

大規模モデル アプリケーションの徹底的な探求により、検索拡張生成テクノロジは広く注目を集め、ナレッジ ベース Q&A、法律顧問、学習アシスタント、Web サイト ロボットなどのさまざまなシナリオに適用されています。
しかし、多くの友人は、ベクトル データベースと RAG の関係と技術原理についてよく知りません。この記事では、RAG 時代の新しいベクトル データベースについて詳しく説明します。
01.
RAG の幅広い用途とその独自の利点
一般的な RAG フレームワークは、Retriever と Generator の 2 つの部分に分けることができます。取得プロセスには、データのセグメント化 (ドキュメントなど)、ベクトルの埋め込み (Embedding)、インデックスの構築 (チャンク ベクトル) が含まれます。その後、ベクトルの取得を通じて関連する結果が呼び出されます。 、生成プロセスは、検索結果 (Context) に基づいて拡張された Prompt を使用して LLM を起動し、回答 (Result) を生成します。
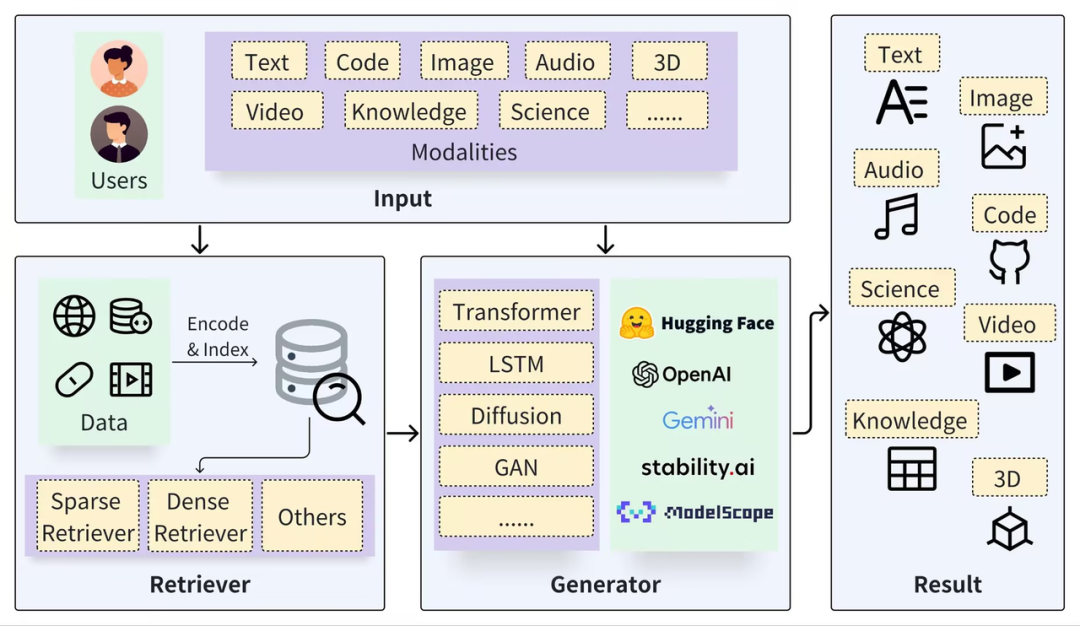
https://arxiv.org/pdf/2402.19473
RAG テクノロジーの鍵は、両方のアプローチの長所を組み合わせていることです。特定の関連する事実とデータを提供する検索システムと、柔軟に回答を構築し、より広範なコンテキストと情報を組み込む生成モデルです。この組み合わせにより、RAG モデルは複雑なクエリを処理し、情報豊富な回答を生成するのに非常に効果的になります。これは、質問応答システム、対話システム、および自然言語の理解と生成が必要なその他のアプリケーションで非常に役立ちます。ネイティブの大規模モデルと比較して、RAG と組み合わせることで、自然に補完的な利点が得られます。
「幻覚」の問題を回避する: RAG は、入力として外部情報を取得することで、大規模モデルが質問に答えるのを支援し、不正確な生成情報に関する質問を大幅に減らし、回答の追跡可能性を高めます。
データのプライバシーとセキュリティ: RAG は、ナレッジ ベースを外部添付ファイルとして使用して、企業または機関のプライベート データを管理し、モデル学習後に制御不能な方法でデータが漏洩するのを防ぐことができます。
情報のリアルタイム性: RAG を使用すると、外部データ ソースから情報をリアルタイムで取得できるため、最新のドメイン固有の知識を取得でき、知識の適時性の問題を解決できます。
大規模モデルに関する最先端の研究も、民間データに基づく微調整やモデル自体の長文処理能力の向上など、上記の課題の解決に向けて行われていますが、これらの研究は大規模モデルの高度化を促進するのに役立ちます。スケールモデル技術。ただし、より一般的なシナリオでは、主に RAG には次の利点があるため、RAG は依然として安定性、信頼性、コスト効率の高い選択肢です。
ホワイトボックス モデル: ファインチューニングや長いテキスト処理の「ブラック ボックス」効果と比較して、RAG モジュール間の関係が明確かつ密接であるため、エフェクト チューニングの操作性と解釈性が向上し、品質と信頼性が向上します。取得およびリコールされたコンテンツの(確実性)は高くありませんが、RAG システムは LLM の介入を禁止し、ナンセンスをでっち上げる代わりに「分からない」と直接応答することもできます。
コストと応答速度: RAG には、微調整されたモデルと比較してトレーニング時間が短くコストが低いという利点があり、長いテキスト処理と比較して応答速度が速く、推論コストが大幅に低くなります。研究や実験の段階では効果と精度が最も魅力的ですが、産業や産業への導入に関してはコストが無視できない決定要因となります。
プライベート データ管理:ナレッジ ベースを大規模モデルから切り離すことで、RAG は安全で実装可能な実用的な基盤を提供するだけでなく、企業の既存のナレッジと新しいナレッジをより適切に管理し、ナレッジの依存性の問題を解決することもできます。もう 1 つの関連する側面は、アクセス制御とデータ管理です。これは、RAG のベース データベースでは簡単に実行できますが、大規模なモデルでは困難です。
したがって、大型モデルの研究が深化するにつれ、RAG 技術は今後も代替されることはなく、今後も重要な地位を維持していくだろうと私は考えています。これは主に、RAG 上に構築されたアプリケーションが多くの分野で活躍できるようにする LLM との自然な相補性によるものです。 RAG 改善の鍵は、一方では LLM 機能の向上であり、他方では、取得 (Retrieval) のさまざまな改善と最適化に依存しています。
02.
RAG 検索の基盤: ベクトル データベース
業界の実践では、RAG 検索は通常、ベクトル データベースと密接に統合されており、CVP テクノロジー スタックと呼ばれる、ChatGPT + ベクトル データベース + プロンプトに基づく RAG ソリューションも誕生しました。このソリューションは、ベクトル データベースを利用して関連情報を効率的に取得し、LLM によって生成されたクエリをベクトルに変換することで、RAG システムはベクトル データベース内の対応するナレッジ エントリを迅速に見つけることができます。この検索メカニズムにより、LLM は特定の問題に直面したときにベクトル データベースに保存されている最新情報を利用できるようになり、LLM に固有の知識更新の遅延と錯覚の問題が効果的に解決されます。
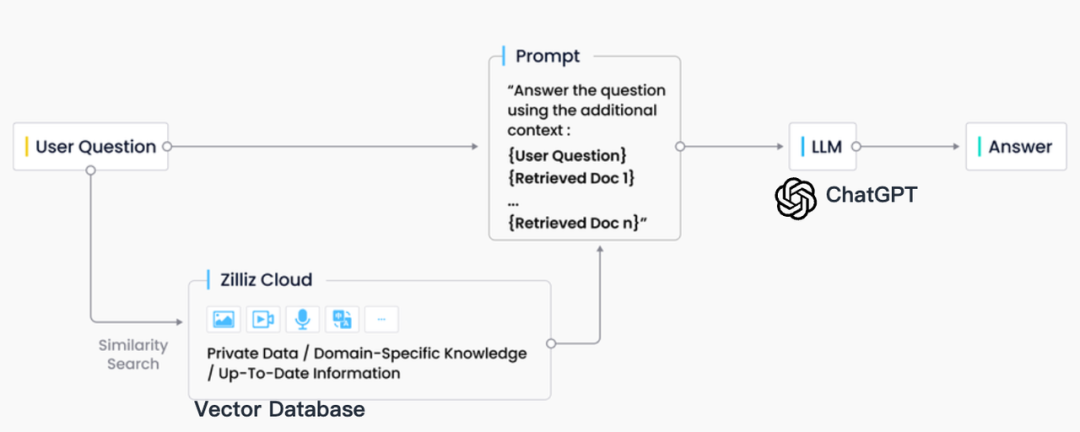
情報検索の分野には、検索エンジン、リレーショナル データベース、ドキュメント データベースなど、多くの保存および検索テクノロジがありますが、RAG シナリオではベクトル データベースが業界の最初の選択肢となっています。この選択の背景には、多数の埋め込みベクターを効率的に保存および取得できるベクター データベースの優れた機能があります。これらの埋め込みベクトルは機械学習モデルによって生成され、テキストや画像などの複数のデータ タイプを特徴付けるだけでなく、それらの深い意味情報もキャプチャできます。 RAG システムでは、検索タスクは、入力クエリのセマンティクスに最も一致する情報を迅速かつ正確に見つけることであり、ベクトル データベースは、高次元ベクトル データの処理と高速な類似性検索の実行において顕著な利点を備えています。
以下は、ベクトル検索で代表されるベクトル データベースと他の技術オプションの水平比較と、それを RAG シナリオで主流の選択にする重要な要素の分析です。
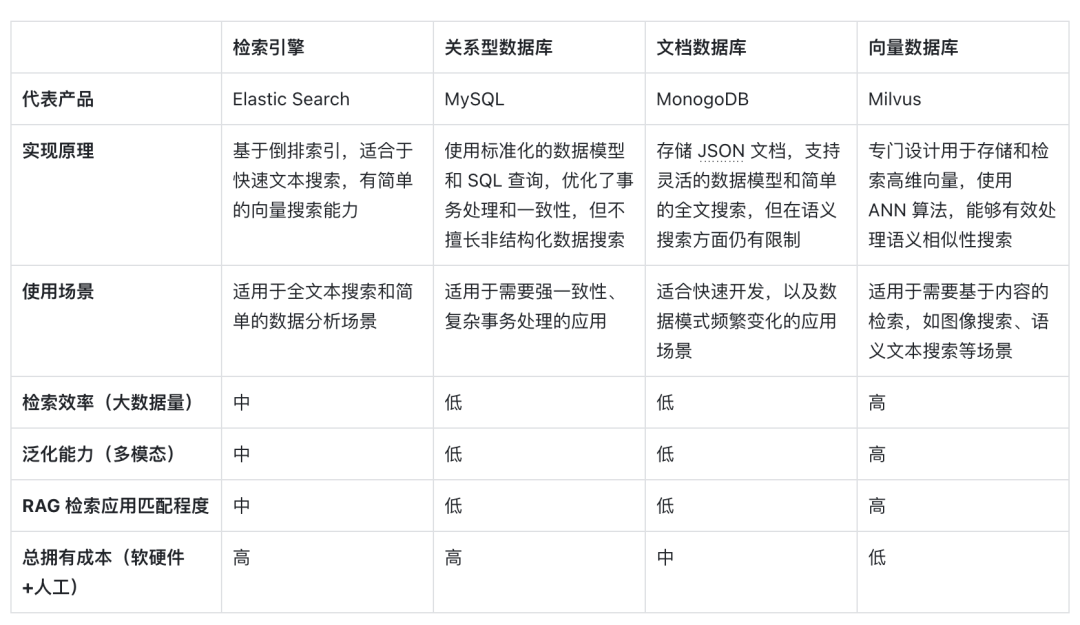
まず、実装原理の観点から言えば、ベクトルはモデルの意味論的な意味のエンコード形式であり、ベクトル データベースはキーワードの一致だけでなくテキストの意味をエンコードする深層学習モデルの機能を活用するため、クエリの意味論的な内容をよりよく理解できます。 。 AI モデルの開発の恩恵を受けて、その背後にある意味の精度も着実に向上しており、意味の類似性を表現するためにベクトル距離の類似性を使用することが、情報媒体を処理するための最初の選択肢となっています。
第二に、検索効率の点で、情報は高次元のベクトルとして表現できるため、特別なインデックスの最適化と定量化の手法をベクトルに追加できます。これにより、データ量が増加するにつれて、検索効率が大幅に向上し、ストレージコストが圧縮されます。ベクトル データベースは水平方向に拡張でき、クエリ応答時間を維持できます。これは大量のデータを処理する必要がある RAG システムにとって重要であるため、ベクトル データベースは非常に大規模な非構造化データの処理に優れています。
一般化能力の次元に関しては、ほとんどの従来の検索エンジン、リレーショナル データベースやドキュメント データベースはテキストのみを処理でき、ベクトル データベースはテキスト データに限定されず、画像、音声、その他の非構造化データも処理できます。 . タイプの埋め込みベクトルであり、RAG システムをより柔軟で多用途にします。
最後に、総所有コストの観点から見ると、ベクター データベースは他のオプションと比べて展開が容易で使いやすく、豊富な API も提供しているため、既存の機械学習フレームワークやワークフローとの統合が容易であるため、人気があります。多くの RAG アプリケーション開発者のお気に入りです。
ベクトル検索は、その意味理解能力、高い検索効率、およびマルチモダリティの汎化サポートにより、大規模モデルの時代における理想的な RAG 検索ツールとなっています。AI と埋め込みモデルのさらなる発展により、これらの利点はさらに顕著になる可能性があります。将来。
03.
RAG シナリオにおけるベクトル データベースの要件
虽然向量数据库成为了检索的重要方式,但随着 RAG 应用的深入以及人们对高质量回答的需求,检索引擎依旧面临着诸多挑战。这里以一个最基础的 RAG 构建流程为例:检索器的组成包括了语料的预处理如切分、数据清洗、embedding 入库等,然后是索引的构建和管理,最后是通过 vector search 找到相近的片段提供给 prompt 做增强生成。大多数向量数据库的功能还只落在索引的构建管理和搜索的计算上,进一步则是包含了 embedding 模型的功能。
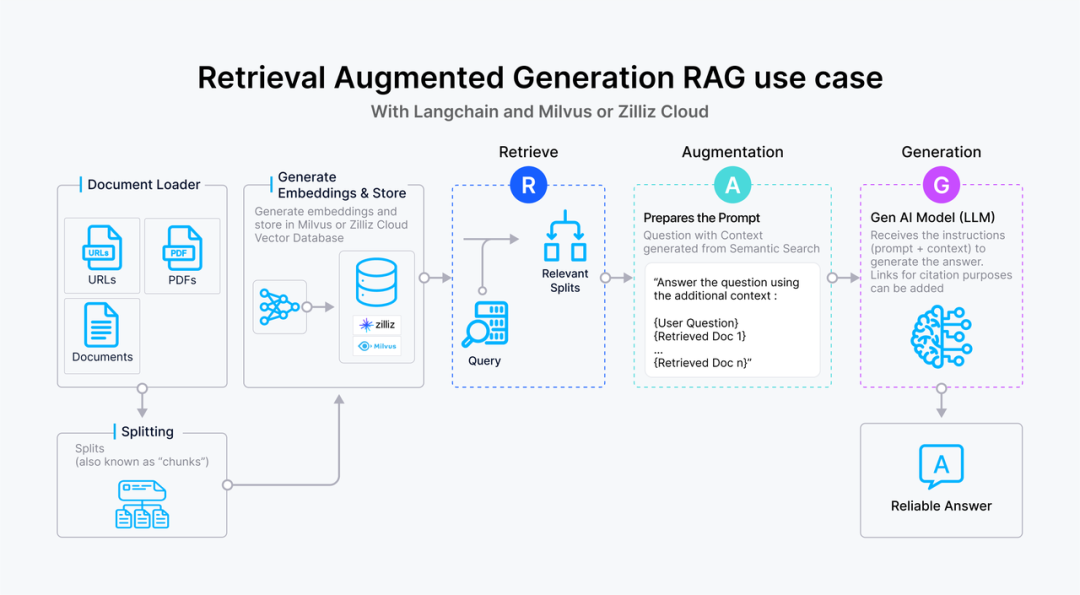
但在更高级的 RAG 场景中,因为召回的质量将直接影响到生成模型的输出质量和相关性,因此作为检索器底座的向量数据库应该更多的对检索质量负责。为了提升检索质量,这里其实有很多工程化的优化手段,如 chunk_size 的选择,切分是否需要 overlap,如何选择 embedding model,是否需要额外的内容标签,是否加入基于词法的检索来做 hybrid search,重排序 reranker 的选择等等,其中有不少工作是可以纳入向量数据库的考量之中。而检索系统对向量数据库的需求可以抽象描述为:
高精度的召回:向量数据库需要能够准确召回与查询语义最相关的文档或信息片段。这要求数据库能够理解和处理高维向量空间中的复杂语义关系,确保召回内容与查询的高度相关性。这里的效果既包括向量检索的数学召回精度也包括嵌入模型的语义精度。
快速响应:为了不影响用户体验,召回操作需要在极短的时间内完成,通常是毫秒级别。这要求向量数据库具备高效的查询处理能力,以快速从大规模数据集中检索和召回信息。此外,随着数据量的增长和查询需求的变化,向量数据库需要能够灵活扩展,以支持更多的数据和更复杂的查询,同时保持召回效果的稳定性和可靠性。
处理多模态数据的能力:随着应用场景的多样化,向量数据库可能需要处理不仅仅是文本,还有图像、视频等多模态数据。这要求数据库能够支持不同种类数据的嵌入,并能根据不同模态的数据查询进行有效的召回。
可解释性和可调试性:在召回效果不理想时,能够提供足够的信息帮助开发者诊断和优化是非常有价值的。因此,向量数据库在设计时也应考虑到系统的可解释性和可调试性。
RAG 场景中对向量数据库的召回效果有着严格的要求,不仅需要高精度和快速响应的召回这类基础能力,还需要处理多模态数据的能力以及可解释性和可调试性这类更高级的功能,以确保生成模型能够基于高质量的召回结果产生准确和相关的输出。在多模态处理、检索的可解释性和可调试性方面,向量数据库仍有许多工作值得探索和优化,而 RAG 应用的开发者也急需一套端到端的解决方案来达到高质量的检索效果。
本文作者


本文分享自微信公众号 - ZILLIZ(Zilliztech)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。