
著者: Xingji、Changjun、Youyi、Liutao
コンテナワーキングメモリ WorkingSet の概念の紹介
Kubernetes シナリオでは、コンテナー メモリのリアルタイム使用統計 (Pod メモリ) は WorkingSet ワーキング メモリ (WSS と略称) によって表されます。
WorkingSet のインジケーターの概念は、コンテナー シナリオのアドバイザーによって定義されます。
ワーキング メモリ WorkingSet は、ノードの削除などのメモリ リソースを決定するための Kubernetes スケジューリング決定の指標でもあります。
ワーキングセットの計算式
公式定義: K8s 公式 Web サイトのドキュメントを参照してください。
https://kubernetes.io/docs/concepts/scheduling-eviction/node-pressure-eviction/#eviction-signals
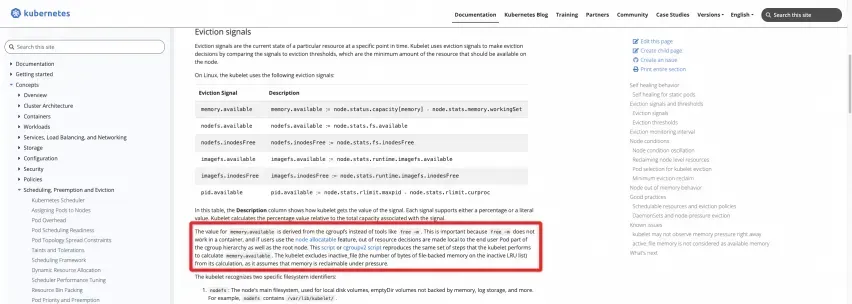
次の 2 つのスクリプトをノード上で実行して、結果を直接計算できます。
CグループV1
https://kubernetes.io/examples/admin/resource/memory-available.sh
#!/bin/bash
#!/usr/bin/env bash
# This script reproduces what the kubelet does
# to calculate memory.available relative to root cgroup.
# current memory usage
memory_capacity_in_kb=$(cat /proc/meminfo | grep MemTotal | awk '{print $2}')
memory_capacity_in_bytes=$((memory_capacity_in_kb * 1024))
memory_usage_in_bytes=$(cat /sys/fs/cgroup/memory/memory.usage_in_bytes)
memory_total_inactive_file=$(cat /sys/fs/cgroup/memory/memory.stat | grep total_inactive_file | awk '{print $2}')
memory_working_set=${memory_usage_in_bytes}
if [ "$memory_working_set" -lt "$memory_total_inactive_file" ];
then
memory_working_set=0
else
memory_working_set=$((memory_usage_in_bytes - memory_total_inactive_file))
fi
memory_available_in_bytes=$((memory_capacity_in_bytes - memory_working_set))
memory_available_in_kb=$((memory_available_in_bytes / 1024))
memory_available_in_mb=$((memory_available_in_kb / 1024))
echo "memory.capacity_in_bytes $memory_capacity_in_bytes"
echo "memory.usage_in_bytes $memory_usage_in_bytes"
echo "memory.total_inactive_file $memory_total_inactive_file"
echo "memory.working_set $memory_working_set"
echo "memory.available_in_bytes $memory_available_in_bytes"
echo "memory.available_in_kb $memory_available_in_kb"
echo "memory.available_in_mb $memory_available_in_mb"
CグループV2
https://kubernetes.io/examples/admin/resource/memory-available-cgroupv2.sh
#!/bin/bash
# This script reproduces what the kubelet does
# to calculate memory.available relative to kubepods cgroup.
# current memory usage
memory_capacity_in_kb=$(cat /proc/meminfo | grep MemTotal | awk '{print $2}')
memory_capacity_in_bytes=$((memory_capacity_in_kb * 1024))
memory_usage_in_bytes=$(cat /sys/fs/cgroup/kubepods.slice/memory.current)
memory_total_inactive_file=$(cat /sys/fs/cgroup/kubepods.slice/memory.stat | grep inactive_file | awk '{print $2}')
memory_working_set=${memory_usage_in_bytes}
if [ "$memory_working_set" -lt "$memory_total_inactive_file" ];
then
memory_working_set=0
else
memory_working_set=$((memory_usage_in_bytes - memory_total_inactive_file))
fi
memory_available_in_bytes=$((memory_capacity_in_bytes - memory_working_set))
memory_available_in_kb=$((memory_available_in_bytes / 1024))
memory_available_in_mb=$((memory_available_in_kb / 1024))
echo "memory.capacity_in_bytes $memory_capacity_in_bytes"
echo "memory.usage_in_bytes $memory_usage_in_bytes"
echo "memory.total_inactive_file $memory_total_inactive_file"
echo "memory.working_set $memory_working_set"
echo "memory.available_in_bytes $memory_available_in_bytes"
echo "memory.available_in_kb $memory_available_in_kb"
echo "memory.available_in_mb $memory_available_in_mb"
コードを見せてください
ご覧のとおり、ノードの WorkingSet の作業メモリは、ルート cgroup のメモリ使用量から Inactve(file) 部分のキャッシュを差し引いたものです。同様に、Pod 内のコンテナの WorkingSet 作業メモリは、コンテナに対応する cgroup メモリ使用量から Inactve(file) 部分のキャッシュを差し引いたものです。
実際の Kubernetes ランタイムの kubelet では、cadvisor によって提供されるインジケーター ロジックのこの部分の実際のコードは次のとおりです。
cadvisor コード[ 1]から、 WorkingSet ワーキング メモリの定義が明確にわかります。
The amount of working set memory, this includes recently accessed memory,dirty memory, and kernel memory. Working set is <= "usage".
そして、cadvisor による WorkingSet の計算の具体的なコード実装[ 2] :
inactiveFileKeyName := "total_inactive_file"
if cgroups.IsCgroup2UnifiedMode() {
inactiveFileKeyName = "inactive_file"
}
workingSet := ret.Memory.Usage
if v, ok := s.MemoryStats.Stats[inactiveFileKeyName]; ok {
if workingSet < v {
workingSet = 0
} else {
workingSet -= v
}
}
コンテナーのメモリ問題に関する一般的なユーザーの問題のケース
ACK チームがコンテナ シナリオのサービス サポートを多数のユーザーに提供する過程で、多くの顧客はビジネス アプリケーションをコンテナにデプロイする際に、多かれ少なかれコンテナ メモリの問題に遭遇しました。数多くの顧客の問題を経験した後、ACK チームと Alibaba Cloud オペレーティング システム チームは、コンテナ メモリに関してユーザーが直面する一般的な問題を次のようにまとめました。
FAQ 1: ホストのメモリ使用量とノードごとのコンテナの合計使用量の間には、ホストが約 40%、コンテナが約 90% あります。
おそらく、コンテナの Pod が PageCache などのキャッシュを含む WorkingSet と見なされていることが原因です。
ホストのメモリ値にはキャッシュ、ページキャッシュ、ダーティ メモリなどは含まれませんが、作業メモリにはこの部分が含まれます。
最も一般的なシナリオは、JAVA アプリケーションのコンテナ化、JAVA アプリケーションの Log4J、およびその非常に人気のある実装である Logback です。デフォルトの Appender は、非常に「単純に」NIO を使用し、mmap を使用して Dirty Memory を使用します。これにより、メモリ キャッシュが増加し、それによって Pod の作業メモリ WorkingSet が増加します。
JAVA アプリケーション ポッドの Logback ロギング シナリオ
キャッシュ メモリとワーキングセット メモリの増加を引き起こすインスタンス
FAQ 2: Podでtopコマンドを実行すると、kubectl top podで見るワーキングメモリの値(WorkingSet)よりも取得される値が小さくなります。
Pod で top コマンドを実行します。コンテナのランタイム分離などの問題により、実際にはコンテナの分離が壊れ、ホストの上位監視値が取得されます。
したがって、表示されるのは Cache、PageCache、Dirty Memory などを含まないホスト マシンのメモリ値ですが、ワーキング メモリにはこの部分が含まれるため、FAQ 1 と同様になります。
FAQ 3: ポッド メモリのブラック ホールの問題
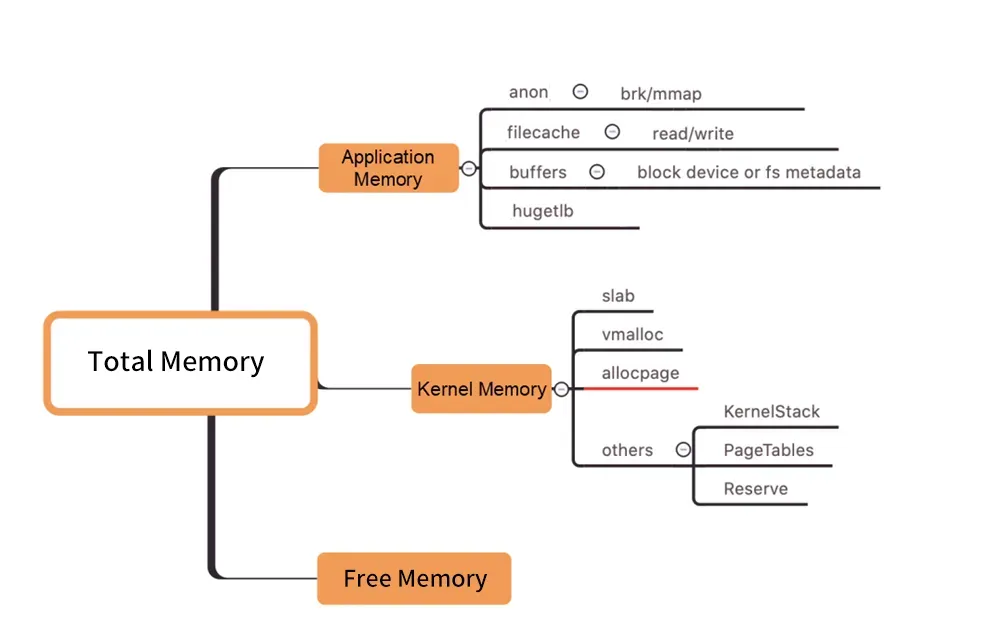
図/カーネルレベルのメモリ配分
上の図に示されているように、Pod WorkingSet のワーキング メモリには Inactive (anno) が含まれておらず、ユーザーが使用する Pod メモリの他のコンポーネントが期待を満たしていないため、最終的に WorkingSet のワークロードが増加し、最終的にはノードが停止する可能性があります。立ち退き。
多くの記憶要素の中から作業記憶が増加する本当の原因を見つける方法は、ブラックホールと同じくらい盲目です。 (「メモリ ブラック ホール」はこの問題を指します)。
WorkingSet の高さの問題を解決する方法
通常、メモリのリサイクルの遅延には、ワーキング セットのメモリ使用量の増加が伴います。では、この種の問題を解決するにはどうすればよいでしょうか。
直接拡張
キャパシティ プランニング (直接拡張) は、高リソースの問題に対する一般的な解決策です。
「メモリ ブラック ホール」 - 大量のメモリ コスト (PageCache など) が原因である場合の対処方法
ただし、メモリの問題を診断したい場合は、まず解剖し、洞察を得て、分析する必要があります。人間の言葉で言えば、メモリのどの部分が誰 (どのプロセス、またはファイルなどの特定のリソース) によって保持されているかを明確に確認する必要があります。次に、ターゲットを絞った収束最適化を実行して、最終的に問題を解決します。
ステップ 1: メモリを確認する
まず、オペレーティング システムのカーネル レベルのコンテナ監視メモリ インジケーターを分析するにはどうすればよいでしょうか? ACK チームはオペレーティング システム チームと協力して、 オペレーティング システムのカーネル層でコンテナを監視するSysOM (System Observer Monitoring)製品機能を開始しました。これは現在、 SysOM コンテナのポッド メモリ モニターを表示することで Alibaba Cloud に固有です。 System Monitoring-Pod ディメンションでは、以下に示すように、Pod のメモリ使用量の詳細な分布を把握できます。
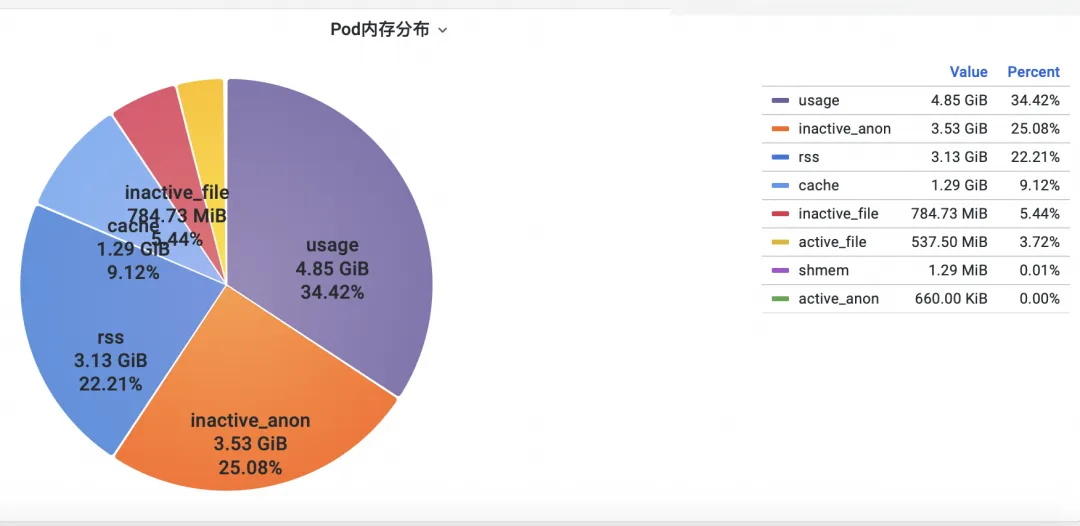
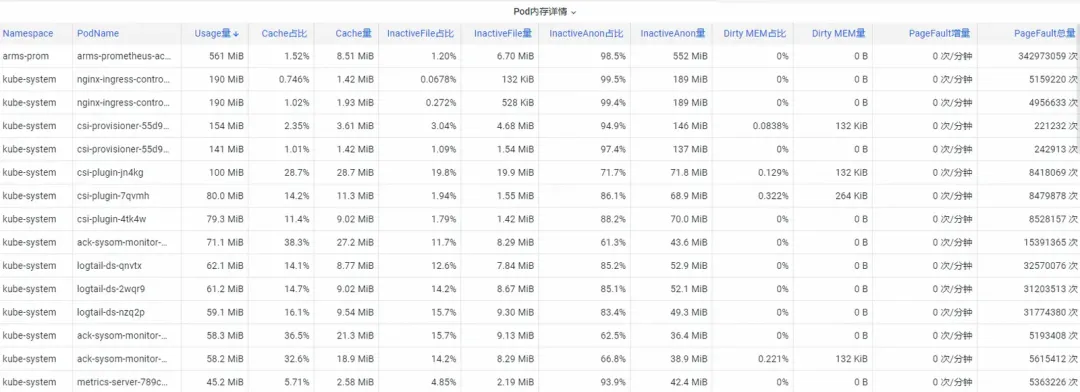
SysOM コンテナ システムの監視では、各ポッドの詳細なメモリ構成を詳細なレベルで表示できます。 Pod Cache (キャッシュ メモリ)、InactiveFile (非アクティブなファイル メモリの使用量)、InactiveAnon (非アクティブな匿名メモリの使用量)、Dirty Memory (システムのダーティ メモリの使用量) などのさまざまなメモリ コンポーネントの監視と表示を通じて、一般的な Pod メモリのブラック ホールの問題が発生します。発見した。
ポッド ファイル キャッシュの場合、ポッドで現在開いているファイルと閉じているファイルの PageCache 使用状況を同時に監視できます (対応するファイルを削除すると、対応するキャッシュ メモリが解放されます)。
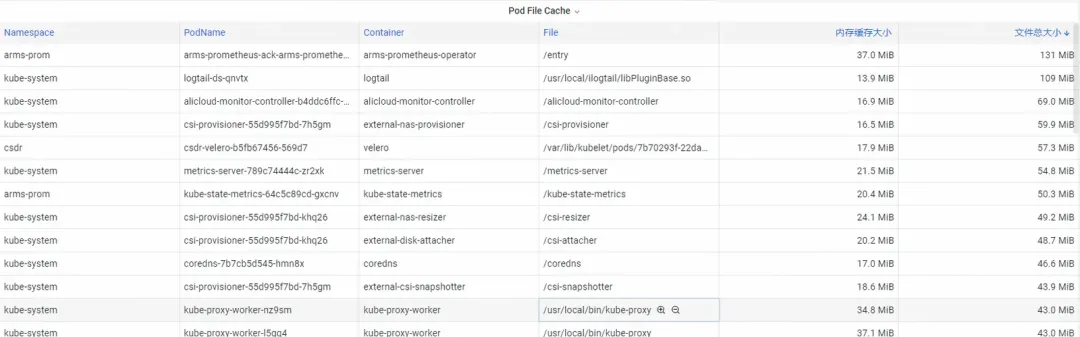
ステップ 2: メモリを最適化する
ユーザーが明確に認識していても、簡単には収束できない根深いメモリ消費が多数あります。たとえば、オペレーティング システムによって均一に再利用される PageCache やその他のメモリでは、ユーザーはフラッシュ( の追加など) をコードに強制的に変更する必要があります。 ) を Log4J の Appender に追加して、定期的に sync() を呼び出します。
https://stackoverflow.com/questions/11829922/logback-file-appender-doesnt-flush-immediately
これは非常に非現実的です。
ACK コンテナ サービス チームは、Koordinator QoS のきめ細かいスケジューリング機能を開始しました。
オペレーティング システムのメモリ パラメーターを制御するために Kubernetes に実装されています。
クラスター内で差別化された SLO コロケーションが有効になっている場合、システムはレイテンシーに敏感な LS (Latency-Sensitive) ポッドのメモリー QoS を優先し、マシン全体でメモリーのリサイクルをトリガーする LS ポッドのタイミングを遅らせます。
以下の図では、memory.limit_in_bytes はメモリ使用量の上限を表し、memory.high はメモリ電流制限しきい値を表し、memory.wmark_high はメモリ バックグラウンド リサイクルしきい値を表し、memory.min はメモリ使用量のロックしきい値を表します。
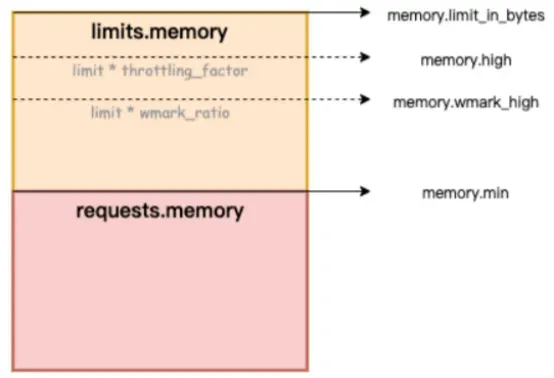
Figure/ack-koordinator はコンテナにメモリ QoS (Quality of Service) 保証機能を提供します
メモリ ブラック ホールの問題を解決するにはどうすればよいですか? Alibaba Cloud Container Service は、洗練されたスケジューリング機能を使用し、コンテナのメモリ サービス品質 QoS (Quality of Service) 保証機能を提供する Koordinator に依存しています。アプリケーションの実行時のメモリ パフォーマンスの公平性を確保することを前提としています。この記事では、コンテナ メモリ QoS 機能について説明します。詳細な手順については、コンテナ メモリ QoS [ 3]を参照してください。
コンテナにはメモリを使用する際に主に次の 2 つの制約があります。
1) 独自のメモリ制限: コンテナ自体のメモリ (PageCache を含む) がコンテナの上限に近づくと、コンテナ次元のメモリのリサイクルがトリガーされ、コンテナ内のアプリケーションのメモリ アプリケーションとリリースのパフォーマンスに影響します。メモリ要求を満たすことができない場合、コンテナ OOM がトリガーされます。
2) ノード メモリ制限: コンテナ メモリが過剰に販売され (メモリ制限 > リクエスト)、マシン全体のメモリが不足すると、ノード ディメンションでのグローバル メモリ リサイクルがトリガーされ、極端な場合にはパフォーマンスに大きな影響を与えます。 、さらにはマシン全体に異常を引き起こす可能性があります。リサイクルが不十分な場合、コンテナは OOM Kill の対象として選択されます。
上記の典型的なコンテナ メモリの問題に対処するために、ack-koordinator は次の拡張機能を提供します。
1) コンテナー メモリのバックグラウンド リサイクルの水位: ポッドのメモリ使用量が Limit 制限に近づくと、メモリの一部がバックグラウンドで非同期的にリサイクルされ、直接メモリのリサイクルによって引き起こされるパフォーマンスへの影響が軽減されます。
2) コンテナのメモリロックのリサイクル/水位の制限: Pod 間でより公平なメモリのリサイクルを実装します。マシン全体のメモリリソースが不足している場合、メモリの過剰使用 (メモリ使用量 > 要求) のある Pod からのメモリのリサイクルが優先され、個別のメモリの使用が回避されます。ポッドが原因でマシンのメモリ リソース全体の品質が低下しました。
3) 全体的なメモリ リサイクルの差別化された保証: BestEffort メモリの過剰販売シナリオでは、保証/バースタブル ポッドのメモリ実行品質を確保することが優先されます。
ACK コンテナメモリ QoS によって有効になるカーネル機能の詳細については、「Alibaba Cloud Linux のカーネル機能とインターフェイスの概要[ 4]」を参照してください。
コンテナ メモリのブラック ホールの問題が観察の最初のステップで発見された後、ACK ファイン スケジューリング機能をメモリに敏感な Pod のターゲット選択と組み合わせて、コンテナ メモリの QoS 機能が閉ループ修復を完了できるようにします。
参考ドキュメント:
[1] ACK SysOM機能説明書
[2] ベストプラクティスに関するドキュメント
[3] 中国のドラゴントカゲコミュニティ
https://mp.weixin.qq.com/s/b5QNHmD_U0DcmUGwVm8Apw
【4】国際線駅英語
https://www.alibabacloud.com/blog/sysom-container-monitoring-from-the-kernels-perspective_600792
関連リンク:
[1] アドバイザーコード
[2] cadvisorによるWorkingSet計算の具体的なコード実装
[3] コンテナメモリのQoS
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dicate/user-guide/memory-qos-for-containers
[4] Alibaba Cloud Linuxのカーネル機能とインターフェースの概要
https://help.aliyun.com/zh/ecs/user-guide/overview-23
マイクロソフトの中国AIチームは数百人を巻き込んで米国に渡ったが、 未知のオープンソースプロジェクトはどれだけの収益をもたらすことができるだろうか? 華中科技大学のオープンソースミラーステーション の立場が調整されたとファーウェイが正式に発表した。 外部ネットワークへのアクセスを正式にオープンしました。 詐欺師は TeamViewer を使用して 398 万件を転送しました。リモート デスクトップ ベンダーは何をすべきでしょうか? 初のフロントエンド視覚化ライブラリであり、Baidu の有名なオープンソース プロジェクト ECharts の創設者である - 有名なオープンソース企業の元従業員が「海に行った」というニュースを伝えた: 部下からの挑戦を受けて、技術者はリーダーは激怒し、無礼になり、妊娠中の女性従業員を解雇しました。OpenAI が AI にポルノ コンテンツを生成させることを検討したと 、Rust Foundation に報告されました。time.sleep (6) の役割を教えてください。 ?