
データベース インデックスは、データベース システムのパフォーマンスを最適化するための重要なコンポーネントです。効果的なインデックスがないと、データベース クエリが遅くなり非効率になり、その結果、ユーザー エクスペリエンスが低下し、生産性が低下する可能性があります。この記事では、データベース インデックスの作成と使用に関するいくつかのベスト プラクティスについて説明します。
著者: Java トレイル
この記事と表紙のソース: https://medium.com/、Axon オープン ソース コミュニティによって翻訳されました。
この記事は約 2,700 ワードで、読むのに 9 分かかると予想されます。
データベースでは、クエリのパフォーマンスを向上させるために、さまざまなインデックス作成アルゴリズムが使用されています。最も一般的に使用されるインデックス作成アルゴリズムのいくつかを次に示します。
B ツリー インデックス
B ツリー インデックスは、データの順序を維持し、対数時間での検索、順次アクセス、挿入、削除を可能にする自己均衡ツリー データ構造です。 B ツリー インデックス構造は、データベースやファイル システムで広く使用されています。 B ツリー インデックスは、MySQL や PostgreSQL などのリレーショナル データベースで広く使用されています。
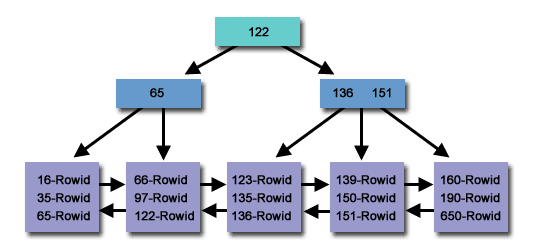
B ツリー インデックスは、値の範囲内のすべてのレコードを効率的に検索できるため、範囲クエリ用に最適化されています。これは、レコードがインデックスにソートされた順序で格納されるためです。=、>、>=、<、<=または演算子を使用する式での列比較を活用しますBETWEEN。
たとえば、次のテーブル構造を持つ products テーブルがあるとします。
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(255),
price DECIMAL(10,2)
);
price次の SQL ステートメントを使用して、B ツリー インデックスをフィールドに追加できます。
CREATE INDEX products_price_index ON products (price);
ハッシュインデックス
ハッシュ インデックスは、クエリを高速化するために使用されるもう 1 つの一般的なインデックス作成アルゴリズムです。ハッシュ インデックスは、ハッシュ関数を使用してキーをインデックスの場所にマップします。このインデックス作成アルゴリズムは、主キー値に基づいて特定のレコードを検索するなど、完全一致クエリに最も役立ちます。ハッシュ インデックスは、Redis などのインメモリ データベースでよく使用されます。
ハッシュ インデックスは、ハッシュ値に基づいてテーブル内の各レコードを一意のバケットにマッピングすることで機能します。ハッシュ値は、データ項目を入力として受け取り、一意の整数値を返す数学関数であるハッシュ関数を使用して計算されます。
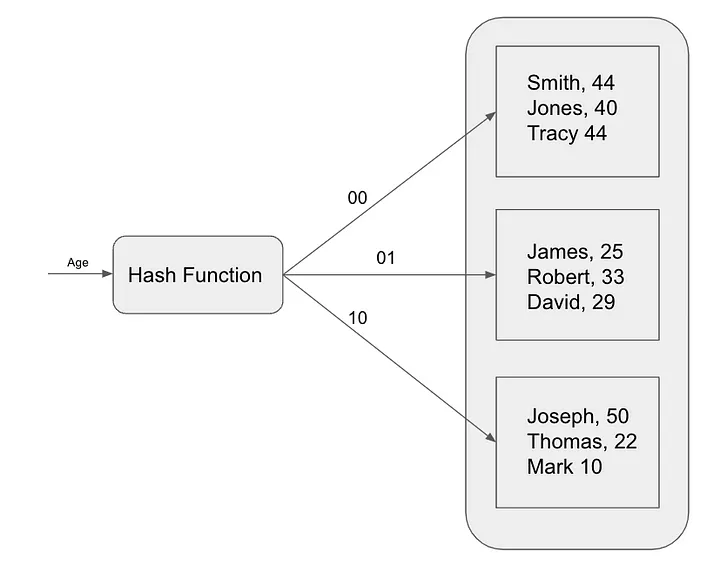
ハッシュされたインデックス内のレコードを検索するには、データベースは検索キーのハッシュを計算し、対応するバケットを検索します。レコードがバケット内にある場合、データベースはレコードを返します。それ以外の場合、データベースはテーブル全体のスキャンを実行します。
ハッシュ インデックスは検索には非常に高速ですが、データ範囲を効率的にクエリするために使用することはできません。これは、ハッシュ関数がテーブル内のレコード間の順序を保持しないためです。
ハッシュ インデックスを使用してクエリを実行するには、次の手順を実行します。
- データベースはクエリ基準のハッシュ値を計算します。
- ハッシュ テーブルで対応するハッシュ バケットを見つけます。
- 次にデータベースは、対応するハッシュ値を持つテーブル内の行へのポインターを取得します。
- これらのポインターを使用して、テーブルから実際の行を取得します。
次のテーブル構造を持つ products テーブルがあるとします。
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(255),
price DECIMAL(10,2)
);
Q: ハッシュ インデックスは B-Tree のように最適化されていませんか?
状況によっては、ハッシュ インデックスが最適な選択ではない可能性があります。
=ハッシュ インデックスは、検索 ( or演算子を使用した等価比較) に関してはツリー インデックスよりも高速です<=>が、データ範囲を効率的にクエリするために使用することはできません。- ツリー インデックスは検索時にハッシュ インデックスよりも遅くなりますが、データ範囲を効率的にクエリするために使用できます。
範囲クエリ:ハッシュ インデックスは、値の範囲内でレコードを検索する必要がある範囲クエリに対しては最適化されていません ( =、>、>=、<、<=またはBETWEEN演算子を使用)。この場合、B ツリー インデックスの方が適切です。
並べ替え:ハッシュ インデックスは並べ替え用に最適化されていないため、特定の列に基づいてレコードを並べ替える必要があります。この場合、B-Tree インデックスまたはクラスター化インデックスの方が適しています。
大規模なデータセット:ハッシュ インデックスはメモリを大量に消費する可能性があるため、メモリ使用量が懸念される大規模なデータセットには適さない可能性があります。
name次のコマンドを使用して、列にハッシュ インデックスを作成できます。
CREATE INDEX products_name_hash ON products (name);
SELECT * FROM products WHERE name = 'iPhone 13 Pro';
CREATE INDEX products_name_tree ON products (name);
SELECT * FROM products WHERE name = 'iPhone 13 Pro';
ハッシュ インデックスを使用する場合、データベースは検索キー「iPhone 13 Pro」のハッシュ値を計算し、対応するバケットを検索します。ハッシュ関数は決定論的であるため、データベースは、レコードがテーブルに格納されている順序に関係なく、常に同じバケット内のレコードを検索します。
ツリー インデックスを使用する場合、データベースはツリーのルートから開始され、検索キー「iPhone 13 Pro」とルートに保存されているキーの値を比較します。ツリーはソートされているため、データベースは検索キーを含むレコードをすぐに見つけます。
Q: B-Tree がハッシュ インデックスよりも範囲クエリに対して最適化されているのはなぜですか?
ここで、価格が 100 ドルから 200 ドルまでの製品をすべて検索したいとします。次のクエリを使用できます。
SELECT * FROM products WHERE price BETWEEN 100 AND 200;
動作原理
B ツリー
B ツリー インデックスは、レコードをソートされた順序で保存することによって機能します。 B ツリー インデックス内のレコードを検索するには、
- データベースはツリーのルートから開始され、検索キーとルートに格納されているキーの値を比較します。
- 検索キーがルート キーと等しい場合、データベースはそのレコードを返します。
- それ以外の場合、データベースは比較結果に基づいて次にどのサブツリーを検索するかを決定します。
ハッシュ
ハッシュ インデックスは、ハッシュ値に基づいてテーブル内の各レコードを一意のバケットにマッピングすることで機能します。ハッシュ値はハッシュ関数を使用して計算されます。ハッシュ インデックスはバケット全体にデータをランダムに分散するため、範囲クエリが非効率的になります。 100 ドルから 200 ドルまでの価格などの値の範囲を取得するには、その範囲内のすべてのバケットをスキャンする必要があり、実質的にテーブル全体のスキャンが行われることになります。ハッシュ インデックスは高速な完全一致検索には優れていますが、効率的な範囲クエリに必要なデータの順序付けが不足しています。
質問です。ソートにおいて、B ツリー インデックスがハッシュ インデックスよりも最適化されているのはなぜですか?
B ツリー ツリー インデックスはレコードを並べ替えられた順序で保存するため、ハッシュ インデックスよりも効率的にデータを並べ替えます。これにより、データベースはソートされた順序でレコードを迅速に繰り返すことができます。
ハッシュ インデックスは、ハッシュ値に基づいてテーブル内の各レコードを一意のバケットにマッピングすることで機能します。これは、バケット内のレコードの順序がランダムであることを意味します。レコードを並べ替えるには、データベースですべてのバケットを反復処理し、各バケット内のレコードを並べ替える必要があります。これは、レコードをソート順に格納する B ツリー インデックスを使用するよりも遅くなります。
price次のコマンドを使用して、列に B ツリー インデックスを作成できます。
CREATE INDEX products_price_index ON products (price);
ここで、製品を価格の昇順に並べ替えたいとします。次のクエリを使用できます。
SELECT * FROM products ORDER BY price ASC;
データベースは B ツリー インデックスを使用して、ソートされた順序で製品を迅速に反復処理します。
ハッシュインデックスの欠点:
- ハッシュ インデックスは範囲クエリや並べ替えをサポートしていません
- ハッシュインデックスは大量のメモリを消費します
- ハッシュ インデックスは頻繁に更新されるデータベースには適していません
ビットマップインデックス
ビットマップ インデックスは、ブール列や性別列など、少数の個別の値を持つ列に使用されます。ビットマップ インデックスは非常にコンパクトで、カーディナリティの低い列に対して効率的です。
SELECT * FROM employees WHERE gender = 'Female';
ビットマップ インデックスはカーディナリティの低い列に対して非常に効率的であり、ユニオンやインターセクションなどの高速なセット操作が可能です。アドホックなレポート作成やデータ ウェアハウジングに最適です。
全文インデックス
全文インデックス作成は、ドキュメントや Web ページなどの大量のテキスト データのインデックスを作成するために使用されます。このインデックス作成アルゴリズムは、テキストを単語またはトークンに分割し、効率的な検索操作を可能にする方法でインデックスを作成します。全文インデックスは、テキスト内の特定の単語や語句の検索を伴うクエリに最も役立ちます。全文インデックス作成は、Elasticsearch などの検索エンジンでよく使用されます。
電子商取引の全文インデックス作成の使用例:
全文インデックス作成により、電子商取引アプリケーションは、ユーザーが入力した検索クエリに基づいて大規模な製品カタログを迅速に検索できます。全文インデックス作成により、スペルミス、同義語、さらには関連概念を含む複数の単語やフレーズに基づいて検索できます。これにより、ユーザーは正確な製品名や説明が分からない場合でも、探しているものを簡単に見つけることができます。
たとえば、顧客が新しいランニング シューズを探していると想像してください。彼らは検索バーに「ランニング シューズ」と入力します。全文インデックスを使用すると、電子商取引アプリケーションはすべての製品説明、名前、ラベルをすばやく検索して、ランニング シューズに関連するすべての製品を見つけることができます。検索結果は関連性によって並べ替えられます。関連性は、検索語が製品情報に表示される頻度によって決まります。
全文インデックスを作成しないと、製品の説明やラベルなど、顧客に関連する可能性のある他の要素が考慮されず、製品名のみが検索される可能性があります。さらに、検索ではスペルミスや、「ジョギング シューズ」や「スニーカー」などの関連概念が処理されない場合があります。
products次の列を含む名前のテーブルがあるとします: id、name、descriptionおよびtags。
CREATE FULLTEXT INDEX products_ft_index ON products(name, description, tags);
ここで、顧客が「ランニング シューズ」を検索すると想像してください。次のクエリを使用して、検索語に関連する製品を検索できます。
SELECT id, name, description, MATCH(name, description, tags) AGAINST('running shoes') as relevance
FROM products
WHERE MATCH(name, description, tags) AGAINST('running shoes' IN BOOLEAN MODE)
ORDER BY relevance DESC
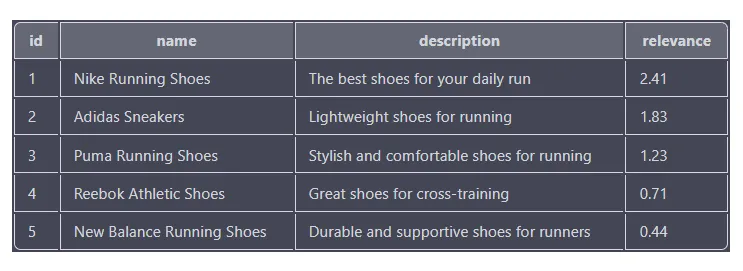
関連性スコアは、各製品が検索用語にどの程度一致するかに基づいており、スコアが高いほど一致が近いことを示します。結果は関連性スコアに基づいて降順に並べ替えられるため、関連性スコアが最も高い製品 (Nike ランニング シューズ) がリストの先頭に表示されます。
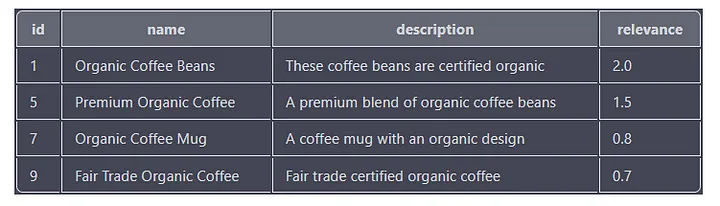
「オーガニック」と「コーヒー」という単語を含む製品を検索する別のクエリの例を次に示します。
SELECT id, name, description, MATCH(name, description, tags) AGAINST('+"organic" +"coffee"') as relevance
FROM products
WHERE MATCH(name, description, tags) AGAINST('+"organic" +"coffee"' IN BOOLEAN MODE)
ORDER BY relevance DESC;
このクエリは、名前、説明、またはラベルの列に「オーガニック」と「コーヒー」の両方のキーワードが含まれるすべての製品を検索します。各結果の関連性スコアも、列内のキーワードの回数と位置に基づいて計算されます。
出力には「id」、「name」、「description」、「relevance」列が含まれ、結果は「relevance」列で降順に並べ替えられます。
アドバンテージ
- フルテキスト インデックスはテキストベースの列に対して非常にうまく機能します。
- 検索エンジンやコンテンツ管理システムに最適
- 検索結果の関連性ランキングをサポート
欠点がある
- 全文インデックス作成は多くのストレージ容量を消費します
- 非常に大規模なデータセットの場合、パフォーマンスが低下する可能性があります
- 全文インデックス作成は数値データやカテゴリデータには適していません
さらに技術的な記事については、https: //opensource.actionsky.com/をご覧ください。
SQLEについて
SQLE は、開発環境から運用環境までの SQL 監査と管理をカバーする包括的な SQL 品質管理プラットフォームです。主流のオープンソース、商用および国内データベースをサポートし、開発、運用および保守のためのプロセス自動化機能を提供し、オンライン効率を向上させ、データ品質を向上させます。
SQL取得
| タイプ | 住所 |
|---|---|
| リポジトリ | https://github.com/actiontech/sqle |
| 書類 | https://actiontech.github.io/sqle-docs/ |
| リリースニュース | https://github.com/actiontech/sqle/releases |
| データ監査プラグイン開発ドキュメント | https://actiontech.github.io/sqle-docs/docs/dev-manual/plugins/howtouse |