
MySQL 接続のメモリ使用量を視覚化する方法を学びます。
著者: ベンジャミン ディケン
この記事と表紙のソース: https://planetscale.com/blog/、Axon オープン ソース コミュニティによって翻訳されました。
この記事は約 3,000 ワードで、読むのに 10 分かかると予想されます。
導入
ソフトウェアのパフォーマンスを考慮する場合、時間と空間の間には典型的なトレードオフがあります。 MySQL クエリのパフォーマンスを評価するプロセスでは、クエリ パフォーマンスの主な指標として実行時間 (またはクエリ レイテンシー) に焦点を当てることがよくあります。最終的にはクエリ結果をできるだけ早く取得したいので、これは使用するのに適したメトリックです。
私は最近、 「問題のある MySQL クエリを特定して分析する方法」に関するブログ投稿を公開しました。この記事では、実行時間と行読み取りの観点からパフォーマンスの低下を測定することに重点を置いています。ただし、この説明ではメモリ消費量はほとんど無視されています。
頻繁に必要になるわけではありませんが、MySQL には、クエリで使用されるメモリの量とそのメモリの使用目的に関する洞察を提供する組み込みメカニズムもあります。この機能を詳しく調べて、MySQL 接続のメモリ使用量をリアルタイムで監視する方法を見てみましょう。
メモリ統計
MySQL には、個別に計測できるシステムのコンポーネントが多数あります。表performance_schema.setup_instrumentsには各コンポーネントがリストされており、かなりの数のコンポーネントがあります。
SELECT count(*) FROM performance_schema.setup_instruments;
+----------+
| count(*) |
+----------+
| 1255 |
+----------+
この表には、メモリ分析に使用できる多くのツールが含まれています。利用可能なものを確認するには、表から選択し、 でフィルタリングしてみてくださいmemory/。
SELECT name, documentation
FROM performance_schema.setup_instruments
WHERE name LIKE 'memory/%';
何百もの結果が表示されるはずです。これらはそれぞれ異なるカテゴリのメモリを表しており、MySQL で個別に検出できます。これらのカテゴリの一部にはdocumentation、そのメモリ カテゴリが何を表すか、または何に使用されるかを説明する短い段落が含まれています。 null 以外の値を持つメモリ タイプのみを確認したい場合はdocumentation、次を実行できます。
SELECT name, documentation
FROM performance_schema.setup_instruments
WHERE name LIKE 'memory/%'
AND documentation IS NOT NULL;
これらの各メモリ クラスは、いくつかの異なる粒度でサンプリングできます。さまざまなレベルの粒度が複数のテーブルに保存されます。
SELECT table_name
FROM information_schema.tables
WHERE table_name LIKE '%memory_summary%'
AND table_schema = 'performance_schema';
+-----------------------------------------+
| TABLE_NAME |
+-----------------------------------------+
| memory_summary_by_account_by_event_name |
| memory_summary_by_host_by_event_name |
| memory_summary_by_thread_by_event_name |
| memory_summary_by_user_by_event_name |
| memory_summary_global_by_event_name |
+-----------------------------------------+
- Memory_summary_by_account_by_event_name: アカウントごとにメモリ イベントを要約します (アカウントはユーザーとホストの組み合わせです)
- Memory_summary_by_host_by_event_name: ホストの粒度でメモリ イベントを要約します。
- Memory_summary_by_thread_by_event_name: MySQL スレッド粒度でメモリ イベントを要約します。
- Memory_summary_by_user_by_event_name: ユーザー粒度でメモリ イベントを要約します。
- Memory_summary_global_by_event_name: メモリ統計のグローバル サマリー
各クエリ レベルでのメモリ使用量の特定の追跡はないことに注意してください。ただし、クエリのメモリ使用量を分析できないというわけではありません。これを実現するには、対象のクエリを実行している接続上のメモリ使用量を監視します。したがって、 memory_summary_by_thread_by_event_nameMySQL 接続とスレッドの間には便利なマッピングがあるため、テーブルの使用に焦点を当てます。
接続の目的を見つける
この時点で、コマンドラインで MySQL サーバーへの 2 つの別々の接続を設定する必要があります。 1 つ目は、メモリ使用量を監視するクエリを実行するクエリです。 2 番目のものは監視目的で使用されます。
最初の接続で、これらのクエリを実行して接続 ID とスレッド ID を取得します。
SET @cid = (SELECT CONNECTION_ID());
SET @tid = (SELECT thread_id
FROM performance_schema.threads
WHERE PROCESSLIST_ID=@cid);
次に、これらの値を取得します。もちろん、実際のものはここに表示されているものとは異なる場合があります。
SELECT @cid, @tid;
+------+------+
| @cid | @tid |
+------+------+
| 49 | 89 |
+------+------+
次に、メモリ使用量を分析したい長時間実行クエリをいくつか実行します。この例では、1 億行のテーブルから大規模な操作を実行します。SELECTalias列にインデックスがないため、しばらく時間がかかります。
SELECT alias FROM chat.message ORDER BY alias DESC LIMIT 100000;
ここで、実行中に別のコンソール接続に切り替えて次のコマンドを実行します。スレッド ID を接続のスレッド ID に置き換えます。
SELECT
event_name,
current_number_of_bytes_used
FROM performance_schema.memory_summary_by_thread_by_event_name
WHERE thread_id = YOUR_THREAD_ID
ORDER BY current_number_of_bytes_used DESC
次のような結果が表示されるはずですが、詳細はクエリとデータに大きく依存します。
+---------------------------------------+------------------------------+
| event_name | current_number_of_bytes_used |
+---------------------------------------+------------------------------+
| memory/sql/Filesort_buffer::sort_keys | 203488 |
| memory/innodb/memory | 169800 |
| memory/sql/THD::main_mem_root | 46176 |
| memory/innodb/ha_innodb | 35936 |
...
これは、このクエリの実行時に各カテゴリで使用されるメモリの量を示します。別のクエリの実行中にこのクエリを複数回実行するとSELECT alias...、クエリのメモリ使用量が実行全体を通じて必ずしも一定ではないため、異なる結果が表示される可能性があります。このクエリの各実行は、ある時点のサンプルを表します。したがって、時間の経過とともに使用量がどのように変化するかを理解したい場合は、多くのサンプルを採取する必要があります。
memory/sql/Filesort_buffer::sort_keysがテーブルにdocumentationありませんperformance_schema.setup_instruments。
SELECT name, documentation
FROM performance_schema.setup_instruments
WHERE name LIKE 'memory%sort_keys';
+---------------------------------------+---------------+
| name | documentation |
+---------------------------------------+---------------+
| memory/sql/Filesort_buffer::sort_keys | <null> |
+---------------------------------------+---------------+
ただし、名前は、それがファイル内のデータを並べ替えるために使用されるメモリであることを示しています。このクエリのコストのほとんどは、データを降順で表示できるようにデータを並べ替えることにかかるため、これは当然のことです。
時間をかけて使用量を収集する
次に、メモリ使用量を経時的にサンプリングできるようにする必要があります。このクエリは分析クエリの実行中に 1 回または少数回しか実行できないため、短いクエリにはあまり役に立ちません。これは、実行時間が長いクエリ (数秒または数分かかるクエリ) の場合により便利です。いずれにせよ、これらのクエリはメモリの大部分を使用する可能性が高いため、これらのタイプのクエリを分析したいと考えています。
これは完全に SQL で実装でき、ストアド プロシージャ経由で呼び出すことができます。ただし、この場合は、Python の別のスクリプトを使用して監視を提供します。
#!/usr/bin/env python3
import time
import MySQLdb
import argparse
MEM_QUERY='''
SELECT event_name, current_number_of_bytes_used
FROM performance_schema.memory_summary_by_thread_by_event_name
WHERE thread_id = %s
ORDER BY current_number_of_bytes_used DESC LIMIT 4
'''
parser = argparse.ArgumentParser()
parser.add_argument('--thread-id', type=int, required=True)
args = parser.parse_args()
dbc = MySQLdb.connect(host='127.0.0.1', user='root', password='password')
c = dbc.cursor()
ms = 0
while(True):
c.execute(MEM_QUERY, (args.thread_id,))
results = c.fetchall()
print(f'\n## Memory usage at time {ms} ##')
for r in results:
print(f'{r[0][7:]} -> {round(r[1]/1024,2)}Kb')
ms+=250
time.sleep(0.25)
これは、このタイプの監視スクリプトの簡単な最初の試みです。要約すると、このコードは次のことを行います。
- コマンドライン経由で監視する提供されたスレッド ID を取得します。
- MySQL データベースへの接続をセットアップする
- 250 ミリ秒ごとにクエリを実行して、最も使用されている 4 つのメモリ カテゴリを取得し、読み取り値を出力します。
これは、分析のニーズに応じてさまざまな方法で調整できます。たとえば、サーバーへの ping の頻度を調整したり、反復ごとにリストされるメモリ クラスの数を変更したりします。クエリの実行中にこのコマンドを実行すると、次の結果が得られます。
...
## Memory usage at time 4250 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
## Memory usage at time 4500 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
## Memory usage at time 4750 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
## Memory usage at time 5000 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
...
それは素晴らしいことですが、いくつかの弱点もあります。最初の 4 つのメモリ使用量カテゴリを超えたものが表示されるのは良いことですが、その数を増やすと、このすでに大きな出力ダンプのサイズが増加します。視覚化してメモリ使用量を一目で理解する簡単な方法があればいいのにと思います。これは、スクリプトで結果を CSV または JSON にダンプし、ビジュアライザーにロードすることで実行できます。さらに良いのは、データが流入するにつれてリアルタイムの結果をプロットできることです。これにより、更新されたビューが提供され、1 つのツールでメモリ使用量をリアルタイムで観察できるようになります。
メモリ使用量をプロットする
ツールをより便利にし、視覚化するために、いくつかの変更が加えられます。
- ユーザーはコマンド ラインで接続 ID を指定し、スクリプトは基礎となるスレッドを検索します。
- スクリプトがメモリ データを要求する頻度もコマンド ラインから設定できます。
- この
matplotlibライブラリは、メモリ使用量の視覚化を生成するために使用されます。これには、最も高いメモリ使用量カテゴリを示す凡例を含むスタック プロットが含まれ、過去 50 個のサンプルが保持されます。
これはかなりの量のコードですが、完全を期すためにここに含めています。
#!/usr/bin/env python3
import matplotlib.pyplot as plt
import numpy as np
import MySQLdb
import argparse
MEM_QUERY='''
SELECT event_name, current_number_of_bytes_used
FROM performance_schema.memory_summary_by_thread_by_event_name
WHERE thread_id = %s
ORDER BY event_name DESC'''
TID_QUERY='''
SELECT thread_id
FROM performance_schema.threads
WHERE PROCESSLIST_ID=%s'''
class MemoryProfiler:
def __init__(self):
self.x = []
self.y = []
self.mem_labels = ['XXXXXXXXXXXXXXXXXXXXXXX']
self.ms = 0
self.color_sequence = ['#ffc59b', '#d4c9fe', '#a9dffe', '#a9ecb8',
'#fff1a8', '#fbbfc7', '#fd812d', '#a18bf5',
'#47b7f8', '#40d763', '#f2b600', '#ff7082']
plt.rcParams['axes.xmargin'] = 0
plt.rcParams['axes.ymargin'] = 0
plt.rcParams["font.family"] = "inter"
def update_xy_axis(self, results, frequency):
self.ms += frequency
self.x.append(self.ms)
if (len(self.y) == 0):
self.y = [[] for x in range(len(results))]
for i in range(len(results)-1, -1, -1):
usage = float(results[i][1]) / 1024
self.y[i].append(usage)
if (len(self.x) > 50):
self.x.pop(0)
for i in range(len(self.y)):
self.y[i].pop(0)
def update_labels(self, results):
total_mem = sum(map(lambda e: e[1], results))
self.mem_labels.clear()
for i in range(len(results)-1, -1, -1):
usage = float(results[i][1]) / 1024
mem_type = results[i][0]
# Remove 'memory/' from beginning of name for brevity
mem_type = mem_type[7:]
# Only show top memory users in legend
if (usage < total_mem / 1024 / 50):
mem_type = '_' + mem_type
self.mem_labels.insert(0, mem_type)
def draw_plot(self, plt):
plt.clf()
plt.stackplot(self.x, self.y, colors = self.color_sequence)
plt.legend(labels=self.mem_labels, bbox_to_anchor=(1.04, 1), loc="upper left", borderaxespad=0)
plt.xlabel("milliseconds since monitor began")
plt.ylabel("Kilobytes of memory")
def configure_plot(self, plt):
plt.ion()
fig = plt.figure(figsize=(12,5))
plt.stackplot(self.x, self.y, colors=self.color_sequence)
plt.legend(labels=self.mem_labels, bbox_to_anchor=(1.04, 1), loc="upper left", borderaxespad=0)
plt.tight_layout(pad=4)
return fig
def start_visualization(self, database_connection, connection_id, frequency):
c = database_connection.cursor();
fig = self.configure_plot(plt)
while(True):
c.execute(MEM_QUERY, (connection_id,))
results = c.fetchall()
self.update_xy_axis(results, frequency)
self.update_labels(results)
self.draw_plot(plt)
fig.canvas.draw_idle()
fig.canvas.start_event_loop(frequency / 1000)
def get_command_line_args():
'''
Process arguments and return argparse object to caller.
'''
parser = argparse.ArgumentParser(description='Monitor MySQL query memory for a particular connection.')
parser.add_argument('--connection-id', type=int, required=True,
help='The MySQL connection to monitor memory usage of')
parser.add_argument('--frequency', type=float, default=500,
help='The frequency at which to ping for memory usage update in milliseconds')
return parser.parse_args()
def get_thread_for_connection_id(database_connection, cid):
'''
Get a thread ID corresponding to the connection ID
PARAMS
database_connection - Database connection object
cid - The connection ID to find the thread for
'''
c = database_connection.cursor()
c.execute(TID_QUERY, (cid,))
result = c.fetchone()
return int(result[0])
def main():
args = get_command_line_args()
database_connection = MySQLdb.connect(host='127.0.0.1', user='root', password='password')
connection_id = get_thread_for_connection_id(database_connection, args.connection_id)
m = MemoryProfiler()
m.start_visualization(database_connection, connection_id, args.frequency)
connection.close()
if __name__ == "__main__":
main()
これにより、MySQL クエリの実行を詳細に監視できるようになります。これを使用するには、まず分析する接続の接続 ID を取得します。
SELECT CONNECTION_ID();
次に、次のコマンドを実行すると、監視セッションが開始されます。
./monitor.py --connection-id YOUR_CONNECTION_ID --frequency 250
データベースに対してクエリを実行すると、メモリ使用量の増加を観察し、どのカテゴリがメモリに最も貢献しているかを確認できます。
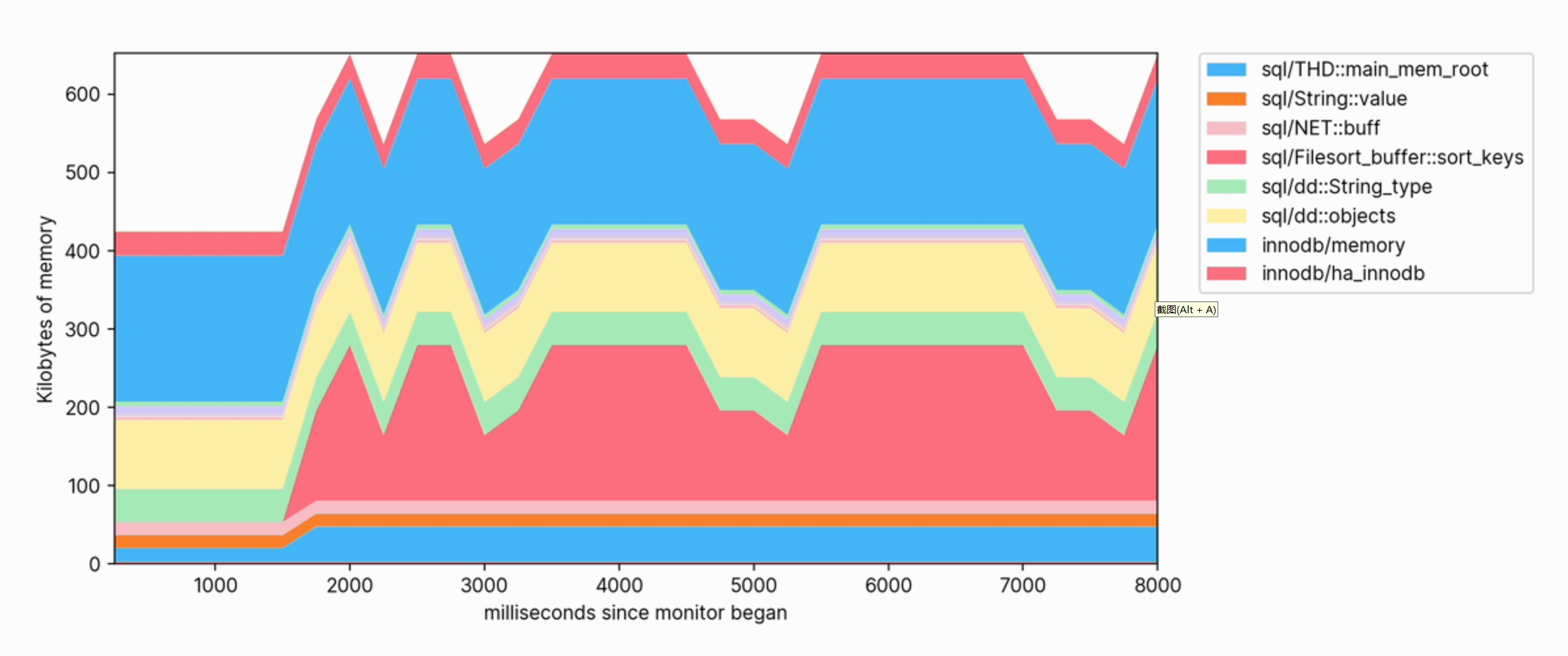
この視覚化は、どの操作がメモリを消費するかを明確に確認するのにも役立ちます。たとえば、次は、大きなテーブルに FULLTEXT インデックスを作成するために使用されるメモリ プロファイルのスニペットです。
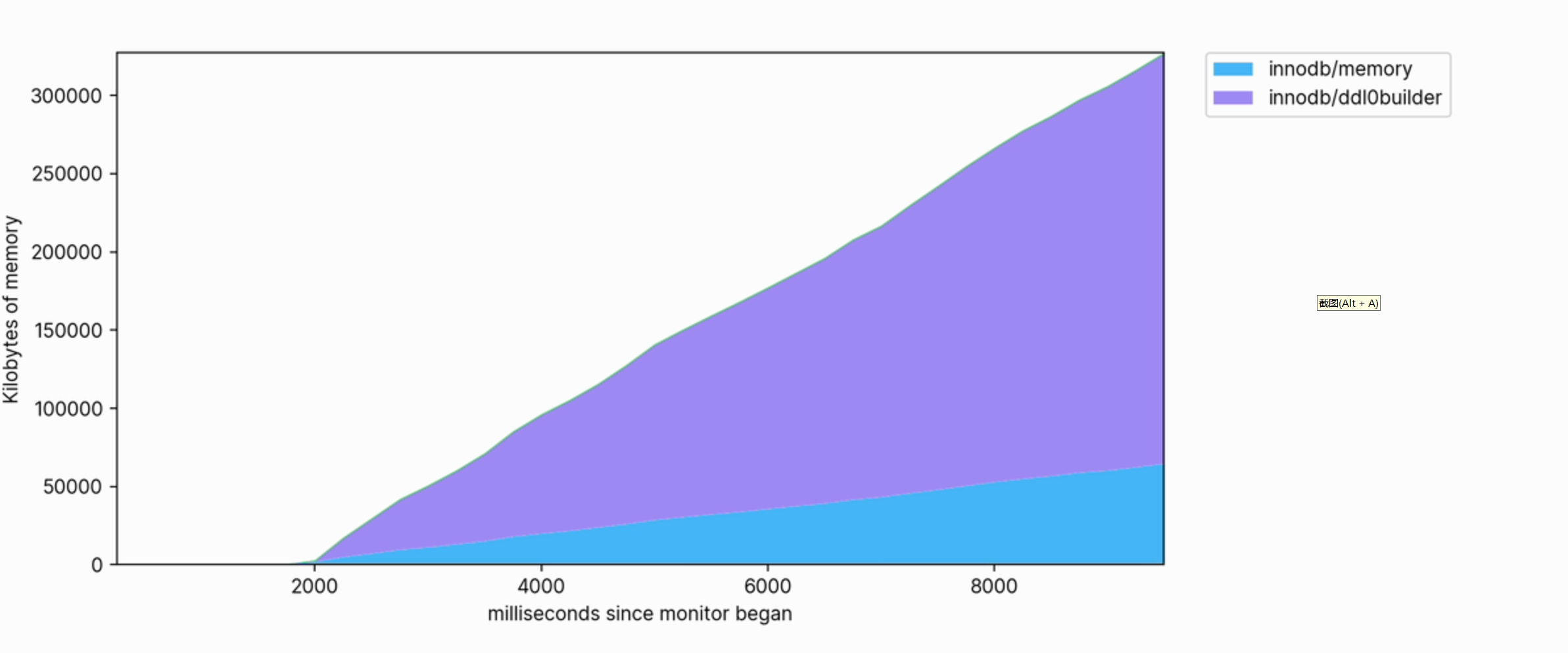
メモリの使用量は多く、実行中に数百メガバイトを使用するまで増加し続けます。
結論は
頻繁に必要になるわけではありませんが、詳細なメモリ使用量情報を取得できる機能は、詳細なクエリの最適化が必要な場合に非常に役立ちます。そうすることで、MySQL がシステムにメモリ負荷をかけている時期と理由、またはデータベース サーバーでメモリのアップグレードが必要かどうかを明らかにできます。 MySQL には、クエリやワークロードの分析ツールを開発できるプリミティブが多数用意されています。
さらに技術的な記事については、https: //opensource.actionsky.com/をご覧ください。
SQLEについて
SQLE は、開発環境から運用環境までの SQL 監査と管理をカバーする包括的な SQL 品質管理プラットフォームです。主流のオープンソース、商用および国内データベースをサポートし、開発、運用および保守のためのプロセス自動化機能を提供し、オンライン効率を向上させ、データ品質を向上させます。
SQL取得
| タイプ | 住所 |
|---|---|
| リポジトリ | https://github.com/actiontech/sqle |
| 書類 | https://actiontech.github.io/sqle-docs/ |
| リリースニュース | https://github.com/actiontech/sqle/releases |
| データ監査プラグイン開発ドキュメント | https://actiontech.github.io/sqle-docs/docs/dev-manual/plugins/howtouse |