
C, Java, PHP 또는 Golang을 사용하든 인터넷 백엔드 인터페이스를 매일 개발할 때 데이터를 얻기 위해 mysql, redis 및 기타 구성 요소를 호출 할 필요가 없습니다. 또한 일부 rpc 원격을 수행해야 할 수도 있습니다. 다른 편안한 API를 호출하거나 호출하십시오. 이러한 호출의 맨 아래에는 TCP 프로토콜이 기본적으로 전송에 사용됩니다. 이는 전송 계층 프로토콜에서 TCP 프로토콜이 안정적인 연결, 오류 재전송, 혼잡 제어라는 장점이있어 현재 UDP보다 더 널리 사용되고 있기 때문입니다.
TCP에도 몇 가지 단점이 있다는 것을 들어 보셨을 것입니다. 즉, 구식 오버 헤드가 약간 더 큽니다. 그러나 다양한 기술 블로그에서 비용이 크거나 작다고 말하고 특정 정량 분석이 제공되지 않는 경우는 드뭅니다. 천만에요. 영양이 거의없는 말도 안됩니다. 일상적인 일을 생각하고 나서 더 이해하고 싶은 것은 오버 헤드가 얼마인지입니다. TCP 연결 설정을 지연하는 데 시간이 얼마나 걸리나요? 몇 밀리 초 또는 몇 마이크로 초? 대략적인 정량적 추정이 가능합니까? 물론 네트워크 패킷 손실과 같이 TCP의 시간 소비에 영향을 미치는 많은 요소가 있습니다. 오늘날 저는 업무 실습에서 마주 친 다양한 상황의 상대적으로 높은 발생률 만 공유합니다.
정상적인 TCP 연결 설정 프로세스
시간이 많이 걸리는 TCP 연결 설정을 이해하려면 연결 설정 프로세스를 자세히 이해해야합니다. 이전 기사 "Illustrated Linux Network Packet Receiving Process" 에서 데이터 패킷이 수신 측에서 수신되는 방식을 소개했습니다. 데이터 패킷은 발신자에서 나와 네트워크를 통해 수신자의 네트워크 카드에 도달합니다. 수신기 네트워크 카드가 데이터 패킷을 RingBuffer로 DMA 한 후 커널은 하드 인터럽트, 소프트 인터럽트 및 기타 메커니즘을 통해이를 처리합니다 (사용자 데이터가 전송되면 최종적으로 소켓 수신 대기열로 전송되고 사용자 프로세스를 깨 웁니다). .
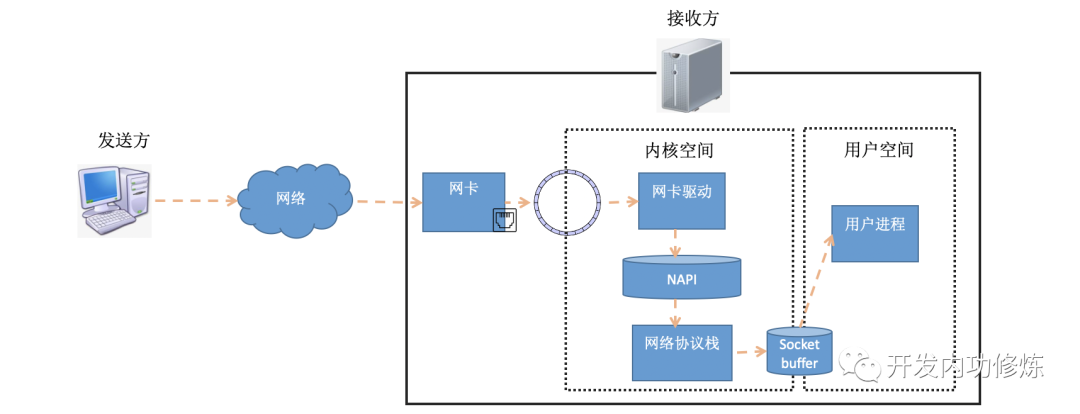
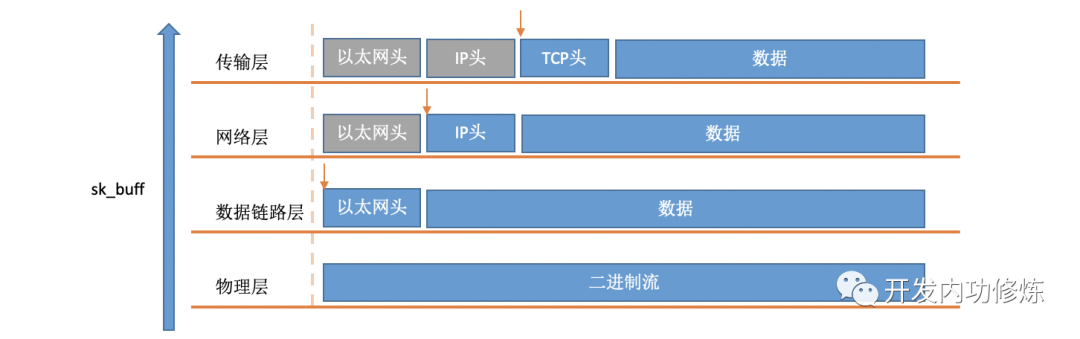
소프트 인터럽트에서 커널이 RingBuffer에서 패킷을 가져 오면 커널의 struct sk_buff구조 로 표시됩니다 (커널 코드 참조 include/linux/skbuff.h). 데이터 멤버는 수신 된 데이터로, 프로토콜 스택을 계층별로 처리 할 때 포인터를 데이터의 다른 위치를 가리 키도록 수정하여 프로토콜의 각 계층이 신경 쓰는 데이터를 찾을 수 있습니다.
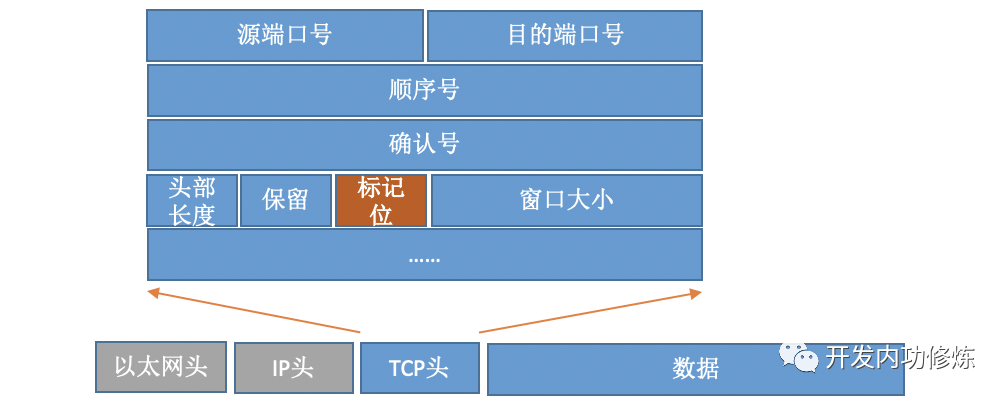
TCP 프로토콜 패킷의 경우 헤더에 중요한 필드 플래그가 있습니다. 아래 그림과 같이:
서로 다른 플래그를 설정함으로써 TCP 패킷은 SYNC, FIN, ACK, RST 및 기타 유형으로 나뉩니다. 클라이언트는 연결 시스템을 사용하여 명령 커널을 호출하여 SYNC, ACK 및 기타 패키지를 전송하여 서버와의 TCP 연결을 설정합니다. 서버 측에서는 많은 연결 요청이 수신 될 수 있으며 커널은 일부 보조 데이터 구조 (반 연결 큐 및 완전 연결 큐)를 사용해야합니다. 전체 연결 프로세스를 살펴 보겠습니다.
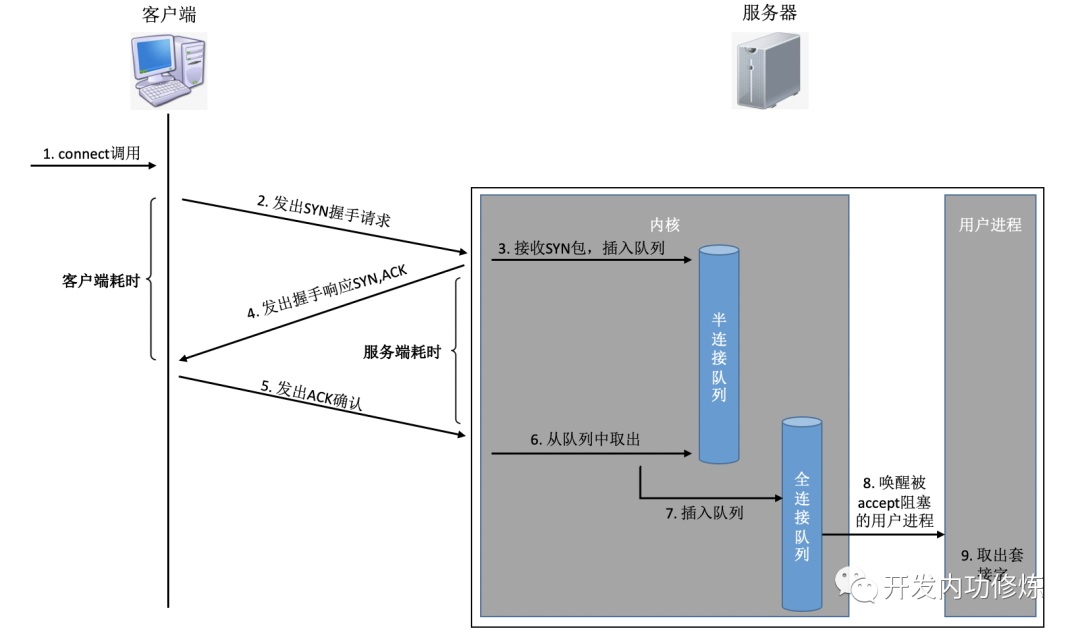
이 연결 과정에서 각 단계에 소요되는 시간을 간단히 분석해 보겠습니다.
클라이언트는 SYNC 패킷을 보냅니다. 클라이언트는 일반적으로 로컬 시스템 호출과 소프트 인터럽트의 CPU 시간 소모적 인 오버 헤드를 포함하는 연결 시스템 호출을 통해 SYN을 보냅니다.
SYN이 서버 로 전송 : 클라이언트의 네트워크 카드에서 SYN이 전송되고 "산과 바다를 건너, 또한 사람의 바다를 통해 ..."시작되는 장거리 네트워크 전송입니다.
서버는 SYN 패킷을 처리합니다. 커널은 소프트 인터럽트를 통해 패킷을 수신 한 다음 세미 연결 대기열에 넣은 다음 SYN / ACK 응답을 보냅니다. CPU 시간 소모적 인 오버 헤드
SYC / ACK가 클라이언트로 전송됩니다. SYC / ACK가 서버에서 전송 된 후 많은 산과 바다를 건너 클라이언트로 전송됩니다. 또 다른 긴 네트워크 여행
클라이언트는 SYN / ACK를 처리합니다. 클라이언트 커널이 패킷을 수신하고 SYN을 처리 한 후 CPU에서 몇 명이 처리 한 다음 ACK를 보냅니다. 소프트 인터럽트 처리 오버 헤드도 마찬가지입니다.
ACK는 서버로 전송 : SYN 패킷과 동일하게 거의 동일한 거리를 통해 다시 전송됩니다. 또 다른 긴 네트워크 여행
서버는 ACK를 수신합니다. 서버 커널은 ACK를 수신하고 처리 한 다음 해당 연결을 반 연결 대기열에서 꺼내 전체 연결 대기열에 넣습니다. 하나의 소프트 인터럽트 CPU 오버 헤드
서버 측 사용자 프로세스 깨우기 : accpet 시스템 호출에 의해 차단 된 사용자 프로세스가 깨어 난 다음 설정된 연결이 전체 연결 대기열에서 가져옵니다. 컨텍스트 전환의 CPU 오버 헤드
위의 단계는 간단히 두 가지 범주로 나눌 수 있습니다.
첫 번째 범주는 커널이 시스템 호출, 소프트 인터럽트 및 컨텍스트 전환을 포함하여 수신, 전송 또는 처리를 위해 CPU를 소비한다는 것입니다. 그들의 시간 소모는 기본적으로 우리 몇 명입니다. 구체적인 분석 과정 은 "시스템 호출의 오버 헤드는 얼마입니까?" 를 참조하십시오. " , "소프트 인터럽트가 얼마나 많은 CPU를 사용합니까? " ", " 프로세스 / 스레드 전환은 CPU를 많이 사용할 수 있습니까? " 이 세 가지 기사.
두 번째 유형은 네트워크 전송으로 기계에서 패킷이 전송되면 다양한 네트워크 케이블과 다양한 스위치 라우터를 통과합니다. 따라서 시간이 많이 걸리는 네트워크 전송은이 시스템의 CPU 처리보다 훨씬 높습니다. 네트워크의 거리에 따라 일반적으로 수 ms에서 수백 ms 사이입니다. .
1ms는 1000us와 같으므로 네트워크 전송 시간은 듀얼 엔드 CPU 오버 헤드보다 약 1000 배 더 높으며 100000 배 더 높을 수도 있습니다. 따라서 일반적인 TCP 연결 설정 과정에서 일반적으로 네트워크 지연을 고려할 수 있습니다. RTT는 한 서버에서 다른 서버로 패킷이 지연되는 시간을 나타냅니다. 따라서 글로벌 관점에서 TCP 연결에 의해 설정된 네트워크는 약 세 번의 전송과 양 당사자 모두에 대해 적은 양의 CPU 오버 헤드를 필요로합니다. 이는 총 RTT의 1.5 배보다 약간 큽니다. 그러나 클라이언트의 관점에서 ACK 패킷이 전송되는 한 커널은 연결이 성공적으로 설정된 것으로 간주합니다. 따라서 클라이언트가 시간이 많이 걸리는 TCP 연결 설정을 계산하는 경우 두 번의 전송 만 필요합니다. 즉, 하나의 RTT가 조금 더 오래 걸립니다. (서버 측의 관점에서도 마찬가지입니다. SYN 패킷 수신 시작부터 ACK 수신까지 중간에 RTT 시간이 많이 소요됩니다.)
2. TCP 접속시 이상 상황
이전 섹션에서 볼 수 있듯이 클라이언트의 관점에서 정상적인 상황에서 TCP 연결에 소비되는 총 시간은 네트워크 RTT가 소비하는 시간에 대한 것입니다. 모든 것이 그렇게 간단하다면 내 공유가 불필요하다고 생각합니다. 상황이 항상 그렇게 아름답지는 않고 항상 사고가있을 것입니다. 경우에 따라 연결 중 네트워크 전송 시간이 증가하거나 CPU 처리 오버 헤드가 증가하거나 연결 실패가 발생할 수 있습니다. 이제 내가 온라인에서 만난 다양한 틈새와 장애물에 대해 이야기 해 봅시다.
1) 클라이언트 연결 시스템 호출에 시간이 걸립니다.
일반적으로 시스템 호출에는 몇 마이크로 초가 걸립니다. 그러나 "서버 CPU를 고갈시킨 살인자 추적!" 이라는 기사에서 저자의 서버는 당시 상황에 직면했습니다. 어떤 운영 및 유지 보수 학생은 서비스 CPU가 충분하지 않아 확장해야한다고 전했습니다. 이때 모니터링되는 서버는 다음과 같습니다.
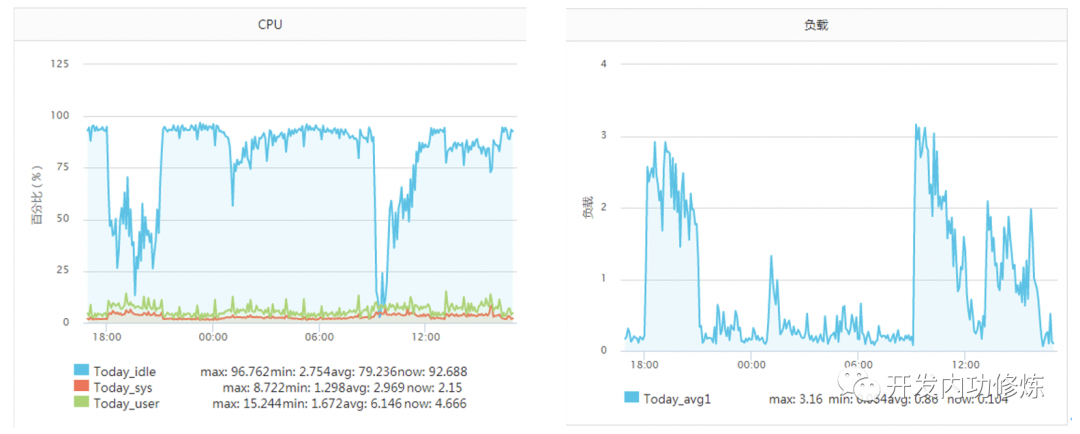
이 서비스는 이전에 초당 약 2000 qps에 대한 내성이 있었으며 CPU의 idel은 항상 70 % 이상이었습니다. 왜 갑자기 CPU가 충분하지 않습니다. 더 이상한 점은 CPU가 바닥에 도달 한 기간 동안로드가 높지 않다는 것입니다 (서버는 4 코어 머신이고로드 3-4는 정상 임). 나중에 조사 결과 TCP 클라이언트 TIME_WAIT가 약 30,000 개가되어 사용 가능한 포트가 부족한 경우 연결 시스템 호출의 CPU 오버 헤드가 직접 100 배 이상 증가하고 시간 소비가 2500us에 도달 한 것으로 확인되었습니다. 마이크로 초) 매번 밀리 초 수준.
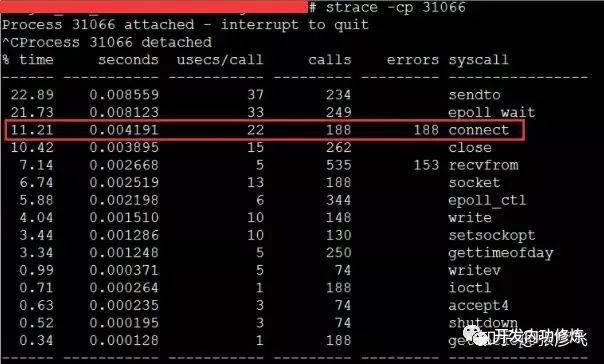
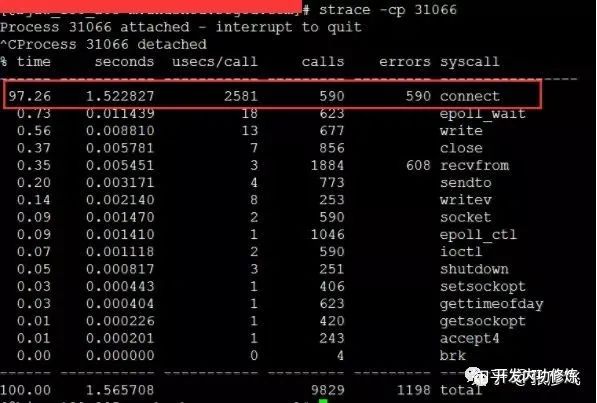
이러한 문제가 발생하면 TCP 연결 설정 시간이 약 2ms 만 증가했지만 전체 TCP 연결 시간은 괜찮은 것처럼 보였습니다. 그러나 여기서 문제는 이러한 2ms의 대부분이 CPU 사이클을 소비하므로 문제가 작지 않다는 것입니다. 해결 방법도 매우 간단하며 여러 가지 방법이 있습니다. 커널 매개 변수 net.ipv4.ip_local_port_range를 수정하여 더 많은 포트 번호를 예약하거나 긴 연결로 전환합니다.
2) 절반 / 전체 연결 대기열이 가득 참
연결 설정 중에 대기열이 가득 차면 클라이언트가 보낸 syn 또는 ack가 삭제됩니다. 클라이언트가 오래 기다린 후 소용이 없으면 TCP 재전송을 보냅니다. 세미 연결 대기열의 예를 살펴 보겠습니다.
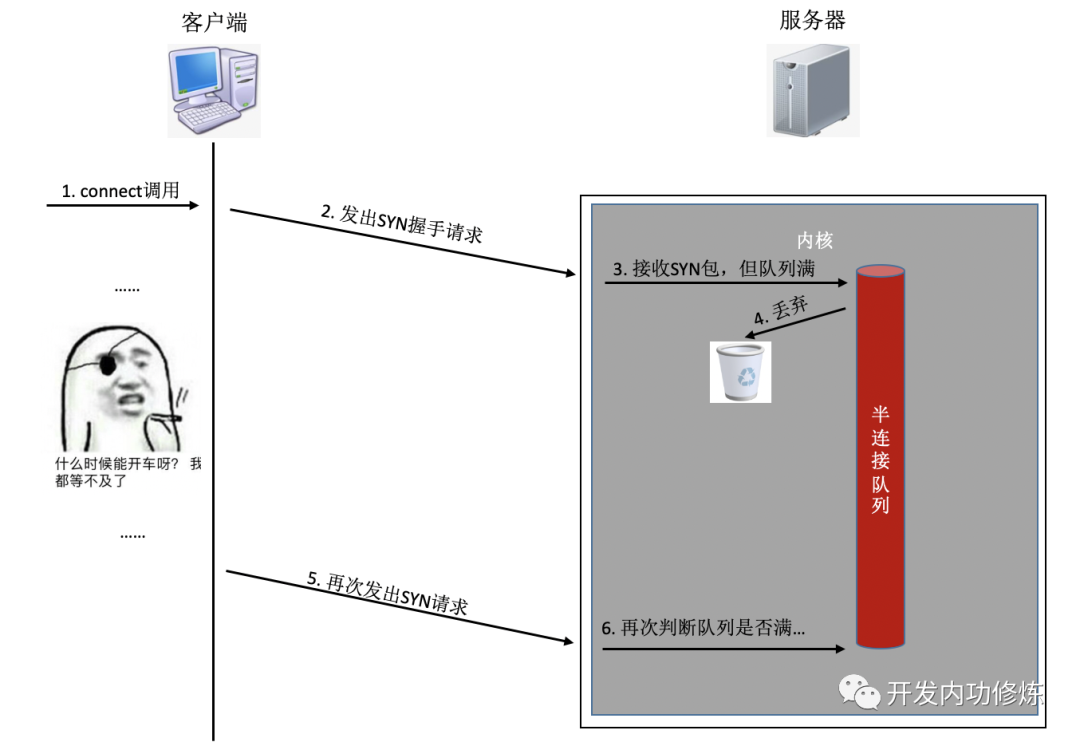
알아야 할 것은 위의 TCP 핸드 셰이크 시간 초과의 재전송 시간이 초 단위라는 것입니다. 즉, 서버 측의 연결 대기열로 인해 연결이 성공적으로 설정되지 않으면 연결을 설정하는 데 최소 몇 초가 걸립니다. 일반적으로 동일한 컴퓨터 실에서 1 밀리 초 미만으로 소요되며 이는 약 1000 배 더 높습니다. 특히 사용자에게 실시간 서비스를 제공하는 프로그램의 경우 사용자 경험에 큰 영향을 미칠 것입니다. 재전송을해도 핸드 셰이크가 성공하지 못하면 사용자가 두 번째 재 시도를 기다릴 수 없으며 사용자 액세스가 직접 시간 초과됩니다.
또 다른 더 나쁜 상황이 있으며 다른 사용자에게도 영향을 미칠 수 있습니다. 프로세스 / 스레드 풀 모델을 사용하여 php-fpm과 같은 서비스를 제공하는 경우. fpm 프로세스가 차단 된 것을 알고 있으며 사용자 요청에 응답 할 때 프로세스는 다른 요청에 응답 할 방법이 없습니다. 100 개의 프로세스 / 스레드를 열었고 일정 시간 내에 50 개의 프로세스 / 스레드가 redis 또는 mysql 서버와의 핸드 셰이크 연결에 멈춰 있다고 가정합니다 ( 참고 : 현재 서버는 TCP 연결의 클라이언트 측입니다 ). . 이 기간 동안 사용할 수있는 정상적인 작업 프로세스 / 스레드는 50 개뿐입니다. 이 50 명의 작업자는 전혀 처리하지 못할 수 있으며 현재 서비스가 혼잡 할 수 있습니다. 조금 더 오래 지속되면 눈사태가 발생할 수 있으며 전체 서비스에 영향을 미칠 수 있습니다.
결과가 너무 심각 할 수 있으므로 절반 / 전체 연결 대기열이 가득 차서 당면한 서비스가 발생했는지 어떻게 확인할 수 있습니까? 클라이언트 측에서는 패킷을 캡처하여 SYN TCP 재전송이 있는지 확인할 수 있습니다. 가끔 TCP 재전송이 발생하는 경우 해당 서버 연결 대기열에 문제가있을 수 있습니다.
서버 측에서는보기가 더 쉽습니다. netstat -s현재 시스템 반 연결 대기열이 가득 차서 발생한 패킷 손실 통계를 볼 수 있지만이 숫자는 손실 된 총 패킷 수를 기록합니다. 동적으로 모니터링 하려면 명령 을 사용해야 watch합니다. 모니터링 중에 아래 숫자가 변경되면 전체 절반 연결 대기열로 인해 현재 서버에서 패킷이 손실되었음을 의미합니다. 세미 연결 대기열의 길이를 늘려야 할 수 있습니다.
$ watch 'netstat -s | grep LISTEN'
8 SYNs to LISTEN sockets ignored완전히 연결된 대기열의 경우보기 방법이 비슷합니다.
$ watch 'netstat -s | grep overflowed'
160 times the listen queue of a socket overflowed대기열이 가득 차서 서비스에서 패킷이 손실되는 경우이를 수행하는 한 가지 방법은 절반 / 전체 연결 대기열의 길이를 늘리는 것입니다. Linux 커널에서 세미 커넥션 큐 길이는 주로 tcp_max_syn_backlog의 영향을받으며 적절한 값으로 늘릴 수 있습니다.
# cat /proc/sys/net/ipv4/tcp_max_syn_backlog
1024
# echo "2048" > /proc/sys/net/ipv4/tcp_max_syn_backlog완전히 연결된 대기열의 길이는 애플리케이션이 listen 및 커널 매개 변수 net.core.somaxconn을 호출 할 때 전달되는 백 로그 중 더 작습니다. 애플리케이션과이 커널 매개 변수를 동시에 조정해야 할 수도 있습니다.
# cat /proc/sys/net/core/somaxconn
128
# echo "256" > /proc/sys/net/core/somaxconn改完之后我们可以通过ss命令输出的Send-Q确认最终生效长度:
$ ss -nlt
Recv-Q Send-Q Local Address:Port Address:Port
0 128 *:80 *:*
Recv-Q告诉了我们当前该进程的全连接队列使用长度情况。如果Recv-Q已经逼近了Send-Q,那么可能不需要等到丢包也应该准备加大你的全连接队列了。
如果加大队列后仍然有非常偶发的队列溢出的话,我们可以暂且容忍。如果仍然有较长时间处理不过来怎么办?另外一个做法就是直接报错,不要让客户端超时等待。例如将Redis、Mysql等后端接口的内核参数tcp_abort_on_overflow为1。如果队列满了,直接发reset给client。告诉后端进程/线程不要痴情地傻等。这时候client会收到错误“connection reset by peer”。牺牲一个用户的访问请求,要比把整个站都搞崩了还是要强的。
三TCP连接耗时实测
我写了一段非常简单的代码,用来在客户端统计每创建一个TCP连接需要消耗多长时间。
<?php
$ip = {服务器ip};
$port = {服务器端口};
$count = 50000;
function buildConnect($ip,$port,$num){
for($i=0;$i<$num;$i++){
$socket = socket_create(AF_INET,SOCK_STREAM,SOL_TCP);
if($socket ==false) {
echo "$ip $port socket_create() 失败的原因是:".socket_strerror(socket_last_error($socket))."\n";
sleep(5);
continue;
}
if(false == socket_connect($socket, $ip, $port)){
echo "$ip $port socket_connect() 失败的原因是:".socket_strerror(socket_last_error($socket))."\n";
sleep(5);
continue;
}
socket_close($socket);
}
}
$t1 = microtime(true);
buildConnect($ip, $port, $count);
echo (($t2-$t1)*1000).'ms';在测试之前,我们需要本机linux可用的端口数充足,如果不够50000个,最好调整充足。
# echo "5000 65000" /proc/sys/net/ipv4/ip_local_port_range
1)正常情况
注意:无论是客户端还是服务器端都不要选择有线上服务在跑的机器,否则你的测试可能会影响正常用户访问
首先我的客户端位于河北怀来的IDC机房内,服务器选择的是公司广东机房的某台机器。执行ping命令得到的延迟大约是37ms,使用上述脚本建立50000次连接后,得到的连接平均耗时也是37ms。这是因为前面我们说过的,对于客户端来看,第三次的握手只要包发送出去,就认为是握手成功了,所以只需要一次RTT、两次传输耗时。虽然这中间还会有客户端和服务端的系统调用开销、软中断开销,但由于它们的开销正常情况下只有几个us(微秒),所以对总的连接建立延时影响不大。
接下来我换了一台目标服务器,该服务器所在机房位于北京。离怀来有一些距离,但是和广东比起来可要近多了。这一次ping出来的RTT是1.6~1.7ms左右,在客户端统计建立50000次连接后算出每条连接耗时是1.64ms。
再做一次实验,这次选中实验的服务器和客户端直接位于同一个机房内,ping延迟在0.2ms~0.3ms左右。跑了以上脚本以后,实验结果是50000 TCP连接总共消耗了11605ms,平均每次需要0.23ms。
线上架构提示:这里看到同机房延迟只有零点几ms,但是跨个距离不远的机房,光TCP握手耗时就涨了4倍。如果再要是跨地区到广东,那就是百倍的耗时差距了。线上部署时,理想的方案是将自己服务依赖的各种mysql、redis等服务和自己部署在同一个地区、同一个机房(再变态一点,甚至可以是甚至是同一个机架)。因为这样包括TCP链接建立啥的各种网络包传输都要快很多。要尽可能避免长途跨地区机房的调用情况出现。
2)连接队列溢出
测试完了跨地区、跨机房和跨机器。这次为了快,直接和本机建立连接结果会咋样呢?Ping本机ip或127.0.0.1的延迟大概是0.02ms,本机ip比其它机器RTT肯定要短。我觉得肯定连接会非常快,嗯实验一下。连续建立5W TCP连接,总时间消耗27154ms,平均每次需要0.54ms左右。嗯!?怎么比跨机器还长很多? 有了前面的理论基础,我们应该想到了,由于本机RTT太短,所以瞬间连接建立请求量很大,就会导致全连接队列或者半连接队列被打满的情况。一旦发生队列满,当时撞上的那个连接请求就得需要3秒+的连接建立延时。所以上面的实验结果中,平均耗时看起来比RTT高很多。
在实验的过程中,我使用tcpdump抓包看到了下面的一幕。原来有少部分握手耗时3s+,原因是半连接队列满了导致客户端等待超时后进行了SYN的重传。

我们又重新改成每500个连接,sleep 1秒。嗯好,终于没有卡的了(或者也可以加大连接队列长度)。结论是本机50000次TCP连接在客户端统计总耗时102399 ms,减去sleep的100秒后,平均每个TCP连接消耗0.048ms。比ping延迟略高一些。这是因为当RTT变的足够小的时候,内核CPU耗时开销就会显现出来了,另外TCP连接要比ping的icmp协议更复杂一些,所以比ping延迟略高0.02ms左右比较正常。
四结论
TCP连接建立异常情况下,可能需要好几秒,一个坏处就是会影响用户体验,甚至导致当前用户访问超时都有可能。另外一个坏处是可能会诱发雪崩。所以当你的服务器使用短连接的方式访问数据的时候,一定要学会要监控你的服务器的连接建立是否有异常状态发生。如果有,学会优化掉它。当然你也可以采用本机内存缓存,或者使用连接池来保持长连接,通过这两种方式直接避免掉TCP握手挥手的各种开销也可以。
게다가 정상적인 상황에서 TCP 설정의 지연은 두 시스템 사이의 RTT 시간 정도이므로 피할 수 없습니다. 그러나 두 머신 간의 물리적 거리를 제어하여이 RTT를 줄일 수 있습니다 (예 : 액세스하려는 redis를 가능한 한 백엔드 인터페이스 머신에 가깝게 배치하여 RTT를 수십 ms에서 다음으로 줄일 수 있음). 가능한 가장 낮은 0. 몇 ms.
마지막으로 베이징에 서버를 배포하면 뉴욕에있는 사용자에게 액세스 권한을 부여 할 수 있습니까? 우리가 같은 컴퓨터 실에 있든 컴퓨터 실에 있든 상관없이 전기 신호 전송에 소요되는 시간은 기본적으로 무시할 수있는 수준이며 (물리적 거리가 매우 가까우므로) 네트워크 지연은 기본적으로 포워딩 장비가 소비하는 시간입니다. 그러나 지구 절반을 통과하면 전기 신호의 전송 시간을 계산할 수 있습니다. 베이징에서 뉴욕까지의 구면 거리는 약 15,000km입니다. 그런 다음 장치의 전달 지연에 관계없이 빛의 속도 만 앞뒤로 이동하며 (RTT는 R 왕복 시간이며 두 번 실행해야 함) 소요 시간 = 15,000,000 * 2 / 광속 = 100ms. 실제 지연은 이보다 클 수 있으며 일반적으로 200ms 이상입니다. 이러한 지연으로 인해 사용자가 액세스 할 수있는 2 단계 서비스를 제공하기가 매우 어렵습니다. 따라서 해외 사용자의 경우 로컬 전산실을 구축하거나 해외 서버를 구입하는 것이 가장 좋습니다.