


現在主流の高速化アイデアには、オペレーターの最適化、モデルのコンパイル、モデルのキャッシュ、モデルの蒸留などが含まれます。以下では、テストで使用されるいくつかの代表的なオープンソース ソリューションを簡単に紹介します。
▐オペレーターの最適化: FlashAttendant2
▐モデルのコンパイル: oneflow/stable-fast
oneflow は、モデルを静的グラフにコンパイルし、それを oneflow.nn.Graph の組み込み演算子融合やその他の高速化戦略と組み合わせることで、モデル推論を高速化します。利点は、基本的な SD モデルではアクセラレーションを完了するために 1 行のコンパイル コードのみが必要であること、アクセラレーション効果が明白であること、生成効果の差が小さいこと、他のアクセラレーション ソリューション (ディープキャッシュなど) と組み合わせて使用できることです。 , 公式の更新頻度も高いです。欠点については後で説明します。
Stable-fast もモデル コンパイルに基づく高速化ライブラリであり、一連の演算子融合高速化メソッドを組み合わせていますが、そのパフォーマンスの最適化は xformer、triton、torch.jit などのツールに依存しています。
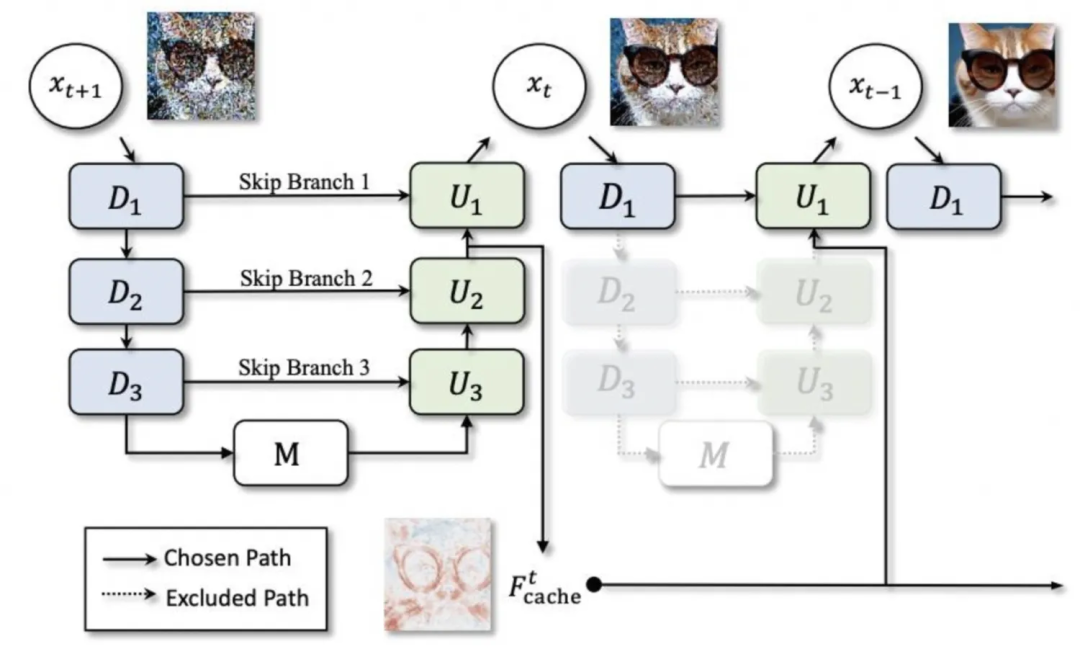
▐モデルのキャッシュ: ディープキャッシュ
▐モデル蒸留: lcm-lora
lcm (Latent Consistency Model) と lora を組み合わせると、lcm は sd モデル全体を抽出して数ステップの推論を実現しますが、lcm-lora は lora の形式を使用して lora 部分のみを最適化し、高速化を実現することもできます。 lora を定期的に使用する場合。

SD1.5加速試験
▐テスト環境
▐テスト結果
-
生成されたイメージを固定シードと比較すると、oneflow コンパイルでは精度をほとんど損なうことなく rt を 40% 以上削減できることがわかります。ただし、新しいパイプラインを初めて使用してイメージを生成する場合、数十の時間がかかります。ウォームアップとして数秒のコンパイル時間がかかります。 -
これに基づいて、Deepcache は rt をさらに 15% ~ 25% 削減できますが、同時に、キャッシュ間隔が増加するにつれて、生成効果の違いがますます明らかになります。 -
oneflowはcontrolnetを使用したSD1.5モデルにも有効です -
安定高速は外部パッケージに大きく依存しており、さまざまなバージョンの問題や外部ツールのエラーが発生しやすく、oneflow と同様に、最初のイメージ生成にある程度のコンパイル時間がかかり、最終的な高速化効果は若干劣ります。ワンフロー。
▐詳細な比較データ
最適化 |
平均生成時間 (秒) 512*512,50ステップ |
加速効果 |
エフェクト1の生成 |
エフェクト2の生成 |
エフェクト3の生成 |
ディフューザー |
3.3701 |
0 |
|
|
|
ディフューザー+BF16 |
3.3669 |
≈0 |
|
|
|
ディフューザー+コントロールネット |
4.7452 |
|
|||
ディフューザー+ワンフローコンピレーション |
1.9857 |
41.08% |
|
|
|
ディフューザー + ワンフロー コンパイル + コントロールネット |
2.8017 |
|
|||
ディフューザー + ワンフロー コンパイル + ディープキャッシュ |
間隔=2:1.4581 |
56.73%(15.65%) |
|
|
|
間隔=3:1.3027 |
61.35%(20.27%) |
|
|
||
間隔=5:1.1583 |
65.63%(24.55%) |
|
|
||
ディフューザー+高速 |
2.3799 |
29.38% |















▐テスト環境
▐テスト結果
基本的なsdxlモデル:
固定シードの条件下では、sdxl モデルは、異なる加速スキームを使用することで画像を生成する効果に影響を与える可能性が高くなります。
Oneflow は rt を 24% しか削減できませんが、それでも生成された画像の精度を保証できます。
Deepcache は、間隔が 2 (つまり、キャッシュが 1 回のみ使用される) の場合、rt は 42% 削減されますが、間隔が 5 の場合、rt は 69% 削減されます。画像も一目瞭然。
lcm-lora は、グラフの生成に必要なステップ数を大幅に削減し、推論の高速化を大幅に実現できますが、事前にトレーニングされた重みを使用する場合、安定性が非常に低く、ステップ数に非常に敏感です。要求された画像と一致する安定した出力を保証する
oneflow と deepcache/lcm-lora は一緒に使用できます
ロラ:
lora をロードすると、ディフューザーの推論速度が大幅に低下します。低下の程度は、使用される lora の種類と量に関係します。
deepcache はまだ機能しており、精度の問題はまだありますが、キャッシュ間隔が短い場合には違いは大きくありません
lora を使用する場合、oneflow コンパイルではシードを修正して元のバージョンとの一貫性を保つことができません。
Oneflow コンパイルは、lora をロードした後の推論速度を最適化します。複数の lora がロードされた場合、推論 rt は lora がロードされていない場合とほぼ同じになり、高速化効果が非常に大きくなります。たとえば、毛糸+水彩を2ローラ同時に使用すると、rtを約65%削減できます。
oneflow は lora のロード時間を若干最適化しましたが、lora ロード後の設定操作時間が増加しました。
▐詳細な比較データ
最適化 |
ローラ |
平均生成時間(秒) 512*512、50step |
Lora のロード時間 (秒) |
lora 変更時間 (秒) |
効果1 |
効果2 |
効果3 |
ディフューザー |
なし |
4.5713 |
|
||||
糸 |
7.6641 |
13.9235 11.0447 |
0.06~0.09 根据配置的lora数量 |
||||
watercolor |
7.0263 |
||||||
yarn+watercolor |
10.1402 |
|
|||||
diffusers+bf16 |
无 |
4.6610 |
|
||||
yarn |
7.6367 |
12.6095 11.1033 |
0.06~0.09 根据配置的lora数量 |
||||
watercolor |
7.0192 |
||||||
yarn+ watercolor |
10.0729 |
||||||
diffusers+deepcache |
无 |
interval=2:2.6402 |
|
||||
yarn |
interval=2:4.6076 |
||||||
watercolor |
interval=2:4.3953 |
||||||
yarn+ watercolor |
interval=2:5.9759 |
|
|||||
无 |
interval=5: 1.4068 |
|
|||||
yarn |
interval=5:2.7706 |
||||||
watercolor |
interval=5:2.8226 |
||||||
yarn+watercolor |
interval=5:3.4852 |
|
|||||
diffusers+oneflow编译 |
无 |
3.4745 |
|
||||
yarn |
3.5109 |
11.7784 10.3166 |
0.5左右 移除lora 0.17 |
||||
watercolor |
3.5483 |
||||||
yarn+watercolor |
3.5559 |
|
|||||
diffusers+oneflow编译+deepcache |
无 |
interval=2:1.8972 |
|
||||
yarn |
interval=2:1.9149 |
||||||
watercolor |
interval=2:1.9474 |
||||||
yarn+watercolor |
interval=2:1.9647 |
|
|||||
无 |
interval=5:0.9817 |
|
|||||
yarn |
interval=5:0.9915 |
||||||
watercolor |
interval=5:1.0108 |
||||||
yarn+watercolor |
interval=5:1.0107 |
|
|||||
diffusers+lcm-lora |
4step:0.6113 |
||||||
diffusers+oneflow编译+lcm-lora |
4step:0.4488 |














AI试衣业务场景使用了算法在diffusers框架基础上改造的专用pipeline,功能为根据待替换服饰图对原模特图进行换衣,基础模型为SD2.1。
根据调研的结果,deepcache与oneflow是优先考虑的加速方案,同时,由于pytorch版本较低,也可以尝试使用较新版本的pytorch进行加速。
▐ 测试环境
A10 + cu118 + py310 + torch2.0.1 + diffusers0.21.4
图生图(示意图,仅供参考):
待替换服饰 |
原模特图 |
|
|


▐ 测试结果
pytorch2.2版本集成了FlashAttention2,更新版本后,推理加速效果明显
deepcache仍然有效,为了尽量不损失精度,可设置interval为2或3
对于被“魔改”的pipeline和子模型,oneflow的图转换功能无法处理部分操作,如使用闭包函数替换forward、使用布尔索引等,而且很多错误原因较难通过报错信息来定位。在进行详细的排查之后,我们尝试了改造原模型代码,对其中不被支持的操作进行替换,虽然成功地在没有影响常规生成效果的前提下完成了改造,通过了oneflow编译,但编译后的生成效果很差,可以看出oneflow对pytorch的支持仍然不够完善
最终采取pytorch2.2.1+deepcache的结合作为加速方案,能够实现rt降低40%~50%、生成效果基本一致且不需要过多改动原服务代码
▐ 详细对比数据
优化方法 |
平均生成耗时(秒) 576*768,25step |
生成效果 |
diffusers |
22.7289 |
|
diffusers+torch2.2.1 |
15.5341 |
|
diffusers+torch2.2.1+deepcache |
11.7734 |
|
diffusers+oneflow编译 |
17.5857 |
|
diffusers+deepcache |
interval=2:18.0031 |
|
interval=3:16.5286 |
|
|
interval=5:15.0359 |
|








目前市面上有很多非常好用的开源模型加速工具,pytorch官方也不断将各种广泛采纳的优化技术整合到最新的版本中。
我们在初期的调研与测试环节尝试了很多加速方案,在排除了部分优化效果不明显、限制较大或效果不稳定的加速方法之后,初步认为deepcache和oneflow是多数情况下的较优解。
但在解决实际线上服务的加速问题时,oneflow表现不太令人满意,虽然oneflow团队针对SD系列模型开发了专用的加速工具包onediff,且一直保持高更新频率,但当前版本的onediff仍存在不小的限制。
如果使用的SD pipeline没有对unet的各种子模块进行复杂修改,oneflow仍然值得尝试;否则,确保pytorch版本为最新的稳定版本以及适度使用deepcache可能是更省心且有效的选择。

相关资料
FlashAttention:
https://github.com/Dao-AILab/flash-attention
https://courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf
oneflow
https://github.com/Oneflow-Inc/oneflow
https://github.com/siliconflow/onediff
stable-fast
https://github.com/chengzeyi/stable-fast
deepcache
https://github.com/horseee/DeepCache
lcm-lora
https://latent-consistency-models.github.io/
pytorch 2.2
https://pytorch.org/blog/pytorch2-2/

我们是淘天集团内容技术AI工程团队,通过搭建完善的算法工程化一站式平台,辅助上千个淘宝图文、视频、直播等泛内容领域算法的工程落地、部署和优化,承接每日上亿级别的数字内容数据,支撑并推动AI技术在淘宝内容社交生态中的广泛应用。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。