

▐ URL ブラックリスト (ブルーム フィルター)
100 億のブラックリスト URL、それぞれ 64B、このブラックリストを保存するにはどうすればよいですか? URL がブラックリストに含まれているかどうかを確認する
ハッシュ表:
ブラックリストをセットとみなしてハッシュマップに保存すると、大きすぎて 640G が必要になり、明らかに非科学的です。
ブルームフィルター:
これは実際には長いバイナリ ベクトルと一連のランダム マッピング関数です。
これは、要素がセット内にあるかどうかを判断するために使用できます。その利点は、メモリ空間を少量しか消費せず、クエリ効率が高いことです。ブルーム フィルターの本質はビット配列です。ビット配列とは、配列の各要素が 1 ビットのみを占有し、各要素は 0 または 1 のみであることを意味します。
配列内の各ビットはバイナリ ビットです。ビット配列に加えて、ブルーム フィルターには K 個のハッシュ関数もあります。要素がブルーム フィルターに追加されると、次の操作が実行されます。
K 個のハッシュ関数を使用して要素値に対して K 個の計算を実行し、K 個のハッシュ値を取得します。
取得されたハッシュ値に従って、ビット配列内の対応する添字値が 1 に設定されます。
▐単語頻度統計(ファイルに分割)
20 億の整数の中から最も頻度の高い数値を見つけるための 2GB メモリ
通常のアプローチは、ハッシュ テーブルを使用して、出現する各数値の単語頻度統計を作成することです。ハッシュ テーブルのキーは整数であり、値はその整数が出現した回数を記録します。この質問のデータ量は 20 億です。オーバーフローを避けるために、ハッシュ テーブルのキーは 32 ビット (4B) であり、値も 32 ビット (4B) です。 )すると、ハッシュテーブルのレコードは8Bを占有する必要があります。
ハッシュ テーブルのレコード数が 2 億の場合、16 億バイト (8*2 億) が必要で、少なくとも 1.6 GB のメモリが必要です (16 億/2^30,1GB==2^30 バイト== 1000000000) )。その場合、20 億レコードには少なくとも 16 GB のメモリが必要ですが、これは質問の要件を満たしていません。
解決策は、ハッシュ関数を使用して、20 億個の数値を含む大きなファイルを 16 個の小さなファイルに分割することです。ハッシュ関数によれば、20 億個のデータは 16 個のファイルに均等に分散されます。同じ数値を分割することはできません。ハッシュ関数が十分であると仮定して、さまざまな小さなファイルに対して。次に、小さなファイルごとにハッシュ関数を使用して各数値の出現回数を数え、16 個のファイルの中で最も多く出現する数値を取得し、16 個の数値から最も出現率の高いキーを選択します。
▐出現しない数値(ビット配列)
40 億の非負の整数の中から出現しない数値を見つけます
元の問題では、出現した数値を保存するためにハッシュ テーブルを使用すると、最悪の場合、40 億の数値が異なることになり、ハッシュ テーブルには 40 億個のデータを保存する必要があり、32 ビット整数には4B の場合、40 億 * 4B = 160 億バイトになります。一般に、約 10 億バイトのデータには 1G のスペースが必要なので、約 16G のスペースが必要となり、要件を満たしません。
方法を変えて、ビット配列を適用してみましょう。配列サイズは 4294967295、つまり約 40 億ビット、つまり 5 億バイトなので、ビット配列の各位置には 2 つの状態が必要です。 0 と 1。では、このビット配列をどのように使用するのでしょうか?はは、配列の長さが整数の数値範囲にちょうど一致している場合、配列の各添字値は 4294967295 の数値に対応し、40 億個の符号なし数値を 1 つずつ走査します。たとえば、20 が見つかった場合、bitArray が計算されます。 [20]= 1; 666 が見つかった場合、bitArray[666]=1、すべての数値を調べた後、配列の対応する位置を 1 に変更します。
40 億の非負の整数の中に出現しない数値を検索します。メモリ制限は 10MB です。
10 億バイトのデータを処理するには約 1 GB のスペースが必要なので、10 MB のメモリで 1,000 万バイトのデータを処理できます。これは、40 億の非負の整数の場合、ビット配列に適用すると 40 億ビットになります。 /080million bit=50 の場合、処理には少なくとも 50 ブロックかかります。64 ブロックを使用して分析して答えましょう。
先進的なソリューションを要約する
10MB のメモリ制限に従って、統計間隔のサイズを決定します。これは、2 回目の走査中の bitArr サイズです。
間隔カウントを使用して、カウントが不十分な間隔を見つけます。この間隔には表示されない数値が存在する必要があります。
この間隔内の数値のビット マップ マッピングを実行し、ビット マップを走査して、表示されていない数値を見つけます。
私自身の意見
数値を探しているだけの場合は、高ビットのモジュラス演算を実行し、それを 64 の異なるファイルに書き込み、最小ファイルの bitArray を通じて一度にすべて処理できます。
40 億の符号なし整数、1 GB のメモリ、2 回出現するすべての数値を検索
元の問題では、ビットマップを使用して数値の出現を表すことができます。具体的には、長さ 4294967295×2 のビット型配列 bitArr を適用することになります。数値の単語頻度を表すのに 2 つの位置が使用されるため、長さ 4294967295×2 のビット型配列になります。 1GBのスペースを占有します。この bitArr 配列の使い方は?これらの 40 億の符号なし数値を調べます。num が初めて見つかった場合は、bitArr[num 2+1] と bitArr[num 2] を 01 に設定します。num が 2 回目に見つかった場合は、bitArr[num 2+1 ]を設定します。 num が 3 回目の場合、bitArr[num 2+1] と bitArr[num 2 ] は 11 に設定されます。将来再び num に遭遇すると、この時点では bitArr[num 2+1] と bitArr[num 2] が 11 に設定されていることがわかります。そのため、これ以上の設定は行われません。走査が完了した後、bitArr を順番に走査し、bitArr[i 2+1] と bitArr[i 2] が 10 に設定されていることが判明した場合、i は 2 回出現する数値です。
▐URLの重複(マシンによる)
100億のURLの中から重複するURLを見つける
元の問題の解決策は、ビッグ データの問題を解決するための従来の方法を使用します。つまり、ハッシュ関数を使用して大きなファイルをマシンに割り当てるか、ハッシュ関数を使用して大きなファイルを小さなファイルに分割します。この除算は、除算の結果がリソース制約を満たすまで実行されます。まず、面接官に、メモリやコンピューティング時間などの要件を含む、リソースの制約について尋ねる必要があります。制限要件を明確にした後、各 URL をハッシュ関数を通じて複数のマシンに割り当てるか、いくつかの小さなファイルに分割することができます。ここでの「いくつか」の正確な数は、特定のリソース制限に基づいて計算されます。
たとえば、100 億バイトの大きなファイルがハッシュ関数を通じて 100 台のマシンに配布され、各マシンは、割り当てられた URL 内に重複する URL があるかどうかをカウントします。同時に、ハッシュ関数の性質によって、重複する URL があるかどうかが決まります。同じ URL を別のマシンに配布したり、単一のマシン上でハッシュ関数を使用して大きなファイルを 1000 個の小さなファイルに分割したり、各小さなファイルに対してハッシュ テーブルを使用して重複する URL を検索したりすることは不可能です。マシンに配布するか、ファイルを分割した後、ソートし、ソート後のURLが重複していないか確認してください。つまり、ビッグ データの問題の多くはオフロードと切り離せないということを覚えておいてください。ハッシュ関数が大きなファイルの内容を別のマシンに分散するか、ハッシュ関数が大きなファイルを小さなファイルに分割して、それぞれの小さなコレクションを処理します。 。
▐ TOPK検索(小さな根の山)
多数の単語を検索して、最も人気のある TOP100 の単語を見つけます。
当初、私たちはハッシュ シャントのアイデアを使用して、数百億のデータを含むボキャブラリ ファイルを別のマシンにシャントしました。マシンの具体的な数は、インタビュアーまたはそれ以上の制限によって決まりました。各マシンのメモリ不足などで分散データ量がまだ多い場合、ハッシュ関数を利用して各マシンの分散ファイルを小さなファイルに分割して処理できます。
それぞれの小さなファイルを処理するときに、ハッシュ テーブルは各単語とその単語の頻度をカウントします。ハッシュ テーブルのレコードが確立された後、ハッシュ テーブルの走査中に、サイズ 100 の小さなルート ヒープが使用されて [Get the] が選択されます。各小さなファイルの上位 100 (ソートされていない全体の上位 100)。それぞれの小さなファイルには、単語頻度の独自の小さなルート ヒープ (ソートされていない全体の上位 100) があり、単語の頻度に従って小さなルート ヒープ内の単語をソートすることにより、各小さなファイルのソートされた上位 100 が得られます。次に、各小さなファイルの上位 100 を外部でソートするか、引き続き小さなルート ヒープを使用して各マシン上で上位 100 を選択します。次に、異なるマシン間の上位 100 が外部でソートされるか、小さなルート ヒープが引き続き使用され、最終的に数百億のデータ全体の上位 100 が取得されます。トップK問題については、ハッシュ関数流用やハッシュテーブルを用いた単語頻度統計のほか、ヒープ構造や外部ソートを用いて対処することが多い。
▐中央値(一方向二分探索)
10MB メモリ、100 億の整数の中央値を求める
十分なメモリ: 十分なメモリがある場合は、100 億個の項目をすべて並べ替えて、真ん中の項目を見つけるだけです。しかし、面接官はあなたの思い出を教えてくれると思いますか? ?
メモリ不足: 質問には整数とありますが、signed int であると考えられるため、4 バイトで 32 ビットを占有します。
100 億の数値が大きなファイルに保存されていると仮定し、ファイルの一部を順番にメモリに読み取り (メモリ制限を超えないように)、各数値をバイナリで表し、バイナリの最上位ビット (ビット 32、符号ビット、 0 は正、1 は負です)、数値の最上位ビットが 0 の場合、数値は file_0 ファイルに書き込まれ、最上位ビットが 1 の場合、数値は file_1 ファイルに書き込まれます。
したがって、100 億の数値が 2 つのファイルに分割されます。file_0 ファイルには 60 億の数値があり、file_1 ファイルには 40 億の数値があるとします。次に、中央値は file_0 ファイル内にあり、file_0 ファイル内のすべての数値を並べ替えた後の 10 億番目の数値になります。 (file_1 の数値はすべて負の数値であり、file_0 の数値はすべて正の数値です。つまり、負の数値は合計で 40 億個しかないため、並べ替え後の 50 億番目の数値は file_0 に存在する必要があります。)
ここでは、file_0 ファイルを処理するだけで済みます (file_1 ファイルについてはもう考慮する必要はありません)。 file_0 ファイルについても、上記と同じ措置を講じます。file_0 ファイルの一部を順番にメモリに読み取り (メモリ制限を超えないように)、各数値をバイナリで表し、バイナリの 2 番目に上位のビット (31 番目のビット) を比較します。数値の 2 番目に上位のビットが 0 の場合は、file_0_0 ファイルに書き込みます。2 番目の上位のビットが 1 の場合は、file_0_1 ファイルに書き込みます。
ここで、file_0_0 に 30 億の数値があり、file_0_1 に 30 億の数値があると仮定すると、中央値は、file_0_0 の数値を小さいものから大きいものに並べ替えた後の 10 億番目の数値になります。
file_0_1 ファイルを破棄し、次に高い桁 (30 番目の位置) に従って file_0_0 ファイルを分割し続けます。今回分割された 2 つのファイルには、file_0_0_0 に 5 億個の数値があり、file_0_0_1 には 25 億個の数値があるとします。 file_0_0_1 ファイル内のすべての数値を並べ替えた後の 5 億番目の数値です。
上記の考え方によれば、分割されたファイルをメモリに直接ロードできるようになるまでは、数値を直接ソートして中央値を求めることができます。
▐短縮ドメインネームシステム (キャッシュ)
長い URL を短い URL に変換する短いドメイン ネーム システムを設計します。
番号アサイナを使用する場合、初期値は 0 です。ショート リンク生成リクエストごとに、番号アサイナの値が増分され、この値が 62 の 16 進数 (a-zA-Z0-9) に変換されます。 request リクエスト時の番号アサイナの値は 0 で、16 進数の a に対応します。2 番目のリクエストでは、番号アサイナの値は 1 で、16 進数の b に対応します。番号割り当て子は 10000 で、16 進表記は sBc に対応します。
短いリンク サーバーのドメイン名と、割り当て者の 62 桁の 16 進値を文字列として連結します。これは、短いリンクの URL です (例: t.cn/sBc)。
リダイレクト プロセス: ショート リンクを生成した後、ショート リンクとロング リンクの間のマッピング関係 (つまり、sBc -> URL) を保存する必要があります。ブラウザはショート リンク サーバーにアクセスすると、元のリンクを取得します。 URL パスを指定し、302 リダイレクトを実行します。マッピング関係は、Redis や Memcache などの KV を使用して保存できます。
▐大規模なコメントの保存 (メッセージキュー)
このようなシナリオがあるとします。ニュースに対するコメントの数はどのように設計すればよいでしょうか。
フロントエンド ページはユーザーに直接表示され、メッセージ キューを通じて非同期にデータベースに保存されます。
▐オンライン/同時ユーザー数 (Redis)
-
Web サイト上のオンライン ユーザー数を表示するためのソリューションのアイデア
-
オンラインユーザーテーブルを維持する -
Redis 統計の使用
-
Webサイトの同時接続ユーザー数を表示します。
-
ユーザーがサービスにアクセスするたびに、ユーザーの ID が ZSORT キューに書き込まれ、重みが現在の時刻になります。 -
重み (つまり、時間) に基づいて、1 分以内に組織 Zrange のユーザー数を計算します。 -
有効期限が 1 分以上経過したユーザー Zrem を削除します。
▐人気の文字列 (プレフィックス ツリー)
HashMap メソッド
文字列の合計数は比較的多くなりますが、重複排除後は 300w を超えることはありません。そのため、すべての文字列とその出現回数を HashMap に保存することを検討できます。占有されるスペースは 300w*(255+4)≈777M (そのうち) です。 4 整数が占める 4 バイトを表します)。 1G のメモリ空間があれば完全に十分であることがわかります。
アイデアは次のとおりです
まず、文字列を走査します。文字列がマップ内にない場合は、値を 1 として記録し、対応する値に 1 を加算しますO(N)。
次に、マップを走査して 10 要素の小さな上部ヒープを構築します。走査された文字列の出現数がヒープの上部にある文字列の出現数より大きい場合は、それを置き換えてヒープを小さな上部に調整します。ヒープ。
トラバーサルが完了すると、ヒープ内の 10 個の文字列が最も多く出現する文字列になります。このステップの時間計算量O(Nlog10)。
プレフィックスツリー方式
これらの文字列に同じプレフィックスが多数ある場合は、プレフィックス ツリーを使用して文字列の出現数をカウントすることを検討できます。ツリーのノードによって文字列の出現数が保存され、0 は出現しないことを意味します。
アイデアは次のとおりです
文字列をトラバースするときに、プレフィックス ツリー内を検索します。見つかった場合は、ノードに格納されている文字列の数に 1 を追加します。それ以外の場合は、構築が完了した後、その文字列の出現を追加します。葉ノードの回数は1に設定されます。
最後に、小さな上部ヒープは、文字列の出現数を並べ替えるために引き続き使用されます。
▐レッドエンベロープアルゴリズム
N-1ナイフを1間隔で切断する直線切断方式。早いほど良い
二重平均法、[0~残量/残人数*2]でランダム、比較的均一

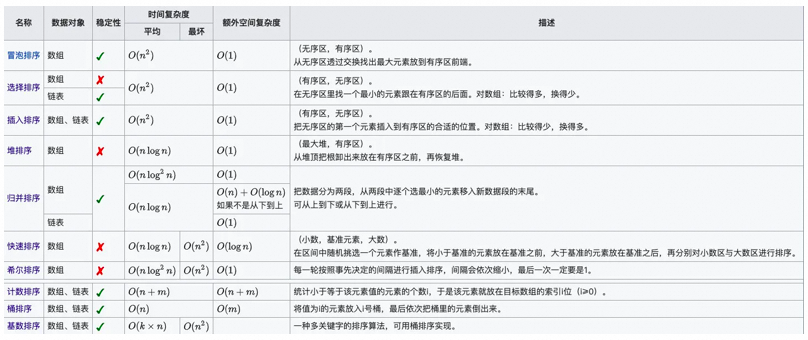
▐手書きのクイックソート
public class QuickSort {public static void swap(int[] arr, int i, int j) {int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;}/* 常规快排 */public static void quickSort1(int[] arr, int L , int R) {if (L > R) return;int M = partition(arr, L, R);quickSort1(arr, L, M - 1);quickSort1(arr, M + 1, R);}public static int partition(int[] arr, int L, int R) {if (L > R) return -1;if (L == R) return L;int lessEqual = L - 1;int index = L;while (index < R) {if (arr[index] <= arr[R])swap(arr, index, ++lessEqual);index++;}swap(arr, ++lessEqual, R);return lessEqual;}/* 荷兰国旗 */public static void quickSort2(int[] arr, int L, int R) {if (L > R) return;int[] equalArea = netherlandsFlag(arr, L, R);quickSort2(arr, L, equalArea[0] - 1);quickSort2(arr, equalArea[1] + 1, R);}public static int[] netherlandsFlag(int[] arr, int L, int R) {if (L > R) return new int[] { -1, -1 };if (L == R) return new int[] { L, R };int less = L - 1;int more = R;int index = L;while (index < more) {if (arr[index] == arr[R]) {index++;} else if (arr[index] < arr[R]) {swap(arr, index++, ++less);} else {swap(arr, index, --more);}}swap(arr, more, R);return new int[] { less + 1, more };}// for testpublic static void main(String[] args) {int testTime = 1;int maxSize = 10000000;int maxValue = 100000;boolean succeed = true;long T1=0,T2=0;for (int i = 0; i < testTime; i++) {int[] arr1 = generateRandomArray(maxSize, maxValue);int[] arr2 = copyArray(arr1);int[] arr3 = copyArray(arr1);// int[] arr1 = {9,8,7,6,5,4,3,2,1};long t1 = System.currentTimeMillis();quickSort1(arr1,0,arr1.length-1);long t2 = System.currentTimeMillis();quickSort2(arr2,0,arr2.length-1);long t3 = System.currentTimeMillis();T1 += (t2-t1);T2 += (t3-t2);if (!isEqual(arr1, arr2) || !isEqual(arr2, arr3)) {succeed = false;break;}}System.out.println(T1+" "+T2);// System.out.println(succeed ? "Nice!" : "Oops!");}private static int[] generateRandomArray(int maxSize, int maxValue) {int[] arr = new int[(int) ((maxSize + 1) * Math.random())];for (int i = 0; i < arr.length; i++) {arr[i] = (int) ((maxValue + 1) * Math.random())- (int) (maxValue * Math.random());}return arr;}private static int[] copyArray(int[] arr) {if (arr == null) return null;int[] res = new int[arr.length];for (int i = 0; i < arr.length; i++) {res[i] = arr[i];}return res;}private static boolean isEqual(int[] arr1, int[] arr2) {if ((arr1 == null && arr2 != null) || (arr1 != null && arr2 == null))return false;if (arr1 == null && arr2 == null)return true;if (arr1.length != arr2.length)return false;for (int i = 0; i < arr1.length; i++)if (arr1[i] != arr2[i])return false;return true;}private static void printArray(int[] arr) {if (arr == null)return;for (int i = 0; i < arr.length; i++)System.out.print(arr[i] + " ");System.out.println();}}
▐手書きの差し込み
public static void merge(int[] arr, int L, int M, int R) {int[] help = new int[R - L + 1];int i = 0;int p1 = L;int p2 = M + 1;while (p1 <= M && p2 <= R)help[i++] = arr[p1] <= arr[p2] ? arr[p1++] : arr[p2++];while (p1 <= M)help[i++] = arr[p1++];while (p2 <= R)help[i++] = arr[p2++];for (i = 0; i < help.length; i++)arr[L + i] = help[i];}public static void mergeSort(int[] arr, int L, int R) {if (L == R)return;int mid = L + ((R - L) >> 1);process(arr, L, mid);process(arr, mid + 1, R);merge(arr, L, mid, R);}public static void main(String[] args) {int[] arr1 = {9,8,7,6,5,4,3,2,1};mergeSort(arr, 0, arr.length - 1);printArray(arr);}
▐手書きのスタック
// 堆排序额外空间复杂度O(1)public static void heapSort(int[] arr) {if (arr == null || arr.length < 2)return;for (int i = arr.length - 1; i >= 0; i--)heapify(arr, i, arr.length);int heapSize = arr.length;swap(arr, 0, --heapSize);// O(N*logN)while (heapSize > 0) { // O(N)heapify(arr, 0, heapSize); // O(logN)swap(arr, 0, --heapSize); // O(1)}}// arr[index]刚来的数,往上public static void heapInsert(int[] arr, int index) {while (arr[index] > arr[(index - 1) / 2]) {swap(arr, index, (index - 1) / 2);index = (index - 1) / 2;}}// arr[index]位置的数,能否往下移动public static void heapify(int[] arr, int index, int heapSize) {int left = index * 2 + 1; // 左孩子的下标while (left < heapSize) { // 下方还有孩子的时候// 两个孩子中,谁的值大,把下标给largest// 1)只有左孩子,left -> largest// 2) 同时有左孩子和右孩子,右孩子的值<= 左孩子的值,left -> largest// 3) 同时有左孩子和右孩子并且右孩子的值> 左孩子的值, right -> largestint largest = left+1 < heapSize && arr[left+1]> arr[left] ? left+1 : left;// 父和较大的孩子之间,谁的值大,把下标给largestlargest = arr[largest] > arr[index] ? largest : index;if (largest == index)break;swap(arr, largest, index);index = largest;left = index * 2 + 1;}}public static void swap(int[] arr, int i, int j) {int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;}public static void main(String[] args) {int[] arr1 = {9,8,7,6,5,4,3,2,1};heapSort(arr1);printArray(arr1);}
▐手書きのシングルトン
public class Singleton {private volatile static Singleton singleton;private Singleton() {}public static Singleton getSingleton() {if (singleton == null) {synchronized (Singleton.class) {if (singleton == null) {singleton = new Singleton();}}}return singleton;}}
▐手書きのLRUキャッシュ
// 基于linkedHashMappublic class LRUCache {private LinkedHashMap<Integer,Integer> cache;private int capacity; //容量大小public LRUCache(int capacity) {cache = new LinkedHashMap<>(capacity);this.capacity = capacity;}public int get(int key) {//缓存中不存在此key,直接返回if(!cache.containsKey(key)) {return -1;}int res = cache.get(key);cache.remove(key); //先从链表中删除cache.put(key,res); //再把该节点放到链表末尾处return res;}public void put(int key,int value) {if(cache.containsKey(key)) {cache.remove(key); //已经存在,在当前链表移除}if(capacity == cache.size()) {//cache已满,删除链表头位置Set<Integer> keySet = cache.keySet();Iterator<Integer> iterator = keySet.iterator();cache.remove(iterator.next());}cache.put(key,value); //插入到链表末尾}}
//手写双向链表class LRUCache {class DNode {DNode prev;DNode next;int val;int key;}Map<Integer, DNode> map = new HashMap<>();DNode head, tail;int cap;public LRUCache(int capacity) {head = new DNode();tail = new DNode();head.next = tail;tail.prev = head;cap = capacity;}public int get(int key) {if (map.containsKey(key)) {DNode node = map.get(key);removeNode(node);addToHead(node);return node.val;} else {return -1;}}public void put(int key, int value) {if (map.containsKey(key)) {DNode node = map.get(key);node.val = value;removeNode(node);addToHead(node);} else {DNode newNode = new DNode();newNode.val = value;newNode.key = key;addToHead(newNode);map.put(key, newNode);if (map.size() > cap) {map.remove(tail.prev.key);removeNode(tail.prev);}}}public void removeNode(DNode node) {DNode prevNode = node.prev;DNode nextNode = node.next;prevNode.next = nextNode;nextNode.prev = prevNode;}public void addToHead(DNode node) {DNode firstNode = head.next;head.next = node;node.prev = head;node.next = firstNode;firstNode.prev = node;}}
▐手書きスレッドプール
package com.concurrent.pool;import java.util.HashSet;import java.util.Set;import java.util.concurrent.ArrayBlockingQueue;import java.util.concurrent.BlockingQueue;public class MySelfThreadPool {//默认线程池中的线程的数量private static final int WORK_NUM = 5;//默认处理任务的数量private static final int TASK_NUM = 100;private int workNum;//线程数量private int taskNum;//任务数量private final Set<WorkThread> workThreads;//保存线程的集合private final BlockingQueue<Runnable> taskQueue;//阻塞有序队列存放任务public MySelfThreadPool() {this(WORK_NUM, TASK_NUM);}public MySelfThreadPool(int workNum, int taskNum) {if (workNum <= 0) workNum = WORK_NUM;if (taskNum <= 0) taskNum = TASK_NUM;taskQueue = new ArrayBlockingQueue<>(taskNum);this.workNum = workNum;this.taskNum = taskNum;workThreads = new HashSet<>();//启动一定数量的线程数,从队列中获取任务处理for (int i=0;i<workNum;i++) {WorkThread workThread = new WorkThread("thead_"+i);workThread.start();workThreads.add(workThread);}}public void execute(Runnable task) {try {taskQueue.put(task);} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}}public void destroy() {System.out.println("ready close thread pool...");if (workThreads == null || workThreads.isEmpty()) return ;for (WorkThread workThread : workThreads) {workThread.stopWork();workThread = null;//help gc}workThreads.clear();}private class WorkThread extends Thread{public WorkThread(String name) {super();setName(name);}@Overridepublic void run() {while (!interrupted()) {try {Runnable runnable = taskQueue.take();//获取任务if (runnable !=null) {System.out.println(getName()+" readyexecute:"+runnable.toString());runnable.run();//执行任务}runnable = null;//help gc} catch (Exception e) {interrupt();e.printStackTrace();}}}public void stopWork() {interrupt();}}}package com.concurrent.pool;public class TestMySelfThreadPool {private static final int TASK_NUM = 50;//任务的个数public static void main(String[] args) {MySelfThreadPool myPool = new MySelfThreadPool(3,50);for (int i=0;i<TASK_NUM;i++) {myPool.execute(new MyTask("task_"+i));}}static class MyTask implements Runnable{private String name;public MyTask(String name) {this.name = name;}public String getName() {return name;}public void setName(String name) {this.name = name;}@Overridepublic void run() {try {Thread.sleep(1000);} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();}System.out.println("task :"+name+" end...");}@Overridepublic String toString() {// TODO Auto-generated method stubreturn "name = "+name;}}}
▐手書きの消費者生産者パターン
public class Storage {private static int MAX_VALUE = 100;private List<Object> list = new ArrayList<>();public void produce(int num) {synchronized (list) {while (list.size() + num > MAX_VALUE) {System.out.println("暂时不能执行生产任务");try {list.wait();} catch (InterruptedException e) {e.printStackTrace();}}for (int i = 0; i < num; i++) {list.add(new Object());}System.out.println("已生产产品数"+num+" 仓库容量"+list.size());list.notifyAll();}}public void consume(int num) {synchronized (list) {while (list.size() < num) {System.out.println("暂时不能执行消费任务");try {list.wait();} catch (InterruptedException e) {e.printStackTrace();}}for (int i = 0; i < num; i++) {list.remove(0);}System.out.println("已消费产品数"+num+" 仓库容量" + list.size());list.notifyAll();}}}public class Producer extends Thread {private int num;private Storage storage;public Producer(Storage storage) {this.storage = storage;}public void setNum(int num) {this.num = num;}public void run() {storage.produce(this.num);}}public class Customer extends Thread {private int num;private Storage storage;public Customer(Storage storage) {this.storage = storage;}public void setNum(int num) {this.num = num;}public void run() {storage.consume(this.num);}}public class Test {public static void main(String[] args) {Storage storage = new Storage();Producer p1 = new Producer(storage);Producer p2 = new Producer(storage);Producer p3 = new Producer(storage);Producer p4 = new Producer(storage);Customer c1 = new Customer(storage);Customer c2 = new Customer(storage);Customer c3 = new Customer(storage);p1.setNum(10);p2.setNum(20);p3.setNum(80);c1.setNum(50);c2.setNum(20);c3.setNum(20);c1.start();c2.start();c3.start();p1.start();p2.start();p3.start();}}
▐手書きブロックキュー
public class blockQueue {private List<Integer> container = new ArrayList<>();private volatile int size;private volatile int capacity;private Lock lock = new ReentrantLock();private final Condition isNull = lock.newCondition();private final Condition isFull = lock.newCondition();blockQueue(int capacity) {this.capacity = capacity;}public void add(int data) {try {lock.lock();try {while (size >= capacity) {System.out.println("阻塞队列满了");isFull.await();}} catch (Exception e) {isFull.signal();e.printStackTrace();}++size;container.add(data);isNull.signal();} finally {lock.unlock();}}public int take() {try {lock.lock();try {while (size == 0) {System.out.println("阻塞队列空了");isNull.await();}} catch (Exception e) {isNull.signal();e.printStackTrace();}--size;int res = container.get(0);container.remove(0);isFull.signal();return res;} finally {lock.unlock();}}}public static void main(String[] args) {AxinBlockQueue queue = new AxinBlockQueue(5);Thread t1 = new Thread(() -> {for (int i = 0; i < 100; i++) {queue.add(i);System.out.println("塞入" + i);try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}}});Thread t2 = new Thread(() -> {for (; ; ) {System.out.println("消费"+queue.take());try {Thread.sleep(800);} catch (InterruptedException e) {e.printStackTrace();}}});t1.start();t2.start();}
▐手書きマルチスレッド交互印刷 ABC
package com.demo.test;import java.util.concurrent.locks.Condition;import java.util.concurrent.locks.ReentrantLock;public class syncPrinter implements Runnable{// 打印次数private static final int PRINT_COUNT = 10;private final ReentrantLock reentrantLock;private final Condition thisCondtion;private final Condition nextCondtion;private final char printChar;public syncPrinter(ReentrantLock reentrantLock, Condition thisCondtion, Condition nextCondition, char printChar) {this.reentrantLock = reentrantLock;this.nextCondtion = nextCondition;this.thisCondtion = thisCondtion;this.printChar = printChar;}@Overridepublic void run() {// 获取打印锁 进入临界区reentrantLock.lock();try {// 连续打印PRINT_COUNT次for (int i = 0; i < PRINT_COUNT; i++) {//打印字符System.out.print(printChar);// 使用nextCondition唤醒下一个线程// 因为只有一个线程在等待,所以signal或者signalAll都可以nextCondtion.signal();// 不是最后一次则通过thisCondtion等待被唤醒// 必须要加判断,不然虽然能够打印10次,但10次后就会直接死锁if (i < PRINT_COUNT - 1) {try {// 本线程让出锁并等待唤醒thisCondtion.await();} catch (InterruptedException e) {e.printStackTrace();}}}} finally {reentrantLock.unlock();}}public static void main(String[] args) throws InterruptedException {ReentrantLock lock = new ReentrantLock();Condition conditionA = lock.newCondition();Condition conditionB = lock.newCondition();Condition conditionC = lock.newCondition();Thread printA = new Thread(new syncPrinter(lock, conditionA, conditionB,'A'));Thread printB = new Thread(new syncPrinter(lock, conditionB, conditionC,'B'));Thread printC = new Thread(new syncPrinter(lock, conditionC, conditionA,'C'));printA.start();Thread.sleep(100);printB.start();Thread.sleep(100);printC.start();}}
▐FooBarを交互に印刷する
//手太阴肺经 BLOCKING Queuepublic class FooBar {private int n;private BlockingQueue<Integer> bar = new LinkedBlockingQueue<>(1);private BlockingQueue<Integer> foo = new LinkedBlockingQueue<>(1);public FooBar(int n) {this.n = n;}public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {foo.put(i);printFoo.run();bar.put(i);}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; i++) {bar.take();printBar.run();foo.take();}}}//手阳明大肠经CyclicBarrier 控制先后class FooBar6 {private int n;public FooBar6(int n) {this.n = n;}CyclicBarrier cb = new CyclicBarrier(2);volatile boolean fin = true;public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {while(!fin);printFoo.run();fin = false;try {cb.await();} catch (BrokenBarrierException e) {}}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; i++) {try {cb.await();} catch (BrokenBarrierException e) {}printBar.run();fin = true;}}}//手少阴心经 自旋 + 让出CPUclass FooBar5 {private int n;public FooBar5(int n) {this.n = n;}volatile boolean permitFoo = true;public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; ) {if(permitFoo) {printFoo.run();i++;permitFoo = false;}else{Thread.yield();}}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; ) {if(!permitFoo) {printBar.run();i++;permitFoo = true;}else{Thread.yield();}}}}//手少阳三焦经 可重入锁 + Conditionclass FooBar4 {private int n;public FooBar4(int n) {this.n = n;}Lock lock = new ReentrantLock(true);private final Condition foo = lock.newCondition();volatile boolean flag = true;public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {lock.lock();try {while(!flag) {foo.await();}printFoo.run();flag = false;foo.signal();}finally {lock.unlock();}}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n;i++) {lock.lock();try {while(flag) {foo.await();}printBar.run();flag = true;foo.signal();}finally {lock.unlock();}}}}//手厥阴心包经 synchronized + 标志位 + 唤醒class FooBar3 {private int n;// 标志位,控制执行顺序,true执行printFoo,false执行printBarprivate volatile boolean type = true;private final Object foo= new Object(); // 锁标志public FooBar3(int n) {this.n = n;}public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {synchronized (foo) {while(!type){foo.wait();}printFoo.run();type = false;foo.notifyAll();}}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; i++) {synchronized (foo) {while(type){foo.wait();}printBar.run();type = true;foo.notifyAll();}}}}//手太阳小肠经 信号量 适合控制顺序class FooBar2 {private int n;private Semaphore foo = new Semaphore(1);private Semaphore bar = new Semaphore(0);public FooBar2(int n) {this.n = n;}public void foo(Runnable printFoo) throws InterruptedException {for (int i = 0; i < n; i++) {foo.acquire();printFoo.run();bar.release();}}public void bar(Runnable printBar) throws InterruptedException {for (int i = 0; i < n; i++) {bar.acquire();printBar.run();foo.release();}}}
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。