
著者: vivo インターネットビッグデータチームの Ye Jidong
この記事では主に、FileSystem クラスによるオンライン メモリ リークによるメモリ オーバーフローの問題を分析および解決する全体のプロセスを紹介します。
メモリ リークの定義: プログラムで使用されなくなったオブジェクトまたは変数が依然としてメモリ内の記憶領域を占有しており、JVM は変更されたオブジェクトまたは変数を適切に再利用できません。単一のメモリ リークは大きな影響を与えないように見えますが、メモリ リークが蓄積するとメモリ オーバーフローが発生します。
メモリ オーバーフロー (メモリ不足) : 割り当てられたメモリ領域の不足またはプログラムの実行中の不適切な使用により、プログラムの実行を続行できないエラーを指します。このとき、OOM エラーが報告されます。いわゆるメモリオーバーフロー。
1. 背景
Xiaoye は週末にキャニオン オブ キングスで人々を殺害していましたが、彼の携帯電話は突然、CPU 使用率が 80% を超えると大量の CPU アラームを受信しました。同時に、フル GC アラームも受信しました。サービスのために。このサービスは、Xiaoye プロジェクト チームにとって非常に重要なサービスです。Xiaoye はすぐに Honor of Kings を置き、問題を確認するためにコンピューターの電源を入れました。


図1.1 CPUアラーム フルGCアラーム
2. 問題の発見
2.1 監視と表示
サービス CPU とフル GC がアラームを発しているため、サービス モニタリングを開いて CPU モニタリングとフル GC モニタリングを表示すると、CPU アラームが発生したときに両方のモニターに異常なバルジがあることがわかります。特にFull GCが頻繁に発生するため、 CPU 使用率増加アラームはFull GCが原因であると推測されます。
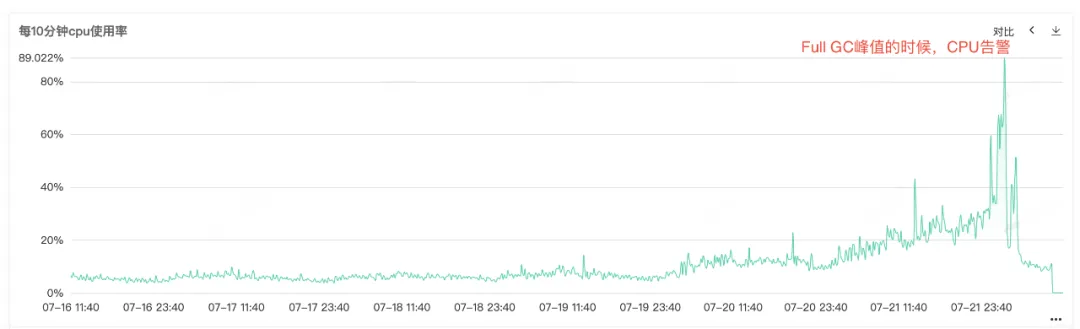
図 2.1 CPU 使用率
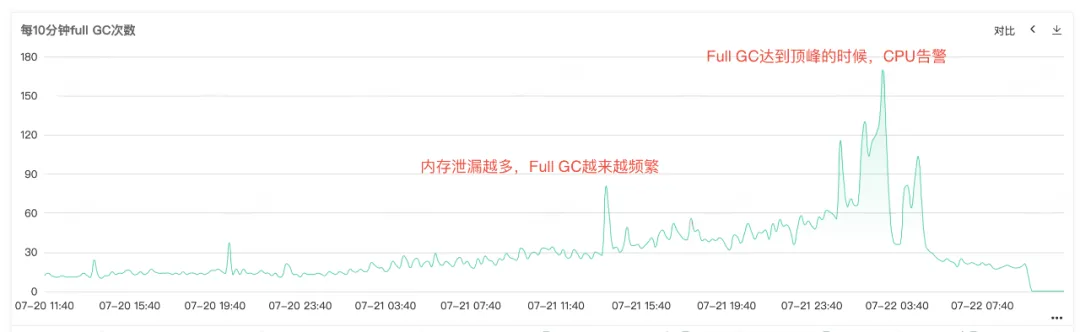
図 2.2 フル GC 時間
2.2 メモリリーク
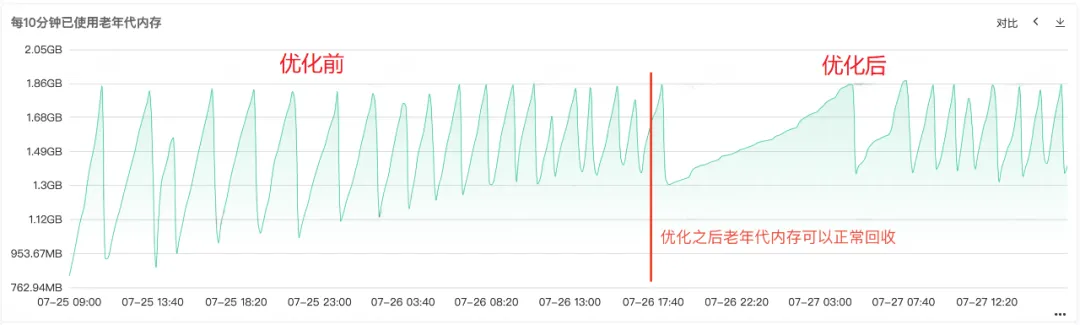
Full Gc が頻繁に発生することから、サービスのメモリの再利用に問題があることがわかります。そのため、サービスの常駐メモリ図から、ヒープ メモリ、古い世代のメモリ、および若い世代のメモリの監視を確認します。古い世代では、古い世代の常駐メモリがますます大きくなり、再利用できないオブジェクトが増え、最終的にすべての常駐メモリが占有され、明らかなメモリ リークが見られます。 。
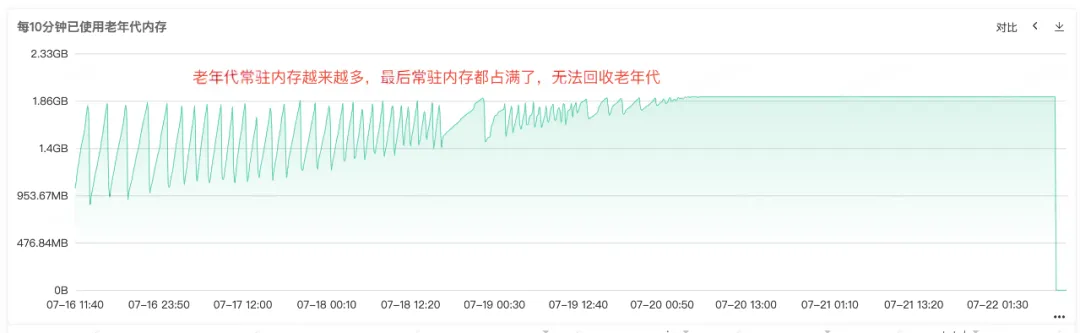
図 2.3 旧世代メモリ
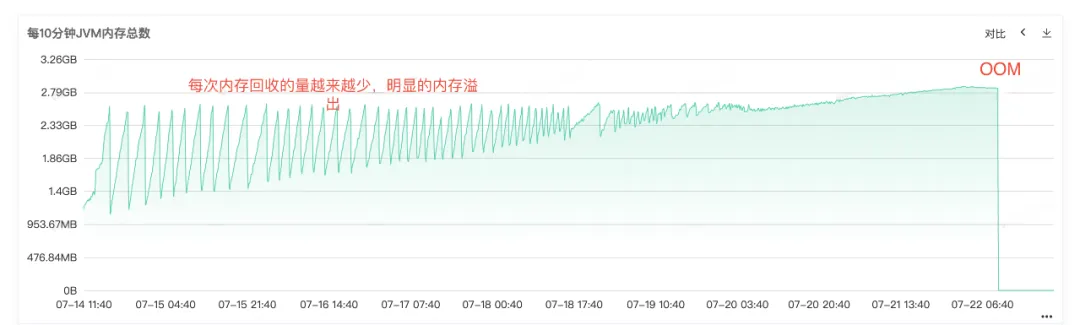
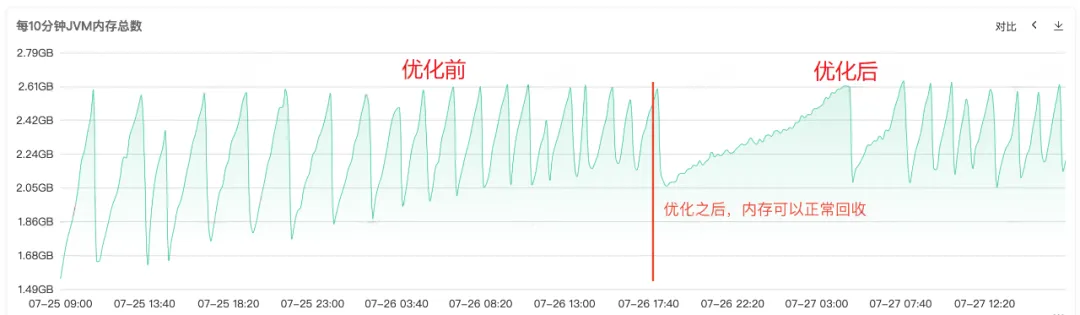
図 2.4 JVM メモリ
2.3 メモリオーバーフロー
オンライン エラー ログから、サービスが OOM になったことも明確にわかります。つまり、問題の根本的な原因は、メモリ リークによってメモリが OOM オーバーフローし、最終的にサービスが利用できなくなったことです。

図 2.5 OOM ログ
3. 問題のトラブルシューティング
3.1 ヒープメモリの解析
問題の原因がメモリ リークであることが判明した後、すぐにサービス メモリ スナップショットをダンプし、ダンプ ファイルを分析のために MAT (Eclipse Memory Analyzer) にインポートしました。リークの疑い リークの疑いのあるポイント ビューを入力します。
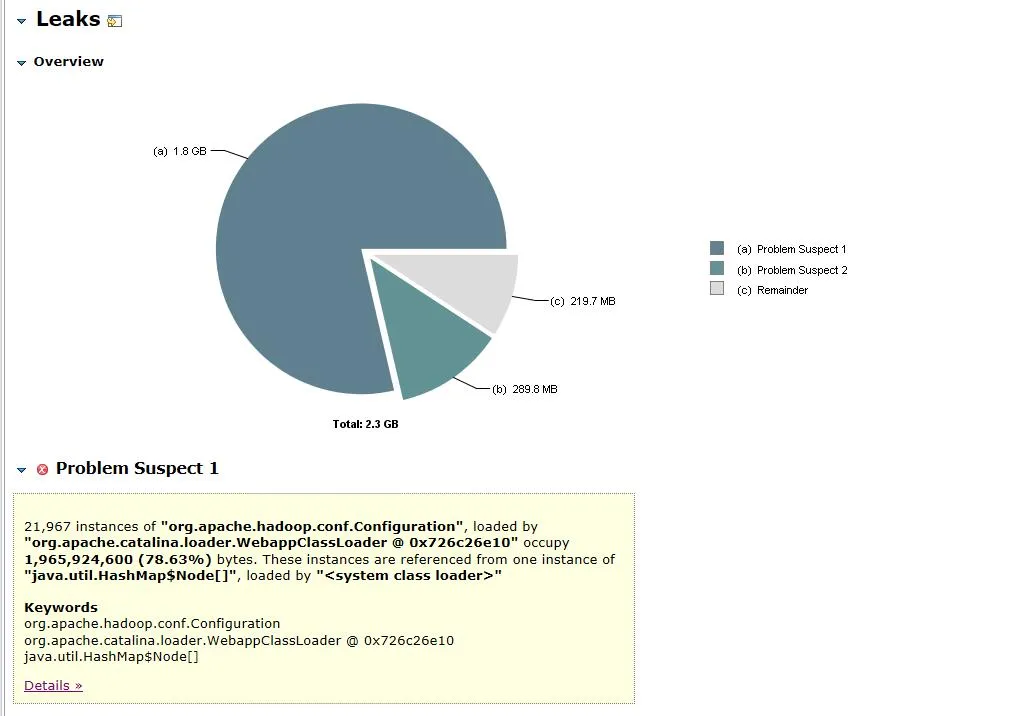
図 3.1 メモリオブジェクトの解析
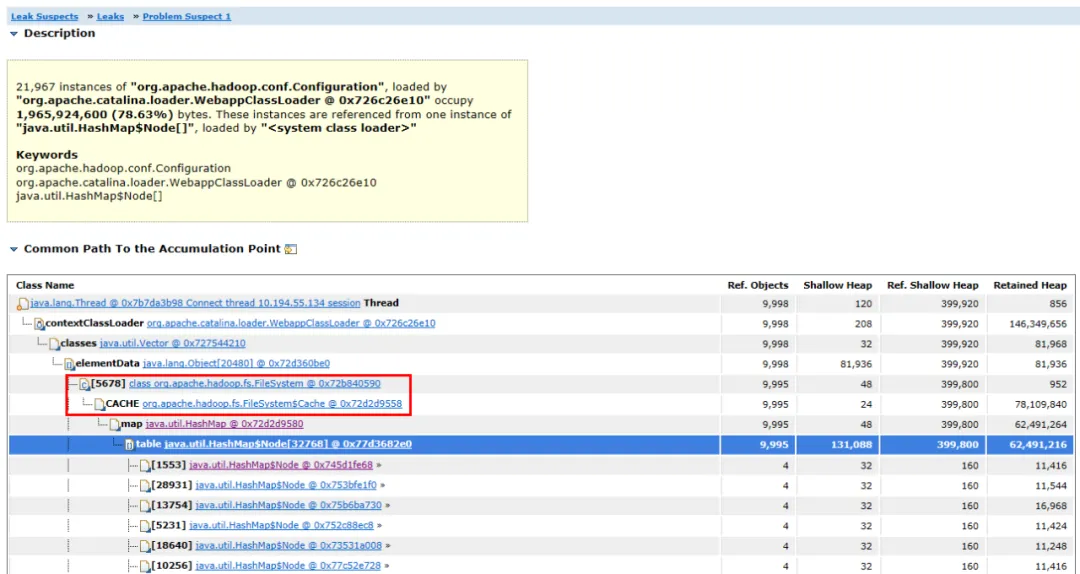
図 3.2 オブジェクトリンク図
開いたダンプ ファイルを図 3.1 に示します。 org.apache.hadoop.conf.Configuration オブジェクトは 2.3G ヒープ メモリのうち 1.8G を占め、ヒープ メモリ全体の 78.63% を占めます。
関連するオブジェクトとそのオブジェクトのパスを展開すると、主要なオブジェクトがHashMapであり、その HashMap がFileSystem.Cacheオブジェクトによって保持され、その上位層がFileSystemであることがわかります。メモリ リークはファイル システムに関連している可能性が高いと推測できます。
3.2 ソースコード解析
メモリ リーク オブジェクトを見つけたら、次のステップはメモリ リーク コードを見つけることです。
図 3.3 では、コード内にこのようなコードがあり、hdfs と対話するたびに、hdfs との接続が確立され、FileSystem オブジェクトが作成されます。しかし、FileSystem オブジェクトを使用した後、接続を解放するために close() メソッドが呼び出されませんでした。
ただし、ここでのConfigurationインスタンスとFileSystemインスタンスは両方ともローカル変数であり、メソッドの実行後、これら 2 つのオブジェクトは JVM によって再利用可能になるはずです。どのようにしてメモリ リークが発生するのでしょうか。
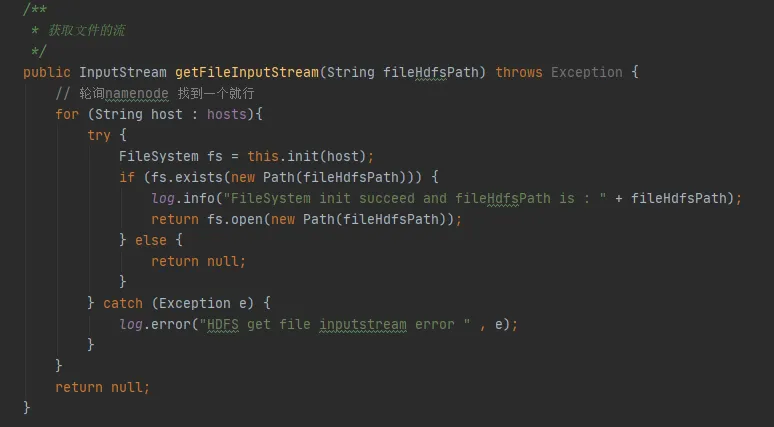
図 3.3
(1) 推測 1: FileSystem には定数オブジェクトがあるか?
次に、FileSystem クラスのソース コードを見ていきます。FileSystemのinit メソッドと getメソッドは次のとおりです。
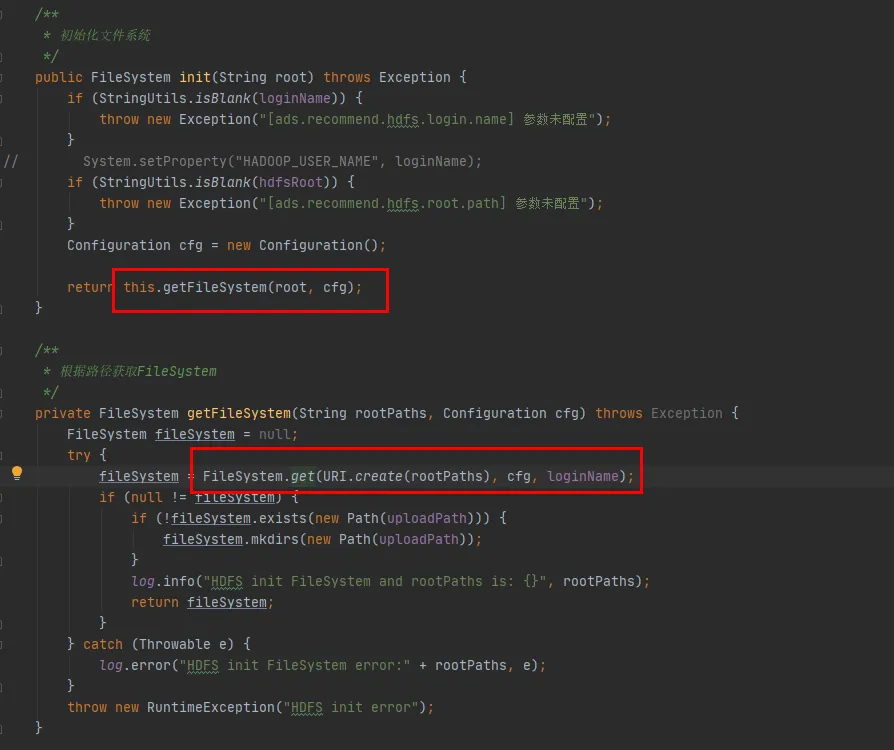

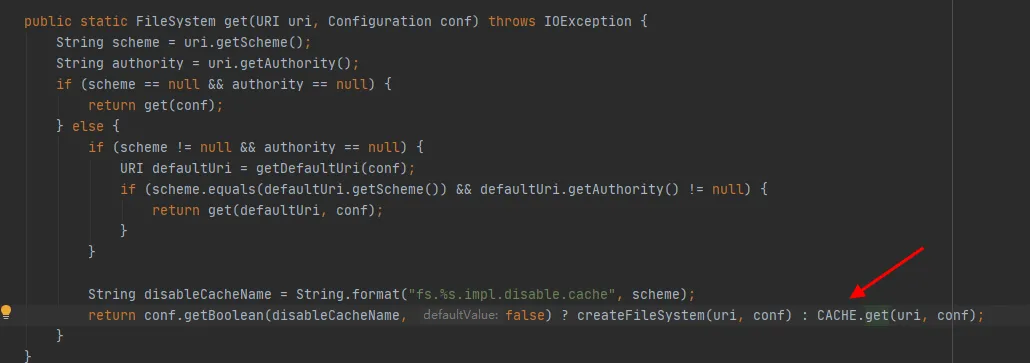
図 3.4
図 3.4 のコードの最後の行からわかるように、FileSystem クラスには CACHE があり、キャッシュからオブジェクトを取得するかどうかを制御するために disableCacheName が使用されます。このパラメータのデフォルト値は false です。つまり、 FileSystem はデフォルトで CACHE オブジェクトを通じて返されます。

図 3.5
図 3.5 から、CACHE は FileSystem クラスの静的オブジェクトであることがわかります。つまり、CACHE オブジェクトは常に存在し、再利用されません。定数オブジェクト CACHE は存在し、推測が検証されました。
次に、CACHE.get メソッドを見てみましょう。
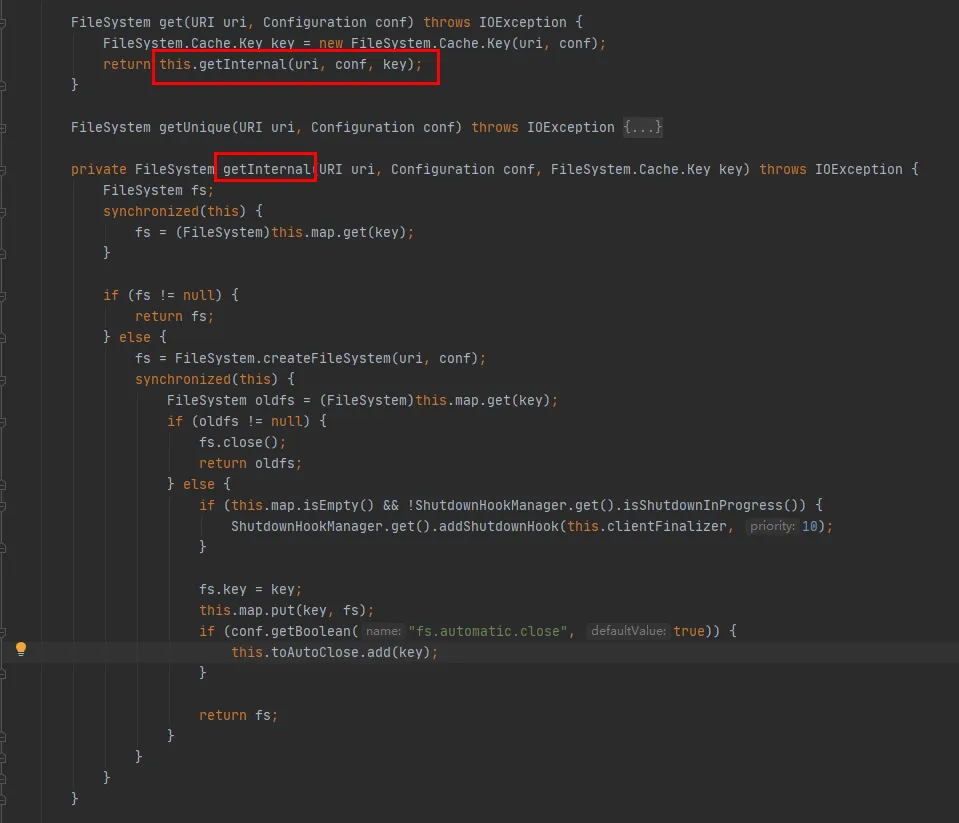
このコードからわかるように:
-
Map は Cache クラス内で維持され、接続された FileSystem オブジェクトをキャッシュするために使用されます。Map のキーは Cache.Key オブジェクトです。 FileSystem は毎回 Cache.Key を通じて取得されます。取得できない場合は、作成プロセスが続行されます。
-
Set (toAutoClose) は Cache クラス内で維持され、自動的に閉じる必要がある接続を保存するために使用されます。このコレクション内の接続は、クライアントが閉じると自動的に閉じられます。
-
作成された各 FileSystem は、Cache.Key をキー、FileSystem を値として Cache クラスの Map に保存されます。キャッシュ時に同じ hdfs URI に対して複数のキャッシュが存在するかどうかについては、Cache.Key の hashCode メソッドを確認する必要があります。
Cache.Key の hashCode メソッドは次のとおりです。

スキーマ変数と権限変数は String 型であり、同じ URI 内にある場合、そのハッシュコードは一貫しています。 unique パラメータの値は毎回 0 です。次に、 Cache.Key の hashCode はuge.hashCode()によって決定されます。
上記のコード分析から、次のことが整理できます。
-
ビジネス コードと HDFS の間の対話中に、対話ごとにFileSystem接続が作成され、最後に FileSystem 接続は閉じられません。
-
FileSystem には静的Cacheが組み込まれており、Cache 内には接続を作成した FileSystem をキャッシュする Map があります。
-
パラメータ fs.hdfs.impl.disable.cache は、FileSystem をキャッシュする必要があるかどうかを制御するために使用されます。デフォルトでは、これは false (キャッシュを意味します) です。
-
キャッシュ内のマップ、キーは Cache.Key クラスであり、上記の Cache.Key の hashCode メソッドで示したように、 scheme、authority、uge、および unique の 4 つのパラメーターを通じて Key を決定します。
(2) 推測 2: FileSystem は同じ hdfs URI を複数回キャッシュしますか?
FileSystem.Cache.Key コンストラクターは次のとおりです。 uge は UserGroupInformation の getCurrentUser() によって決定されます。

次のように、UserGroupInformation の getCurrentUser() メソッドを引き続き確認します。

重要なのは、AccessControlContext を通じて Subject オブジェクトを取得できるかどうかです。この例では、get(final URI uri、final Configuration conf、final String user) で取得すると、デバッグ中に毎回ここで新しい Subject オブジェクトが取得できることがわかります。つまり、同じ hdfs パスが毎回FileSystem オブジェクトをキャッシュします。
推測 2 が検証されました。同じ HDFS URI が複数回キャッシュされるため、キャッシュが急速に拡大し、キャッシュには有効期限と削除ポリシーが設定されず、最終的にメモリ オーバーフローが発生します。
(3) FileSystem が繰り返しキャッシュを行うのはなぜですか?
では、なぜ毎回新しい Subject オブジェクトを取得するのでしょうか。次のように、AccessControlContext を取得するコードを見てみましょう。
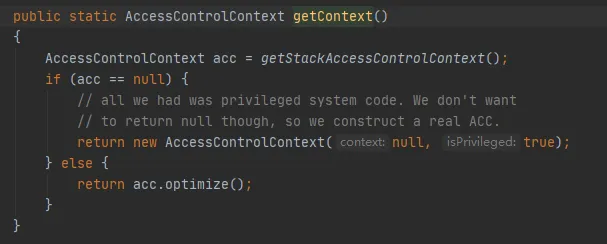
重要なメソッドは getStackAccessControlContext メソッドで、次のようにネイティブ メソッドを呼び出します。

このメソッドは、現在のスタックの保護ドメイン権限の AccessControlContext オブジェクトを返します。
次のように、図 3.6 の get(final URI uri,final Configuration conf,final String user) メソッドを通じてそれを確認できます。
-
まず、 UserGroupInformation.getBestUGIメソッドを通じてUserGroupInformationオブジェクトを取得します。
-
次に、 UserGroupInformationの doAs メソッドを通じてget(URI uri, Configuration conf) メソッドが呼び出されます。
-
図 3.7 UserGroupInformation.getBestUGIメソッドの実装 ここでは、渡される 2 つのパラメーター、ticketCachePath と userに注目します。 ticketCachePath は、hadoop.security.kerberos.ticket.cache.path を構成することによって取得される値です。この例では、このパラメーターは構成されていないため、ticketCachePath は空です。 user パラメータは、この例で渡されたユーザー名です。
-
ticketCachePath は空であり、user も空ではないため、図 3.7 のcreateRemoteUserメソッドが最終的に実行されます。

図 3.6

図 3.7
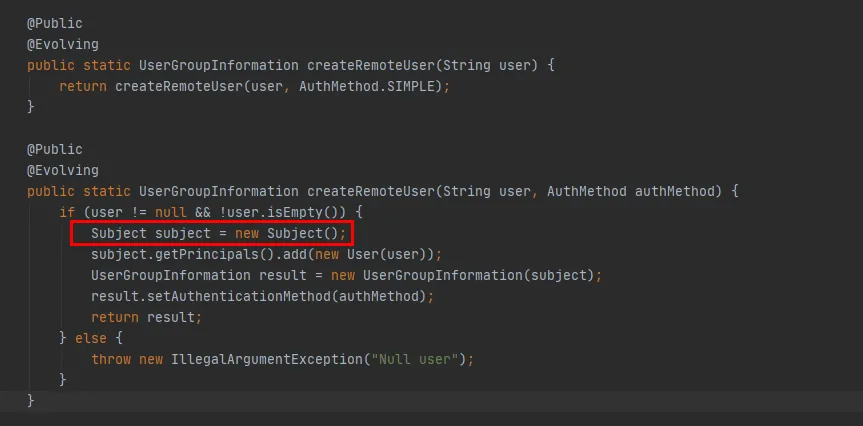
図 3.8
図 3.8 の赤いコードから、createRemoteUser メソッドで新しいSubject オブジェクトが作成され、このオブジェクトを通じてUserGroupInformationオブジェクトが作成されることがわかります。この時点で、UserGroupInformation.getBestUGI メソッドの実行が完了します。
次に、次のように、 UserGroupInformation.doAsメソッド (FileSystem.get(final URI uri, Final Configuration conf, Final String user) によって実行される最後のメソッド)を確認します。
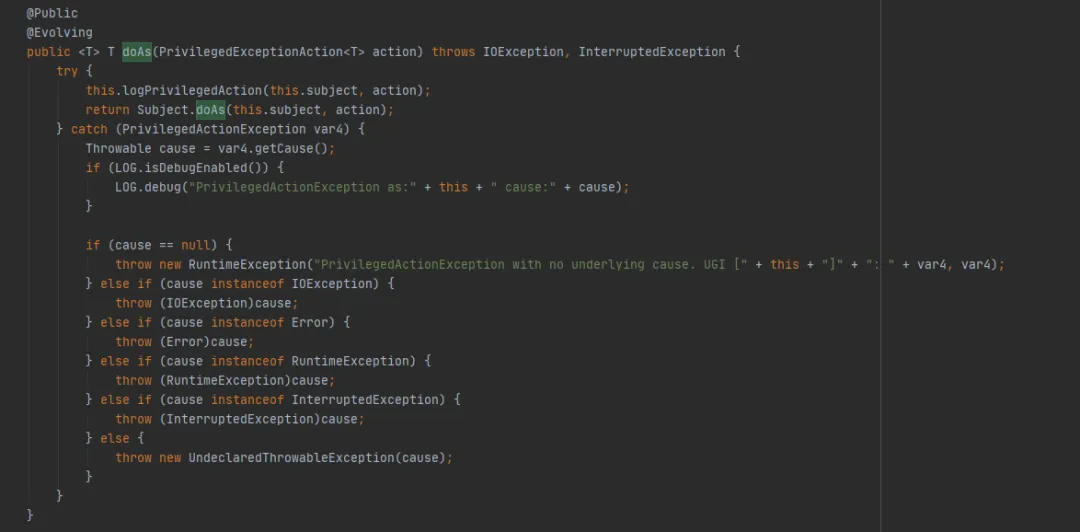
次に、次のように Subject.doAs メソッドを呼び出します。
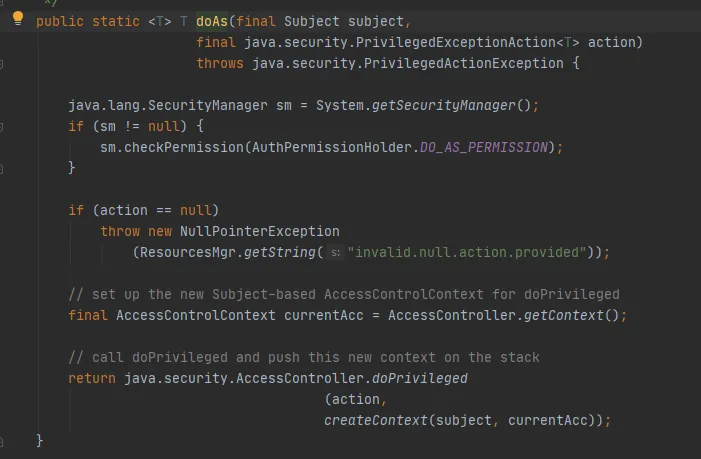
最後に、次のように AccessController.doPrivileged メソッドを呼び出します。
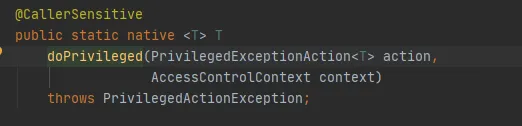
このメソッドはネイティブ メソッドであり、指定された AccessControlContext を使用して PrivilegedExceptionAction を実行します。つまり、実装の run メソッドを呼び出します。それが FileSystem.get(uri, conf) メソッドです。
この時点で、この例では、get(final URI uri、final Configuration conf、final String user) メソッドで FileSystem を作成するときに、FileSystem の Cache に格納されている Cache.key の hashCode が毎回不整合であることが説明できます。 。
要約する:
-
get(final URI uri、final Configuration conf、final String user)メソッドを使用してFileSystemを作成すると、毎回新しいUserGroupInformation オブジェクトとSubjectオブジェクトが作成されます。
-
Cache.Key オブジェクトがhashCodeを計算するとき、計算結果に影響を与えるのは、 UserGroupInformation.hashCodeメソッドの呼び出しです。
-
UserGroupInformation.hashCode メソッド。 System.identityHashCode(subject)として計算されます。つまり、Subject が同じオブジェクトであれば、同じ hashCode が返されることになります。この例では毎回異なるため、計算された hashCode は矛盾します。
-
要約すると、毎回計算される Cache.key の hashCode が不一致となり、FileSystem の Cache が繰り返し書き込まれることになります。
(4) ファイルシステムの正しい使い方
上記の分析から、FileSystem.Cache がその役割を果たしていないのに、なぜこの Cache を設計する必要があるのでしょうか?実際のところ、私たちの使い方が間違っているだけです。
FileSystem には、オーバーロードされた get メソッドが 2 つあります。
public static FileSystem get(final URI uri, final Configuration conf, final String user)
public static FileSystem get(URI uri, Configuration conf)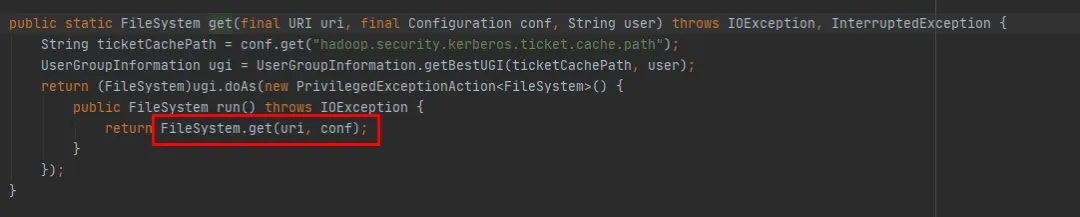
FileSystem get(final URI uri,final Configuration conf,final String user) メソッドが最終的に FileSystem get(URI uri, Configuration conf) メソッドを呼び出すことがわかります。違いは、FileSystem get(URI uri, Configuration conf) メソッドであることです。毎回新しい件名を作成する操作が欠けているだけです。

図 3.9
新しいサブジェクトを作成する操作がない場合、図 3.9 のサブジェクトは null となり、最後の getLoginUser メソッドを使用して loginUser が取得されます。 LoginUser は静的変数であるため、loginUser オブジェクトが正常に初期化されると、そのオブジェクトは今後も使用されます。 UserGroupInformation.hashCode メソッドは同じ hashCode 値を返します。つまり、FileSystem にキャッシュされたキャッシュは正常に使用できます。

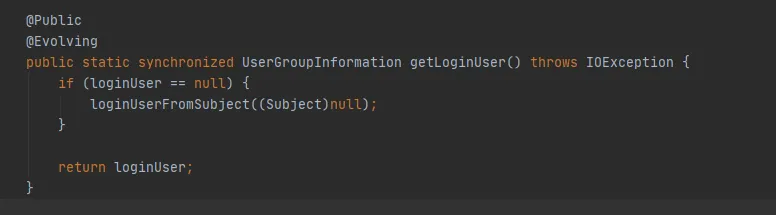
図3.10
4. 解決策
前回の紹介の後、FileSystem のメモリ リーク問題を解決したい場合は、次の 2 つの方法があります。
(1)public static FileSystem get(URI uri, Configuration conf)を使用:
-
このメソッドはファイルシステム キャッシュを使用できます。これは、同じ hdfs URI に対してファイルシステム接続オブジェクトが 1 つだけ存在することを意味します。
-
System.setProperty("HADOOP_USER_NAME", "hive") を通じてアクセス ユーザーを設定します。
-
デフォルトでは、fs.automatic.close=true、つまり、すべての接続が ShutdownHook を通じて閉じられます。
(2)public static FileSystem を使用 get(final URI uri、final Configuration conf、final String user):
-
上記で分析したように、このメソッドはファイルシステムのキャッシュを無効にし、毎回キャッシュのマップに追加されるため、リサイクルされなくなります。
-
これを使用する場合、解決策の 1 つは、同じ hdfs URI に対して FileSystem 接続オブジェクトが 1 つだけ存在するようにすることです。
-
もう 1 つの解決策は、FileSystem を使用するたびに close メソッドを呼び出して、キャッシュ内の FileSystem を削除することです。
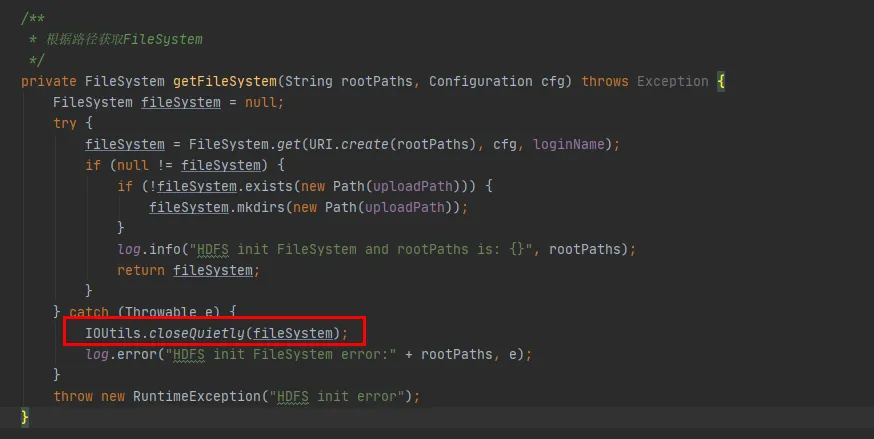
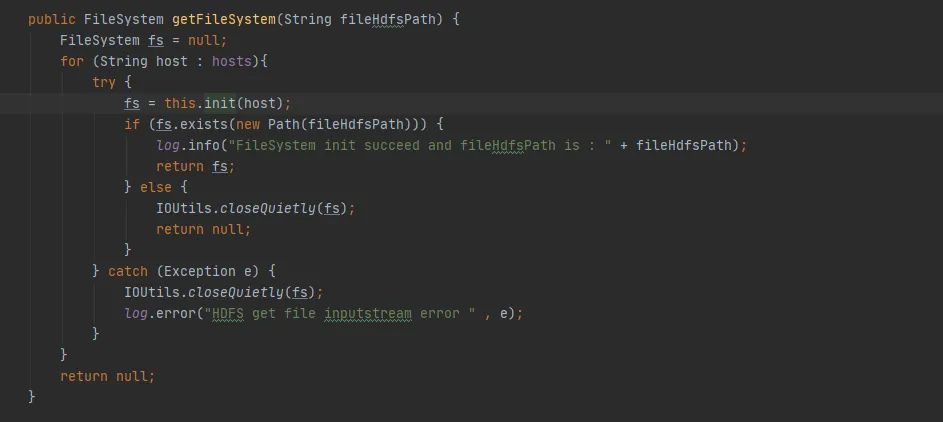
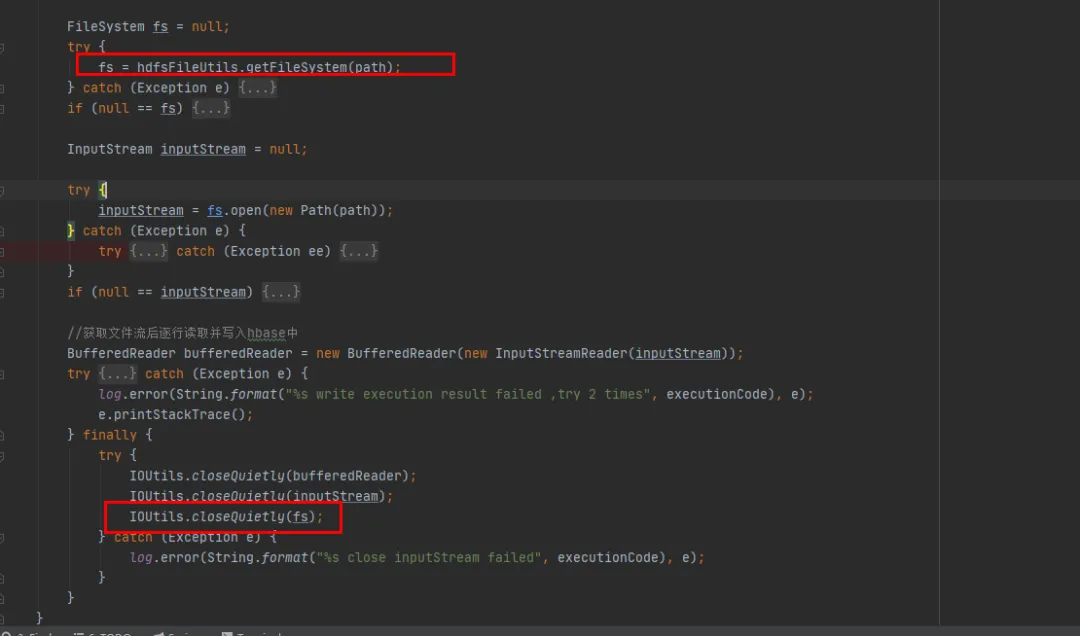
既存の歴史的コードへの変更は最小限であるという前提に基づいて、2 番目の変更方法を選択しました。 FileSystem を使用するたびに、FileSystem オブジェクトを閉じます。
5. 最適化結果
コードが修復され、オンラインで公開されると、以下の図 1 に示すように、修復後に古い世代のメモリが正常にリサイクルできることがわかります。この時点で、問題は最終的に解決されています。
6. まとめ
メモリ オーバーフローは、Java 開発で最も一般的な問題の 1 つであり、その原因は通常、メモリが正常にリサイクルされないメモリ リークによって発生します。この記事では、完全なオンライン メモリ オーバーフロー処理プロセスを詳しく紹介します。
メモリ オーバーフローが発生した場合の一般的な解決策を要約します。
(1)ヒープメモリファイルの生成:
サービス起動コマンドを追加する
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/baseOOM が発生したときにサービスが自動的にメモリ ファイルをダンプするようにするか、jam コマンドを使用してメモリ ファイルをダンプします。
(2)ヒープ メモリの分析: メモリ オーバーフローの問題をより深く分析し、メモリ オーバーフローの原因を特定するには、メモリ分析ツールを使用します。一般的に使用されるいくつかのメモリ分析ツールを次に示します。
-
Eclipse Memory Analyzer : メモリ リークを迅速に特定するのに役立つオープン ソースの Java メモリ分析ツール。
-
VisualVM Memory Analyzer : Java アプリケーションのメモリ使用量の分析に役立つグラフィカル インターフェイスに基づくツール。
(3) ヒープ メモリ分析に基づいて、特定のメモリ リーク コードを特定します。
(4) メモリリークコードを修正し、検証のために再リリースします。
メモリ リークはメモリ オーバーフローの一般的な原因ですが、原因はそれだけではありません。メモリ オーバーフローの問題の一般的な原因には、サイズが大きすぎるオブジェクト、小さすぎるヒープ メモリ割り当て、無限ループ呼び出しなどがあり、これらはすべてメモリ オーバーフロー問題を引き起こす可能性があります。
メモリ オーバーフローの問題が発生した場合は、さまざまな側面から考え、さまざまな角度から問題を分析する必要があります。上記の方法とツール、およびさまざまな監視を通じて、問題を迅速に特定して解決し、システムの安定性と可用性を向上させることができます。
1990 年代生まれのプログラマーがビデオ移植ソフトウェアを開発し、1 年足らずで 700 万以上の利益を上げました。結末は非常に罰的でした。 高校生が成人式にオープンソースプログラミング言語を自作―ネチズンの鋭いコメント: 詐欺横行でRustDesk依存、国内サービスの タオバオ(taobao.com)は国内サービスを一時停止、ウェブ版の最適化作業を再開 Java最も一般的に使用されている Java LTS バージョンは 17 、Windows 11 は減少し続ける Open Source Daily | Google がオープンソースの Rabbit R1 を支持、Microsoft の不安と野心; Electricがオープンプラットフォームを閉鎖 AppleがM4チップをリリース GoogleがAndroidユニバーサルカーネル(ACK)を削除 RISC-Vアーキテクチャのサポート Yunfengがアリババを辞任し、将来的にはWindowsプラットフォームで独立したゲームを制作する予定