
記事の推奨事項
GPT-4o がリリースされ、すぐにユーザーがレビューしました。OpenAI には誇張はありますか?
アリも一緒に楽しんでいます! Ant の「510 親戚と友人の日」AI の希望に満ちた旅
OpenAIライブブロードキャストカウントダウン、GPT-5不在が確認、GPT-3.5から5へ、AI進化の大きな違いが1つの記事でわかる!
この記事は、昨年 QCon に参加した後の Ant の Wu Jun の要約から来ており、AI エージェントに焦点を当て、AI エージェントの現在のアプリケーションと課題に焦点を当てます。原文は以下の通りです。
**著者について:** Ant Group のエアダクト技術部門の AI エンジニアリング チームの TL である Wu Jun (Yide) は、現在エアダクトの大規模モデル アプリケーション エンジニアリングを担当しており、大規模なエアダクトのいくつかのビジネスシナリオのモデル評価と大規模モデル推論、大規模モデルアプリケーションの最適化と実装。
この QCon の重要な主役は間違いなく大規模モデルです。2 日間の大規模モデルの 3 つの側面は、現在の大規模モデル アーキテクチャの古典的な階層化、つまりアプリケーション層、ツール層、モデル層、AI インフラストラクチャにも対応します。
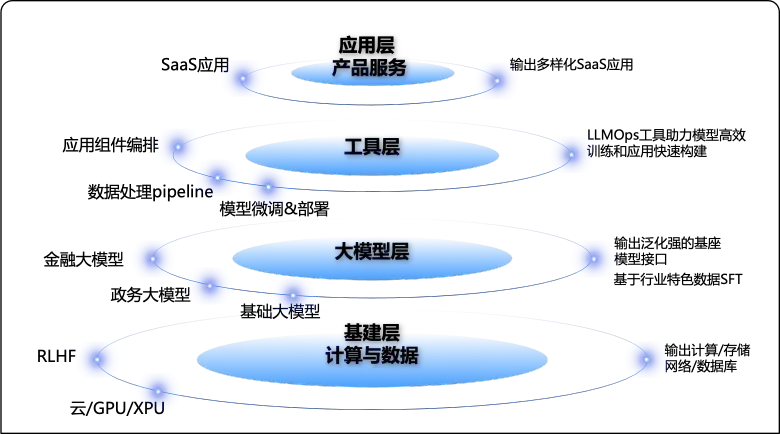
- **アプリケーション層 - 大規模モデルアプリケーション:** 主に RAG&AI Agent の第一世代モデルで明らかになった主な実装シナリオには、内部データ分析 - 生成 BI である GBI、研究開発補助効率向上 - 生成コード、および外部ユーザーが含まれます。 2. ナレッジベース Q&A - ChatPDF など。
- **ツール層 - アプリケーション構築機能: ** 独自のシナリオの大規模なモデル アプリケーションを効率的かつ迅速に構築する方法を主に紹介します (AI エージェントの構築に焦点を当てています)。次のようなアプリケーション構築ツール - LangChain、エージェント開発フレームワークがあります。 MetaGPT、Amazon Bedrock 用の ModelScop-Agent&Agents などの MaaS プラットフォーム。
- **モデルとインフラストラクチャ層 - 大規模モデルの最適化の高速化: **モデル推論の高速化におけるコアの探求は、将来、限られたコンピューティング能力の下で大規模なモデル アプリケーションを大規模に生産する際のパフォーマンスとセキュリティの要件を満たします。も競合 打開のキーポイントを探る。
AIエージェントとは何ですか?
AIエージェントの定義
AI エージェントは、人工知能エージェントの概念であり、環境を認識し、意思決定を行い、行動を実行することができ、通常は機械学習と人工知能技術に基づいており、自律的に学習し改善する能力を備えています。タスクまたはドメイン内。より完全なエージェントは、環境と完全に対話する必要があります。エージェントは 2 つの部分で構成され、もう 1 つは環境部分です。このときのエージェントは、物理世界における「人間」のようなものであり、物理世界は人間の「外部環境」である。
AIエージェントの主なコンポーネント
LLM を活用した自律エージェント システム (LLM エージェント) では、LLM がエージェントの頭脳として機能し、いくつかの主要コンポーネントと連携します。
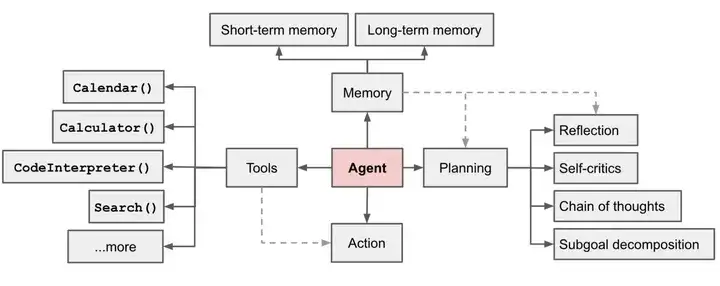
計画
- サブ目標の分解: エージェントは、複雑なタスクを効率的に処理できるように、大きなタスクを管理しやすい小さなサブ目標に分割します。
- 反省と改善: エージェントは過去のアクションを自己批判および反省し、間違いから学び、その後のステップで改善することで、最終結果の品質を向上させることができます。
メモリ
- 短期記憶: 文脈学習は、モデルを使用した短期記憶学習です。
- 長期記憶: エージェントに長期情報を保持および呼び出す機能を提供します。通常、外部ベクトル ストレージと取得を使用して実装されます。
ツールの使用
- モデルの重み付けで失われた情報については、エージェントは外部 API を呼び出して、現在の情報、コード実行機能、独自の情報ソースへのアクセスなどの追加情報を取得する方法を学習します。
アクション
- アクション モジュールは、実際に決定または応答を実行するエージェントの一部です。さまざまなタスクに直面するエージェント システムは、一連の完全なアクション戦略を備えており、よく知られている記憶の検索、推論、学習、プログラミングなど、意思決定を行うときに実行するアクションを選択できます。
人機連携モード
大規模なモデルに基づくエージェントにより、誰もが強化された機能を備えた専用のインテリジェント アシスタントを持つことができるようになるだけでなく、人間と機械のコラボレーションのモデルが変化し、より広範な人間と機械の統合がもたらされます。生成 AI のインテリジェント革命はこれまでに進化し、人間とマシンのコラボレーションの 3 つのモードが登場しました。
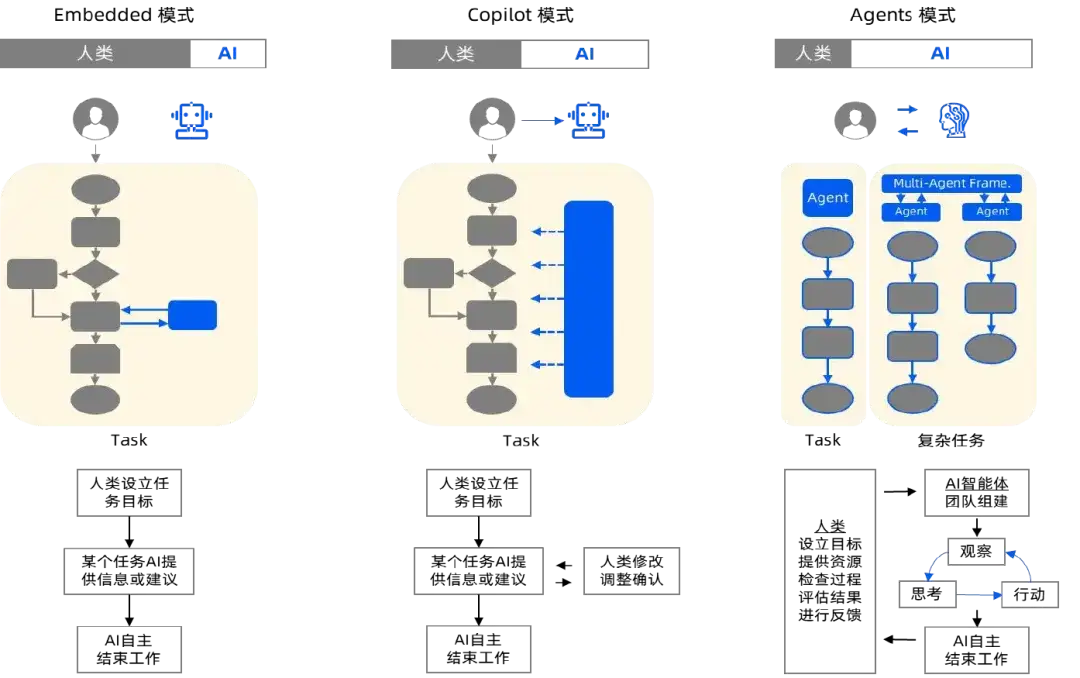
埋め込みモード:
ユーザーは言語コミュニケーションを通じて AI と協力し、即発的な言葉を使って目標を設定し、ユーザーは生成 AI を使用して小説、音楽作品、3D コンテンツなどを作成します。このモードでは、AI が命令を実行し、人間が意思決定者および指揮官となります。
副操縦士モード:
人間と AI はパートナーであり、一緒にワークフローに参加します。 AI は、プログラマー向けのコードの作成、エラーの検出、ソフトウェア開発のパフォーマンスの最適化などのタスクを提案し、支援します。 AI は単なるツールではなく、知識豊富なパートナーです。
エージェントモード:
人間が目標を設定してリソースを提供し、AI がほとんどの作業を独立して実行し、人間がプロセスを監督して結果を評価します。 AI は自律性と適応性を体現し、独立した主体に近づき、人間は監督者と評価者の役割を果たします。エージェント モードは組み込みモードや副操縦士モードより効率的であり、将来的には人間と機械のコラボレーションの主要なモードになる可能性があります。
インテリジェント エージェントの人間とマシンのコラボレーション モードでは、すべての普通の個人が、独自の AI チームと自動化されたタスク ワークフローを備えた超個人になる可能性があります。彼らは、他の超個人とよりインテリジェントで自動化された協力関係を確立できます。業界にはすでに、このモデルを積極的に検討している個人企業や超個人企業がいくつかあります。
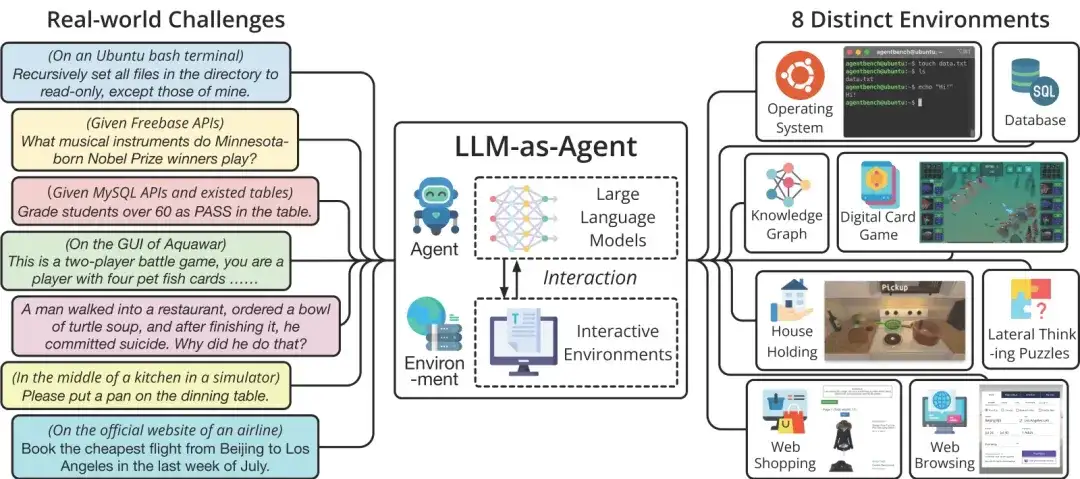
AIエージェントアプリケーション
現在、AI エージェントは、大規模言語モデルを実装する効果的な方法の 1 つとして認識されており、これにより、より多くの人が大規模言語モデルの起業の方向性、および LLM、エージェント、および既存の統合と応用の見通しを明確に理解できるようになります。産業技術。現在、大規模な言語モデル エージェントは、コード生成、データ分析、一般的な質問応答、科学研究などの多くの分野でオープンソースまたはクローズドソースのプロジェクトを多数抱えており、その人気の高さを示しています。

業界関連のAIエージェントの例

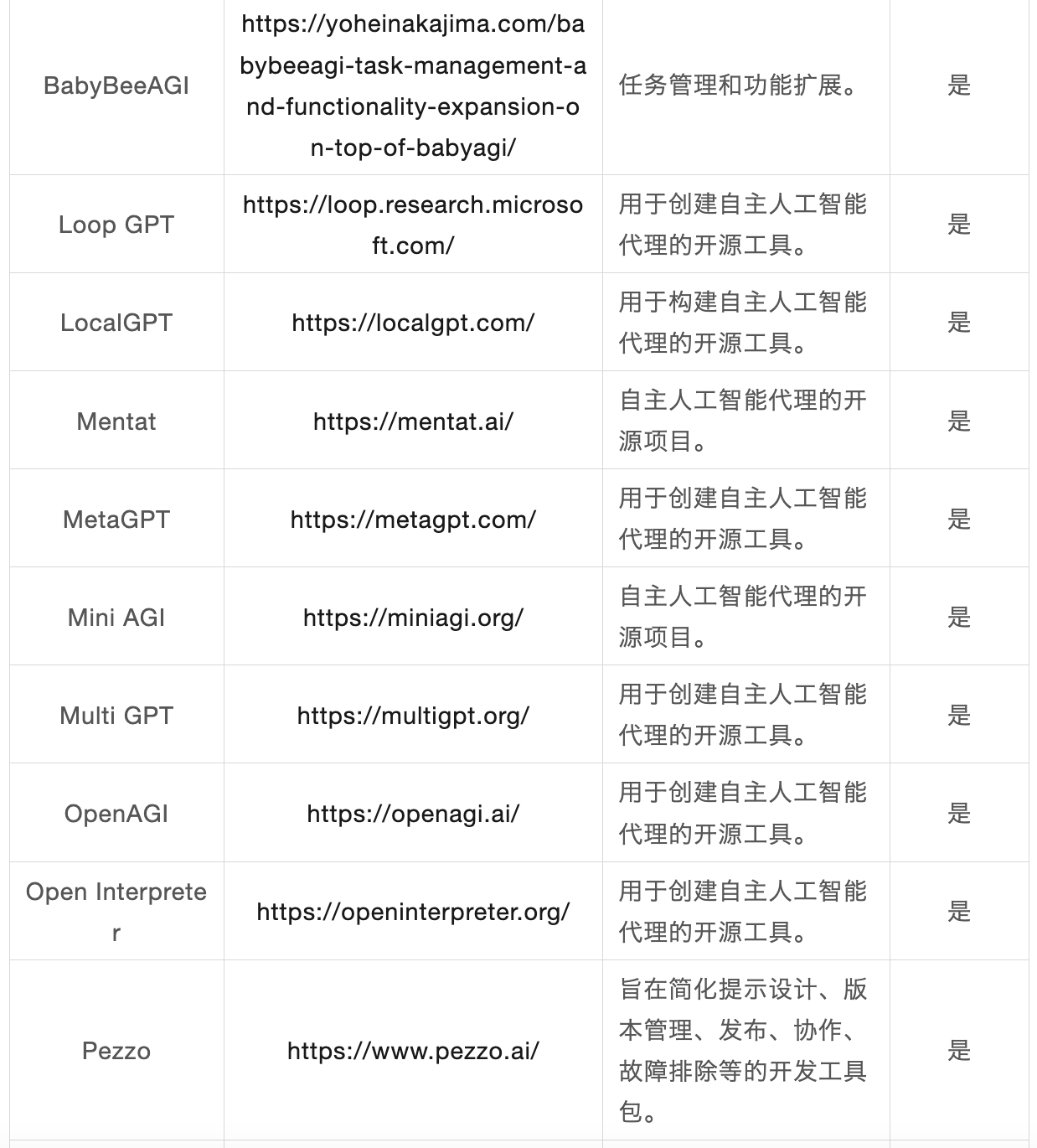
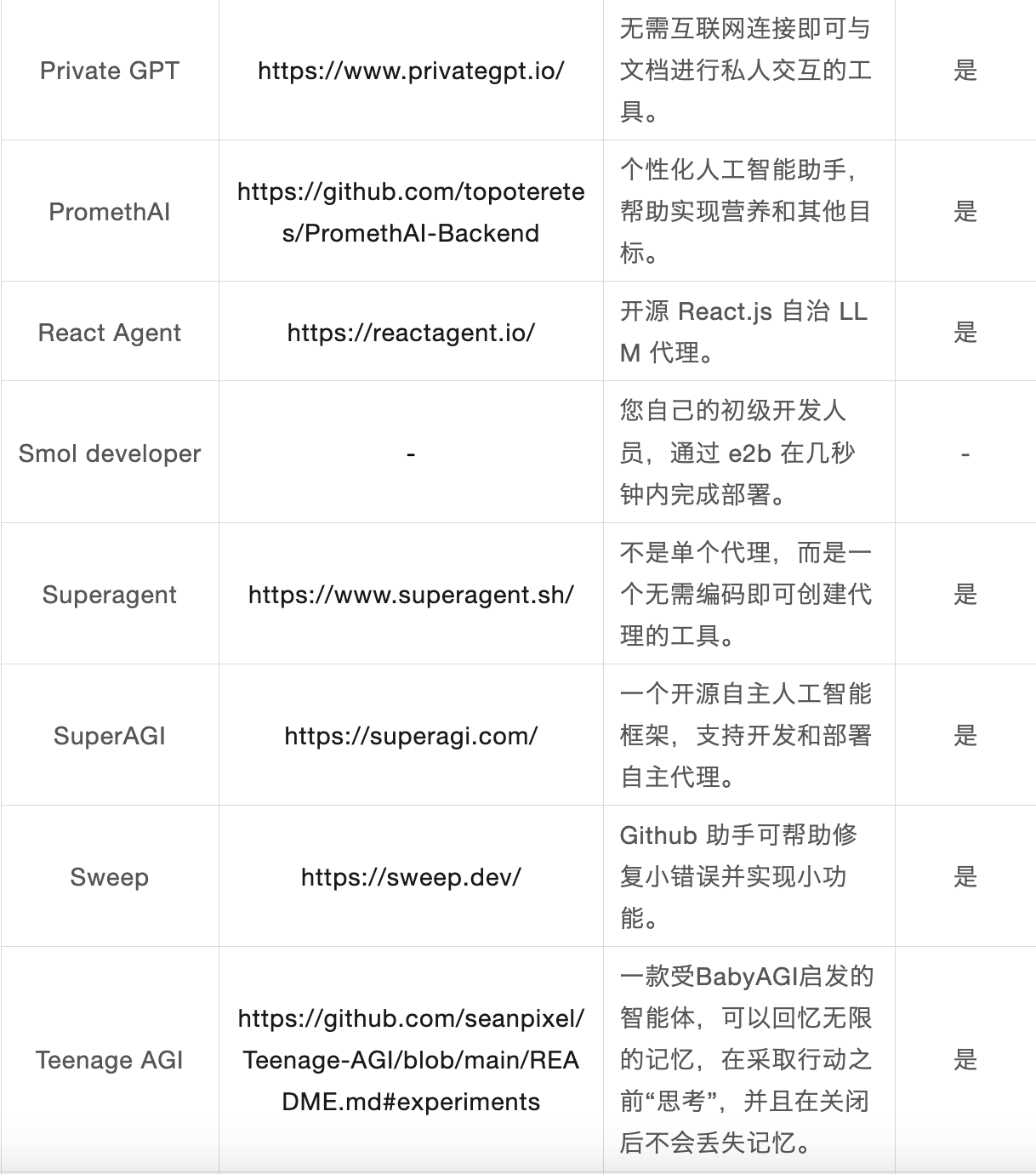
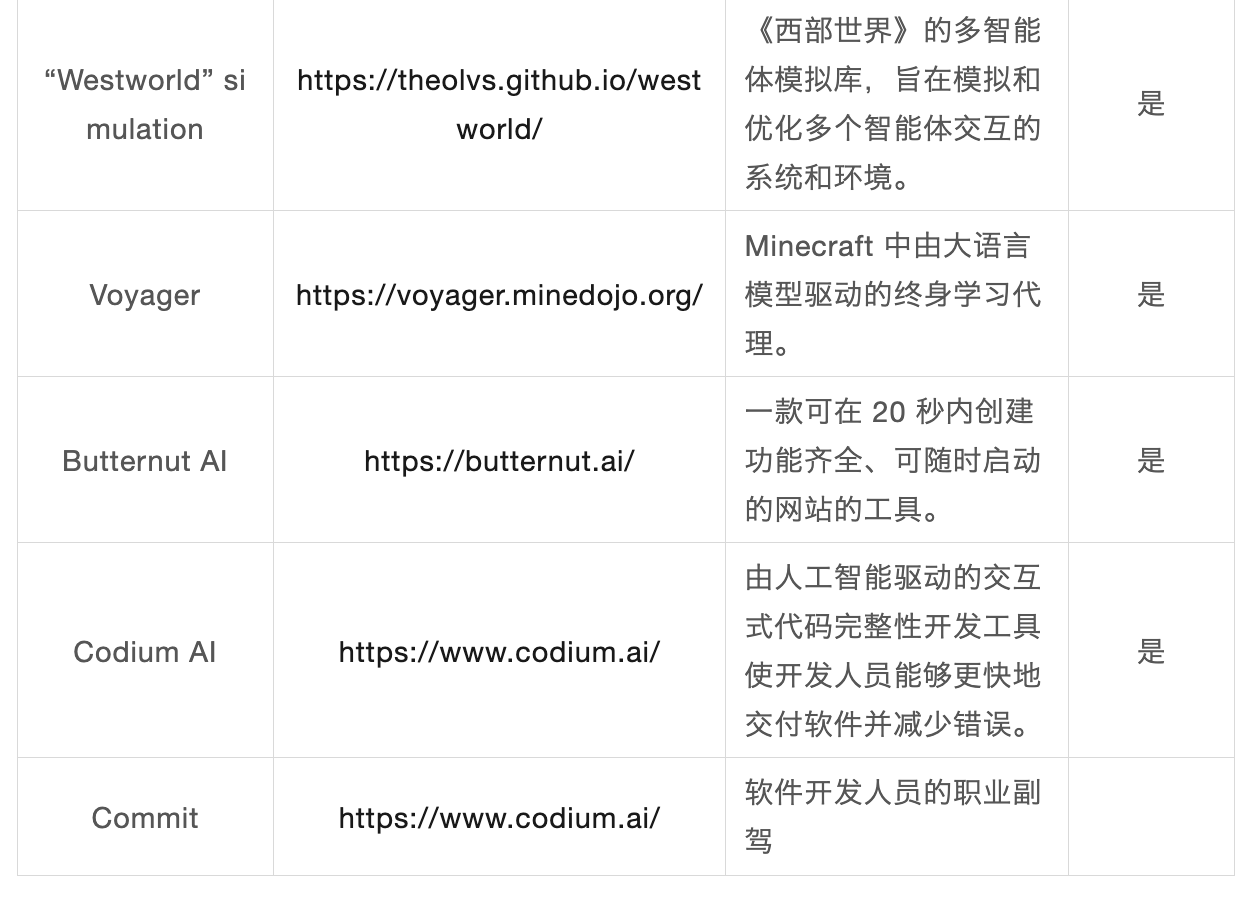
AIエージェントアプリケーション
この記事では、ABI/GBI 生成 BI またはデータ分析、RAG テクノロジに基づく知識の質問と回答の 3 種類のアプリケーションまたはシナリオに焦点を当てます。
01. BI (データ分析) エージェント - 生成型 BI
LLM の金融インテリジェンス アプリケーションの研究開発における実践的な経験と探索
ジェネレーティブ BI (データ エージェント) に関しては、その日の特別講演で Tencent Cloud のテクニカル ディレクターが共有したトピックを聞きました。彼は txt2SQL インテリジェントな質問と回答システムの設計について共有し、全体的な精度を確認できました。驚異的な 99% に達します (純粋な大規模モデルの生成と、複雑さの低い SQL の精度は約 80% 以上です)。しかし本質的に、彼らのソリューションは主にエンジニアリング機能に依存しており、大規模モデルの NL2SQL 生成機能を完全には使用せず、代わりに、RAG を組み合わせてクエリを使用して、一般的なクエリの問題と RAG 内の対応する SQL 例を照合し、取得したデータに基づいています。 SQL はデータ ソースに接続されています。
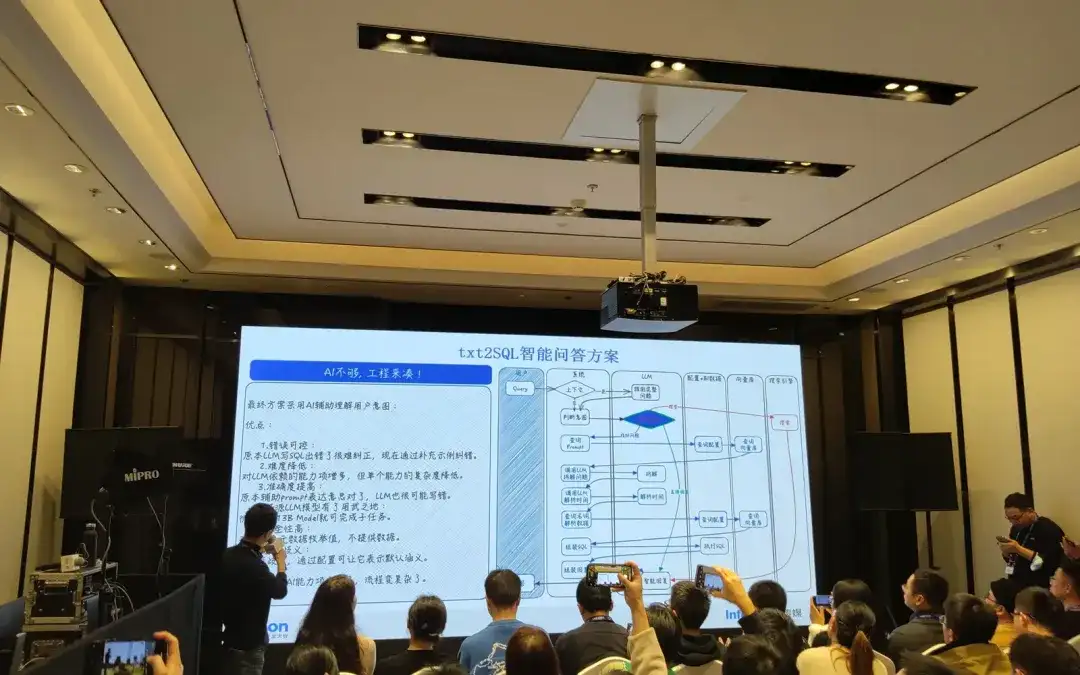
大規模デジタルモデルであるSwiftAgentのビジネス分析分野への応用
Shushi Technology/Financial Digital Products General Manager が共有する同様の DataAgent 製品である swiftAgent は、インタラクティブな指標照会、インテリジェントなインサイト属性を含む、言語 (LUI) モードに基づく大規模なモデルを通じて、従来の BI マニュアルのフルプロセス製品 (GUI) を再構築します。 、分析レポートの自動生成、インジケーターの完全なライフサイクル管理、およびその他の機能。
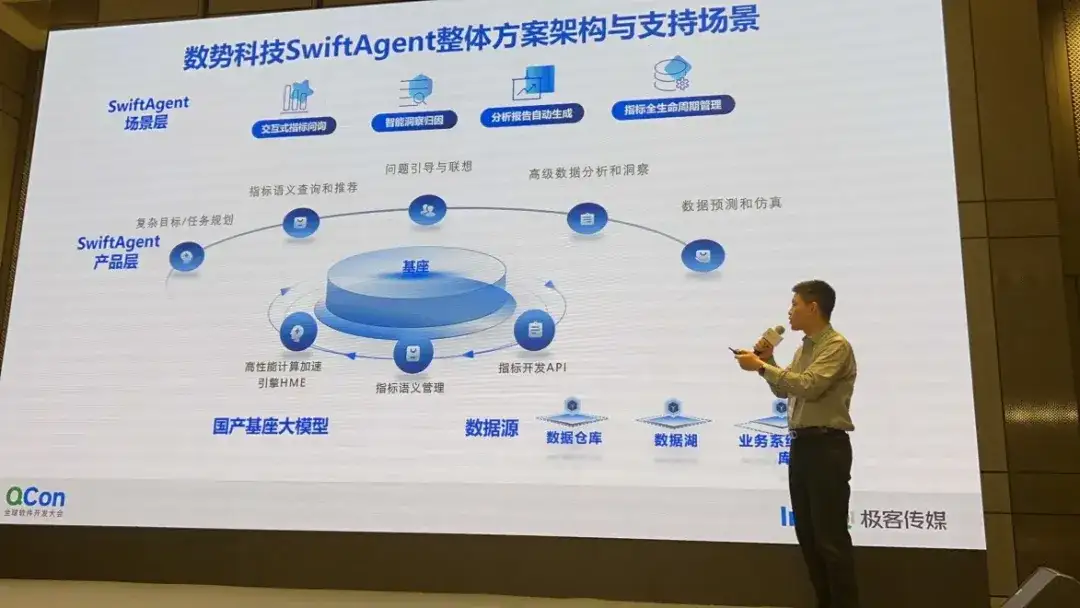
AIGC とデータ分析の統合により、新しいデータ消費モデルが作成されます。
NetEase Shufan のビッグ データ ソリューションの専門家が、Data Agent に関する NetEase の取り組みを共有しました。大規模なモデルでのエラーに直面して、彼らは信頼性の方向に焦点を当て、NL2SQL によってクエリされたデータが信頼できるものであることを保証するために製品の相互作用に関して多くの作業を行いました。
- 需要は当然です。自社開発の NL2SQL 専用大規模モデルにより、同年/チェーン/グループ/グループのソート機能などの関連データ関連機能が強化されています。
- プロセスは検証可能です。対話型インターフェイス上で自然言語でクエリの説明を生成することで、ユーザーはモデル生成プロセスの正誤を簡単に識別して、生成プロセスの信頼性を確保できます。
- ユーザーが介入できる: クエリの説明に基づいて、ユーザーはクエリ結果のクエリ条件を手動で調整し、決定的な手段で正しい結果を取得できます。
- 運用結果: リアルタイムのラベル付けと正しい結果と誤った結果のフィードバックを通じて、大規模モデル生成の正確性を継続的に最適化します。
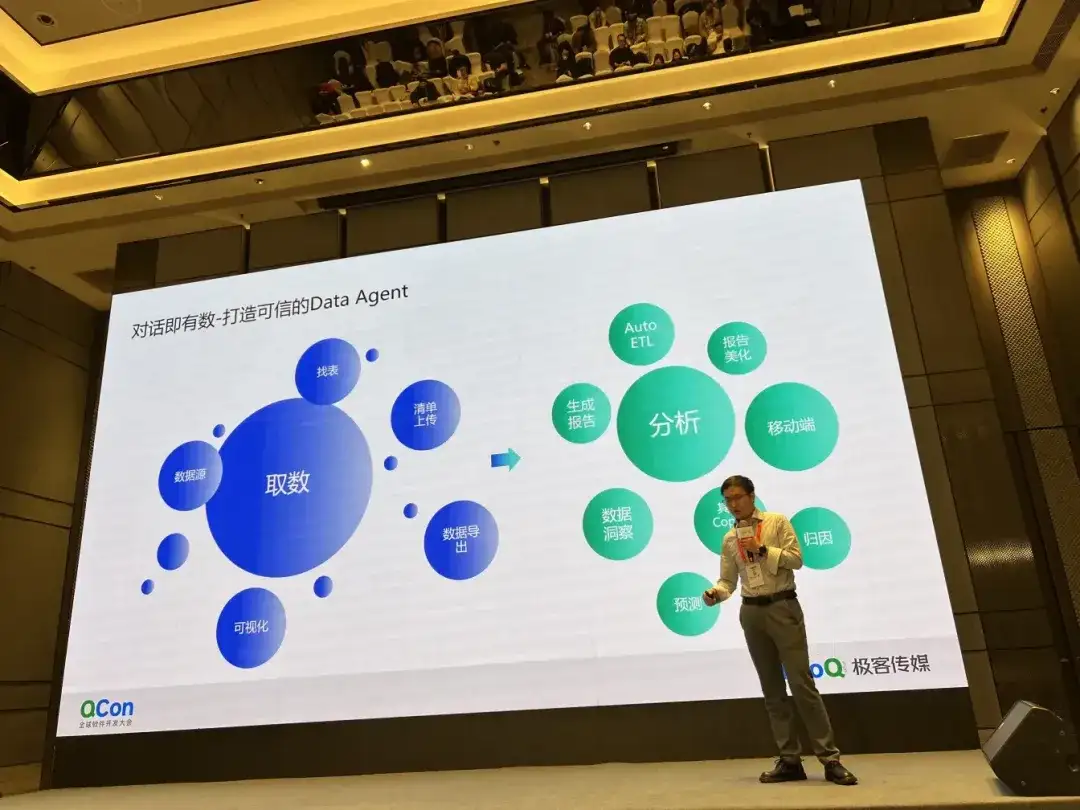
さらに、いくつかの企業が NL2SQL 関連のシナリオを試していますが、ここでは 1 つずつ列挙しません。
02.コーディングエージェント
私は初期段階で Github Copilot、codeGeex、CodeFuse などについて深い経験を積んできたので、中核となる役割は、コード生成、コード最適化、コード検出、その他の研究開発支援でプログラマーを支援し、効率を向上させることです。このシナリオでは、コードのセキュリティの問題に重点が置かれています。ここでは詳細については説明しません。関連する共有リンクと PPT ダウンロード リンクは次のとおりです。
- 企業における aiXcoder コード モデルの適用実践:
https://qcon.infoq.cn/2023/shanghai/presentation/5683
- CodeFuse に基づく次世代の研究開発の探索:
https://qcon.infoq.cn/2023/shanghai/presentation/5681
- 大規模なモデルをコード アシスタント シナリオに実装する調査と実践:
https://qcon.infoq.cn/2023/shanghai/presentation/5690
- Baidu の大規模モデル主導のインテリジェント コード アシスタントの効率向上の実践:
https://qcon.infoq.cn/2023/shanghai/presentation/5679
03. RAGベースの知識質疑応答
スペースの制約のため、RAG 関連の大規模モデル アプリケーションについては、別の記事で詳しく説明し、分解します。
チャレンジ
技術的な観点から見ると、AI エージェントの開発はまだ遅く、ほとんどのアプリケーションはまだ POC または理論的な実験段階にあります。現時点では、複雑なドメイン シナリオで完全に自律できる大規模な AI エージェント アプリケーションを見ることはほとんどありません。その主な理由は、AI エージェントの頭脳として機能する LLM モデルがまだ十分に強力ではないことです。最も強力な GPT4 であっても、適用するといくつかの問題に直面します。
1. コンテキストの長さは制限されており、履歴情報、詳細な説明、API 呼び出しコンテキストおよび応答の包含が制限されます。
2. 長期的な計画とタスクの分解は依然として困難です。
3. 現在のエージェント システムは、外部コンポーネントとのインターフェイスとして自然言語に依存していますが、モデル出力の信頼性には疑問があります。
さらに、AI エージェントのコストは、特にマルチエージェント システムでは比較的高くなります。多くのシナリオでは、Copilot モードと比較して、AI エージェントを使用する効果が大幅に改善されないか、コストの増加をカバーできません。 AI エージェント テクノロジのほとんどはまだ研究段階にあります。最後に、AI エージェントは、セキュリティとプライバシー、倫理と責任、経済的および社会的雇用への影響など、多くの課題に直面する可能性があります。
「信頼できるAIの進歩」公式アカウントは、大規模なグラフ学習、因果推論、ナレッジグラフ、大規模モデル、その他の技術分野をカバーする、最新の信頼できる人工知能技術の普及とオープンソース技術の育成に専念しています。 QRコードをスキャンしてフォローし、より多くのAI情報をロック解除してください~
