


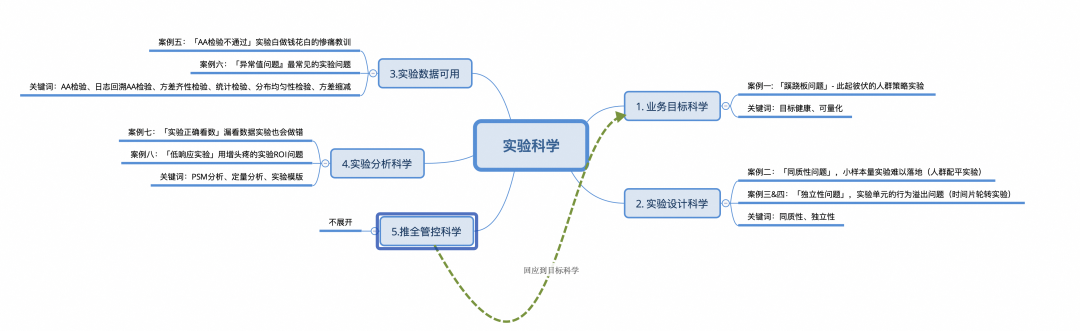

ビジネス目標の科学: 成長目標は、長期的で健全で定量化可能なものである必要があります。
▐事例1:「スカイソー問題」~相次ぐ運用実験~

事例分析
実験の結果から、この実験により 1 人当たりの GMV が大幅に増加した一方、ユーザー エクスペリエンスが大幅に低下したことがわかります。このようなヘッジ指標は、単価を下げることなく 1 人当たりの取引数を増やすなど、ビジネスでは珍しくありません。一人当たりの閲覧時間を増やすなど、一人当たりの取引金額などは減らさないようにしますが、異なる小規模チームにたまたまヘッジ指標が割り当てられている場合(組織構造における一般的な問題)、大規模チームは合理的に目標を設定し、特別な注意を払う必要があります。ヘッジインジケーターに。
現在のソリューション
-
大規模なチームはコア指標とフェンス指標を維持しますが、これらには通常、ビジネス リーダー、財務、BI の決定が必要です。
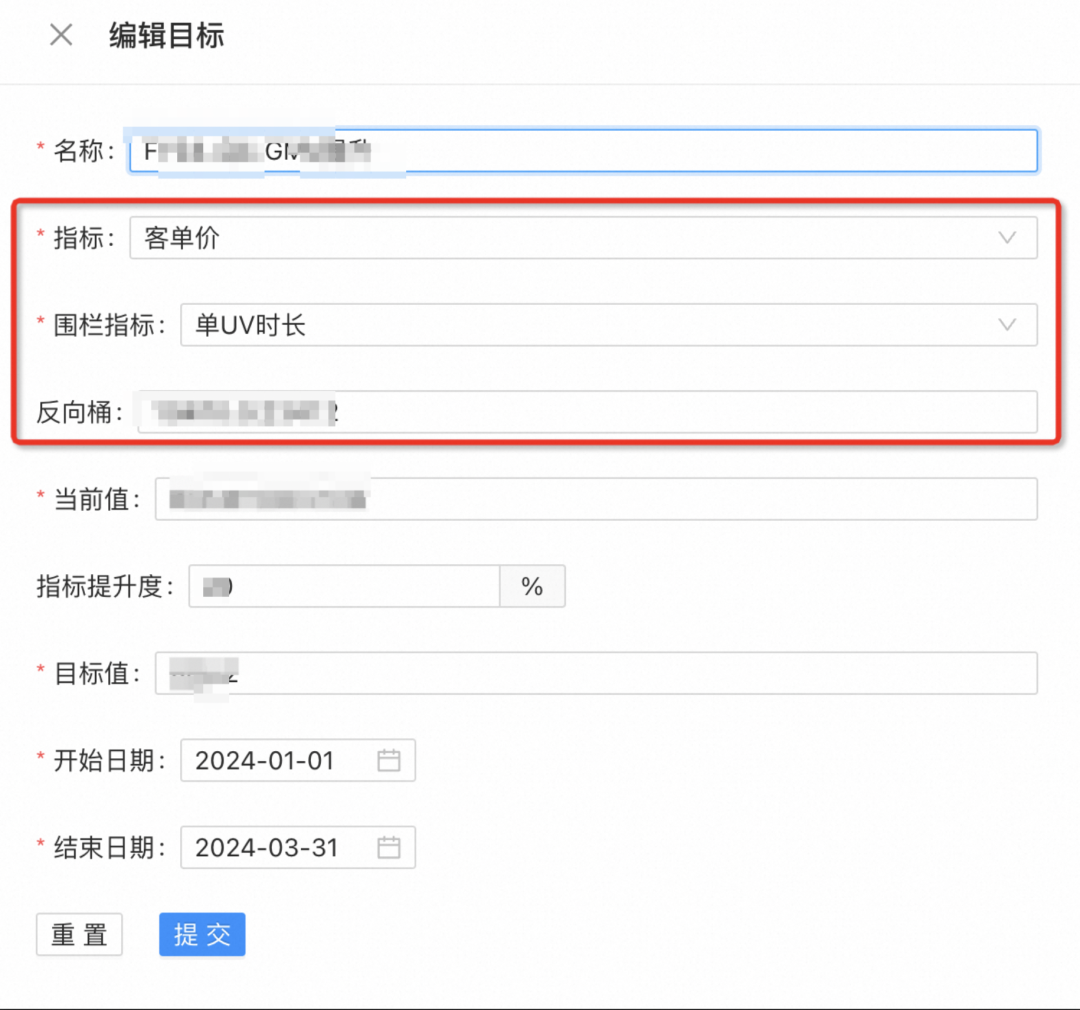
コアインジケーターとフェンスインジケーターのレンダリングの傾向を正規化し、すべてのノードの実験的なプッシュによって引き起こされる直感的な変化を観察します。
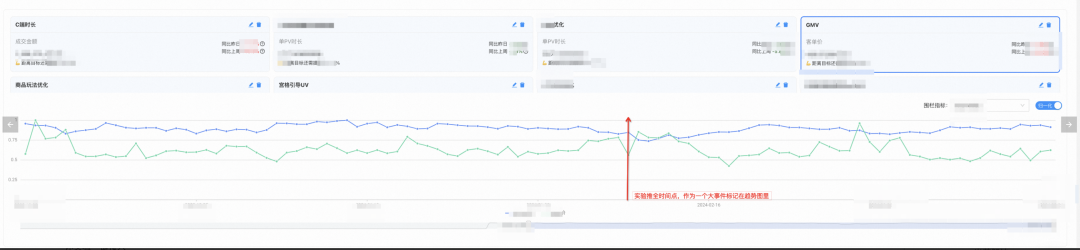
-
長期リバースバケットと組み合わせることで、実験の増分値が検証されます。 (写真には写っていません)
考える:実験的管理の観点からビジネスOKR指標はどのように決定されるべきですか?
-
OKRは実験で証明できる指標(一人当たりGMVなど)として設定されており、この指標は実験の価値を定量的に評価するために使用されます。 -
厳格なリバース バケットの管理と制御プロセス、およびリバース バケットによる GMV 寄与の推定。

▐ケース2:「均一性問題」、サンプルサイズが小さい実験は難しい:新しいアンカー実験
事例分析
ビジネス仮説: 私たちは通常、淘宝網での新しいアンカーのエクスペリエンスを向上させるために多くの戦略的な実験を行っています。ある戦略を例に挙げると、この戦略は新しいアンカーの熱意を効果的に向上させることができると想定しています。
実態:事業仕分け後に試験できる新規アンカーのサンプル数が少なく、アンカー間の個体差が大きいため、ランダムに抽出した2つのサンプル群間の指標が大きく変動し、実験が不可能である。 。
現在のソリューションのアイデア
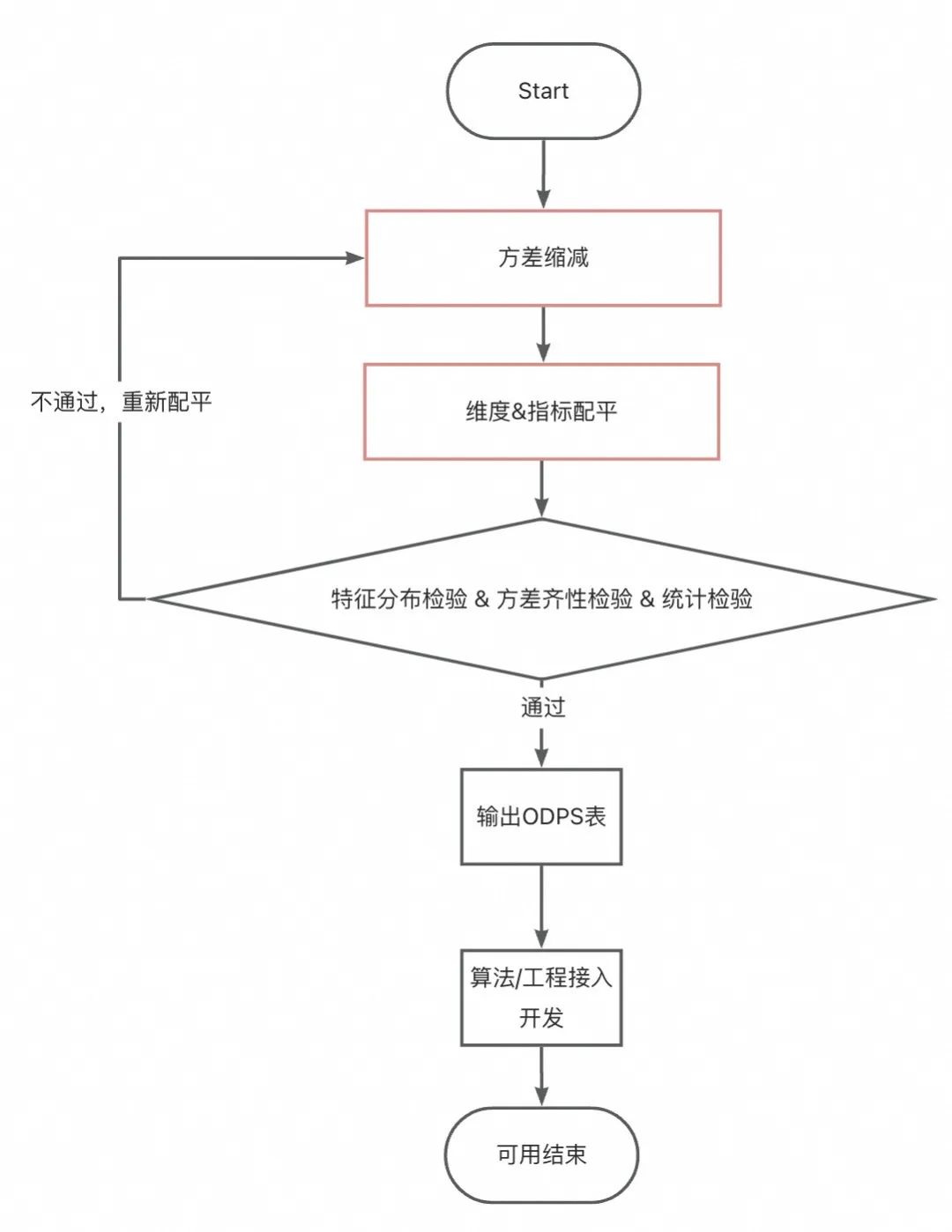
-
分散の削減: 実験で検証される指標の周囲で、 適切な量の外れ値を削除します (注: 削除しすぎると実験効果が小さくなり、削除しすぎると過度の変動が生じます。経験的には、少なくとも次の値に保ちます)分散がまだ高すぎる場合は、 長期指標に適切に処理 できます 。この場合、アンカーの 1 日の取引額の差が大きすぎるため、3 つを採用しました。 -日の平均取引額。ただし、 実験データの回復サイクルが長くなり 、 実験の解釈性が悪化する可能性がある ため、キャリバー処理の前に実験の目的を明確にする必要があります。 -
インジケーターと次元のバランス : オフライン処理を通じて、等しいインジケーター データ分布と等しい次元分布を持つサンプルの複数のグループが取得されます。
-
サンプルサイズがそれほど小さくなく、グループ内の違いがあまり明らかでない 場合は、単純なグループバランス を試すことができます 。つまり、各グループから同じ割合のアンカーが実験に参加します。 -
サンプルサイズが小さすぎる場合 、またはグループ内の差異が大きい 場合、モデルを使用して指標と次元のバランスをとることができます。この場合、 AA テストに安定して合格できる共変量適応ランダム化手法が使用されます。
-
AA テスト: グループ化の結果が均一であること、および実験の結論が使用可能であることを確認します。このセクションについては後で詳しく説明します。
考える
サンプルサイズが小さい実験は、市場全体への影響が小さく、実施が難しいため、簡単に無視されることがよくありますが、洗練された運用の下では、そのような実験は徐々に真剣に受け止められ始めています。また、サンプルサイズが小さいという「小さい」点にも注意する必要があります。実際の製品の価格引き下げのケースでは、500 個の製品がランダムに 1,000 回サンプリングされ、平均集合が正規分布に従わないことがわかりました。 10,000 個の製品をランダムにサンプリングするように調整すると、平均値は明らかな正規分布を示し始めるため、この状況での実験でサンプリングできるサンプル数は 10,000 未満であってはなりません。
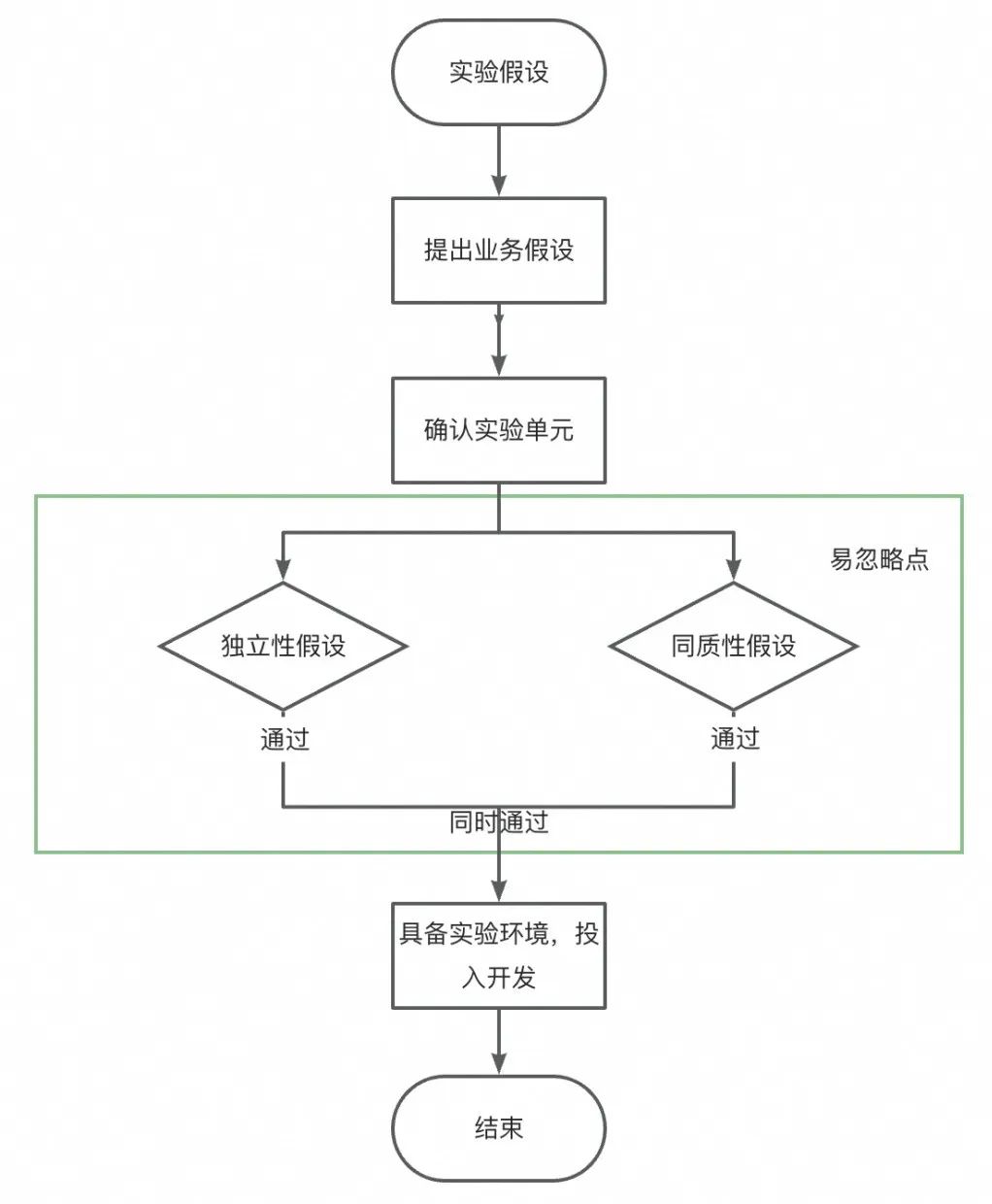
▐ケース3 と 4: 「独立性の問題」、ファン間のコミュニティ関係によって引き起こされるユーザー行動のオーバーフロー、およびアンカー間のトラフィック競合関係によって引き起こされるアンカー行動のオーバーフロー これらの実験はどのように行うか?
事例分析
現在のソリューション
時間を複数のタイム スライスに分割し、各タイム スライスを独立した実験単位として使用することで、同じタイム スライス内のすべてのユーザーが同じ戦略を確実に体験できるようになります。この設計により、ユーザー エクスペリエンスの不一致の問題が効果的に回避されます。同様に、各タイム スライスで、すべてのトラフィックがポリシーに均一に割り当てられます。この配置により、トラフィックの競合やユーザー エクスペリエンスの不一致が根本的に防止され、実験の公平性と有効性が確保されます。タイムスライスローテーション実験により、いつでもすべてのユーザーに統一されたエクスペリエンスを提供することができ、一貫性を維持し、実験中の潜在的な中断を回避できます。

欠点:
由于其实验单元为时间,所以可统计样本量较少,导致实验效果评估周期长,同时日期切片容易受热点事件影响,导致实验结论偏差。
由于需保证实验单元的独立性,且日期天然存在延续性,因此要减少日期之间的影响,例如1号的策略会影响到2号凌晨的主播(因为主播的场次容易跨天),所以日期切割需要结合业务特点,灵活选择时间切片大小和切割点。

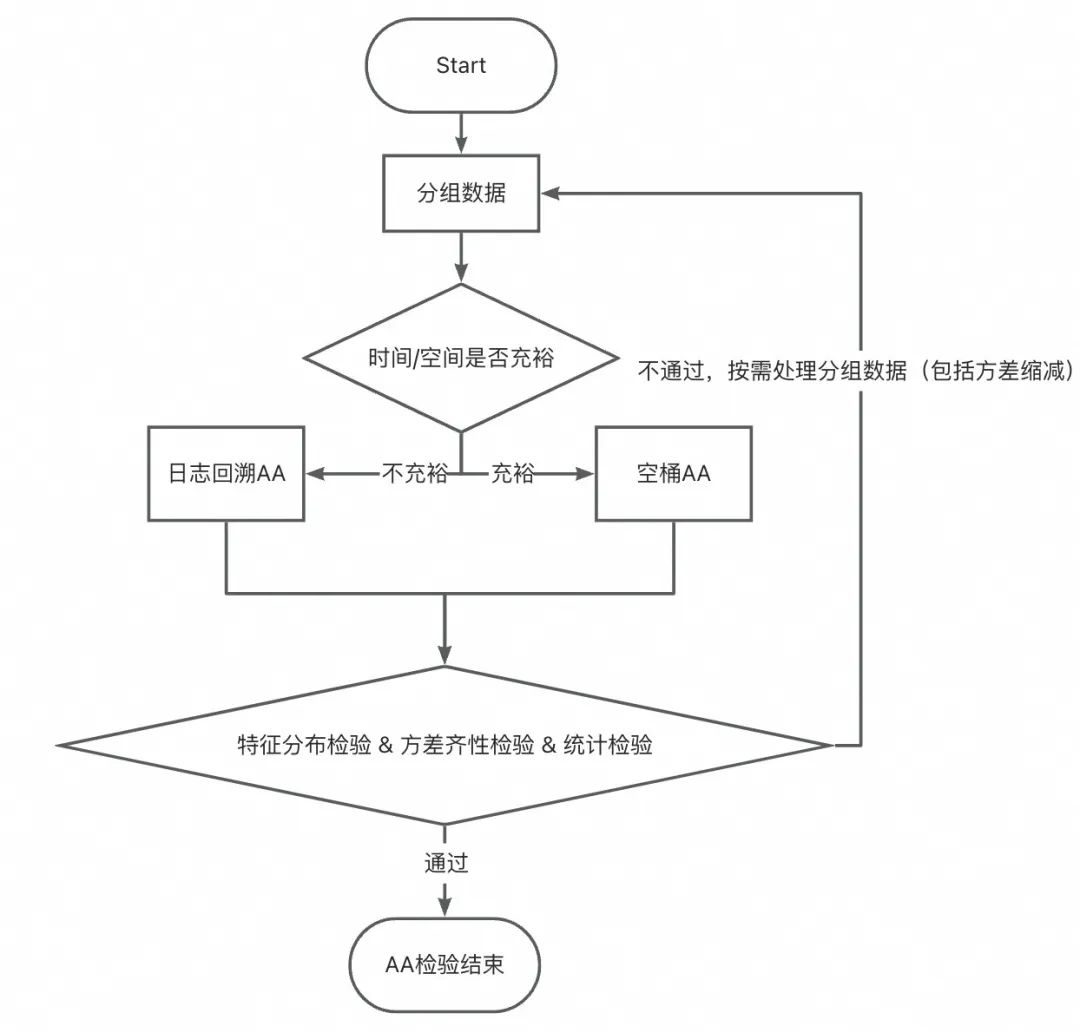
▐ 案例五:「AA检验不通过」在一次下单返红包的实验中,在分析实验数据时才发现用户分布不均匀,导致实验结论严重错误,甚至得出相反结论,浪费实验期间投入的预算等资源。
案例分析
当前解法
1、分布均匀性检验
在这次案例中,实验组和对照组在购买力分层上严重不均,从而导致其核心指标也显著不均,无法获得实验效果。注意:
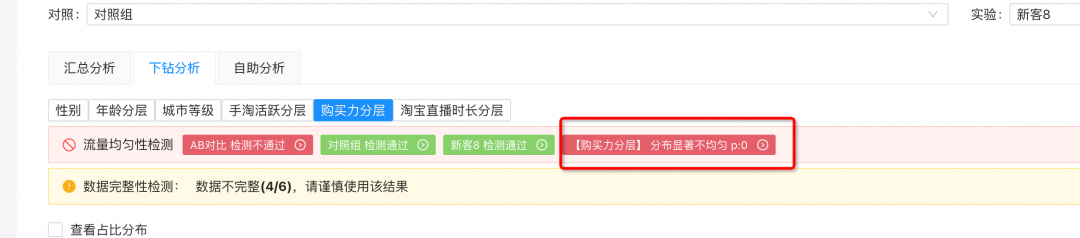
注意:分布不均匀并不一定表示实验数据不可用,本次案例是由于分布不均匀引起了核心指标不同质,导致了实验效果无法验证;
2、方差齐性检验 & 统计检验
在这次案例中,购买力的分布不均已经引起了指标不同质。从下图可以直观理解不同质现象,假设实验组和对照组本身同质,那么他们的数据分布应该都在绿色区域中,随后因为实验组施加了不同策略,导致实验组数据分布从绿色区域移动到了黄色区域。如果实验组未上策略就已经移动到了黄色区域,那么我们是无法证明策略对实验的影响。


图为检验结果
-
统计检验:通过双样本T检验或者多样本ANOVA检验,比较两个独立样本或配对样本的均值差异,具体检验方法可以根据实验样本量大小、样本均衡性情况、样本组数量决定。 -
方差齐性检验:通过Levene's Test或Bartlett's Test来验证实验组和对照组的数据方差是否一致。如果p值大于常用的显著性水平(如0.05),则可以认为组间方差是同质的。
▐ 案例六:「异常值问题』在一次打赏实验中,发现实验效果波动较大,排查后发现榜一大哥竟能左右实验效果
案例分析
在这个案例中,由于实验的用户一致性,榜一大哥会持续进入同一个实验组,于是大哥上线的天数该实验组效果就很好,大哥不在的天数则表现平平。这种实验如果没有找到这个异常值,按照常规经验难以进行分析和迭代。
当前解法
方差缩减:因为异常值会影响到指标的均值、方差,因此异常值除了引起汇总结果的波动外,实验的AA检验、AB检验也都会受影响。目前根据参与实验的实际样本量,采用常用手段:四分位数间距法、标准差法、Z-Score、孤立森林等方式做动态处理。
思考
A/B实验是验证因果关系的黄金标准。错误的因,只会带来错误的果。做好数据可用性验证,保证因果关系的正确发现,是沉淀实验经验,建立实验文化的必要基础。

在获得可用的数据基础后,我们开始关注实验分析的问题,图示为一个简化的实验分析流程。
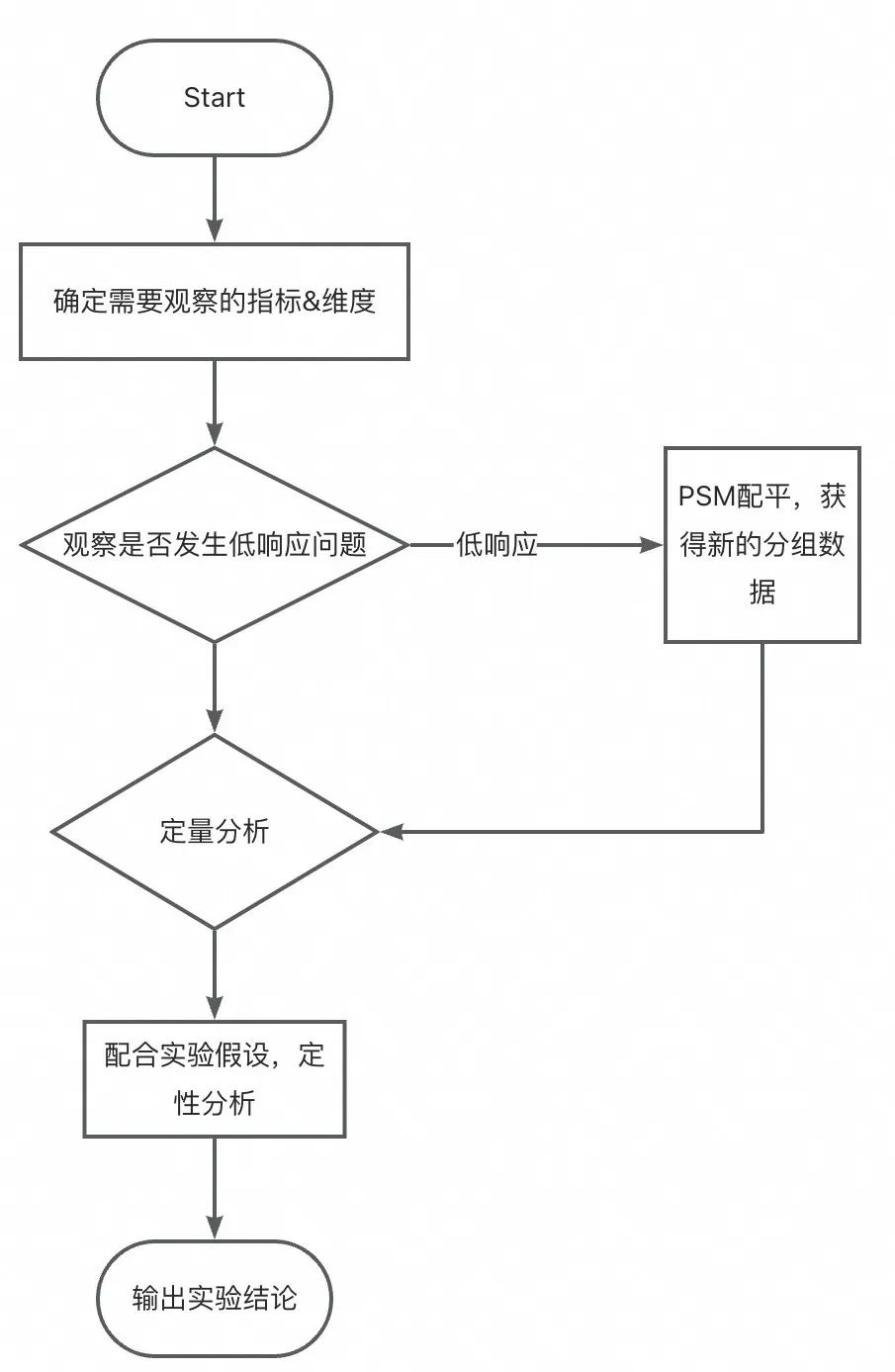
确定需要观察的指标&维度:
在上述案例中,可以发现漏看关键指标、关键维度都可能影响实验结论产出,且实际过程中实验往往需要下钻到关键维度,根据维度项里对实验的差异反应,寻找迭代方向。
▐ 案例七:「实验正确看数」在提单价的实验中,我们发现实验的GMV提升明显,但是观看时长显著降低
案例分析
由于提高了价格带,导致部分低购用户直接选择不看了,而这部分用户本身对GMV的贡献也不大,所以实验依然能够取得明显效果,然而低购群体里的较低年龄段用户他们贡献了较多的观看时长,因此该实验的观看时长也被显著降低。
因此得出一个业务经验:提单价的实验应避免波及(低GMV贡献但高观看时长贡献)的用户。
当前解法
针对不同业务背景,提前确定看数范围(指标+维度),避免经验不足引起的实验观察错误,通常这块由业务方+数据同学共同制定。
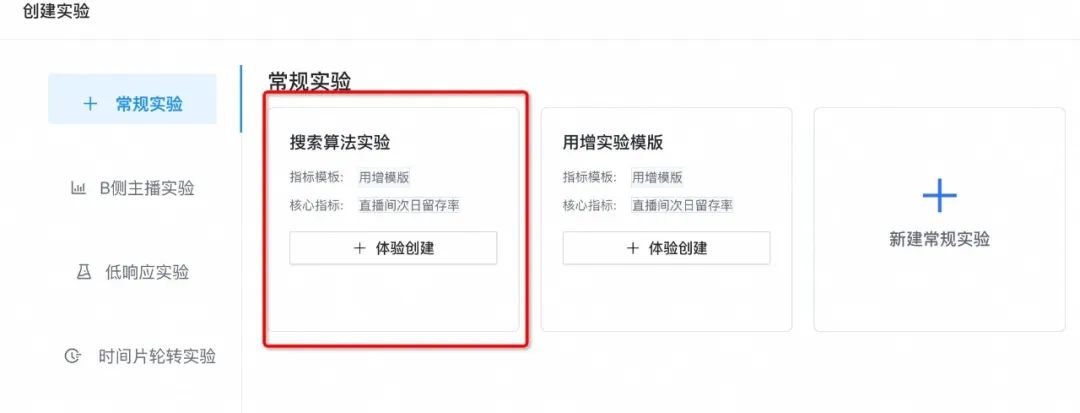
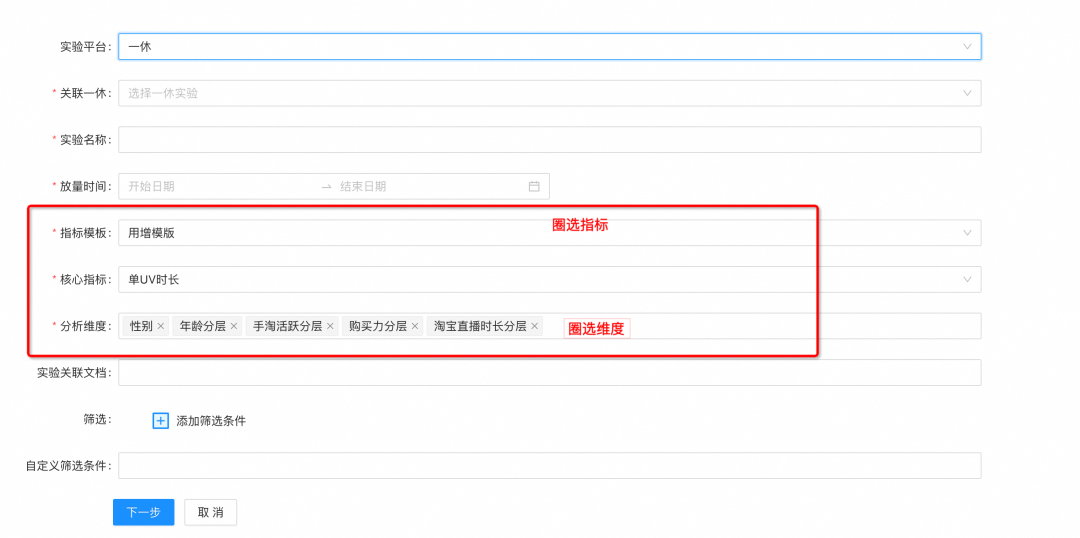
判断低响应实验
▐ 案例八:「低响应实验」活动入口做的AB实验,响应度太低无法分析实验数据。

案例分析
当前解法
▐ 定量分析
这块在第一篇文章中已经浓重介绍过,这里不再赘述。简单提及要点:没有置信度支撑的数据叫随机波动,不要当作实验结论。
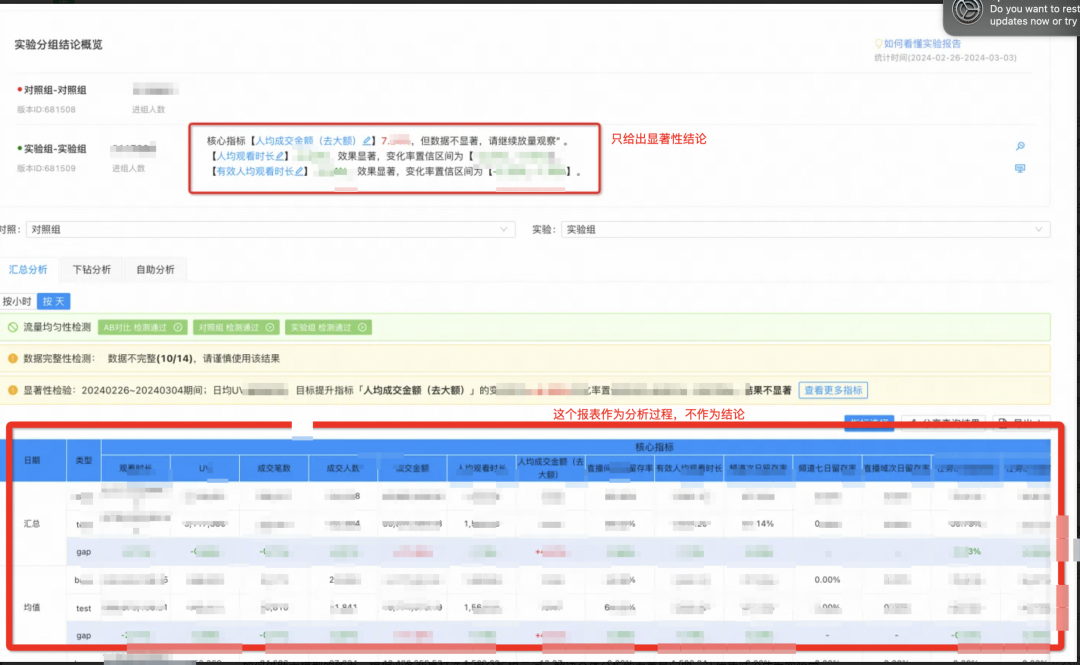
思考:

相关资料
实验推全最终会回应到业务目标达成,我在这块的推动经验较为薄弱,如何围绕业务目标建立可量化的推全标准,这需要多方的信任基础和强大的组织推力,以后补充。
感谢领导信任,让我有机会在直播业务中完善我对A/B实验的理解;感谢大佬的大力支持,感谢所有合作的产品老师、运营老师、算法老师、工程老师、数据研发老师、数据科学老师的大力支持。

技术线内容技术团队,是承接淘天内容电商最核心的技术力量,团队拥有非常全面的内容技术领域布局,不仅覆盖音视频编解码、流媒体传输、低延时直播等多媒体技术,也包含计算机视觉、自然语言处理、多模态內容理解、AIGC等人工智能领域。
在内容技术领域之外,团队拥有强大的算法、前端、客户端、服务端、测试开发、数据开发、数据科学团队、负责面向亿级消费者提供服务的淘宝直播、淘宝逛逛、点淘等核心业务场域;
面向千万级商家、品牌、机构、达人的内容创作工具、内容运营平台内容商业化解决方案;以及面向淘天集团电商板块各业务线的内容管理、内容总线等基石平台。
简历投递邮箱:[email protected]
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。