
皆さんも GitHub でスターを付けてください:
分散型フルリンク因果学習システム OpenASCE: https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
大規模なモデル駆動型ナレッジ グラフ OpenSPG: https://github.com/OpenSPG/openspg
大規模グラフ学習システム OpenAGL: https://github.com/TuGraph-family/TuGraph-AntGraphLearning
5 年も経たないうちに、大型モデルと Transformers テクノロジーは自然言語処理の分野をほぼ完全に変え、コンピューター ビジョンや計算生物学などの分野に革命を起こし始めました。 Sebastian Raschka 博士は学術研究論文に焦点を当てており、機械学習の研究者や実践者向けに入門用の読書リストを作成しました。これを順番に読んでいくと、現在の大規模モデル テクノロジの分野を本格的に始めることができます。
もちろん、Sebastian Raschka 博士は、他にも次のような役立つリソースがたくさんあるとも述べました。
- ジェイ・アランマーの《イラストレイテッド・トランスフォーマー》;
- Lilian Weng によるその他の技術的なブログ投稿。
- トランスフォーマーのすべてのカタログと系譜はザビエル・アマトリアンによって整理されました。
- Andrej Karpathy によって教育目的で書かれた生成言語モデルの最小限のコード実装。
- この記事の著者による講義シリーズと書籍の章。
主なアーキテクチャとタスクを理解する
トランスフォーマーや大型モデルを初めて使用する場合は、最初から始めるのが最も合理的です。
1. 位置合わせと翻訳の共同学習によるニューラル機械翻訳 (2014)
作者:Bahdanau、Cho和Bengio
論文リンク: https://arxiv.org/abs/1409.0473
数分の余裕がある場合は、この文書から始めることをお勧めします。この論文では、長いシーケンスのモデリング機能を強化するためにリカレント ニューラル ネットワーク (RNN) にアテンション メカニズムを導入します。これにより、RNN は長い文をより正確に翻訳できるようになります。これが、元の Transformer アーキテクチャの開発の背後にある動機でした。
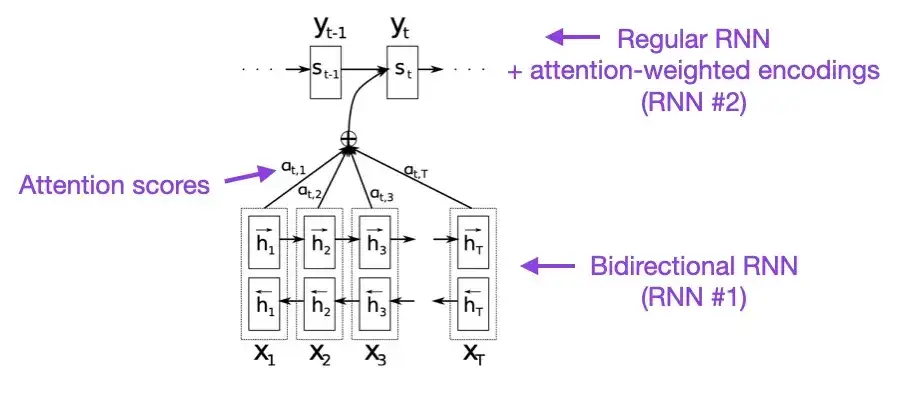
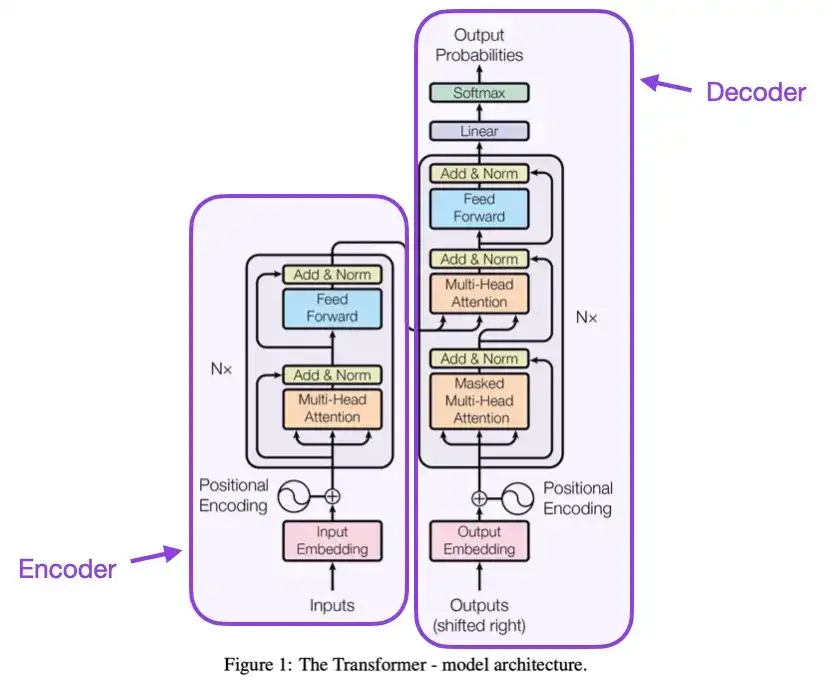
2. アテンション・イズ・オール・ユー・ニード (2017)
クレジット: Vaswani、Shazeer、Parmar、Uszkoreit、Jones、Gomez、Kaiser、Polosukhin
論文リンク: https://arxiv.org/abs/1706.03762
この文書では、エンコーダとデコーダの 2 つの部分で構成されるオリジナルの Transformer アーキテクチャを紹介します。これらの 2 つの部分は、後で説明するために独立したモジュールになります。さらに、この論文では、スケーリング ドット積アテンション メカニズム、マルチヘッド アテンション ブロック、位置入力エンコーディングなどの概念も紹介しました。これらは依然として最新の Transformer モデルの基礎となっています。
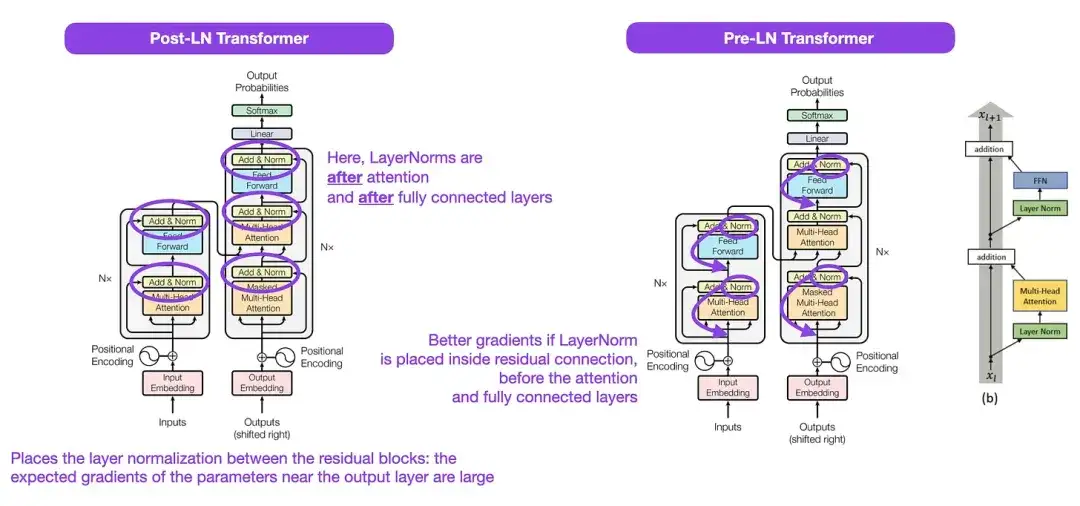
3. トランスフォーマーアーキテクチャにおけるレイヤー正規化について__ (2020)
著者: Yang、He、K Zheng、S Zheng、Xing、Zhang、Lan、Wang、Liu
論文リンク: https://arxiv.org/abs/2002.04745
上の図に示されている元の Transformer 構造は、元のエンコーダ/デコーダ アーキテクチャの非常に優れた要約ですが、図内の LayerNorm の位置については議論の余地があります。たとえば、「Attendance Is All You Need」の Transformer 構造図では、残差ブロックの間に LayerNorm が配置されていますが、これは、元の Transformer 論文に付属する公式 (更新された) コード実装と矛盾しています。 「注意だけで十分です」の図に示されているバリアントは Post-LN Transformer と呼ばれており、更新されたコード実装ではデフォルトで Pre-LN バリアントが使用されます。
「Transformer Architecture における Layer Normalization」の記事では、Pre-LN の方がより効果的に機能し、勾配の問題を解決できることが指摘されています。以下に示すように、実際には多くのアーキテクチャがこのアプローチを採用していますが、表現の崩壊につながる可能性があります。したがって、Post-LN を使用するか Pre-LN を使用するかについての議論は続いていますが、新しい論文「ResiDual: Transformer with Dual Residual Connections」( https://arxiv.org/abs/2304.14802 ) では、両方の利点を活用することを提案しています。実際のその有効性はまだ分からない。
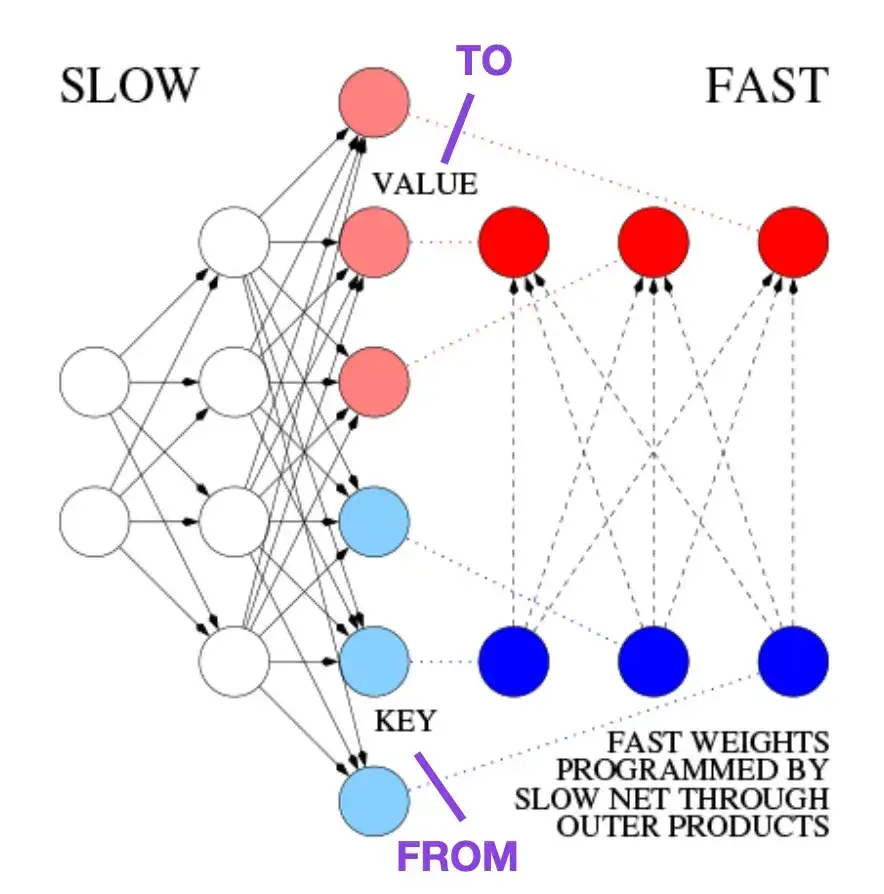
4. 高速重み付け記憶の制御方法の学習: 動的リカレント ニューラル ネットワークの代替案__ (1991)
著者: シュミットフーバー
論文リンク:
この文書は、歴史的な逸話や、現代の Transformer アーキテクチャに似た初期のテクノロジーに興味のある読者にお勧めします。たとえば、Transformer のオリジナルの論文「Attending Is All You Need」が発表される約 25 年前の 1991 年に、Juergen Schmidhuber はリカレント ニューラル ネットワークの代替として Fast Weight Programmer (FWP) を提案しました。 FWP メソッドには、別のニューラル ネットワークの急速な重み変更をプログラムするために勾配降下法を介してゆっくりと学習するフィードフォワード ニューラル ネットワークが含まれます。最新の Transformer との類似点については、次のブログ投稿で説明されています。
現在の Transformer 用語では、FROM と TO はそれぞれキーと値と呼ばれます。高速ネットワークで使用される INPUT はクエリと呼ばれます。基本的に、クエリは、キーと値の外積の合計である高速重み行列を通じて処理されます (正規化と射影は無視します)。両方のネットワークのすべての操作が微分可能であるため、外積または 2 次テンソル積の追加を通じて、高速な重み変更のエンドツーエンドの微分可能なアクティブ制御が得られます。したがって、低速ネットワークは勾配降下法によって学習でき、シーケンス処理中に高速ネットワークを迅速に変更できます。これは、線形セルフアテンション トランスフォーマー (または線形トランスフォーマー) として知られるようになったものと数学的に同等です (正規化を除く)。
上記のブログ投稿の抜粋で述べたように、このアプローチは現在、「線形トランスフォーマー」または「線形化されたセルフアテンションを備えたトランスフォーマー」として知られています。その後、線形化された自己注意と 1990 年代の高速ウェイト プログラマーとの同等性が、2021 年の論文「Linear Transformers Are Secretly Fast Weight Programmers」で明確に実証されました。
5. テキスト分類のためのユニバーサル言語モデルの微調整(2018)
著者、ハワード、ルーダー
論文アドレス: https://arxiv.org/abs/1801.06146
これは歴史的な観点から見て非常に興味深い記事です。これは「Attending Is All You Need」のリリースから 1 年後に書かれましたが、Transformer には関与しておらず、リカレント ニューラル ネットワークに焦点を当てていました。ただし、下流タスク用の事前トレーニング済み言語モデルと転移学習を効果的に提案しているため、依然として注目に値します。転移学習はコンピューター ビジョンの分野では十分に確立されていますが、自然言語処理 (NLP) ではまだ普及していません。 ULMFit は、事前トレーニングされた言語モデルと特定のタスクに合わせて微調整することを実証した最初の論文の 1 つであり、その結果、多くの NLP タスクで最先端の結果が得られます。
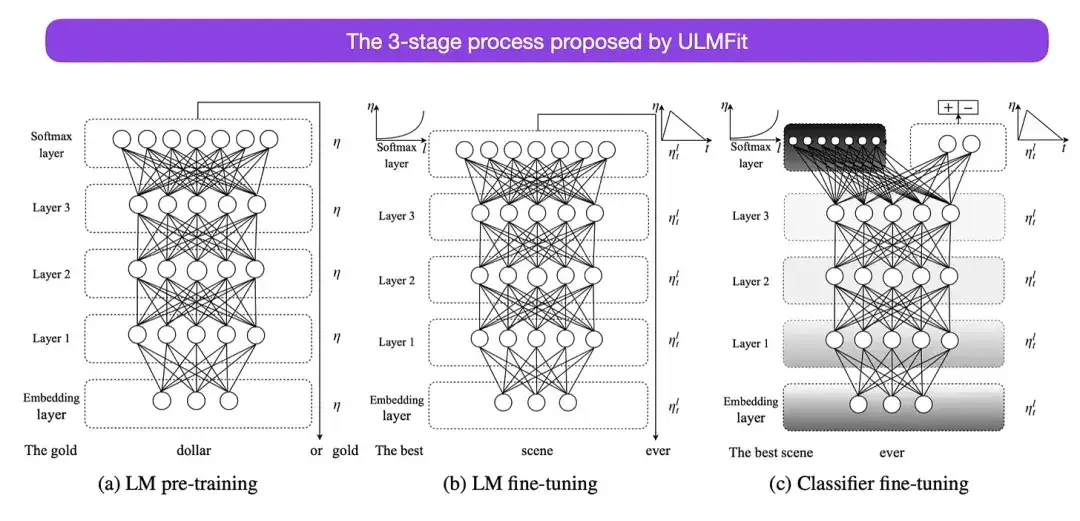
ULMFit が提案する言語モデルを微調整する 3 段階のプロセスは次のとおりです。
- 大規模なテキスト コーパスで言語モデルをトレーニングします。
- この事前トレーニング済み言語モデルをタスク固有のデータに基づいて微調整して、特定のテキストのスタイルと語彙に適応させます。
- タスク固有のデータに基づいて分類器を微調整しながら、レイヤーのフリーズを徐々に解除することで、壊滅的な忘却を回避します。
この方法 - 最初に大規模なコーパスで言語モデルをトレーニングし、次にそれを下流のタスクに合わせて微調整する - は、Transformer ベースのモデルおよび基本モデル (BERT、GPT-2/3/4、RoBERTa、等。)。ただし、ULMFit の重要な部分である段階的なフリーズ解除は、コンバータ アーキテクチャを実際に動作させるときに通常は日常的に実行されるわけではなく、通常はすべてのレイヤーが一度に微調整されます。
6. BERT: 言語理解のための深い双方向トランスフォーマーの事前トレーニング****(2018)
著者:デブリン、チャン、リー、トウタノバ
論文リンク: https://arxiv.org/abs/1810.04805
オリジナルの Transformer アーキテクチャによれば、大規模言語モデルの研究は 2 つの方向に分岐し始めました。1 つは予測モデリング タスク (テキスト分類など) のためのエンコーダベースの Transformer、もう 1 つは生成モデリング タスク (翻訳、要約、デコーダなど) です。他のテキスト作成フォーム用のスタイル トランスフォーマー)。
前述の BERT 論文は、マスクされた言語モデリングと次の文予測の独自の概念を導入しており、今でも最も影響力のあるエンコーダー スタイルのアーキテクチャです。この分野の研究に興味がある場合は、RoBERTa について学習し続けることをお勧めします。RoBERTa は、次の文の予測タスクを削除することで、トレーニング前の目標を簡素化します。
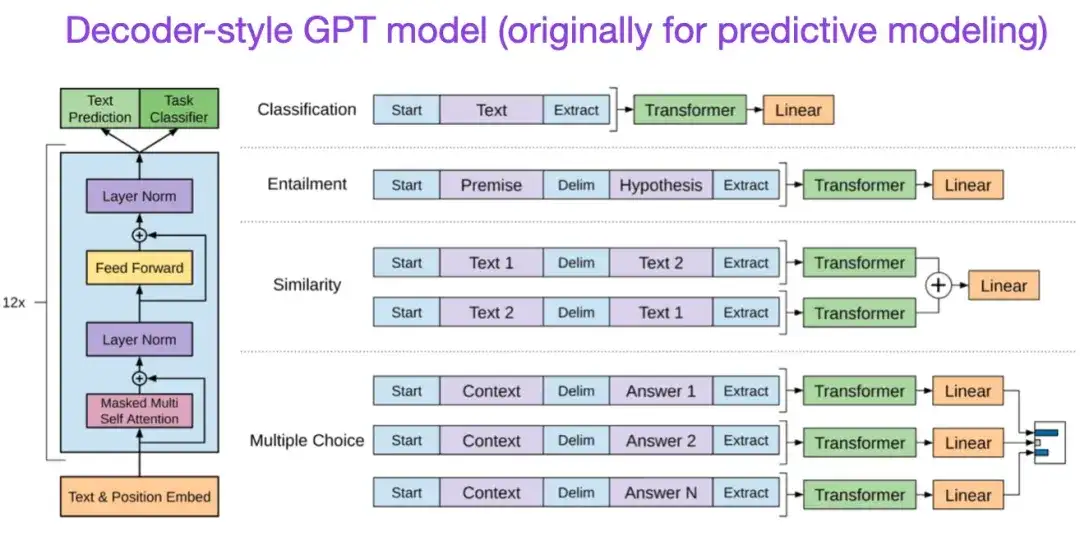
** 7. 生成的事前トレーニングによる言語理解の改善(2018)** 著者: Radford および Narasimhan 論文アドレス:
元の GPT 論文では、一般的なデコーダー スタイルのアーキテクチャと、次の単語予測による事前トレーニングが導入されました。 BERT はマスクされた言語モデルの事前トレーニング目的により双方向トランスフォーマーとみなすことができますが、GPT は一方向の自己回帰モデルです。 GPT 埋め込みは分類にも使用できますが、GPT メソッドは、ChatGPT など、今日最も影響力のある大規模言語モデル (LLM) の中核となっています。
この研究の方向性に興味がある場合は、引き続き GPT-2 および GPT-3 関連の論文についてさらに学習することをお勧めします。これら 2 つの論文は、LLM がゼロショット学習と少数ショット学習を達成できることを実証し、LLM の新たな機能を強調しています。 GPT-3 は、現在の LLM をトレーニングするために依然として最も一般的に使用されているベースラインおよび基本モデルです。ChatGPT を生み出した InstructGPT テクノロジについては、後ほど別のエントリで紹介します。
GPT3 関連の論文: https://arxiv.org/abs/2005.14165
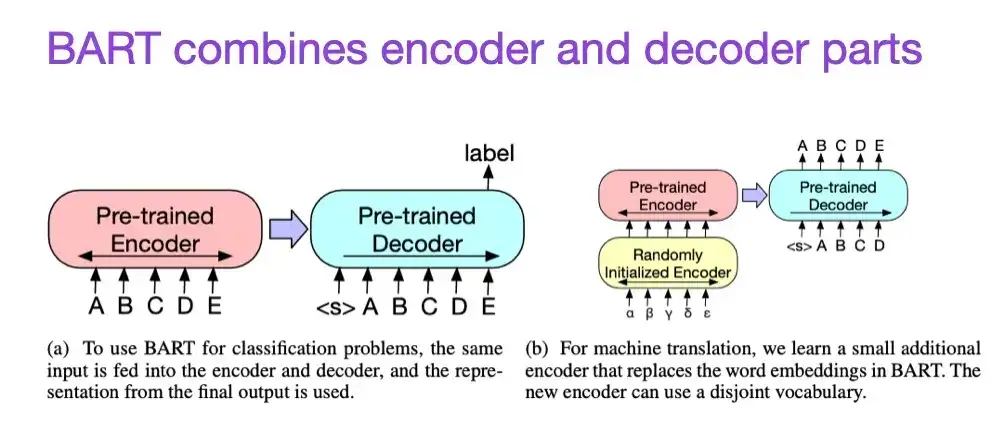
8. BART: 自然言語の生成、翻訳、理解のためのノイズ除去シーケンス間の事前トレーニング(2019)
著者:ルイス、リュー、ゴヤル、ガズヴィニネジャド、モハメド、レヴィ、ストヤノフ、ゼトルモイヤー
論文リンク: https://arxiv.org/abs/1910.13461。
前述したように、BERT タイプのエンコーダー スタイルの大規模言語モデル (LLM) は一般に、予測モデリング タスクに適していますが、GPT タイプのデコーダー スタイルの LLM はテキストの生成に適しています。両方の長所を組み合わせるために、上記の BART 論文では、エンコーダ部分とデコーダ部分が結合されています (これは、2 番目の論文で紹介されたオリジナルの Transformer 構造に似ています)。
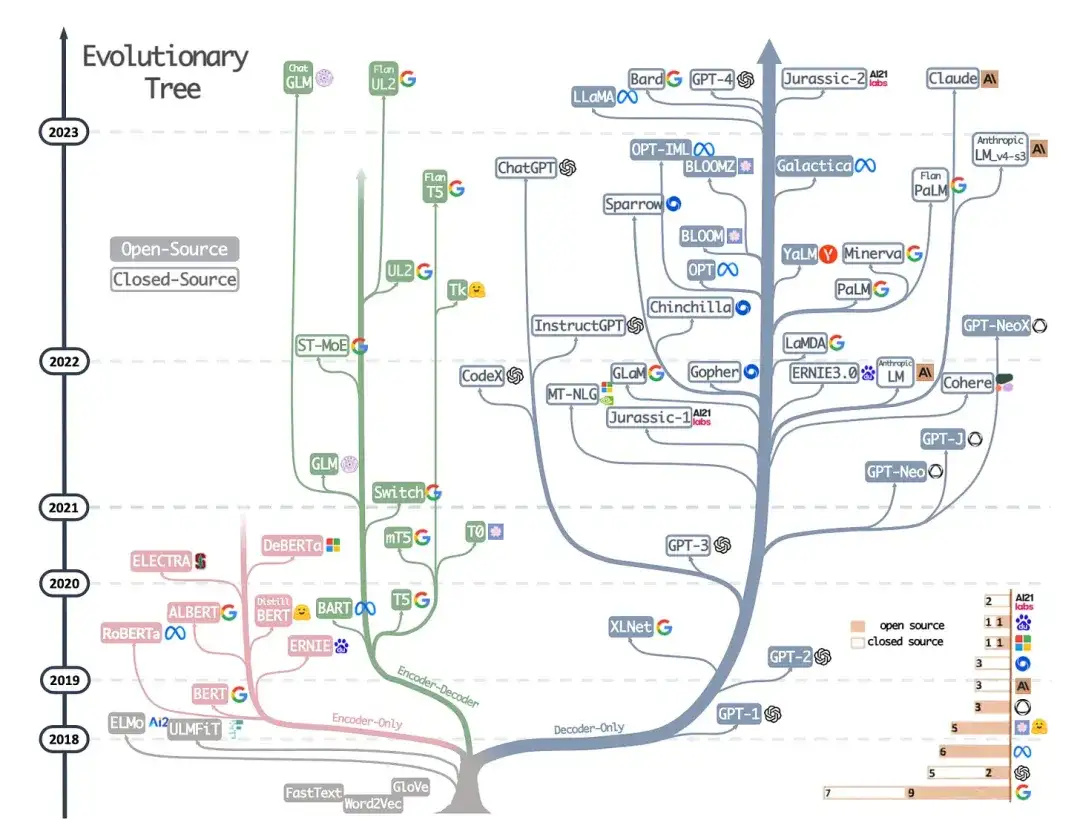
9. LLM の力を実際に活用する: ChatGPT 以降に関する調査(2023)
著者: ヤン、ジン、タン、ハン、フォン、ジャン、イン、胡、
論文リンク: https://arxiv.org/abs/2304.13712
これは研究論文ではありませんが、おそらくこれまでで最高のアーキテクチャ概要記事であり、さまざまなアーキテクチャがどのように進化してきたかを生き生きと示しています。ただし、BERT スタイルのマスク言語モデル (エンコーダー) と GPT スタイルの自己回帰言語モデル (デコーダー) について説明することに加えて、事前トレーニングとデータの微調整に関する役立つ説明とガイダンスも提供します。
法律の拡張と効率の向上
変圧器の効率を向上させるためのさまざまな手法について詳しく知りたい場合は、2020 年の論文「効率的な変圧器: 調査」と 2023 年の論文「変圧器の効率的なトレーニングに関する調査」を読むことをお勧めします。さらに、私が特に興味深く読む価値があると感じた論文をいくつか紹介します。
- 《効率的な変圧器: 調査》:
https://arxiv.org/abs/2009.06732
- 《変圧器の効率的な訓練に関する調査》:
https://arxiv.org/abs/2302.01107
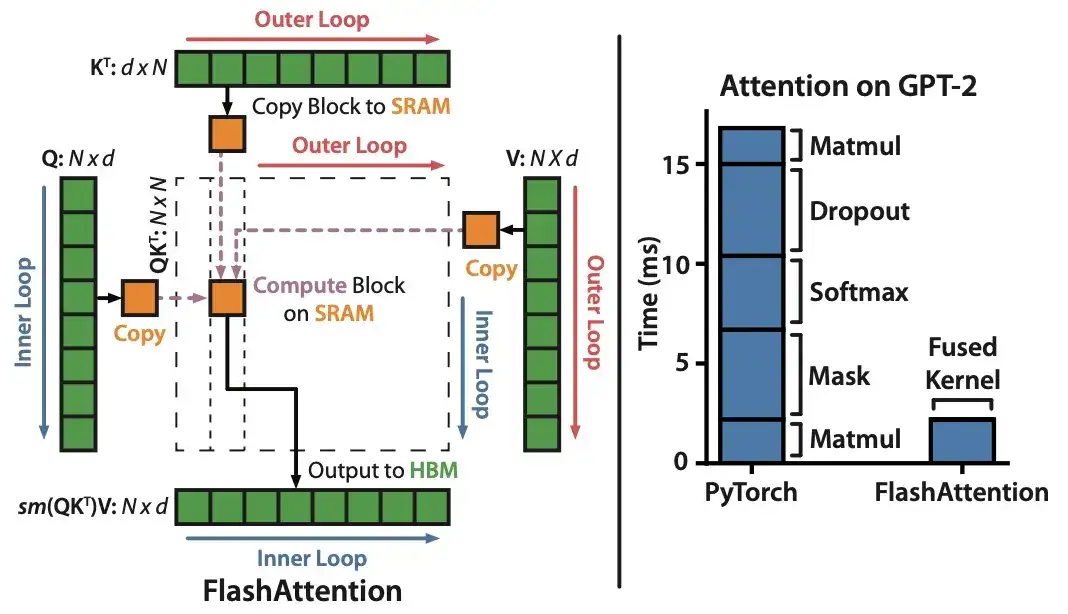
10. FlashAttendant: IO 認識を備えた高速でメモリ効率の高い Exact Attendance (2022)
著者: ダオ、フー、エルモン、ルドラ、レ
論文リンク: https://arxiv.org/abs/2205.14135。
ほとんどの Transformer 論文では、セルフ アテンションを実現するために元のスケーリングされたドット積メカニズムをわざわざ置き換えることはありませんが、私が最近引用したメカニズムの 1 つは FlashAttend です。
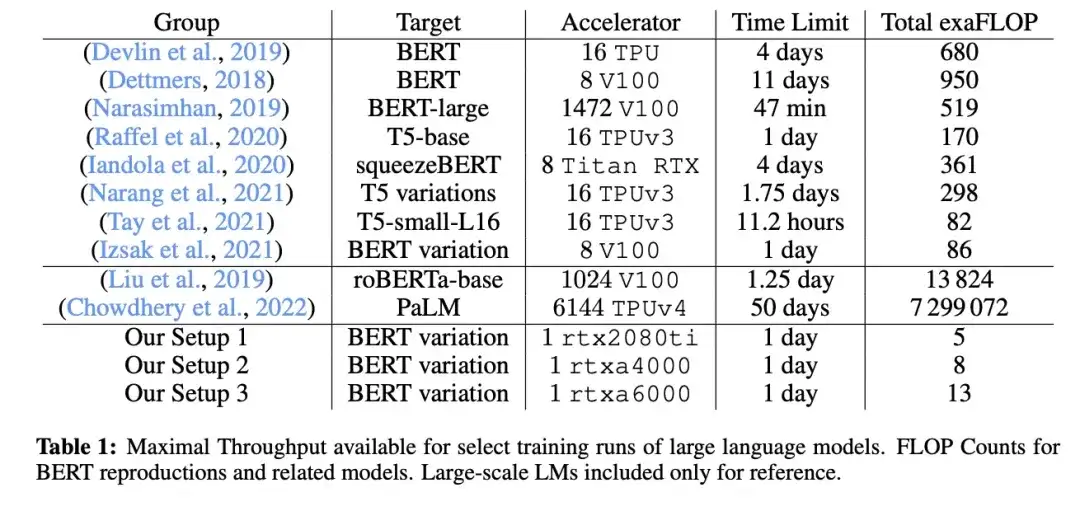
11. クラミング: 1 日で単一 GPU で言語モデルをトレーニング (2022)
_著者:_ガイピンとゴールドスタイン、
論文リンク: https://arxiv.org/abs/2212.14034
この論文では、研究者は単一の GPU を使用して、マスクされた言語モデル/エンコーダー スタイルの大規模言語モデル (ここでは BERT) を 24 時間トレーニングしました。比較のために、2018 年の元の BERT 論文は 16 個の TPU で 4 日間トレーニングされました。興味深い発見は、小さいモデルはスループットが高いものの、学習効率も低いということです。したがって、大規模なモデルでは、特定の予測パフォーマンスしきい値に到達するために、より長いトレーニング時間を必要としません。
12. LoRA: 大規模言語モデルの低ランク適応 (2021)
著者: Hu、Shen、Wallis、Allen-Zhu、Li、L Wang、S Wang、Chen 著
論文リンク: https://arxiv.org/abs/2106.09685。
最新の大規模言語モデルは、大規模なデータセットでの事前トレーニングを通じて新たな機能を発揮し、言語翻訳、要約生成、プログラミング、質問応答などのさまざまなタスクで良好に実行します。ただし、トランスフォーマーを微調整して、ドメイン固有のデータや特殊なタスクの機能を向上させることには価値があります。低ランク適応 (LoRA) は、大規模な言語モデルをパラメーター効率よく微調整するための最も影響力のある方法の 1 つです。
パラメータを効率的に微調整するための他の方法も存在しますが、LoRA は洗練されており、非常に汎用的であり、他のタイプのモデルにも適用できるため、特に注目に値します。事前トレーニングされたモデルの重みは、事前トレーニングされたタスクでのフルランクを持ちますが、LoRA の著者らは、大規模な言語モデルが新しいタスクに適応されると「固有の次元」が低くなることを指摘しています。したがって、LoRA の中心となるアイデアは、重みの変化 ΔW を低ランクの表現に分解して、より高いパラメーター効率を達成することです。

13_。スケールダウンからスケールアップへ: パラメーター効率の良い微調整ガイド (2022)_
著者: リアリン、デシュパンデ、ラムシスキー
論文リンク: https://arxiv.org/abs/2303.15647。
このレビューでは、微調整プロセスの計算効率を (非常に) 高めることを目的として、効率的なパラメータ微調整方法 (プレフィックス調整、アダプター、低ランク適応などの一般的な技術をカバー) に関する 40 以上の論文をレビューします。
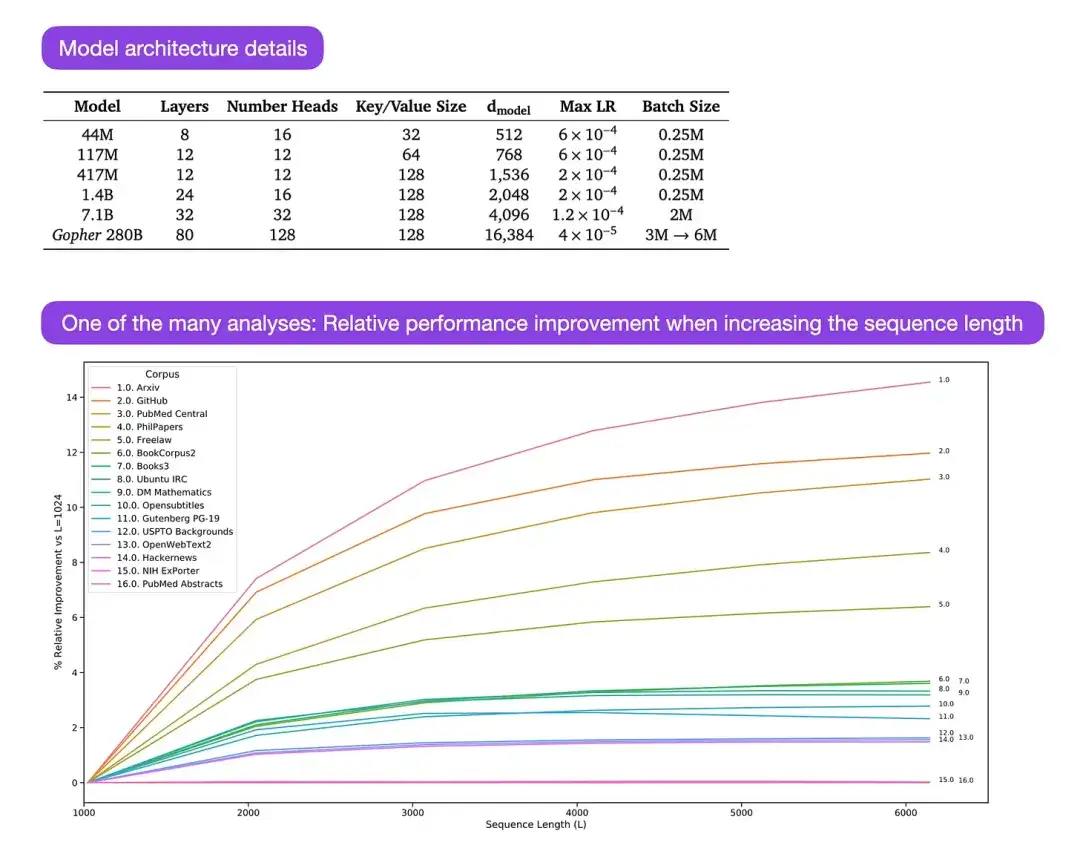
** 14. スケーリング言語モデル: トレーニング Gopher からの方法、分析、洞察(2022)** 著者: Rae と 78 人の同僚
論文リンク: https://arxiv.org/abs/2112.11446
Gopher は、大規模言語モデル (LLM) のトレーニング プロセスを理解するための多くの分析を含む、特に優れた論文です。研究者はここで 280B のパラメーターと 80 のレイヤーを使用してモデルをトレーニングしました。モデルは 300B のトークンに基づいてトレーニングされました。これには、LayerNorm (レイヤー正規化) の代わりに RMSNorm (二乗平均平方根正規化) を使用するなど、いくつかの興味深いアーキテクチャの改善が含まれています。 LayerNorm と RMSNorm はどちらも、バッチ サイズに依存せず、同期を必要としないため、BatchNorm よりも推奨されます。これは、分散設定で小規模なバッチを使用する場合に特に有利です。ただし、ディープ アーキテクチャのトレーニング プロセスを安定させるには、RMSNorm の方が効果的であると一般に考えられています。
これらの興味深い詳細は別として、この論文の主な焦点は、さまざまなスケールでのタスクのパフォーマンスの分析にあります。 152 のさまざまなタスクの評価では、モデル サイズを増やすと、理解、事実確認、有害な言語の特定などのタスクに最も大きな改善効果があることがわかりました。ただし、論理的および数学的推論に関連するタスクでは、アーキテクチャの拡張によるメリットはあまりありません。
15. コンピューティングに最適な大規模言語モデルのトレーニング(2022)
著者:ホフマン、ボルジョー、メンシュ、ブチャツカヤ、カイ、ラザフォード、デ・ラス・カサス、ヘンドリックス、ウェルブル、クラーク、ヘニガン、ノーランド、ミリカン、ファン・デン・ドリーシェ、ダモック、ガイ、オシンデロ、シモニャン、エルセン、レイ、ヴィニャルズ、和シフレ
論文リンク: https://arxiv.org/abs/2203.15556。
この記事では、生成モデリング タスクにおいて一般的な 175B パラメーターの GPT-3 モデルを上回る、Chinchilla と呼ばれる 70B パラメーター モデルを紹介します。ただし、その核心は、現在の大規模言語モデルが「大幅にトレーニングされていない」ことを指摘することです。この論文では、大規模な言語モデルのトレーニングのための線形スケーリング則を定義しています。たとえば、Chinchilla は GPT-3 の半分のサイズしかありませんが、(わずか 3,000 億ではなく) 1 兆 4,000 億のトークンでトレーニングされたため、GPT-3 を上回っています。言い換えれば、トレーニング トークンの数はモデルのサイズと同様に重要です。
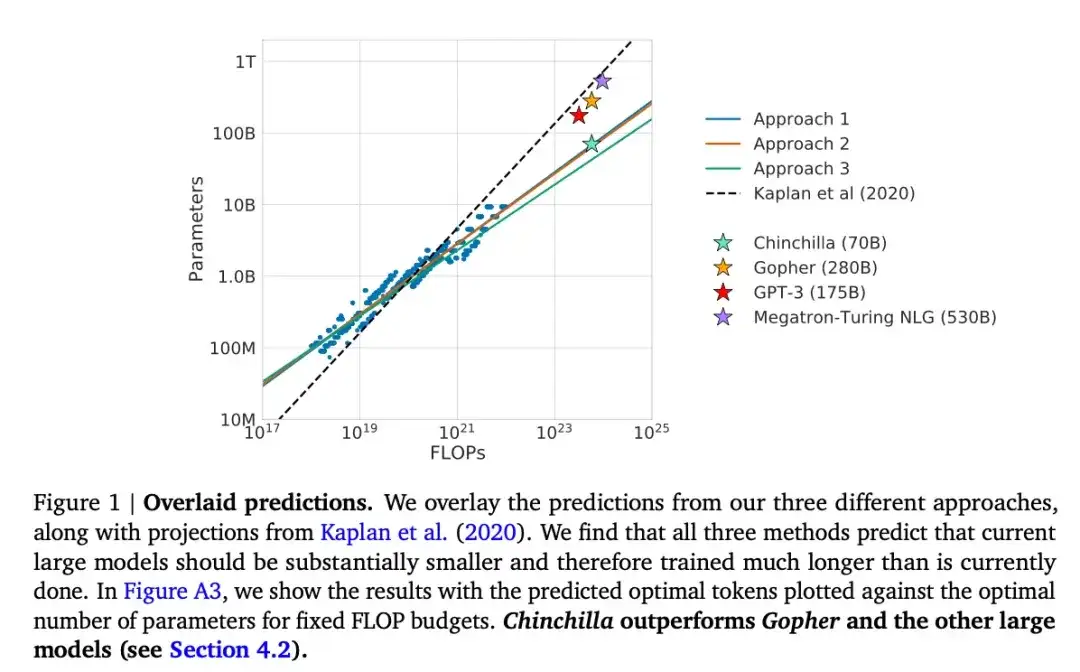
16.Pythia :トレーニングとスケーリングにわたって大規模な言語モデルを分析するためのスイート(2023)
作说:ビダーマン、シェルコップ、アンソニー、ブラッドリー、オブライエン、ハラハン、カーン、プロヒット、プラシャンス、ラフ、スコウロン、スタウィカ、和ヴァン・デル・ヴァル
論文リンク: https://arxiv.org/abs/2304.01373
Pythia は、トレーニング プロセス中に大規模言語モデルの進化を研究するために設計された一連のオープンソース大規模言語モデル (700M から 12B パラメーターの範囲) です。そのアーキテクチャは GPT-3 に似ていますが、フラッシュ アテンション (LLaMA に類似) やロータリー位置エンベディング (PaLM に類似) などのいくつかの改善が含まれています。 Pythia は Pile データ セット (825 GB) でトレーニングされ、トレーニングでは 300B トークン (通常の PILE の 1 エポック、または重複排除された PILE の 1.5 エポックにほぼ相当) が使用されます。
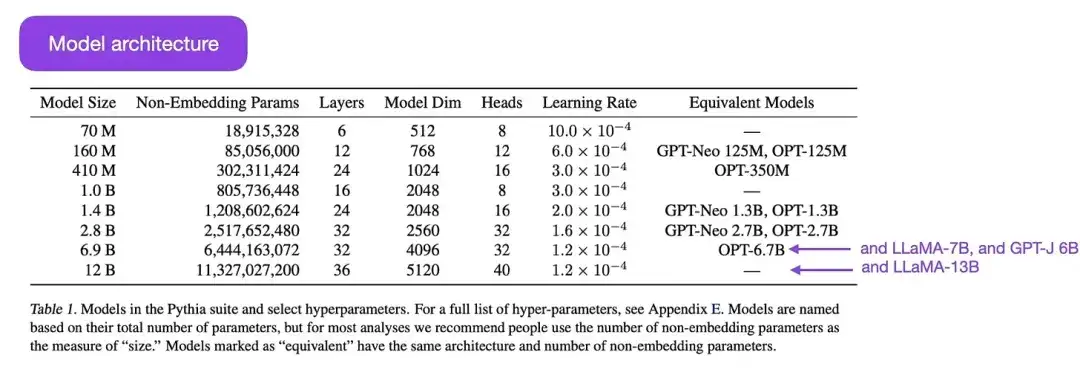
Pythia 研究の主な結果は次のとおりです。
- 繰り返されるデータでのトレーニング (大規模な言語モデルのトレーニング方法により、複数のエポックのトレーニングを意味します) は、パフォーマンスに役立ったり悪影響を及ぼしたりすることはありません。
- トレーニングの順序は記憶効果に影響しません。これは残念なことです。なぜなら、その逆が真であれば、トレーニング データの順序を変更することで、望ましくない逐語的記憶の問題を軽減できるからです。
- 事前トレーニング中の単語の頻度はタスクのパフォーマンスに影響します。たとえば、出現頻度が高い単語の場合、サンプル数が少ないほど精度が高くなる傾向があります。
- バッチ サイズを 2 倍にすると、収束に影響を与えることなくトレーニング時間を半分に短縮できます。
調整: 大規模な言語モデルを望ましい目標と関心に導く
近年、比較的強力でリアルなテキストを生成できる大規模な言語モデル (GPT-3 や Chinchilla など) が多数登場しています。一般的に使用されている事前トレーニング パラダイムの下で達成できる限界に達しているようです。
言語モデルをより有用にし、誤った情報や有害な言語の生成を減らすために、研究者たちは、事前トレーニングされた基本モデルを微調整するための追加のトレーニング パラダイムを設計しました。
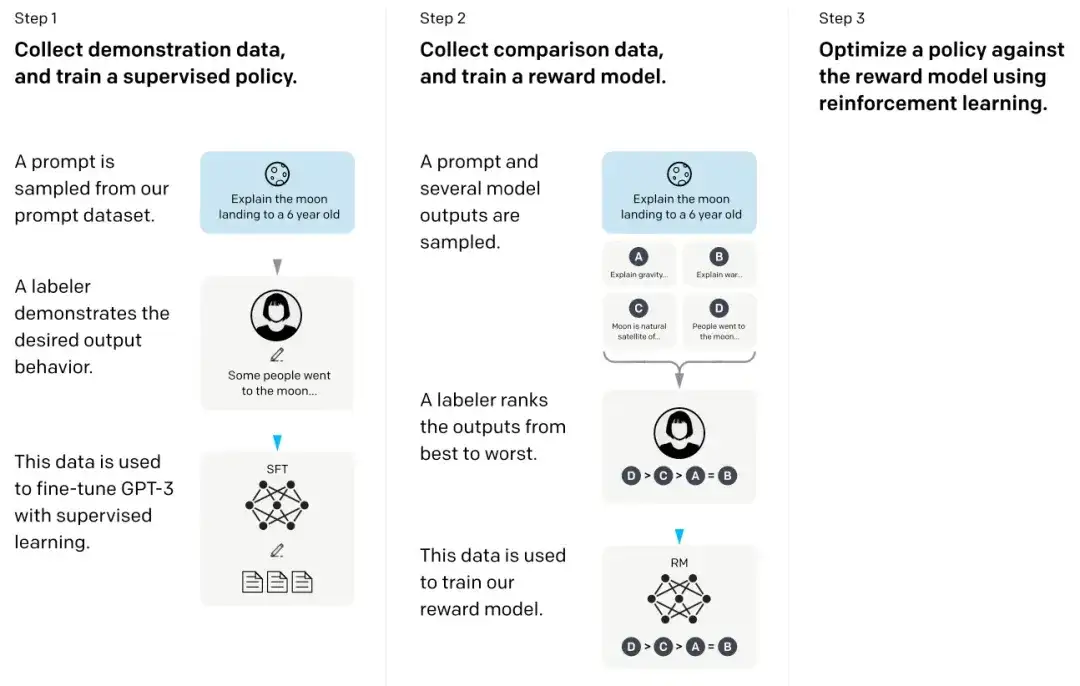
17. 人間のフィードバックによる指示に従う言語モデルのトレーニング****(2022)
著者:欧陽、呉、江、アルメイダ、ウェインライト、ミシュキン、チャン、アガルワル、スラマ、レイ、シュルマン、ヒルトン、ケルトン、ミラー、サイメンス、アスケル、ウェリンダー、クリスティアーノ、ライク、和ロウ、
論文リンク: https://arxiv.org/abs/2203.02155。
いわゆる InstructGPT 論文では、研究者らはヒューマン フィードバック (RLHF) と組み合わせた強化学習メカニズムを使用しました。彼らはまず、事前トレーニング済みの GPT-3 ベース モデルを使用し、人間が生成したキューと応答のペアに関する教師あり学習を通じてそれをさらに微調整しました (ステップ 1)。次に、人間にモデルの出力をランク付けして報酬モデルをトレーニングしました (ステップ 2)。最後に、報酬モデルを使用して、近接ポリシー最適化の強化学習手法を通じて、事前トレーニングおよび微調整された GPT-3 モデルを更新しました (ステップ 3)。
ちなみに、この論文は、ChatGPT の背後にある考え方を説明する論文とも考えられています。最近の噂によると、ChatGPT は、より大きなデータ セットで微調整された InstructGPT のスケール バージョンです。
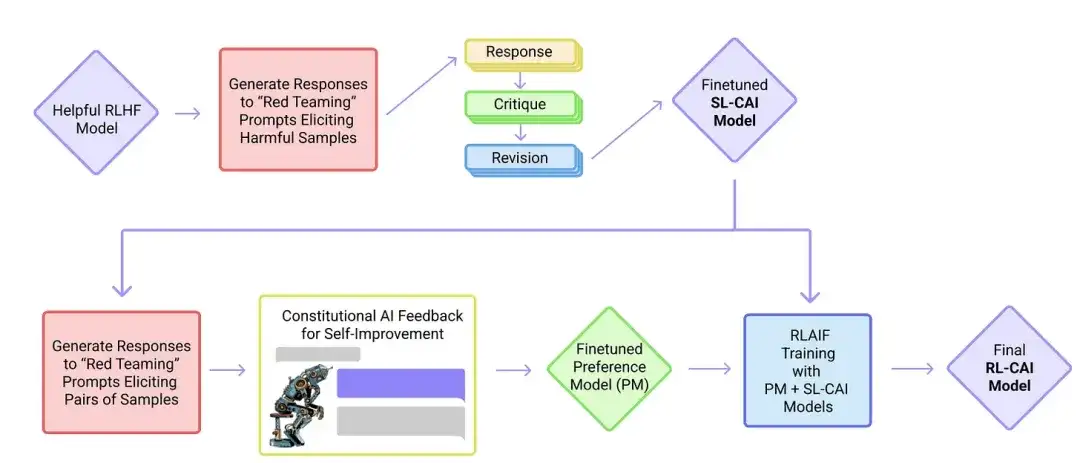
18. 憲法上の AI: AI フィードバックによる無害性(2022 年)
注目:ユンタオ、サウラフ、サンディパン、アマンダ、ジャクソン、ジョーンズ、チェン、アンナ、ミルホセイニ、マッキノン、チェン、オルソン、オラ、ヘルナンデス、ドレイン、ガングリ、リー、トランジョンソン、ペレス、カー、ミューラー、ラディッシュ、ランダウ、ンドウス、ルコスイート、ロビット、セリット、エルハーゲ、シーファー、メルカド、ダスサルマ、ラセンビー、ラーソン、リンガー、ジョンストン、クラベック、エル・ショーク、フォート、ランハム、テレーン=ロートン、コナリー、ヘニハン、ヒューム、ボーマン、ハットフィールド=ドッズ、マン、アモデイ、ジョセフ、マッキャンドリッシュ、ブラウン、カプラン
論文リンク: https://arxiv.org/abs/2212.08073。
この論文では、研究者たちは「アライメント」のアイデアをさらに発展させ、「無害な」AI システムを作成するためのトレーニング メカニズムを提案しています。研究者らは、人間が直接監督する代わりに、人間が提供するルールのリストに基づいた自己訓練メカニズムを提案している。前述の InstructGPT の論文と同様に、提案された手法は強化学習手法を使用します。
19. Self-Instruct: 言語モデルと自己生成命令の調整(2022)
論文の著者: Wang、Kordi、Mishra、Liu、Smith、Khashabi、Hajishirzi
論文リンク: https://arxiv.org/abs/2212.10560
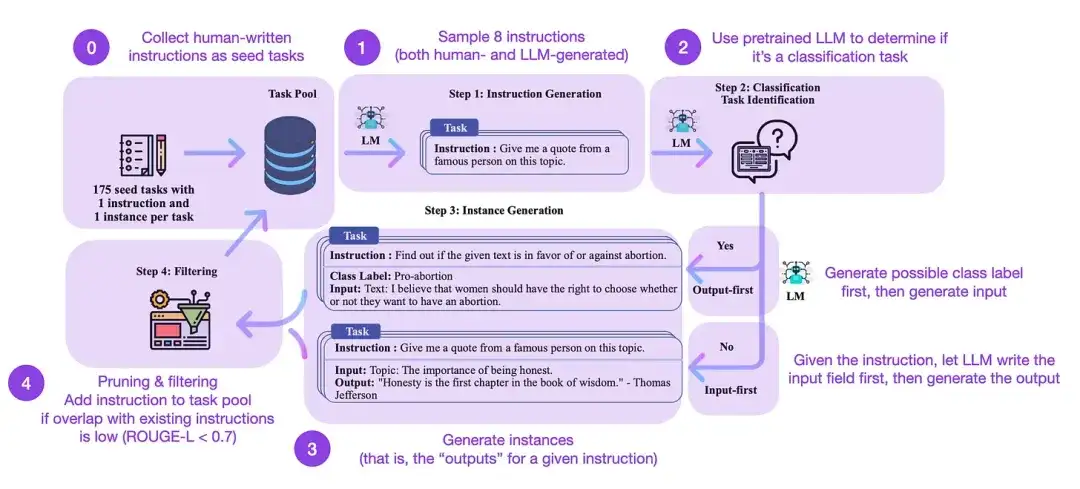
命令の微調整は、GPT-3 のような事前トレーニングされた基本モデルから ChatGPT のようなより強力な LLM に移行する方法です。 databricks-dolly-15k のようなオープンソースの人間が生成した命令データセットは、このプロセスを可能にするのに役立ちます。しかし、規模を達成するにはどうすればよいでしょうか? 1 つのアプローチは、LLM が独自に生成したコンテンツに基づいてブートストラップ学習を実行させることです。
Self-Instruct は、事前トレーニングされた LLM を命令と調整する (ほぼアノテーションなしの) 方法です。このプロセスはどのように機能するのでしょうか?つまり、次の 4 つのステップで構成されます。
- 人間が書いた一連の命令 (この場合は 175) とそこからのサンプル命令を使用してタスク プールを初期化します。
- 事前トレーニングされた LLM (GPT-3 など) を使用してタスク カテゴリを決定します。
- 新しい命令の場合は、事前トレーニングされた LLM に応答を生成させます。
- これらの応答は、タスク プールに追加される前に収集され、フィルター処理されます。
このように、自己指示メソッドは、手動による注釈を減らしながら、事前トレーニング済み言語モデルの指示に従ったり生成したりする能力を効果的に向上させることができ、それによってモデルの機能を拡張および最適化できます。
実際には、この方法は ROUGE スコアに基づいて比較的良好に機能します。たとえば、大規模言語モデル (LLM) のセルフガイド微調整は GPT-3 基本モデルを上回り、人間が書いた大規模な命令セットで事前トレーニングされた LLM と競合することができました。さらに、セルフガイダンスは、人間の指示によって微調整された LLM にも利益をもたらします。
もちろん、LLM を評価するための最も重要な標準は、人間の評価者に参加を依頼することです。人間による評価に基づくセルフガイド手法は、基本的な LLM だけでなく、教師ありの方法で人間の指示データセットでトレーニングされた LLM (SuperNI、T0 Trainer など) を超えています。しかし興味深いことに、自己指導は、ヒューマンフィードバックを組み込んだ強化学習法(RLHF)を通じて訓練されたものよりも優れていませんでした。
人間が生成した命令データ セットと自己誘導データ セットではどちらがより有望ですか?私はどちらにも強気です。 databricks-dolly-15k の 15,000 個の命令など、人間が生成した命令データセットから始めて、それを自主的な方法で拡張してみてはいかがでしょうか?
強化学習とヒューマン フィードバック (RLHF) 強化学習とヒューマン フィードバック (RLHF) の詳細な説明、および RLHF を実装するための近接ポリシーの最適化に関する関連論文については、以下の私の詳細な記事を参照してください。
研究の最新情報であろうとチュートリアルであろうと、大規模言語モデル (LLM) について議論するとき、私はしばしばヒューマン フィードバックによる強化学習 (RLHF) と呼ばれるプロセスに言及します。 RLHF は人間の好みを最適化フレームワークに組み込むことができるため、最新の LLM トレーニング パイプラインの重要な部分になっており、それによってモデルの有用性と安全性が向上します。
記事全文を読む:
https://magazine.sebastianraschka.com/p/llm-training-rlhf-and-its-alternatives
結論とさらなる読み物
私は、現代の大規模言語モデルの設計、制限、進化を理解する上位 10 件の論文 (および RLHF に関する 3 件の論文) に焦点を当て、上記のリストを簡潔かつ簡潔に保つよう努めました。さらに詳しく研究するには、上記の論文で引用されている文献を参照することをお勧めします。以下に追加のリソースをいくつか示します。
GPT に代わるオープンソースの代替手段:
- BLOOM: 176B パラメーターのオープンアクセス多言語言語モデル (2022)、https://arxiv.org/abs/2211.05100
- OPT: オープンな事前トレーニング済み Transformer 言語モデル (2022)、https://arxiv.org/abs/2205.01068
- UL2: 言語学習パラダイムの統一 (2022)、https://arxiv.org/abs/2205.05131
ChatGPT の代替案:
- LaMDA: ダイアログ アプリケーションの言語モデル (2022)、https://arxiv.org/abs/2201.08239
- (Bloomz) マルチタスクの微調整による言語を超えた一般化 (2022)、https://arxiv.org/abs/2211.01786
- (Sparrow) 対象を絞った人間の判断による対話エージェントの調整の改善 (2022)、https://arxiv.org/abs/2209.14375
- BlenderBot 3: 責任を持って関与することを継続的に学習する、デプロイされた会話エージェント、https://arxiv.org/abs/2208.03188
バイオコンピューティングにおける大規模モデル:
- ProtTrans: 自己教師あり深層学習とハイパフォーマンス コンピューティングによる生命のコードの言語の解読に向けて (2021)、https://arxiv.org/abs/2007.06225
- AlphaFold による高精度のタンパク質構造予測 (2021)、https://www.nature.com/articles/s41586-021-03819-2
- 大規模言語モデルは多様な家族にわたって機能的なタンパク質配列を生成する (2023)、https://www.nature.com/articles/s41587-022-01618-2
記事の推奨事項
平均月給は46,000超え!ハーバード大学、スタンフォード大学、マイクロソフト、グーグルなどが制作したAI分野の最も重要なコースをまとめました!
誰もが開発者である時代において、プログラミングを学ぶことはまだ役に立ちますか?
侵害がある場合は、削除するためにご連絡ください。参考リンク:
https://magazine.sebastianraschka.com/p/ Understanding-large- language-models
私たちに従ってください
OpenSPG:
公式 Web サイト: https://spg.openkg.cn
Github: https://github.com/OpenSPG/openspg
OpenASCE:
公式 Web サイト: https://openasce.openfinai.org/
GitHub: [https://github .com /Open-All-Scale-Causal-Engine/OpenASCE ]