
著者:Chen Xin(シェンシウ)
皆さんこんにちは。Tongyi Lingma の製品テクニカル ディレクターの Chen Xin です。過去 8 年間、私はアリババ グループで R&D パフォーマンス、つまり R&D ツール関連の仕事に従事してきました。
当社は 2015 年にワンストップの DevOps プラットフォームの構築を開始し、その後、DevOps プラットフォームをクラウド化する Cloud Effect を作成しました。 2023年までに、大型モデルの時代が到来し、ソフトウェアツールは徹底的な革新に直面し、大型モデルとソフトウェアツールチェーンの組み合わせによって、ソフトウェアの研究開発は次の時代に移行すると確信しています。
それで、最初の停留所はどこでしょうか?実際、これは補助プログラミングであるため、大規模なコード モデルに基づく AI 補助ツールである製品Tongyi Lingmaの作成を開始しました。本日は、この機会を利用して、Tongyi Lingma テクノロジーの実装に関する詳細と、ソフトウェア研究開発分野における大規模モデルの開発についての当社の見解を共有したいと思います。
3回に分けてシェアさせていただきます。最初の部分では、AIGC がソフトウェアの研究開発に与える基本的な影響を紹介し、マクロの観点から現在のトレンドを紹介します。2 番目の部分では、Copilot モデルを紹介します。3 番目の部分では、将来のソフトウェア開発エージェント製品の進捗状況を紹介します。なぜ Copilot Agent について言及したかについては、後ほど説明します。
AIGC がソフトウェア開発に与える基本的な影響
この絵は私がここ数年で描いた絵ですが、企業の研究開発効率に影響を与える中心的な要素はこの3点であると考えています。
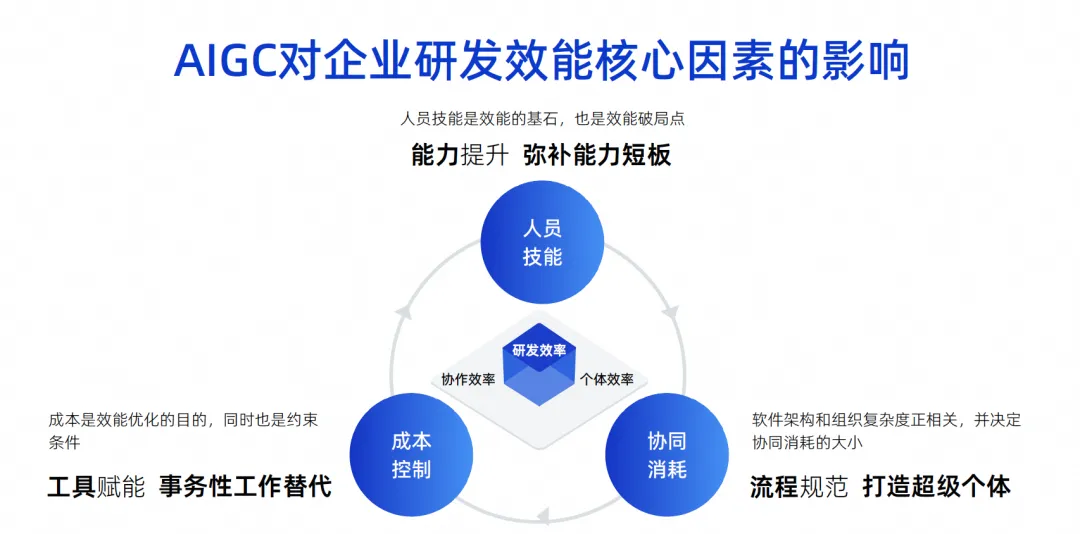
1つ目のポイントはヒューマンスキルです。たとえば、Google では、個人の能力が他の人よりも 10 倍高いエンジニアを採用できます。つまり、10 倍以上のグループで構成される小さなグループに相当します。有能なエンジニアは戦闘効率が非常に高く、役割分担が非常にシンプルで、作業が非常に効率的であり、最終的な効率も非常に優れています。
しかし実際には、Google のレベルに到達できる企業、特に中国企業はほとんどありません。これは客観的な影響要因であり、人事スキルは有効性の基礎であり、もちろん有効性の限界点でもあると考えています。
2点目は、協働消費です。すべてのエンジニアに高い能力を求めることはできないため、たとえば、ソフトウェアの設計を行う人もいれば、開発、テスト、プロジェクト管理を行う人もいるというように、全員が専門的に分業する必要があります。これらの人々で構成されるチームのソフトウェア アーキテクチャが複雑になると、それに比例して組織の複雑さも増加し、最終的には全体的な研究開発の効率が低下します。
3つ目はコスト管理です。プロジェクトに取り組むと、人は必ずしも裕福とは限らず、人手は常に不足しており、10倍のエンジニアを雇用するための資金を無限に持つことは不可能であり、これも制約であることがわかりました。
AIGC の時代の今日、これら 3 つの要因により根本的な変化が生じています。
人材スキルの面では、 AI 支援により一部の若手エンジニアの能力を急速に向上させることができます。実際、海外では若手エンジニアのコード支援ツール利用効果が上級エンジニアよりも大幅に高いという報告もあります。これらのツールは初心者レベルの作業の代替として、またはその補助的な効果として非常に優れているため、若手エンジニアの欠点をすぐに補うことができます。
共同消費の観点から言えば、今日 AI が超個人的になることができれば、プロセスの共同消費を減らすのに実際に役立つでしょう。例えば、簡単な作業は人が介在する必要がなく、AIが直接行うことができ、要件のテスト方法を全員に説明する必要もなく、AIは簡単なテストを行うだけで済むため、時間効率が向上します。 。したがって、スーパー個人を通じて共同消費を効果的に削減できます。
実際、コスト管理の観点から言えば、コード支援のための大規模なコード モデルの現在の使用を含め、多くの AI の使用がトランザクション作業を置き換えることになり、これも日々のトランザクション労働の 70% を置き換えると予想されています。
具体的に見てみると、インテリジェンスには次の 4 つの課題と機会が存在します。

1つ目は、先ほどご紹介したように、多数の研究開発エンジニアの反復作業や単純なコミュニケーションをAIで完結させるモデルです。
コラボレーション効率のもう 1 つの側面は、いくつかの単純なタスクを AI によって直接実行できるため、これについては先ほど明確に説明しました。
3 つ目は、R&D の経験です。DevOps ツール チェーンはこれまで何に重点を置いていましたか?それらは 1 つずつ、大規模な組立ラインとツールチェーン全体を形成します。実際、各ツール チェーンは企業ごとに異なる使用習慣を持っている可能性があり、異なるアカウント システム、異なるインターフェイス、異なる操作、異なる権限を持っている場合もあります。この複雑さは、開発者に非常に大きなコンテキスト切り替えコストと理解コストをもたらし、目に見えない形で開発者を非常に不満にさせます。
しかし、AI 時代にはいくつかの変化が起こりました。私たちは自然言語を使用して、統合された対話の入り口を通じて多くのツールを操作できるようになり、自然言語ウィンドウで多くの問題を解決することさえできます。
たとえば、SQL ステートメントにパフォーマンス上の問題があるかどうかを確認する場合、どうすればよいでしょうか。まずコード内の SQL ステートメントを抽出し、実行可能なステートメントに変換してから、それを DMS システムに入れて診断し、インデックスが使用されているかどうか、問題があるかどうかを確認し、手動で問題があるかどうかを判断します。この SQL を変更して最適化し、最後に IDE で変更する必要があります。このプロセスでは、複数のシステムを切り替える必要があり、多くの作業を行う必要があります。
将来的には、コード インテリジェンス ツールがあれば、コードを丸で囲んで、この SQL に問題があるかどうかを大規模モデルに問い合わせることができます。この大規模モデルは、DMS システムなどのいくつかのツールを独立して呼び出して分析することができます。得られた結果は、大規模なモデルを通じて SQL をどのように最適化するかを直接教えてもらい、問題を解決するためにそれを採用するだけで済み、操作全体のリンクが短縮され、エクスペリエンスが向上し、研究開発が可能になります。効率が向上します。
4つ目は、デジタル資産です。昔はみんなでコードを書いてそこに置いたので、当然、発掘されていない素晴らしい金鉱がたくさんあります。見つけたい時間が見つからない。
しかし、AI 時代において、私たちが行う最も重要なことの 1 つは、資産とドキュメントを整理し、SFT と RAG を通じて大規模なモデルに機能を与え、大規模なモデルがよりスマートになり、ユーザーの個性に沿ったものになるようにすることです。したがって、人間とコンピューターの対話方法における今日の変化は、エクスペリエンスに変化をもたらすでしょう。

人工知能は、人間とコンピューターの対話方法に 3 つの変化をもたらすことを、その影響要因を分析します。 1 つ目は、AI がツールと結合して副操縦士となり、人間が AI に命令して、単一ポイントのツールを完成させることができるようになるということです。第 2 段階では、全員が実際に合意を得る必要があります。これは、コードの作成やテストの実行などのタスクを独立して完了できることを意味します。実際、このツールはマルチドメインのエキスパートとして機能します。必要なのは、コンテキストを提供して知識の調整を完了することだけです。第 3 段階では、第 2 段階でも意思決定者は依然として人間であるため、AI が意思決定者になる可能性があると判断します。第 3 段階では、大規模なモデルがある程度の意思決定能力を持つ可能性があります。より高度な情報統合および分析機能が含まれます。現時点では、人々はビジネスの創造性と修正により重点を置き、多くのことを大規模なモデルに任せることができます。このさまざまなマンマシンモードの変更により、全体的な作業効率が向上します。

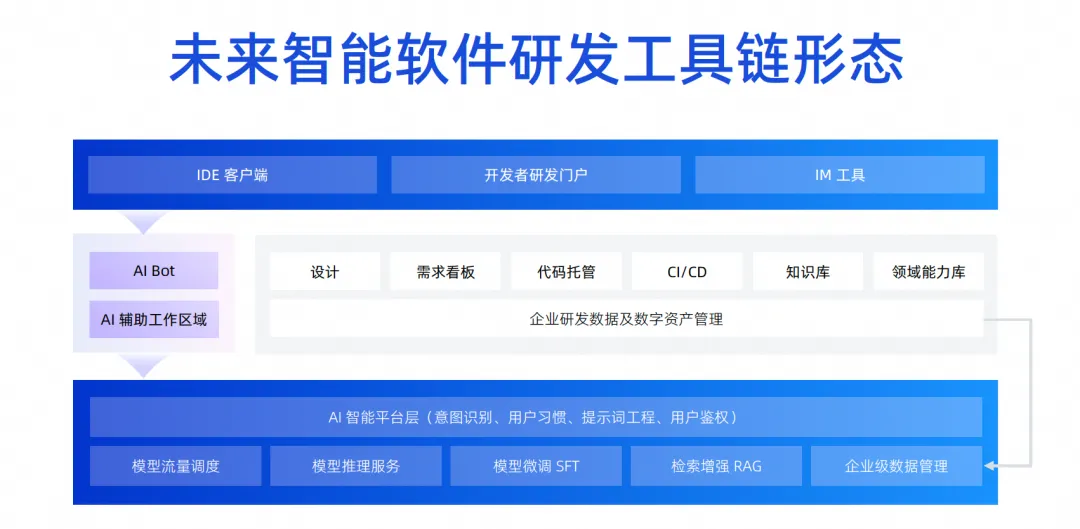
もう一つの点は、先ほど話した知識伝達の形態も根本的に変化しているということです。これまで、知識の伝達の問題は、口頭、トレーニング、古いものが新しいものをもたらすことによって解決されていました。将来的には、これは必要なくなる可能性が非常に高くなります。必要なのは、ビジネス知識とドメインの経験をモデルに装備し、すべての開発エンジニアがインテリジェントなツールを使用できるようにすることだけです。上に示すように、DevOps 用のワンストップ ツール チェーンが表示されます。多数のコードとドキュメント資産を蓄積した後、これらの資産が分類され、RAG と SFT を通じて大規模なモデルにまとめられ、そのモデルが DevOps ツールの各リンクに埋め込まれ、より多くのデータが生成され、このようなフォワードが形成されます。このプロセスでは、最前線の開発者は資産によってもたらされる恩恵や機能を享受できます。
上記は、大型モデルの研究開発効率に影響を与える中心的な要因と、その形態における 2 つの最も重要な変化をマクロの観点から紹介したものです。1 つ目は人間とコンピュータの相互作用の形態の変化であり、2 つ目は知識の伝達方法が根本的に変わります。大規模モデルの開発段階ではさまざまな技術的な制限や問題があるため、私たちが最も得意とするのは Copilot の人間とコンピューターの対話モードです。次に、私たちの経験の一部と、最適な Copilot の人間とコンピューターの対話モードを作成する方法を紹介します。 。
最高の副操縦士のポーズを作成する
私たちは、コード開発の人間とコンピューターの対話モデルが現在解決できるのは、小規模なタスク、手動での採用が必要な問題、およびコード補完による段落の生成などの高頻度の問題のみであると考えており、それを受け入れます。これは非常に頻繁に発生する問題であり、一度にプロジェクトを生成したり、一度にクラスを生成したりすることはありません。毎回関数または数行。なぜこれを行うのでしょうか?実際、これはモデル自体の機能の制限と大きく関係しています。
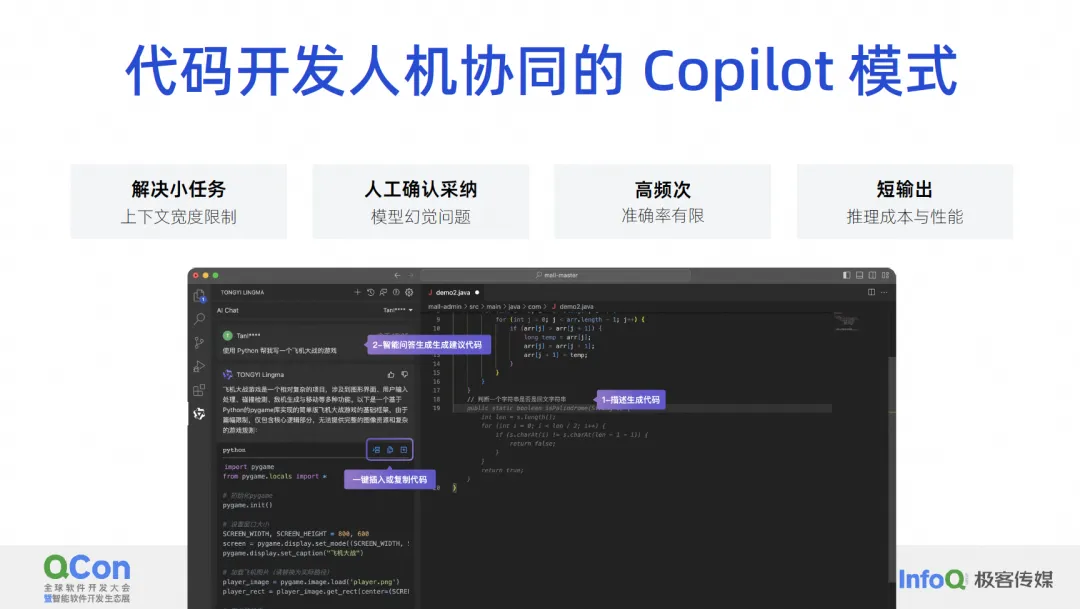
現在のコンテキスト幅はまだ非常に限られているため、要件を完了したい場合、すべての背景知識を一度に渡す方法はないため、エージェントを使用して要件を小さなタスクの束に分割するか、そしてそれらを段階的に解決してください。または、コメントに従って小さなコードを生成するなど、最も単純なタスクをコパイロット モードで完了させます。これは、いわゆる小さなタスクの解決です。
手動による導入に関しては、大規模なコード モデルによって生成された結果を人間が判断する必要があります。現在うまくいっているのは、採用率が 30% ~ 40% である可能性があります。これは、生成されたコードの半分以上が実際には不正確であるか、開発者の期待を満たしていないことを意味するため、錯覚の問題を常に排除する必要があります。
ただし、大規模なモデルを本番レベルで本当に使用できるようにするために最も重要なことは、手動で確認することです。その場合、このコードが正しいかどうかを手動で確認するコストがかかるため、高頻度のモデルをあまり生成せず、毎回少量ずつ生成します。 OK はパフォーマンスにも影響します。この記事では、私たちの考え方と取り組みについて説明し、高周波による精度の制限の問題を解決します。さらに、生産量が不足するのは主にパフォーマンスとコストの問題が原因です。
コードアシスタントの現在のモデルは、実際には大規模モデルのいくつかの技術的制限を非常に正確に満たしているため、そのような製品を迅速にリリースできる非常に良い機会があります。私たちの意見では、開発者が最も好む Copilot モデルは、次の 4 つのキーワードです。高頻度で厳格なニーズ、手の届くところにある、自分の欲しいものを知っている、自分だけのものです。

1 つ目は、開発者がこれが単なるおもちゃではなく本当に便利であると感じられるように、高頻度で緊急に必要なシナリオを解決する必要があるということです。
2 つ目は手の届くところにあり、いつでも目覚めることができ、いつでも問題を解決するのに役立ちます。以前のようにさまざまな検索エンジンでコードを検索する必要はなくなり、まるで自分のそばにいるかのように、いつでも起動して問題を解決することができます。
3つ目は、自分が何を考えているかを知ること、つまり、私の質問に対する答えの正確さと、質問に答えてくれるタイミングが非常に重要です。
最後に、完全にオープンソースのものだけを理解するのではなく、私の個人的な知識の一部を理解できる必要があります。この4つのポイントについて詳しく解説していきます。
高周波が必要なだけ
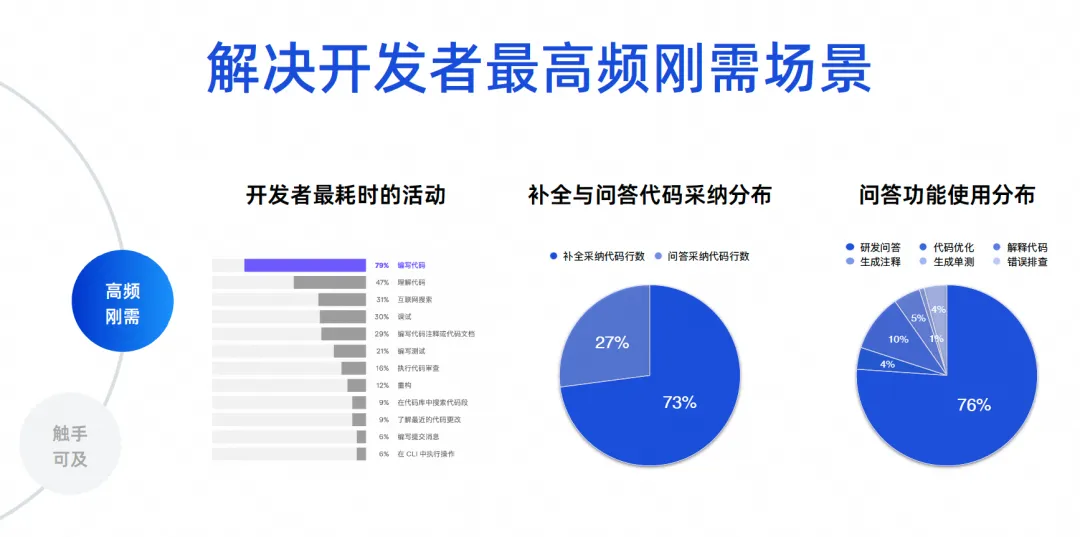
ソフトウェア開発で最も頻繁に起こるシナリオは何かを判断する必要があります。ここに実際のデータがあります。最初のデータは、2023 年に JetBrains によって作成された開発者エコロジカル レポートからのものです。これは、開発者の 70% から 80% がコードを作成しており、コードを理解していることがわかります。インターネットを検索し、デバッグし、コメントを書き、テストを作成します。これらのシナリオは、実際にはコード インテリジェンス ツールの機能であり、Tongyi Lingma のような製品が解決する中心的な問題は、実際に最も頻繁に発生する問題です。
後の 2 つのデータは、Tongyi Lingma Online の数十万人のユーザーのデータ分析です。現在オンラインで採用されているコードの 73% は完了タスクによるもので、27% は質疑応答タスクの採用によるものです。したがって、現在、多くの AI が人間に代わってコードを記述しており、それらは依然として IDE の行間で生成されています。これは現実の状況を反映した結果です。次に、Q&A 機能の使用割合は、研究開発 Q&A が 76% で、残りの 10% がコードの最適化やコード解釈などの一連のコード作業です。したがって、大多数の開発者は依然として当社のツールを使用して、一般的な研究開発の知識を求めたり、自然言語を使用して大規模なコード モデルからアルゴリズムを生成して、いくつかの小さな問題を解決したりしています。
次の 23% は実際の詳細なコーディング タスクであり、全員にデータの洞察を提供するためのものです。したがって、私たちには核となる目標があります。まず、コード生成、特に行間の問題を解決する必要があります。第二に、研究開発課題の正確性と専門性の問題を解決する必要があります。
届く範囲で

私たちが最終的に話したいのは、没入型のプログラミング エクスペリエンスを作成することです。今日開発者が直面している問題のほとんどが、IDE 内で解決できることを願っています。
私たちの過去の経験は何だったのでしょうか?問題が発生した場合は、インターネットで検索したり、人に聞いたりして、最後にコードを書いてコピーし、IDE に入れてデバッグやコンパイルを行って、問題がないかどうかを再度確認する必要があります。これは非常に時間がかかります。 IDE で大きなモデルに直接問い合わせて、大きなモデルにコードを生成してもらえるようになり、非常に快適なエクスペリエンスが得られることを期待しています。このような技術的な選択により、私たちは没入型プログラミング体験の問題を解決しました。
完了タスクはパフォーマンスが重要なタスクであり、その出力は 300 ~ 500 ミリ秒以内、できれば 1 秒以内である必要があるため、主にコードの生成とそのトレーニングの大部分に使用される小さなパラメーター モデルがあります。コーパスもコードから得られます。モデルパラメータは小さいですが、コード生成の精度は非常に高いです。
2 番目のタスクは、アノテーションの生成、単体テスト、コードの最適化、操作エラーのトラブルシューティングなどの 7 つのタスクを含む、実際のタスクの 20% ~ 30% を実行することです。
現在、中程度のパラメータ モデルを使用しています。ここでの主な考慮事項は、第一に発電効率、第二にチューニングです。非常に大きなパラメーターのモデルの場合、調整コストは非常に高くなりますが、この中程度のパラメーターのモデルでは、コードの理解とコード生成の効果がすでに優れているため、中程度のパラメーターのモデルを選択しました。
次に、大規模モデルに関しては、特に研究開発の質問の 70% 以上に答える際に、高精度でリアルタイムの知識を追求します。そこで、最大パラメータ モデルを通じて RAG テクノロジーを重ね合わせ、ほぼリアルタイムのインターネット ベースのナレッジ ベースにプラグインできるようにしました。そのため、回答の品質と効果は非常に高く、モデルの錯覚を大幅に排除して回答を向上させることができます。品質。私たちは、このような 3 つのモデルを通じて、没入型プログラミング体験全体をサポートします。

2 番目のポイントは、より多くの端末をカバーすることによってのみ、より多くの開発者をカバーできるため、複数の端末を実装する必要があるということです。現在、Tongyi Lingma は VS コードと JetBrains をサポートしており、主にトリガーの問題、表示の問題、および一部の対話性の問題を解決します。
コアレベルでは、ローカルエージェントサービスは独立したプロセスです。このプロセスと上記のプラグインの間で通信が行われます。このプロセスは主に、コードのインテリジェントな補完、セッション管理、エージェントなど、コードのいくつかのコア機能に対処します。
さらに、ファイル間参照の問題を解決するには、構文解析サービスも非常に重要です。ローカル検索を強化したい場合は、軽量のローカル ベクトル検索エンジンも必要です。したがって、実際には、この方法でバックエンド サービス全体を迅速に拡張できます。
また、JetBrains を含め、オフラインで実行できる、B の数十分の小さなローカル オフライン モデルもあります。 。このようにして、ローカル セッション管理やローカル ストレージなど、データ セキュリティとプライバシーの問題の一部はすべてローカル コンピューターに配置されます。

私が何を考えているかを知ってください
IDE プラグイン ツールについては、いくつかの点があると思います。 1 つ目はトリガー時間であり、トリガーされるときも開発者のエクスペリエンスに大きな影響を与えます。たとえば、スペースを入力したときにトリガーする必要がありますか? IDE がプロンプトを生成したときにトリガーする必要がありますか?このコードを削除するときにトリガーされるべきですか?おそらく 30 ~ 50 以上のシナリオを整理する必要がありますが、このシナリオでコードをトリガーするかどうかは、慎重に調べて開発者のエクスペリエンスを調査する限り、解決できます。これはそれほど奥深いテクノロジーではありません。 。
しかし、コード生成の長さの観点から見ると、それはより困難であると考えられます。異なる編集領域の異なる場所では、生成されるコードの長さがエクスペリエンスに直接影響するためです。開発者が 1 行のコードのみを生成する傾向がある場合、問題は、開発者が生成されたコンテンツ全体を理解できないことです。たとえば、関数を生成するとき、または if を生成するとき、関数が何を行うのかがわかりません。 if ステートメントの内容がわかりません。ビジネス ロジックは何ですか? 機能単位を完全に判断する方法はありません。これはユーザーの経験に影響します。
それを何か決まったルールでやると、相対的に厳格になってしまうという問題も出てきます。したがって、私たちのアプローチは実際にはコードのセマンティック情報に基づいており、トレーニングと多数のサンプルを通じて、モデルはどのシナリオでどのくらいの時間生成されるべきかを理解し、クラスレベル、機能を自動的に決定するモデルを実装しました。論理ブロックレベルおよび行レベルでの生成強度を適応型生成強度決定といいます。事前トレーニングをたくさん行うことでモデルに認識させ、生成の精度を向上させることも重要な技術項目であると考えています。
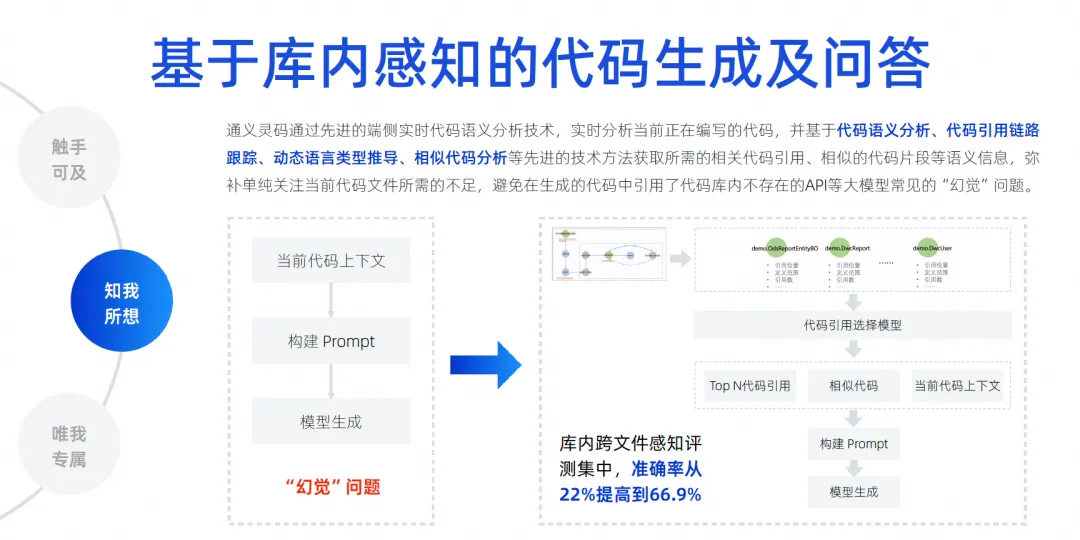
今後最も重要なことは、モデルの幻想をどのように排除するかです。なぜなら、モデルの幻想が十分に排除されて初めて、採用率を向上させることができるからです。したがって、ライブラリ内でファイル間のコンテキスト認識を実装する必要があります。ここでは、コードベースのセマンティック分析、参照チェーンの追跡、類似のコード、および動的言語型の派生を数多く実行します。
最も重要なことは、開発者がこのポジションに就くためにどのような背景知識が必要かを推測することです。これらには、言語、フレームワーク、ユーザーの習慣などが関係する場合もあります。さまざまなものを組み合わせて使用します。コンテキストに優先順位を付け、最も重要な情報をコンテキストに組み込み、それを導出のために大規模なモデルに与えることで、大規模なモデルが錯覚を排除できるようになります。このテクノロジーにより、ファイル間のコンテキストを認識したテスト セットを実現でき、精度は 22% から 66.9% に向上し、現在も補完効果は継続的に向上しています。
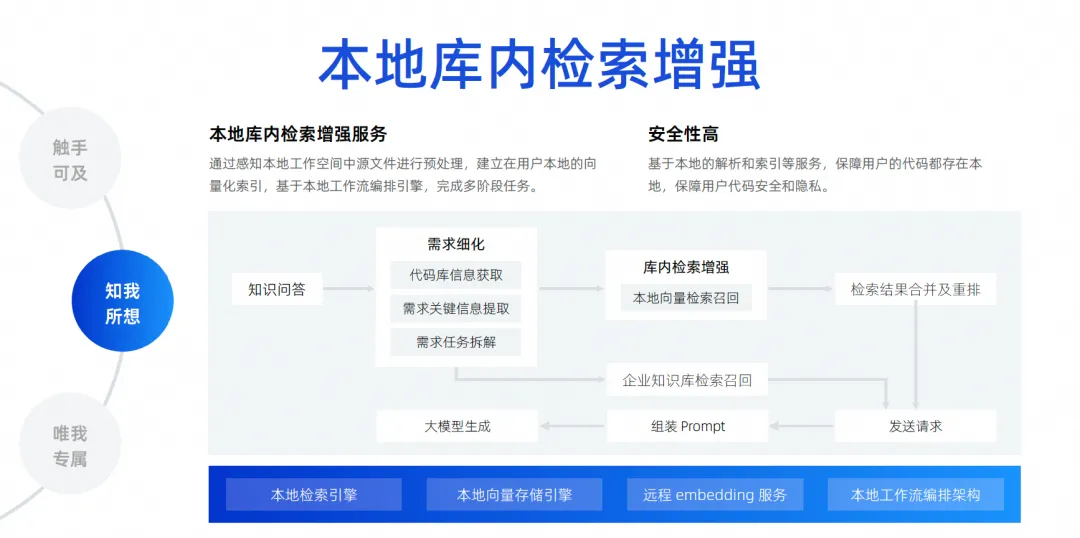
最後の機能は、ローカルな図書館内検索の機能強化です。先ほど述べたように、コンテキスト認識は、トリガー位置における開発者のコンテキストを推測するだけです。より一般的なシナリオは、今日開発者が質問したいと考えており、ローカル ライブラリ内のすべてのファイルに基づいて問題を解決するのに大規模なモデルを支援してもらうことです。たとえば、バグの修正を手伝ってくれたり、要件の追加を手伝ってくれたり、助けてくれたりします。ファイルに入力し、自動的に追加、削除、変更、検索を実行し、さらに新しいパッケージ バージョンを Pompt ファイルに追加する これを実現するには、実際に検索エンジンを接続する必要があります。大型モデルの場合。コンテキスト幅の影響により、プロジェクト全体のすべてのファイルを大規模なモデルに詰め込むことは不可能であるため、ローカル ライブラリ内検索強化と呼ばれるテクノロジーを使用する必要があります。
この機能は、ライブラリに基づいた無料の Q&A を実現し、ライブラリ内でのローカル検索強化サービスを確立するためのものであり、この方法が開発者のエクスペリエンスにとって最適であり、最も高いセキュリティを備えていると判断しました。
リンク全体を完成させるためにコードをクラウドにアップロードする必要はありません。リンク全体の観点から見ると、開発者が質問した後、コード ベースに移動して、タスクの逆アセンブルに必要な重要な情報を抽出します。逆アセンブルが完了した後、ローカル ベクトル検索とリコールを実行します。企業はエンタープライズレベルで統合されたナレッジベース管理を行っているため、検索結果をマージおよび再配置し、企業の内部データナレッジベースを検索します。最後に、すべての情報が要約されて大きなモデルに送信され、大きなモデルが問題を生成して解決できるようになります。

私だけのために
企業が大規模なコード モデルで非常に優れた効果を達成したい場合、このレベルから逃れることはできないと思います。例えば、プロジェクト管理段階などでエンタープライズデータのパーソナライズされたシナリオを実現する方法、要件/タスク/欠陥内容の固有の形式と仕様に従って大規模なモデルを生成する方法、データの自動分解と自動更新の実現に役立ちます。ライティング、自動要約などの要件。
開発段階は、誰もが最も注意を払う部分かもしれません。企業は、自社のコード仕様に準拠し、自社のセカンドパーティ ライブラリを参照し、フロントエンドの使用を含めて API を呼び出して SQL を生成する必要があるとよく言います。会社が自社開発したフレームワーク、コンポーネント ライブラリなど、これらはすべて開発シナリオに属します。テスト シナリオでは、企業の仕様に準拠し、ビジネスを理解するテスト ケースも生成する必要があります。運用および保守のシナリオでは、常に企業の運用および保守の知識を探し、質問に答えて企業の運用および保守 API の一部を取得し、コードを迅速に生成する必要があります。これらは、私たちが実行する必要があると考えているエンタープライズ データのパーソナライゼーションのシナリオです。具体的なアプローチは、検索の強化またはトレーニングの微調整を通じてこれを達成することです。
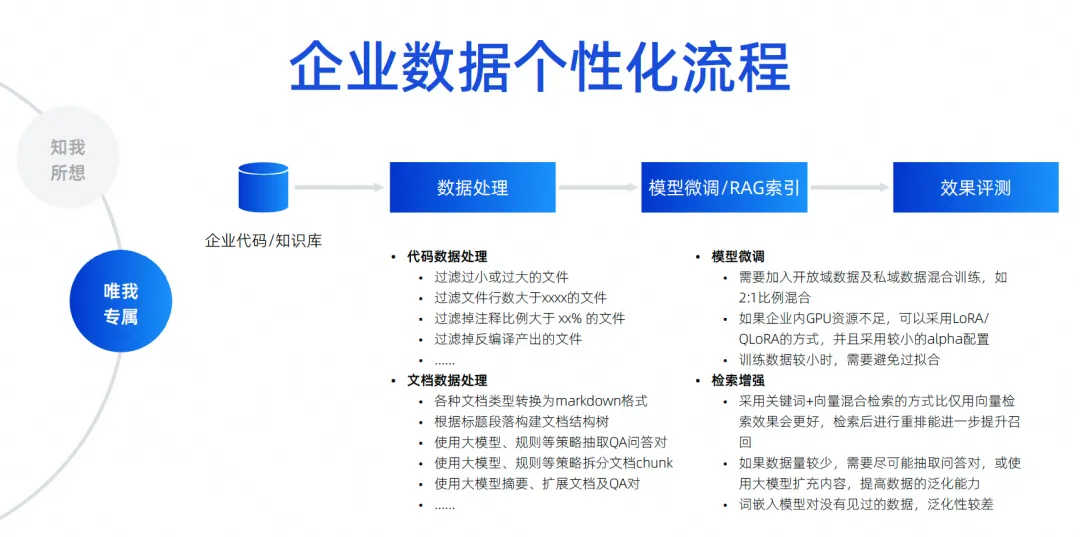
ここでは、コードの処理方法、ドキュメントの処理方法、使用前にコードをフィルタリング、クリーンアップ、構造化する必要があるなど、いくつかの簡単なシナリオと注意すべき事項をリストしました。
トレーニング プロセス中に、オープン ドメイン データとプライベート ドメイン データの混合を考慮する必要があります。たとえば、検索の強化に関しては、いくつかの異なるパラメータの調整を行う必要があります。実際には、コード生成シナリオで必要なコンテキスト情報をどのようにヒットするかなど、さまざまな検索強化戦略を検討する必要があります。質問と回答のシナリオで必要な回答のコンテキスト情報をヒットすることは、検索の強化です。
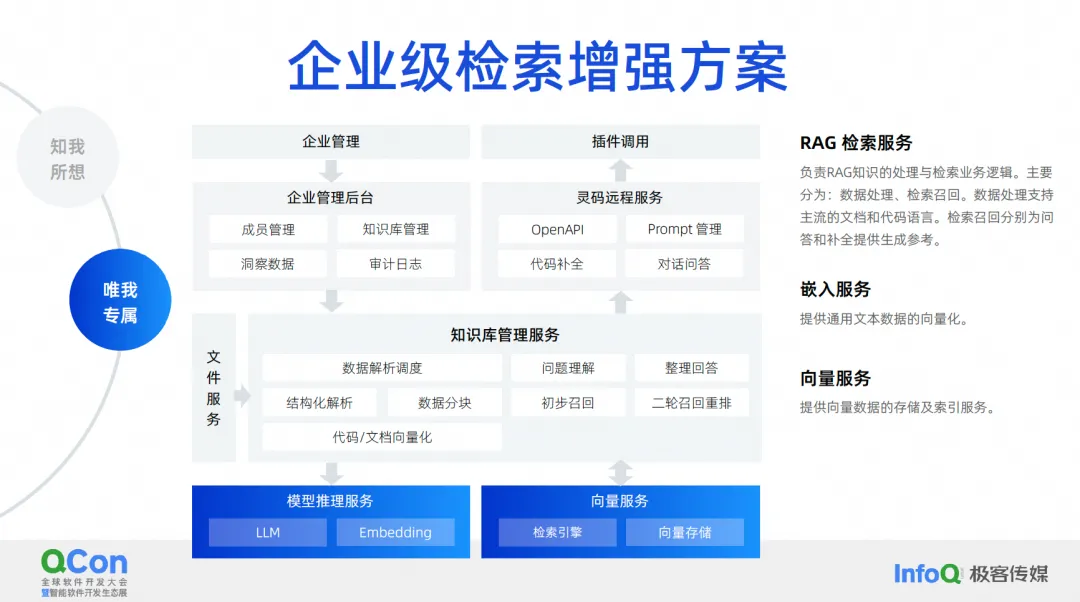
私たちがやりたいのは、エンタープライズ レベルの検索強化ソリューションです。エンタープライズ レベルの検索強化ソリューションの現在のアーキテクチャ図は、おおよそ次のようになります。中央には、データ分析のスケジュール設定、質問の理解、回答の整理、構造化分析、データのセグメンテーションなどを含むナレッジ ベースの管理サービスがあります。コア機能は中央にあり、その下にあるのは、より一般的に使用される埋め込みサービスです。 . 、大規模なモデル、ベクトルの保存と取得のためのサービスを含みます。
このシナリオでは、ドキュメントの検索の強化とコード生成の検索の強化をサポートするバックエンドがいくつかあります。コード生成は、このシナリオの検索と拡張を完了するために必要な処理方法とテクノロジが、実際にはドキュメントの場合とは少し異なります。
過去に私たちは復丹大学と数年間にわたり学術研究を行ってきましたが、その際のテストセットの結果も 1.1 のモデルに基づいたものであり、その努力に非常に感謝しています。探索強化と合わせて1Bまでの精度と効果は実質7B以上の機種と同等の効果が得られます。
ソフトウェア開発エージェント製品の今後の進化
私たちは、将来のソフトウェア開発は間違いなくエージェント時代に突入すると信じています。これはエージェントがある程度の自律性を持ち、私たちのツールを非常に簡単に使用し、人間の意図を理解して作業を完了し、最終的には図に示すような多目的ソフトウェアを形成できることを意味します。エージェントの協調モデル。

ちょうど今年の 3 月に、デビンが誕生したことで、この問題が本当に加速するのを感じました。これまでは、この問題が実際のビジネス プロジェクトを完了させるとは想像もしていませんでした。まだ 1 年先のことかもしれませんが、その出現により、今日では大規模なモデルを介して何百、何千ものステップを実際に分解し、問題が発生した場合にそれを自分自身で反省して繰り返すことができるようになります。強力な分解能力と推理力にとても驚きました。
Devin の誕生とともに、さまざまな専門家や学者が投資を開始しました。その中には、すぐに OpenDevin と呼ばれるプロジェクトを立ち上げた当社の Tongyi 研究所も含まれます。このプロジェクトはわずか数週間で 20,000 スターを超えており、皆さんがこの分野に非常に熱心であることがわかります。その後、すぐに SWE の Agent プロジェクトをオープンソース化し、SWE ベンチ ソリューションの比率を 10% 以上に押し上げました。これまでの大規模モデルはすべて数パーセントの範囲にありましたが、10% に押し上げると、すでに Devin のパフォーマンスに近づいています。私たちは、この分野の学術研究は非常に早く進む可能性があると判断しました。
大胆に推測してみましょう。2024 年半ば頃の 6 月から 9 月にかけて、SWE ベンチの解決率は 30% を超える可能性が高くなります。大胆に推測してみましょう。50 ~ 60 パーセントの解決率を達成できれば、そのテスト セットは実際に Github の問題を解決し、バグを修正して、そのようなニーズを解決できるでしょう。このテストセットでAIの自律完了率が50~60%に達すれば、本当に本番レベルで実装できると考えています。少なくともいくつかの単純な欠陥はこれによって修正できます。これは、業界で私たちが見てきた最新の開発の一部です。
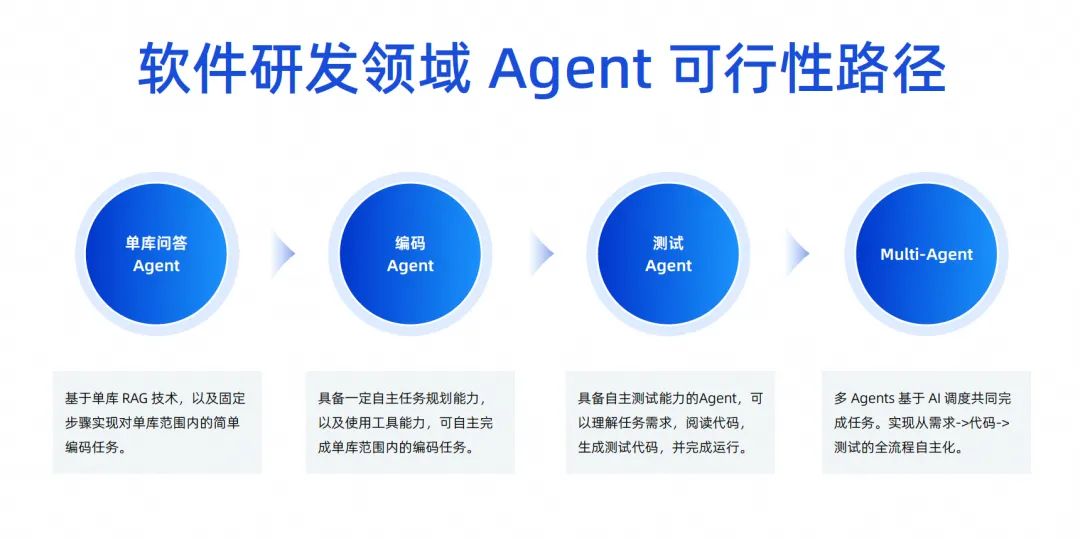
ただし、このイメージは技術的な観点からすぐに実現できるものではなく、次の 4 つのステップで段階的に実現していきます。
最初のステップでは、現在、単一データベースの Q&A エージェントの開発に取り組んでいます。この分野は非常に最先端の作業であり、近い将来にオンラインになる予定です。
次のステップでは、コーディング タスクを独立して完了できるエージェントを起動したいと考えています。その主な役割は、いくつかのツールを使用して背景知識を理解し、単一の内部でコーディング タスクを独立して完了できることです。ライブラリ間ではなく、要件が複数のコードベースを持ち、フロントエンドも変更され、バックエンドも変更されて、最終的に要件が形成されるのはまだ遠いと感じます。 。
したがって、最初に単一ライブラリのコーディング エージェントを実装し、次にテスト エージェントを実行します。テスト エージェントは、コーディング エージェントの生成された結果に基づいて、タスクの要件の理解やドキュメントの読み取りなど、いくつかのテスト タスクを自動的に完了できます。コードを作成し、テスト ケースを生成し、自律的に実行します。
これら 2 つのステップの成功率が比較的高い場合は、3 番目のステップに進みます。複数のエージェントが連携して AI スケジューリングに基づいてタスクを完了できるようにすることで、要件からコード、テストに至るプロセス全体の自律性を実現します。
エンジニアリングの観点から、各ステップがより良い生産レベルの実装に到達し、最終的に製品が生産されるように、段階的に進めていきます。しかし、学術的な観点から見ると、彼らの研究スピードは私たちよりも速いでしょう。現在、私たちは学術的および工学的な観点から議論しており、モデル進化という 3 番目の分野があります。これら 3 つのパスは、現在 Alibaba Cloud および Tongyi Lab と共同で行っている研究の一部です。
最終的には、マルチエージェントの概念アーキテクチャを形成し、ユーザーが大規模モデルと対話し、大規模モデルがタスクを分割できるようになり、マルチエージェントのコラボレーション システムが構築されます。このエージェントはいくつかのツールを接続でき、独自の実行環境を持つことができ、複数のエージェントが相互に連携でき、いくつかのコンテキスト メカニズムも共有します。
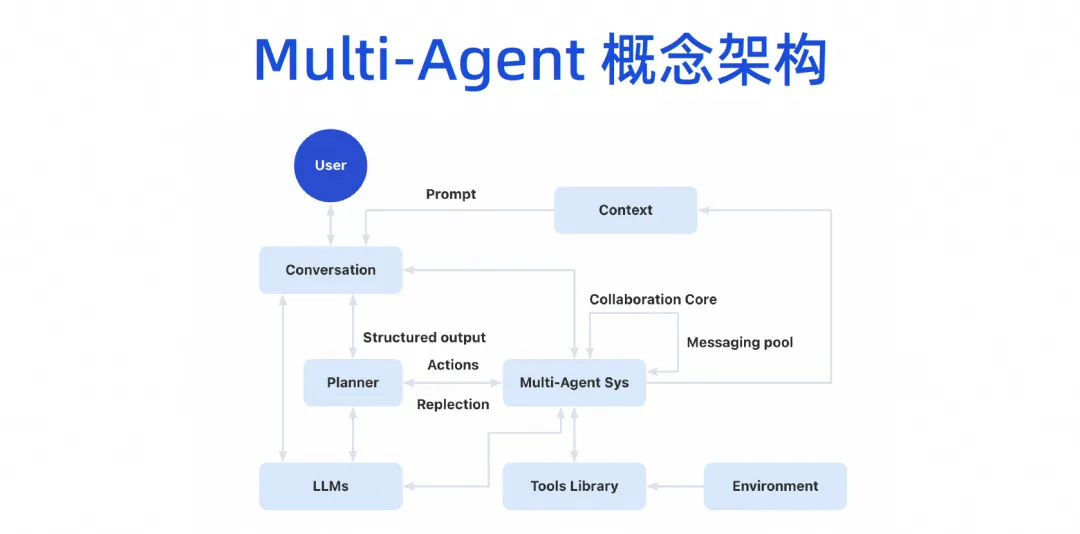
この商品画像は3つのレイヤーに分かれております。一番下は基本レイヤーです。企業の場合は、最初に基本レイヤーを完了できます。たとえば、AI Bot をすぐには実装していませんが、IDE コード生成プラグインの機能が備わっており、すでにいくつかの作業を実行できるようになりました (Copilot モデル)。
コパイロット モードは、インフラストラクチャ層の上にエージェント層を進化させます。実際、インフラストラクチャは再利用できます。実行すべき検索の強化、トレーニングおよび知識ベースの微調整は、今すぐ実行できます。この知識の整理と資産の蓄積は、独自のDevOpsプラットフォームの蓄積から生まれます。いくつかのプロンプト ワード プロジェクトを通じて、現在の基本機能レイヤーを DevOps ツール チェーン全体と組み合わせることができるようになりました。
要件の段階でいくつかの実験を行いましたが、この大規模なモデルで要件の自動分解を実現したい場合は、過去のいくつかの逆アセンブリ データと現在の要件を大規模なモデルのプロンプトに組み合わせるだけで済みます。そして人員の割り当ても改善されました。実験では、結果の精度が非常に高いことがわかりました。
実際、DevOps ツール チェーン全体で、すべてにエージェントやコパイロットが必要なわけではありません。現在、いくつかのプロンプト ワード プロジェクトを使用しています。CICD プロセスでの自動デバッグ、ナレッジ ベース分野でのインテリジェントな質疑応答など、すぐに活用できるシナリオが多数あります。
複数のエージェントを実装した後、エージェントは IDE、開発者ポータル、DevOps プラットフォーム、さらには IM ツールで公開できます。それは実際には擬人化された知性です。エージェント自体には独自のワークスペースがあり、開発者やマネージャーは、エージェントがコードの作成にどのように役立つか、テストの完了にどのように役立つか、インターネット上でどのような種類の知識が取得されるかを監視できます。作業が完了すると、独自の作業スペースが確保され、最終的にはタスク全体の完全なプロセスが実現されます。
トンイリンマを体験するにはここをクリックしてください。
Google Python Foundation チームが解雇されたことを Google が確認し、Flutter、Dart、Python に関与するチームが GitHub のホット リストに殺到しました - オープンソースのプログラミング言語とフレームワークはどうしてこんなにも魅力的なのでしょうか? Xshell 8 が ベータ テストを開始: RDP プロトコルをサポートし、Windows 10/11 にリモート接続 できる Rail WiFi の最初の長期サポート バージョン 8.4 GA AI 検索ツール Perplexica : 完全にオープンソースで無料、Perplexity の代替となるオープンソースの価値をファーウェイ幹部が評価 : 継続的な抑制にもかかわらず、依然として独自のオペレーティング システムを持っています。ドイツの自動車ソフトウェア会社 Elektrobit が、Ubuntu をベースとした自動車オペレーティング システム ソリューションをオープンソース化しました。