


共有ゲスト: Qiu Lu、Tang Chunxu、Wang Beinan
現在、人工知能 (AI) と機械学習 (ML) の分野は急速に発展しており、トレーニング中に大規模なデータセットを効果的に処理することがますます重要になっています。 Ray はこの分野で重要な役割を果たしており、効率的なデータ ストリーム処理を通じて大規模なデータ セットのトレーニングを可能にしています。 Ray は、データ セット全体をトレーニング マシンにローカルに保存することなく、大きなデータ セットを管理可能なチャンクに分割し、トレーニング ジョブを小さなタスクに分割します。ただし、この革新的なアプローチには特定の課題もあります。
Ray は大規模なデータセットを使用したトレーニングを容易にしますが、データの読み込みが依然として深刻なボトルネックとなっています。各エポックでは、リモート ストレージからデータ セット全体を再ロードする必要があるため、GPU の使用率が大幅に低下し、保存されたデータの送信コストが増加します。そのため、トレーニング プロセス中にデータを管理し、効率を向上させるためのより最適化された方法が必要です。
Ray は主にメモリを使用してデータを保存し、そのメモリ内オブジェクト ストレージは大規模なタスク データ用に設計されています。ただし、このアプローチは、大規模なタスクに必要なデータを実行前に Ray のメモリ ストレージにプリロードする必要があるため、データ集約型のタスクではボトルネックに直面します。通常、オブジェクト ストレージのサイズはトレーニング データ セットを収容できないため、複数のトレーニング エポックにわたってデータをキャッシュするのには適していません。このことは、Ray フレームワーク用のよりスケーラブルなデータ管理ソリューションの必要性も強調しています。
Ray の重要な利点の 1 つは、データのロードと前処理に CPU を利用しながら、トレーニングには GPU を利用することです。この方法では、Ray クラスター内の GPU、CPU、およびメモリ リソースを効率的に利用できますが、ディスク リソースが十分に活用されず、効果的な管理ができなくなることもあります。革新的なアイデアが生まれました。それは、マシン全体で非効率なディスク リソースをインテリジェントに管理することで、トレーニング データ セットをキャッシュしてアクセスするための高性能データ アクセス レイヤーを構築することで、全体的なトレーニング パフォーマンスを大幅に向上させ、リモート ストレージへのアクセス頻度を削減することができます。
Alluxio は、GPU および隣接する CPU マシン上の未使用のディスク容量を分散キャッシュに賢明かつ効率的に利用することで、大規模なデータセットのトレーニングを加速します。この革新的なアプローチにより、大規模なデータセットを使用したトレーニングに不可欠なデータ読み込みパフォーマンスが大幅に向上すると同時に、リモート ストレージへの依存と関連するデータ転送コストも削減されます。
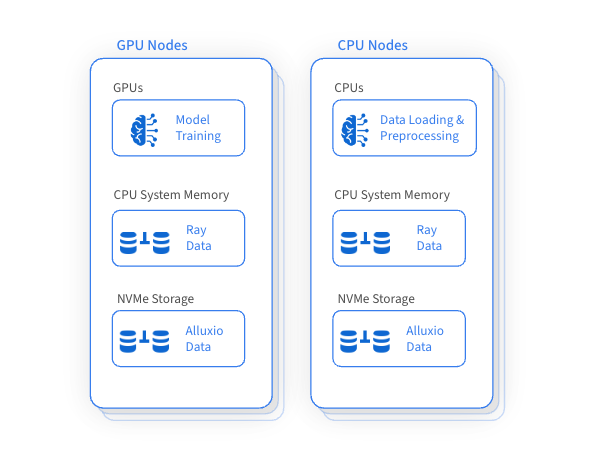
Alluxio を統合すると、Ray のデータ管理機能が向上し、多くのメリットがもたらされます。
√
スケーラビリティ
データアクセスとキャッシュは拡張性が高い
√
データアクセスの高速化
高性能ディスクを利用してデータをキャッシュします
Parquet などの列ストレージ ファイル形式の同時実行性の高いランダム読み取り用に最適化されています。
ゼロコピー
√
信頼性と可用性
単一障害点がない
停止中の堅牢なリモート ストレージ アクセス
√
柔軟なリソース管理
ワークロードのニーズに基づいてキャッシュ リソースを動的に割り当ておよび解放する
Ray は、機械学習ワークフローを効果的に調整し、データの読み込み、前処理、トレーニング フレームワークとシームレスに統合できます。 Alluxio は、高性能データ アクセス レイヤーとして、特にリモート ストレージ データに繰り返しアクセスする必要がある場合に、AI/ML トレーニングと推論タスクを大幅に最適化できます。
Ray は PyArrow を利用してデータをロードし、データ形式を Arrow 形式に変換します。これは次の段階の Ray ワークフローで使用されます。 PyArrow はストレージ接続の問題を fsspec フレームワークに委任し、Alluxio は Ray と基盤となるストレージ システム (S3、Azure Blob Storage、Hugging Face など) の間の中間キャッシュ層として機能します。
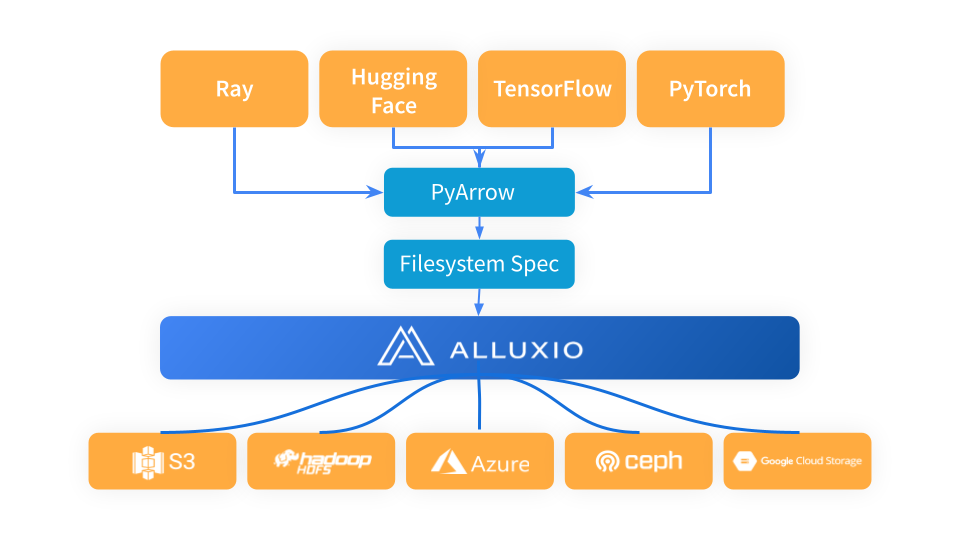
Ray と S3 の間のキャッシュ レイヤーとして Alluxio を使用する場合は、Alluxiofs をインポートし、Alluxio ファイル システムを初期化し、Ray ファイル システムを Alluxio に変更するだけです。
# Import fsspec & alluxio fsspec implementationimport fsspecfrom alluxiofs import AlluxioFileSystemfsspec.register_implementation("alluxio", AlluxioFileSystem)# Create Alluxio filesystem with S3 as the underlying storage systemalluxio = fsspec.filesystem("alluxio", target_protocol=”s3”, etcd_host=args.etcd_host)# Ray read data from Alluxio using S3 URLds = ray.data.read_images("s3://datasets/imagenet-full/train", filesystem=alluxio)
Ray Data の Ray Data 夜間テストを使用して、同じリージョン内の異なるトレーニング エポックでの Alluxio と S3 のデータ読み込みパフォーマンスを比較します。ベンチマーク結果は、Alluxio と Ray を統合することによって、ストレージ コストが大幅に削減され、スループットが向上することを示しています。

√
データ アクセス パフォーマンスの向上: Ray のオブジェクト ストレージがメモリ負荷の影響を受けない場合、Alluxio のスループットは同じ領域で S3 の 2 倍であることが観察されました。
√
メモリ負荷がかかると、その利点はより明白になります。Rayのオブジェクト ストレージがメモリ負荷に直面すると、Alluxio のパフォーマンス上の利点が大幅に増加し、そのスループットが S3 の 5 倍になることは注目に値します。
Ray タスクの場合、未使用のディスク リソースを分散キャッシュのストレージとして使用することは戦略的に非常に重要です。この方法はデータ読み込みパフォーマンスを大幅に向上させ、複数のエポックにわたって同じデータセットを使用してトレーニングまたはチューニングする場合に特に役立ちます。さらに、Ray はメモリ不足に直面した場合、これらのシナリオでデータ管理プロセスを最適化および簡素化するための実用的なソリューションを提供できます。
✦
[アシスタントを追加して詳細情報を入手]
✦

✦
【最近の人気】
✦

✦
【保電市場】
✦






この記事は WeChat 公開アカウント - Alluxio (Alluxio_China) から共有されたものです。
侵害がある場合は、削除について [email protected] までご連絡ください。
この記事は「OSC ソース作成計画」に参加していますので、読んでいる方もぜひ参加して共有してください。