
DolphinDB は、分散コンピューティング、トランザクション サポート、マルチモード ストレージ、およびストリーミング バッチ統合機能を備えた高性能の分散時系列データベースであり、ワンストップの高機能データ プラットフォームを簡単に構築するための理想的な軽量ビッグ データ プラットフォームとして非常に適しています。パフォーマンスのリアルタイム データベース。
このチュートリアルでは、ケースとスクリプトを使用して、さまざまな業界 (エネルギーと電力、航空宇宙、車両のインターネット、石油化学、鉱業、インテリジェント製造、貿易、政府関係、ビジネスシナリオにおける膨大なデータの複雑な指標の計算と分析を低遅延で迅速に実装します。
このチュートリアルには、原則と実際の操作の概要、およびサポートされるサンプル コードが含まれており、ユーザーはチュートリアルに従って、独自のビジネス特性を組み合わせて、軽量で高性能のリアルタイム データ ウェアハウスを構築できます。
1 はじめに
1.1 事例の背景とニーズ
ビッグデータ時代の到来により、あらゆる分野でデータ処理のリアルタイム性と精度に対する要求がますます高まっています。従来のオフライン データ ウェアハウスは、企業のデータ ストレージとオフライン分析のニーズをある程度満たすことができますが、多くの場合、大規模なリアルタイム データを処理できません。特に、リアルタイム データに対する非常に高い要件を持つ大手 IoT 企業や金融企業では、オフライン データ ウェアハウスの限界がさらに明らかです。
電力業界の発電所を例にとると、各発電所には多数の計測点があり、発電所の稼働データをリアルタイムに収集します。発電所の膨大な稼働データをどのように組み合わせて、リアルタイムデータの正確かつ複雑な計算と分析を行うかが、発電所にとって大きな課題となっています。従来のリアルタイム データベースには、大規模なデータの集計分析とコンピューティング機能が不足しています。一方、従来のビッグ データ システムによって構築されたオフライン データ ウェアハウスは、処理速度が遅く、遅延が長く、アーキテクチャが複雑であるため、より深いビジネス ニーズを満たすことが困難です。
軽量のワンストップ リアルタイム データ ウェアハウス ソリューションである DolphinDB は、高性能分散コンピューティング フレームワーク、リアルタイム ストリーミング データ処理機能、分散マルチモーダル ストレージ エンジン、およびメモリ コンピューティング テクノロジにより、この問題を解決します。 。
この記事では、DolphinDB を使用して、典型的な発電側の需要シナリオを実装します。発電側で毎秒40,000点の測定点をサンプリングし、各種測定点指標(最大値、最小値、平均値、中央値、95%分位、5%分位、変化量、変化率、開始値、終了値など) .)、ミリ秒レベルのクエリ応答を実現します。これらの指標は、発電所の運転監視、故障警告、エネルギー効率分析、ビッグデータ表示などに重要です。 (その他の IoT 業界シナリオ ソリューションについては、DolphinDB アシスタント dolphindb1 を追加してください)
1.2 データウェアハウスの基本概念
データ ウェアハウス (略して DW または DWH) は、大量のデータを保存、処理、分析するために使用されるシステムであり、特定のビジネス シナリオにおける意思決定プロセスをサポートするように設計されています。データ ウェアハウスは、データを通じて複数のデータ ソース (MySQL、Oracle、MongoDB、HBase など) から異種データ (データ テーブル、Json、CSV、Protobuf など) を収集および統合できる技術アーキテクチャでもあります。クリーニング、統合、変換、ユニファイド ストレージ システム (DolphinDB、Hadoop など) へのデータの統合を行い、多次元のビジネス分析、データ マイニング、正確な意思決定をサポートします。
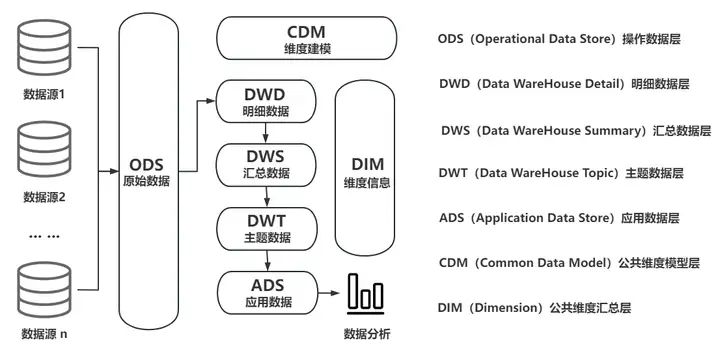
1.1 従来のデータ ウェアハウスの典型的なアーキテクチャ図
データ ウェアハウスの重要性は、企業がデータの一元管理と効率的な利用を実現できることにあります。データ ウェアハウスは、その目的とリアルタイムの性質に応じて、オフライン データ ウェアハウスとリアルタイム データ ウェアハウスの 2 つのタイプに分類できます。
オフライン データ ウェアハウスは通常、T-1 方式で実装されます。つまり、前日の履歴データがジョブ タスクを通じて毎日定時 (早朝など) にデータ ウェアハウスにインポートされ、その後、大量の履歴データがインポートされます (バッチデータ)は、OLAP(オンライン分析処理)を通じて分析されます。
ほとんどの企業にとって、リアルタイムのリスク管理、リアルタイムの影響分析、リアルタイムのプロセス管理などのビジネス機能を実現するための T+0 が緊急に必要とされています。従来のオフライン データ ウェアハウスはリアルタイム要件を満たすことができないため、リアルタイムと分析機能を考慮した新しいデータ ウェアハウス アーキテクチャ、つまりリアルタイム データ ウェアハウスが登場しました。
リアルタイム データ ウェアハウスの技術要件と実装の難易度は、従来のデータ ウェアハウスのそれをはるかに超えています。従来のデータ ウェアハウスと比較して、リアルタイム データ ウェアハウスは、より効率的なデータ処理機能とリアルタイム (準リアルタイム) のデータ更新頻度を実現できます。低レイテンシのパフォーマンス要件の下では、データ ソースの異質性、データ品質管理、トランザクションと強整合性、マルチモード ストレージ、高パフォーマンスの集計分析などの技術的問題を解決する必要があります。さらに、一般の開発者がリアルタイム データ ウェアハウスの開発と運用保守能力をどのように備え、継続的かつ安定的にプロダクト イテレーションを行えるようにするかという点も、非常に大きな試練となります。
1.3 従来のリアルタイム データ ウェアハウスの典型的なアーキテクチャ
従来のリアルタイム データ ウェアハウスは通常、Hadoop ビッグ データ フレームワークに基づいており、Lambda アーキテクチャまたは Kappa アーキテクチャを使用します。このテクノロジーは複雑で開発サイクルが長いため、開発コスト、時間コスト、ハードウェア投資コストの点で企業にとって大きな負担となっています。
従来のリアルタイム データ ウェアハウスの典型的なテクノロジー スタックは次のとおりです。
- コレクション (Sqoop、Flume、Flink CDC、DataX、Kafka)
- ストレージ (HBase、HDFS、Hive、MySQL、MongoDB)
- データ処理とコンピューティング (Hive、Spark、Flink、Storm、Presto)
- OLAP 分析とクエリ (TSDB/HTAP、ES、Kylin、DorisDB)
企業が従来のリアルタイム データ ウェアハウスを実装したい場合、高い学習コスト、大量のリソース消費、不十分なスケーラビリティとリアルタイム パフォーマンスなど、多くの問題に直面することになります。
1.4 DolphinDB リアルタイム データ ウェアハウスのアーキテクチャとパフォーマンス
複雑な従来のリアルタイム データ ウェアハウスとは異なり、DolphinDB は独自の製品機能を通じて軽量のリアルタイム データ ウェアハウスを迅速に実装できます。収集、保存、フロー コンピューティング、ETL、意思決定分析と計算、ビジュアル表示を独立して実行できます。また、企業が展開するさまざまなサードパーティ アプリケーション (ビッグ データ プラットフォーム、AI ミドル プラットフォーム、コックピットなど) の効果的な補足としても使用して、エンタープライズ レベルのアプリケーション システムやグループにリアルタイムのデータ ウェアハウス技術サポートを提供することもできます。より複雑なアプリケーション シナリオを実現するためのレベル データ ミドル プラットフォーム。
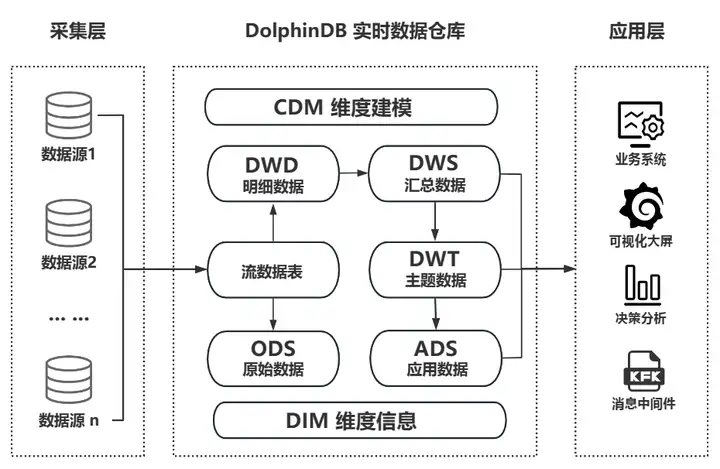
DolphinDB リアルタイム データ ウェアハウス ビジネス アーキテクチャ図
DolphinDB には、モノのインターネットや金融などのさまざまな業界における豊富で成熟したデータ ウェアハウスの実践事例があり、その広範なアプリケーションの価値を十分に実証しています。
地方の税関電子港湾会社のリアルタイム データ ウェアハウス プロジェクトを例に挙げると、DolphinDB によって構築されたリアルタイム データ ウェアハウスは、All In One の軽量ワンストップ製品の利点を最大限に活用しています。マルチソースの異種データへのアクセスをサポートし、標準 SQL と互換性があり、複雑な複数テーブルの関連付けをサポートし、強力な ETL データ クリーニング機能を備えているため、データ処理チェーンが大幅に短縮され、運用、保守、開発のコストが削減されます。その事業構造と技術的特徴を下図に示します。
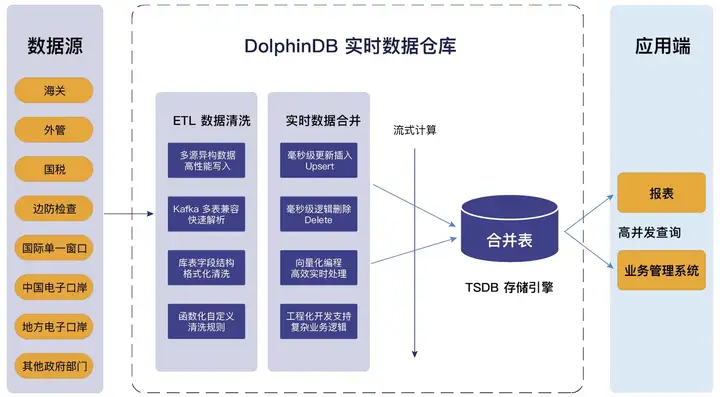
省の電子港湾リアルタイムデータウェアハウスプロジェクトの事業構造図
以下は、3 台のマシンの高可用性クラスターを展開するときに DolphinDB がサポートできるリアルタイム データ ウェアハウス パフォーマンス インジケーターのリファレンスです。
- サポートされる測定点の数: > 1 億測定点
- 書き込みスループット: > 1 億測定ポイント/秒
- ODS でサポートされるレコードの数: > 1 兆
- 最大クライアント接続数: >5000
- 同時クエリ (QPS): >5000
- 多次元集計クエリ: ミリ秒レベル
- リアルタイムストリームコンピューティング特徴量抽出: >500,000/秒
- 単一レコードおよび単一プロセスの削除および変更 (ソフト削除、アップサート) の同期時間: ≈ 10ms
- 高可用性クラスター: 複数のコピー (データの高可用性)、複数の制御ノード (メタデータの高可用性)、クライアントの切断再接続とフェイルオーバー (クライアントの高可用性)
- 柔軟な拡張: ダウンタイムなしの水平方向の拡張 (ノードの追加)、ダウンタイムなしの垂直方向の拡張 (ディスク ボリュームの追加)、およびグレースケール アップグレードをサポートします。
2. DolphinDB リアルタイム データ ウェアハウスの実践
次に、水力発電所の発電機設備のリアルタイム監視という実際のニーズを例として、DolphinDB を使用して軽量のリアルタイム データ ウェアハウスを構築します。この事例は、エネルギーと電力、産業用モノのインターネット、車両のインターネット、その他の産業に適用できます。
ぜひ皆さんも試して一緒に検証してみてください!
2.1 DolphinDB のインストールとデプロイメント
1. 公式 Web サイトのコミュニティの最新バージョンをダウンロードします。バージョン 2.00.11 以降を推奨します。
ポータル: https://cdn.dolphindb.cn/downloads/DolphinDB_Win64_V2.00.11.3.zip
2. Program Files パスへのインストールを避けるため、Windows の解凍パスにはスペースを含めないでください。
公式 Web サイトのチュートリアル: https://docs.dolphindb.cn/zh/tutorials/deploy_dolphindb_on_new_server.htm l
3. このテストはエンタープライズ版を使用しており、無料トライアルライセンスを申し込むことができます。無料のコミュニティ バージョンを使用する場合は、テストのデータ レベルを下げることをお勧めします。
入手方法:https://dolphindb.cn/product#ダウンロード
4. インストールおよびテストのプロセス中に質問がある場合は、バックグラウンドでプライベート メッセージを送信して相談することができます。
2.2 リアルタイム データ ウェアハウス インジケーターの要件
- 基本的なデータ状況
測定点数:40000点
サンプリング周波数:秒
- 算出指標(集計値)

2.3 実践的な計画立案
DolphinDB ストリーム コンピューティング フレームワークに基づいて、エッジに軽量のリアルタイム データ ウェアハウスが構築されます。データの書き込み中にすべての計算結果が効率的に完了し、遅延はミリ秒レベルで制御されます。
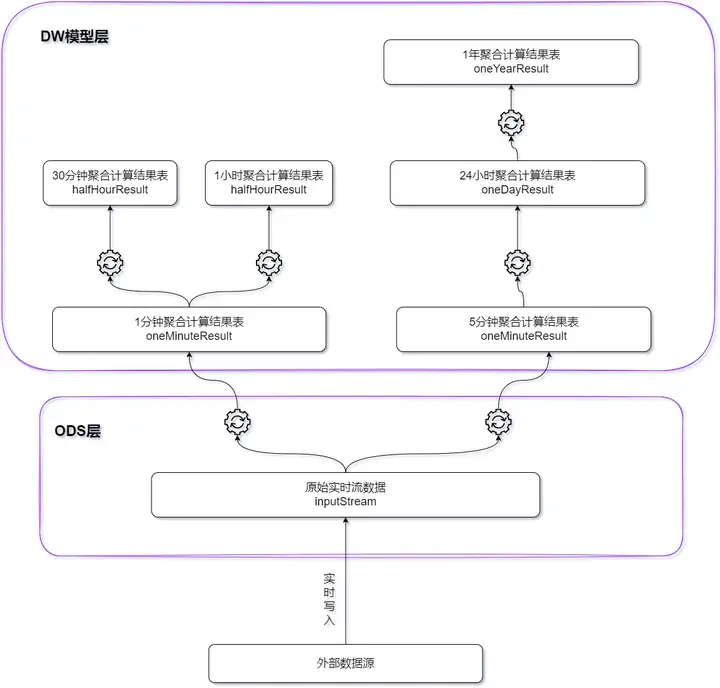
- 1 分の計算期間と 5 分の計算期間を持つインジケーターの場合、元のリアルタイム データがベース テーブルとして使用されます。
- 計算期間が 30 分と計算期間が 1 時間のインジケーターの場合、1 分の計算結果がベース テーブルとして使用されます。
- 24 時間計算サイクル指標の場合、5 分間の計算結果がベーステーブルとして使用されます。
- 計算期間が1年の指標の場合、24時間の計算結果が実表として使用されます。
各タイプのインジケーターの計算ウィンドウとスライディング ステップ サイズは次の表に示すとおりです。
| 計算周期 | ウィンドウの長さ | スライドステップサイズ | 述べる |
|---|---|---|---|
| 1分 | 1分 | 1分 | 1 分ごとに、過去 1 分間のウィンドウ内の値が計算されます |
| 5分 | 5分 | 5分 | 5 分ごとに、過去 5 分間のウィンドウ内の値が計算されます |
| 30分 | 30分 | 30分 | 30 分ごとに、過去 30 分間のウィンドウ内の値が計算されます |
| 1時間 | 1時間 | 1時間 | 1 時間ごとに、過去 1 時間枠内の値が計算されます。 |
| 24時間 | 24時間 | 24時間 | 24 時間ごとに、過去 24 時間のウィンドウ内の値が計算されます |
| 1年 | 1年 | 24時間 | 1 日ごとに、過去 1 年間の値が計算されます。 |
3. 性能試験と結果
3.1 テスト環境
テストと検証を容易にするために、単一マシンおよび単一ノードの展開方法を使用して軽量のリアルタイム データ ウェアハウスを実装します。サーバー構成は次のとおりです。
- CPU:12コア
- メモリ: 32GB
- ディスク: 1.1T HDD 150MB/秒
スクリプトを使用して、24 時間 (2023.01.01T00:00:00-2023.01.02T00:00:01.000) 以内のすべての測定ポイント (40000) のリアルタイム データをシミュレートし、1 分、5 分、30 分、1 を実行します。時間および 24 時間ごとにウィンドウ集計計算が実行され、計算結果が分散データベースに書き込まれます。 (ウィンドウによってはデータ数がウィンドウ長よりも少ない場合があります)
1年ウィンドウの計算では、24時間ウィンドウの計算結果のリアルタイムデータもシミュレーションし、シミュレーション結果をリアルタイムに集計して計算します。
詳細なテスト スクリプトは、記事の最後にある添付ファイルに含まれています。
3.2 試験結果
パフォーマンス テストの結果を次の表に示します。
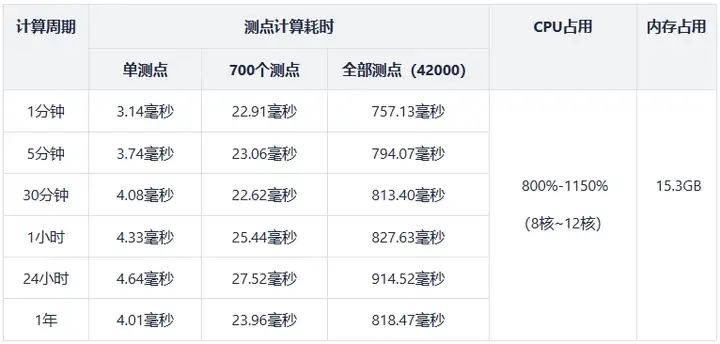
注: 上の表では、すべての測定点の計算時間は、時間ウィンドウ内のすべての測定点の指標を計算する時間です。単一/複数の測定点の計算時間は、選択した測定点の指標を計算する時間です。時間枠内のポイント。
4. まとめ
このチュートリアルの学習と実践を通じて、軽量のリアルタイム データ ウェアハウスを構築する際の DolphinDB の強力な機能を深く理解しました。 DolphinDB は、高性能、分散型、リアルタイム コンピューティングの特性により、大規模なデータに対する複雑な指標の低遅延計算と分析を迅速に実現するための強力なツールをさまざまな業界に提供します。
実際の操作を通じて、DolphinDB の使いやすさと効率性を体験できます。データのインポート、データ クエリ、または複雑なストリーミング計算のいずれであっても、DolphinDB は簡潔かつ明確な構文と強力な機能を提供します。添付のスクリプトには、DolphinDB の基本的な使い方や操作方法だけでなく、リアルタイム データ ウェアハウスの構築原理や応用シナリオについても深く理解できます。これにより、ビジネス ニーズを満たすリアルタイム データ ウェアハウスを迅速に構築し、さまざまな複雑な分析ニーズにリアルタイムで対応できるようになります。
最後に、読者がこのチュートリアルのサンプル コードを独自のビジネス特性と組み合わせて、軽量で高性能のリアルタイム データ ウェアハウスを構築できることを願っています。実際のアプリケーションでは、エネルギーと電力、石油化学産業、インテリジェント製造、航空宇宙、車両のインターネット、金融、その他の産業のいずれであっても、DolphinDB の可能性が継続的に探求されており、実際の幅広いアプリケーションに強力なサポートを提供できます。時間データ ウェアハウス。
5. 付属品
テスト結果は、次のスクリプトを通じて DolphinDB サーバー上で再現できます。
def clearEnv(){
//取消订阅
unsubscribeTable(tableName=`inputStream, actionName="dispatch1")
unsubscribeTable(tableName=`inputStream, actionName="dispatch2")
unsubscribeTable(tableName=`oneMinuteResult, actionName="calcHalfHour")
unsubscribeTable(tableName=`oneMinuteResult, actionName="calcOneHour")
unsubscribeTable(tableName=`fiveMinuteResult, actionName="calcOneDay")
unsubscribeTable(tableName = `oneDayResultSimulate,actionName=`calcOneYear)
unsubscribeTable(tableName = `oneMinuteResult,actionName=`appendInToDFS)
unsubscribeTable(tableName = `fiveMinuteResult,actionName=`appendInToDFS)
unsubscribeTable(tableName = `halfHourResult,actionName=`appendInToDFS)
unsubscribeTable(tableName = `oneHourResult,actionName=`appendInToDFS)
unsubscribeTable(tableName = `oneDayResult,actionName=`appendInToDFS)
unsubscribeTable(tableName = `oneYearResult,actionName=`appendInToDFS)
//删除流计算引擎
for(i in 1..2){
try{dropStreamEngine(`dispatchDemo+string(i))}catch(ex){print(ex)}
}
for(i in 1..5){
try{dropStreamEngine(`oneMinuteCalc+string(i))}catch(ex){print(ex)}
try{dropStreamEngine(`fiveMinuteCalc+string(i))}catch(ex){print(ex)}
}
try{dropStreamEngine(`halfHourCalc)}catch(ex){print(ex)}
try{dropStreamEngine(`oneHourCalc)}catch(ex){print(ex)}
try{dropStreamEngine(`oneDayCalc)}catch(ex){print(ex)}
try{dropStreamEngine(`oneYearCalc)}catch(ex){print(ex)}
//删除流数据表
try{dropStreamTable(`inputStream)}catch(ex){print(ex)}
try{dropStreamTable(`oneMinuteResult)}catch(ex){print(ex)}
try{dropStreamTable(`fiveMinuteResult)}catch(ex){print(ex)}
try{dropStreamTable(`halfHourResult)}catch(ex){print(ex)}
try{dropStreamTable(`oneHourResult)}catch(ex){print(ex)}
try{dropStreamTable(`oneDayResult)}catch(ex){print(ex)}
try{dropStreamTable(`oneDayResultSimulate)}catch(ex){print(ex)}
try{dropStreamTable(`oneYearResult)}catch(ex){print(ex)}
}
def createStreamTable(){
//定义输入流表
enableTableShareAndPersistence(table = streamTable(1000:0,`Time`deviceId`value,`TIMESTAMP`SYMBOL`DOUBLE),
tableName = `inputStream,cacheSize = 1000000,precache=1000000)
colName = `Time`deviceId`filterTime`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last`endTime
colType = `TIMESTAMP`SYMBOL`NANOTIMESTAMP join take(`DOUBLE,10) join `NANOTIMESTAMP
//定义1分钟窗口计算结果流表
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `oneMinuteResult,cacheSize = 1000000,precache=1000000)
//定义5分钟窗口计算结果流表
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `fiveMinuteResult,cacheSize = 1000000,precache=1000000)
//定义30分钟窗口计算结果流表
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `halfHourResult,cacheSize = 1000000,precache=1000000)
//定义1小时窗口计算结果流表
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `oneHourResult,cacheSize = 1000000,precache=1000000)
//定义24小时窗口计算结果流表
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `oneDayResult,cacheSize = 1000000,precache=1000000)
//定义模拟24小时窗口计算结果流表
colName = `TIME`deviceId`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last
colType = `DATE`SYMBOL join take(`DOUBLE,10)
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `oneDayResultSimulate,cacheSize = 1000000,precache=1000000)
//定义1年窗口计算结果流表
colName = `Time`deviceId`filterTime`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last`endTime
colType = `DATE`SYMBOL`NANOTIMESTAMP join take(`DOUBLE,10) join `NANOTIMESTAMP
enableTableShareAndPersistence(table = streamTable(1000:0,colName,colType),
tableName = `oneYearResult,cacheSize = 1000000,precache=1000000)
}
def createDFS(){
//创建存储计算1分钟窗口计算结果表
if(existsDatabase("dfs://oneMinuteCalc")){dropDatabase("dfs://oneMinuteCalc")}
db1 = database(, VALUE,2023.01.01..2023.01.03)
db2 = database(, HASH,[SYMBOL,20])
db = database(directory="dfs://oneMinuteCalc", partitionType=COMPO, partitionScheme=[db1,db2],engine="TSDB")
colName = `Time`deviceId`filterTime`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last`endTime
colType = `TIMESTAMP`SYMBOL`NANOTIMESTAMP join take(`DOUBLE,10) join `NANOTIMESTAMP
t = table(1:0,colName,colType)
pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time","deviceId"],
sortColumns =["deviceId","Time"],compressMethods={Time:"delta"})
//创建存储计算5分钟窗口计算结果表
if(existsDatabase("dfs://fiveMinuteCalc")){dropDatabase("dfs://fiveMinuteCalc")}
db = database(directory="dfs://fiveMinuteCalc", partitionType=VALUE,
partitionScheme=2023.01.01..2023.01.03,engine="TSDB")
t = table(1:0,colName,colType)
pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time"],
sortColumns =["deviceId","Time"],compressMethods={Time:"delta"},
sortKeyMappingFunction=[hashBucket{,100}])
//创建存储计算30分钟窗口计算结果表
if(existsDatabase("dfs://halfHourCalc")){dropDatabase("dfs://halfHourCalc")}
db = database(directory="dfs://halfHourCalc", partitionType=VALUE,
partitionScheme=2023.01.01..2023.01.03,engine="TSDB")
t = table(1:0,colName,colType)
pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time"],
sortColumns =["deviceId","Time"],compressMethods={Time:"delta"})
//创建存储计算1小时窗口计算结果表
if(existsDatabase("dfs://oneHourCalc")){dropDatabase("dfs://oneHourCalc")}
db = database(directory="dfs://oneHourCalc", partitionType=VALUE,
partitionScheme=2023.01.01..2023.01.03,engine="TSDB")
t = table(1:0,colName,colType)
pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time"],
sortColumns =["deviceId","Time"],compressMethods={Time:"delta"})
//创建存储计算24小时窗口计算结果表
if(existsDatabase("dfs://oneDayCalc")){dropDatabase("dfs://oneDayCalc")}
db = database(directory="dfs://oneDayCalc", partitionType=VALUE,
partitionScheme=2023.01.01..2023.01.03,engine="TSDB")
t = table(1:0,colName,colType)
pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time"],
sortColumns =["deviceId","Time"],compressMethods={Time:"delta"})
//创建存储计算1年窗口计算结果表
if(existsDatabase("dfs://oneYearCalc")){dropDatabase("dfs://oneYearCalc")}
db = database(directory="dfs://oneYearCalc", partitionType=VALUE,
partitionScheme=2023.01.01..2023.01.03,engine="TSDB")
t = table(1:0,colName,colType)
pt = db.createPartitionedTable(table=t,tableName ="test" ,partitionColumns = ["Time"],
sortColumns =["deviceId","Time"],compressMethods={Time:"delta"})
}
//1分钟窗口计算过滤函数
def filter1(msg){
t = select *,now(true) as filterTime from msg
getStreamEngine(`dispatchDemo1).append!(t)
}
//5分钟窗口计算过滤函数
def filter2(msg){
t = select *,now(true) as filterTime from msg
getStreamEngine(`dispatchDemo2).append!(t)
}
//30分钟窗口计算过滤函数
def filter3(msg){
t = select *,now(true) as filterTime2 from msg
getStreamEngine(`halfHourCalc).append!(t)
}
//1小时窗口计算
def filter4(msg){
t = select *,now(true) as filterTime2 from msg
getStreamEngine(`oneHourCalc).append!(t)
}
//24小时窗口计算
def filter5(msg){
t = select *,now(true) as filterTime2 from msg
getStreamEngine(`oneDayCalc).append!(t)
}
clearEnv();
createStreamTable();
createDFS();
schemas1 = table(1:0,`Time`deviceId`value`filterTime,`TIMESTAMP`SYMBOL`DOUBLE`NANOTIMESTAMP)
metrics1 = <[first(filterTime),max(value),min(value),mean(value),med(value),percentile(value,95),
percentile(value,5),last(value)-first(value),
(last(value)-first(value))/first(value),first(value),last(value),now(true)]>
//创建1分钟窗口聚合计算引擎
for(i in 1..5){
engine1 = createTimeSeriesEngine(name="oneMinuteCalc"+string(i), windowSize=60000, step=60000,
metrics=metrics1 , dummyTable=schemas1 , outputTable=objByName(`oneMinuteResult),
timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)
}
//创建5分钟窗口聚合计算引擎
for(i in 1..5){
engine2 = createTimeSeriesEngine(name="fiveMinuteCalc"+string(i), windowSize=300000, step=300000,
metrics=metrics1 , dummyTable=schemas1 , outputTable=objByName(`fiveMinuteResult),
timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)
}
//1分钟、5分钟窗口聚合计算分发引擎
dispatchEngine1=createStreamDispatchEngine(name="dispatchDemo1", dummyTable=schemas1, keyColumn=`deviceId,
outputTable=[getStreamEngine("oneMinuteCalc1"),getStreamEngine("oneMinuteCalc2"),
getStreamEngine("oneMinuteCalc3"),getStreamEngine("oneMinuteCalc4"),
getStreamEngine("oneMinuteCalc5")])
dispatchEngine2=createStreamDispatchEngine(name="dispatchDemo2", dummyTable=schemas1, keyColumn=`deviceId,
outputTable=[getStreamEngine("fiveMinuteCalc1"),getStreamEngine("fiveMinuteCalc2"),
getStreamEngine("fiveMinuteCalc3"),getStreamEngine("fiveMinuteCalc4"),
getStreamEngine("fiveMinuteCalc5")])
colName = `Time`deviceId`filterTime`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last`endTime`filterTime2
colType = `TIMESTAMP`SYMBOL`NANOTIMESTAMP join take(`DOUBLE,10) join `NANOTIMESTAMP`NANOTIMESTAMP
schemas2 = table(1:0,colName,colType)
metrics2 = <[first(filterTime2),max(MAX),min(MIN),mean(MEAN),med(MED),avg(P95),avg(P5),last(last)-first(first),
(last(last)-first(first))/first(first),first(first),last(last),now(true)]>
//创建30分钟窗口聚合计算引擎
engine3 = createTimeSeriesEngine(name="halfHourCalc", windowSize=1800000, step=1800000, metrics=metrics2 ,
dummyTable=schemas2 , outputTable=objByName(`halfHourResult),
timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)
//创建1小时窗口聚合计算引擎
engine4 = createTimeSeriesEngine(name="oneHourCalc", windowSize=3600000, step=3600000, metrics=metrics2 ,
dummyTable=schemas2 , outputTable=objByName(`oneHourResult),
timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)
//创建24小时窗口聚合计算引擎
engine5 = createTimeSeriesEngine(name="oneDayCalc", windowSize=86400000, step=86400000,
metrics=metrics2 , dummyTable=schemas2 , outputTable=objByName(`oneDayResult),
timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)
//订阅
subscribeTable(tableName=`inputStream, actionName="dispatch1", handler=filter1, msgAsTable = true,
batchSize = 10240)
subscribeTable(tableName=`inputStream, actionName="dispatch2", handler=filter2, msgAsTable = true,
batchSize = 10240)
subscribeTable(tableName=`oneMinuteResult, actionName="calcHalfHour", handler=filter3,
msgAsTable = true,batchSize = 10240)
subscribeTable(tableName=`oneMinuteResult, actionName="calcOneHour", handler=filter4,
msgAsTable = true,batchSize = 10240)
subscribeTable(tableName=`fiveMinuteResult, actionName="calcOneDay", handler=filter5,
msgAsTable = true,batchSize = 10240)
subscribeTable(tableName = `oneMinuteResult,actionName=`appendInToDFS,offset=0,
handler=loadTable("dfs://oneMinuteCalc","test"),
msgAsTable=true,batchSize=10240)
subscribeTable(tableName = `fiveMinuteResult,actionName=`appendInToDFS,offset=0,
handler=loadTable("dfs://fiveMinuteCalc","test"),
msgAsTable=true,batchSize=10240)
subscribeTable(tableName = `halfHourResult,actionName=`appendInToDFS,offset=0,
handler=loadTable("dfs://halfHourCalc","test"),
msgAsTable=true,batchSize=10240)
subscribeTable(tableName = `oneHourResult,actionName=`appendInToDFS,offset=0,
handler=loadTable("dfs://oneHourCalc","test"),
msgAsTable=true,batchSize=10240)
subscribeTable(tableName = `oneDayResult,actionName=`appendInToDFS,offset=0,
handler=loadTable("dfs://oneDayCalc","test"),
msgAsTable=true,batchSize=10240)
def filter6(msg){
tmp = select * ,now(true) as filterTime from msg
getStreamEngine(`oneYearCalc).append!(tmp)
}
colName = `Time`deviceId`MAX`MIN`MEAN`MED`P95`P5`CHANGE`CHANGE_RATE`first`last`filterTime
colType = `DATE`SYMBOL join take(`DOUBLE,10) join `NANOTIMESTAMP
schemas3 = table(1:0,colName,colType)
metrics3 = <[last(filterTime),max(MAX),min(MIN),mean(MEAN),med(MED),avg(P95),avg(P5),last(last)-first(first),
(last(last)-first(first))/first(first),first(first),last(last),now(true)]>
engine6 = createTimeSeriesEngine(name="oneYearCalc", windowSize=365, step=1, metrics=metrics3 ,
dummyTable=schemas3 , outputTable=objByName(`oneYearResult),
timeColumn = `Time, useSystemTime=false, keyColumn = `deviceId)
subscribeTable(tableName = `oneDayResultSimulate,actionName=`calcOneYear, handler=filter6,
msgAsTable = true,batchSize = 10240)
subscribeTable(tableName = `oneYearResult,actionName=`appendInToDFS,offset=0,
handler=loadTable("dfs://oneYearCalc","test"),
msgAsTable=true)
deviceIdList = lapd(string(rand(10000,700)),6,"0") //测点id
//模拟数据的函数,一共模拟1小时的数据
def simulateData(deviceIdList){
num = deviceIdList.size()
startTime = timestamp(2023.01.01)
do{
Time = take(startTime,num)
deviceId = deviceIdList
value = rand(100.0,num)
objByName(`inputStream).append!(table(Time,deviceId,value))
startTime = startTime+1000
sleep(100)
}while(startTime<=2023.01.02T00:00:10.000)
}
def simulateOneDay(deviceIdList){
num = deviceIdList.size()
startTime =2022.01.01
do{
Time = take(startTime,num)
deviceId = deviceIdList
MAX = rand(100.0,num)
MIN = rand(100.0,num)
MEAN = rand(100.0,num)
MED = rand(100.0,num)
P95 = rand(100.0,num)
P5 = rand(100.0,num)
CHANGE = rand(100.0,num)
CHANGE_RATE = rand(100.0,num)
first = rand(100.0,num)
last = rand(100.0,num)
tmp = table(Time,deviceId,MAX,MIN,MEAN,MED,P95,P5,CHANGE,CHANGE_RATE,first,last)
objByName(`oneDayResultSimulate).append!(tmp)
startTime = startTime+1
sleep(500)
}while(startTime<=2023.12.31)
}
submitJob("simulateData","write",simulateData,deviceIdList)
submitJob("simulateOneDay","write",simulateOneDay,deviceIdList)
//耗时统计
tmp1 = select Time,deviceId,filterTime,endTime from loadTable("dfs://oneYearCalc","test") order by Time,deviceId
tmp2 = select Time,deviceId,next(filterTime) as startTime,endTime from tmp1 context by deviceId
select avg(endTime-startTime)\1000\1000 as timeUsed from tmp2 group by deviceId //统计单个测点的计算耗时
tmp3 = select min(startTime) as st,max(endTime) as dt from tmp2 group by Time
select (dt-st)\1000\1000 as used from tmp3 //统计整个时间窗口的计算耗时