
mysqld: 兄さん、起きられないんです...
著者: Ben Shaohua、ACOSEN R&D センターのエンジニア、プロジェクト要件とメンテナンスを担当。他の正体: コーギーのハシビロコウ。
Aikeson オープンソース コミュニティによって作成されています。オリジナルのコンテンツを許可なく使用することはできません。転載する場合は編集者に連絡し、出典を明記してください。
この記事は約 2,100 ワードの長さで、読むのに 7 分かかると予想されます。
導入
タイトルにあるように、自動テスト シナリオでは、 MySQL をsystemdから起動できません。
引き続きkill -9インスタンスプロセスを終了し、終了後にmysqld が正しくプルアップされるかどうかを確認します。
具体的な情報は次のとおりです。
- ホスト情報:CentOS 8(Dockerコンテナ)
- systemdを使用してmysqldプロセスを管理する
- systemd サービスの動作モードは次のとおりです。
- 起動コマンドは以下のとおりです。
# systemd 启动命令
sudo -S systemctl start mysqld_11690.service
# systemd service 内的 ExecStart 启动命令
/opt/mysql/base/8.0.34/bin/mysqld --defaults-file=/opt/mysql/etc/11690/my.cnf --daemonize --pid-file=/opt/mysql/data/11690/mysqld.pid --user=actiontech-mysql --socket=/opt/mysql/data/11690/mysqld.sock --port=11690
症状
起動コマンドはハングし続け、何度か試行しても成功も復帰もありません。シナリオを手動で再現することはできません。
以下の図は再現シナリオを示しています。サービスのポート番号が一致しない場合は無視してください。

MySQL エラー ログには情報が含まれていません。systemd サービスのステータスを確認し、MAIN PIDパラメータが不足しているために起動スクリプトの実行に失敗したことを確認します。
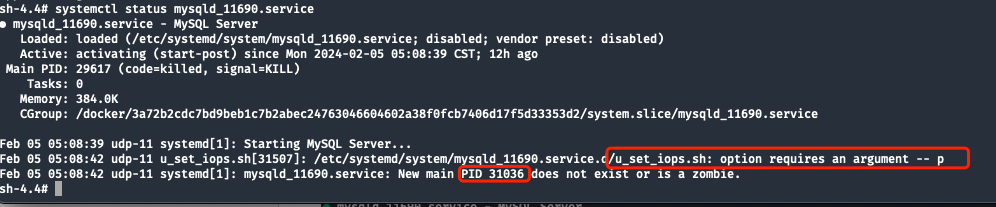
systemdによって出力される最終的な情報は次のとおりです。New main PID 31036 does not exist or is a zombie
理由の要約
systemd がmysqldを開始すると、まずサービステンプレートの設定に従って実行されます。
- ExecStart ( mysqldを開始)
- mysqld が
pidファイルの作成を開始します - ExecStartPost (いくつかのカスタマイズされたポストスクリプト: 権限の調整、cgroup
pidへの書き込みなど)
ステップ 2-3の中間状態、つまりpidファイルが作成されたばかりのとき、ホストは自動テストによって発行されたコマンドを受け取りますsudo -S kill -9 $(cat /opt/mysql/data/11690/mysqld.pid)。
このpidファイルとpidプロセスは存在するため (killコマンドまたはコマンドが存在しない場合はcatエラーが報告されます)、自動 CASE はkill操作が正常に終了したと見なされます。ただし、mysqld.pidこのファイルは MySQL 自体によって維持されるため、systemdの観点から見ると、起動が成功したとみなされる前に、ステップ 3が完了するまで待つ必要があります。
systemd がフォークモードを使用する場合、PID子プロセスの値に基づいてサービスが正常に開始されたかどうかが判断されます。
子プロセスが正常に開始され、予期しない終了が発生しない場合、systemd はサービスが開始されたと見なし、子プロセスのPID値を に設定しますMAIN PID。
子プロセスが開始に失敗するか予期せず終了すると、systemd はサービスが正常に開始できなかったとみなします。
結論は
ExecStartPost を実行すると、子プロセスID 31036が削除されているためkill、後処理にはshell起動パラメーターが不足していますが、ExecStart ステップは完了しているため、MAIN PID 31036 はsystemdにのみ存在するゾンビ プロセスになります。
トラブルシューティングのプロセス
この問題に遭遇したとき、私は少し混乱してメモリとディスクの基本情報を確認しました。それは期待に応え、リソースの不足はありませんでした。
まず、MySQL のエラー ログを調べて、何が見つかったのかを確認してみましょう。結果は次のように表示されます。
...无关内容省略...
2024-02-05T05:08:42.538326+08:00 0 [Warning] [MY-010539] [Repl] Recovery from source pos 3943309 and file mysql-bin.000001 for channel ''. Previous relay log pos and relay log file had been set to 4, /opt/mysql/log/relaylog/11690/mysql-relay.000004 respectively.
2024-02-05T05:08:42.548513+08:00 0 [System] [MY-010931] [Server] /opt/mysql/base/8.0.34/bin/mysqld: ready for connections. Version: '8.0.34' socket: '/opt/mysql/data/11690/mysqld.sock' port: 11690 MySQL Community Server - GPL.
2024-02-05T05:08:42.548633+08:00 0 [System] [MY-013292] [Server] Admin interface ready for connections, address: '127.0.0.1' port: 6114
2024-02-05T05:08:42.548620+08:00 5 [Note] [MY-010051] [Server] Event Scheduler: scheduler thread started with id 5
エラーログを観察したところ、起動時以降はログ情報が出力されておらず、有用な情報がないことがわかりました。
systemctl statusをチェックして、サービスの現在のステータスを確認します。
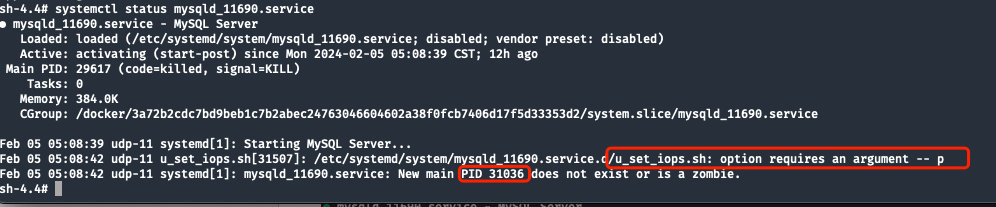
以下の図は、通常の状況におけるステータス情報を示しています。

比較後、2 つの有益な情報がまとめられました。
shellパラメーターが不足しているため、事後実行に失敗しました-p(-pパラメーターはMAIN PID、つまり fork 子プロセスが開始された後ですPID)。- systemdを取得できないか
PID 31036、存在しないか、またはゾンビ プロセスです。
まずはプロセスを確認してIDみmysqld.pidましょう。
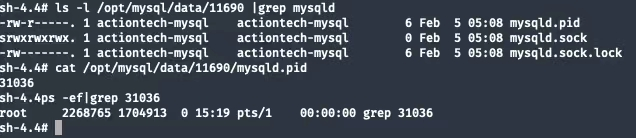
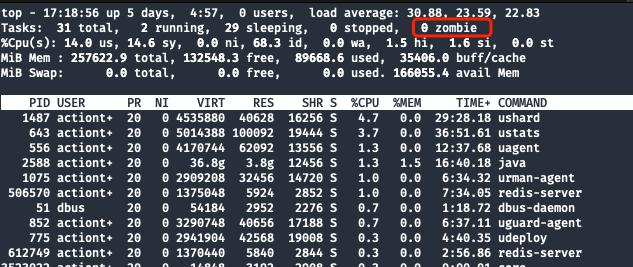
確認の手掛かり:
PID 31036存在しないmysqld.pidファイルは存在し、ファイルの内容は 31036 ですtopゾンビプロセスが存在していないか確認するコマンド
原因を確認するにはさらに多くの手がかりを得る必要がありますjournalctl -u。内容を確認して役立つかどうかを確認してください。
sh-4.4# journalctl -u mysqld_11690.service
-- Logs begin at Mon 2024-02-05 04:00:35 CST, end at Mon 2024-02-05 17:08:01 CST. --
Feb 05 05:07:54 udp-11 systemd[1]: Starting MySQL Server...
Feb 05 05:07:56 udp-11 systemd[1]: Started MySQL Server.
Feb 05 05:08:31 udp-11 systemd[1]: mysqld_11690.service: Main process exited, code=killed, status=9/KILL
Feb 05 05:08:31 udp-11 systemd[1]: mysqld_11690.service: Failed with result 'signal'.
Feb 05 05:08:32 udp-11 systemd[1]: Starting MySQL Server...
Feb 05 05:08:36 udp-11 systemd[1]: Started MySQL Server.
Feb 05 05:08:37 udp-11 systemd[1]: mysqld_11690.service: Main process exited, code=killed, status=9/KILL
Feb 05 05:08:37 udp-11 systemd[1]: mysqld_11690.service: Failed with result 'signal'.
Feb 05 05:08:39 udp-11 systemd[1]: Starting MySQL Server...
Feb 05 05:08:42 udp-11 u_set_iops.sh[31507]: /etc/systemd/system/mysqld_11690.service.d/u_set_iops.sh: option requires an argument -- p
Feb 05 05:08:42 udp-11 systemd[1]: mysqld_11690.service: New main PID 31036 does not exist or is a zombie.
ここでの内容はjournalctl -u現象を説明するだけであり、具体的な原因を分析することはできません。systemctl statusの内容と似ており、あまり役に立ちません。
/var/log/messagesシステム ログの内容を表示します。

検索した結果、ループがいくつかのメモリ エラー情報を報告していることが判明しました。エラーはハードウェアの問題である可能性があります。自動テストの同僚に尋ねた結果、私は次の結論に達しました。
- このシナリオでは、ユースケースが 4 回実行され、2 回が成功し、2 回が失敗しました。
- 各実行は同じホストおよび同じコンテナー イメージ上で行われます。
- 失敗しても、ハングが存在するコンテナは同じです。
実行結果は成功しているので、ここではハードウェアの問題を無視します。
コンテナについて言及したところで、 cgroups がホストにマップされるかどうかを考えると問題が生じます。上記で確認したsystemctl ステータスでは、 cgroupによってマップされたホスト ディレクトリが次であることがわかります。CGroup: /docker/3a72b2cdc7bd9beb1c7b2abec24763046604602a38f0fcb7406d17f5d33353d2/system.slice/mysqld_11690.service
親フォルダの読み書き権限を確認してsystem.slice異常はありません。まず、一時的にcgroupマッピングの問題を解決します (同じcgroupを使用するホスト上のsystemdによって引き継がれる他のサービスがあるため)。
pstackがsystemctl startに関して、具体的にsystemdがハングする場所を確認できるかどうかを試してみる予定です。3048143pid
sh-4.4# pstack 3048143
#0 0x00007fdfaef33ade in ppoll () from /lib64/libc.so.6
#1 0x00007fdfaf7768ee in bus_poll () from /usr/lib/systemd/libsystemd-shared-239.so
#2 0x00007fdfaf6a8f3d in bus_wait_for_jobs () from /usr/lib/systemd/libsystemd-shared-239.so
#3 0x000055b4c2d59b2e in start_unit ()
#4 0x00007fdfaf7457e3 in dispatch_verb () from /usr/lib/systemd/libsystemd-shared-239.so
#5 0x000055b4c2d4c2b4 in main ()
観察の結果、start_unitが疑わしいことが判明しました。この関数は実行可能start_unit()ファイル内にありますが、役に立ちません。
既存の手がかりに基づいて、次のように推測できます。
mysqld.pidファイルが存在する場合、以前に開始されたプロセス番号を持つmysqld プロセスが実際に存在したことを意味します。31036- プロセスが開始されると、自動化されたユースケース
kill -9によって終了されます。 - systemd はすでに終了した を取得しました
MAIN PIDが、シェル後の実行は失敗し、フォークプロセスは失敗しました。
systemdの起動プロセスのステップを整理することで、可能性を推測できます。 MySQL インスタンスは、mysqldが正常に開始された後にのみファイルを生成するため、mysqld.pid後続の手順でkill -9誤って終了したことが原因である可能性があります。
再生方法
他に手がかりや手がかりはないので、推測した結論をもとに再現してみる予定です。
4.1 systemd mysql サービステンプレートを調整する
mysqld の開始から数秒後にテンプレート ファイルを編集して/etc/systemd/system/mysqld_11690.service、この時間枠内でインスタンス プロセスを強制終了するシナリオをシミュレートできるようにします。sleep10
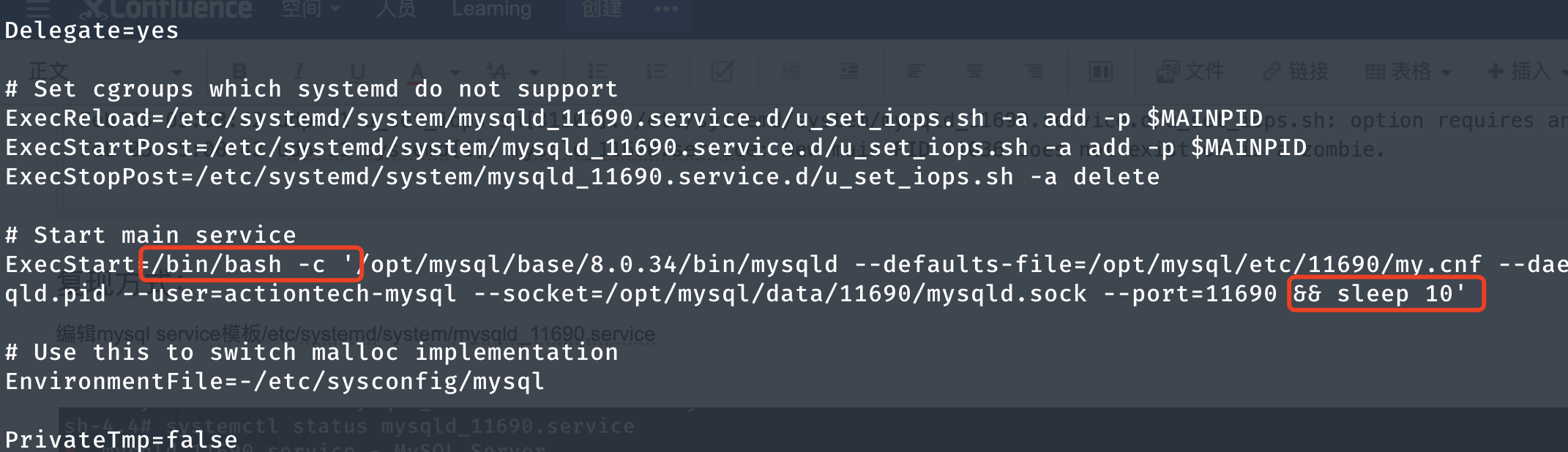
4.2 設定の再ロード
執行systemctl daemon-reload命令の変更が有効になります。
4.3 シーンの再現
- [ssh セッション A] まず、新しいコンテナを準備し、関連する設定を行って実行し、mysqld
sudo -S systemctl start mysqld_11690.serviceプロセスを開始します。このとき、何らかの理由でセッションがハングします。sleep - [ssh セッション B] 別のセッション ウィンドウで、
startコマンド ハングが有効な間にmysqld.pidファイルを確認し、ファイルが作成されたらすぐに実行しますsudo -S kill -9 $(cat /opt/mysql/data/11690/mysqld.pid)。 - 現時点で、systemctl のステータスを観察すると、パフォーマンスは期待どおりです。

解決
まず、killハングしているsystemctl startコマンドを削除して実行しますsystemctl stop mysqld_11690.service。これにより、systemd がゾンビ プロセスをアクティブに終了できるようになりますがstop、コマンドには影響しません。
stop実行が完了するまで待ってから、startコマンドを使用して再度開始し、通常の状態に戻ります。
さらに技術的な記事については、https: //opensource.actionsky.com/をご覧ください。
SQLEについて
SQLE は、開発環境から運用環境までの SQL 監査と管理をカバーする包括的な SQL 品質管理プラットフォームです。主流のオープンソース、商用および国内データベースをサポートし、開発、運用および保守のためのプロセス自動化機能を提供し、オンライン効率を向上させ、データ品質を向上させます。
SQL取得
| タイプ | 住所 |
|---|---|
| リポジトリ | https://github.com/actiontech/sqle |
| 書類 | https://actiontech.github.io/sqle-docs/ |
| リリースニュース | https://github.com/actiontech/sqle/releases |
| データ監査プラグイン開発ドキュメント | https://actiontech.github.io/sqle-docs/docs/dev-manual/plugins/howtouse |