

ゲストを共有する:
ヤン・リンサン-ホイシー・インテリジェンス
Huixi Intelligence について:
Huixi Intelligence は 2022 年に設立された自動運転チップを製造する新興企業です。革新的な車載インテリジェント コンピューティング プラットフォームの構築に注力し、ハイエンドのインテリジェント運転チップ、使いやすいオープン ツール チェーン、フルスタックの自動運転ソリューションを提供し、自動車会社が高品質で効率的な自動運転の量産を実現できるように支援します。および配送を実現し、低コストで大規模な自動化された反復機能を構築し、データ主導時代のハイエンドのスマート旅行をリードします。
概要を共有します。
- スタートアップで Alluxio を使用するにはどうすればよいですか?
- Alluxio を 0 から 1 まで使用するプロセス (調査、導入、本番環境へ)。
- 実践的な経験の共有。
以下は共有されたコンテンツの全文版です
トピックを共有:
「自動運転モデル訓練におけるAlluxioの応用と展開」
自動運転データクローズドループ
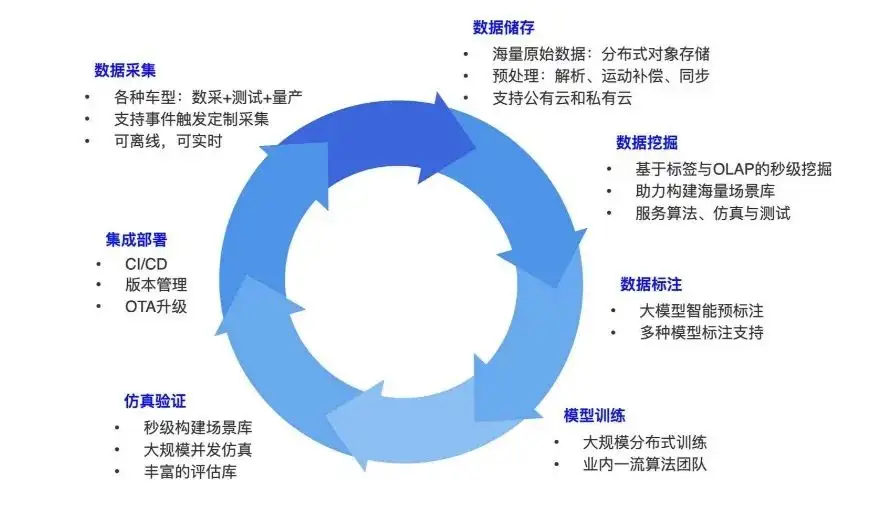
まず、自動運転におけるデータ閉ループを構築する方法について説明します。このビジネス プロセスは誰もが知っているかもしれません。自動運転には、データマイニング車両やアルゴリズムを搭載して道路を走行する車両など、さまざまなタイプの車両が含まれます。データ収集とは、自動運転車が走行する過程でさまざまなデータを収集することです。たとえば、カメラデータは写真、LIDAR データは点群です。
センサー データが収集されると、自動車は毎日数テラバイトのデータを生成することがあります。この種のデータは、ベース ディスクまたはその他のアップロード方法を通じて全体として保存され、オブジェクト ストレージに転送されます。元のデータが保存された後、データ分析と前処理のためのパイプラインが存在します。たとえば、データを一度に 1 フレームずつデータ フレームに分割し、各フレーム内の異なるセンサー データ間で同期および位置合わせ操作を実行できます。
データ分析が完了したら、さらに詳しく調べます。データセットを 1 つずつ構築します。アルゴリズム、シミュレーション、テストのいずれの場合でも、データセットを構築する必要があるためです。たとえば、雨の日の特定の夜、特定の交差点、または人口密集地域のデータが必要な場合、システム全体でそのようなデータ要件が大量に存在するため、ラベルを付ける必要があります。データを作成し、いくつかのラベルを追加します。たとえば、清華大学の東門では、この場所の経度と緯度を取得し、周囲の POI を分析する必要があります。次に、マイニングされたデータにラベルを付けます。一般的な注釈には、物体、歩行者、物体の種類などが含まれます。
このラベル付きデータはトレーニングに使用されます。一般的なタスクには、ターゲット検出、車線境界線検出、またはより大規模なエンドツーエンド モデルが含まれます。モデルがトレーニングされた後、いくつかのシミュレーション検証を行う必要があります。検証後、車に展開してデータを実行し、これに基づいてさらにデータを収集します。このようなサイクルで、データを継続的に強化し、パフォーマンスが向上したモデルを継続的に構築します。これはトレーニングとデータの閉ループ全体で行う必要があることであり、現在の自動運転の研究開発の中核でもあります。
アルゴリズムトレーニング: NAS
私たちはモデル トレーニングに重点を置いています。モデル トレーニングでは主にデータ マイニングを通じてデータを取得し、データ セットを生成します。データ セットは内部的にはデータ、チャネル、ストレージの場所を含む pkl ファイルです。最後に、データ アルゴリズムをトレーニングする学生は、オブジェクト ストレージからデータをローカルにプルするための独自のダウンロード スクリプトを作成します。
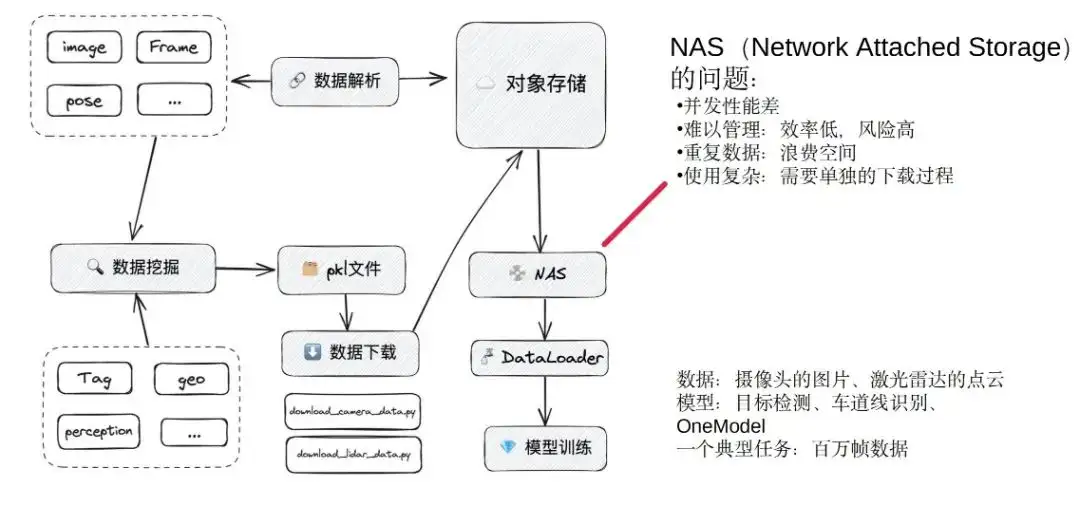
Alluxio を選択する前は、NAS システムをキャッシュとして機能させ、オブジェクト ストレージ データを NAS にプルし、最後にさまざまなモデルを使用してトレーニング用のデータをロードしていました。これは、Alluxio を使用する前のおおよそのトレーニング プロセスです。
NAS における最大の問題の 1 つは次のとおりです。
- 同時実行パフォーマンスは比較的劣っています。NAS は大きなハードディスクとして理解できますが、少数のタスクだけが一緒に実行されている場合には、これで十分です。ただし、数十のトレーニング タスクが同時に実行され、多くのモデルがトレーニングされている場合、スタックが頻繁に発生します。私たちが非常に行き詰まり、研究開発チームが毎日不満を言っていた時期がありました。非常に行き詰まっているため、可用性と同時実行パフォーマンスが非常に低くなります。
- 管理の難しさ- 全員がダウンロードした独自のスクリプトを使用し、必要なデータを独自のディレクトリにダウンロードします。別の人が自分で別のデータの山をダウンロードして NAS の別のディレクトリに置く可能性があります。これにより、NAS スペースがいっぱいになったときにクリーンアップすることが困難になります。当時は基本的に対面かWeChatグループでコミュニケーションを取っていました。一方で、効率は非常に低く、グループメッセージ管理に依存すると遅れてしまいます。一方、手動で削除すると、いくつかのリスクが生じる可能性もあります。データを削除するときに他の人のデータセットが削除されるという状況が発生しました。これにより、オンライン タスク領域でもエラーが発生し、これも問題点となります。
- スペースの無駄- さまざまなユーザーがダウンロードしたデータが別のディレクトリに配置されると、同じデータ フレームが複数のデータ セットに表示され、スペースが大幅に無駄になる可能性があります。
- 使用するのは非常に複雑です。pkl のファイル形式が異なり、ダウンロード ロジックも異なり、全員が個別にダウンロード プログラムを作成する必要があるためです。
これらは、以前 NAS を使用する際に直面した困難と問題の一部です。これらの問題を解決するために、私たちは研究を行いました。調査の結果、私たちは Alluxio に注目しました。 Alluxio は比較的統合されたキャッシュを提供し、トレーニング速度を向上させ、管理コストを削減できることがわかりました。また、コンピュータ室の二重化問題にも Alluxio システムを活用して対応していきます。統一された名前空間とアクセス方法により、システム設計が簡素化される一方で、コードの実装も非常にシンプルになります。
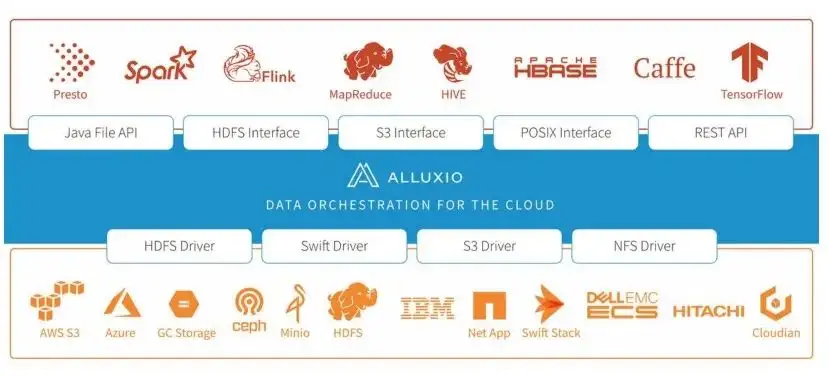
Alluxio に導入されたアルゴリズム トレーニング
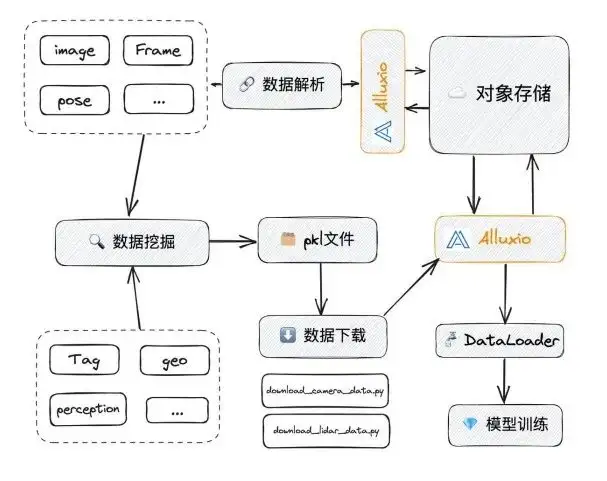
NAS を Alluxio に置き換えると、Alluxio は具体的に、今述べた問題のいくつかを解決できます。
- 同時実行性の観点: NAS 自体は完全に分散されたシステムではありませんが、Alluxio は完全に分散されたシステムです。 NASがアクセスするIOが一定の速度に達すると、数G/sに達するとフリーズし始めることがあります。 Alluxio の上限は非常に高いので、この点を説明するために以下の特別なテストを行います。
- 手動によるクリーニングや管理は非常に面倒です。Alluixoはキャッシュ削除ポリシーを構成します。通常は LRU を介して、しきい値 (90% など) に達すると、キャッシュが自動的に削除され、消去されます。これによる効果:
- 効率が大幅に向上します。
- 誤って削除することによって引き起こされるセキュリティ上の問題を回避できます。
- データが重複する問題を解決しました。
Alluxio では、UFS 上のファイルは Alluxio 内のパスに対応しており、誰もがこのパスにアクセスすると、対応するデータを取得できるため、データの重複の問題は発生しません。さらに、上記の使用方法は比較的簡単で、FUSE インターフェイスを介してアクセスするだけでよく、ファイルをダウンロードする必要はありません。
上記により、論理レベルから今話したさまざまな問題が解決されます。 Alluxio を 0 から 1 に実現するための、最初の POC テストからさまざまなパフォーマンスの検証、最終的な導入、運用、保守に至るまで、導入プロセス全体について説明します。私たちの実際の経験の一部です。
Alluxio の導入: 単一のコンピュータ ルーム
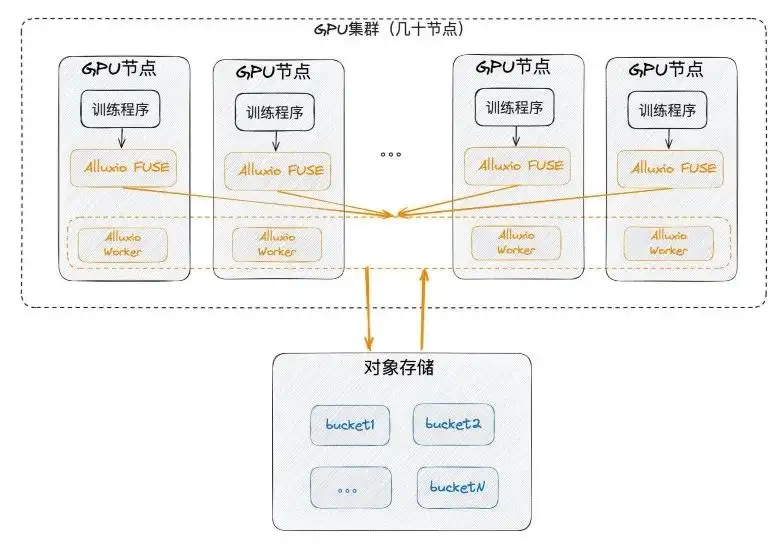
まず、単一のコンピューター室にデプロイする可能性があります。つまり、GPU の近くにあり、GPU ノードにデプロイされる必要があります。同時に、これまで GPU ではほとんど使用されていなかった SSD を使用して各ノードを活用し、FUSE とワーカーを一緒にデプロイしました。 FUSE はクライアントに相当し、ワーカーは FUSE サービスを提供するイントラネット通信を備えた小規模なキャッシュ クラスターに相当します。最後に、ワーカーは基礎となるオブジェクト ストレージ自体と通信します。
Alluxio の導入: コンピュータ ルーム全体
しかし、さまざまな理由により、クロスマシン ルームは引き続き存在します。現在、コンピューター ルームは 2 つあり、各コンピューター ルームには対応する S3 サービスと対応する GPU コンピューティング ノードがあります。基本的には、すべてのコンピューター室に Alluxio を配備します。同時に、このプロセスにも注意を払う必要があります。1 つのコンピュータ ルームに 2 つの Alluxio オブジェクト ストアが存在する場合は、バケット名については統一した計画を立てるようにしてください。 2つに過負荷をかけます。たとえば、ここにバケット 1 があり、あちらにバケット 1 がある場合、Alluxio がマウントされているときに問題が発生します。
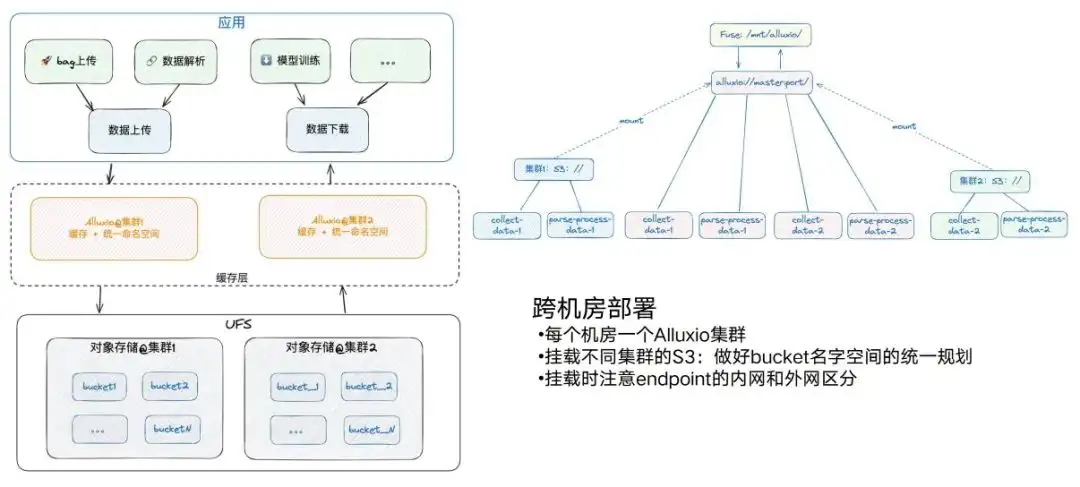
また、異なるエンドポイントでは、内部ネットワークと外部ネットワークの区別に注意してください。たとえば、クラスター 1 の Alluxio はクラスター 1 のエンドポイントの内部ネットワークをマウントし、それ以外の場合は外部ネットワークが反対側にあります。パフォーマンスが大幅に低下します。マウント後は、同じパスを介して異なるクラスター上の異なるバケットのデータにアクセスできるため、マシンルームをまたがる展開という観点から、アーキテクチャ全体が非常にシンプルになります。
Alluxio テスト: 機能
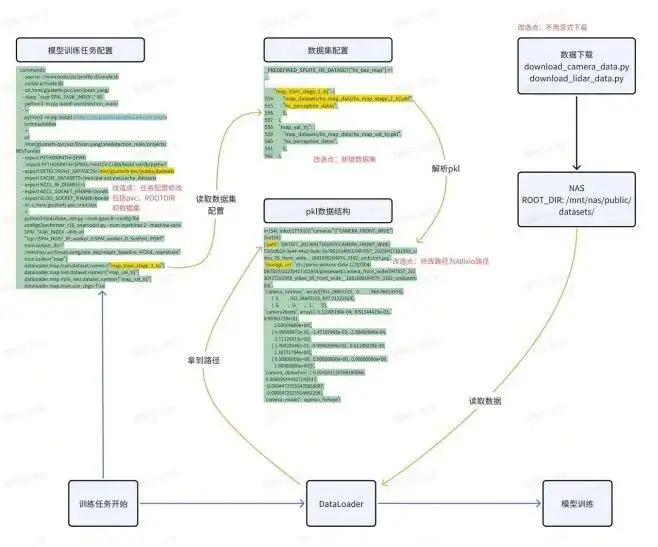
本当に NAS を Alluxio に置き換えたい場合は、導入前に多くの機能テストを行う必要があります。この種の機能テストの目的は、既存のアルゴリズム プロセスを最小限に変更して、アルゴリズムの学習者も使用できるようにすることです。これは実際の状況によって異なる場合があります。私たちは Alluxio を使用してほぼ 2 ~ 3 週間の POC 検証を行いました。これには、たとえば次のような内容が含まれます。
- K8S 上の PVC にアクセスする構成。
- データセットがどのように構成されているか。
- ジョブ送信の構成。
- アクセスパスの置き換え。
- 最終的にアクセスされるスクリプト インターフェイス。
上記で発生した問題の多くは、少なくともそれによって典型的なタスクを選択し、いくつかの変更を加えて、最終的に NAS を比較的スムーズに Alluxio に置き換える必要があることを確認する必要があります。
Alluxio テスト: パフォーマンス
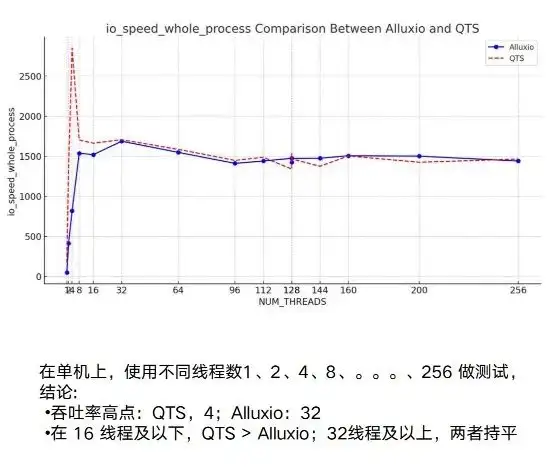
次に、これに基づいていくつかのパフォーマンス テストが実行されます。このプロセスでは、単一マシンであっても複数マシンであっても、比較的十分なテストが行われています。単一マシン上では、Alluxio と元の NAS のパフォーマンスは基本的に同じです。
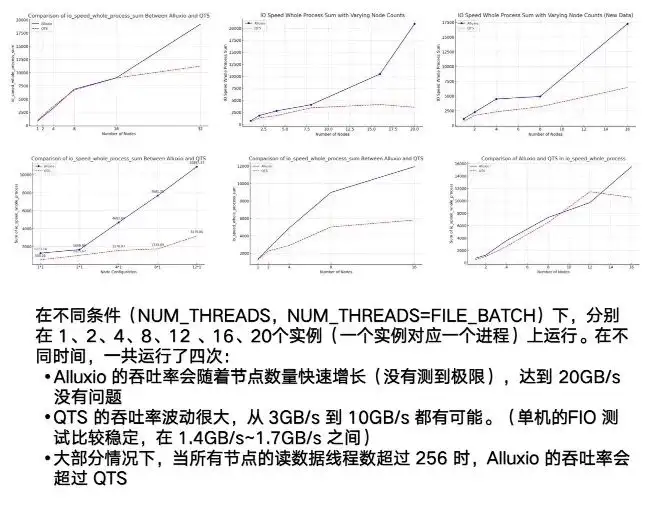
実際、Alluxio の利点を真に体現しているのは、そのマルチホスト機能と分散機能です。 NAS や QTS の例をご覧ください。これには、不安定性という非常に明白な点があります。 3G と 10G の間の変動は比較的大きくなりますが、7/8G 程度になると、基本的には安定します。
実際、Alluxio の利点を真に体現しているのは、そのマルチホスト機能と分散機能です。 NAS や QTS の例をご覧ください。これには、不安定性という非常に明白な点があります。 3G と 10G の間の変動は比較的大きくなりますが、7/8G 程度になると、基本的には安定します。
Alluxio に関しては、テスト プロセス全体で、実行中のインスタンスの数が増加するにつれて、ノードが非常に高い上限に達する可能性がありますが、20 GB/秒に設定しても、依然として上昇傾向を示しました。これは、Alluxio の全体的な同時分散パフォーマンスが非常に優れていることを示しています。
Alluxio の着陸: パラメータの調整と環境の適応
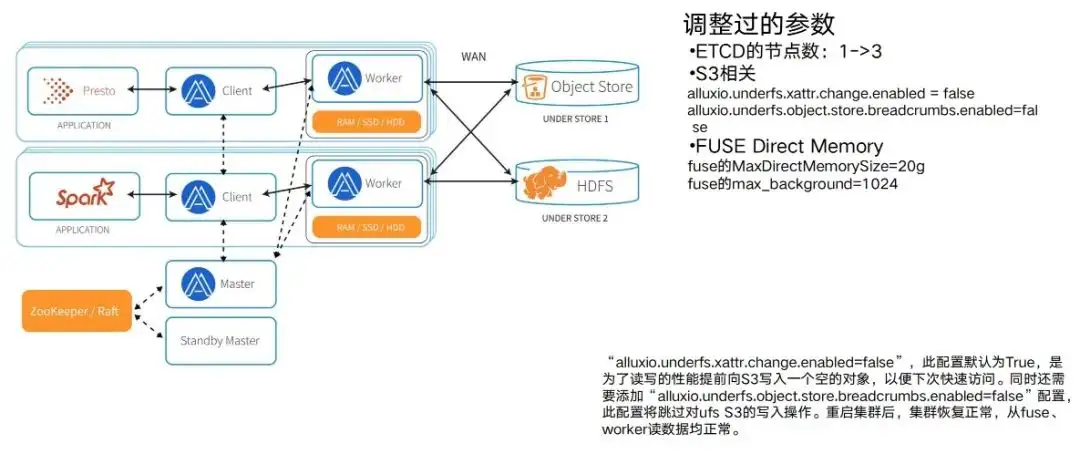
機能検証とパフォーマンステストが完了したら、実際に Alluxio クラスターをデプロイします。デプロイ後は、パラメーターの調整と適応のプロセスが必要です。テストではいくつかの典型的なタスクのみが使用されたため、実際に Alluxio 環境を使用すると、タスクが増加するにつれてパラメータの調整と適応のプロセスが発生することがわかります。 Alluxio のパフォーマンスを最大限に活用するには、Alluxio の対応するパラメータを実際の動作環境に合わせる必要があります。したがって、実行、運用および保守、パラメータの調整というプロセスが発生します。
次のようないくつかの典型的なパラメータ調整プロセスを実行しました。
- ETCD のノードがここにリストされます。最初は 1 で、その後 3 に変わります。これにより、ハングアップするのは 1 つの ETCD であり、クラスタ全体がハングアップしないことが保証されます。
- S3関連もあります。たとえば、Alluxio が実装されている場合、S3 は比較的長いアクセス パスを生成し、パフォーマンスを向上させるために中間パス ノードにデフォルトでいくつかの空白を書き込みます。ただし、この場合、トレーニング タスクの S3 には権限制御があり、この種のデータの書き込みは許可されていません。この種の矛盾に直面すると、パラメータの調整も必要になります。
- FUSE ノード自体が許容できる同時実行強度などの機能もあります。使用するダイレクト メモリのサイズも含めて、実際にはビジネス全体の実際の同時実行強度に大きく関係します。実際には、一度にアクセスできるデータの量に大きく関係します。また、パラメーターの調整プロセスなどもあります。環境が異なれば、さまざまな問題が発生する可能性があります。これが Alluxio Enterprise Edition を選択する理由でもあります。 Alluxio はエンタープライズ バージョンでは非常に強力なサポートを受けるため、問題が発生した場合は 24 時間年中無休で調整し、協力することができます。相互に調整されたサイクルによってのみ、クラスター全体をよりスムーズに実行できます。
Alluxioの導入:運用・保守
私たちのチームの初期の運用保守のクラスメートは 1 人だけで、その人が多くの基礎的なインフラ保守と関連作業を担当していました。私が Alluxio を導入したいと思ったとき、運用保守側のリソースは実際には十分ではなかったので、それと同等でした。私も半分は運営と保守の仕事をしています。自分で何かを運用・保守するという観点から見ると、特に初心者にとっては、運用・保守に関する知識や記録をたくさん残しておくことが重要です。たとえば、次回は問題をより良く解決する方法や、以前にそのような経験があったかどうかなどです。
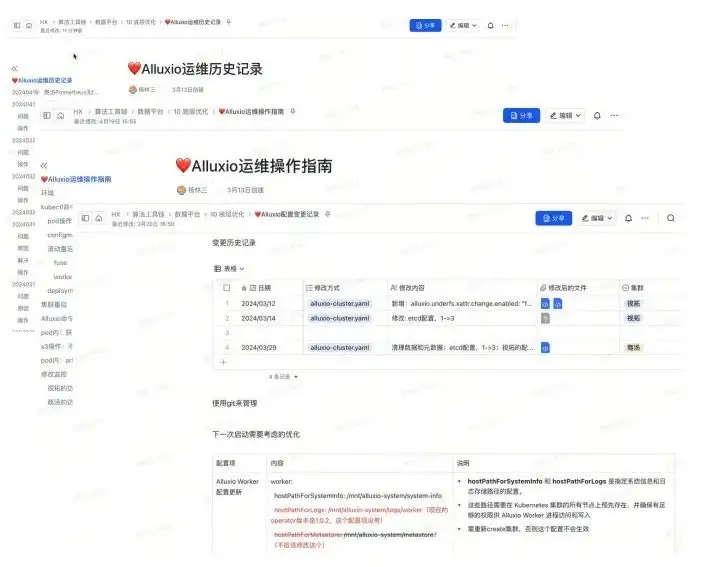
その時点の環境に基づいて、3 つのドキュメントが維持されます。
- 運用保守履歴文書:例えば、どの日にどのような問題が発生し、その根本的な原因と解決策は何か。具体的にはどのような操作があるのでしょうか?
- 運用ドキュメント: たとえば、K8S を運用および保守する場合、再起動する手順は何か、操作内容、問題が発生した場合のログの読み方、トラブルシューティングの方法、確認するにはどのタスクと作業を実行する必要があるかなど。 FUSE、モニタリングなどに対応するデータ。これらは一般的に使用される操作の一部です。
- 設定の変更: Alluxio がパラメータを調整中であるためです。時々、異なる構成ファイルや yaml ファイルが見つかる可能性があり、バックアップの作成が必要になる場合があります。 Git を使用して管理することも、単にドキュメント管理を使用することもできます。このようにして、現在の構成および過去の構成バージョンまで遡ることができます。
これに基づいて、Alluxio をより効果的に使用するための関連するサポート構築も行う予定です。研究開発の学生は、Alluxio を使用してみて、非常に使いやすいと感じています。しかし、マルチタスクを行う場合、サポート構築のニーズが明らかになります。たとえば、より多くのタスク キャッシュをサポートするには、画像のサイズを変更し、画像を高解像度 4K から 720P に縮小する必要があります。
トレーニング データ セットはクラスター間で同期され、データのプリロードが向上します。これらはすべて、Alluxio が行う必要がある体系的な構築を中心としています。
Alluxio の着陸: 共に前進する
Alluxio を使用し続けると、改善すべき点もいくつか見つかります。Alluxio にフィードバックを提供することで、製品全体のイテレーションを促進しました。特に次の点が挙げられます。
アルゴリズムを開発する学生が気にしていることは次のとおりです。
- 安定性: Alluxio で何かがクラッシュしたために、システム全体のトレーニングが妨げられないよう、動作中に安定している必要があります。ここには、FUSE をできるだけ再起動しないようにするなど、運用およびメンテナンスのヒントが記載されている可能性があります。先ほど述べたように、FUSE を再起動すると、アクセス パスに障害が発生し、データ ファイルの読み取り時に IO エラーが発生します。
- 決定論:たとえば、Alluxio は以前、データをプリロードする必要はない、つまり、事前トレーニング前に一度読み取る必要はなく、最初のエポック中に一度だけ読み取る必要があることを示唆しました。ただし、研究開発にはリリース サイクルがあるため、最初のエポックを読み込む場合に、プリロードにかかる時間を正確に把握する必要があり、トレーニング全体の時間を見積もることは困難です。これは実際には、ファイル リストを介してキャッシュする方法にも当てはまります。これは、Alluxio にもいくつかの要求を課します。
- 制御性: Alluxio は自動化された LRU ベースのキャッシュ削除とキャッシュ クリーニングを提供できます。しかし実際には、R&D は依然として、キャッシュされた一部のデータを積極的に消去できることを望んでいます。では、Alluxio にファイル リストを提供してこのデータを解放してもらうこともできますか?これは、間接的な使用に加えて、Alluxio を直接かつ非常に制御可能な方法で使用する必要性でもあります。
運用と保守の面からも、いくつかの要件が提起されます。
- 構成センター: Alluxio 自体は、構成履歴を保存するための構成センターを提供できます。構成項目の変更を実装する機能を追加する場合は、その変更がどのような影響を与えるかを事前に計画してください。
- トレースは、コマンドの実行プロセスを追跡します。たとえば、下部の UFS ファイルにアクセスするときの遅延が比較的大きいという問題が見つかりました。その理由は何でしょうか。 FUSE ログを見ても原因がわからない場合があるため、その場所に対応するワーカー ログを確認する必要があります。これは実際には非常に時間がかかり面倒なプロセスであり、多くの場合問題を解決できないため、Alluxio のオンライン カスタマー サービス サポートが必要になります。 Alluxio は、リンク全体にアクセスするときの FUSE、作業、UFS からの読み取りなどの時間のかかる問題をトレースする Trace コマンドを追加できますか?これは実際、運用とメンテナンスのプロセス全体、またはトラブルシューティングのプロセスに非常に役立ちます。
- インテリジェントな監視:監視対象が、すでに知っていることである場合があります。たとえば、ダイレクトメモリに問題がある場合、監視項目を設定してみましょう。しかし、次に新しい問題がログに現れるときは、それは誰にも気づかれずに静かに発生する隠れた問題である可能性があります。この状況を自動的に監視できるようにしたいと考えています。
私たちは作業指示のフィードバックを通じて Alluxio にさまざまな提案を行いました。 Alluxio が製品の反復プロセス中にさらに強力な機能を提供できることが期待されています。研究開発、運用、保守全体をより満足のいくものにします。
まとめ
まず、 Alluxio は、自動運転モデルのトレーニング全体のキャッシュ高速化の点で、NAS と比較して非常に優れた使いやすさを提供します。私たちにとっても、約 10 倍の改善になります。コスト削減は次の 2 つの部分から生じます。
- 製品の調達コストが低い。
- NAS には 20% ~ 30% の冗長ストレージが搭載されている場合がありますが、これは Alluxio で解決できます。
保守性の観点からは、データを自動的にクリーンアップできるため、よりタイムリーかつ安全です。使いやすさの点では、FUSE を介してより便利にデータにアクセスできます。
次に、 Huixi が Alluxio を 0 から 1 まで導入し、システムを運用および保守する方法についても共有しました。
以上が私のシェアです、皆さんありがとうございました。
