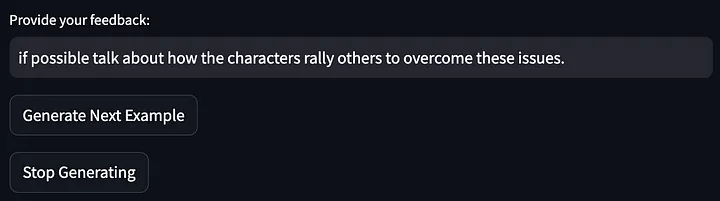
次に、プロンプトの単語がさらに最適化されました。

結局のところ、今回の最適化結果は非常に良好で、最初は単なるプロンプト ワードでしたが、2 分未満の (多少カジュアルではありますが) フィードバックの後、3 回の反復後に最適化されたプロンプト ワードが得られました。これで、単に座って LLM 出力に対する不満を表明するだけで、プロンプトの単語の最適化を続けることができます。
この機能の内部実装は、メタプロンプトから開始し、ユーザーの動的なフィードバックに基づいて継続的に最適化して新しいプロンプトワードを生成します。特別なことは何もなく、さらに改善の余地があることは間違いありませんが、良いスタートだと言えます。
prompt_improvement_prompt = """
# Context #
You are given an original prompt.
The original prompt was used to generate some example responses. For each response, feedback was provided on how to improve the desired response.
Your task is to review all the feedback and then return an improved prompt that addresses the feedback, making it better at generating responses when prompted against the GPT language model.
# Guidelines #
- The original prompt will contain placeholders within double curly brackets. These are values for input that you will see in the examples.
- The improved prompt should not exceed 200 words
- Just return the improved prompt and nothing else before and after. Remember to include the same placeholders with double curly brackets.
- When generating the improved prompt, refrain from writing the entire prompt as one paragraph. Instead, you should use a combination of task descriptions, guidelines (in point form), and other sections to the prompt as appropriate.
- The guidelines should be in point form, and should not be a repetition of the task. The guidelines should also be distinct from one another.
- The improved prompt should be written in normal English that is best understood by the language model.
- Based on the feedback provided, you must rephrase the desired behavior of the response into `must`, imperative statements, instead of `should` suggestive statements.
- Improvements made to the prompt should not be overly specific to one single example.
# Details #
The original prompt is:
```
{original_prompt}
```
These are the examples that were provided and the feedback for each:
```
{examples}
```
The improved prompt is:
```
"""
このツールの使用中に観察された点は次のとおりです。
- GPT4 は、テキストを生成するときに多数の単語を使用する傾向があります (「ポリグロット」機能)。このため、2つの効果が考えられます。まず、この「冗長」プロパティにより、特定の例への過剰適合が促進される可能性があります。 ** LLM に与えられた単語が多すぎる場合、LLM はユーザーから与えられた特定のフィードバックを修正するためにそれらを使用します。第二に、この「言語的」特性は、プロンプトワードの有効性を損なう可能性があり、特に長いプロンプトワードでは、いくつかの重要なガイド情報が不明瞭になる可能性があります。最初の問題は、ユーザーのフィードバックに基づいてモデルを一般化することを促す適切なメタプロンプトを作成することで解決できると思います。しかし、2 番目の問題はさらに困難です。他の使用例では、プロンプトの単語が長すぎると、指示的なプロンプトが無視されることがよくあります。メタプロンプトにいくつかの制限を追加できます (上記のプロンプトの例の単語数の制限など)が、これは実際には任意であり、プロンプトの単語の一部の制限やルールは、基礎となる大規模モデルの影響を受ける可能性があります。特定の属性または動作の影響。
- 改善されたプロンプト ワードでは、プロンプト ワードに対する以前の最適化が忘れられることがあります。この問題を解決する 1 つの方法は、より長い改善履歴をシステムに提供することですが、そうすると改善を促す言葉が長くなりすぎます。
- 最初の反復におけるこのアプローチの利点の 1 つは、LLM がユーザー フィードバックの一部ではない改善のためのガイダンスを提供できることです。たとえば、上記の最初の単語の最適化では、フィードバックが単に信頼できるソースからの関連統計の要求であると指定したにもかかわらず、ツールは「議論されている問題についてより広い視点を提供する…」と追加しました。
このツールはまだデプロイしていません。なぜなら、メタプロンプトで何が最適かを確認し、ストリームリット フレームワークの問題の一部を回避し、プログラムで発生する可能性のある他のエラーや例外を処理する作業をまだ行っているからです。しかし、このツールはすぐに公開されるはずです。
03 おわりに
プロンプト エンジニアリングの分野全体は、タスクを解決するための最適なプロンプト ワードを提供することに重点を置いています。 APE と OPRO はこの分野で最も重要かつ優れた例ですが、これらがすべてを代表するものではありません。私たちはこの分野で将来どれだけ進歩できるかに興奮しており、楽しみにしています。さまざまなモデルに対するこれらの手法の効果を評価することは、これらのモデルの動作傾向や動作特性を明らかにすることができ、どのメタプロンプト手法が効果的であるかを理解するのにも役立ちます。したがって、これらは LLM の使用に役立つ非常に重要なタスクだと思います。私たちの日々の生産現場で。
ただし、これらの方法は、クリエイティブなタスクに LLM を使用したい人には適していない可能性があります。今のところ、学習を始めるための既存の学習マニュアルは数多くありますが、試行錯誤に勝るものはありません。したがって、短期的には、人間の強みに応じてこの実験プロセスをいかに効率的に完了し(フィードバックを与える)、残りをLLMに任せる(プロンプトワードの改善)ことが最も価値があると思います。
また、POC (概念実証) にもさらに取り組んでいきますので、ご興味がございましたら、ぜひご連絡ください ( https://www.linkedin.com/in/ianhojy/)。
読んでくれてありがとう!
終わり
参考文献
[1] https://www.linkedin.com/in/moritz-lauler/?originalSubdomain=de
[2] https://arxiv.org/pdf/2205.11916.pdf
[3] https://arxiv.org/pdf/2211.01910.pdf
[4] https://arxiv.org/pdf/2309.03409.pdf
[5] https://github.com/keirp/automatic_prompt_engineer
[6] https://arxiv.org/abs/2104.08691
[7] https://medium.com/mantisnlp/automatic-prompt-engineering-part-i-main-concepts-73f94846cacb
[8] https://www.promptingguide.ai/techniques/ape
この記事は、原著者の許可を得て、Baihai IDP によって編集されました。翻訳を転載する必要がある場合は、許可を得るため当社までご連絡ください。
元のリンク:
https://towardsdatascience.com/automated-prompt-engineering-78678c6371b9
私はオープンソース紅蒙を諦めることにしました 、オープンソース紅蒙の父である王成露氏:オープンソース紅蒙は 中国の基本ソフトウェア分野における唯一の建築革新産業ソフトウェアイベントです - OGG 1.0がリリースされ、ファーウェイがすべてのソースコードを提供します。 Google Readerが「コードクソ山」に殺される Fedora Linux 40が正式リリース 元Microsoft開発者:Windows 11のパフォーマンスは「ばかばかしいほど悪い」 馬化騰氏と周宏毅氏が「恨みを晴らす」ために握手 有名ゲーム会社が新たな規制を発行:従業員の結婚祝いは10万元を超えてはならない Ubuntu 24.04 LTSが正式リリース Pinduoduoが不正競争の罪で判決 賠償金500万元