문자열과 튜플은 매우 유사하며 일단 정의되면 쉽게 수정할 수 없습니다.
수정해야하는 경우 슬라이스 및 연결을 사용
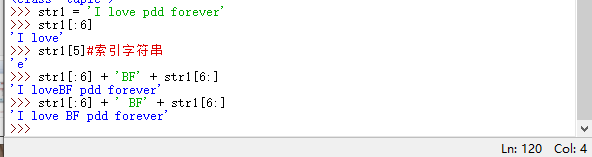
하여 이전 문자열 str1이 여전히 거기에 있고 할당 후 덮어 쓰기됩니다. 파이썬의 가비지 수집 메커니즘은 태그가없는 문자열을 제거합니다.

문자열에 대한 내장 메소드
| 방법 | 의미 |
|---|---|
| 자본화 () | 문자열의 첫 번째 문자를 대문자로 변경하고 다른 모든 문자를 소문자로 변경합니다. |
| 케이스 폴드 () | 새 문자열의 모든 문자는 소문자가됩니다. |
| center (너비, fillchar = '') | 중심에있는 새 문자열을 반환합니다 (너비 <= 문자열 길이, 새 문자열 = 원래 문자열, 너비> 문자열 너비, 모든 문자가 가운데 정렬되고 왼쪽과 오른쪽이 fillchar 매개 변수에 지정된 문자로 채워짐). |
| 개수 (서브 [, 시작 [, 끝]]) | 문자열에서 겹치지 않는 sub 항목 수를 반환합니다. 선택적 매개 변수 start 및 end는 시작 및 끝 위치를 지정하는 데 사용됩니다. |
| endswith (접미사 [, 시작 [, 끝]]) | 문자열이 접미사로 지정된 하위 문자열로 끝나면 True를 반환하고 그렇지 않으면 False를 반환합니다. 선택적 매개 변수 start 및 end는 시작 및 끝 위치를 지정하는 데 사용됩니다. |
| expandtabs ([tabsize = 8]) | 공백을 사용하여 탭을 대체하는 새 문자열을 반환합니다. tabsize 매개 변수가 지정되지 않은 경우 기본적으로 탭 1 개 = 공백 8 개입니다. |
| 찾기 (서브 [, 시작 [, 끝]]) | 문자열에서 하위 하위 문자열을 찾고 일치 항목의 가장 낮은 인덱스 값을 반환합니다. 선택적 매개 변수 start 및 end는 시작 및 끝 위치를 지정하는 데 사용됩니다. 하위 문자열이 일치하지 않으면 -1을 반환합니다. |
| join (반복 가능) | 여러 문자열을 연결하고 새 문자열을 반환합니다.이 메서드를 구분 기호로 호출하는 문자열을 사용하여 반복 가능한 매개 변수로 지정된 각 문자열의 중간에 삽입합니다. |
| encode (encoding = 'utf-8', errors = 'strict') | encoding 매개 변수에서 지정한 인코딩 형식으로 문자열을 인코딩합니다. errors 매개 변수는 인코딩 오류가 발생할 때 솔루션을 지정합니다. default'strict '는 오류가 발생하면 UnicodeEncodeError가 발생 함을 의미합니다. 기타 사용 가능한 매개 변수 값은 'ignore', 'replace'및 'xmlcharrefreplace'입니다. |
| 형식 (* args, ** kwargs) | 새로운 형식의 문자열을 반환하고 위치 매개 변수 (args) 및 키워드 인수 (kwargs)를 사용하여 대체합니다. |
| format_map (매핑) | 새로운 형식의 문자열을 반환하고 매핑 매개 변수 (매핑)를 사용하여 |
| 색인 (서브 [, 시작 [, 끝]]) | 문자열에서 하위 하위 문자열을 찾고 일치 항목의 가장 낮은 색인 값을 반환합니다. 선택적 매개 변수 start 및 end는 시작 및 끝 위치를 지정하는 데 사용됩니다. 하위 문자열이 일치하지 않으면 ValueError 예외가 발생합니다. |
| isalnum () | 문자열에 하나 이상의 문자가 있고 모든 문자가 문자 또는 숫자이면 True를 반환하고 그렇지 않으면 False를 반환합니다. |
| isalpha () | 문자열에 하나 이상의 문자가 있고 모든 문자가 문자이면 True를 반환하고 그렇지 않으면 False를 반환합니다. |
| isascii () | 문자열의 모든 문자가 ASCII이면 True, 그렇지 않으면 False를 반환합니다 .ASCII 문자 인코딩 범위는 U + 0000 ~ U + 007F이고 빈 문자열도 ASCII입니다. |
| isdecimal () | 문자열에 하나 이상의 문자가 있고 모든 문자가 10 진수이면 True를 반환하고 그렇지 않으면 False를 반환합니다. |
| isdigit () | 문자열에 하나 이상의 문자가 있고 모든 문자가 숫자이면 True를 반환하고 그렇지 않으면 False를 반환합니다. |
| 식별자 () | 문자열이 유효한 Python 식별자이면 True를 반환하고, 그렇지 않으면 False를 반환합니다. keyword.iskeyword (s)를 호출하여 문자열이 예약 된 식별자 (예 : "if"또는 "for")인지 확인합니다. |
| islower () | 문자열에 대소 문자를 구분하는 영어 문자가 하나 이상 포함되어 있고 이러한 문자가 모두 소문자이면 True를 반환하고 그렇지 않으면 False를 반환합니다. |
| isnumeric () | 문자열에 하나 이상의 문자가 있고 모든 문자가 숫자이면 True를 반환하고 그렇지 않으면 False를 반환합니다. |
| 인쇄 가능 () | 문자열이 인쇄 가능하면 True를 반환하고 그렇지 않으면 False를 반환합니다. |
| isspace () | 문자열에 하나 이상의 문자가 있고 모든 문자가 공백이면 True를 반환하고 그렇지 않으면 False를 반환합니다. |
| 목록 () | 문자열이 제목이 지정된 문자열이면 (모든 단어가 대문자로 시작하고 나머지 문자는 소문자) True를 반환하고 그렇지 않으면 False를 반환합니다. |
| isupper () | 문자열에 대소 문자를 구분하는 영어 문자가 하나 이상 포함되어 있고 이러한 문자가 모두 대문자이면 True를 반환하고 그렇지 않으면 False를 반환합니다. |
| join (반복 가능) | 여러 문자열을 연결하고 새 문자열을 반환합니다.이 메서드를 구분 기호로 호출하는 문자열을 사용하여 반복 가능한 매개 변수로 지정된 각 문자열의 중간에 삽입합니다. |
| 밝게 (너비) | 문자가 왼쪽으로 정렬 된 새 문자열을 반환합니다 (너비 <= 문자열 길이, 새 문자열 = 원래 문자열; 너비> 문자열 너비, 모든 문자는 왼쪽 정렬, 오른쪽은 fillchar 매개 변수로 지정된 문자로 채워짐). |
| 보다 낮은() | 모든 영어 문자가 소문자로 변환 된 새 문자열을 반환합니다. |
| lstrip (chars = 없음) | 왼쪽 공백 문자가 제거 된 새 문자열을 반환합니다. chars 매개 변수를 사용하여 제거 할 문자열을 지정할 수 있습니다. |
| 파티션 (9 월) | 문자열에서 sep 매개 변수로 지정된 구분 기호를 검색합니다. 찾으면 3- 튜플 ( 'sep 이전 부분', 'sep', 'sep 이후 부분')을 반환하고, 찾을 수 없으면 ( '원래 문자열 ',', '') |
| removeprefix (접두사) | prefix 매개 변수에 의해 지정된 접두사 하위 문자열이 있으면 접두사가 제거 된 새 문자열을 반환하고, 존재하지 않으면 원래 문자열의 복사본을 반환합니다. |
| removesuffix (suffix) | suffix 매개 변수에 의해 지정된 접미사 하위 문자열이 있으면 접미사가 제거 된 새 문자열을 반환하고, 존재하지 않으면 원래 문자열의 복사본을 반환합니다. |
| 교체 (이전, 새, 개수 = -1) | 返回一个将所有 old 参数指定的子字符串替换为 new 的新字符串;count 参数指定替换的次数,默认是 -1,表示替换全部 |
| rfind(sub[, start[, end]]) | 在字符串中自右向左查找 sub 子字符串,返回匹配的最高索引值;可选参数 start 和 end 用于指定起始和结束位置;如果未能匹配子字符串,返回 -1 |
| rindex(sub[, start[, end]]) | 在字符串中自右向左查找 sub 子字符串,返回匹配的最高索引值;可选参数 start 和 end 用于指定起始和结束位置;如果未能匹配子字符串,抛出 ValueError 异常 |
| rjust(width, fillchar=’ ') | 返回一个字符右对齐的新字符串(width <= 字符串长度,新字符串 = 原字符串;width > 字符串宽度,所有字符右对齐,左侧使用 fillchar 参数指定的字符填充) |
| rpartition(sep) | 在字符串中自右向左搜索sep参数指定的分隔符,如果找到,返回一个 3 元组 (‘在sep前面的部分’, ‘sep’, ‘在sep后面的部分’);如果未找到,则返回 (’’, ‘’, ‘原字符串’) |
| rsplit(sep=None, maxsplit=-1) | 将字符串自右向左进行分割,并将结果以列表的形式返回;sep 参数指定一个字符串作为分隔的依据,默认是任意空白字符;maxsplit 参数用于指定分割的次数(注意:分割 2 次的结果是 3 份),默认是不限制 |
| rstrip(chars=None) | 返回一个去除右侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串 |
| split(sep=None, maxsplit=-1) | 将字符串进行分割,并将结果以列表的形式返回;sep 参数指定一个字符串作为分隔的依据,默认是任意空白字符;maxsplit参数用于指定分割的次数(注意:分割 2 次的结果是 3 份),默认是不限制 |
| splitlines(keepends=False) | 将字符串按行分割,并将结果以列表的形式返回;keepends 参数指定是否包含换行符,True 是包含,False 是不包含 |
| startswith(prefix[, start[, end]]) | 如果存在 prefix 参数指定的前缀子字符串,则返回 True,否则返回 False;可选参数 start 和 end 用于指定起始和结束位置;prefix 参数允许以元组的形式提供多个子字符串 |
| strip(chars=None) | 返回一个去除左右两侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串 |
| swapcase() | 返回一个大小写字母翻转的新字符串 |
| title() | 返回标题化(所有的单词都是以大写开始,其余字母均小写)的字符串。 |
| translate(table) | 返回一个根据 table 参数转换后的新字符串;table 参数应该提供一个转换规则(可以由 str.maketrans(‘a’, ‘b’) 进行定制,例如 “FishC”.translate(str.maketrans(“FC”, “15”)) -> ‘1ish5’) |
| upper() | 返回一个所有英文字母都转换成大写后的新字符串 |
| zfill(width) | 返回一个左侧用 0 填充的新字符串(width <= 字符串长度,新字符串 = 原字符串;width > 字符串宽度,所有字符右对齐,左侧使用 0 进行填充) |
capitalize():将字符串的第一个字符修改为大写,其他字符全部改为小写

casefold() :新字符串的所有字母变为小写

center(width, fillchar=’ ') : 返回一个字符居中的新字符串(width <= 字符串长度,新字符串 = 原字符串;width > 字符串宽度,所有字符居中,左右使用 fillchar 参数指定的字符填充)

count(sub[, start[, end]]): 返回 sub 在字符串中不重叠的出现次数,可选参数 start 和 end 用于指定起始和结束位置

endswith(suffix[, start[, end]]): 如果字符串是以 suffix 指定的子字符串为结尾,那么返回 True,否则返回 False;可选参数 start 和 end 用于指定起始和结束位置

expandtabs([tabsize=8]) :返回一个使用空格替换制表符的新字符串,如果没有指定 tabsize 参数,那么默认 1 个制表符 = 8 个空格

find(sub[, start[, end]]) :在字符串中查找 sub 子字符串,返回匹配的最低索引值;可选参数 start 和 end 用于指定起始和结束位置;如果未能匹配子字符串,返回 -1

index(sub[, start[, end]]) :在字符串中查找 sub 子字符串,返回匹配的最低索引值;可选参数 start 和 end 用于指定起始和结束位置;如果未能匹配子字符串,抛出 ValueError 异常
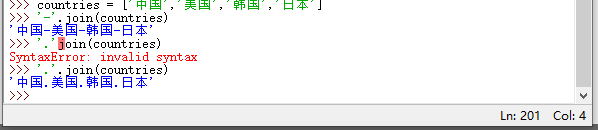
join(iterable) :连接多个字符串并返回一个新字符串;以调用该方法的字符串作为分隔符,插入到 iterable 参数指定的每个字符串的中间;
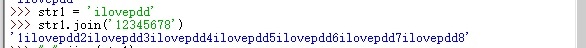
join()方法代替加号来拼接字符串
istitle():如果字符串是标题化字符串(所有的单词都是以大写开始,其余字母均小写)则返回 True,否则返回 False

lstrip(chars=None):返回一个去除左侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串
rstrip(chars=None):返回一个去除右侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串

partition(sep) 在字符串中搜索 sep 参数指定的分隔符,如果找到,返回一个 3 元组 (‘在sep前面的部分’, ‘sep’, ‘在sep后面的部分’);如果未找到,则返回 (‘原字符串’, ‘’, ‘’)
replace(old, new, count=-1) 返回一个将所有 old 参数指定的子字符串替换为 new 的新字符串;count 参数指定替换的次数,默认是 -1,表示替换全部

split(sep=None, maxsplit=-1) 将字符串进行分割,并将结果以列表的形式返回;sep 参数指定一个字符串作为分隔的依据,默认是任意空白字符;maxsplit参数用于指定分割的次数(注意:分割 2 次的结果是 3 份),默认是不限制

strip(chars=None) 返回一个去除左右两侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串


swapcase() 返回一个大小写字母翻转的新字符串

translate(table) 返回一个根据 table 参数转换后的新字符串;table 参数应该提供一个转换规则(可以由 str.maketrans(‘a’, ‘b’) 进行定制,例如 “FishC”.translate(str.maketrans(“FC”, “15”)) -> ‘1ish5’)

Task
0. 还记得如何定义一个跨越多行的字符串吗(请至少写出两种实现的方法)?
【1】三重引号字符串
【2】转义字符\n

【3】
>>> str3 = ('待卿长发及腰,我必凯旋回朝。'
'昔日纵马任逍遥,俱是少年英豪。'
'东都霞色好,西湖烟波渺。'
'执枪血战八方,誓守山河多娇。'
'应有得胜归来日,与卿共度良宵。'
'盼携手终老,愿与子同袍。')
1. 三引号字符串通常我们用于做什么使用?
三引号字符串不赋值的情况下,通常当作跨行注释使用
2. file1 = open ( 'C : \ windows \ temp \ readme.txt', 'r')은 "C : \ windows \ temp \ readme.txt"텍스트 파일을 읽기 전용 모드로 여는 것을 의미하지만 실제로는 이 진술은 오류를보고합니다. 그 이유를 알고 있습니까? 어떻게 수정 하시겠습니까?
"\ T"및 "\ r"는 각각 "수평 탭 (TAB)"및 "캐리지 리턴"을 나타냅니다.
>>> file1 = open(r'C:\windows\temp\readme.txt', 'r')
3. 문자열 : str1 = '<a href="http://www.fishc.com/dvd" target="_blank"> Fish C 리소스 패키징', 하위 문자열을 추출하는 방법 : 'www.fishc. com '
>>> str1 = '<a href="http://www.fishc.com/dvd" target="_blank">鱼C资源打包</a>'
>>> str1[16:29]

4. 슬라이싱 작업의 인덱스 값으로 음수를 사용하면 세 번째 질문에 따라 결과를 시각적으로 정확하게 감지 할 수 있습니까?
>>> str1 = '<a href="http://www.fishc.com/dvd" target="_blank">鱼C资源打包</a>'
>>> str1[-45:-32]

5. 문제 3의 문자열입니다. 아래 문장에 무엇이 표시됩니까?
>>> str1[20:-36]
'fishc'
6. IQ가 150보다 높은 생선 기름 만이 문자열을 잠금 해제 할 수 있다고합니다 (의미있는 문자열로 되돌림). str1 = 'i2sl54ovvvb4e3bferi32s56h; $ c43.sfc67o0cm99'

(잘 모르겠어요 ?????)
7. 암호 보안 검사를위한 코드를 작성하십시오 : check.py (생각 중 ...)
# 密码安全性检查代码
#
# 低级密码要求:
# 1. 密码由单纯的数字或字母组成
# 2. 密码长度小于等于8位
#
# 中级密码要求:
# 1. 密码必须由数字、字母或特殊字符(仅限:~!@#$%^&*()_=-/,.?<>;:[]{}|\)任意两种组合
# 2. 密码长度不能低于8位
#
# 高级密码要求:
# 1. 密码必须由数字、字母及特殊字符(仅限:~!@#$%^&*()_=-/,.?<>;:[]{}|\)三种组合
# 2. 密码只能由字母开头
# 3. 密码长度不能低于16位
