
デジタル時代において、データは企業にとって最も貴重な資産の 1 つです。ただし、データ量が増加するにつれて、データベース管理も複雑になります。データベースの障害はビジネスの混乱を引き起こし、会社に多大な経済的および評判の損失を引き起こす可能性があります。このブログでは、KaiwuDB が障害診断ツールを設計する方法と具体的なデモ例を紹介します。
01 デザインアイデア
基本原則に従う
- ユーザーフレンドリー: さまざまなスキルレベルを持つユーザーでも、当社のツールを簡単に使用できます。
- 包括的な監視: パフォーマンス指標、システム リソース、クエリ効率など、データベース システムのあらゆる側面を包括的に監視します。
- インテリジェントな診断: 高度なアルゴリズムを利用して問題の根本原因を特定します。
- 自動修復: ワンクリックで修復の提案が提供され、可能な場合はこれらの修復が自動的に適用されます。
- 拡張性: ユーザーがツールの機能を特定のニーズに合わせて拡張およびカスタマイズできるようにします。
主要指標の収集をサポート
包括的な診断を確実にするために、このツールは以下を含む一連の重要な指標を収集しますが、これらに限定されません。
- システム構成: データベースのバージョン、オペレーティング システム、CPU アーキテクチャと数、メモリ容量、ディスクの種類と容量、マウント ポイント、ファイル システムの種類。
- 導入状況: ベアメタル導入かコンテナ導入か、データベースインスタンスの導入モードとノード数、データ構成: データディレクトリの構造、ローカルおよびクラスタ構成、システムテーブルとパラメータ。
- データベース統計: ビジネス データベースの数、各データベース内のテーブルの数、およびテーブル構造。
- 列の特性: 数値列と列挙型列の統計的特性、文字列列の長さと特殊文字の検出。
- ログ ファイル: 関係ログ、タイミング ログ、エラー ログ、監査ログ。
- PID 情報: データベース プロセスによってオープンされたハンドルの数、オープンされた MMAP の数、統計およびその他の情報。
- パフォーマンス データ: SQL 実行計画、システム監視データ (CPU、メモリ、I/O)、インデックスの使用量と効率、データ アクセス パターン、ロック (トランザクションの競合と待機イベント)、システム イベントなど。
さまざまな動作モードをサポート
このツールは、さまざまなシナリオのニーズを満たすために 2 つの動作モードを提供します。
- ワンタイム収集: 現在のシステムステータスとパフォーマンスデータを迅速に取得し、問題の即時診断に適しています。
- スケジュールされた収集: 長期的なパフォーマンスの監視と傾向分析のために、事前に設定された計画に従ってデータを定期的に収集します。
さまざまなトレンド分析に対応
収集されたデータは、次のような機能を備えた傾向分析を実行するために使用されます。
- パフォーマンスの傾向: データベースのパフォーマンスの長期的な傾向を特定し、潜在的なパフォーマンスのボトルネックを予測します。
- リソース使用量: システム リソースの使用量を追跡し、リソース割り当ての最適化に役立ちます。
- ログ分析: ログ ファイルを分析して、異常なパターンと頻繁なエラーを特定します。
- クエリの最適化: SQL 実行プランを分析することにより、クエリの最適化に関する提案を提供します。
- ベスト プラクティス: データ分散とハードウェア リソースの包括的な分析を通じて、最適な構成の推奨事項を提供します。
02 全体アーキテクチャ
障害診断ツールは、収集と分析の 2 つの部分に分かれています。
- 収集部分はターゲットのオペレーティング システム/データベース/監視サーバーに接続され、ローカル ルールの簡略化された分析をサポートし、プレーン テキストのレポートを出力します。
- 分析部分は、収集されたデータを読み取ってフォーマットし、永続化するために分析サーバーにアップロードします。オンライン ルールの詳細な分析と予測をサポートし、UI を通じて詳細なレポートを出力します。
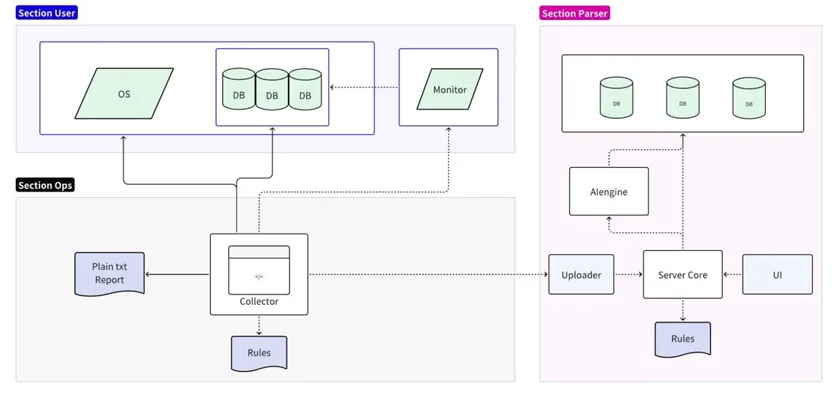
コレクターの実装
コレクターは、運用保守担当者が現場で直接使用するツールで、オペレーティング システム、データベース、監視サービスを通じて現場のさまざまな独自情報を取得します。デフォルトでは、収集後の圧縮と直接エクスポートがサポートされています。ローカル ルールを使用して、すべてのエラー メッセージを検索して出力するなど、最も基本的な分析を行うこともできます。

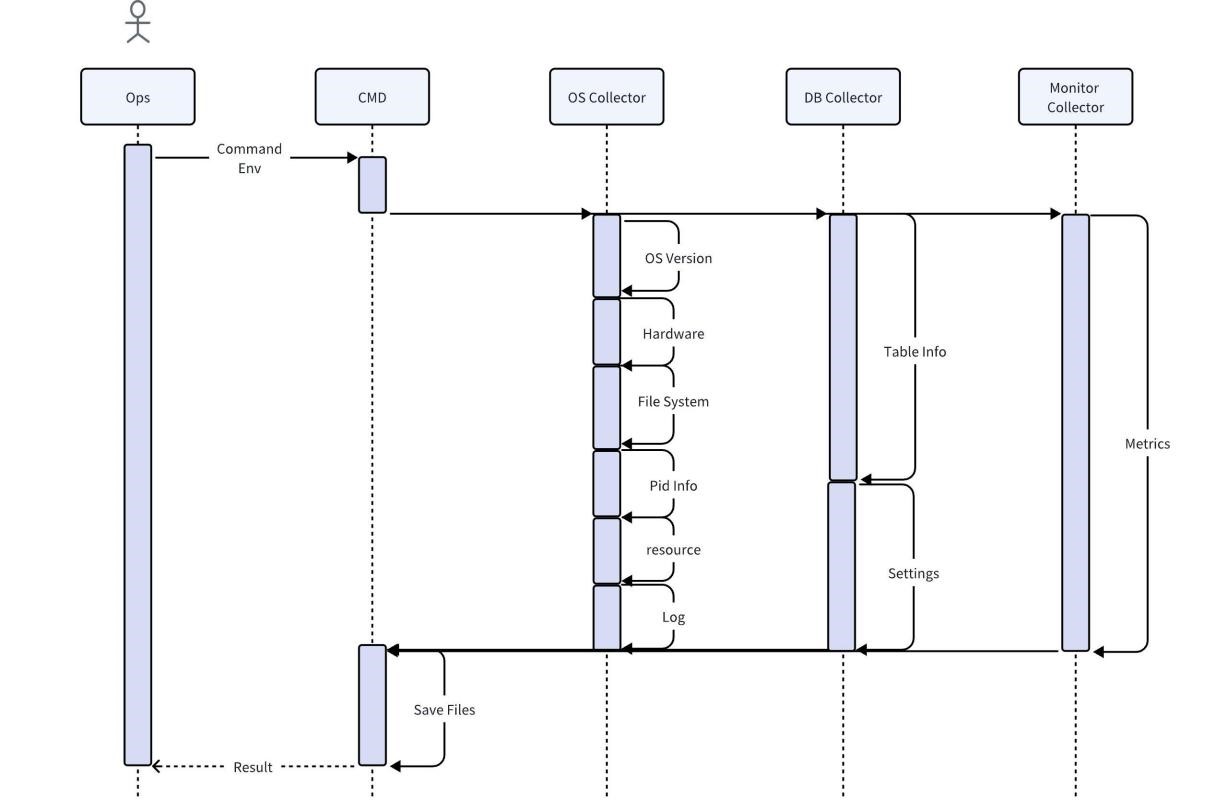
ユーザーのビジネスデータを直接収集するとユーザー情報が漏洩するリスクにつながる可能性があることを考慮し、データベースコレクターの収集プロセスではユーザーのデータ特性のみがキャプチャされ、データはコピーされません。その他のデータの完全性と正確性を確保するため、収集されたデータは分析前にいかなる処理も行われず、完全な情報を提供するために必要なデータが維持されます。スペースを節約するには、収集したデータを圧縮する必要があります。同時に、コレクターはほとんどのオペレーティング システムと互換性があり、追加の依存関係を必要としない必要があります。
ルールエンジンの実装
その後のデータ分析のために、ルール エンジンはデータ コレクターと互換性があり、標準化されたデータ出力を提供し、一定のスケーラビリティを備えている必要があります。例えば、特定のSQLを実行した際のCPU使用率の増加を分析するには、SQLクエリのメタデータ(SQLテキストや実行時間など)や性能指標(CPU使用率など)を出力する必要があります。パフォーマンスのボトルネックを分析するためのタイミング エンジンのフォーマット。
十分なスケーラビリティを提供し、エラー コード チェックなどの機能上の問題を含む、拡大し続けるルール セットに対応できるようにするために、ルール エンジンは外部ファイルからルールを読み取り、これらのルールを適用してデータを分析します。以下にいくつかのコード例を示します。
Python
import pandas as pd
import json
# 加载规则
def load\_rules(rule\_file):
with open(rule_file, 'r') as file:
return json.load(file)
# 自定义规则函数,这个函数将检查特定SQL执行时CPU使用率是否有显著增加
def sql\_cpu\_bottleneck(row, threshold):
# 比较当前行的CPU使用率是否超过阈值
return row\['sql\_query'\] == 'SELECT * FROM table\_name' and row\['cpu_usage'\] > threshold
# 应用规则
def apply\_rules(data, rules\_config, custom_rules):
for rule in rules_config:
data\[rule\['name'\]\] = data.eval(rule\['expression'\])
for rule\_name, custom\_rule in custom_rules.items():
data\[rule\_name\] = data.apply(custom\_rule, axis=1)
return data
# 读取CSV数据
df = pd.read\_csv('sql\_performance_data.csv')
# 加载规则
rules\_config = load\_rules('rules.json')
# 定义自定义规则
custom_rules = {
'sql\_cpu\_bottleneck': lambda row: sql\_cpu\_bottleneck(row, threshold=80)
}
# 应用规则并得到结果
df = apply\_rules(df, rules\_config, custom_rules)
# 输出带有规则检查结果的数据
df.to\_csv('evaluated\_sql_performance.csv', index=False)
ルール ファイルはバージョンの反復とともに継続的に拡張し、ホット アップデートをサポートする必要があります。以下は、JSON 形式のルール設定ファイルの例です。ルールは JSON オブジェクトとして定義され、それぞれには Pandas DataFrame によって理解される名前と式が含まれます。
JSON
\[
{
"name": "high\_execution\_time",
"expression": "execution_time > 5"
},
{
"name": "general\_high\_cpu_usage",
"expression": "cpu_usage > 80"
},
{
"name": "slow_query",
"expression": "query_time > 5"
},
{
"name": "error\_code\_check",
"expression": "error_code not in \[0, 200, 404\]"
}
// 其他规则可以在此添加
\]
予測が現実化
診断ツールを予測エンジンに接続して、潜在的なリスクを事前に検出できます。次の例では、scikit-learn デシジョン ツリー分類子を使用してモデルをトレーニングし、そのモデルを使用して予測を行います。
Python
from sklearn.tree import DecisionTreeClassifier
from sklearn.model\_selection import train\_test_split
from sklearn.metrics import accuracy_score
# 读取CSV数据
df = pd.read\_csv('performance\_data.csv')
# 假设我们已经有了一个标记了性能问题的列 'performance_issue'
# 这个列可以通过规则引擎或历史数据分析得到
# 特征和标签
X = df\[\['cpu\_usage', 'disk\_io', 'query_time'\]\]
y = df\['performance_issue'\]
# 分割数据集为训练集和测试集
X\_train, X\_test, y\_train, y\_test = train\_test\_split(X, y, test\_size=0.2, random\_state=42)
# 创建决策树模型
model = DecisionTreeClassifier()
# 训练模型
model.fit(X\_train, y\_train)
# 预测测试集
y\_pred = model.predict(X\_test)
# 打印准确率
print(f'Accuracy: {accuracy\_score(y\_test, y_pred)}')
# 保存模型,以便以后使用
import joblib
joblib.dump(model, 'performance\_predictor\_model.joblib')
# 若要使用模型进行实时预测
def predict\_performance(cpu\_usage, disk\_io, query\_time):
model = joblib.load('performance\_predictor\_model.joblib')
prediction = model.predict(\[\[cpu\_usage, disk\_io, query_time\]\])
return 'Issue' if prediction\[0\] == 1 else 'No issue'
# 示例:使用模型预测一个新的数据点
print(predict_performance(85, 90, 3))
03 サンプルデモンストレーション
仮説シナリオ: あなたはモノのインターネット企業の IT 専門家で、デバイスのステータス データを処理するための時系列データベースのクエリ応答時間が特定の期間で非常に遅いことに気づきました。これにどのように対処できますか?
データ収集
使用するデータベース診断ツールは、次のデータの収集を開始します。
1. クエリ ログ: 頻繁に表示され、実行時間が他のクエリに比べて非常に長いクエリが見つかりました。
Plaintext
SELECT avg(temperature) FROM device_readings
WHERE device_id = ? AND time > now() - interval '1 hour'
GROUP BY time_bucket('5 minutes', time);Plaintext
2. 実行計画: このクエリの実行計画は、この SQL がテーブル全体をスキャンしてから device_id をフィルタリングすることを示しています。
3. インデックスの使用: device_readings テーブルの device_id には TAG インデックスがありません。
4. リソース使用量: このクエリの実行時に CPU と I/O がピークになります。
5. ロックおよび待機イベント: 異常なロック イベントは見つかりませんでした。
分析とパターン認識
診断ツールはクエリと実行プランを分析して、次のパターンを特定します。
- 頻繁にフルテーブルスキャンを行うと、I/O と CPU の負荷が増加します。
- 適切なインデックスがないと、クエリはデータを効率的に見つけることができません。
問題の診断
このツールは、次の診断に一致する組み込みルールを使用します。 クエリの非効率性は、適切なインデックスの欠如によって引き起こされます。
提案の生成
このパターンに基づいて、診断ツールは次の推奨事項を生成します。 device_readings テーブルの device_id フィールドに TAG インデックスを作成します。
推奨事項の実装
データベース管理者は次の SQL ステートメントを実行してインデックスを作成します。
SQL
ALTER TABLE device\_readings ADD TAG device\_id;
検証結果
インデックスの作成後、データベース診断ツールはデータを再度収集し、次のことを発見しました。
- この特定のクエリの実行時間は大幅に短縮されました。
- クエリの実行中は、CPU と I/O の負荷が通常のレベルに低下します。
- ウェブサイトの製品カタログページの読み込み時間が通常に戻りました。
アルゴリズムの説明
この例では、診断ツールは次のアルゴリズムとロジックを使用します。
- パターン認識: クエリの頻度と実行時間を検出します。
- 相関分析: 実行時間の長いクエリと実行計画およびインデックスの使用状況を関連付けます。
- デシジョン ツリーまたはルール エンジン: フル テーブル スキャンが見つかり、対応するフィールドにインデックスがない場合は、インデックスを作成することをお勧めします。
- パフォーマンスの変化の監視: インデックスの作成後、パフォーマンスの向上を監視して、推奨事項の有効性を判断します。