
eBPF コードの魔法。ピア アドレスを TCP ストリームに直接伝播して通信トポロジを再構築します。
「非侵入的な方法で Kubernetes アプリケーションのネットワーク トポロジを構築する」作者 Ilya Shakhat の記事。
導入
Kubernetes アプリケーションは論理的に 2 つの部分に分割されます。1 つの部分はコンピューティング リソース (ポッドで表されます) であり、もう 1 つの部分はアプリケーションへのアクセスを提供します (サービスで表されます)。アプリケーション クライアントは、実際にどのポッドがリクエストを処理するかを気にすることなく、抽象名を使用してそれにアクセスできます。また、1 つのサービスにバックエンドとして複数のポッドがある場合があるため、ロード バランサーとしても機能します。デフォルトの Kubernetes デプロイメントでは、この負荷分散機能は非常に単純な iptables または Linux IPVS を使用して実装されます。どちらも L4 (TCP など) レイヤーで動作し、単純なランダムベースのラウンドロビン メカニズムを実装します。もちろん、クラウド プロバイダーは、アプリケーションを公開するためのより従来型の負荷分散ソリューションを提供することもできますが、まずは簡単に始めましょう。
Kubernetes にデプロイされたアプリケーションで発生する可能性のあるさまざまな問題について考えると、クライアント リクエストの処理の具体的なインスタンスを理解する必要がある問題のクラスが存在します。例: (1) アプリケーション Pod がネットワーク接続が不十分なホストにデプロイされており、新しい接続の確立に他の Pod よりも時間がかかる、または (2) Pod のパフォーマンスが時間の経過とともに低下する一方で、他の Pod のパフォーマンスは安定している、または (3) 特定のクライアントのリクエストがアプリケーションのパフォーマンスに影響を与える。分散トレースは、多くの場合、このような問題について洞察を得る方法の 1 つであり、明らかに、クライアント リクエストからバックエンド アプリケーションへのパスをトレースするために使用されます。従来、分散トレースには何らかの形式のインストルメンテーションが必要であり、手動によるコードの追加からランタイムへの完全に自動化されたインジェクションに移行する可能性があります。しかし、クライアント コードをまったく変更せずに同じ効果を達成できるでしょうか?
上記の問題をデバッグするには、基本的に分散トレースの 2 つの機能が必要です。(1) リクエストのレイテンシーに関連するメトリクスを収集すること、および (2) 各リクエストの行き先を正確に把握することです。最初の機能は、eBPF (カーネル関数に動的にプローブを接続できるテクノロジ) によってサポートされる多数のツールの 1 つを使用して、非侵入的な方法で簡単に実装できます。たとえば、新しい接続を確立したプロセスのログ、ソケット/接続関連のメトリクスの取得などです。さらに、再送信や悪意のある接続リセットもチェックします。 openEuler エコシステムでは、そのようなツールは gala-gopher であり、ソケット、TCP、L7/HTTP(s) プローブなど、多数の異なるプローブを提供します。ただし、2 番目の機能 (個々のリクエストの宛先を知る) を達成するのははるかに困難です。分散トレース フレームワークでは、これはアプリケーション ペイロードにスパン/トレース ID を挿入し、同じスパン ID を使用してクライアントとバックエンドの両方からの観測値を相関させることによって実現されます。アプリケーション コードに侵入しないということは、同じ情報を一般的な方法で注入する必要があることを意味しますが、これをアプリケーション プロトコルに行うことは、送信トラフィックを傍受し、解析し、ID とそのトラフィックを注入する必要があるため、単純に現実的ではありません。シリアル化されて転送されます。サービス メッシュを再発明したようです。
先に進む前に、ネットワーク監視で利用できるデータを見てみましょう。ここでは、モニターがアプリケーション Pod をホストしているすべてのノードから情報を取得し、このデータが Prometheus などによって処理されることを想定しています。集めてください。これを実現するには、実験環境が必要です。
テスト環境
まず、デプロイされたマルチノード Kubernetes クラスターが必要です。 Huawei Cloud では、対応するサービスは Cloud Container Engine (CCE) と呼ばれます。
次に、テスト アプリケーションが必要になります。このために、HTTP リクエストを受け入れ、元のリクエストで指定されたアドレスに発信 HTTP リクエストを送信できる、非常に単純な Python プログラムを使用します。このようにして、アプリケーションを簡単にリンクできます。
これらのアプリケーションには、ラテン文字の A、B などの名前が付けられます。アプリケーション A は、デプロイメント A およびサービス A としてデプロイされ、以下同様になります。最初のアプリケーションも外部に公開され、外部から呼び出すことができます。
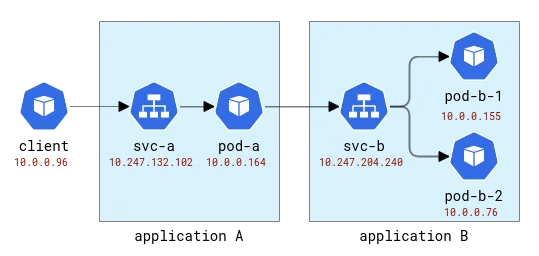
A および B アプリケーション トポロジ
Kubernetes では、Gala-gopher はデーモン セットとしてデプロイされ、すべての Kubernetes ノードで実行されます。 Prometheus によって使用され、最終的に Grafana によって視覚化されるメトリクスを提供します。サービス トポロジはメトリクスに基づいて構築され、NodeGraph プラグインによって視覚化されます。
可観測性
次のように、いくつかのリクエストをアプリケーション A に送信し、アプリケーション B に転送してみましょう。
[root@debug-7d8bdd568c-5jrmf /]# curl http://a.app:8000/b.app:8000
..Hello from pod b-67b75c8557-698tr ip 10.0.0.76 at node 192.168.3.218
Hello from pod a-7954c595f7-tmnx8 ip 10.0.0.148 at node 192.168.3.14
[root@debug-7d8bdd568c-5jrmf /]# curl http://a.app:8000/b.app:8000
..Hello from pod b-67b75c8557-mzn6p ip 10.0.0.149 at node 192.168.3.14
Hello from pod a-7954c595f7-tmnx8 ip 10.0.0.148 at node 192.168.3.14
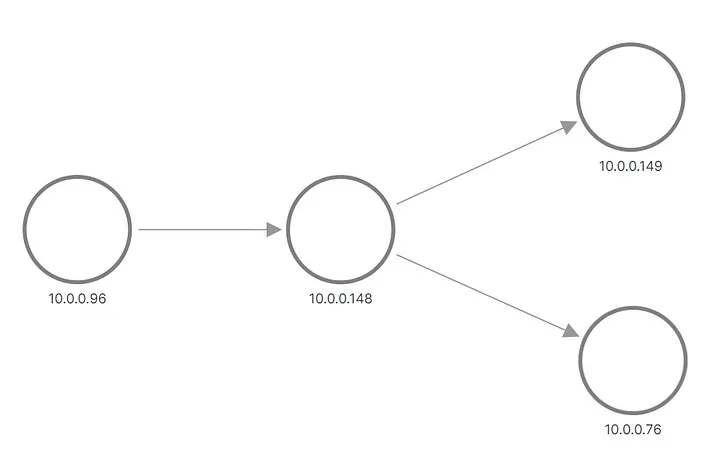
出力では、アプリケーション B のリクエストの 1 つが 1 つのポッドに送信され、もう 1 つのリクエストが別のポッドに送信されたことがわかります。 Grafana でトポロジがどのように表示されるかは次のとおりです。
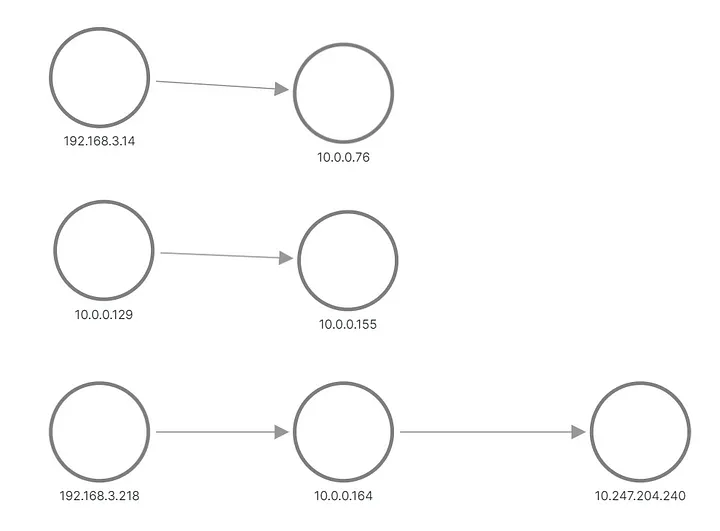
A と B はメトリックから再構築されたトポロジを適用します
上の行と真ん中の行は、アプリケーション B のポッドにリクエストを送信するものを示し、下部の行は、サービス B の仮想 IP にリクエストを送信する A のポッドの 1 つを示します。しかし、これは私たちが期待していたものとはまったく異なりますね。ノード間にリンクのない 3 セットのノードのみが表示されます。 192.168.3.0/24 サブネットの IP アドレスはクラスター プライベート ネットワーク (VPC) のノード アドレスであり、10.0.0.1/24 はポッド アドレスです。ただし、イントラ ネットワークに使用されるノード アドレスである 10.0.0.129 は除きます。ノード通信。
現在、これらのメトリクスはソケット レベルで収集されます。つまり、それらはアプリケーション プロセスが認識できるものとまったく同じです。収集は eBPF プローブを介して行われるため、最初のアイデアは、オペレーティング システム カーネルがソケットで入手可能な情報よりもアプリケーション接続について詳しいかどうかを確認することです。クラスターはデフォルトの CNI で構成され、Kubernetes サービスは iptables ルールとして実装されます。 iptables-save の出力には構成が表示されます。最も興味深いのは、実際に負荷分散を構成する次のルールです。
-A KUBE-SERVICES -d 10.247.204.240/32 -p tcp -m comment
--comment "app/b:http-port cluster IP" -m tcp --dport 8000 -j KUBE-SVC-CELO6J2CXNI7KVVA
-A KUBE-SVC-CELO6J2CXNI7KVVA -d 10.247.204.240/32 -p tcp -m comment
--comment "app/b:http-port cluster IP" -m tcp --dport 8000 -j KUBE-MARK-MASQ
-A KUBE-SVC-CELO6J2CXNI7KVVA -m comment --comment "app/b:http-port -> 10.0.0.155:8000"
-m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-VFBYZLZKPEFJ3QIZ
-A KUBE-SVC-CELO6J2CXNI7KVVA -m comment --comment "app/b:http-port -> 10.0.0.76:8000"
-j KUBE-SEP-SXF6FD423VYX6VFB
負荷分散はクライアントと同じノードで行われます。したがって、ポッドをノードにマップすると、次のようになります。
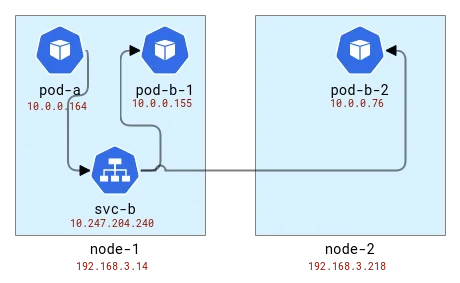
A および B のアプリケーション トポロジを Kubernetes ノードにマップする
内部的に iptables (実際にはnftables ) は conntrack モジュールを使用して、パケットが同じ接続に属し、同様の方法で処理される必要があることを認識します。 Conntrack はアドレス変換も担当するため、クライアント アプリケーションを備えたノードはパケットの送信先を認識している必要があります。 conntrack CLI ツールを使用して確認してみましょう。
# node-1
# conntrack -L | grep 8000
tcp 6 82 TIME_WAIT src=10.0.0.164 dst=10.247.204.240 sport=51030 dport=8000 src=10.0.0.76 dst=192.168.3.14 sport=8000 dport=19554 [ASSURED] use=1
tcp 6 79 TIME_WAIT src=10.0.0.164 dst=10.247.204.240 sport=51014 dport=8000 src=10.0.0.155 dst=10.0.0.129 sport=8000 dport=56734 [ASSURED] use=1
# node-2
# conntrack -L | grep 8000
tcp 6 249 CLOSE_WAIT src=10.0.0.76 dst=192.168.3.14 sport=8000 dport=19554 [UNREPLIED] src=192.168.3.14 dst=10.0.0.76 sport=19554 dport=8000 use=1
最初のノードでは、アドレスがアプリケーション A のポッドから変換され、ランダムなポートを持つノード アドレスを取得したことがわかります。 2 番目のノードでは、自身のパケットが実際には応答であるため、接続情報が逆になりますが、これを念頭に置くと、要求は最初のノードと同じランダム ポートから送信されていることがわかります。2 つのリクエストを送信し、同じノード上の pod-b-1 と別のノード上の pod-b-2 という異なるポッドによって処理されたため、ノード 1 に 2 つのリクエストがあることに注意してください。
ここでの良いニュースは、クライアント ノードで実際のリクエスト受信者を知ることは可能ですが、サーバー側ではクライアント ノードで収集された情報と関連付けられる必要があることです。このような:
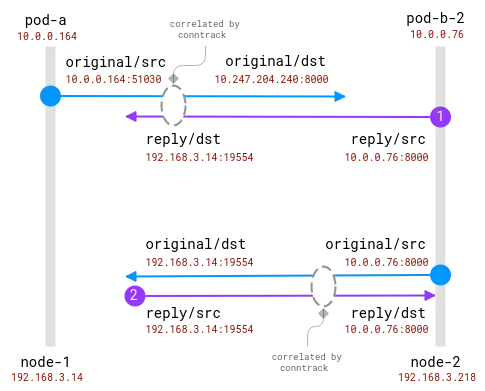
接続は conntrack モジュールによって追跡されます。青い円はソケットで観察されるローカル アドレス、紫の円はリモート アドレスです。課題は、紫と青を関連付けることです。
クライアント ポッドとサーバー ポッドの両方が同じノード上にある場合、相関関係はより簡単になりますが、どのアドレスが本物でどのアドレスを無視すべきかについては、まだいくつかの仮定があります。
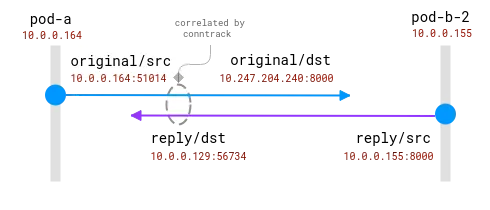
同じノード上の 2 つの Pod 間の接続。送信元アドレスは本物ですが、宛先アドレスはマッピングする必要があります
ここで、オペレーティング システムは NAT を完全に認識し、実際の送信元と実際の宛先の間のマッピングを提供できます。完全なストリームを 10.0.0.164 から 10.0.0.155 に再構築することは可能です。
このセクションの結論として、既存の eBPF プローブを拡張して、conntrack モジュールからのアドレス変換に関する情報を含めることができる必要があります。クライアントはリクエストの宛先を知ることができます。しかし、サーバーはクライアントが誰であるかを常に知ることができるわけではなく、集中化された相関アルゴリズムが直接存在しません。対照的に、分散トレース方式は、通信データからクライアントとサーバーにピアに関する情報を直接かつ即時に提供します。そこで、FlowTracer の登場です。
フロートレーサー
考え方はシンプルです。接続内で直接ピア間でデータを転送します。このような機能が必要になるのはこれが初めてではありません。たとえば、HTTP ロード バランサーは X-Forwarded-For HTTP ヘッダーを挿入して、バックエンド サーバーにクライアントについて知らせます。ここでの制限は、L4 に留まりたいため、あらゆるアプリケーション レベルのプロトコルをサポートすることです。このような機能も存在し、一部の L4 ロード バランサー (この例など) は、発信元アドレスを TCP ヘッダー オプションとして挿入し、サーバーで使用できるようにすることができます。
要件の概要:
- L4 層トランスポート ピア アドレス。
- アドレスインジェクションを動的に有効にする機能 (K8 にアプリケーションを簡単にデプロイするなど)。
- 非侵襲的かつ迅速です。
最も簡単なアプローチは、TCP ヘッダー オプション (TOA とも呼ばれる) を使用することのようです。ペイロードは IP アドレスとポート番号です (アドレス変換中に変更されるため)。 Huawei Kubernetes の展開では IPv4 のみがサポートされるため、サポートを IPv4 のみに制限できます。 IPv4 アドレスは 32 ビットですが、ポート番号には 16 ビットが必要で、合計 6 バイトに、オプション タイプ用の 1 バイトとオプション長用の 1 バイトが必要です。 TCP ヘッダーの仕様は次のようになります。
ヘッダーには、最大 40 バイトの複数のオプションを含めることができます。各オプションには可変長とタイプ/種類を指定できます。
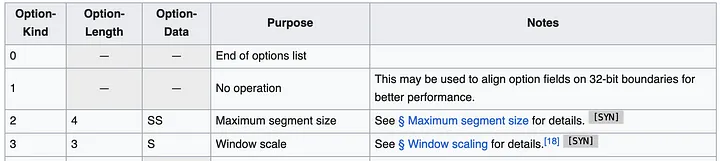
一般に、Linux TCP パケットには、MSS やタイムスタンプなどのいくつかのオプションがすでにあります。しかし、まだ約 20 バイトの空き領域が残っています。
データをどこに配置するかがわかったら、次の問題は、コードをどこに追加するかということです。私たちは、ソリューションができる限り汎用的であり、すべての TCP 接続に使用できるようにしたいと考えています。理想的な場所は、ネットワーク スタック内のカーネル内のどこか、いわゆるソケット バッファ (ネットワーク接続情報を表す構造) 内で、最上位からネットワーク経由で送信する準備ができているパケットに至るまで続きます。実装の観点から見ると、コードは eBPF コードである必要があり (もちろん!)、アドレス挿入機能を動的に有効にすることができます。
この種のコードが最もわかりやすい場所は、フロー制御モジュールである TC です。 TC では、eBPF プログラムは作成されたパケットにアクセスし、パケットからデータを読み書きすることができます。 1 つの欠点は、パケットを最初から解析する必要があることです。つまり、bpf_skb_load_bytes_relative関数が L3 ヘッダーの先頭へのポインターを提供しても、L4 の位置は手動で計算する必要があるということです。最も問題となるのは挿入操作です。bpf_skb_adjust_roomとbpf_skb_change_tailという有望な名前の関数が 2 つありますが、これらは L4 ではなく L3 パケットまでのサイズ変更を許可します。別の解決策は、既存の TCP ヘッダーに特定のオプションが含まれているかどうかを確認してそれらをオーバーライドすることですが、最初に一般的なパケットに何が含まれているかを確認してみましょう。
1514772378.301862 IP (tos 0x0, ttl 64, id 20960, offset 0, flags [DF], proto TCP (6), length 60)
192.168.3.14.28301 > 10.0.0.76.8000: Flags [S], cksum 0xbc03 (correct), seq 1849406961, win 64240, options [mss 1460,sackOK,TS val 142477455 ecr 0,nop,wscale 9], length 0
0x0000: 0000 0001 0006 fa16 3e22 3096 0000 0800 ........>"0.....
0x0010: 4500 003c 51e0 4000 4006 1ada c0a8 030e E..<Q.@.@.......
0x0020: 0a00 004c 6e8d 1f40 6e3b b5f1 0000 0000 ...Ln..@n;......
0x0030: a002 faf0 bc03 0000 0204 05b4 0402 080a ................
0x0040: 087e 088f 0000 0000 0103 0309 .~..........
これは、クライアントがバックエンド アプリケーションとの接続を確立するときに送信される TCP SYN パケットです。ヘッダーにはいくつかのオプションが含まれています。最大セグメント サイズを指定する MSS、次にオプションの確認応答、パケットの順序を保証する特定のタイムスタンプ、おそらくワード アライメントのためのオペコード NOP、最後にアライメントのためのウィンドウ サイズのウィンドウ スケーリングです。そのリストから、タイムスタンプ オプションが対象となる最適な候補です (Wikipedia によると、採用率はまだ約 40%)。一方、非侵入型 eBPF 追跡のリーダーの 1 つである DeepFlow は、この操作が で実行されました。
このアプローチは実現可能に見えますが、実装するのは簡単ではありません。 TC プログラムは変換されたアドレスにアクセスできます。これは、変換マップを何らかの方法で conntrack モジュールから取得して保存する必要があることを意味します。 TC プログラムはネットワーク カードに接続されるため、ノードに複数のネットワーク カードがある場合、展開では接続場所を正しく識別する必要があります。リーダー モジュールは、すべてのパケットを解析して TCP を見つけ、ヘッダーを反復処理してヘッダーがどこにあるかを見つける必要があります。他に方法はありますか?
2023 年 8 月に Google でこの質問を検索すると、検索結果ページの下部に「No More Results」が表示されるのが一般的です (このブログ投稿がそれを変えることを願っています!)。最も役立つ参考資料は、2020 年に Facebook エンジニアによって作成された Linux カーネル パッチへのリンクです。このパッチは私たちが探しているものを示しています:
BPF-TCP-CC に関する初期の作業により、TCP 輻輳制御アルゴリズムを BPF で記述することが可能になりました。新しい輻輳制御アイデアをテスト/リリースする際に、運用環境での所要時間を短縮する機会が提供されます。同じ柔軟性を TCP ヘッダー オプションの記述にも拡張できます。
TCP のパフォーマンスを向上させるために、新しい TCP ヘッダー オプションをテストしたいと考える人は珍しくありません。もう 1 つの使用例は、より制御された環境を備え、ヘッダー オプションを内部専用トラフィックに配置できるデータ センターであり、これにより柔軟性が高まります。
究極の目標は、 bpf_store_hdr_optおよびbpf_load_hdr_opt関数です。どちらも、5.10 カーネル以降で利用可能な特別なタイプのsock opsプログラムに属しており、2022 年以降のほぼすべてのバージョンで使用できることを意味します。 Sock ops プログラムは、cgroup v2 に付属する単一の関数であり、特定のソケット (たとえば、特定のコンテナに属する) に対してのみ有効にすることができます。プログラムは、ソケットの現在の状態を示す単一の操作を受け取ります。新しいヘッダー オプションを書き込む場合は、まずアクティブまたはパッシブ接続の書き込みを有効にする必要があります。次に、ヘッダー ペイロードを書き込む前に、新しいヘッダーの長さを伝える必要があります。読み取り操作は簡単ですが、ヘッダー オプションを読み取る前に、最初に読み取りを有効にする必要もあります。 TCP パケットが作成されると、TCP ヘッダー コールバックが呼び出されます。これはアドレス変換の前に行われるため、ソケットの送信元アドレスをヘッダー オプションにコピーできます。リーダーはヘッダー オプションから値を簡単に抽出して BPF マップに保存できるため、後でコンシューマーは監視されたリモート アドレスを読み取って実際のアドレスにマッピングできます。最初に実行されるコードの BPF 部分は 100 行よりはるかに少ないです。かなり良い!
コードを本番環境に対応できるようにする
しかし、悪魔は細部に宿ります。まず、BPF マップから古いレコードを削除する方法が必要です。これを行うのに最適なタイミングは、conntrack モジュールがテーブルから接続を削除するときです。 Arthur Chiao によるこの記事では、 conntrack モジュールと接続ライフサイクルの内部構造について詳しく説明しているため、カーネル ソースで正しい関数 ( nf_conntrack_destroy ) を簡単に見つけることができます。この関数は、内部テーブルから削除する前に conntrack エントリを受け取ります。この時点で接続が正式に終了するため、マッピング テーブルから接続を削除するプローブを追加することもできます。
sock ops プログラムでは、新しいヘッダー オプションがすべてのパケットに適用されると想定して、どのパケットに挿入されるかを指定しません。実際、これは真実ですが、読み取りは接続が確立/確認済みの状態にある場合にのみ有効です。これは、サーバー側が受信 SYN パケットからヘッダー オプションを読み取ることができないことを意味します。 SYN-ACK も通常の TCP スタックの前に処理され、ヘッダー オプションは挿入も読み取りもできません。実際、この機能は、接続が最初の PSH (パケット) で完全に実行されている場合にのみ、両端で機能します。これは接続が機能している場合にはまったく問題ありませんが、接続の試行が失敗した場合、クライアントはどこに接続しようとしていたのかがわかりません。これは重大な間違いです。この情報はネットワークの問題をデバッグするのに役立ちます。ご存知のとおり、Kubernetes の負荷分散はクライアント ノードに実装されているため、conntrack から情報を抽出し、ストリームを通じて受信したデータと同じ形式で保存できます。 Conntrack 関数 ___nf_conntrack_confirm_ がここで役に立ちます。この関数は、新しい接続が確認されようとしているときに呼び出されます。これは、アクティブなクライアント (発信) TCP 接続の場合、最初の SYN パケットが送信されるときに発生します。
これらすべての追加により、コードは少し肥大化しますが、それでも合計 1000 行よりはるかに少ないです。完全なパッチはこの MRで入手できます。実験設定でこれを有効にして、メトリクスとトポロジを再度確認してみましょう。
見て:
正しい A/B アプリケーション トポロジ
1990 年代生まれのプログラマーがビデオ移植ソフトウェアを開発し、1 年足らずで 700 万以上の利益を上げました。結末は非常に懲罰的でした。 高校生が成人式にオープンソースプログラミング言語を自作―ネチズンの鋭いコメント: 詐欺横行でRustDesk依存、国内サービスの タオバオ(taobao.com)は国内サービスを一時停止、ウェブ版の最適化作業を再開 Java最も一般的に使用されている Java LTS バージョンは 17 、Windows 11 は減少し続ける Open Source Daily | Google がオープンソースの Rabbit R1 を支持、Microsoft の不安と野心; Electricがオープンプラットフォームを閉鎖 AppleがM4チップをリリース GoogleがAndroidユニバーサルカーネル(ACK)を削除 RISC-Vアーキテクチャのサポート Yunfengがアリババを辞任し、将来的にはWindowsプラットフォーム用の独立したゲームを制作する予定この記事はYunyunzhongsheng ( https://yylives.cc/ ) で最初に公開されたもので、どなたでもご覧いただけます。