

オープンソース モデルを中心に AI アプリケーションを構築すると、アプリケーションをより良く、より安く、より速くすることができます。
著者 Aidan Cooper のHow to Beat Proprietary LLMs With Smaller Open Source Modelsから翻訳。
導入
テキスト生成モデルを使用するシステムを設計するとき、多くの人はまず OpenAI の GPT-4 や Google の Gemini などの独自のサービスに目を向けます。結局のところ、これらは世の中で最大かつ最高のモデルなので、なぜ他のものを気にする必要があるのでしょうか?最終的に、アプリケーションはこれらの API がサポートできない規模に達するか、コストが法外に高くなるか、応答時間が非常に遅くなります。オープンソース モデルはこれらすべての問題を解決できますが、独自の LLM を使用するのと同じ方法でオープン ソース モデルを使用しようとすると、十分なパフォーマンスが得られません。
この記事では、オープンソース LLM の独自の利点と、それを活用してプロプライエタリ LLM よりも安価で高速なだけでなく、優れた AI アプリケーションを開発する方法について説明します。
プロプライエタリ LLM とオープンソース LLM の比較
表 1 は、プロプライエタリ LLM とオープンソース LLM の主な特徴を比較しています。オープンソース LLM は、オンプレミスでもクラウドでも、ユーザー管理のインフラストラクチャ上で実行されると考えられています。要約すると、プロプライエタリ LLM はマネージド サービスであり、最も強力なクローズド ソース モデルと最大のコンテキスト ウィンドウを提供しますが、他の重要な点ではオープン ソース LLM の方が優れています。
以下は、中国語版の表 (マークダウン形式) です。
| 独自の大規模言語モデル | オープンソースの大規模言語モデル | |
|---|---|---|
| 例 | GPT-4 (OpenAI)、Gemini (Google)、Claude (Anthropic) | ジェマ 2B (Google)、ミストラル 7B (ミストラル AI)、ラマ 3 70B (メタ) |
| ソフトウェアのアクセシビリティ | クローズドソース | オープンソース |
| パラメータの数 | 兆レベル | 典型的なスケール: 2B、7B、70B |
| コンテキストウィンドウ | より長い、100k-1M+トークン | より短い、一般的な 8,000 ~ 32,000 トークン |
| 能力 | すべてのリーダーボードとベンチマークで最高のパフォーマー | 歴史的に独自の大規模言語モデルに後れを取っている |
| インフラストラクチャー | プロバイダーによって管理されるサービスとしてのプラットフォーム (PaaS)。構成できません。 API レート制限。 | 通常はクラウド インフラストラクチャ (IaaS) で自己管理されます。完全に構成可能。 |
| 推論コスト | より高い | より低い |
| スピード | 同じ価格帯では遅い。調整できません。 | インフラストラクチャ、テクノロジー、最適化に依存しますが、より速くなります。高度に構成可能。 |
| スループット | 通常は API レート制限の対象となります。 | 無制限: インフラストラクチャに合わせて拡張します。 |
| 遅れ | より高い。会話を複数ラウンド行うと、ネットワーク遅延が大幅に蓄積する可能性があります。 | モデルをローカルで実行する場合、ネットワーク遅延は発生しません。 |
| 関数 | 通常、API を通じて限定された機能セットを公開します。 | モデルに直接アクセスすると、多くの強力なテクニックが利用可能になります。 |
| キャッシュ | サーバー側にアクセスできません | スループットを向上させ、コストを削減するための構成可能なサーバー側ポリシー。 |
| 微調整 | 限定的な微調整サービス (OpenAI など) | 微調整を完全に制御します。 |
| プロンプト/フロープロジェクト | コストが高いため、またはレート制限や遅延により不可能な場合が多い | 制限がなく、慎重に設計された制御プロセスにより、悪影響は最小限に抑えられます。 |
**表 1.** プロプライエタリ LLM とオープンソース LLM 機能の比較
この記事の焦点は、オープンソース モデルの強みを活用することで、独自の LLM よりも優れたタスクを実行すると同時に、より優れたスループットとコスト プロファイルを実現する AI アプリケーションを構築できるということです。
私たちは、独自の LLM では不可能な、または効果が低いオープンソース モデルの戦略に焦点を当てます。これは、少数ショットのヒントや検索拡張生成 (RAG) など、両方に利益をもたらす手法については説明しないことを意味します。
効果的な LLM システムの要件
LLM を中心に効果的なシステムを設計する方法を考えるとき、心に留めておくべき重要な原則がいくつかあります。
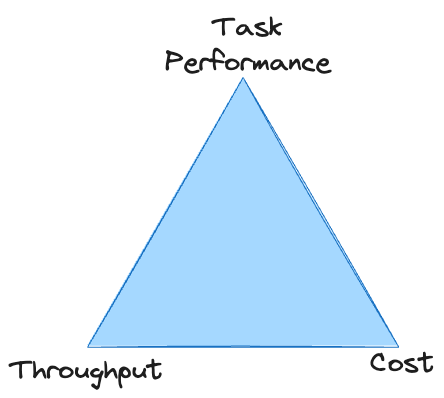
タスクのパフォーマンス、スループット、コストの間には直接的なトレードオフがあります。これらのいずれかを改善するのは簡単ですが、通常は他の 2 つが犠牲になります。無制限の予算がない限り、システムが存続するには、3 つの領域すべてで最低基準を満たしている必要があります。独自の LLM を使用すると、三角形の頂点で行き詰まり、許容可能なコストで十分なスループットを達成できないことがよくあります。
それぞれの問題の解決に役立つ戦略を検討する前に、これらの非機能要件のそれぞれの特徴について簡単に説明します。
スループット
多くの LLM システムは、LLM が遅いという理由だけで、適切なスループットを達成するのに苦労しています。
LLM を使用する場合、システム全体のスループットは、テキスト出力の生成に必要な時間によってほぼ完全に決まります。
データ処理が特に重い場合を除き、テキスト生成以外の要素は比較的重要ではありません。 LLM は、テキストを生成するよりもはるかに速くテキストを「読み取る」ことができます。これは、入力トークンが並行して計算され、出力トークンが順次生成されるためです。
品質を犠牲にしたり過剰なコストをかけたりすることなく、テキスト生成速度を最大化する必要があります。
これにより、スループットを向上させることが目標の場合、次の 2 つのレバーを引くことができます。
- 生成する必要があるトークンの数を減らす
- 個々のトークンの生成速度を向上させます。
以下の戦略の多くは、これらの領域の一方または両方を改善するように設計されています。
料金
独自の LLM の場合は、入力トークンと出力トークンごとに請求されます。各トークンの価格は、使用するモデルの品質 (つまり、サイズ) に関連します。これにより、コストを削減するためのオプションが限られます。入力/出力トークンの数を減らすか、より安価なモデルを使用する必要があります (選択できるモデルはあまり多くありません)。
セルフホスト型 LLM の場合、コストはインフラストラクチャによって決まります。ホスティングにクラウド サービスを使用する場合、仮想マシンを「レンタル」した時間単位ごとに料金が請求されます。

大規模なモデルには、より大規模で高価な仮想マシンが必要になります。ハードウェアを変更せずにスループットを向上させると、固定量のデータの処理に必要なコンピューティング時間が短縮されるため、コストが削減されます。同様に、ハードウェアを垂直または水平にスケーリングすることでスループットを向上させることもできますが、コストが増加します。
コストを最小限に抑えるための戦略は、タスク用に小型のモデルを有効にすることに重点を置いています。これは、これらのモデルのスループットが最も高く、実行コストが最も安価であるためです。
タスクパフォーマンス
ミッションのパフォーマンスは 3 つの要件の中で最も曖昧ですが、最適化と改善の範囲が最も広い要件でもあります。適切なタスクのパフォーマンスを達成するための主な課題の 1 つは、そのパフォーマンスを測定することです。LLM 出力の信頼できる定量的な評価を適切に取得することは困難です。
私たちは、オープンソース LLM に独自のメリットをもたらすテクノロジーに重点を置いているため、より少ないリソースでより多くのことを実行し、モデルへの直接アクセスでのみ可能となる方法を活用することを戦略で重視しています。
プロプライエタリな LLM を打ち破るオープンソース LLM 戦略
以下の戦略はすべて単独でも効果的ですが、補完的なものでもあります。これらをさまざまな程度に適用して、システムの非機能要件間の適切なバランスをとり、全体的なパフォーマンスを最大化することができます。
マルチターンダイアログと制御フロー
- タスクのパフォーマンスを向上させる
- スループットの低下
- 入力あたりのコストを追加する
独自の LLM ではさまざまなマルチターン対話戦略を使用できますが、これらの戦略は次の理由から実行不可能であることがよくあります。
- トークンで請求するとコストがかかる可能性がある
- 入力ごとに複数の API 呼び出しが必要となるため、API レート制限を使い果たす可能性があります
- 往復の交換に多くのトークンの生成が含まれる場合、または大量のネットワーク遅延が蓄積される場合は、遅すぎる可能性があります。
独自の LLM がより高速で、よりスケーラブルになり、より手頃な価格になるにつれて、この状況は時間の経過とともに改善される可能性があります。しかし現時点では、独自の LLM は多くの場合、現実世界のユースケースに大規模に適用できる単一の単一プロンプト戦略に限定されています。これは、独自の LLM によって提供されるより大きなコンテキスト ウィンドウと一致しています。多くの場合、推奨される戦略は、多くの情報と指示を 1 つのプロンプトに詰め込むことです (ちなみに、これはコストと速度にマイナスの影響を及ぼします)。
セルフホスト型モデルでは、マルチラウンド会話のこれらの欠点はあまり気にされません。トークンあたりのコストはあまり関係なく、API レート制限がなく、ネットワーク遅延を最小限に抑えることができます。オープンソース モデルのコンテキスト ウィンドウが小さく、推論機能が弱いため、単一のヒントを使用することもできません。これにより、独自の LLM を打ち負かすための中核となる戦略がわかります。
独自の LLM を克服する鍵は、より小さなオープンソース モデルを使用して、一連のよりきめの細かいサブタスクでより多くの作業を実行することです。
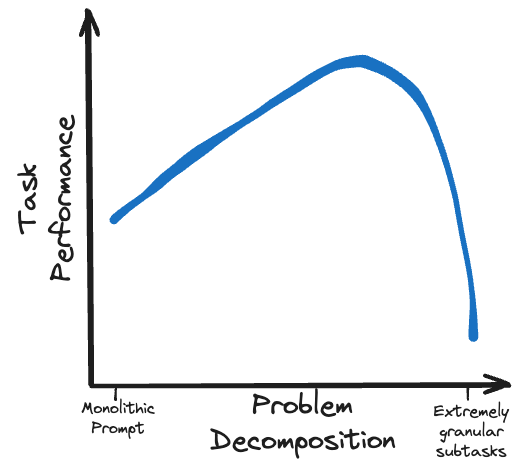
慎重に策定された複数ラウンドのプロンプト戦略は、ローカル モデルで実現可能です。Chain of Thoughts (CoT)、Trees of Thought (ToT)、ReActなどの手法を使用すると、能力の低いモデルでも大規模なモデルと同等のパフォーマンスを実現できます。
もう 1 つのレベルの複雑さは、モデルを正しい推論パスに沿って動的にガイドし、一部の処理タスクを外部関数にオフロードするための制御フローと分岐の使用です。これらは、メイン プロンプト フローの外側の分岐でサブタスクをフォークし、それらのフォークの集計結果を再結合することにより、コンテキスト ウィンドウのトークン バジェットを保存するメカニズムとしても使用できます。
小規模なオープンソース モデルに過度に複雑なタスクを課すのではなく、問題を実行可能なサブタスクの論理フローに分割します。
制限されたデコード
- スループットの向上
- コストカット
- タスクのパフォーマンスを向上させる
構造化出力 (JSON オブジェクトなど) の生成を伴うアプリケーションの場合、制限付きデコードは次のことを可能にする強力な手法です。
- 要求された構造に準拠した出力を保証
- トークン生成を高速化し、生成する必要があるトークンの数を減らすことで、スループットを大幅に向上します。
- モデルをガイドすることでタスクのパフォーマンスを向上させる
このトピックについて詳しく説明した別の記事を書きました:制限付きデコードによる構造化生成ガイド 言語モデル出力の生成方法、理由、機能、および落とし穴
重要なことは、制約デコードは、完全な次のトークン確率分布への直接アクセスを提供するテキスト生成モデルでのみ機能することです。この分布は、この記事の執筆時点では、主要な独自の LLM プロバイダーからは利用できません。
OpenAI はJSON スキーマを提供しますが、この厳密に制限されたデコードでは、JSON 出力の構造的またはスループットの利点が保証されません。
制約デコードは、さまざまな分岐オプションへの応答を制限することで、大規模な言語モデルを事前に指定されたパスに確実に誘導できるため、制御フロー戦略と連携しています。一連の長い複数ターンにわたる対話の質問に対する短く、制約された回答を生成するようにモデルに依頼することは、非常に高速かつ低コストです (スループット速度は生成されるトークンの数によって決まることに注意してください)。
制約デコードには目立った欠点はないため、タスクで構造化された出力が必要な場合は、制約デコードを使用する必要があります。
キャッシュ、モデルの量子化、その他のバックエンドの最適化
- スループットの向上
- コストカット
- タスクのパフォーマンスには影響しません
キャッシュは、計算の入力と出力のペアを保存し、同じ入力が再び発生した場合に結果を再利用することにより、データ取得操作を高速化する手法です。
非 LLM システムでは、通常、以前に確認されたリクエストと完全に一致するリクエストにキャッシュが適用されます。一部の LLM システムでも、この厳密な形式のキャッシュから恩恵を受ける場合がありますが、一般に、LLM を使用して構築する場合、まったく同じ入力に頻繁に遭遇することは望ましくありません。
幸いなことに、 LLM 専用の、はるかに柔軟な高度なキー/値キャッシュ技術があります。これらの手法を使用すると、以前に確認された入力に部分的に一致するが正確には一致しないリクエストのテキスト生成を大幅に高速化できます。これにより、生成する必要があるトークンの量が減り (または、特定のキャッシュ テクノロジとシナリオによっては少なくともトークンの速度が向上します)、システムのスループットが向上します。
独自の LLM では、リクエストに対してキャッシュがどのように実行されるか、または実行されないかを制御できません。ただし、オープンソース LLM の場合、推論スループットを大幅に向上させ、システムのカスタマイズされた要件に応じて構成できる LLM サービス用のさまざまなバックエンド フレームワークが存在します。
キャッシュに加えて、モデルの量子化など、推論スループットを向上させるために使用できる LLM 最適化もあります。モデルの重み付けに使用される精度を下げることにより、出力の品質を大幅に損なうことなく、モデルのサイズ (したがってメモリ要件) を削減できます。人気のあるモデルには、オープン ソース コミュニティによって提供された Hugging Face で利用可能な量子化されたバリアントが多数用意されていることが多く、これにより、量子化プロセスを自分で実行する必要がなくなります。
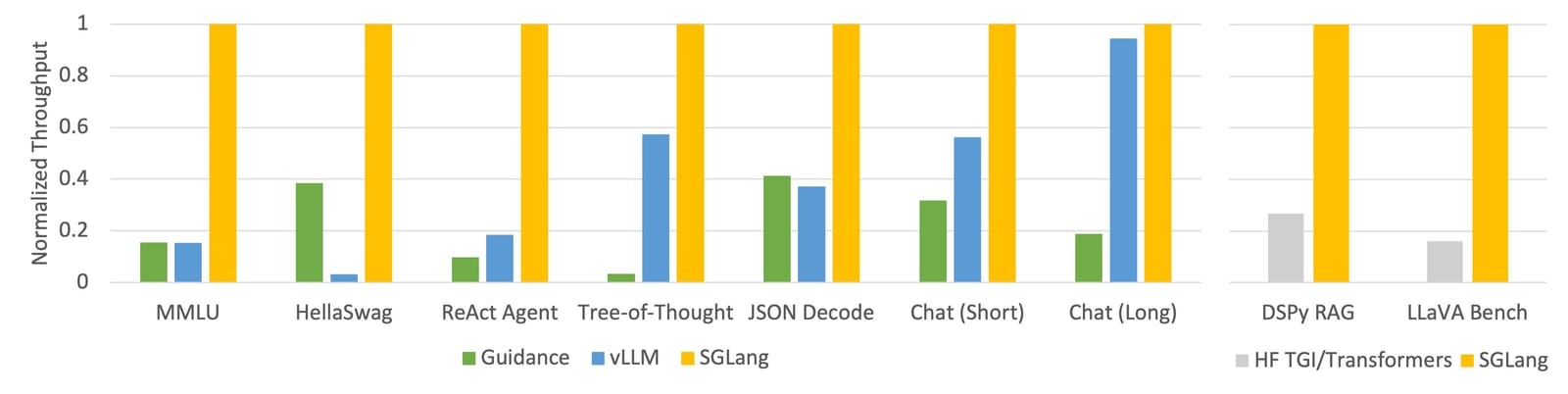
SGLang の驚異的なスループットの発表 (SGLang リリースのブログ投稿を参照)
vLLM は、さまざまなキャッシュ メカニズム、並列化、カーネル最適化、モデル量子化手法を備えた、おそらく最も成熟したサービス フレームワークです。SGLang は、vLLM と同様の機能を備えた新しいプレーヤーであり、特に優れたパフォーマンスを誇る革新的なRadixAttendantキャッシュ メソッドも備えています。
モデルを自己ホストする場合は、スループットが少なくとも 1 桁向上することが合理的に期待できるため、これらのフレームワークと最適化手法を使用する価値は十分にあります。
モデルの微調整と知識の抽出
- タスク実行効率の向上
- 推論コストには影響しない
- スループットには影響しません
微調整には、特定のタスクのパフォーマンスを向上させるために既存のモデルを調整するためのさまざまな手法が含まれます。このトピックの入門書として、微調整方法に関するSebastian Raschka のブログ投稿をチェックすることをお勧めします。知識の蒸留は、対象のタスクに関するより大きな「教師」モデルの出力をシミュレートするために、より小さな「生徒」モデルをトレーニングする関連概念です。
OpenAIなどの一部の独自の LLM プロバイダーは、最小限の微調整機能を提供します。ただし、微調整プロセスを完全に制御し、包括的な微調整テクノロジーにアクセスできるのは、オープンソース モデルだけです。
モデルを微調整すると、推論コストやスループットに影響を与えることなく、タスクのパフォーマンスを大幅に向上させることができます。ただし、微調整の実装には時間、スキル、適切なデータが必要であり、トレーニング プロセスにはコストがかかります。LoRAなどの PEFT ( Parameter Efficient Fine-Tuning ) 手法は、必要なリソース量に比べて最高のパフォーマンスが得られるため、特に魅力的です。
微調整と知識の蒸留は、モデルのパフォーマンスを最大化するための最も強力なテクニックの 1 つです。正しく実装されている限り、実行に必要な初期投資を除いて欠点はありません。ただし、キュー フローや制限されたデコード出力構造など、システムの他の側面と一貫した方法で微調整が行われるように注意する必要があります。これらのテクノロジー間に違いがある場合、予期しない動作が発生する可能性があります。
モデルサイズの最適化
小型モデル:
- スループットの向上
- コストカット
- タスクの実行パフォーマンスを低下させる
これは、反対の長所と短所を備えた「大型モデル」とも言えます。重要なポイントは次のとおりです。
モデルをできるだけ小さくしますが、それでもタスクを理解し、確実に完了するのに十分な容量を維持します。
ほとんどの独自の LLM プロバイダーは、いくつかのモデル サイズ/機能層を提供しています。そして、オープンソースに関しては、最大 100B 以上のパラメータに至るまで、あらゆるサイズのめまいのするようなモデル オプションがあります。
マルチターン会話セクションで述べたように、複雑なタスクを一連のより管理しやすいサブタスクに分割することで、それらを簡素化できます。しかし、これ以上分解できない問題、または分解すると、より完全に対処する必要があるミッションの側面が損なわれる可能性がある問題が常に存在します。これはユースケースに大きく依存しますが、最小のモデル サイズで適切なタスク パフォーマンスを達成できることからわかるように、タスクの粒度と複雑さによって、モデルの適切なサイズを決定するスイート スポットが存在します。
これは、一部のタスクでは、見つけられる最大かつ最も機能的なモデルを使用することを意味しますが、他のタスクでは、非常に小さなモデル (非 LLM であっても) を使用できる場合があります。
いずれの場合も、特定のパラメーター サイズでクラス最高のモデルを使用することを選択してください。これは、この分野の開発の急速なペースに基づいて定期的に変更される公開ベンチマークとランキングを参照することで特定できます。一部のベンチマークは他のベンチマークよりもユースケースに適しているため、どれが最適に機能するかを調べる価値があります。
ただし、単に新しい最高のモデルに置き換えるだけで、すぐにパフォーマンスの向上が達成できるとは考えないでください。モデルが異なれば故障モードや特性も異なるため、あるモデルに最適化されたシステムが、たとえより優れているはずであっても、別のモデルでも機能するとは限りません。
技術ロードマップ
前述したように、これらの戦略はすべて補完的であり、組み合わせると複合して堅牢で包括的なシステムが生成されます。ただし、これらのテクノロジー間には依存関係があるため、機能不全を防ぐために一貫性を確保することが重要です。
次の図は、これらのテクノロジを実装するための論理シーケンスを示す依存関係図です。これは、ユースケースで構造化された出力を生成する必要があることを前提としています。
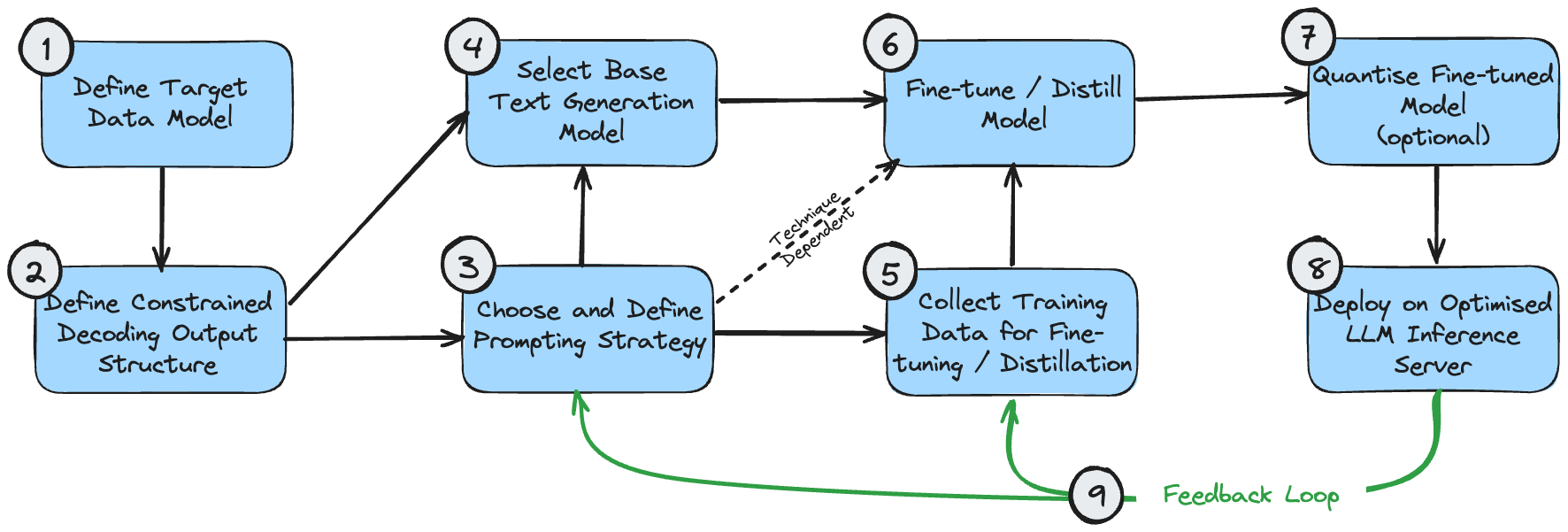
これらの段階は次のように理解できます。
- ターゲット データ モデルは、作成する最終出力です。これは、ユースケースと、テキスト処理の生成を超えたシステム全体の広範な要件によって決まります。
- 制限付きデコードの出力構造は、ターゲット データ モデルと同じである場合もありますが、制限付きデコード中に最適なパフォーマンスを得るためにわずかに変更される場合もあります。なぜこれが起こるのかを理解するには、私の制限されたデコードに関する記事を参照してください。異なる場合は、最終的なターゲット データ モデルに変換するための後処理段階が必要になります。
- ユースケースに応じた正しいプロンプト戦略について、最初に最善の推測を行う必要があります。問題が単純な場合、または直感的に分解できない場合は、単一のプロンプト戦略を選択します。問題が非常に複雑で、細かいサブコンポーネントが多数ある場合は、マルチプロンプト戦略を選択します。
- 最初のモデルの選択は主に、サイズを最適化し、モデルのプロパティが問題の機能要件を満たしていることを確認することです。最適なモデル サイズについては上で説明しました。必要なコンテキスト ウィンドウの長さなどのモデル プロパティは、予想される出力構造 ((1) および (2)) とプロンプト戦略 (3) に基づいて計算できます。
- モデルの微調整に使用されるトレーニング データは、出力構造 (2) と一致している必要があります。出力を段階的に構築するマルチキュー戦略が使用される場合、トレーニング データもこのプロセスの各段階を反映する必要があります。
- モデルの微調整/蒸留は、当然のことながら、モデルの選択、トレーニング データのキュレーション、およびプロンプト フローに依存します。
- 微調整モデルの量子化はオプションです。定量化オプションは、選択した基本モデルによって異なります。
- LLM 推論サーバーは特定のモデル アーキテクチャと量子化方法のみをサポートするため、以前の選択が目的のバックエンド構成と互換性があることを確認してください。
- エンドツーエンドのシステムを導入したら、継続的な改善のためのフィードバック ループを作成できます。システムが許容可能な出力を生成できない例を考慮して、プロンプトと数ショットの例 (使用している場合) を定期的に調整する必要があります。失敗ケースの適切なサンプルを蓄積したら、これらのサンプルを使用してモデルをさらに微調整することも検討する必要があります。
実際には、開発プロセスは決して完全に直線的ではないため、ユースケースによっては、これらのコンポーネントの一部を他のコンポーネントよりも優先して最適化する必要がある場合があります。ただし、これは、特定の要件に基づいてロードマップを設計するための合理的な基礎です。
結論は
オープンソース モデルは、プロプライエタリな LLM よりも高速で、安価で、優れたものとなる可能性があります。これは、オープンソース モデルの独自の強みを活用し、スループット、コスト、ミッション パフォーマンスの間で適切なトレードオフを行う、より複雑なシステムを設計することで実現できます。
この設計選択により、システムの複雑さと引き換えに全体的なパフォーマンスが得られます。有効な代替案は、独自の LLM を搭載した、よりシンプルで同等に強力なシステムを使用することですが、コストは高く、スループットは低くなります。正しい決定は、アプリケーション、予算、エンジニアリング リソースの可用性によって異なります。
ただし、テクノロジー戦略を適応させずに、オープンソース モデルをすぐに放棄しないでください。その機能に驚かれるかもしれません。
私はオープンソースの産業用ソフトウェアを諦めることにしました - OGG 1.0 がリリースされ、Huawei がすべてのソース コードを提供しました。Google Python Foundation チームは「コード クソ マウンテン」によって解雇されました 。 Fedora Linux 40が正式リリース。有名ゲーム会社がリリース 新規定:従業員の結婚祝儀は10万元を超えてはならない。チャイナユニコム、世界初のオープンソースモデルLlama3 8B中国語版をリリース。Pinduoduoに賠償判決国内のクラウド入力方式に500万元の罰金- クラウドデータアップロードのセキュリティ問題がないのはファーウェイだけこの記事はYunyunzhongsheng ( https://yylives.cc/ ) で最初に公開されたもので、どなたでもご覧いただけます。