사전 가져오기
이전에 SSMP 통합을 할 때 데이터 레이어 솔루션에는 MySQL 데이터베이스와 MyBatisPlus 프레임워크가 포함되었고 이후에는 Druid 데이터 소스 구성이 포함되었으므로 이제 데이터 레이어 솔루션은 Mysql+Druid+MyBatisPlus라고 할 수 있습니다. 세 가지 기술은 세 가지 수준의 데이터 계층 작업에 해당합니다.
- 데이터 소스 기술: Druid
- 지속성 기술: MyBatisPlus
- 데이터베이스 기술: MySQL
다음의 연구는 3단계로 나누어 연구를 진행하는데, 위의 3가지 측면에 해당하여 첫 번째 데이터 소스 기술부터 시작해보자.
데이터 소스 기술
현재 우리가 사용하는 데이터 소스 기술은 Druid이며 해당 데이터 소스 초기화 정보는 다음과 같이 런타임 시 로그에서 볼 수 있습니다.
INFO 28600 --- [ main] c.a.d.s.b.a.DruidDataSourceAutoConfigure : Init DruidDataSource
INFO 28600 --- [ main] com.alibaba.druid.pool.DruidDataSource : {dataSource-1} inited
Druid 데이터 소스를 사용하지 않는 경우 실행 후 프로그램은 어떻게 되나요? 독립적인 데이터베이스 연결 개체입니까, 아니면 다른 연결 풀링 기술에서 지원합니까? Druid 기술에 해당하는 스타터를 제거하고 프로그램을 다시 실행하여 로그에서 다음 초기화 정보를 찾습니다.
INFO 31820 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting...
INFO 31820 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed.
DruidDataSource와 관련된 정보는 없지만 로그에 HikariDataSource에 대한 정보가 있음을 확인했습니다.이 기술이 무엇인지 모르더라도 이름을 보면 알 수 있습니다. DataSource로 끝나는 이름은 반드시 데이터 소스 기술이 됩니다. 우리는 이 기술을 수동으로 추가하지 않았습니다. 이 기술은 어디에서 왔습니까? 이것은 springboot 임베디드 데이터 소스입니다.
데이터 계층 기술은 데이터베이스 연결 관리를 수행해야 하는 모든 엔터프라이즈급 애플리케이션에서 사용됩니다. Springboot는 개발자의 습관에 기초하고 있습니다.개발자는 데이터 소스 기술을 제공하고 당신이 제공하는 것을 사용하지만 개발자는 그것을 제공하지 않습니다.그렇다면 각 데이터베이스 연결 개체를 수동으로 관리 할 수 없습니다.어떻게해야합니까? 나는 당신에게 걱정과 수고를 덜어주고 모두에게 편리한 기본 값을 줄 것입니다.
springboot는 다음과 같이 3가지 임베디드 데이터 소스 기술을 제공합니다.
- 히카리CP
- Tomcat은 DataSource를 제공합니다.
- 커먼즈 DBCP
첫 번째는 Springboot에서 공식적으로 권장하는 데이터 소스 기술인 HikartCP입니다.기본 내장 데이터 소스로 사용. 무슨 뜻이에요? 데이터 소스를 구성하지 않은 경우 이를 사용하십시오.
두 번째, Tomcat에서 제공하는 DataSource,HikartCP를 사용하지 않고 웹 프로그램 개발을 위한 웹 서버로 tomcat을 사용하고 싶지 않다면 다음을 사용하십시오.. 왜 다른 웹 서버가 아닌 Tomcat입니까? 웹 기술을 스타터로 가져온 후 기본적으로 내장된 tomcat을 사용하기 때문에 기본적으로 사용되는 기술이므로 끝까지 사용하고 데이터 소스도 사용합니다. 누군가 Tomcat과 함께 HikartCP에서 제공하는 기본 데이터 소스 개체를 사용하지 않는 방법을 제안했습니까? HikartCP 기술의 좌표는 제외해도 됩니다.
세 번째 유형인 DBCP는 이 사용 조건이 더욱 가혹합니다.HikartCP나 tomcat의 DataSource가 모두 사용되지 않으면 이것이 기본적으로 사용됩니다..
Springboot의 고민도 깨졌습니다. 연결 객체를 스스로 관리할 수 없을까 두렵습니다. 추천해 드리겠습니다. 정말 개발 세계에서 가장 강력한 조수입니다. 그들이 당신에게 우유를 주었기 때문에 그것을 사용할 수 있습니다. 이것들을 구성하고 사용하는 방법은 무엇입니까? 이전에 druid를 구성했을 때 druid의 스타터에 해당하는 구성은 다음과 같습니다.
spring:
datasource:
druid:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: ************
기본 데이터 소스인 HikariCP로 변경한 후 다음과 같이 druid를 삭제하면 됩니다.
참고: 이 곳은 Druid 스타터도 삭제해야 합니다.
spring:
datasource:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: *****************
물론 hikari에 대한 설정을 작성할 수도 있지만, url 주소는 별도로 다음과 같이 설정해야 합니다(즉, 다른 작성 방식).
spring:
datasource:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
hikari:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: *************
이것이 hikari 데이터 소스가 구성되는 방식입니다. hikari를 추가로 구성하려면 해당 독립 속성을 계속 구성할 수 있습니다. 예:
spring:
datasource:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
hikari:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: **************
maximum-pool-size: 50
hikari 데이터 소스를 사용하지 않으려면 tomcat 데이터 소스를 사용하거나 DBCP 구성 형식이 동일합니다. 미래에 데이터 계층을 수행할 때 데이터 원본 개체의 선택은 더 이상 druid 데이터 원본 기술의 단일 사용이 아니며 필요에 따라 선택할 수 있습니다.
요약하다
- springboot 기술은 3가지 내장 데이터 소스 기술, 즉 Hikari, tomcat 내장 데이터 소스, DBCP를 제공합니다.
지속성 기술
데이터 소스 솔루션에 대해 이야기한 후 지속성 솔루션에 대해 이야기해 보겠습니다. Springboot는 가장 강력한 보조 기능을 최대한 활용하고 개발자에게 JdbcTemplate이라는 기성 데이터 계층 기술 세트를 제공합니다. 사실 이 기술은 springboot 기술을 사용하지 않고도 사용할 수 있기 때문에 springboot에서 제공한다고 할 수 없습니다. 스프링 기술로 제공되는 것이므로 스프링부트 기술의 범주에 이 기술도 존재한다 결국 스프링부트 기술은 스프링 프로그램의 개발을 가속화하기 위해 만들어진 것이다.
이 기술은 실제로 데이터 계층 개발을 위한 가장 원시적인 jdbc 프로그래밍 형식으로 돌아가 다음 단계를 직접 수행합니다.
1단계 : jdbc에 해당하는 좌표 가져오기, 스타터 기억
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
2단계 : JdbcTemplate 객체 자동 어셈블
@SpringBootTest
class Springboot15SqlApplicationTests {
@Test
void testJdbcTemplate(@Autowired JdbcTemplate jdbcTemplate){
}
}
3단계 : JdbcTemplate을 사용하여 쿼리 작업 구현(엔티티가 아닌 클래스로 캡슐화된 데이터에 대한 쿼리 작업)
@Test
void testJdbcTemplate(@Autowired JdbcTemplate jdbcTemplate){
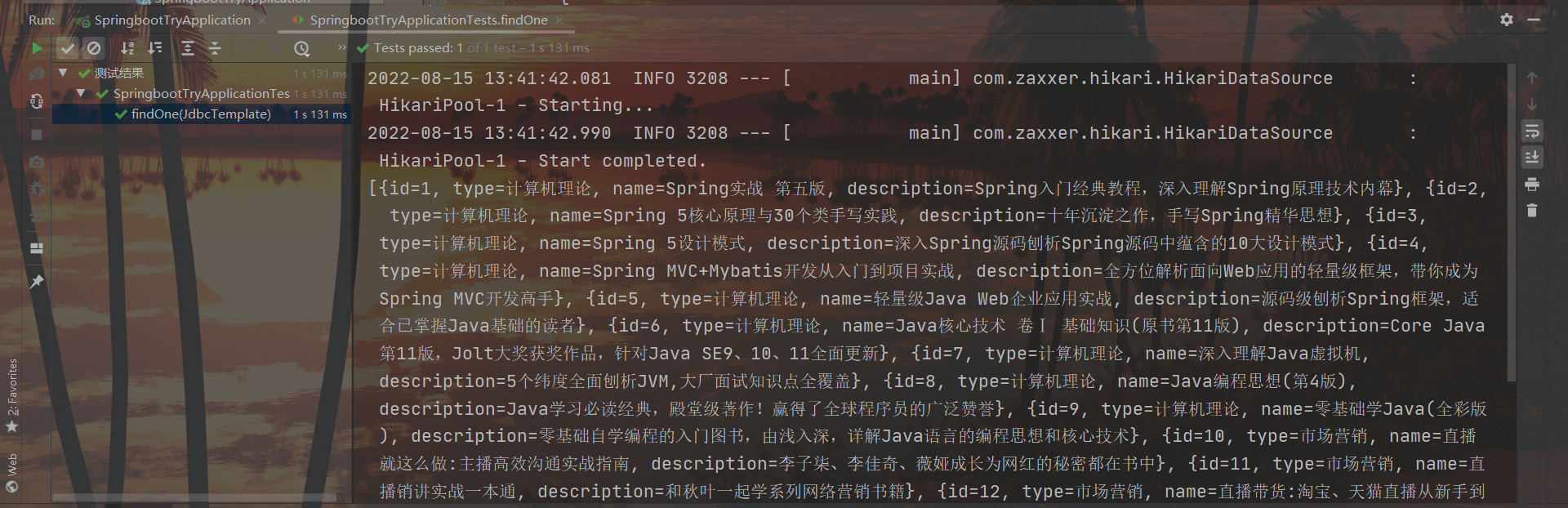
String sql = "select * from tbl_book";
List<Map<String, Object>> maps = jdbcTemplate.queryForList(sql);
System.out.println(maps);
}
결과:
4단계 : JdbcTemplate을 사용하여 쿼리 작업 구현(엔티티 클래스는 데이터 쿼리 작업을 캡슐화함)
@Test
void testJdbcTemplate(@Autowired JdbcTemplate jdbcTemplate){
String sql = "select * from tbl_book";
RowMapper<Book> rm = new RowMapper<Book>() {
@Override
public Book mapRow(ResultSet rs, int rowNum) throws SQLException {
Book temp = new Book();
temp.setId(rs.getInt("id"));
temp.setName(rs.getString("name"));
temp.setType(rs.getString("type"));
temp.setDescription(rs.getString("description"));
return temp;
}
};
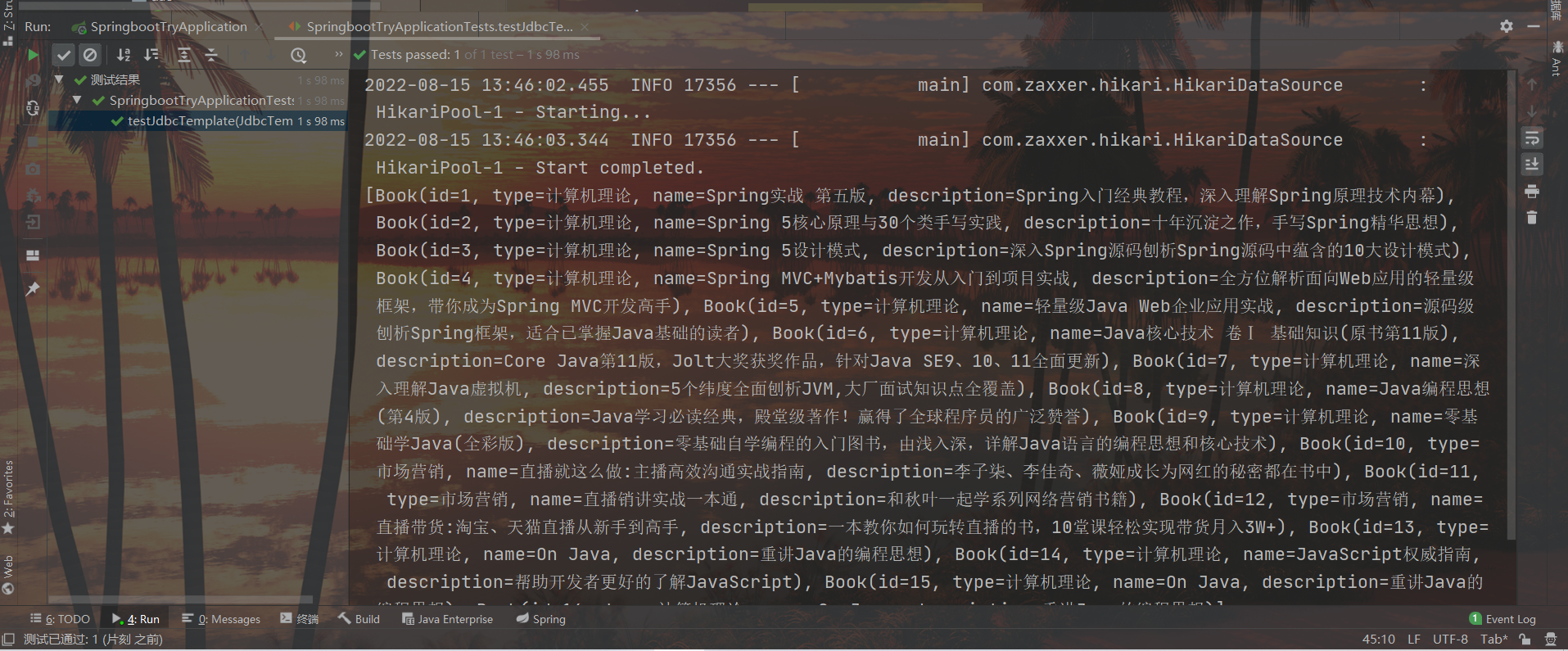
List<Book> list = jdbcTemplate.query(sql, rm);
System.out.println(list);
}
결과:
⑤ 단계 : JdbcTemplate을 사용하여 추가, 삭제 및 수정 작업 구현
@Test
void testJdbcTemplateSave(@Autowired JdbcTemplate jdbcTemplate){
String sql = "insert into tbl_book values(3,'springboot1','springboot2','springboot3')";
jdbcTemplate.update(sql);
}
JdbcTemplate 객체를 설정하고 싶다면 yml 파일에서 다음과 같이 설정하면 됩니다.
spring:
jdbc:
template:
query-timeout: -1 # 查询超时时间
max-rows: 500 # 最大行数
fetch-size: -1 # 缓存行数
fetch-size쿼리 성능을 향상시킬 수 있습니다. 예를 들어, 지금 우리는 10,000개의 데이터를 확인합니다. 한 번에 몇 개의 데이터가 제공됩니까? 이것은 에 의해 제어될 수fetch-size있습니다 . 한 번에 50개를 주고 이 50개도 사용하면 효율성이 매우 높아집니다. 그리고 50개 이상 사용하면 다시 오고 효율이 떨어집니다.
요약하다
- SpringBoot 내장 JdbcTemplate 지속성 솔루션
- JdbcTemplate을 사용하면 spring-boot-starter-jdbc의 좌표를 가져와야 합니다.
데이터베이스 기술
지금까지 springboot는 개발자들에게 내장형 데이터 소스 솔루션과 퍼시스턴스 솔루션을 제공해 왔는데, 3피스 데이터 레이어 솔루션에 하나의 데이터베이스가 남았는데, springboot도 내장형 솔루션을 제공하는 것은 아닐까요? 하나가 아니라 셋이다.
springboot는 다음과 같은 3가지 내장 데이터베이스를 제공합니다.
- H2
- HSQL
- 더비
위 의 세 데이터베이스를 독립적으로 설치하는 것 외에도 spirngboot 컨테이너에서 tomcat 서버와 같은 임베디드 형태로 실행할 수도 있습니다 . 실행하려면 컨테이너에 포함되어야 하며 Java 개체여야 합니다. 예, 이 세 데이터베이스의 맨 아래 계층은 Java 언어를 사용하여 개발되었습니다.
우리는 항상 MySQL 데이터베이스를 사용하고 있는데 이것을 사용해야 하는 이유는 무엇입니까?그 이유는 이 3개의 데이터베이스를 Embedded Container의 형태로 구동할 수 있기 때문이며, 애플리케이션이 실행된 후 테스트 작업을 수행하면 테스트 중인 데이터를 디스크에 저장할 필요가 없지만 편리하고 메모리에서 실행됩니다., 테스트할 시간이고 실행할 시간이며 서버가 종료되면 모든 것이 사라지므로 외부 데이터베이스를 유지 관리하지 않아도 됩니다. 기능 테스트에 편리한 내장형 데이터베이스의 가장 큰 장점이기도 하다.
다음은 이러한 임베디드 데이터베이스를 사용하는 방법을 설명하기 위해 H2 데이터베이스를 예로 들어 설명합니다. 작업 단계도 매우 간단합니다. Simple은 사용하기 쉽습니다.
1단계 : H2 데이터베이스에 해당하는 좌표 가져오기, 총 2개
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
2단계 : 프로젝트를 웹 프로젝트로 설정하고 프로젝트 시작 시 H2 데이터베이스 시작
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
③ 단계 : 구성을 통해 H2 데이터베이스 콘솔 액세스 프로그램을 열거나 다른 데이터베이스 연결 소프트웨어를 사용하여 작동
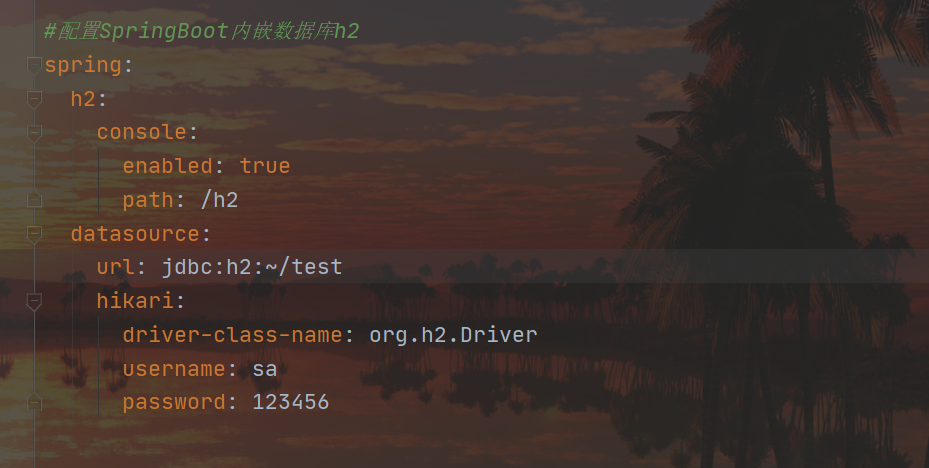
spring:
h2:
console:
enabled: true
path: /h2
그런 다음 서버를 시작하고 localhost/h2에 액세스합니다(포트는 미리 80으로 설정되어 있음)
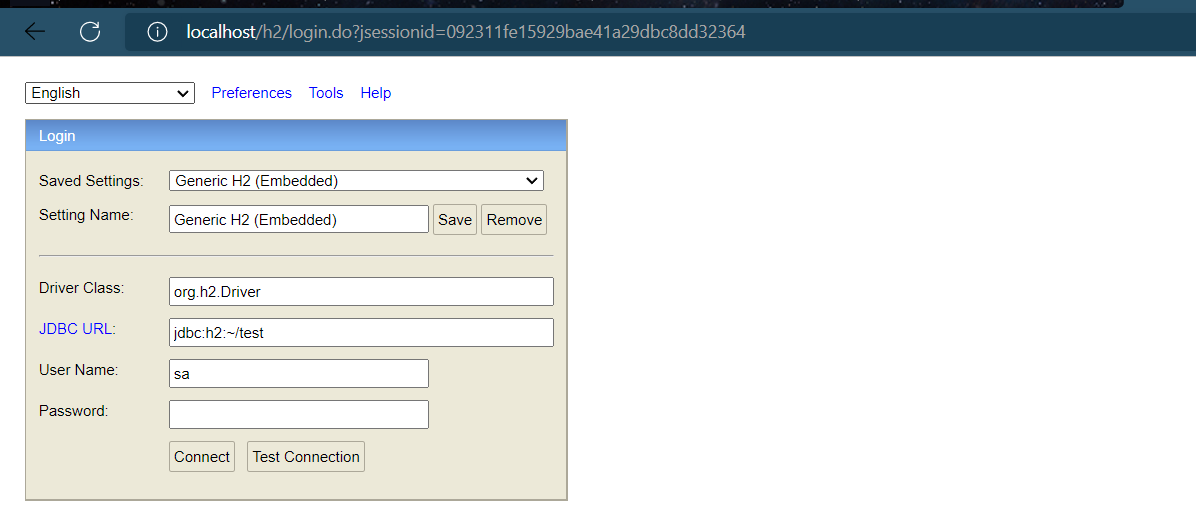
. 데이터 소스 먼저 시작 프로그램이 실행된 후 /h2 경로에 다시 액세스하면 정상적으로 액세스할 수 있습니다(접근에 성공하면 다음 내용을 제거할 수도 있음)
datasource:
url: jdbc:h2:~/test
hikari:
driver-class-name: org.h2.Driver
username: sa
password: 123456
그런 다음 다음 웹 페이지를 입력했습니다.
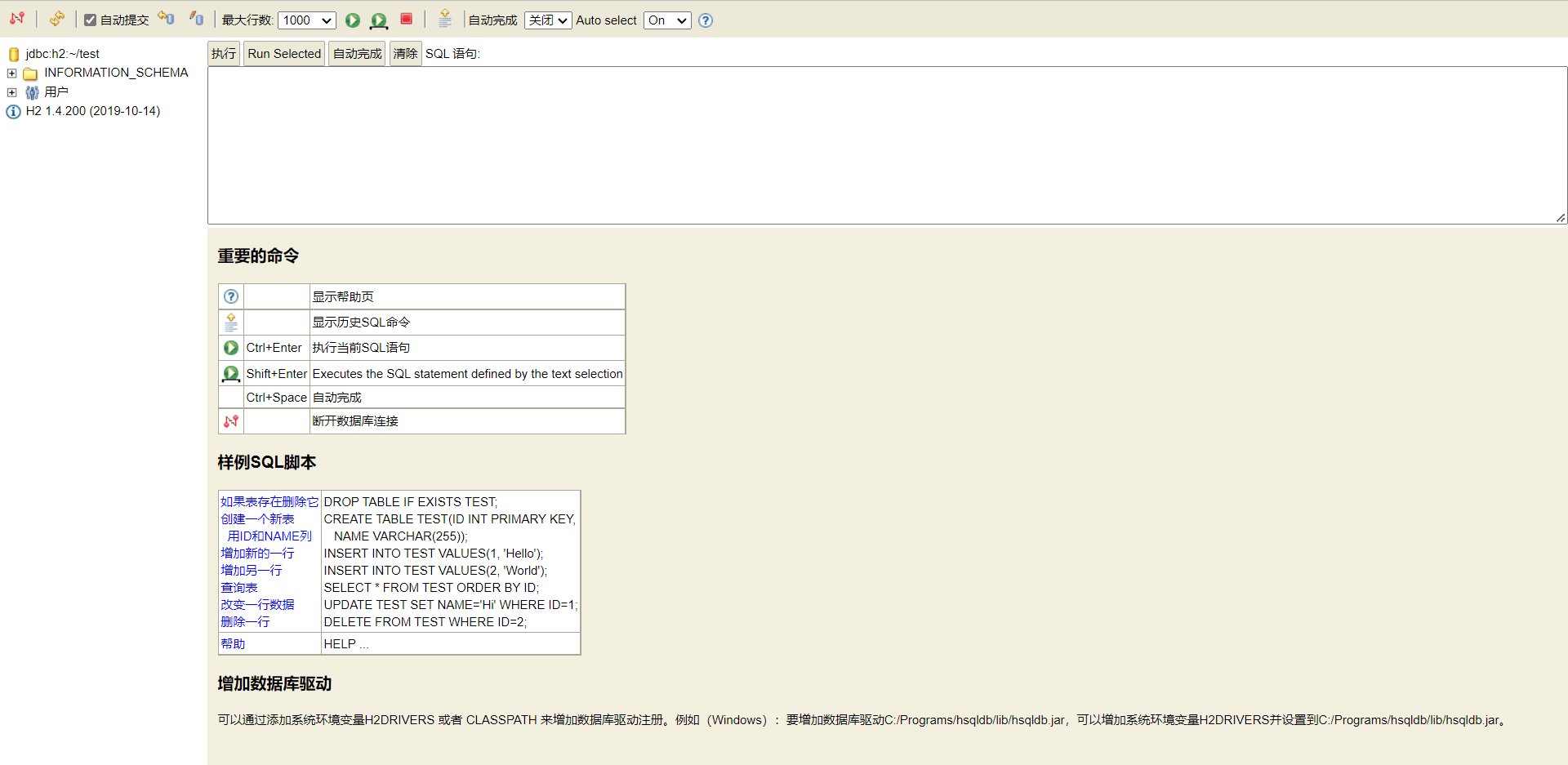
먼저 테이블을 만들 수 있습니다.
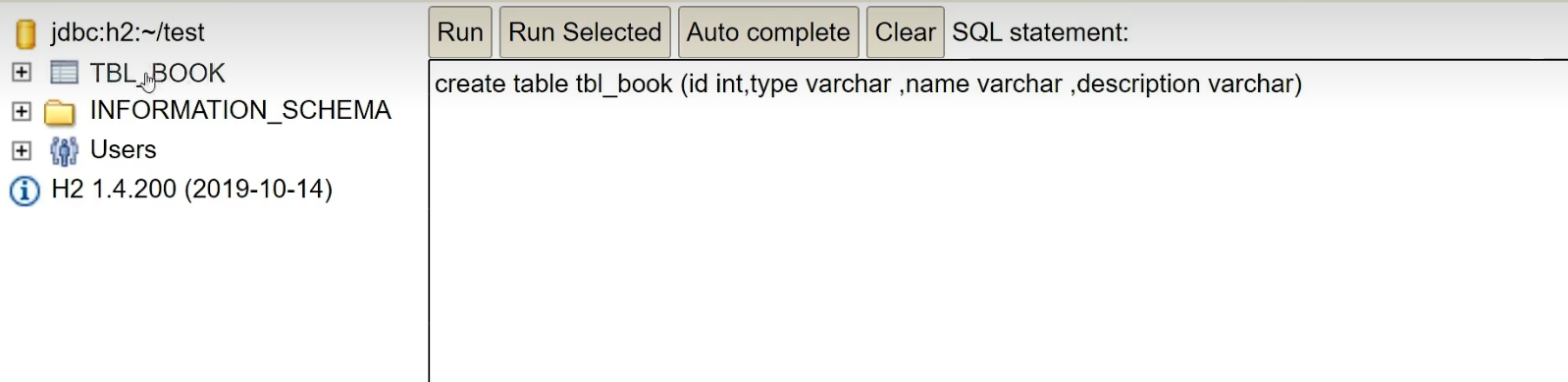
그런 다음 테이블을 살펴봅니다. 테이블
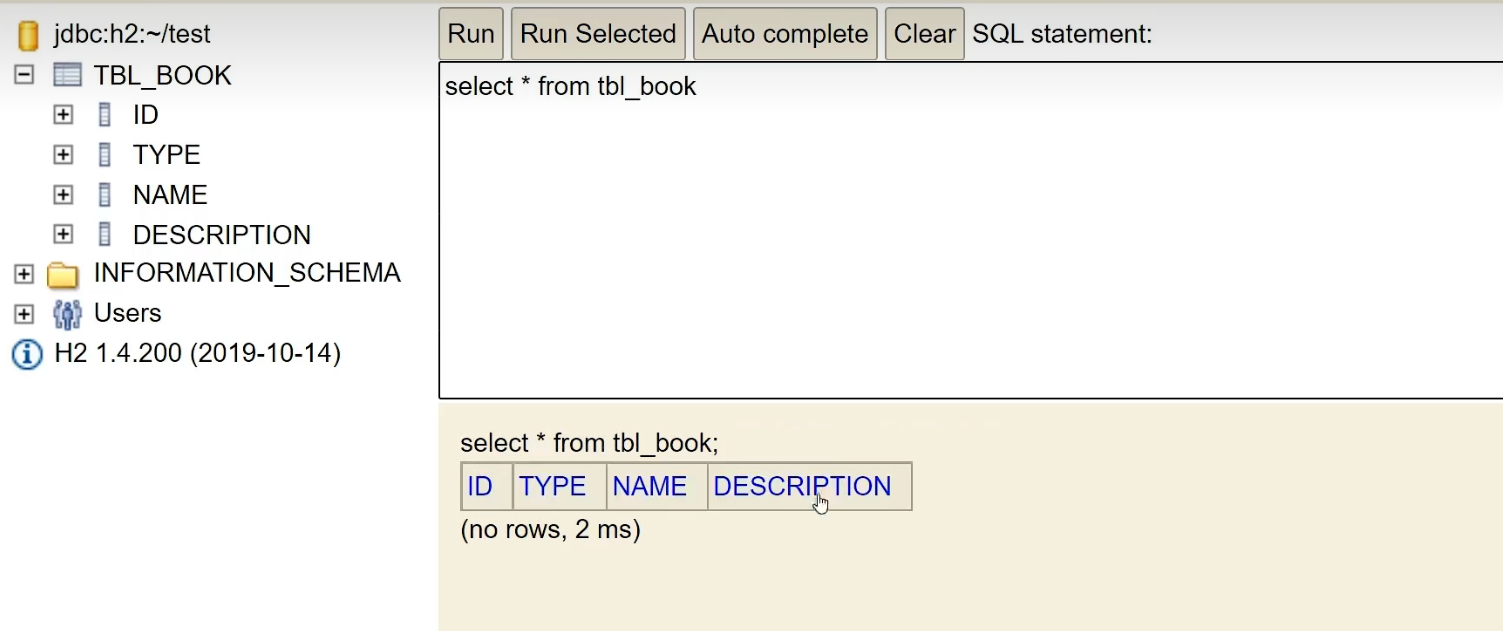
에 두 가지 데이터를 추가합니다.
insert into tbl_book values(1,'springboot','springboot','springboot')
insert into tbl_book values(2,'springboot2','springboot2','springboot2')
테이블을 다시 확인하고 데이터가 성공적으로 추가되었는지 확인합니다.
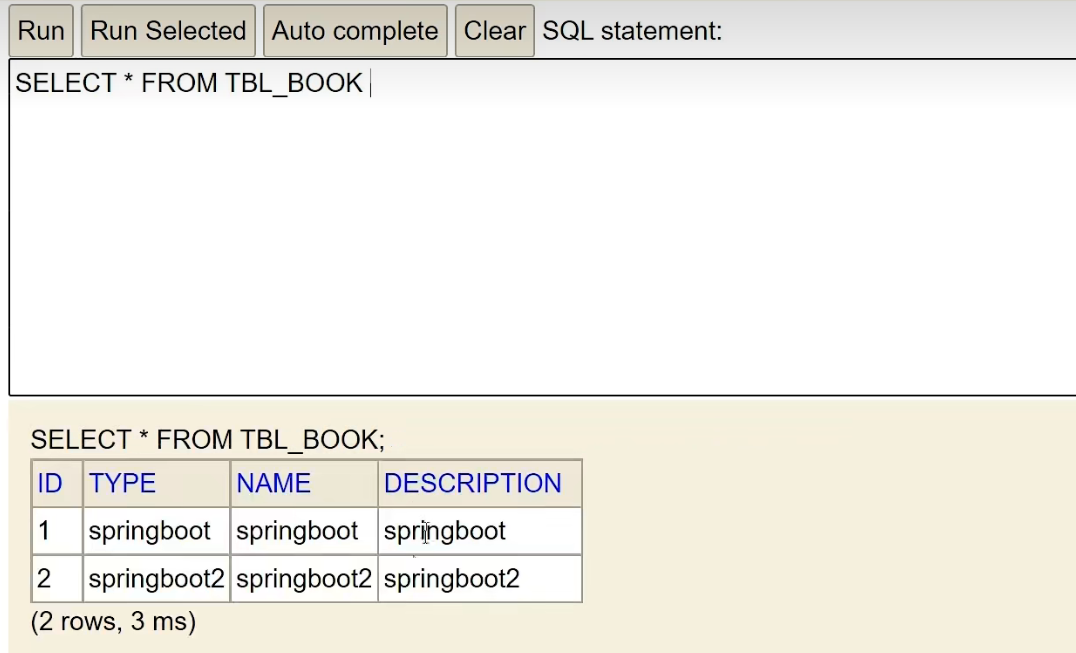
④ 단계 : JdbcTemplate 또는 MyBatisPlus 기술을 사용하여 데이터베이스 운영
여기서는 JdbcTemplate에 대해서만 이야기합니다. MyBatisPlus 기술은 이전과 동일합니다.
이 시점에서 데이터 소스를 작성해야 합니다. 데이터 소스
의 구성 정보는 h2 웹페이지에 처음 들어갈 때 작성됩니다.
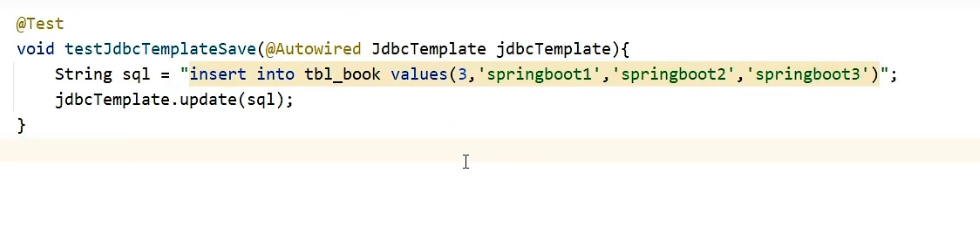
데이터 추가를 테스트해 보겠습니다.

사실, 우리는 단지 데이터베이스를 변경했고 다른 것들은 영향을 받지 않았습니다. 중요한 알림은 온라인 상태일 때 메모리 내 데이터베이스를 닫고 MySQL 데이터베이스를 데이터 지속성 체계로 사용하는 것을 잊지 마십시오. 닫는 방법은 활성화된 속성을 false로 설정하는 것입니다.

요약하다
- H2 임베디드 데이터베이스 시작 방법, 좌표 추가, 구성 추가
- H2 데이터베이스가 온라인으로 실행 중일 때 반드시 닫아야 합니다.
이쯤에서 SQL 관련 데이터 계층 솔루션에 대한 이야기를 마쳤고 이제 선택적 기술이 훨씬 더 풍부해졌습니다.
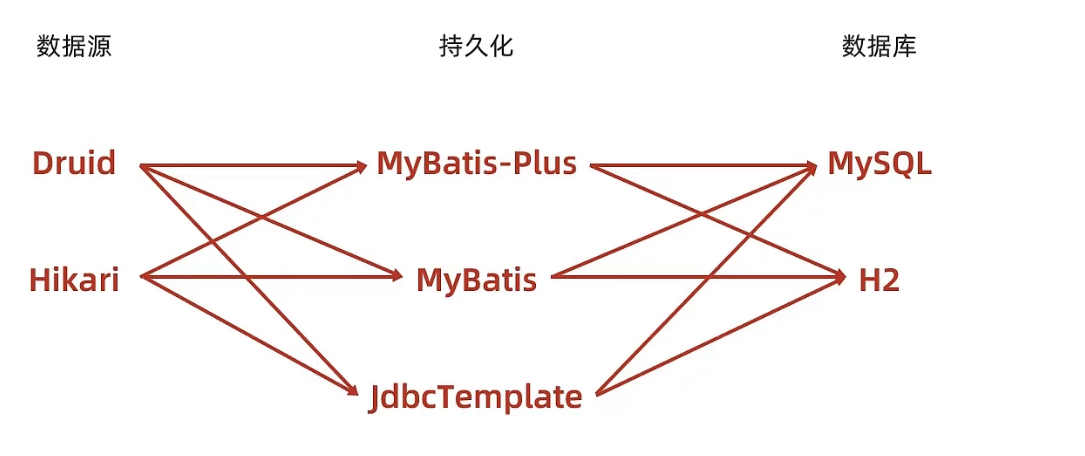
- 데이터 소스 기술: Druid, Hikari, tomcat DataSource, DBCP
- 지속성 기술: MyBatisPlus, MyBatis, JdbcTemplate
- 데이터베이스 기술: MySQL, H2, HSQL, Derby
이제 위의 기술 중 하나를 선택하여 프로그램을 개발할 때 데이터베이스 솔루션을 구성할 수 있습니다.