

SaaS 業界が急速に成長するにつれて、リアルタイム データの流入を処理するには、動的で適応性のあるアーキテクチャが必要になります。それらを構築する方法は次のとおりです。
著者 Christina Lin の「How To Build a Scalable Platform Architecture for Real-Time Data 」から翻訳しました。
ソフトウェア・アズ・ア・サービス (SaaS) 業界は止まらない成長を示しており、市場規模は 2024 年には 3,175 億 5,500 万米ドルに達し、2032 年までにほぼ 3 倍の 12 億 2,887 万米ドルに達すると予想されています。この増加は、強化された堅牢なデータ戦略に対するニーズの高まりを浮き彫りにしています。この傾向は、企業によって生成されるデータの量、速度、多様性の増加と人工知能の統合によって推進されています。
しかし、この成長する状況は、ピーク トラフィックの管理、オンライン トランザクション処理 (OLTP) からオンライン分析処理 (OLAP) へのリアルタイムの移行、セルフサービスと分離の確保、クラウド非依存性とマルチ化など、いくつかの重要な課題をもたらしています。リージョン展開。これらの課題に対処するには、システムのパフォーマンスを損なうことなく高可用性と堅牢なフェイルオーバー メカニズムを保証する洗練されたアーキテクチャ フレームワークが必要です。
この記事のリファレンス アーキテクチャでは、成長する SaaS 業界をサポートする、スケーラブルで自動化された柔軟なデータ プラットフォームを構築する方法について詳しく説明します。このアーキテクチャは、大規模データ処理の技術的ニーズをサポートすると同時に、俊敏性、コスト効率、法規制順守といったビジネス ニーズにも適合します。
データ集約型 SaaS サービスの技術的課題
サービスとデータ量の需要が増大し続けるにつれて、SaaS 業界ではいくつかの共通の課題が生じています。
トラフィックのピークとバーストを処理することは、変動するトラフィック パターンに対処するためにリソースを効率的に割り当てるために重要です。これには、データ損失を防ぎながら、ワークロードを分離し、ピークワークロード中にスケーリングし、オフピーク時にコンピューティングリソースを削減する必要があります。
OLTP を OLAP に対してリアルタイムで維持するということは、データの整合性を重視して大量の高速トランザクションを管理する OLTP と、迅速な分析洞察をサポートする OLAP システムをシームレスにサポートすることを意味します。この二重サポートは、複雑な分析クエリをサポートし、最高のパフォーマンスを維持するために重要です。また、機械学習 (ML) 用のデータセットを準備する際にも重要な役割を果たします。
セルフサービスとデカップリングを有効にするには、中央の IT チームに大きく依存することなく、トピックとクラスターを作成および管理できるセルフサービス機能をチームに与える必要があります。これにより、アプリケーションとサービスを分離して独立したスケーラビリティを実現しながら、開発を迅速化できます。
クラウドの不可知性と安定性を促進することで、機敏性が向上し、AWS、Microsoft Azure、
SaaS フレンドリーなアーキテクチャを構築する方法
これらの課題に対処するために、大規模な SaaS 企業は、複数のリージョンにまたがる複数のクラスターを実行し、カスタム開発されたコントロール プレーンによって管理されるアーキテクチャ フレームワークを採用することがよくあります。コントロール プレーンの設計により、基盤となるインフラストラクチャの柔軟性が強化されると同時に、それに接続されているアプリケーションの複雑さが簡素化されます。
この戦略は高可用性と堅牢なフェイルオーバー メカニズムにとって重要ですが、地理的に分散したクラスター全体で均一なパフォーマンスとデータの整合性を維持するには複雑すぎる可能性があり、ましてやパフォーマンスに影響を与えたり、リソースのスケールアップやスケールダウンを発生したりするという課題はありません。起きます。
さらに、特定のシナリオでは、コンプライアンスまたはセキュリティ上の理由から、データを特定のクラスター内に分離する必要がある場合があります。これらの複雑さを回避する堅牢で柔軟なアーキテクチャを構築できるように、いくつかの提案を紹介します。
1. 安定した基盤を確立する
SaaS サービスの主な課題は、高頻度かつ大量のオンライン クエリ、データ挿入、内部データ交換などのさまざまなトラフィック パターンを処理するためにリソースを割り当てることです。
トラフィックを非同期プロセスに変換することは、より効率的なスケーリングとコンピューティング リソースの迅速な割り当てを可能にする一般的なソリューションです。Apache Kafkaなどのデータ ストリーミング プラットフォームは、大量のデータを効率的に管理するのに最適です。しかし、Kafka のような分散データ プラットフォームの管理には、独自の課題が伴います。Kafka のシステムは、クラスターの調整、同期、スケーリングの管理に加え、追加のセキュリティ プロトコルや回復プロトコルも必要となるため、技術的に複雑であることで有名です。カフカの課題
Kafka の Java 仮想マシン (JVM) も、主に JVM のガベージ コレクション プロセスが原因で、予測できない遅延のスパイクを引き起こす可能性があります。 JVM のメモリ割り当ての管理と、Kafka の高スループット要件に合わせた調整は面倒な作業であることで知られており、Kafka ブローカーの全体的な安定性に影響を与える可能性があります。
もう 1 つの障害は、Kafka のデータ ポリシー管理です。これには、ストレージ コスト、パフォーマンス、コンプライアンスのバランスをある程度保ちながら、データ保持ポリシー、ログ圧縮、データ削除を管理することが含まれます。
つまり、SaaS 環境で Kafka ベースのシステムを効果的に管理するのは難しいのです。その結果、多くの SaaS 企業は、JVM や ZooKeeper などの外部依存関係を必要とせずに、拡張性の高いデータ ストリーミングを提供するKafka の代替手段に注目しています。
2. セルフサービスストリーミングデータを有効にする
開発者が開発から運用までテーマを作成できるセルフサービス ソリューションに対する需要が高まっています。インフラストラクチャまたはプラットフォーム サービスは、集中管理を備えたソリューションを提供し、ログインの詳細を提供し、さまざまなプラットフォームや段階にわたるリソースの迅速な作成と展開を自動化する必要があります。
このため、さまざまな形で提供されるコントロール プレーンの必要性が生じます。一部のコントロール プレーンは、クラスターまたはトピックのライフサイクルを管理し、ストリーミング プラットフォームにアクセス許可を割り当てるためにのみ使用されます。他のコントロール プレーンは、ターゲットを仮想化し、インフラストラクチャの詳細をユーザーやクライアントから隠すことにより、抽象化レイヤーを追加します。
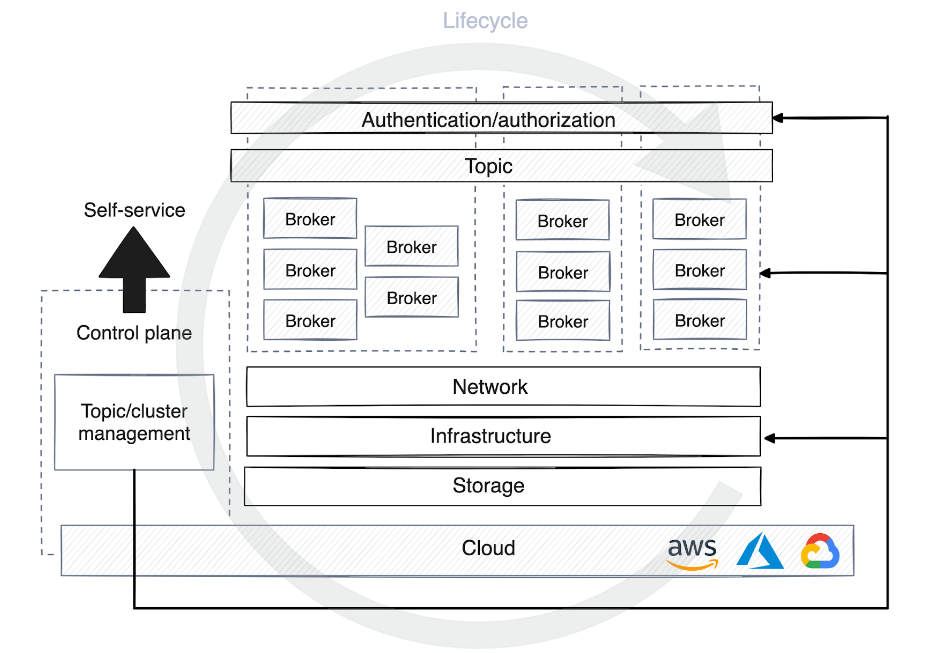
セルフサービス データ プラットフォームのコントロール プレーンにトピックが登録されると、環境の段階に応じてさまざまなコンピューティング リソースの最適化戦略が適用されます。開発では、トピックが他のプロセスとクラスターを共有することが多く、データの保持はあまり重視されず、ほとんどのデータは数日以内に破棄されます。
ただし、運用環境では、トラフィック量に基づいてリソースの割り当てを慎重に計画する必要があります。この計画には、コンシューマのパーティション数の決定、データ保持ポリシーの設定、データの場所の決定、特定の使用例に専用クラスターが必要かどうかの検討が含まれます。
コントロール プレーンの場合、ストリーミング プラットフォームのライフサイクル管理プロセスを自動化することは非常に役立ちます。これにより、コントロール プレーンは自律的にエージェントをデバッグし、パフォーマンス メトリックを監視し、パーティションのリバランスを開始または停止して、大規模なプラットフォームの可用性と安定性を維持できるようになります。
3. OLTPおよびOLAPのリアルタイムサポート
バッチ処理からリアルタイム分析への移行により、OLAP システムを既存のインフラストラクチャに統合することが重要になります。ただし、これらのシステムは通常、大量のデータを処理し、詳細な多次元分析には複雑なデータ モデルを必要とします。
OLAP は複数のデータ ソースに依存しており、企業の成熟度に応じて、通常はデータを保存するデータ ウェアハウスまたはデータ レイクと、データ ソースからデータを移動するために定期的に (通常は毎晩) 実行されるバッチ処理パイプラインがあります。 。このプロセスでは、さまざまな OLTP システムやその他のソースからのデータがマージされます。このプロセスは、データの品質と一貫性を維持する上で複雑になる可能性があります。
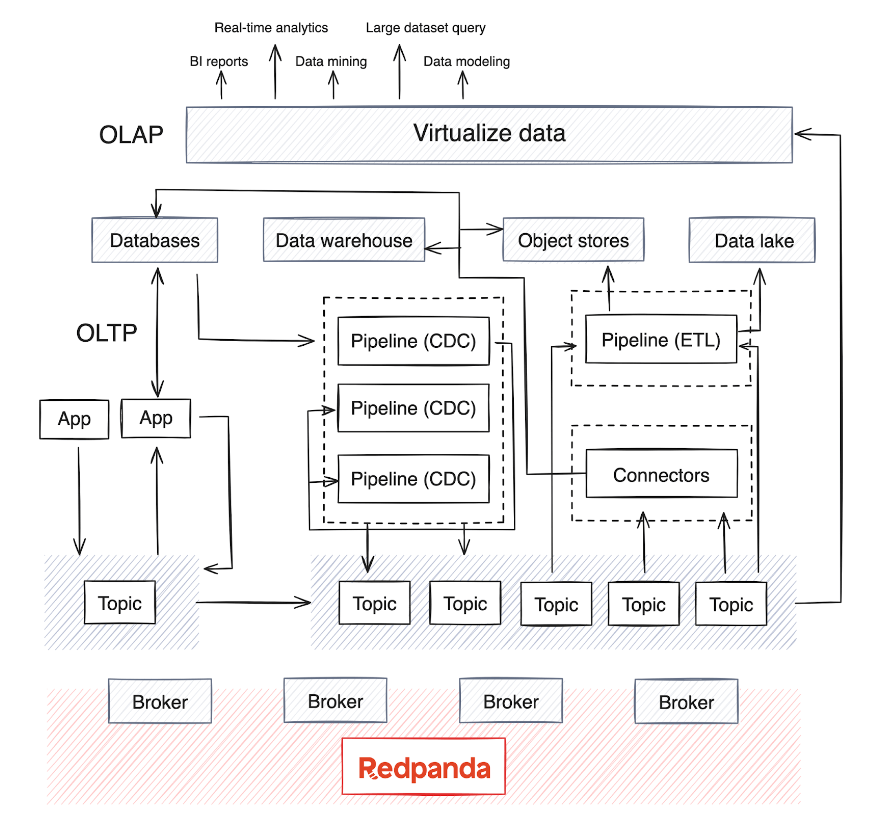
現在、OLAP は AI モデルと大規模なデータセットも統合しています。現在、ほとんどの分散データ処理エンジンとストリーミング データベースは、Kafka や Redpanda などのソースからのストリーミング データのリアルタイムの消費、集約、要約、分析をサポートしています。この傾向により、データベースからイベント ログをストリーミングする変更データ キャプチャ (CDC) パイプラインだけでなく、リアルタイム データの抽出、変換、ロード (ETL) および抽出、ロード、変換 (ELT) パイプラインの台頭も生まれています。
リアルタイム パイプラインは通常Java、Python、またはGolang で実装され、慎重な計画が必要です。これらのパイプラインのライフサイクルを最適化するために、SaaS 企業はパイプラインのライフサイクル管理をコントロール プレーンに組み込み、監視とリソースの調整を最適化しています。
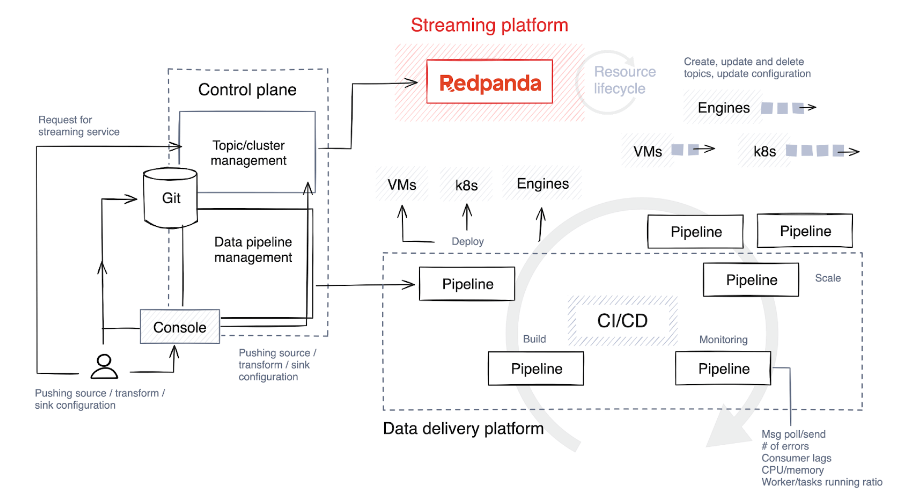
4. データ パイプラインのライフサイクルを理解 (および最適化) する
最初のステップは、テクノロジー スタックを選択し、パイプラインを作成するユーザーが享受できる自由度とカスタマイズのレベルを決定することです。理想的には、さまざまなタスクに応じてさまざまなテクノロジーを選択できるようにし、パイプラインの建設と拡張を制限するガードレールを実装できるようにします。
以下は、パイプラインのライフサイクルに含まれる各段階の概要です。
ビルドとテスト
ソース コードは、パイプライン開発者によって直接、またはコントロール プレーンのカスタム ツールを通じて Git リポジトリにプッシュされます。このコードは、C++、Java、C# などの言語を使用してバイナリ コードまたは実行可能プログラムにコンパイルされます。コンパイル後、コードはアーティファクトにパッケージ化されます。このプロセスには、承認された依存関係と構成ファイルのバンドルも含まれる場合があります。
次に、システムは自動テストを実行してコードを検証します。テスト中、コントロール プレーンはこの目的のために一時的なトピックを作成し、これらのトピックはテストが完了するとすぐに破棄されます。
展開する
アーティファクトは、テクノロジー スタックに応じて、仮想マシン ( Kubernetesなど) またはストリーミング データベースにデプロイされます。一部のプラットフォームでは、ブルー/グリーン デプロイメントなど、より創造的なアプローチでリリース戦略を提供しており、これにより迅速なロールバックが可能になり、ダウンタイムが最小限に抑えられます。もう 1 つの戦略はカナリア リリースです。カナリア リリースでは、新しいバージョンがデータのごく一部にのみ適用されるため、潜在的な問題の影響が軽減されます。
これらの戦略の欠点は、ロールバックが困難になる可能性があり、新しいバージョンの影響を受けるデータを分離するのが難しい場合があることです。場合によっては、完全リリースを実行してデータセット全体をロールバックする方が簡単な場合があります。
拡大する
多くのプラットフォームは、CPU 使用率に基づいて実行中のインスタンスの数を調整するなどの自動スケーリングをサポートしていますが、自動化のレベルは異なります。一部のプラットフォームではこの機能がネイティブで提供されますが、他のプラットフォームでは、ジョブごとの並列タスクまたはワーカー プロセスの最大数の設定など、手動構成が必要です。
導入中、コントロール プレーンは、予想される需要に基づいてデフォルト設定を提供しますが、メトリクスを引き続き厳密に監視します。次に、必要に応じてワーカー プロセス、タスク、またはインスタンスの数を調整することで、トピックに追加のリソースを割り当てます。
モニター
パイプライン内の適切なメトリクスを監視し、可観測性を維持することは、問題を早期に検出するための主な方法です。データ処理パイプラインの効率と信頼性を確保するために、積極的に監視する必要がある主要な指標をいくつか紹介します。
リソースインジケーター
- CPU とメモリの使用量は、リソースがどのように消費されているかを理解するために重要です。
- ディスク I/O は、データの保存と取得操作の効率を評価するために重要です。
スループットとレイテンシ
- 入出力レコードは、1 秒あたりのデータ処理速度を測定します。
- 1 秒あたりに処理されるレコードは、システムの処理能力を表します。
- エンドツーエンドのレイテンシは、データの入力から出力までにかかる合計時間であり、リアルタイム処理のパフォーマンスにとって重要です。
背圧とヒステリシス
- これらは、データ処理のボトルネックを特定し、潜在的な速度低下を防ぐのに役立ちます。
エラー率
- エラー率の追跡は、データの整合性とシステムの信頼性の維持に役立ちます
5. 信頼性、冗長性、回復力の向上
企業は、中断時に継続的な運用を維持するために、高可用性、災害復旧、回復力を優先します。ほとんどのデータ ストリーミング プラットフォームには、主に複数のパーティション、データ センター、クラウドに依存しない可用性ゾーンにクラスターを拡張することによって、強力な保護機能と導入戦略がすでに組み込まれています。
ただし、遅延の増加、データ重複の可能性、コストの増加などのトレードオフが伴います。高可用性、災害復旧、回復力を計画する際のヒントをいくつか示します。
高可用性
コントロール プレーンによって管理される自動展開プロセスは、堅牢な高可用性戦略を確立する上で重要な役割を果たします。この戦略により、パイプライン、コネクタ、ストリーミング プラットフォームが、クラウド プロバイダーまたはデータ センターに基づいてアベイラビリティ ゾーンまたはパーティション全体に戦略的に分散されます。

データ プラットフォームでは、リスクを軽減するためにすべてのデータ パイプラインを複数のアベイラビリティ ゾーン (AZ) に分散することが重要です。継続性は、パーティション障害が発生した場合でも中断のないデータ処理を維持するために、異なる AZ でパイプラインの冗長コピーを実行することによってサポートされます。
データ アーキテクチャの基盤となるストリーミング プラットフォームもこれに倣い、複数の AZ 間でデータを自動的にレプリケートして、復元力を向上させる必要があります。 Redpanda のようなソリューションは、パーティション間のデータ分散を自動化し、プラットフォームの信頼性と耐障害性を向上させることができます。
ただし、アプリケーションとサービスの場所を考慮して、関連するネットワーク帯域幅コストの可能性を考慮してください。たとえば、パイプラインをデータ ストアの近くに維持すると、コストを削減しながらネットワークの遅延とオーバーヘッドを削減できます。
災害からの回復
より迅速な障害回復には、データ複製の増加によるコストの増加が伴い、その結果、帯域幅のオーバーヘッドが増加し、常時オン (アクティブ/アクティブ) 設定が必要となり、ハードウェア使用量が 2 倍になります。すべてのストリーミング テクノロジーがこの機能を提供しているわけではありませんが、Redpanda のようなエンタープライズ グレードのプラットフォームは、データとクラスター メタデータのクラウド オブジェクト ストレージへのバックアップをサポートしています。
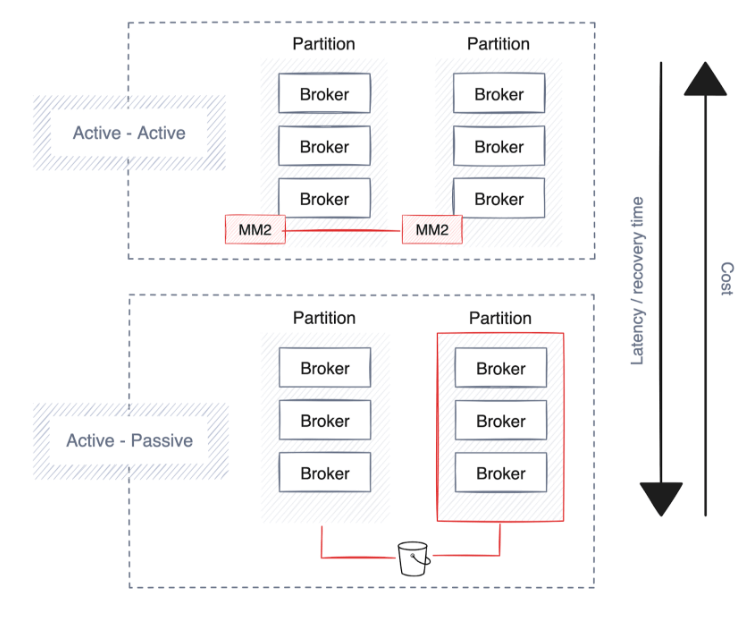
弾性
高可用性と災害復旧に加えて、一部のグローバル企業では、データのストレージと処理が特定の地域の規制に準拠していることを確認するために、地域展開戦略を必要としています。その代わりに、最小限の管理でさまざまなリージョン間でデータをリアルタイムに共有したい企業は、エージェントがリージョン間でデータを複製および分散できるようにする共有クラスターを作成することがよくあります。
ただし、このアプローチでは、データが後続のパーティションに継続的に転送されるため、多大なネットワーク コストと遅延が発生します。データ トラフィックを軽減するために、フォロワー フェッチはデータ コンシューマに、地理的に最も近いフォロワー パーティションからデータを読み取るように指示します。
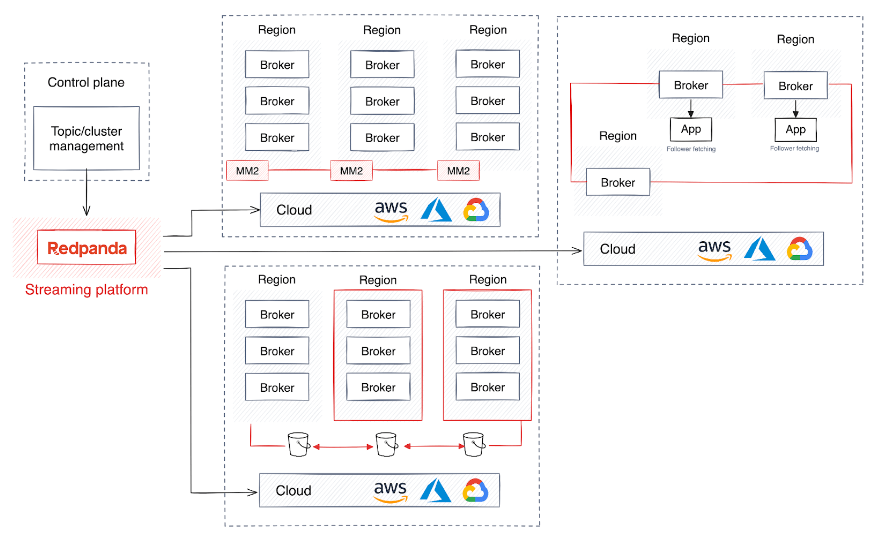
さらに、データ バックフィル用にクラスターをスケーリングすることで、データ センター間の負荷分散が向上します。この拡張性は、増大するデータ量とネットワーク トラフィックを管理するために重要であり、企業がパフォーマンスや信頼性を犠牲にすることなく拡張できるよう支援します。
結論は
企業がデジタルトランスフォーメーションを通じて変革するにつれて、意思決定を導く上でリアルタイムデータの重要性がますます高まっています。これには、コストと運用を最適化しながら、大量のデータセットからより深い洞察を抽出し、より正確な予測を可能にし、自動化された意思決定プロセスを合理化し、よりパーソナライズされたサービスを提供することが含まれます。
1 つのオプションは、C++ で実装されたプラグアンドプレイの Kafka 代替品であるRedpandaなどのスケーラブルなデータ ストリーミング プラットフォームを含むリファレンス アーキテクチャを採用することです。これにより、企業は、シームレスなスケーリング、ライフサイクルの自動化をサポートする管理 API、ストレージ コストを削減する階層型ストレージ、コスト効率の高い読み取り専用クラスターのセットアップを簡素化するリモートリード レプリカ、およびシームレスなデータの地理的分散を容易にすることで、リアルタイム性を回避できます。処理の複雑さ。
適切なテクノロジーを使用すれば、SaaS プロバイダーはサービスを強化し、顧客エクスペリエンスを向上させ、デジタル市場での競争上の優位性を高めることができます。将来の戦略では、SaaS プラットフォームがデータドリブンの世界で成功できるように、効率と適応性を高めるためにこれらのシステムを引き続き最適化する必要があります。
1990 年代生まれのプログラマーがビデオ移植ソフトウェアを開発し、1 年足らずで 700 万以上の利益を上げました。結末は非常に懲罰的でした。 高校生が成人式にオープンソースプログラミング言語を自作―ネチズンの鋭いコメント: 詐欺横行でRustDesk依存、国内サービスの タオバオ(taobao.com)は国内サービスを一時停止、ウェブ版の最適化作業を再開 Java最も一般的に使用されている Java LTS バージョンは 17 、Windows 11 は減少し続ける Open Source Daily | Google がオープンソースの Rabbit R1 を支持、Microsoft の不安と野心; Electricがオープンプラットフォームを閉鎖 AppleがM4チップをリリース GoogleがAndroidユニバーサルカーネル(ACK)を削除 RISC-Vアーキテクチャのサポート Yunfengがアリババを辞任し、将来的にはWindowsプラットフォーム用の独立したゲームを制作する予定この記事はYunyunzhongsheng ( https://yylives.cc/ ) で最初に公開されたもので、どなたでもご覧いただけます。