
高カーディナリティとは
カーディナリティは、数学では、セット内の要素の数を表すために使用されるスカラーとして定義されます。たとえば、有限セット A = {a, b, c} のカーディナリティは 3 です。無限セットのカーディナリティの概念もあります。今日は主にコンピュータの分野について話します。ここでは詳しく説明しません。
データベースのコンテキストでは、カーディナリティの厳密な定義はありませんが、カーディナリティに関する全員のコンセンサスは数学の定義に似ています。カーディナリティは、データ列に含まれるさまざまな値の数を測定するために使用されます。たとえば、ユーザーを記録するデータ テーブルには通常、複数の列があり、UIDのカーディナリティはほど高くなく、の列には比較的少ない値が含まれる可能性があります。したがって、ユーザー テーブルの例では、列は高基底に属し、列は低基底に属すると言えます。NameGenderUIDIDNameUIDGenderUIDGender
時系列データベースの分野にさらに細分化すると、カーディナリティはタイムラインの数を指すことがよくあります。例として、観測可能なフィールドでの時系列データベースのアプリケーションを取り上げます。 API サービス。最も単純な例を挙げると、さまざまなインスタンスの API サービスの各インターフェイスの応答時間には、 と の 2 つのラベルがあります。API RoutesインターフェイスInstanceが 20 個、インスタンスが 5 個ある場合、タイムラインのベースは (20+1)x(5) になります。 +1)-1 = 125 (+1インスタンスのすべてのインターフェースの応答時間、またはすべてのインスタンスのインターフェースの応答時間を個別に表示できることを考慮すると)、値は大きくないようですが、注意が必要です。オペレーターは製品であるため、ラベルのカーディナリティが高いか、新しいラベルが追加されると、タイムラインのカーディナリティは大幅に増加します。
なぜそれが重要なのか
ご存知のとおり、誰もがよく知っている MySQL などのリレーショナル データベースには、通常、ID 列のほかに、電子メール、注文番号などの一般的な列があります。これらはカーディナリティの高い列であり、あまり聞いたことはありません。ただし、このようなデータ モデリングにより、特定の問題が発生します。実際のところ、私たちがよく知っている OLTP 分野では、高カーディナリティは問題にならないことがよくありますが、タイミング分野では、データ モデルが原因で問題が発生することがよくあります。タイミング分野に入る前に、やはり最初にそれについて説明します。高ベースのデータセットが実際に何を意味するかを見てみましょう。
私の考えでは、平たく言えば、データベースの場合、高ベースのデータセットは大量のデータを意味し、データ量の増加は、特に書き込み、クエリ、ストレージに必然的に影響を及ぼします。書くときのインパクトが指標になります。
従来のデータベースの高いカーディナリティ
リレーショナル データベースでインデックスを作成するために使用される最も一般的なデータ構造である B ツリーを例に挙げます。通常、挿入とクエリの複雑さは O(logN) です。 N は要素の数であり、これが私たちが話しているカーディナリティです。当然、Nが大きいほど一定の影響はありますが、挿入やクエリの複雑さは自然対数となるため、データ量がそれほど大きくない場合は影響はそれほど大きくありません。
したがって、高基準データは無視できない影響をもたらすものではなく、逆に、多くの場合、高基準データのインデックスは、低基準データのインデックスよりも選択的であると考えられます。クエリ条件を使用して、条件を満たさない部分的なデータを除外できるため、データベース アプリケーションでは、過剰なディスク I/O オーバーヘッドを回避する必要があります。たとえばselect * from users where gender = "male";、結果として得られるデータ セットは非常に大きくなり、ディスク I/O とネットワーク I/O も非常に大きくなります。実際には、このカーディナリティの低いインデックスを単独で使用することはあまり意味がありません。
時系列データベースの高いカーディナリティ
では、高基数のデータ列が問題を引き起こす原因となる時系列データベースの違いは何でしょうか?時系列データの分野では、データ モデリングであってもエンジン設計であっても、中心はタイムラインを中心に回転します。前述したように、時系列データベースにおける高カーディナリティの問題は、タイムラインの数とサイズを指します。このサイズは、1 つの列のカーディナリティだけではなく、すべてのラベル列のカーディナリティの積によって非常に大きくなります。一般的なリレーショナル データベースでは、高基底は特定の列に分離されており、つまりデータ スケールは線形に増加しますが、時系列データベースでは高基底は複数の列の積であり、非線形であることがわかります。成長。時系列データベースで高基準タイムラインがどのように生成されるかを詳しく見てみましょう。まず最初のシナリオを見てみましょう。
時系列数量
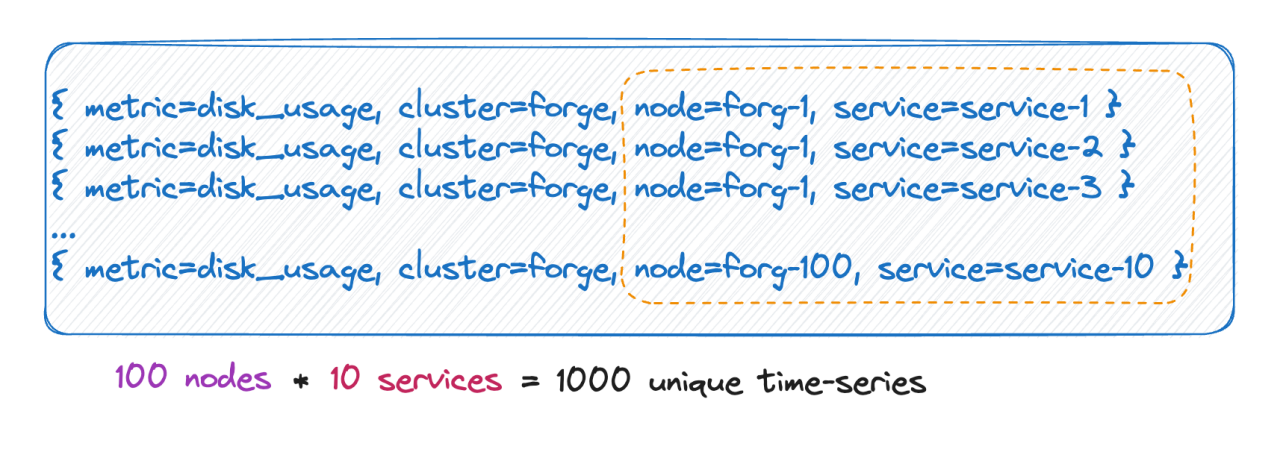
タイムラインの数は、実際にはすべてのラベル ベースのデカルト積に等しいことがわかっています。上の図に示すように、タイムラインの数は 100 * 10 = 1000 タイムラインとなり、このメトリックに 6 つのタグが追加されると、各タグ値には 10 個の値が含まれ、タイムラインの数は 10^9、つまり 1 億になります。タイムラインを見れば、この大きさが想像できるでしょう。
タグには無限の値があります
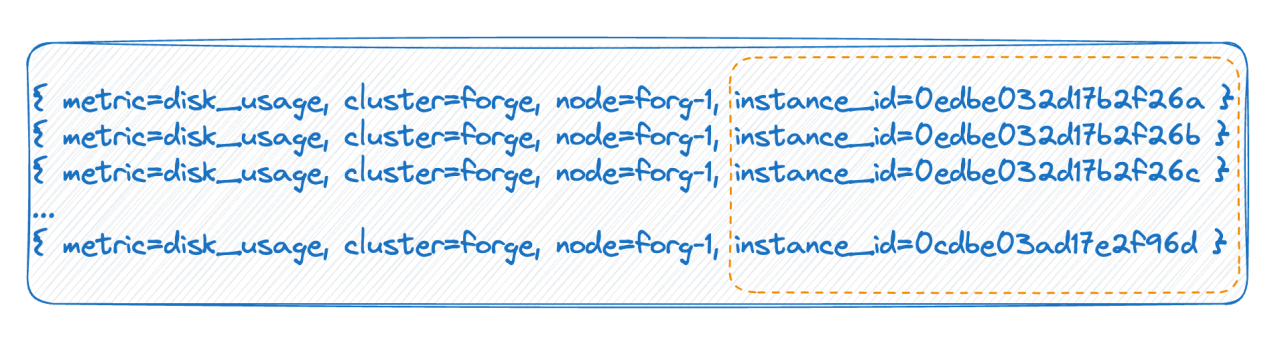
2 番目のケースでは、たとえばクラウドネイティブ環境では、各ポッドに ID があり、再起動されるたびにポッドが実際に削除されて再構築され、新しい ID が生成されるため、タグ値が非常に大きくなります。タイムラインの数は多数あり、完全に再起動するたびにタイムラインの数が 2 倍になります。上記の 2 つの状況は、時系列データベースで言及されている高いカーディナリティの主な理由です。
時系列データベースがデータを整理する方法
私たちは、カーディナリティがどの程度高くなるかを知っており、それがどのような問題を引き起こすかを理解する必要があります。また、主流の時系列データベースがデータをどのように編成するかについても理解する必要があります。
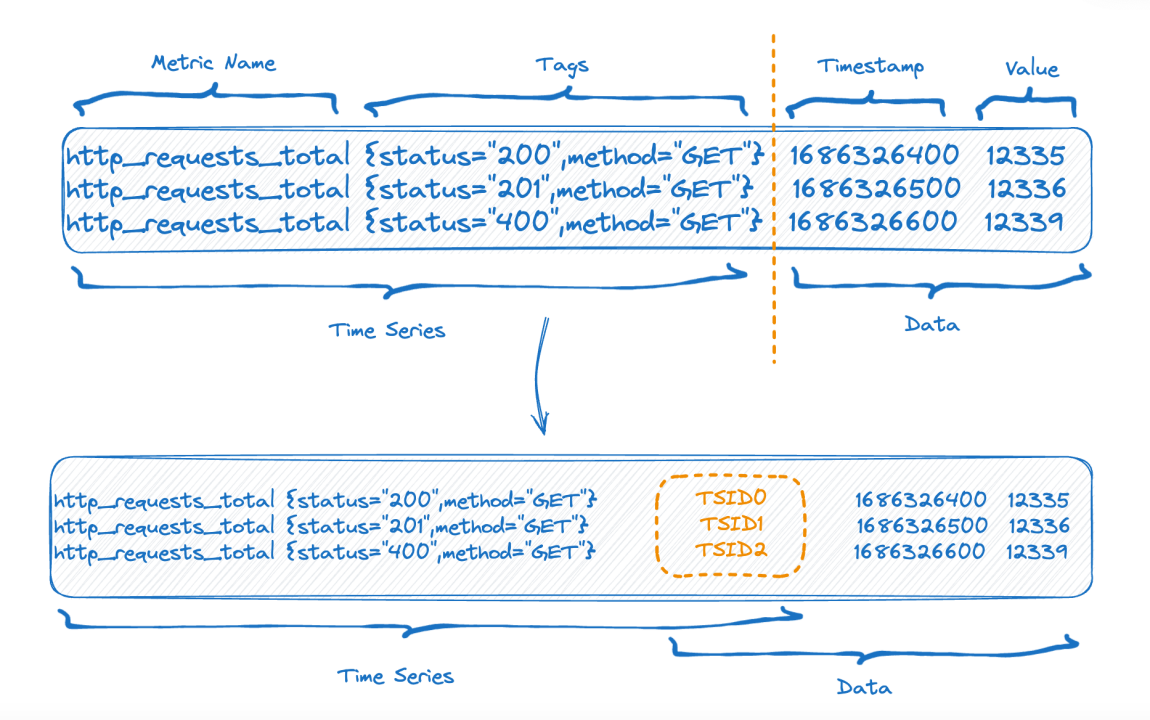
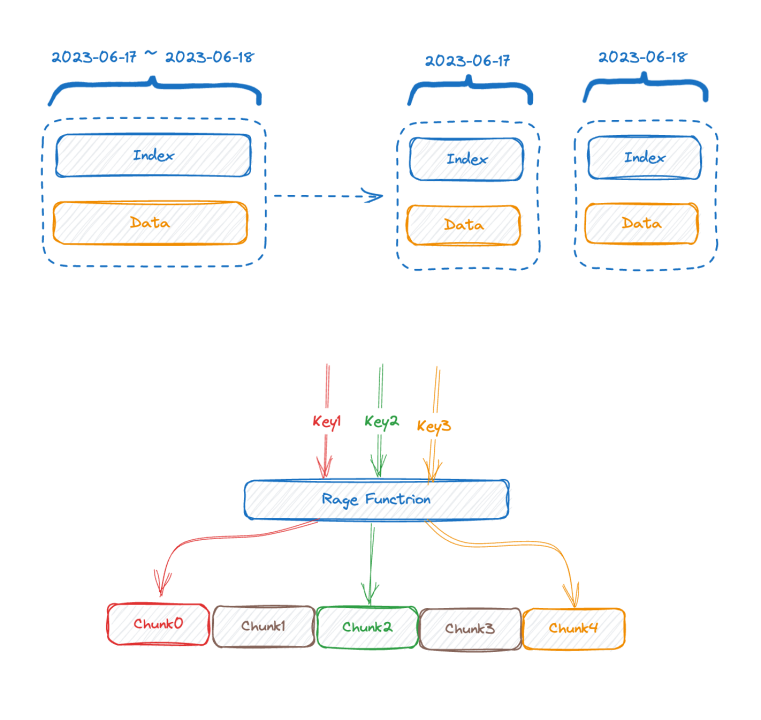
図の上半分はデータを書き込む前の表現、図の下半分は左側が時系列部分のインデックスデータ、右側がデータ格納後の論理表現を示しています。一部。
各時系列は一意の TSID を生成でき、インデックスとデータは TSID を通じて関連付けられます。このインデックスは反転インデックスです。
メモリ内の転置インデックスを表す以下の図を見てみましょう。
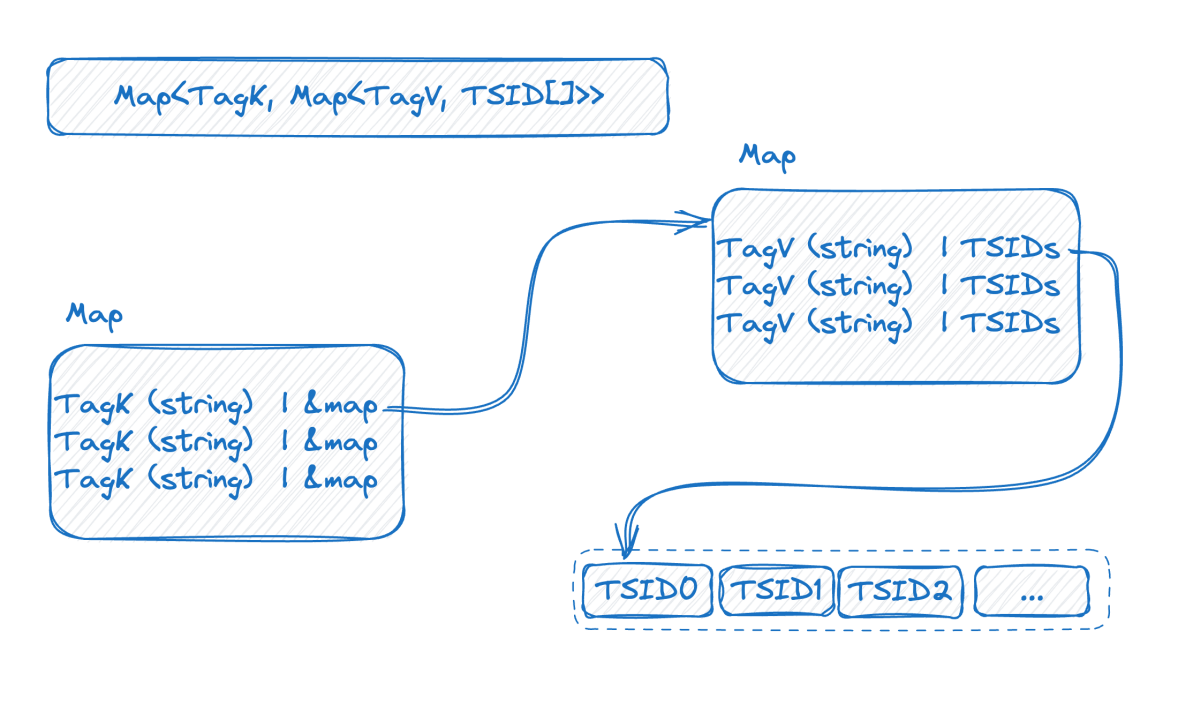
これは 2 層のマップです。外側の層は、最初にタグ名を通じて内側のマップを見つけます。V は、対応するタグ値を含む TSID のセットです。
この時点で、前回の紹介と組み合わせると、時系列データのベースが高いほど、2 層マップが大きくなることがわかります。インデックスの構造を理解した後、高ベーシスの問題がどのように発生するかを理解することができます。
高スループットの書き込みを実現するには、このインデックスをメモリ内に保持することが最善です。カーディナリティが高いとインデックスが拡張され、インデックスをメモリに収めることができなくなります。メモリを保存できない場合は、ディスクにスワップする必要があります。ディスクにスワップした後は、大量のランダムなディスク IO が発生するため、書き込み速度が影響を受けます。もう一度クエリを見てみましょう。インデックス構造から、クエリ条件などのクエリのプロセスを推測できます。そのプロセスは、まずkey でマップをwhere status = 200 and method="get"検索し、次にすべての TSID セットを取得して確認することです。再度同じように条件を設定し、2 つの TSID セットの交差後に得られる新しい TSID セットを使用して、TSID に従ってデータを 1 つずつ取得します。status"200"
問題の核心は、データがタイムラインに従って整理されていることであるため、まずタイムラインを取得し、次にタイムラインに従ってデータを見つける必要があることがわかります。クエリに関与するタイムラインが増えるほど、クエリは遅くなります。
解決方法
私たちの分析が正しく、時系列データの分野における高基底問題の原因がわかっていれば、問題の原因を見てみましょう。
- データ レベル: C(L1) * C(L2) * C(L3) * ... * C(Ln) によって引き起こされるインデックスのメンテナンスとクエリの課題。
- 技術レベル: データはタイムラインに従って編成されているため、最初にタイムラインを取得してから、タイムラインに従ってデータを検索する必要があります。タイムラインが多い場合、クエリは遅くなります。
編集者は、次の 2 つの側面からソリューションについて説明します。
データモデリングの最適化
1 不要なラベルを取り除く
誤って不要なフィールドをラベルとして設定してしまい、タイムラインが肥大化してしまうことがよくあります。たとえば、サーバーのステータスを監視する場合、多くの場合、 、 が表示されますinstance_name。ip実際には、これら 2 つのフィールドのうちの 1 つがラベルになる必要はなく、もう 1 つは属性として設定できます。
2. 実際のクエリに基づいたデータモデリング
モノのインターネットにおけるセンサー監視を例に挙げます。
- 10ワットデバイス
- 100地域
- 10台のデバイス
Prometheus でメトリクスにモデル化すると、タイムラインは 10w * 100 * 10 = 1 億になります。 (厳密でない計算) 考えてみてください、クエリはこのように実行されるでしょうか?たとえば、特定の地域の特定のタイプの機器のタイムラインをクエリするにはどうすればよいでしょうか?これは不合理に思えます。デバイスが指定されるとタイプが決定されるため、実際には 2 つのラベルが一緒である必要はなく、次のようになります。
- metric_one: 10w デバイス
- metric_two:
- 100地域
- 10台のデバイス
- metric_three: (データを収集するためにデバイスが別のリージョンに移動される可能性があると想定)
- 10ワットデバイス
- 100地域
合計は、 10w + 100 10 + 10w 100 ~ 1010wのタイムラインとなり、上記の 10 分の 1 になります。
3. 貴重な高ベースタイムラインデータを分別管理
もちろん、データ モデリングがクエリと非常に一致しているにもかかわらず、データの規模が大きすぎるためにタイムラインを短縮できない場合は、このコア インジケーターに関連するすべてのサービスをより優れたマシンに配置します。
時系列データベース技術の最適化
- 最初の効果的な解決策は、垂直セグメンテーションです。業界のほとんどの主流の時系列データベースは、多かれ少なかれ、時間に応じてインデックスをセグメント化する同様の方法を採用しています。これは、このセグメント化が行われていない場合、時間の経過とともにインデックスが拡大してしまうためです。時間が経つにつれてメモリに保存できなくなり、古いインデックス チャンクをディスクまたはリモート ストレージにスワップすることができます。少なくとも書き込みには影響しません。
- 垂直セグメンテーションの反対は水平セグメンテーションです。シャーディング キーは通常、クエリ述語の使用頻度が最も高い 1 つまたは複数のタグであり、これらのタグの値に基づいて実行されます。分散分割統治のアイデアにより、単一マシン上のボトルネックが解決されますが、代償として、クエリ条件にシャーディング キーが含まれていない場合、演算子をプッシュダウンすることができず、データは計算用の最上位層。
上記 2 つの方法は従来の解決策であり、問題をある程度軽減することはできますが、問題を根本的に解決することはできません。次の 2 つのソリューションは従来のソリューションではありませんが、GreptimeDB が探求しようとしている方向性です。ここでは詳細な分析は行わずに簡単に説明します。参考までに。
-
TimescaleDB は B ツリー インデックスを使用しますが、InfluxDB_IOx は逆インデックスを持たず、カーディナリティの高いクエリの場合、OLAP データベースで一般的に使用されるパーティション スキャンを min-max と組み合わせて使用します。インデックスの枝刈りの最適化を実行すると、効果はさらに良くなるでしょうか?
-
非同期のスマートなインデックス作成: スマートにするには、まず動作を分析して、ユーザーの各クエリのクエリを高速化するために、非同期的にインデックスを作成する必要があります。それに対して反転は作成されません。上記 2 つの解決策を組み合わせると、書き込み時に反転が非同期で構築されるため、書き込み速度にはまったく影響しません。
クエリをもう一度見てみると、時系列データには時間属性があるため、最新の時間バケットにインデックスを付けることはできません。解決策は、ハード スキャンを実行し、プルーニングの最適化のためにいくつかの最小値と最大値のインデックスを組み合わせることです。数千万または数億のラインを数秒でスキャンすることは依然として可能です。
クエリが来た場合、まずそれに関係するタイムラインの数を見積もります。クエリの量が少ない場合は反転を使用し、クエリが大量に含まれる場合は反転せずに直接スキャン + フィルターに進みます。
私たちは上記のアイデアをまだ模索中であり、まだ完璧ではありません。
結論
高いベースが常に問題になるわけではありません。必要となるのは、自社のビジネス状況と使用するツールの性質に基づいて独自のデータ モデルを構築することです。もちろん、ツールには特定のシナリオ制限がある場合があります。たとえば、Prometheus はデフォルトで各メトリックにラベルを付けますが、これは単一マシンのシナリオでは大きな問題ではなく、ユーザーにとっても便利です。大規模なデータを扱う場合には限界があります。 GreptimeDB は、スタンドアロン シナリオと大規模シナリオの両方で統合ソリューションを作成することに取り組んでおり、高ベースの問題に対する技術的な試みも検討しており、誰でもそれについて議論することを歓迎します。
参照
- https://en.wikipedia.org/wiki/カーディナリティ
- https://www.cncf.io/blog/2022/05/23/what-is-high-cardinality/
- https://grafana.com/blog/2022/10/20/how-to-manage-high-cardinality-metrics-in-prometheus-and-kubernetes/
グレップタイムについて:
Greptime Greptime Technology は、スマート カー、モノのインターネット、可観測性など、大量の時系列データを生成する分野にリアルタイムで効率的なデータ ストレージと分析サービスを提供し、顧客がデータの深い価値を発掘できるよう支援することに取り組んでいます。現在、主な製品は次の 3 つです。
-
GreptimeDB は、Rust 言語で書かれた時系列データベースであり、分散型、オープンソース、クラウド ネイティブであり、企業が長期ストレージ コストを削減しながら、リアルタイムで時系列データの読み取り、書き込み、処理、分析を行うのに役立ちます。
-
GreptimeCloud は、可観測性、モノのインターネット、その他の分野と高度に統合できるフルマネージド DBaaS サービスをユーザーに提供できます。
-
GreptimeAI は、LLM アプリケーション向けに調整された可観測性ソリューションです。
-
車両とクラウドの統合ソリューションは、自動車会社の実際のビジネス シナリオに深く入り込み、企業の車両データが急激に増加した後の実際のビジネスの問題点を解決する時系列データベース ソリューションです。
GreptimeCloud と GreptimeAI は正式にテストされています。最新の開発状況については、公式アカウントまたは公式 Web サイトをフォローしてください。 GreptimDB のエンタープライズ バージョンに興味がある場合は、アシスタントに連絡してください (アシスタントを追加するには、WeChat で greptime を検索してください)。
公式サイト:https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
ドキュメント: https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
スラック: https://www.greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime
1990 年代生まれのプログラマーがビデオ移植ソフトウェアを開発し、1 年足らずで 700 万以上の利益を上げました。結末は非常に罰的でした。 高校生が成人式にオープンソースプログラミング言語を自作―ネチズンの鋭いコメント: 詐欺横行でRustDesk依存、国内サービスの タオバオ(taobao.com)は国内サービスを一時停止、ウェブ版の最適化作業を再開 Java最も一般的に使用されている Java LTS バージョンは 17 、Windows 11 は減少し続ける Open Source Daily | Google がオープンソースの Rabbit R1 を支持、Microsoft の不安と野心; Electricがオープンプラットフォームを閉鎖 AppleがM4チップをリリース GoogleがAndroidユニバーサルカーネル(ACK)を削除 RISC-Vアーキテクチャのサポート Yunfengがアリババを辞任し、将来的にはWindowsプラットフォーム用の独立したゲームを制作する予定