

外部キャッシュはレイテンシの短縮には優れていますが、利点よりも多くの問題を引き起こすことがよくあります。この問題を解決する方法は次のとおりです。
Felipe Cardeneti Mendes 著『Why and How Teams Are Replaceing Initial Database Caches』より翻訳。
既存のデータベースが必要なサービス レベル アグリーメント (SLA) を満たせない場合、チームは外部キャッシュを検討することがよくあります。これは明らかにパフォーマンス重視の決定です。データベースの前に外部キャッシュを配置することは、さまざまな要因 (非効率なデータベース内部、ドライバーの使用状況、インフラストラクチャの選択、トラフィックの急増など) によって引き起こされる最適ではないレイテンシーを補うために行われることがよくあります。
キャッシングは、大きな手間をかけずに、またデータベースの拡張、データベース スキーマの再設計、さらにはより深いテクノロジーの変換といった多大なコストを発生させることなく展開を実装できるため、迅速かつ簡単なソリューションであるように見えます。ただし、外部キャッシュはよく言われているほど単純ではありません。これらは、分散アプリケーション アーキテクチャの最も問題のあるコンポーネントの 1 つになる可能性があります。
場合によっては、これは必要悪になります。たとえば、長時間かつ高価な計算の結果、変換されたデータに頻繁にアクセスする必要があり、待機時間を短縮するためにあらゆる方法を試した場合などです。しかし多くの場合、パフォーマンスの向上にはそれだけの価値がありません。 1 つの問題を解決しても、別の問題が発生します。
ここでは、外部キャッシュに関連する見落とされがちなリスクと、3 つのチームがコア データベースと外部キャッシュを単一のソリューションに置き換えることでパフォーマンスの向上とコスト削減を達成した方法を紹介します。スポイラー: 彼らは、特殊な内部キャッシュを活用することでロングテール レイテンシーの改善を実現する高性能データベースである ScyllaDB を使用しています。
なぜキャッシュしないのでしょうか?
ScyllaDB では、従来のデータベースのパフォーマンス向上の試みのコスト、手間、制限に取り組む無数のチームと協力しています。データベースの前に外部キャッシュを配置するときにチームが遭遇する主な問題は次のとおりです。
外部キャッシュによりレイテンシが増加する
個別のキャッシュは、途中でもう 1 回ジャンプすることを意味します。キャッシュがデータベースを囲む場合、最初のアクセスはキャッシュ層で発生します。データがキャッシュにない場合、リクエストはデータベースに送信されます。これにより、キャッシュされていないデータへのすでに遅いパスに待ち時間が追加されます。データセット全体がキャッシュに収まれば、追加の遅延は発生しないと主張する人もいるかもしれません。ただし、データ セットがかなり小さい場合を除き、すべてをメモリに保存するとコストが大幅に増加し、ほとんどの組織にとって法外な費用がかかります。
外部キャッシュには追加料金がかかります
キャッシュとは高価な DRAM を意味します。つまり、ギガバイトあたりのコストがソリッド ステート ディスクよりも高くなります。 (これについての詳細は、P99 CONF での Grafana の Danny Kopping の講演を参照してください。) キャッシュ用に完全に別個のインフラストラクチャをプロビジョニングするよりも、既存のデータベース メモリを使用するか、内部キャッシュに対応するためにメモリを増やす方が良い場合があります。最新のデータベース キャッシュは、サイズを正しく設定すると、従来のメモリ内キャッシュ ソリューションと同じくらい効率的になります。多くの場合、データベースは、ワーキング セットのサイズが大きすぎてメモリに収まらない場合に、フラッシュ ストレージへの I/O アクセスを適切に最適化するため、別のデータベース (外部キャッシュなし) が推奨され、安価なオプションになります。
外部キャッシュにより可用性が低下する
データベース自体に匹敵するキャッシュ高可用性ソリューションはありません。最新の分散データベースには複数のレプリカがあり、トポロジと速度も認識しており、データを失うことなく複数の障害に耐えることができます。
たとえば、一般的なレプリケーション パターンは 3 つのローカル レプリカであり、多くの場合、これらのレプリカ間で読み取りのバランスをとり、データベースの内部キャッシュ メカニズムを効果的に利用できます。レプリケーション係数が 3 の 9 ノードのクラスターを考えてみましょう。基本的に、各ノードはデータセットの合計サイズの約 3 分の 1 を保持します。リクエストはさまざまなレプリカ間でバランスがとれるため、データをキャッシュするためのスペースが増え、外部キャッシュの必要性がなくなります。逆に、多数のコールド リクエストの直前に外部キャッシュがたまたまエントリを無効にした場合、データベースの内部キャッシュにそのデータが存在しないため、可用性が一定期間影響を受ける可能性があります (詳細は後述)。
多くの場合、キャッシュには高可用性の特性が欠けており、ヒューリスティックに基づいてレコードが簡単に失敗したり無効になったりする可能性があります。部分的な障害はより一般的であり、一貫性の点ではさらに悪くなります。必然的にキャッシュに障害が発生すると、データベースは軽減されないクエリの洪水に見舞われ、SLA を破る可能性があります。さらに、キャッシュ自体に高可用性機能が備わっていても、そのような障害の処理をその前にある永続データベースと調整することはできません。結論: レイテンシー SLA をキャッシュに依存させるのではなく、データベースに依存します。
アプリケーションの複雑さ – アプリケーションがより多くの状況を処理する必要がある
外部キャッシュにより、アプリケーションと運用が複雑になります。外部キャッシュを取得したら、そのキャッシュをデータベースで最新の状態に保つのはユーザーの責任です。キャッシュ戦略 (ライトスルー、キャッシュ バイパスなど) に関係なく、キャッシュがデータベースと同期しなくなる可能性があるエッジ ケースが存在するため、アプリケーション開発中にこれらの状況を考慮する必要があります。キャッシュが利用できない場合やコールド状態になった場合に機能するには、クライアント設定 (フェイルオーバー、再試行、タイムアウト ポリシーなど) がキャッシュとデータベースのプロパティと一致する必要があります。通常、このようなシナリオはテストして実装することが困難です。
外部キャッシュによりデータベース キャッシュが破損する
最新のデータベースには、キャッシュとそれを管理するための複雑な戦略が組み込まれています。データベースの前にキャッシュを配置すると、ほとんどの読み取りリクエストは外部キャッシュにのみヒットし、データベースはこれらのオブジェクトをメモリに保持しません。その結果、データベース キャッシュが無効になります。リクエストが最終的にデータベースに到達すると、そのキャッシュはコールドになり、応答は主にディスクから返されます。その結果、キャッシュからデータベースへ、そしてアプリケーションへ戻る往復により、待ち時間が増加する可能性があります。
外部キャッシュによりセキュリティ リスクが増大する可能性がある
外部キャッシュにより、まったく新しい攻撃対象領域がインフラストラクチャに追加されます。キャッシュに配置されたデータの暗号化、分離、およびアクセス制御は、データベース層自体の制御とは異なる場合があります。
外部キャッシュはデータベースの知識とデータベース リソースを無視します
データベースは複雑で、システム上の特殊な I/O ワークロード向けに構築されています。多くのクエリが同じデータにアクセスするため、ディスク アクセスを節約するために、一定量のワーキング セット サイズをメモリにキャッシュできます。優れたデータベースには、どのオブジェクト、インデックス、アクセスをキャッシュするかを決定するための複雑なロジックが必要です。データベースには、いつ新しいデータで既存の (古い) キャッシュ オブジェクトを置き換えるかを決定するエビクション ポリシーも必要です。
スキャン耐性のあるキャッシュはその一例です。大範囲スキャンやテーブル全体のスキャンなど、大規模なデータ セットをスキャンする場合、多数のオブジェクトがディスクから読み取られます。データベースは、これが (通常のクエリではなく) スキャンであることを認識し、そのオブジェクトを内部キャッシュから除外することを選択できます。ただし、外部キャッシュ (リードスルー ポリシーに従う) は、結果セットを他の結果セットと同様に扱い、結果をキャッシュしようとします。データベースは、受信リクエストのレートに基づいて、キャッシュされたコンテンツをディスクと自動的に同期するため、ユーザーと開発者は、最近書き込まれたデータの検索におけるパフォーマンスと一貫性を確保するために何もする必要がありません。したがって、何らかの理由でデータベースの応答が十分に速くない場合は、次のことを意味します。
- キャッシュ構成エラー。
- キャッシュ用の RAM が不足しています。
- ワーキング セットのサイズとリクエスト パターンはキャッシュに適していません。
- データベース キャッシュの実装が不十分です。
より良い選択肢: データベースに処理させます
外部データベース キャッシュのリスクを回避して SLA を満たすにはどうすればよいでしょうか?多くのチームは、より高速なデータベース (ScyllaDB など) に移行し、専用の内部キャッシュを使用することで、より少ない手間と低コストでレイテンシー SLA を満たすことができることに気づきました。もちろん、結果はワークロードの特性や技術要件によって異なります。しかし、可能な限り、これらのチームが何を達成できるかを考えてみましょう。
SecurityScorecard は 90% の遅延削減を達成し、年間 100 万ドルを節約
SecurityScorecard は、何千もの組織がサイバーセキュリティについて理解し、緩和し、コミュニケーションする方法を変えることで、世界をより安全な場所にすることを目指しています。その評価プラットフォームは、組織の全体的なサイバーセキュリティとサイバーリスクエクスポージャを客観的かつデータ主導で定量化できる尺度です。
チームの以前のデータ アーキテクチャはしばらくの間はうまく機能していましたが、成長に追いつくことができませんでした。同社のプラットフォーム API は、3 つのデータ ストアのいずれかをクエリします。Redis (1,200 万のスコアカードの高速検索用)、Aurora (ノード全体で 40 億件の測定統計の保存用)、または Hadoop 分散ファイル システム Presto クラスター (履歴結果に対する複雑な SQL クエリ用) )。
データとリクエストが増大するにつれて、課題が生じます。 Aurora と Presto では、高スループットでレイテンシーが急増します。 Redis の可能な限り最大のインスタンスでもまだ十分ではなく、Redis クラスターの複雑さを利用したくありませんでした。
ビジネスの急速な成長に必要な新たな規模でレイテンシを削減するために、チームは ScyllaDB Cloud に注目し、レイテンシの影響を受けにくいリクエストを Presto および S3 ストレージにルーティングするための新しいスコアリング API を開発しました。このアーキテクチャを視覚化したものは次のとおりです。非常にシンプルです。
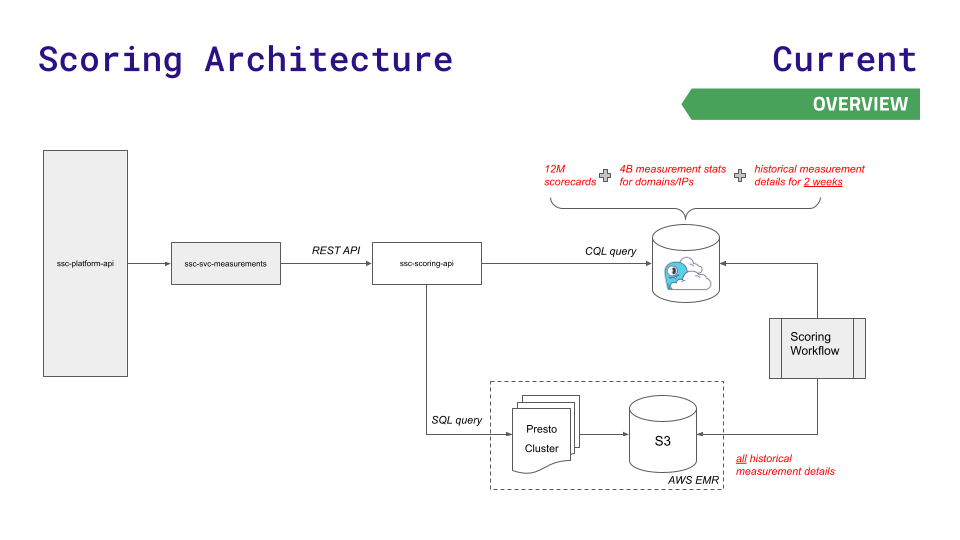
この動きにより、次のような結果が得られました。
- ほとんどのサービス エンドポイントでレイテンシが 90% 短縮
- Presto/Aurora のパフォーマンスに関連する本番環境のインシデントが 80% 削減
- 年間 100 万ドルのインフラストラクチャ コスト削減
- データパイプラインの処理速度が 30% 向上
- 顧客エクスペリエンスを劇的に向上させる
[SecurityScorecard の使用例について詳しく読む]
IMVU は Redis コストを 100 分の 1 に削減します
IMVU は、デスクトップ、タブレット、モバイル デバイス上の 3D アバターを使用して世界中の人々が交流できるようにする人気のソーシャル コミュニティです。 IMVU は、拡大する規模の要件を満たすために、以前のデータベース アーキテクチャ (Redis の前にある MySQL と Memcached) よりも高性能のソリューションが必要であると判断しました。チームは、より構成が簡単で、拡張が簡単で、(成功した場合は) 拡張も簡単なものを探しました。
IMVU のシニア ソフトウェア エンジニアである Ken Rudy 氏は、「Redis はプロトタイピング機能には優れていましたが、実際に展開してみると、その出費を正当化するのが難しくなりました。」と述べています。 「ScyllaDB は、必要なデータをメモリに保持し、その他すべてをディスク上に保持するように最適化されています。ScyllaDB を使用すると、Redis が処理できる規模の何百倍でも同じ応答性を維持できます。」
Comcast はロングテール レイテンシを 95% 削減するために年間 250 万ドルを節約
Comcast は、主に 3 つの事業を展開する世界的なメディアおよびテクノロジー企業です。Comcast Cable は、米国の住宅顧客向けビデオ、高速インターネット、電話の最大手プロバイダーの 1 つです。NBCUniversal と Sky。 Comcast の Xfinity サービスは 1,500 万世帯にサービスを提供しており、毎日 20 億以上の API 呼び出し (読み取り/書き込み) と 2 億以上の新しいオブジェクトを提供しています。 7 年間で、このプログラムは 30,000 台のデバイスのサポートから 3,100 万台以上のデバイスのサポートまで拡大しました。
Cassandra のロングテール レイテンシは、急速に成長する会社の規模では受け入れられないことが判明しました。 Cassandra の遅延の問題をユーザーから隠すために、チームはデータベースの前に 60 台のキャッシュ サーバーを配置しました。このキャッシュ層とデータベースの一貫性を維持することは、管理者にとって多くの悩みの種になります。キャッシュと関連インフラストラクチャはデータセンター間で複製する必要があるため、Comcast はキャッシュをアクティブにしておく必要があります。彼らは、書き込み量をチェックしてデータセンター間でデータをコピーするキャッシュ ウォーマーを実装しました。
Comcast は、このアプローチのオーバーヘッドに悩んだ後、すぐに ScyllaDB に目を向けました。 ScyllaDB は、内部キャッシュ メカニズムを通じてレイテンシのスパイクを最小限に抑えるように設計されており、Comcast が外部キャッシュ レイヤーを排除して、データ サービスがデータ ストアに直接接続するシンプルなフレームワークを提供します。 Comcast は、962 個の Cassandra ノードを 78 個の ScyllaDB ノードのみに置き換えることができました。 60 台のキャッシュ サーバーを完全に排除しながら、全体的な可用性とパフォーマンスが向上しました。結果: P99、P999、および P9999 は遅延を 95% 削減し、60% の運用コストで 2 倍のリクエストを処理できました。これにより、最終的にインフラストラクチャのコストと人件費が年間 250 万ドル節約されました。
結論
外部キャッシュはレイテンシーを短縮するための優れたツールですが (静的コンテンツやパーソナライズされたデータを提供するなど、いかなるレベルの永続性も必要としません)、データベースの前に配置すると利点よりも問題が生じることがよくあります。
主なトレードオフには、コストの増加、アプリケーションの複雑さの増加、データベースへの往復の追加、セキュリティ面の追加などが含まれます。既存のキャッシュ戦略を再考し、大規模で予測可能な低遅延を実現する最新のデータベースに切り替えることで、チームはインフラストラクチャを簡素化し、コストを最小限に抑えることができます。同時に、外部キャッシュによる余分な手間や複雑さを必要とせずに、SLA を満たすことができます。
未知のオープンソースプロジェクトはどれくらいの収益をもたらすのでしょうか? Microsoftの中国AIチームは数百人を巻き込んでまとめて米国に向かいましたが、 Yu Chengdong氏の転職は 15年間の「恥の柱」に釘付けになったと正式に発表されました。前に、しかし今日、彼は私たちに感謝しなければなりません— Tencent QQ Video は過去の屈辱を晴らしますか? 華中科技大学のオープンソース ミラー サイトが外部アクセス向けに正式にオープン レポート: 開発者の 74% にとって Django が依然として第一候補であるZed エディターは、 有名なオープンソース企業の元従業員 によって開発されました。 ニュースを伝えた: 部下から異議を申し立てられた後、技術リーダーは激怒し無礼になり、女性従業員は解雇され、妊娠した。 Alibaba Cloud が Tongyi Qianwen 2.5 を正式リリース Microsoft が Rust Foundation に 100 万米ドルを寄付この記事はYunyunzhongsheng ( https://yylives.cc/ ) で最初に公開されたもので、どなたでもご覧いただけます。