
著者:Lu Yufeng 出典:Zhihu
まとめ
MindNLP の開発には約 1 年がかかり、全体として多くの問題に直面しており、LLM によってもたらされる一連の影響と課題も伴います。 MindSpore に依存して上向きの成長を遂げている後発の NLP フレームワークとして、実際にはそのエコシステムを拡張する方法を検討する必要があります。
格言にあるように、勝てないなら参加しましょう。しかし、オープンソースの世界では、参加について話す必要はありません。私とあなたが私の一部であることは正常です。さらに、2 日前に Pytorch2.1+Ascend が正式に発表された時点では、生態学的接ぎ木は間違いなく最良の解決策です。噂話はこれくらいにして、本題に入りましょう。
01
MindNLP データセット
MindNLP の設計の最初から、関数融合プログラミング、動的グラフ関数、データ処理エンジンなどを含む MindSpore のすべての利点と機能を最大限に活用したいと考えています。ここではデータ処理エンジンを取り出して詳しく説明します。
1.1MindSpore データ処理エンジン
図 1: MindSpore データ エンジン パイプラインの概略図
図に示すように、データ エンジンの設計はパイプライン [1] であり、Tensorflow のデータセットや Pytorch のマップスタイル データセットに非常に似ており、主に高性能データ処理を目的としています。
誰もがまだランキングを更新するために小さなモデルの変更や小さなデータセットを行っている時代では、データの前処理は通常オフラインで行われるため、Python を使用して可能な限り柔軟に処理でき、通常はサーバーの大容量メモリを使用できます。誰もがすべてのデータを一度に詰め込み、それを処理するために複数のプロセスを開きます。その後、それを Tensor にロードし、トレーニングのためにネットワークに送信します。ただし、それでも、データ セットが少し大きい場合は、データ セットの前処理に数時間、場合によっては数日かかる場合があります。
パイプライン方式は、次のいくつかの機能に焦点を当てています。
1. ロードオンデマンド
2. 非同期処理
3. パラレル
このうち 1 と 2 について詳しく説明します。テキスト データを例に挙げると、最も単純な Python 読み込み前処理ロジック (つまり、Pytorch Dataloader) が使用される場合、全体的な実行フローは次のようになります。
数据集全量加载至内存 -> 全量遍历并预处理 -> 单条数据打包Batch -> 循环返回每个Batch
Pipelineの読み込み方法は
より鮮明な説明は次のとおりです。データ セット ファイルの先頭を指すポインタがあり、毎回バッチ サイズのデータをフェッチし、フェッチされるまでポインタはバッチ サイズだけ進みます。
明らかに、毎回適切な量のデータのみをフェッチすることでメモリ消費量を大幅に削減でき、前処理プロセス中に生成される中間変数も小さいサイズに圧縮できます。さらに、この方法では、オフラインのデータ前処理をオンラインに変換できます。
取Batch size条数据加载 -> Batch size条数据遍历并预处理 -> 返回一个Batch
図 2: データ処理とネットワーク コンピューティングのパイプライン
データ処理パイプラインは継続的にデータを処理し、処理されたデータをデバイス側のキャッシュに送信します。ステップの実行後、次のステップのデータがデバイスのキャッシュから直接読み取られます。ネットワークがトレーニングしている間、データも処理され、それぞれが独自の役割を果たします。
もちろん、この方法はメモリ使用率とパフォーマンスを向上させる一方で、使いやすさの問題も引き起こす諸刃の剣でもあります。図 1 のマップは非同期処理であり、各データの前処理操作を構成した後、直接実行して結果を返しません。これは、細かい制御が必要で特殊な条件が多いデータには適しておらず、パイプライン実行が発生する可能性が高くなります。 . 突然異常が発生する。
しかし、LLM はこの状況を変えました。すべてのタスクが Next Token Prediction になり、データ処理もすべてクリーニング + Tokenize になりました。ビジネス シナリオでは、多くの場合、パイプラインが最適なソリューションになります。おそらくこれが、Pytorch がパイプラインを実行し始めた主な理由であり、HuggingFace データセットもパイプラインです)。
1.2MindNLP データセットのサポートの問題
前述したように、MindNLP のデータ処理は MindSpore データ処理エンジンを完全に使用しており、1 年間で 20 以上のデータ セットをサポートしています (torchtext によるベンチマーク)。しかし、実際の使用では、さまざまな NLP タスクがこれら以上のデータ セットを必要とすることは明らかであり、オープン ドメインに継続的に適応することは困難です。
さらに、Shengsi MindSpore のデータセットもいくつかの問題を引き起こしています。主な問題は、MindSpore データセットが次の 3 種類のローダーを設計していることです。
1. 特定のデータセットローダー: IMDBDataset、EnWik9Dataset など。
2. テキスト抽象ローダー: TextFileDataset
3. ユーザー定義ローダー: GeneratorDataset
1 を使用すると、継続的に適応を追加する必要があることを意味します。2 を使用すると、ロードする前に xml や json などの形式を前処理する必要があります。これは、Pipeline の高効率設計コンセプトに反します。 3 を使用した開発量は、依然として手動での調整の必要性に直面しています。これは、図 1 の最初のステップがフルロードに戻ることを意味しますが、これは明らかに私たちが望んでいることではありません。ただし、データ セットを迅速にサポートする必要があるため、サポートには引き続き 1+3 方式を選択しました。
これは効率的ではなく、毎回個別に調整する必要があります。それでは、恒久的な解決策はあるのでしょうか?
02
ハグフェイス生態移植
MindNLP のデータ セットの読み込みでは、次の 2 つのことだけを達成したいと考えています。
1. 調整なしで大規模なデータセットをサポート
2. 効率的なパイプラインを使用する
自分ではどうすることもできないので、エコの力に頼りましょう。 Transformers ウェアハウスに加えて、HuggingFace は AI トレーニングのさまざまなプロセス用のライブラリを開発しており、データセットは数年間蓄積されており、多数のデータ セットをサポートしています。また、HuggingFace はホスティング サービスを提供しているため、多くの新しいデータ セットも直接保存されています。データセットハブで直接公開します。データセットを使用して問題 1 を解決したら、2 番目の問題を見てみましょう。
実際、MindSpore Dataset を使用するほとんどの人は、基本的に次の 2 つの処理方法を選択します。
1. MindRecord へのオフライン前処理、その後 MindDataset を使用したロード
2. データ セットをメモリにロードし、特定のデータ セット ローダー/GeneratorDataset を使用してロードします。
オンラインで前処理を行うためには、方法 1 は明らかに推奨されません。そのため、HuggingFace データセットをグラフトするというアイデアも非常に単純です。以下でそれらについて説明します。
2.1接ぎ木データセットのダウンロード
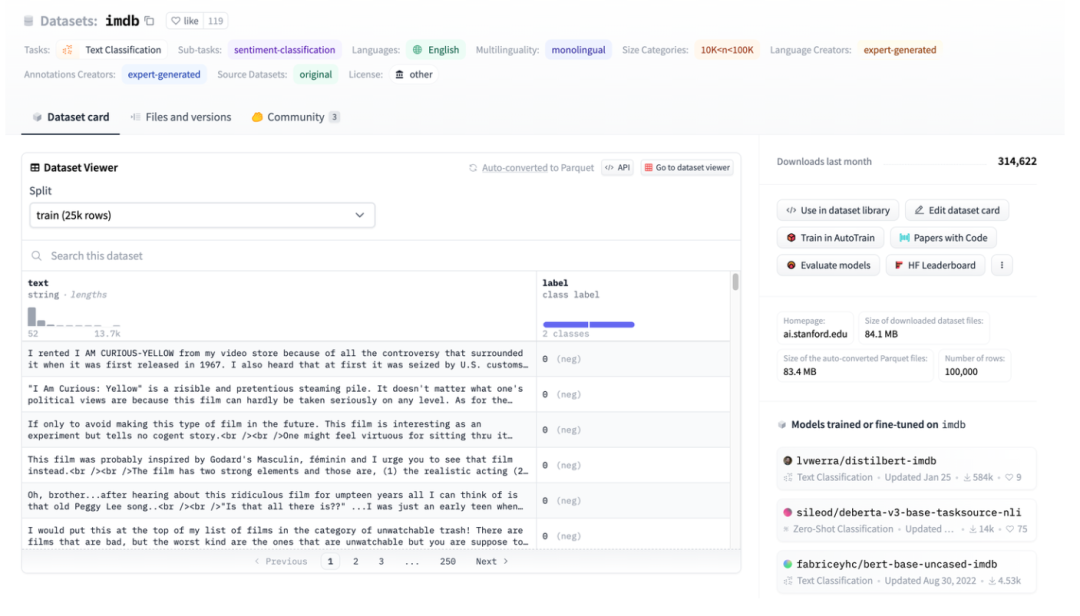 図 3: IMDB を例にした HuggingFace データセットの図
図 3: IMDB を例にした HuggingFace データセットの図
図 3 は、imdb ページのスクリーンショットです。次に、HuggingFace Datasets を使用して直接ダウンロードし、処理されたファイルを直接読み取ります。
図 4: TextFileDataset インターフェイス
TextFileDataset は、ロードするファイル パスまたはパス リストを渡すだけでよいことがわかります。しかし、実際の操作中に問題が発生しました。HuggingFace データセットは Apache Arrow ファイルを使用しています。
図 5: HuggingFace データセットの Arrow 形式の概要
Apache Arrow [2] は、言語に依存せず、ゼロコピー可能なマルチシステムの高性能データ交換フォーマット標準です。これは、MindSpore のデータセットを直接簡単に読み取ることができないことを意味しますが、pyarrow ライブラリを使用して操作することもできますが、複雑さが増し、ロードする前に前処理が必要な状態に戻ります。ただし、Arrow ファイルの特性は MindSpore のデータセットにより適していることがわかりました。
2.2アロー形式のメリット
マルチウォーカー環境では、二足歩行ロボットは荷物を運んで右に歩こうとします。下の写真に示すように、複数のロボットが大きな荷物を運び、連携して作業する必要があります。
HuggingFace は Apache Arrow 形式を使用します。これには、いくつかの明らかな利点があります。
1. Arrow の標準形式ではゼロコピー読み取りが可能であり、事実上すべてのシリアル化オーバーヘッドが排除されます。
2. Arrow は列指向であるため、データ スライスまたはデータ列のクエリと処理が高速になります。
3. Arrow は、各データ セットをメモリ マップされたファイルとして扱います。大きなファイル内の部分データにアクセスする場合、ファイル全体をロードする必要はなく、複数のプロセスがメモリを共有できます。メモリ マッピングを使用すると、比較的小さいデバイス メモリを搭載したマシンで大規模なデータセットを使用できます。完全な英語版 Wikipedia データセットのロードに必要な RAM はわずか数 MB です。
4. データをロードするときに、ストリーミング ロードのストリーミング パラメータを設定できます。
ここで、MindSpore データ エンジンの設計に戻って見てみましょう。オンデマンドの読み込み、オンライン処理、および HuggingFace データセットが完全に一致しています。
2.3 MindNLP の適応
HuggingFace Datasets によってロードされる矢印ファイル自体はメモリ マップト ファイルであるため、メモリにコピーする必要はなく、インデックスインデックスを使用しても完全にはロードされないため、データをロードするソースとして直接使用して送信できます。 GeneratorDataset に直接アクセスして使用します。
図 6: GeneratorDataset インターフェイス
GeneratorDataset の構築には主にソース データと、データの各列に対応する列名が必要です。図 3 を見ると、HuggingFace Datasets がすべての列に名前を付けていることがわかります。以下はインターセプトされたコア コードです。
from mindspore.dataset import GeneratorDataset
from datasets import load_dataset as hf_load
......
def load_dataset(...):
ds_ret = hf_load(path,
name=name,
data_dir=data_dir,
data_files=data_files,
split=split,
cache_dir=cache_dir,
features=features,
download_config=download_config,
download_mode=download_mode,
verification_mode=verification_mode,
keep_in_memory=keep_in_memory,
save_infos=save_infos,
revision=revision,
streaming=streaming,
num_proc=num_proc,
storage_options=storage_options,
)
if isinstance(ds_ret, (list, tuple)):
ds_dict = dict(zip(split, ds_ret))
else:
ds_dict = ds_ret
datasets_dict = {}
for key, raw_ds in ds_dict.items():
column_names = list(raw_ds.features.keys())
source = TransferDataset(raw_ds, column_names) if isinstance(raw_ds, Dataset) \
else TransferIterableDataset(raw_ds, column_names)
ms_ds = GeneratorDataset(
source=source,
column_names=column_names,
shuffle=shuffle,
num_parallel_workers=num_proc if num_proc else 1)
datasets_dict[key] = ms_ds
if len(datasets_dict) == 1:
return datasets_dict.popitem()[1]
return datasets_dict
処理手順も非常に簡単です。
1.HuggingFace Datasetsのload_datasetを使用して読み込みます
2. カプセル化にはカプセル化された通過クラスを使用する
3. GeneratorDataset を渡す
使いやすさを考慮して、load_dataset インターフェイスのパラメータ設定は HuggingFace データセットとまったく同じにしますが、返されるのは MindSpore データ エンジンで処理できるクラスまたは辞書です。 Shengsi MindSpore のデータ処理機能を完成させることができます。
トランジットクラスの構造について簡単に説明しましょう。
HuggingFace データセットのデータ型には、Dataset と IterableDataset が含まれます。
データセット オブジェクトには、Dataset と IterableDataset の 2 種類があります。どのタイプのデータセットを使用または作成するかは、データセットのサイズによって異なります。一般に、IterableDataset は遅延動作と速度の利点があるため、大規模なデータセット (数百 GB を考えてください!) に最適ですが、Dataset はその他すべてに最適です。このページでは、適切なデータセット オブジェクトを選択できるように、Dataset と IterableDataset の違いを比較します。[3]
これら 2 種類のデータ セットを走査すると、MindSpore のデータ処理エンジンではサポートされていない dict が返されます。そのため、他の追加の操作を追加せずに dict 内のデータを読み取るために 2 つの転送クラスが作成されます。 Dataset の場合、TransferDataset クラスを構築し、__getitem__ メソッドで読み取ります。
class TransferDataset():
"""TransferDataset for Huggingface Dataset."""
def __init__(self, arrow_ds, column_names):
self.ds = arrow_ds
self.column_names = column_names
def __getitem__(self, index):
return tuple(self.ds[int(index)][name] for name in self.column_names)
def __len__(self):
return self.ds.dataset_size
ストリーミング データ IterableDataset の場合は、それを __iter__ メソッドで読み取り、反復可能オブジェクトとして TransferIterableDataset を構築する必要があります。
class TransferIterableDataset():
"""TransferIterableDataset for Huggingface IterableDataset."""
def __init__(self, arrow_ds, column_names):
self.ds = arrow_ds
self.column_names = column_names
def __iter__(self):
for data in self.ds:
yield tuple(data[name] for name in self.column_names)
この時点で、ほとんど労力を必要とせず、HuggingFace データセットを完全に移植できる計画が完成しました。Paddle NLPと比較すると、グラフト戦略はシンプルで洗練されています。
03
結論は
オープンソース フレームワークとして、実際には使用できるオープンソース リソースが多数あります。いわゆる南北エコシステムの継続的な拡大は、必ずしも私がそれを使用し、あなたがそれを使用し、あなたが私を使用することを意味するものではありません。 、あなたは幸せで心配がありません。今回、HuggingFace Datasets は Shengsi MindSpore の実践的な共有に移植され、これにより Shengsi MindNLP についてのより深い理解が得られ、Shengsi MindSpore エコシステムの拡大にも役立ちます。
参考文献
[1] https://www.mindspore.cn/docs/zh-CN/r2.1/design/data_engine.htm
[3] https://huggingface.co/docs/datasets/about_mapstyle_vs_iterable
1990 年代生まれのプログラマーがビデオ移植ソフトウェアを開発し、1 年足らずで 700 万以上の利益を上げました。結末は非常に懲罰的でした。 Google は、Flutter、Dart、Python チームの中国人プログラマーの「35 歳の呪い」に関係する人員削減を認めた 。Microsoft は 、 無力な中年者にとっては幸運なおもちゃでもある。強力で GPT-4.5 の疑いがある; Tongyi Qianwen オープンソース 8 モデルWindows 1.0 が 3 か月以内に正式に GA Windows 10 の市場シェアは 70% に達し、Windows 11 GitHub がAI ネイティブ開発ツール GitHub Copilot Workspace JAVAをリリースOLTP+OLAP を処理できる唯一の強力なクエリです。これが最高の ORM です。