
共有者: Zeng Qingguo |学校名: 南方科技大学
簡単な紹介
ムーアの法則の減速により、組み合わせ最適化問題を解決するために特別に設計されたカスタマイズされたイジング マシンなど、非伝統的なコンピューティング パラダイムの開発が促進されました。このセッションでは、確率論と古典の混合コンピューティング環境で、スパース、非同期、高度に並列化されたイジング マシンを使用してディープ ボルツマン ネットワークをトレーニングする、ディープ生成ニューラル ネットワークをトレーニングするための P ビット ベースのイジング マシンの新しいアプリケーションを紹介します。
関連論文
标题:スパース・イジング・マシンによるディープ・ボルツマン・ネットワークのトレーニング
作宇:**Shaila Niazi、Navid Anjum Aadit、Masoud Mohseni、Shuvro Chowdhury、Yao Qin、Kerem Y. Camsari
01
記事の目的
目標:特殊なハードウェア システム (P ビットなど) を使用して、ディープ ボルツマン ネットワークのスパース バージョンを効率的にトレーニングする方法を実証します。これにより、計算上のハード確率サンプリング タスクで一般的に使用されるソフトウェア実装よりも大幅に高速化されます。
長期的な目標:物理学にインスピレーションを得た確率的ハードウェアの開発を促進し、グラフィックスおよびテンソル プロセッシング ユニット (GPU/TPU) に基づく従来のディープ ラーニングの急速に増大するコストを削減します。
ハードウェア実装の難しさ:
1. 接続された p ビットはシリアルに更新する必要があり、高密度システムでは更新が禁止されます。
2. 更新する前に、p ビットが隣接ノードからすべての最新情報を受信していることを確認します。そうしないと、ネットワークが停止します。真のボルツマン分布からのサンプリング。
02
メインコンテンツ
スパースイジングマシンを用いたディープボルツマンネットワークの学習内容は主に4つのパートに分かれています:
1. ネットワーク構造
2. 目的関数
3. パラメータの最適化
4. 推論(分類と画像生成)
1. ネットワーク構造
D-Wave によって開発された Pegasus および Zepyhr トポロジは、ハードウェア対応のスパース ディープ ネットワークをトレーニングするために使用されます。この操作は、人間の脳や高度なマイクロプロセッサなど、拡張されているが接続に制約のあるネットワークからインスピレーションを得ています。機械学習モデルでは完全な接続性が遍在的に使用されているにもかかわらず、高度なマイクロプロセッサと数十億のトランジスタ ネットワークを備えた人間の脳は、両方ともかなりの程度の疎性を示しています。実際、RBM のほとんどのハードウェア実装は、各ノードに必要な高い計算責任によりスケーリングの問題に直面していますが、ハードウェア ニューラル ネットワークの疎な接続には利点が見られることがよくあります。さらに、疎なネットワーク構造は、前述のハードウェア実装の問題をうまく解決します。
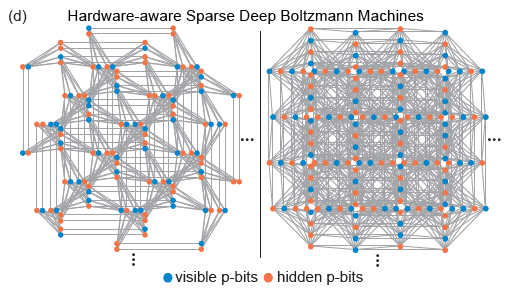
(画像ソース: arXiv:2303.10728)
2. 目的関数
尤度関数を最大化することは、データ分布とモデル分布の間の KL 発散を最小化することと同じです。
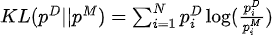
その中には データ分布と
データ分布と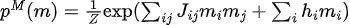 モデル分布があります。
モデル分布があります。
モデルパラメータに対する KL 発散の勾配 ( 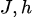 ) は次のとおりです。
) は次のとおりです。
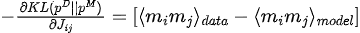
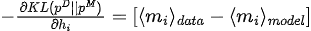
3. パラメータの最適化

(画像ソース: arXiv:2303.10728)
アルゴリズム 1 に従ってネットワーク パラメーターをトレーニングします。
-
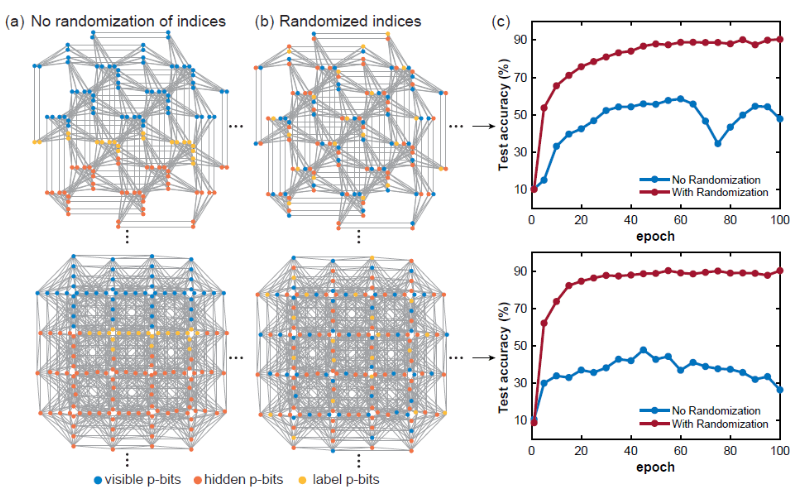
初期化パラメータ (
 、 )
、 )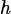 の初期化。
の初期化。 -
トレーニング データを使用して入力層 p ビットに値を割り当て、MC サンプリングを実行してデータ分布のサンプリング サンプルを取得します。
-
MC サンプリングを直接実行して、モデル分布のサンプリング サンプルを取得します。
-
勾配 (持続的コントラスト発散と呼ばれる) は 2 段階でサンプリングされたサンプルを使用して推定され、パラメーターは勾配降下法を使用して更新されます。
その中で、MC サンプリングは p ビットの反復進化を使用します。

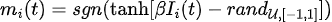
スパース ボルツマン ネットワークを学習させるプロセスでは、次の 2 つの点に注意する必要があります。
-
1) ランダム化された p ビット インデックス
特定の疎ネットワーク上でボルツマン ネットワーク モデルをトレーニングする場合、可視ノード、非表示ノード、およびラベル ノード間のグラフの距離は非常に重要な概念です。通常、層が完全に接続されている場合、特定の 2 つのノード間のグラフの距離は一定ですが、スパース グラフの場合はそうではないため、表示される p ビット、非表示の p ビット、およびラベルの p ビットの位置が非常に重要になります。可視、非表示、およびラベルの p ビットがクラスター化され、近すぎる場合、分類の精度が大きく影響されます。これは、ラベル ビットと可視ビットの間のグラフィック距離が大きすぎると、それらの間の相関が弱くなるためであると考えられます。 p ビット インデックスをランダム化すると、この問題を軽減できます。 -
-
(画像ソース: arXiv:2303.10728)
**2)大规模并行**
在稀疏深度玻尔兹曼网络上,我们使用启发式图着色算法DSatur对图着色,对于未连接p-bits进行并行更新。
-
-
(画像ソース: arXiv:2303.10728)
4. 推論
分類:テスト データを使用して可視 p ビットを修正し、MC サンプリングを実行して、取得したラベル p ビットの期待値を取得し、最大の期待値を持つラベルを予測ラベルとして取得します。
-
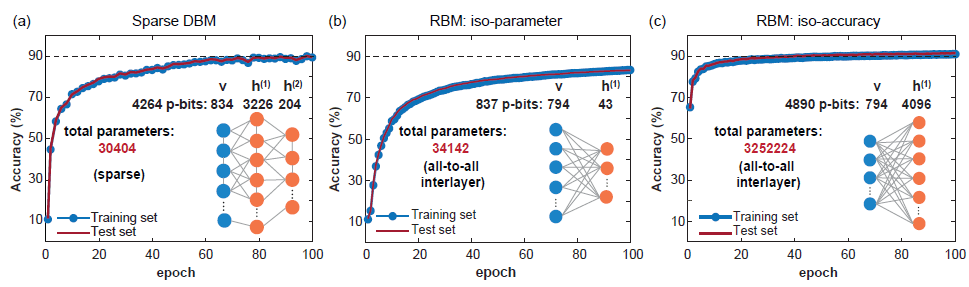
-
(画像ソース: arXiv:2303.10728)
画像生成:生成するラベルに対応するエンコーディングにラベル p ビットを固定し、MC サンプリングを実行し、サンプリング プロセス中にネットワークをアニーリングします (0.125 ステップで 0 から 5 まで徐々に増加します)。サンプルは に対応します。 目に見える p ビットは、生成されたイメージです。
-

-
(画像ソース: arXiv:2303.10728)
03
要約する
この記事では、超並列アーキテクチャを備えたスパース イジング マシンを使用しており、従来の CPU よりも桁違いに速いサンプリング速度を実現しています。この論文では、ハードウェア対応ネットワーク トポロジの混合時間を体系的に研究し、モデルの分類精度がアルゴリズムの計算操作性によって制限されるのではなく、この研究で使用できた適度なサイズの FPGA によって制限されることを示しています。さらなる改善には、超高速の確率的サンプラーを最大限に活用する、より深く、より広範囲で、場合によっては「混合が難しい」ネットワーク アーキテクチャの使用が含まれる可能性があります。さらに、従来の DBM のレイヤーごとのトレーニング テクノロジとこの記事の方法を組み合わせることで、さらなる改善がもたらされる可能性があります。ランダム磁気トンネル接合などのナノスケールデバイスを使用したスパースイジングマシンの実装は、深いボルツマンネットワークの実用化の現状を変える可能性があります。
1990 年代生まれのプログラマーがビデオ移植ソフトウェアを開発し、1 年足らずで 700 万以上の利益を上げました。結末は非常に罰的でした。 Google は、Flutter、Dart、Python チームの中国人プログラマーの「35 歳の呪い」に関係する人員削減を認めた 。Microsoft は 、 無力な中年者にとっては幸運なおもちゃでもある。強力で GPT-4.5 の疑いがある; Tongyi Qianwen オープンソース 8 モデルWindows 1.0 が 3 か月以内に正式に GA Windows 10 の市場シェアは 70% に達し、Windows 11 GitHub がAI ネイティブ開発ツール GitHub Copilot Workspace JAVAをリリースOLTP+OLAP を処理できる唯一の強力なクエリです。これが最高の ORM です。