1. 목록 차이
1.1 ArrayList (작은 변경 사항)
ArrayList가 매개 변수없이 초기화되면 Java 7은 직접 10의 크기를 초기화합니다. Java 8은이 로직을 제거합니다. 초기화 중에는 빈 배열입니다. 첫 번째 추가가 추가되면 10에 따라 확장되기 시작합니다. 다음 그림은 소스 코드의 차이 비교 차트입니다.

Java 7 및 8은 List의 다른 측면에서 변경되지 않았습니다.
2.지도 차이
2.1 HashMap (대규모 변경)
- ArrayList와 마찬가지로 Java 8의 HashMap은 매개 변수가없는 생성자에서 Java 7의 직접 배열 초기화 16을 버리지 만 배열 크기를 확장하기 위해 처음 추가 될 때 사용합니다.
- 해시 알고리즘 계산 공식이 다르며 Java 8의 해시 알고리즘이 더 간단하고 코드가 더 간결합니다.
- Java 8의 HashMap은 Java 7에서는 사용할 수없는 red-black 트리 데이터 구조를 추가합니다. Java 7에는 배열 + 연결 목록 구조 만 있습니다. Java 8에서는 배열 + 연결 목록 + 빨강-검정 트리 구조를 제안합니다. 일반적으로 키는 Java입니다. 예를 들어, API를 사용할 때 문자열 해시 코드는 좋은 API를 구현하고 연결 목록이 레드-블랙 트리로 변환되는 경우는 드뭅니다. 문자열 API의 해시 알고리즘은 충분하기 때문에 키가 사용자 정의 클래스 인 경우에만 재정의합니다. 작성된 해시 코드 알고리즘이 매우 나쁘면 검색 속도를 향상시키기 위해 빨강-검정 트리가 사용됩니다.
- 또한 자바 8이 레드-블랙 트리를 추가했기 때문에 넣기, 제거 및 기타 작업과 같은 배열을 작동하는 거의 모든 방법이 변경 되었기 때문입니다 .Java 8의 HashMap이 거의 다시 작성되었다고 할 수 있으므로 Java 7 확장 중 교착 상태가 발생할 가능성이 매우 적고 데이터가 손실되는 등의 많은 문제가 Java 8로 해결되었습니다.
- 몇 가지 유용한 방법을 추가했습니다.
- 예를 들어, getOrDefault, 소스 코드를 보면 매우 간단합니다.
// 如果 key 对应的值不存在,返回期望的默认值 defaultValue public V getOrDefault(Object key, V defaultValue) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? defaultValue : e.value; }- putIfAbsent (K key, V value) 메소드도있어 맵에 키가 있으면 값을 덮어 쓰지 않고 키가 없으면 추가가 성공합니다.
- 또한 키와 값의 값을 계산하여 맵에 넣을 수있는 계산 방법도 있습니다. 키 값이 없어서 발생하는 알 수없는 오류를 방지하기 위해 맵은 computeIfPresent 메소드도 제공합니다. 즉, 키가있는 경우에만 계산이 수행되고 데모는 다음과 같습니다.
@Test
public void compute(){
HashMap<Integer,Integer> map = Maps.newHashMap();
map.put(10,10);
log.info("compute 之前值为:{}",map.get(10));
map.compute(10,(key,value) -> key * value);
log.info("compute 之后值为:{}",map.get(10));
// 还原测试值
map.put(10,10);
// 如果为 11 的 key 不存在的话,需要注意 value 为空的情况,下面这行代码就会报空指针
// map.compute(11,(key,value) -> key * value);
// 为了防止 key 不存在时导致的未知异常,我们一般有两种办法
// 1:自己判断空指针
map.compute(11,(key,value) -> null == value ? null : key * value);
// 2:computeIfPresent 方法里面判断
map.computeIfPresent(11,(key,value) -> key * value);
log.info("computeIfPresent 之后值为:{}",map.get(11));
}
결과는 다음과 같습니다.
compute 之前值为:10
compute 之后值为:100
computeIfPresent 之后值为:null(这个结果中,可以看出,使用 computeIfPresent 避免了空指针)
2.2 LinkedHashMap
Java 8의 기본 데이터 변경으로 인해 데이터의 HashMap 조작 방식이 거의 재 작성되고 LinkedHashMap의 구현 이름이 다릅니다. 원칙은 동일합니다. 아래 그림을 보면 왼쪽은 Java 7, 오른쪽은 Java 8입니다. .
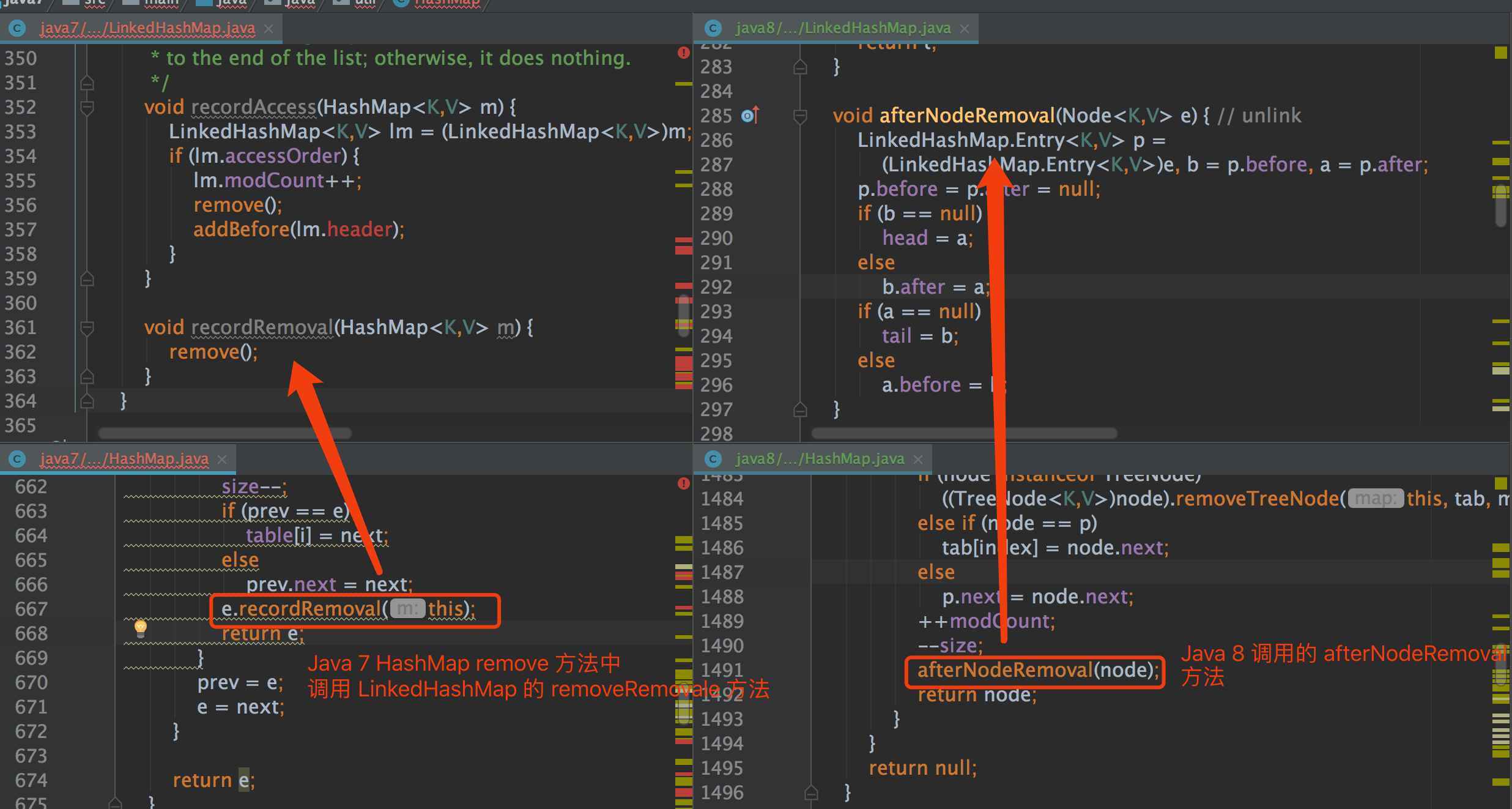
그림에서 LinkedHashMap의 메서드 이름이 수정되었으며 기본 구현 논리가 실제로 동일하다는 것을 알 수 있습니다.
3. 기타 차이점
배열은 병렬을 시작할 때 많은 방법을 제공합니다.
Java 8의 Arrays는 병렬로 시작하는 몇 가지 메소드를 제공합니다. 이러한 메소드는 병렬 계산을 지원합니다. 데이터 양이 많으면 CPU를 최대한 활용하여 계산 효율성을 향상시킵니다. 예를 들어 parallelSort 메소드는 메소드 하단에 판단이 있고 데이터 양만 8192보다 큽니다. 실제 실험에서 병렬 컴퓨팅은 실제로 컴퓨팅 속도를 빠르게 높일 수 있습니다.
4. 몇 가지 질문
-
Java 8은 List 및 Map 인터페이스에 많은 새로운 메소드를 추가했는데 Java 7에서 이러한 인터페이스의 구현자는 이러한 메소드를 구현할 필요가없는 이유는 무엇입니까?
답변 : 주된 이유는 이러한 새 메소드가 default 키워드에 의해 수정되기 때문입니다. 기본 메소드가 인터페이스에서 수정되면 인터페이스의 메소드에 기본 구현을 작성해야하며 하위 클래스는 이러한 메소드를 구현할 필요가 없으므로 Java 7 인터페이스 구현자는 인식 할 필요가 없습니다. -
Java 8에는 많은 새로운 실용적인 방법이 있습니다. 그것들은 무엇입니까?
답변 : 예를 들어 getOrDefault, putIfAbsent, computeIfPresent 메서드 등이 있습니다. 구체적인 사용 방법은 위를 참조하세요. -
computeIfPresent 메서드의 자세에 대해 이야기 하시겠습니까?
답변 : computeIfPresent는 키와 값을 계산 한 다음 계산 결과를 키에 다시 할당 할 수 있습니다. 키가 없으면 null 포인터를보고하지 않고 null 값을 반환합니다. -
forEach 메소드가 Java 8 콜렉션에 추가되었는데 일반 for 루프와 다른 점은 무엇입니까?
답변 : 새로운 forEach 메소드의 입력 매개 변수는 Consumer 및 BiConsumer와 같은 기능적 인터페이스입니다. 이렇게하면 for 루프의 코드가 캡슐화되어 사용자가 각 루프의 비즈니스 논리에만주의를 기울이면 간단하게 반복되는 for 루프 코드는 코드를 더 간결하게 만듭니다. 일반적인 for 루프의 경우 매번 반복되는 for 루프 코드를 작성해야합니다. ForEach는이 반복 된 계산 논리를 잡아 먹고 사용하기 더 편리하게 만듭니다. -
HashMap 8과 7의 차이점은 무엇입니까?
답 : HashMap 8과 HashMap 7의 차이가 너무 큽니다. Red-black 트리가 추가되고 기본 데이터 로직이 수정되고 해시 알고리즘이 수정되었습니다. 기본 배열을 변경하는 거의 모든 방법이 다시 작성되었습니다. Java 8 HashMap이 거의 다되었다고 할 수 있습니다. 다시 할.