최근에 "통계 학습 방법"을 읽고 있는데 이론을 먼저 이해할 계획이고, 앞으로는 C ++로 나만의 ml 라이브러리를 구현하는 데 집중할 것입니다. 실제로이 알고리즘은 평상시에는 거의 사용되지 않지만, 그 주된 장점은 적은 수, 수십 또는 수백 개의 샘플에서 매우 잘 수행 될 수 있다는 것입니다. 그러나 수천 개 이상의 데이터가있는 경우이 알고리즘을 사용해 볼 수 있습니다. 결국 더 빨리 실행되어야합니다. 또한 다른 기계 학습 알고리즘에 비해이 확률 모델은 매우 해석 가능하고 간단히 이해하기 쉽습니다. Naive Bayes에는 Gaussian, polynomial 등 여러 가지가 있으며 Brill, log-likelihood function, 신뢰도 곡선과 같은 많은 평가 방법이 있습니다. 결국 Naive Bayes를 조정할 수 있습니다. 따라서 Naive Bayes를 사용하고 싶지만 조정할 것이없는 경우 신뢰도 곡선 보정을 시도 할 수 있습니다. 예기치 않은 놀라움이있을 수 있습니다. 이것을 소개하고 싶지는 않지만 관심이있는 경우 직접 연구 할 수 있습니다. … 말도 안되는 말은하지 말고 시작합시다.
목차
Naive Bayes는 Bayes의 정리 및 특성 조건을 기반으로하는 독립적 인 분류 방법입니다. 주어진 데이터 세트에 대해 입력과 출력의 결합 확률 분포는 먼저 독립적 인 특성 조건의 가정을 기반으로 계산 된 다음이 모델을 기반으로 주어진 입력에 대해 Bayes의 정리를 사용하여 사후 확률 최대화 출력을 찾습니다. . 여기서 설명해야 할 것은 naive Bayes 알고리즘의 전제는 기능이 조건부로 독립적이라는 것입니다. 기능이 서로 관련되어 있으면 알고리즘의 효과가 그리 좋지 않습니다. 동시에 고차원 기능의 경우 베이지안 알고리즘은 매우 적은 데이터로도 잘 수행 할 수 있으며 빠릅니다. PCA 및 기타 차원 감소 기능의 경우 특정 내부 상관 관계도 있으며이 기능은 naive Bayes 알고리즘에 적용되지 않습니다.
I. 개요
Naive Bayes는 레이블과 기능 간의 확률 관계를 직접 측정하는지도 학습 알고리즘이며 분류에 초점을 맞춘 알고리즘입니다. Naive Bayes 알고리즘의 뿌리는 확률 이론과 수학적 통계를 기반으로 한 베이지안 이론이므로 Masamiao Hong의 확률 모델에 뿌리를두고 있습니다. 다음으로이 간단하고 빠른 확률 알고리즘에 대해 알아 보겠습니다.
Naive Bayes는 가장 간단한 분류 알고리즘 중 하나로 간주됩니다. 첫째, 확률 이론의 몇 가지 기본 이론을 이해해야합니다. 두 개의 랜덤 변수 X와 Y가 있다고 가정하면 각각 x와 y 값을 가질 수 있습니다. 이 두 가지 랜덤 변수를 사용하여 두 가지 확률을 정의 할 수 있습니다.
| 주요 개념 : 공동 확률 및 조건부 확률 |
| 결합 확률 : X는 x와 Y가 동시에 발생할 확률 이며 다음과 같이 표현됩니다. P (X = x, Y = y) |
| 조건부 확률 : X가 x의 값을 취하는 조건에서 Y가 y의 값을 취할 확률 , 다음과 같이 표현됨 : P (Y = y | X = x) |
예를 들어 X를 "온도"로, Y를 "무당 벌레 동면"으로 설정하면 X와 Y의 가능한 값은 x와 y로 나뉩니다. 여기서 x = {0,1}, 0은 0도 이하로 떨어지지 않음, 1은 0도 이하로 떨어졌음을 의미합니다. y = {0,1}, 여기서 0은 아니오를 의미하고 1은 예를 의미합니다. 두 이벤트가 개별적으로 발생할 확률은 다음과 같습니다.
- P (X = 1) = 50 %, 온도가 0도 이하로 떨어질 가능성이 50 %이므로 P (X = 0) = 50 %입니다.
- P (Y = 1) = 70 %, Coccinella septempunctata가 동면 할 확률이 70 %이므로 P (Y = 0) = 30 %입니다.
그러면이 두 사건의 합동 확률은 P (X = 1, Y = 1)이고,이 확률은 온도가 0도 이하로 떨어지고 무당 벌레가 동면 상태가 될 때 두 사건이 동시에 독립적으로 발생할 확률을 나타냅니다.
두 사건 사이의 조건부 확률은 P (Y = 1 | X = 1)이며,이 확률은 온도가 0도 아래로 떨어질 때 조건이 충족 될 때 무당 벌레가 최대 절전 모드로 들어갈 확률을 나타냅니다. 다시 말해, 온도가 0도 이하로 떨어지면서 무당 벌레가 최대 절전 모드에 들어가는 이벤트에 어느 정도 영향을 미쳤습니다. 확률 이론에서 우리는 두 사건의 합동 확률이이 두 사건의 임의의 조건부 확률 * 조건부 사건 자체의 확률과 같다는 것을 증명할 수 있습니다.
더 간단하게 위의 공식을 다음과 같이 작성할 수 있습니다.
![]()
위의 공식에서 베이지안 이론 방정식을 얻을 수 있습니다.
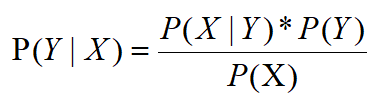
그리고이 공식은 모든 베이지안 알고리즘의 근본 이론입니다. 특성 X를 조건부 이벤트로 간주 할 수 있으며, 조건이 충족 된 후 영향을받을 결과로 해결해야하는 레이블 Y는 P (Y | X)입니다.이 확률 기계 학습에서 레이블의 사후 확률이라고합니다. 즉, 먼저 조건을 알고 결과를 해결합니다. 레이블 Y가 아무런 제한없이 특정 값을 가질 확률은 P (Y)로 작성되며, 이는 완전히 제한이없는 사후 확률과 반대입니다. 레이블의 사전 확률 (사전 확률). 그리고 우리의 P (X | Y)는 "클래스의 조건부 확률"이라고 불리며, Y 값이 고정 될 때 X가 특정 값일 확률을 나타냅니다. 이제 흥미로운 것들이 나타났습니다.
둘째, Naive Bayes의 학습 및 분류
출력 클래스의 레이블이 y = {c1, c2, .. ck}이고 입력 특성이 X이고 훈련 데이터 세트가 T = {(X1, y1), (X2, y2), ...라고 가정합니다. , (Xn, yn)}, 조건부 확률 분포 :
![]()
Bayes 정리의 경우 Naive Bayes가 조건부 확률 분포에 대해 조건부 독립 가정을하기 때문에 분자 P (X | Y)를 얻습니다 (이것은 Naive Bayes 방법의 기원이기도합니다). 따라서 조건부 독립 가정에 따라 다음과 같이 작성할 수 있습니다.

Bayes의 정리 점수 어머니 P (X)의 경우 전체 확률 공식을 사용하여 P (X)를 계산할 수 있습니다.
![]()
따라서 순진 베이지안 분류를 할 때 주어진 입력 x에 대해 학습을 통해 얻은 모델을 통해 사후 확률 분포 P (Y = ck | X = x)를 계산하고 사후 확률이 가장 큰 클래스를 다음 클래스로 출력합니다. x. 사후 확률 계산은 Bayes의 정리에 따라 수행됩니다.
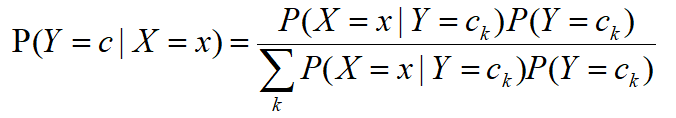
조건부 독립 가정 가져 오기 :
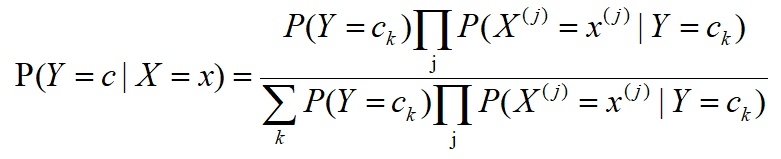
그런 다음 베이지안 분류기는 다음과 같이 표현할 수 있습니다.
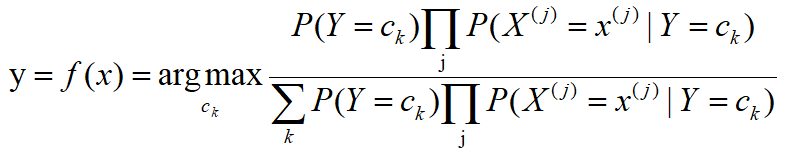
이 공식의 경우 훈련 세트에서 P (Y = ck)를 풀기는 쉽지만 P (X) 및 P (X | Y)의이 부분은 그렇게 쉽지 않습니다. 이 예에서는 전체 확률 공식을 사용하여 분모를 풀고 두 가지 특성에 대해 네 가지 확률을 풉니 다. 특성의 수가 점차 증가함에 따라 분모에 대한 계산이 기하 급수적으로 증가하고 분자의 P (X | Y)를 계산하기가 점점 더 어려워집니다.
실제로 분류를 계산할 때 두 범주를 비교할 때 두 확률 계산의 분모가 동일하므로 분모를 계산할 필요가없고 분자 크기 만 고려합니다. 분자의 크기를 개별적으로 계산 한 후에는 두 개의 분자를 더하여 분모의 값을 구할 수 있으므로 표본의 모든 특성에 대한 확률 계산을 방지 할 수 있습니다. 이 과정을 "최대 사후 추정"(MAP)이라고합니다. 최대 사후 추정에서는 주로 표본 아래의 각 특성 값의 확률을 풀고 곱하여 해당 확률을 얻기 위해 분자를 풀면됩니다.
여기에서 먼저 예제를보고 그것을 읽은 후에 그것을 분류하는 방법을 이해할 것입니다.
| 인덱스 |
온도 (X1) |
무당 벌레 시대 (X2) |
무당 벌레 동면 (Y) |
| 0 |
영하 |
10 일 |
예 |
| 1 |
영하 |
20 일 |
예 |
| 2 |
제로 |
10 일 |
아니 |
| 삼 |
영하 |
한 달 |
예 |
| 4 |
영하 |
20 일 |
아니 |
| 5 |
제로 |
이 개월 |
아니 |
| 6 |
영하 |
한 달 |
아니 |
| 7 |
영하 |
이 개월 |
예 |
| 8 |
제로 |
한 달 |
아니 |
| 9 |
제로 |
10 일 |
아니 |
| 10 |
영하 |
20 일 |
아니 |
이때 20 일령 무당 벌레가 0 미만일 때 동면 할 것인지 예측하고자 합니다.

분자의 경우 다음을 찾을 수 있습니다.
![]()
분모의 경우 다음을 찾을 수 있습니다.
![]()
임계 값은 0.5로 설정됩니다. 0.5보다 크면 최대 절전 모드로 간주되고 0.5보다 작 으면 최대 절전 모드가 아닌 것으로 간주됩니다. 우리의 계산에 따르면, 우리는 영하의 조건에서 20 일령의 무당 벌레가 동면하지 않을 것이라고 믿습니다. 이것으로 예측이 완료됩니다.
셋째, naive Bayes 방법의 모수 추정
이전 섹션에서 볼 수 있듯이 나이브 베이 즈 추정을 수행하려면 P (Y) 및 P (X | Y)를 계산해야합니다. 해당 확률은 최대 가능성을 사용하여 추정 할 수 있습니다. 사전 확률 P (Y = ck)의 최대 가능도 추정치는 다음과 같습니다.
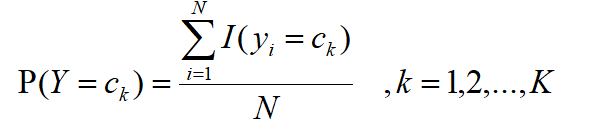
즉, 전체 샘플 수에 대한 Ck의 비율로 샘플 레이블을 직접 계산하여 P (Y)의 확률 분포를 얻을 수 있습니다.
j 번째 특성 xj의 가능한 값 집합이 {aj1, aj2, ..., ajn}이라고 가정하면 조건부 확률 P (Xj = ajl | Y = ck)의 최대 가능성 추정값은 다음과 같습니다.

공식에서 Xij는 i 번째 샘플의 j 번째 특성이고, ajl은 j 번째 특성의 가능한 값의 l 번째 값이고, I ()는 인디케이터 함수입니다.
위의 공식을 통해 조건부 확률 함수 P (Xj = ajl | Y = ck)를 계산하면 실제로 Y = ck 레이블 아래에서 특정 특성의 고유 값이 ajl의 비율과 동일 함을 알 수 있습니다.
3.1, 나이브 베이 즈 알고리즘
입력 : 훈련 데이터 세트![]()
출력 : 인스턴스 x의 분류
- 사전 확률 및 조건부 확률 계산
Priori 확률 :
조건부 확률 :
- 주어진 인스턴스 x = (x1, x2, ... xn) 계산
![]()
- 카테고리 결정
![]()
4. 베이 즈 탐색 : 베이지안 샘플의 불균형
CNB (Complement Naive Bayes) 알고리즘은 표준 다항식 naive Bayes 알고리즘을 개선 한 것입니다. CNB의 발명 팀이 CNB를 만들려는 원래 의도는 베이지안의 "순진한"가정으로 인해 발생하는 다양한 문제를 해결하는 것이 었습니다. 그들은 Naive Bayes의 순진한 가정에서 벗어나는 수학적 방법을 만들려고합니다. 따라서 알고리즘이 모든 기능은 조건부로 독립적입니다. 이를 바탕으로 그들은 표본 불균형 문제를 해결하고 어느 정도 순진한 가설을 무시할 수있는 보완적인 순진 베이 즈를 만들었습니다. 실험에서 CNB의 매개 변수 추정은 일반 다항식 나이브 베이 즈보다 더 안정적인 것으로 입증되었으며 특히 불균형 샘플이있는 데이터 세트에 적합합니다. 때로는 텍스트 분류 작업에 대한 CNB의 성능이 다항식 naive Bayes보다 더 좋을 수 있으므로 이제 naive Bayes의 보완도 인기를 얻기 시작했습니다. Complementary Naive Bayes가 우리의 순진한 가설을 회피하는 방법이나 샘플 불균형 문제를 개선하는 방법에 관해서는 심오한 수학적 원리와 복잡한 수학적 증명이 있습니다. 관심이 있으시면이 논문을 참조하십시오.
간단히 말해서 CNB는 각 태그 카테고리의 보완에서 얻은 확률을 사용하여 각 기능의 가중치를 계산합니다.

여기서 j는 각 샘플을 나타내고 xij는 샘플에서 특성 i의 더 낮은 값을 나타내며, 일반적으로 텍스트 분류의 개수 값 또는 TF-IDF 값입니다. a는 표준 다항식 나이브 베이 즈에서와 같은 평활 계수입니다. 겉보기에 복잡해 보이는이 공식은 실제로 매우 간단하다는 것을 알 수 있습니다. ![]() 사실 라벨 카테고리가 특성 i의 c 값과 같지 않은 모든 샘플의 특성 값의 합계를 나타냅니다. 그리고
사실 라벨 카테고리가 특성 i의 c 값과 같지 않은 모든 샘플의 특성 값의 합계를 나타냅니다. 그리고 ![]() 사실, 모든 기능은 모든 태그 카테고리 기능과 가치의 샘플 C의 가치가 동일하지 않습니다. 사실, 그것은 다항 분포의 역 아이디어입니다.
사실, 모든 기능은 모든 태그 카테고리 기능과 가치의 샘플 C의 가치가 동일하지 않습니다. 사실, 그것은 다항 분포의 역 아이디어입니다.
참조 :