하나의 기사에서 Pandas 데이터 병합 가져 오기
데이터 비즈니스 요구 사항의 실제 처리에서 종종 이러한 요구 사항이 발생합니다. 여러 테이블을 연결 한 다음 SQL의 연결 쿼리 기능과 유사한 데이터 처리 및 분석을 수행합니다.
Pandas는 또한이 기능을 수행하기 위해 여러 가지 방법을 제공합니다. 가장 눈에 띄고 널리 사용되는 방법은 병합입니다. 이 기사에서는 실제 사례를 통해 다음 네 가지 방법과 매개 변수를 자세히 설명합니다.
- 병합
- 추가
- 어울리다
- Concat

은 편의를 위해이 기사의 끝 부분에서이 기사의 소스 코드를 얻는 방법을 제공합니다.기사 디렉토리

이 두 라이브러리는 데이터 분석을 위해 라이브러리 를 가져올 때 가져와야 하며 국제 관행은 일반적입니다.
import pandas as pd
import numpy as np— 01 —
병합
공식 매개 변수
공식적으로 제공되는 병합 함수 의 매개 변수 는 다음과 같습니다. 
다음은 몇 가지 중요한 매개 변수의 사용 사례를 사례를 통해 설명합니다.
DataFrame.merge(left, right,
how='inner', # {‘left’, ‘right’, ‘outer’, ‘inner’}, default ‘inner’
on=None,
left_on=None, right_on=None,
sort=False,
suffixes=('_x', '_y'))시뮬레이션 데이터
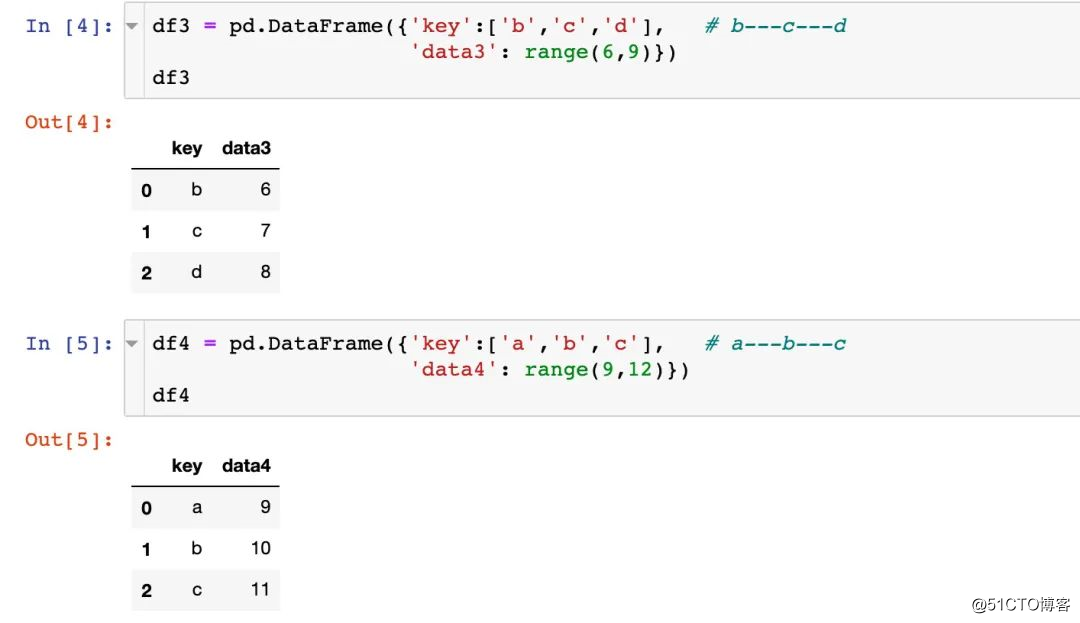
4 개의 데이터 세트 간의 차이점에 유의하십시오.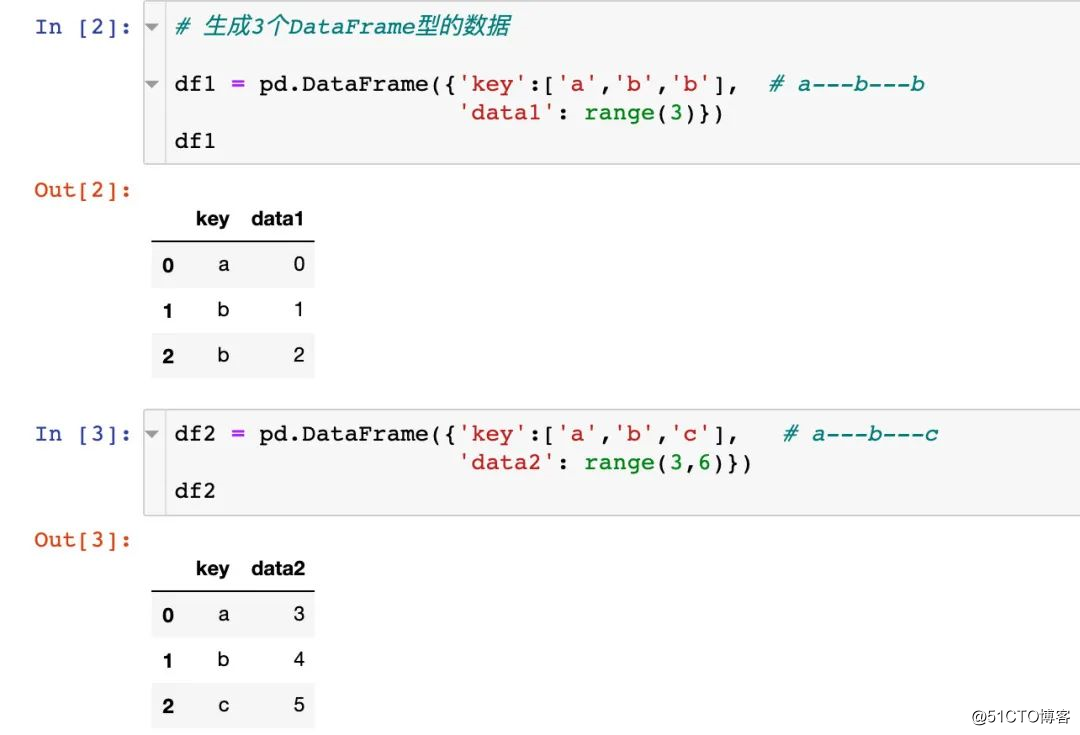
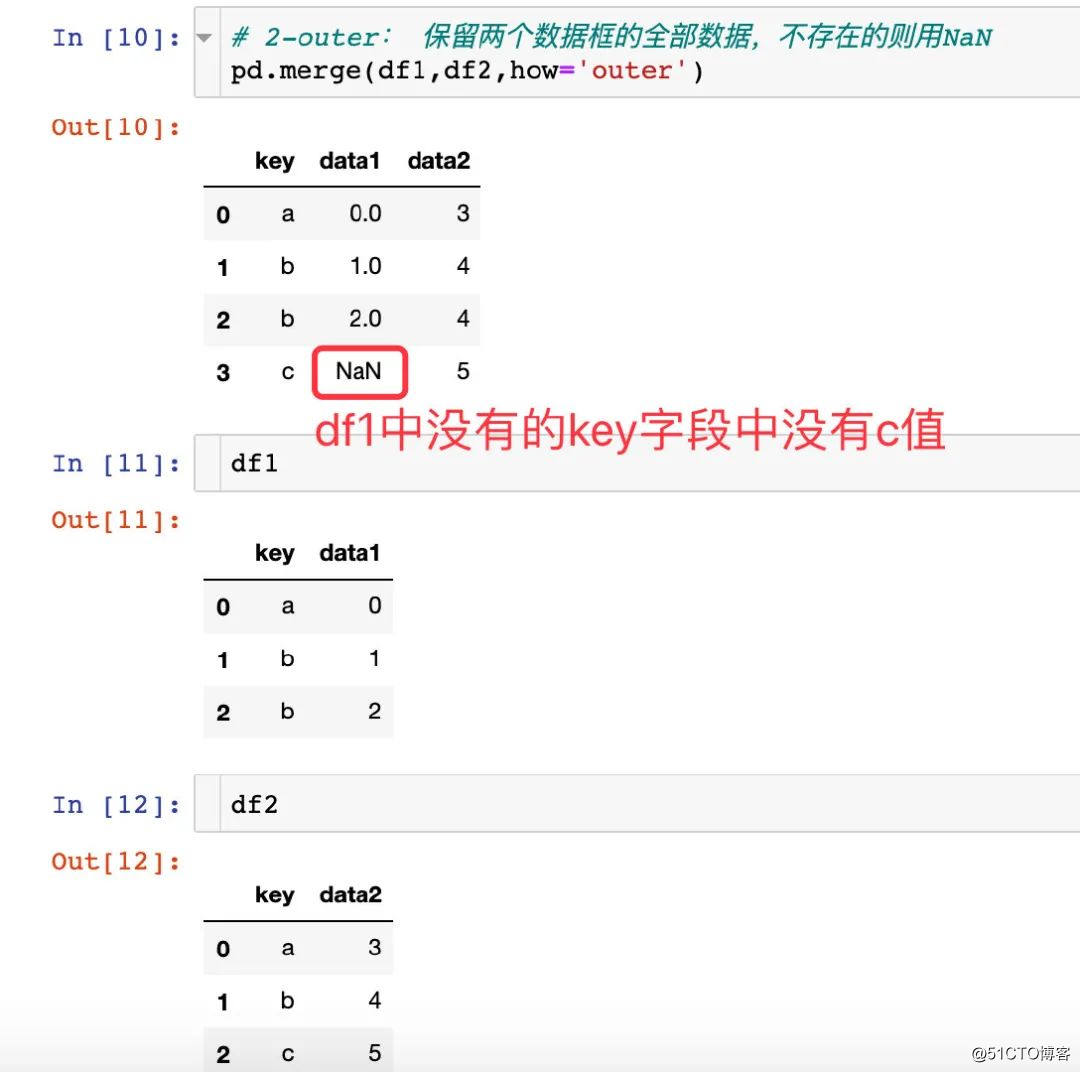
기본 매개 변수 사용
두 가지 다른 쓰기 방법이 동일한 효과를 가짐
매개 변수 방법
- how 매개 변수에는 4 개의 값이 있습니다.
- 내부 (기본값)
- 밖의
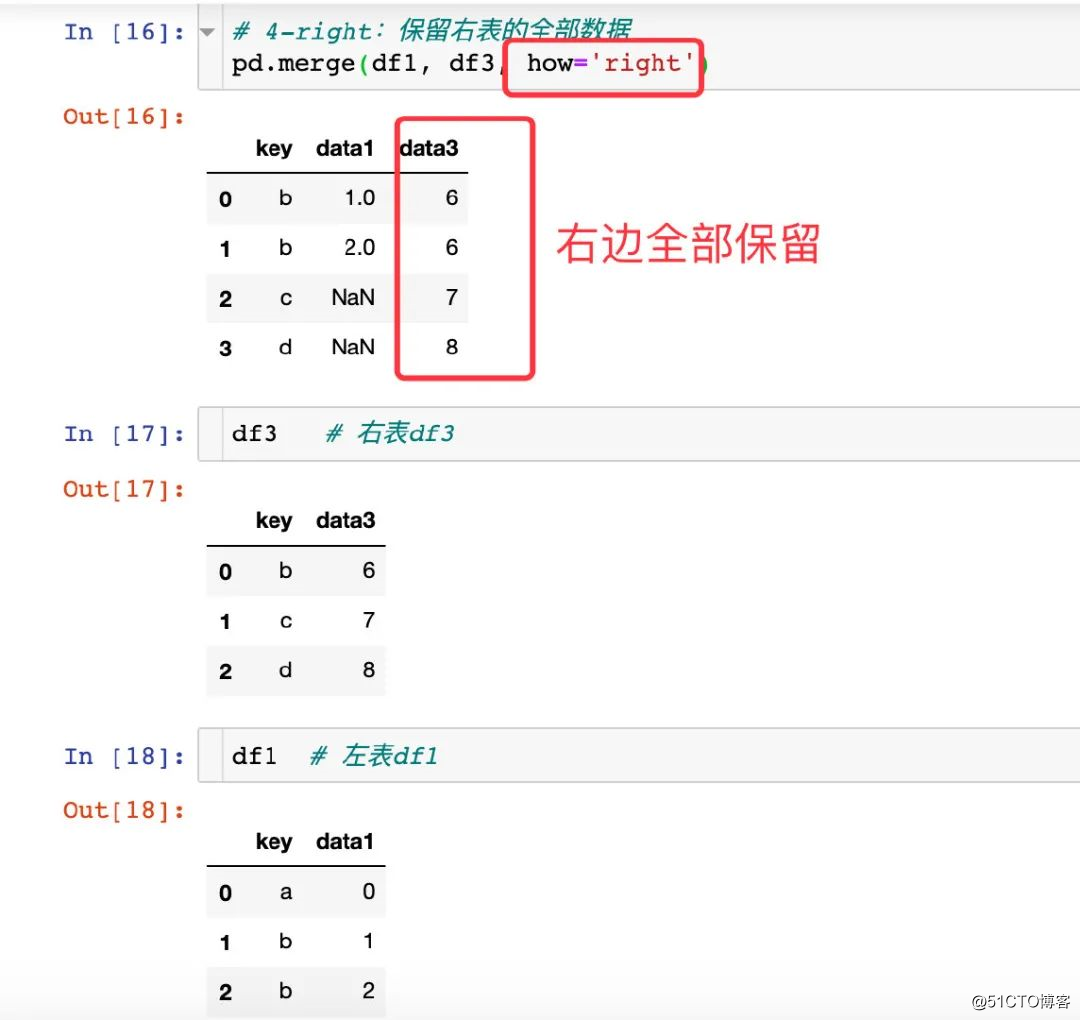
- 권리
- 왼쪽


매개 변수 켜기
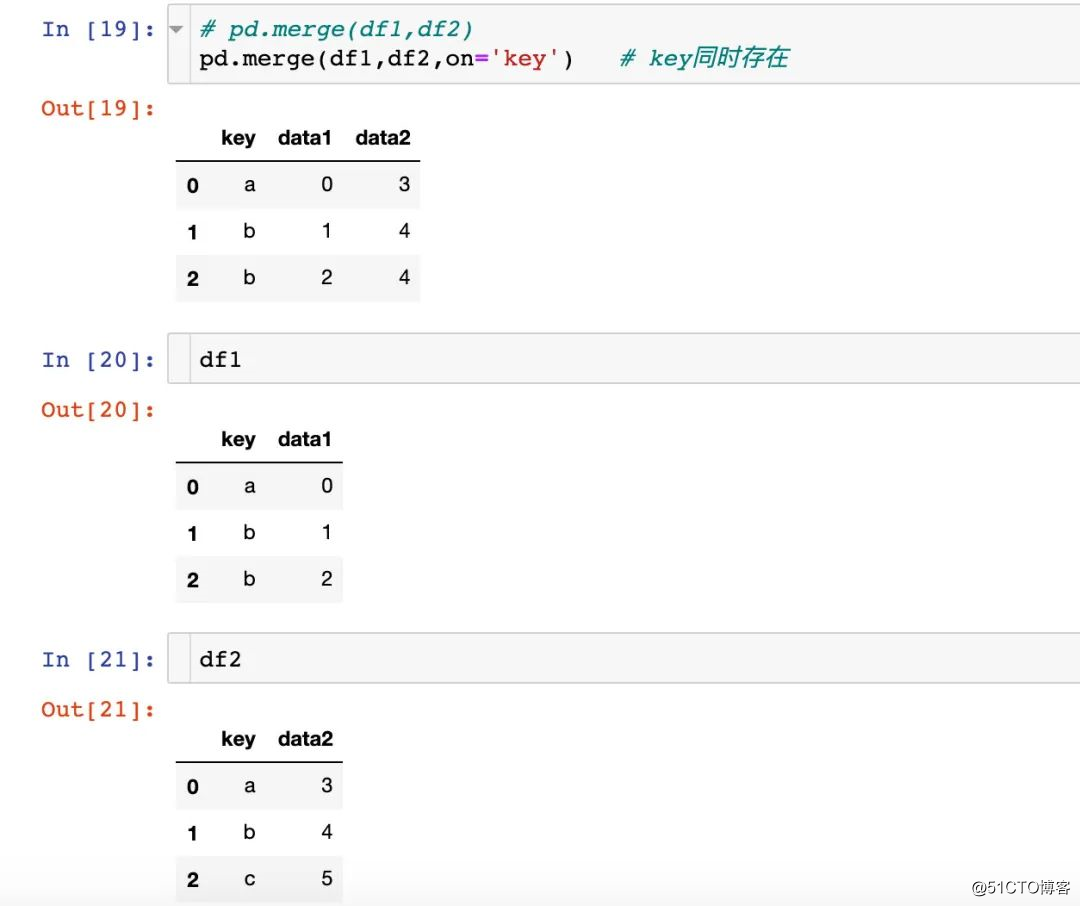
연결에 사용되는 열 인덱스 열 이름은 SQL에서 두 테이블의 동일한 필드 속성과 유사하게 두 데이터 프레임 데이터에 동시에 존재해야합니다.
지정되지 않거나 다른 매개 변수가 지정되지 않은 경우 두 데이터 프레임 데이터 연결 키와 동일한 키
on 매개 변수는 단일 필드입니다.
또 다른 예 : 

on 매개 변수는 여러 필드의 목록입니다.


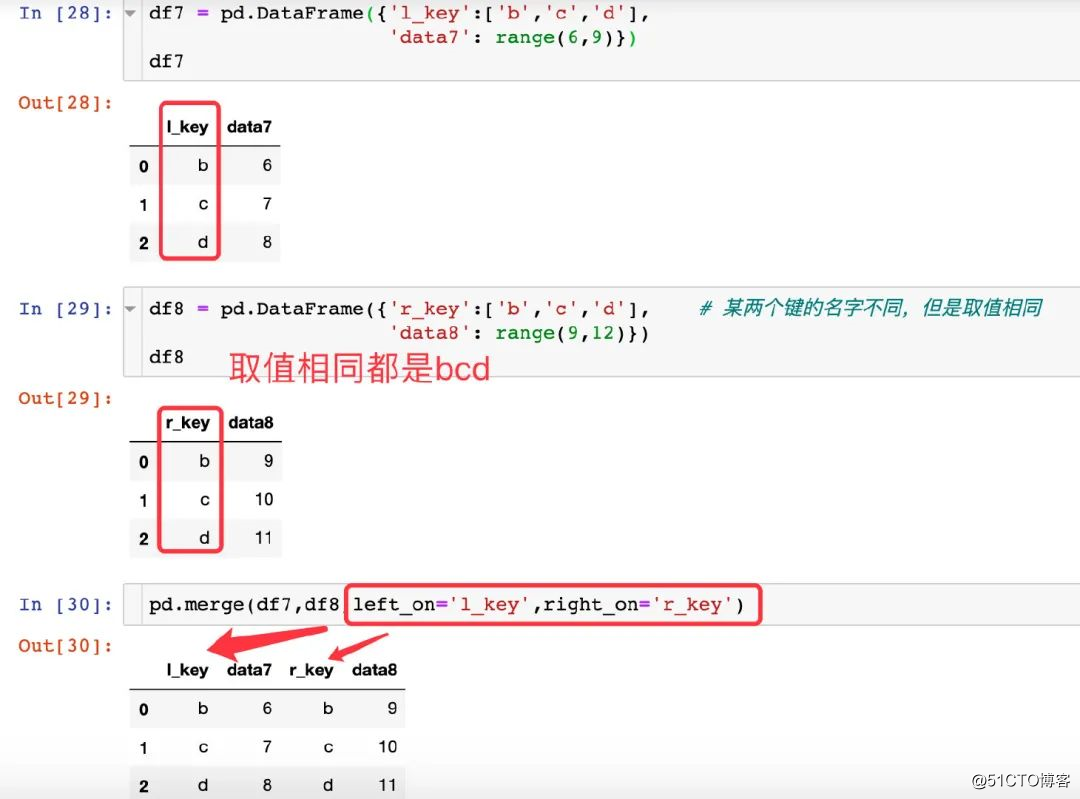
왼쪽 / 오른쪽 매개 변수
매개 변수 접미사
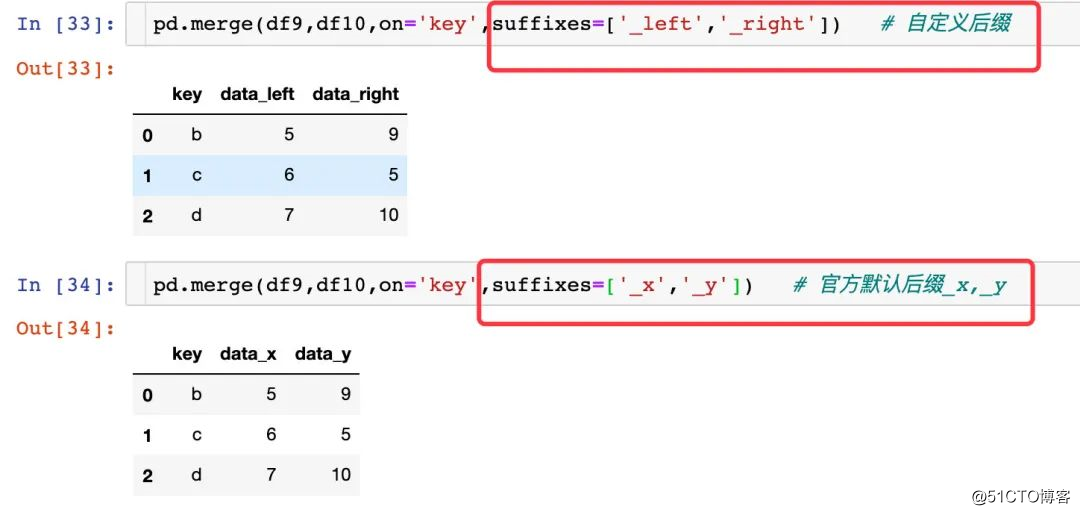
병합시 하나의 열과 두 개의 테이블은 같은 이름이지만 값은 다릅니다. 둘 다 저장하려면 접미사 방식을 사용하고 기본값은 _x, _y이며 직접 지정할 수 있습니다.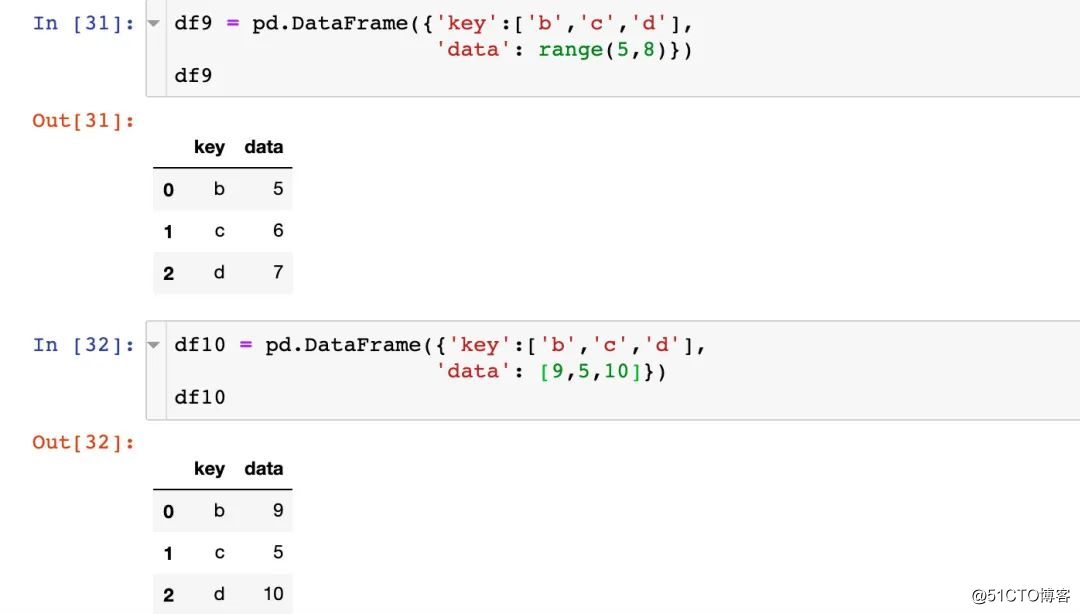
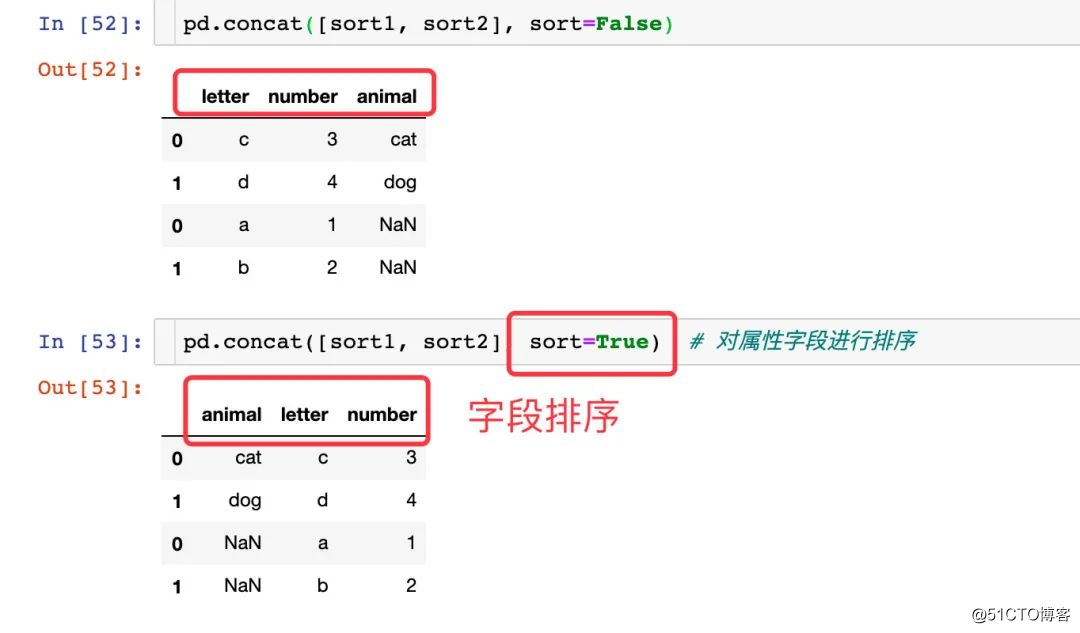
매개 변수 정렬
연결할 때 동일한 키의 값 정렬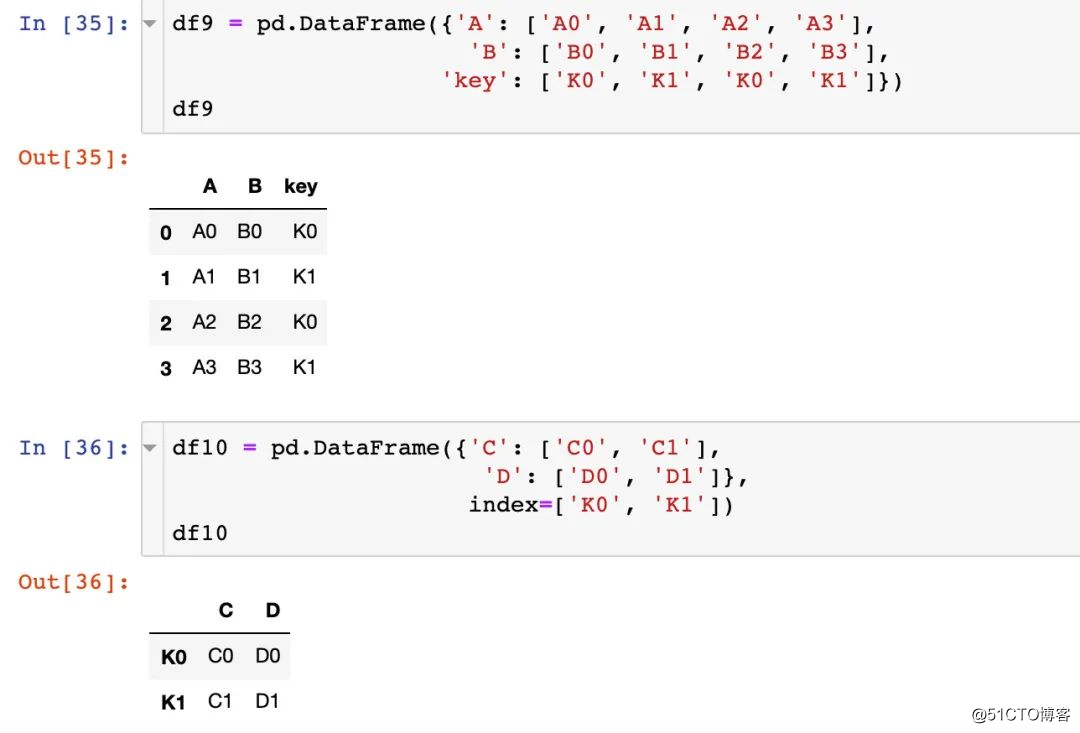
— 02 —
연결
공식 매개 변수
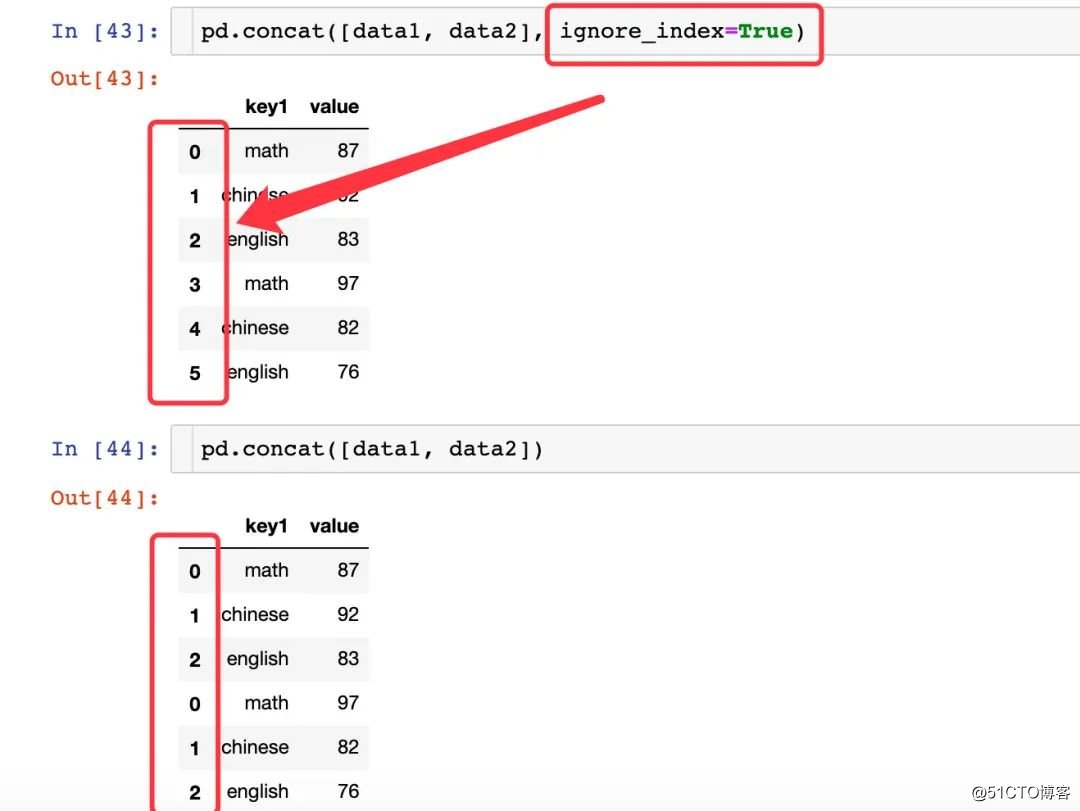
concat 메서드는 두 DataFrame 데이터 프레임의 데이터를 병합하는 것입니다.
- 축 매개 변수를 통해 행 또는 열 방향으로 병합할지 여부를 지정합니다.
- 매개 변수 ignore_index는 병합 된 색인 재 배열을 실현합니다.

데이터 생성
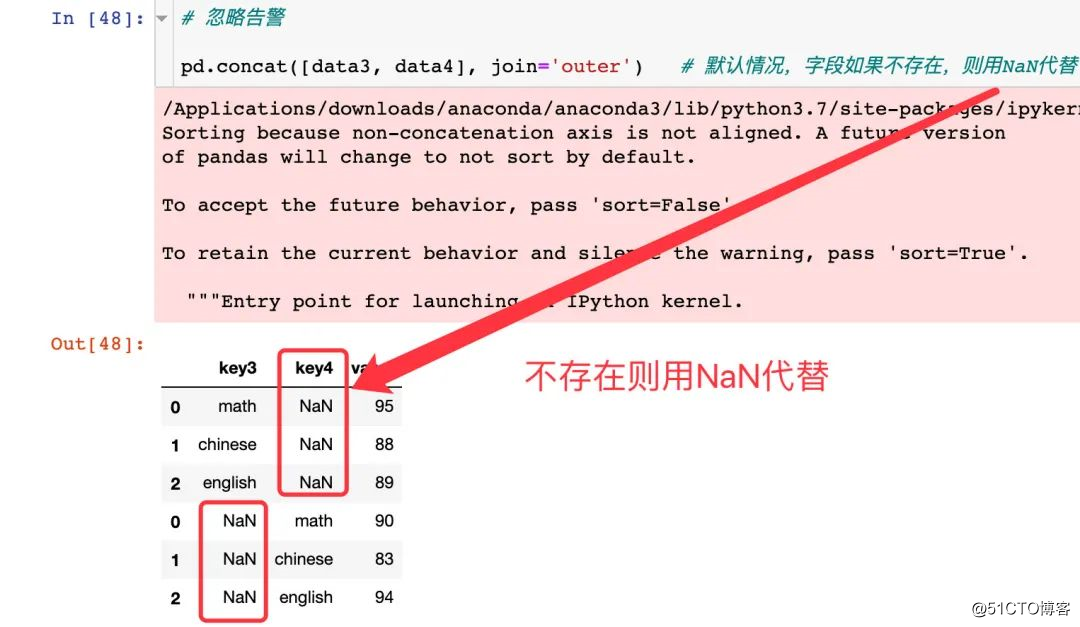
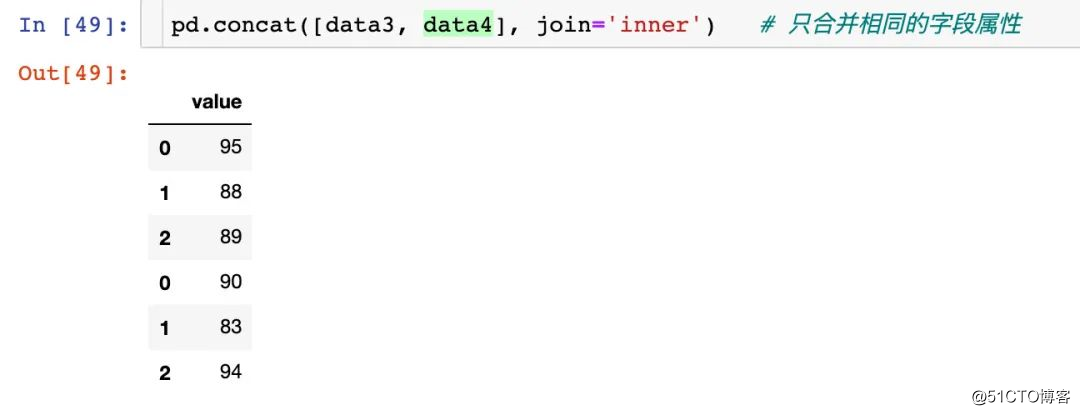
병합 축 지정

색인 변경
결합 매개 변수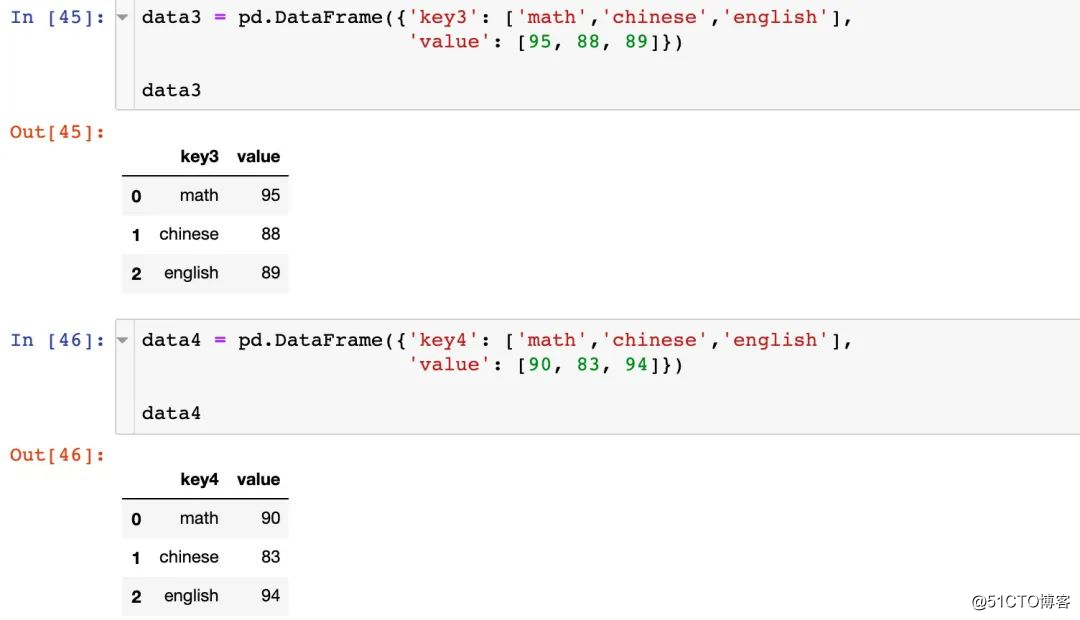
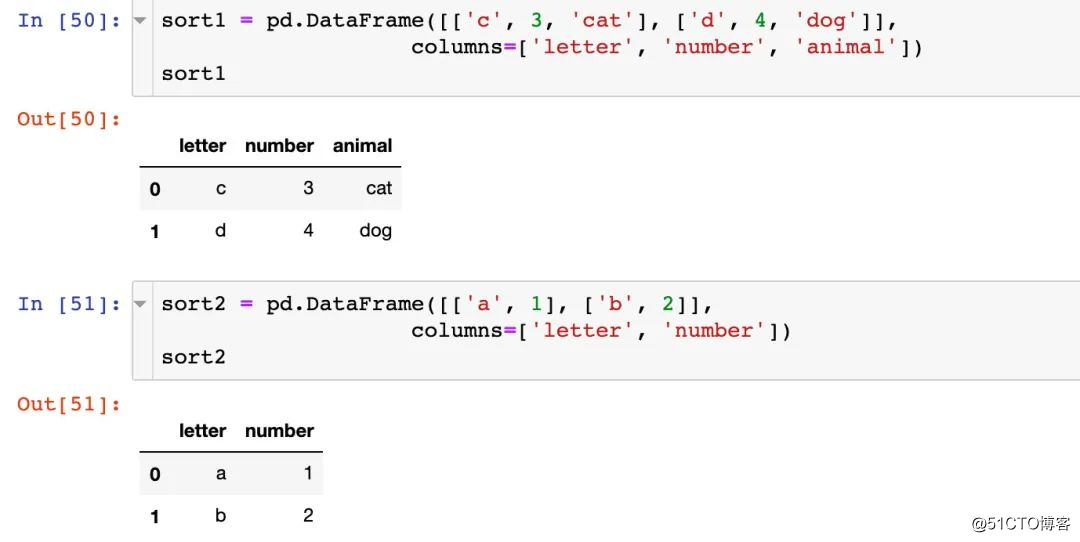
정렬 속성 정렬
— 03 —
추가
공식 매개 변수

기본 사용
data3.append(data4) # 等同于pd.append([data3, data4]) 忽略pandas版本的警告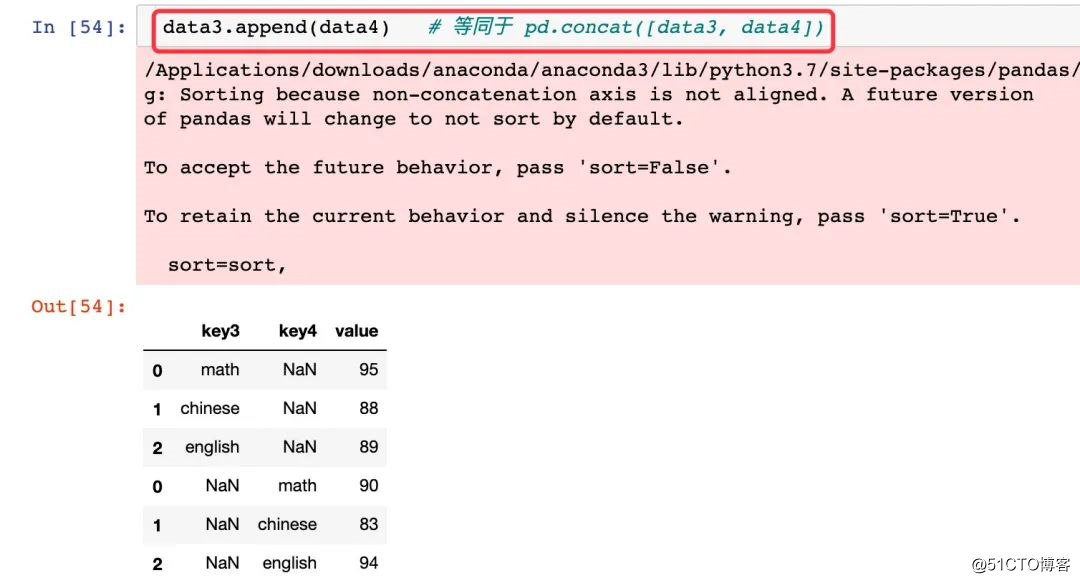
인덱스 자연수 정렬 변경
data3.append(data4, ignore_index=True) # 设置参数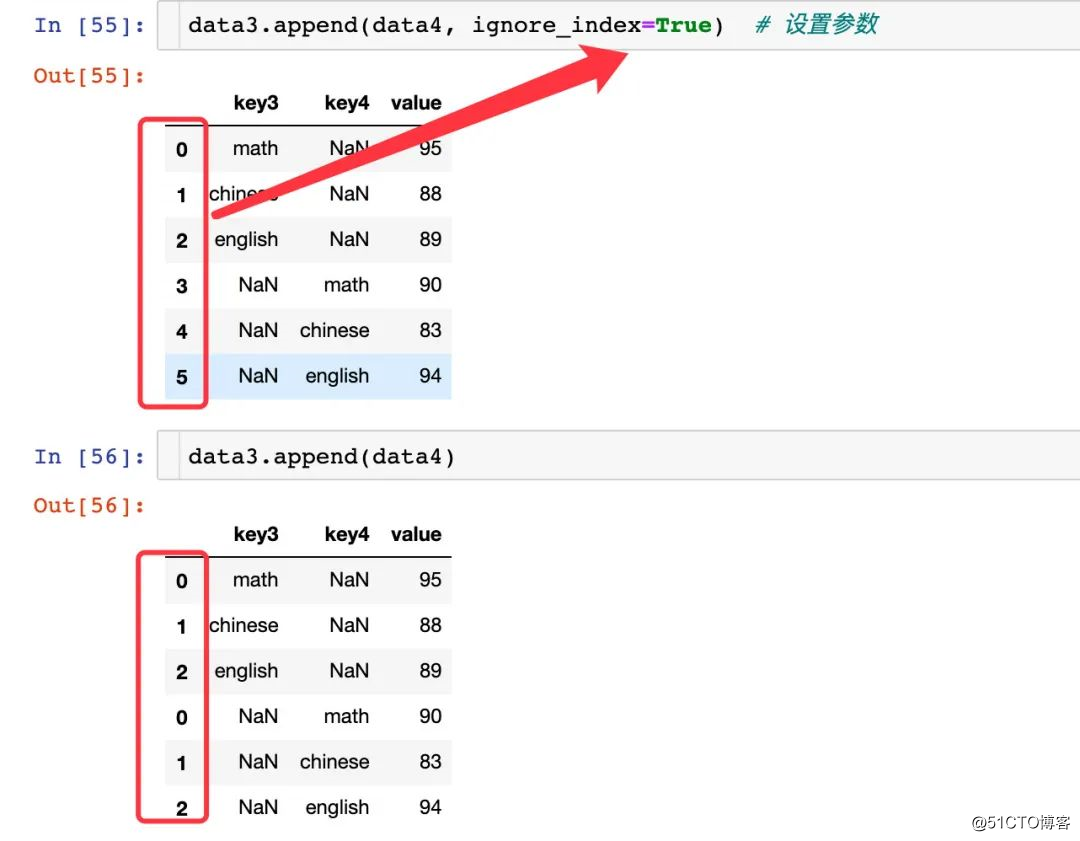
sort = 진정한 속성
data3.append(data4) # 默认对字段属性排序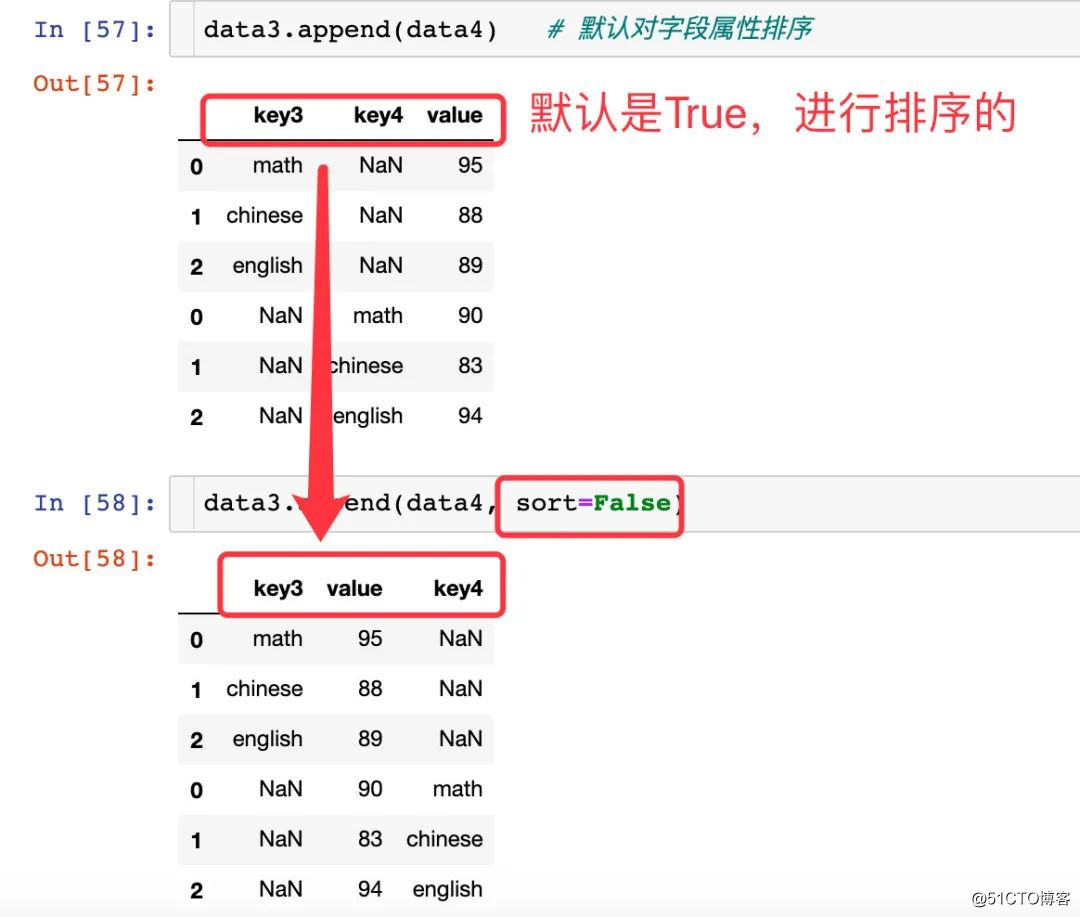
— 04 —
어울리다
공식 매개 변수

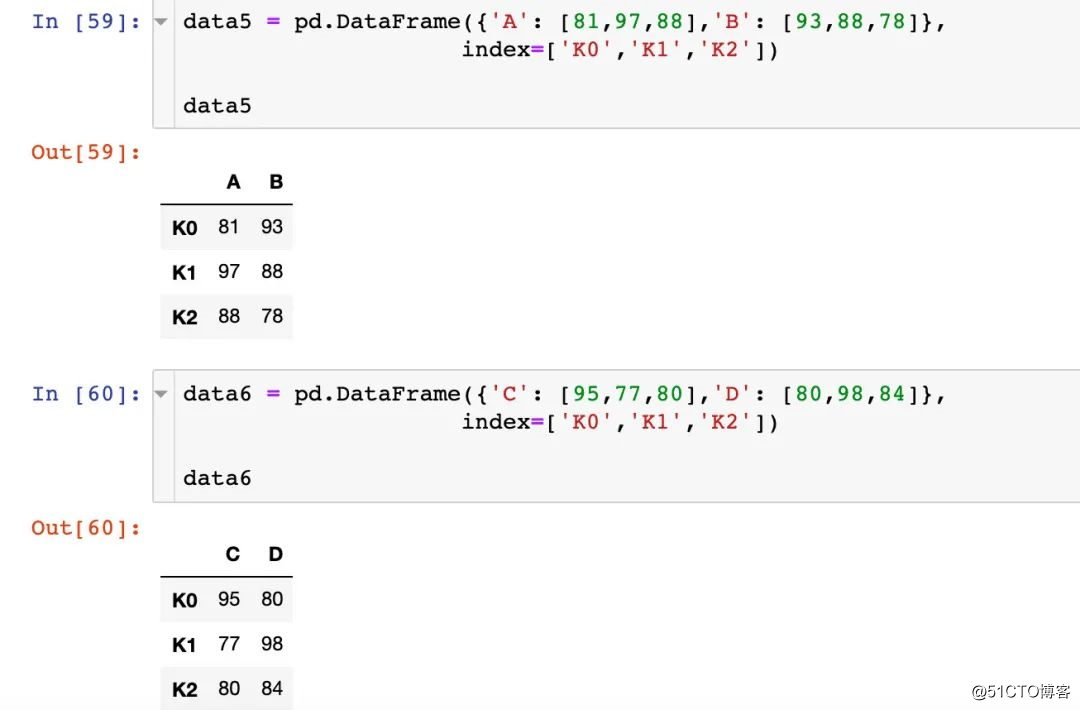
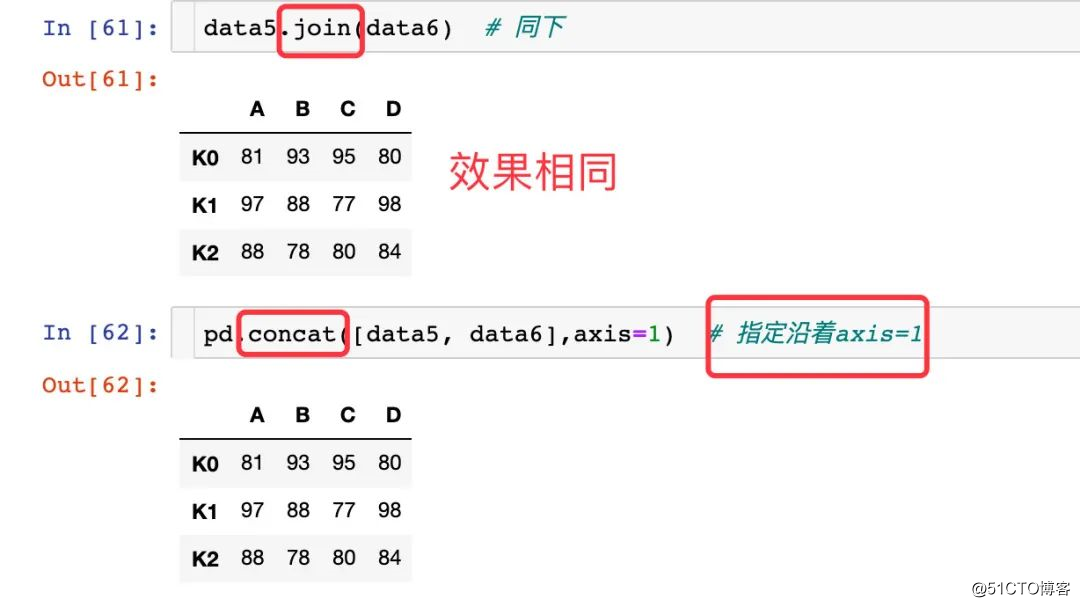
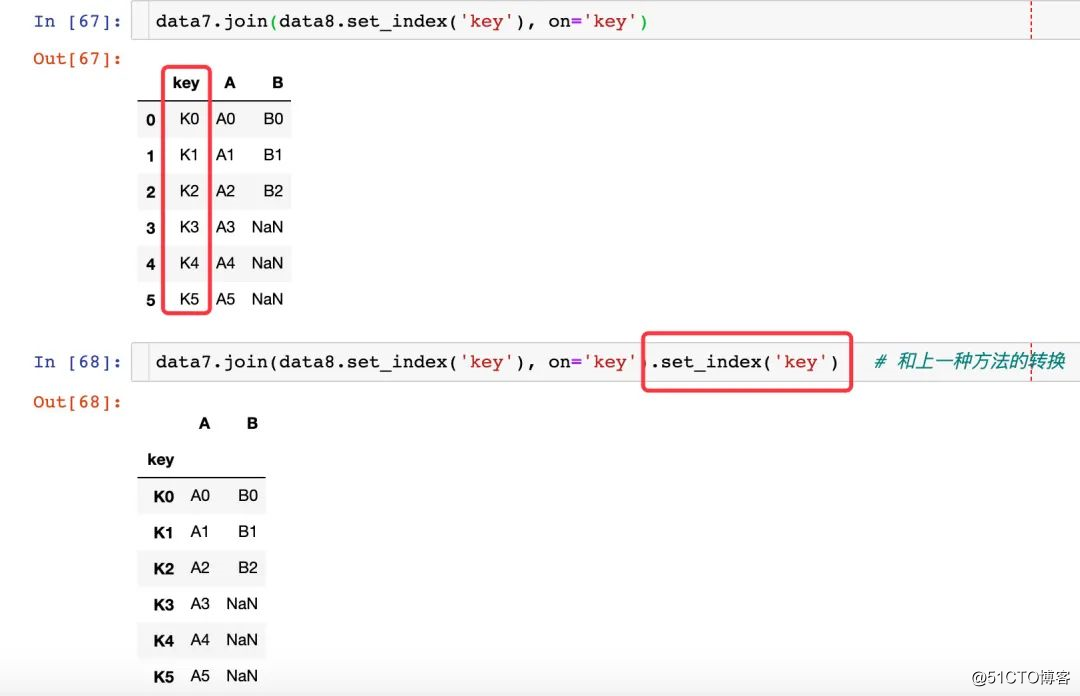
동일한 인덱스를 통해 병합
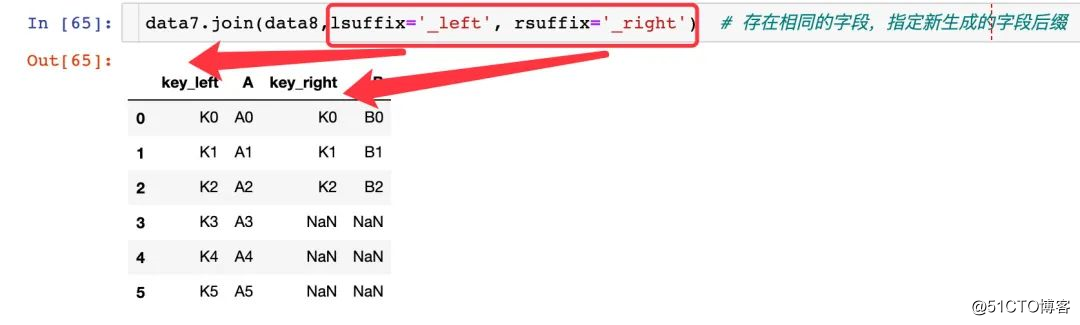
동일한 필드 속성이 접미사를 나타냄
같은 필드가 색인이됩니다.
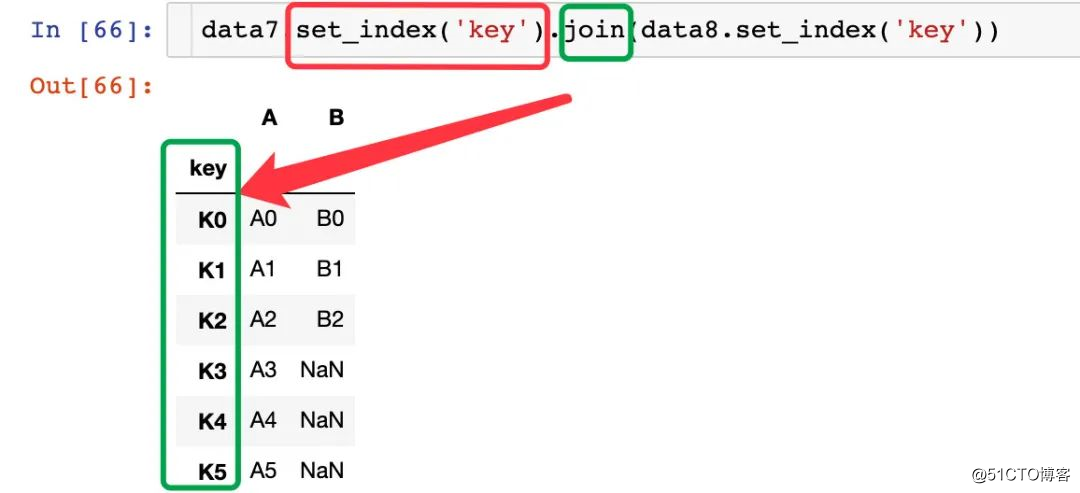
동일한 필드를 한 번 유지
연습을 용이하게하기 위해 공개 계정 "Python Data Way"의 백 스테이지에서 "20200917"에 회신하여이 기사의 소스 코드 파일을 얻을 수 있습니다.
---------종료---------