
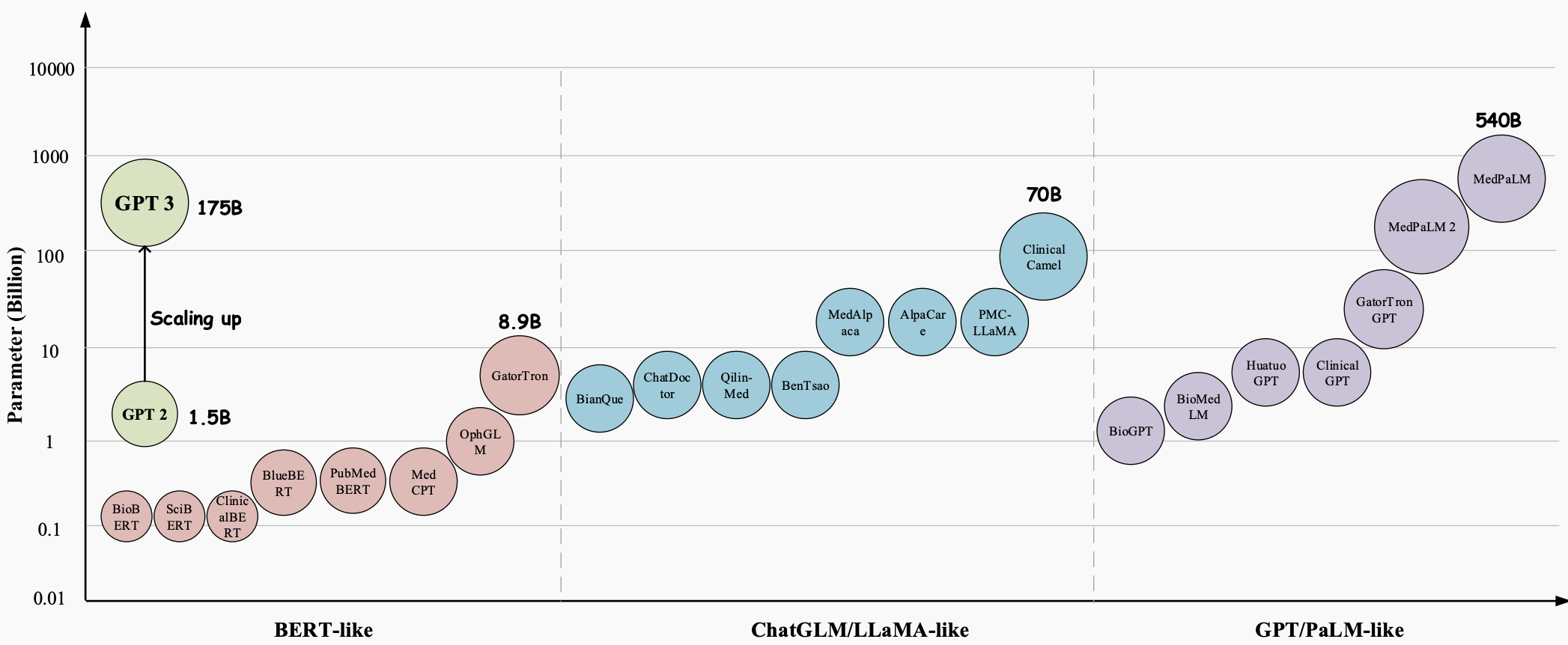
長年にわたり、大規模言語モデル (LLM) は、医療業界のあらゆる側面に革命をもたらす大きな可能性を秘めた画期的なテクノロジーに進化しました。GPT-3、GPT-4、Med-PaLM 2などのこれらのモデルは、人間のようなテキストを理解して生成する優れた機能を実証しており、複雑な医療タスクを処理し、患者ケアを改善するための貴重なツールとなっています。これらは、医療質問応答 (QA)、対話システム、テキスト生成など、さまざまな医療アプリケーションで大きな可能性を示しています。さらに、電子医療記録 (EHR)、医学文献、患者生成データの急激な増加に伴い、LLM は医療専門家が貴重な洞察を抽出し、情報に基づいた意思決定を行うのに役立ちます。
ただし、医療分野における大規模言語モデル (LLM) の大きな可能性にもかかわらず、解決する必要のある重要かつ具体的な課題がまだいくつかあります。
このモデルがエンターテイメントの会話の文脈で使用される場合、エラーの影響は最小限に抑えられますが、医療分野で使用される場合はそうではなく、誤った解釈や回答が患者のケアと転帰に重大な影響を与える可能性があります。言語モデルによって提供される情報の正確性と信頼性は、医療上の決定、診断、治療計画に影響を与える可能性があるため、死活問題となる可能性があります。
たとえば、GPT-3 が妊婦が使用できる薬について質問されたとき、テトラサイクリンは胎児に有害であり、妊婦は使用すべきではないと正しく述べていたにもかかわらず、GPT-3 は誤ってテトラサイクリンを推奨しました。本当にこの間違ったアドバイスに従い、妊婦に薬を投与してしまうと、将来、子供の骨の発育が悪くなる可能性があります。

このような大規模な言語モデルを医療分野で有効に活用するには、医療業界の特性に応じてこれらのモデルを設計し、ベンチマークする必要があります。医療データやアプリケーションにはそれぞれ特有の特徴があるため、それらを考慮する必要があります。そして、これらのモデルを研究だけでなく医療用途でも評価する方法を開発することは実際に重要です。なぜなら、これらのモデルは実際の医療業務で誤って使用されるとリスクを引き起こす可能性があるからです。
オープンソースの医療大規模モデル ランキングは、さまざまな医療タスクやデータセットに対するさまざまな大規模言語モデルのパフォーマンスを評価および比較するための標準化されたプラットフォームを提供することで、これらの課題と制限に対処することを目的としています。このランキングは、各モデルの医学知識と質問応答能力の包括的な評価を提供することで、より効果的で信頼性の高い医療モデルの開発を促進します。
このプラットフォームにより、研究者や医療従事者はさまざまなアプローチの長所と短所を特定し、この分野のさらなる開発を推進し、最終的には患者の転帰の改善に貢献できます。
データセット、タスク、評価設定
Medical Large Model Rank にはさまざまなタスクが含まれており、主な評価指標として精度が使用されます (精度は、さまざまな医療質問と回答のデータセットにおいて言語モデルによって提供される正答率を測定します)。
MedQA
MedQAデータセットには、米国医師免許試験 (USMLE) の多肢選択問題が含まれています。幅広い医学知識をカバーしており、トレーニング セットの質問 11,450 件とテスト セットの質問 1,273 件が含まれています。このデータセットは、質問ごとに 4 つまたは 5 つの回答選択肢があり、米国で医師免許を取得するために必要な医学知識と推論スキルを評価するように設計されています。

MedMCQA
MedMCQA は、インドの医学部入学試験 (AIIMS/NEET) から派生した大規模な多肢選択式の質問と回答のデータセットです。 2,400 の医療分野のトピックと 21 の医学科目をカバーしており、トレーニング セットには 187,000 以上の質問、テスト セットには 6,100 を超える質問が含まれています。各質問には 4 つの回答選択肢があり、説明が付いています。 MedMCQA は、モデルの一般的な医学知識と推論能力を評価します。

PubMedQA
PubMedQA はクローズド ドメインの質問回答データセットであり、関連するコンテキスト (PubMub 概要) を参照することで各質問に回答できます。これには、専門家がラベル付けした 1,000 の質問と回答のペアが含まれています。各質問には文脈に関する PubMed の要約が付いており、そのタスクは要約情報に基づいて「はい」/「いいえ」/「多分」の回答を提供することです。データセットは、500 個のトレーニング質問と 500 個のテスト質問に分かれています。 PubMedQA は、生物医学科学文献を理解し推論するモデルの能力を評価します。

MMLU サブセット (医学および生物学)
MMLU ベンチマーク(大規模マルチタスク言語理解の測定) には、さまざまな分野からの多肢選択式の質問が含まれています。オープンソースの医療大規模モデルのランキングでは、医学知識に最も関連のあるサブセットに焦点を当てています。
- 臨床知識: 臨床知識と意思決定スキルを評価する 265 の質問。
- 医療遺伝学: 医療遺伝学に関連するトピックをカバーする 100 の質問。
- 解剖学: 人体解剖学の知識を評価する 135 の質問。
- 専門医学: 医療専門家に必要な知識を評価する 272 問。
- 大学生物学: 大学レベルの生物学の概念をカバーする 144 の質問。
- College Medicine: 大学レベルの医学知識を評価する 173 問。各 MMLU サブセットには、特定の医学および生物学的領域に対するモデルの理解を評価するために設計された 4 つの回答オプションを備えた多肢選択式の質問が含まれています。

オープンソースの医療大規模モデルのランキングは、医学知識と推論のさまざまな側面におけるモデルのパフォーマンスの堅牢な評価を提供します。
洞察と分析
オープンソース医療大規模モデル ランキングは、さまざまな医療質問応答タスクにおけるさまざまな大規模言語モデル (LLM) のパフォーマンスを評価します。主な調査結果の一部を以下に示します。
- GPT-4 ベースや Med-PaLM-2 などの商用モデルは、さまざまな医療データセットで一貫して高精度スコアを達成し、さまざまな医療分野で優れたパフォーマンスを実証しています。
- Starling-LM-7B、gemma-7b、 Mistral-7B-v0.1 、およびHermes-2-Pro-Mistral-7Bなどのオープンソース モデルは、パラメーターの数が約 70 億しかありませんが、特定のデータに対して良好なパフォーマンスを示します。セットとタスクで競争力のあるパフォーマンスを実現しました。
- 商用およびオープンソースのモデルは、生物医学科学文献に関する理解と推論 (PubMedQA)、臨床知識と意思決定スキルの適用 (MMLU 臨床知識サブセット) などのタスクで良好に機能します。

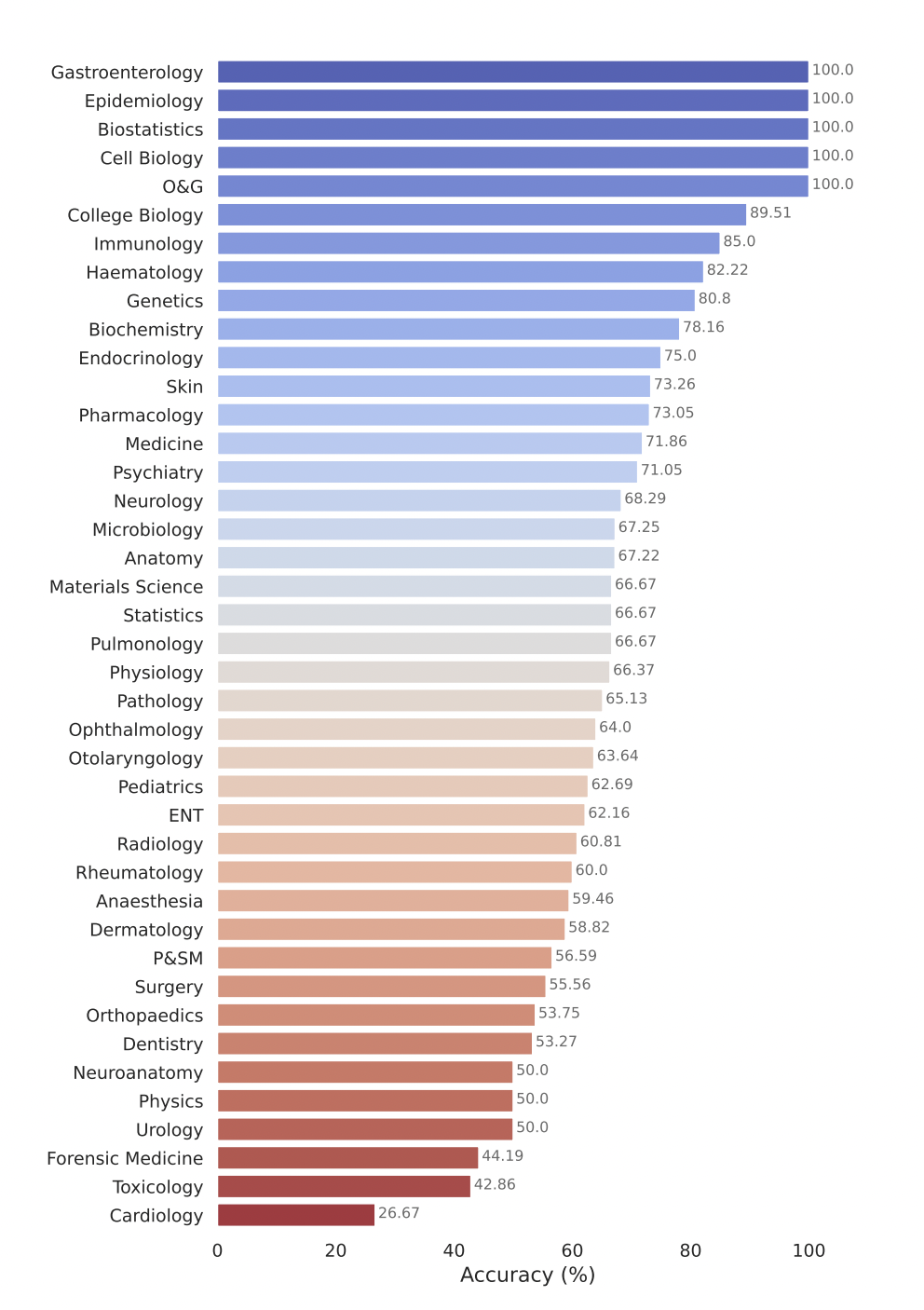
Google のモデルGemini Pro は、複数の医療分野、特に生物統計、細胞生物学、産婦人科などのデータ集約的で手続き的なタスクにおいて優れたパフォーマンスを実証しています。しかし、解剖学、心臓病学、皮膚科などの主要分野では中程度から低いパフォーマンスしか示しておらず、より包括的な医療に応用するにはさらなる改善が必要なギャップが明らかになりました。
評価のためにモデルを送信します
オープンソース ヘルスケア大規模モデル ランキングでの評価のためにモデルを送信するには、次の手順に従ってください。
1. モデルの重みをセーフテンソル形式に変換する
まず、モデルの重みをセーフテンソル形式に変換します。 Safetensor は、より安全かつ高速にロードして使用できるウェイトを保存するための新しい形式です。モデルをこの形式に変換すると、リーダーボードのメイン テーブルにモデルのパラメーターの数を表示できるようになります。
2. AutoClasses との互換性を確保する
モデルを送信する前に、Transformers ライブラリの AutoClasses を使用してモデルとトークナイザーをロードできることを確認してください。互換性をテストするには、次のコード スニペットを使用します。
from transformers import AutoConfig, AutoModel, AutoTokenizer
config = AutoConfig.from_pretrained(MODEL_HUB_ID)
model = AutoModel.from_pretrained("your model name")
tokenizer = AutoTokenizer.from_pretrained("your model name")
このステップで失敗した場合は、送信する前にエラー メッセージに従ってモデルをデバッグしてください。おそらくモデルが不適切にアップロードされた可能性があります。
3. モデルを公開する
モデルがパブリックにアクセスできることを確認してください。リーダーボードは、プライベート モデルや特別なアクセスを必要とするモデルを評価できません。
4. リモートコード実行 (近日公開予定)
現在、オープンソースの医療大規模モデル ランキングでは、必要なuse_remote_code=Trueモデルがサポートされていません。ただし、リーダーボード チームはこの機能を積極的に追加しているため、最新情報をお待ちください。
5. リーダーボード Web サイトを通じてモデルを送信します。
モデルがセーフテンソル形式に変換され、AutoClasses と互換性があり、一般にアクセスできるようになると、Open Source Medical Large Model Rank Web サイトの [Submit Here!] パネルを使用してモデルを評価できます。モデル名、説明、その他の詳細などの必要な情報を入力し、「送信」ボタンをクリックします。リーダーボード チームはあなたの提出物を処理し、さまざまな医療 Q&A データセットでのモデルのパフォーマンスを評価します。評価が完了すると、モデルのスコアがリーダーボードに追加され、そのパフォーマンスを他のモデルと比較できます。
次は何ですか?オープンソースの医療用大型モデルランキングを拡充
オープンソース ヘルスケア大規模モデル ランキングは、研究コミュニティとヘルスケア業界の変化するニーズを満たすために拡大し、適応することに取り組んでいます。主要な分野は次のとおりです。
- 研究者、医療機関、業界パートナーとの協力を通じて、放射線学、病理学、ゲノミクスなどのケアのあらゆる側面をカバーする、より広範な医療データセットを組み込みます。
- 医療アプリケーション固有のニーズを捉えるポイントツーポイント スコアやドメイン固有のメトリクスなど、精度を超えた追加のパフォーマンス測定を探索することで、評価メトリクスとレポート機能を強化します。
- この方向に向けてすでにいくつかの作業が進行中です。私たちが提案する予定の次のベンチマークでの協力に興味がある場合は、Discord コミュニティに参加して詳細を学び、参加してください。ぜひ協力してブレインストーミングをしていきたいと思います!
AI とヘルスケアの交差点、ヘルスケアのモデルの構築に情熱を持っており、大規模な医療モデルの安全性と幻覚の問題に関心がある場合は、Discord のアクティブなコミュニティに参加することをお勧めします。
謝辞

Clémentine Fourrier と Hugging Face チームを含む、これを可能にするのに協力してくれたすべての人々に特別に感謝します。リーダーボードの開発中に議論とフィードバックを提供してくれた Andreas Motzfeldt、Aryo Gema、Logesh Kumar Umapathi に感謝します。エディンバラ大学の Pasquale Minervini 教授にお時間を割いていただき、技術支援と GPU サポートをしていただき、心より感謝いたします。
オープンライフサイエンスAIについて
Open Life Sciences AI は、ライフサイエンスおよび医療分野における人工知能の応用に革命を起こすことを目的としたプロジェクトです。これは、医療モデル、データセット、ベンチマークをリスト化し、会議の期限を追跡する中央ハブとして機能し、AI 支援医療の分野でのコラボレーション、イノベーション、進歩を促進します。私たちは、Open Life Sciences AI を、AI とヘルスケアの交差点に興味があるすべての人にとっての最高の目的地として確立するよう努めています。私たちは、研究者、臨床医、政策立案者、業界の専門家が対話し、洞察を共有し、この分野の最新の発展を探索するためのプラットフォームを提供します。

引用
私たちの評価が役立つと思われる場合は、私たちの研究を引用することを検討してください
医療用大型モデルランキング
@misc{Medical-LLM Leaderboard,
author = {Ankit Pal, Pasquale Minervini, Andreas Geert Motzfeldt, Aryo Pradipta Gema and Beatrice Alex},
title = {openlifescienceai/open_medical_llm_leaderboard},
year = {2024},
publisher = {Hugging Face},
howpublished = "\url{https://huggingface.co/spaces/openlifescienceai/open_medical_llm_leaderboard}"
}
> 英語原文:https://hf.co/blog/leaderboard-medicalllm > 原著者: Aaditya Ura (博士課程探し中)、Pasquale Minervini、Clémentine Fourrier > 翻訳者:innovation64
1990 年代生まれのプログラマーがビデオ移植ソフトウェアを開発し、1 年足らずで 700 万以上の利益を上げました。結末は非常に罰的でした。 高校生が成人式にオープンソースプログラミング言語を自作―ネチズンの鋭いコメント: 詐欺横行でRustDesk依存、国内サービスの タオバオ(taobao.com)は国内サービスを一時停止、ウェブ版の最適化作業を再開 Java最も一般的に使用されている Java LTS バージョンは 17 、Windows 11 は減少し続ける Open Source Daily | Google がオープンソースの Rabbit R1 を支持、Microsoft の不安と野心; Electricがオープンプラットフォームを閉鎖 AppleがM4チップをリリース GoogleがAndroidユニバーサルカーネル(ACK)を削除 RISC-Vアーキテクチャのサポート Yunfengがアリババを辞任し、将来的にはWindowsプラットフォームで独立したゲームを制作する予定