이 실험의 요구 사항은 매우 명확합니다.(이전 학기에 비해) 이 블로그는 python으로 구현되고, 과학 컴퓨팅 라이브러리를 사용 numpy하고, 도면은 사용됩니다 matplotlib.pyplot. 단순화를 위해 파일 시작 부분에 다음을 가져옵니다.
import numpy as np
import matplotlib.pyplot as plt
이 실험에 사용된 numpy 함수
일반적 으로 (numpy를 np로 가져오기) numpy로 축약됩니다 . np다음은 실험에 사용된 numpy 함수에 대한 간략한 소개입니다. 맨 위에 다음 코드를 추가해야 합니다 import numpy as np.
np.array
이 함수는 numpy.ndarray다차원 배열로 이해할 수 있는 객체를 반환합니다(이 실험에서는 1차원(열 벡터로 간주될 수 있음) 및 2차원(행렬)만 사용됨). \pmb x 아래에 소문자 x 사용엑스x 는 열 벡터, 대문자AAA 는 행렬을 나타냅니다. AAA.T를 의미A 의 전치 쌍에ndarray은 일반적으로 요소별로 수행됩니다.
>>> x = np.array([1,2,3])
>>> x
array([1, 2, 3])
>>> A = np.array([[2,3,4],[5,6,7]])
>>> A
array([[2, 3, 4],
[5, 6, 7]])
>>> A.T # 转置
array([[2, 5],
[3, 6],
[4, 7]])
>>> A + 1
array([[3, 4, 5],
[6, 7, 8]])
>>> A * 2
array([[ 4, 6, 8],
[10, 12, 14]])
np.random
np.random이 모듈에는 난수를 생성하기 위한 여러 함수가 포함되어 있습니다. 이 실험에서는 데이터에 노이즈를 추가하기 위해 무작위 초기화 매개변수(경사 하강법)를 사용합니다.
>>> np.random.rand(3, 3) # 生成3 * 3 随机矩阵,每个元素服从[0,1)均匀分布
array([[8.18713933e-01, 5.46592778e-01, 1.36380542e-01],
[9.85514865e-01, 7.07323389e-01, 2.51858374e-04],
[3.14683662e-01, 4.74980699e-02, 4.39658301e-01]])
>>> np.random.rand(1) # 生成单个随机数
array([0.70944563])
>>> np.random.rand(5) # 长为5的一维随机数组
array([0.03911319, 0.67572368, 0.98884287, 0.12501456, 0.39870096])
>>> np.random.randn(3, 3) # 同上,但每个元素服从N(0, 1)(标准正态)
수학 함수
이 실험에서만 사용됩니다 np.sin. 다음 수학 함수 np.ndarray는 요소별로 작동합니다.
>>> x = np.array([0, 3.1415, 3.1415 / 2]) # 0, pi, pi / 2
>>> np.round(np.sin(x)) # 先求sin再四舍五入: 0, 0, 1
array([0., 0., 1.])
또한 python의 라이브러리와 유사한 np.log기능 이 있습니다(다차원 배열에 대한 요소별 연산에만 해당).np.expmath
np.dot
두 행렬의 곱을 반환합니다. 선형 대수학의 행렬 곱셈과 일치합니다. 첫 번째 행렬의 열은 두 번째 행렬의 행 수와 같아야 합니다. 특히, 그 중 하나가 1차원 배열인 경우 모양은 자동으로 n × 1 n\times1N×1 또는1 × n . 1\times n.1×n .
>>> x = np.array([1,2,3]) # 一维数组
>>> A = np.array([[1,1,1],[2,2,2],[3,3,3]]) # 3 * 3矩阵
>>> np.dot(x,A)
array([14, 14, 14])
>>> np.dot(A,x)
array([ 6, 12, 18])
>>> x_2D = np.array([[1,2,3]]) # 这是一个二维数组(1 * 3矩阵)
>>> np.dot(x_2D, A) # 可以运算
array([[14, 14, 14]])
>>> np.dot(A, x_2D) # 行列不匹配
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<__array_function__ internals>", line 5, in dot
ValueError: shapes (3,3) and (1,3) not aligned: 3 (dim 1) != 1 (dim 0)
np.eye
np.eye(n)n차의 단위 행렬을 반환합니다.
>>> A = np.eye(3)
>>> A
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
선형 대수 상관
np.linalg선형 대수와 관련된 라이브러리입니다.
>>> A
array([[1, 0, 0],
[0, 2, 0],
[0, 0, 3]])
>>> np.linalg.inv(A) # 求逆(本实验不考虑逆不存在)
array([[1. , 0. , 0. ],
[0. , 0.5 , 0. ],
[0. , 0. , 0.33333333]])
>>> x = np.array([1,2,3])
>>> np.linalg.norm(x) # 返回向量x的模长(平方求和开根号)
3.7416573867739413
>>> np.linalg.eigvals(A) # A的特征值
array([1., 2., 3.])
데이터 생성
데이터를 생성하려면 노이즈(오류)를 추가해야 합니다. 클래스에 제공된 예제는 사인 함수이며 표준 사인 함수 y = sin x .y=\sin x도 사용합니다.와이=죄x . (노이즈 추가 후y = sin x + ϵ , y=\sin x+\epsilon,와이=죄엑스+ϵ , ϵ ∼ N (0 , σ 2 ) \epsilon\sim N(0, \sigma^2)ϵ~N ( 0 ,피2 ),sin x \sin x죄x 의 최대값1 11 , 오류 분산을 더 작게 설정했습니다. 여기서는1 25 \frac{1}{25}251).
'''
返回数据集,形如[[x_1, y_1], [x_2, y_2], ..., [x_N, y_N]]
保证 bound[0] <= x_i < bound[1].
- N 数据集大小, 默认为 100
- bound 产生数据横坐标的上下界, 应满足 bound[0] < bound[1], 默认为(0, 10)
'''
def get_dataset(N = 100, bound = (0, 10)):
l, r = bound
# np.random.rand 产生[0, 1)的均匀分布,再根据l, r缩放平移
# 这里sort是为了画图时不会乱,可以去掉sorted试一试
x = sorted(np.random.rand(N) * (r - l) + l)
# np.random.randn 产生N(0,1),除以5会变为N(0, 1 / 25)
y = np.sin(x) + np.random.randn(N) / 5
return np.array([x,y]).T
결과 데이터 세트에는 행당 평면에 점이 있습니다. 결과 데이터는 다음과 같습니다.
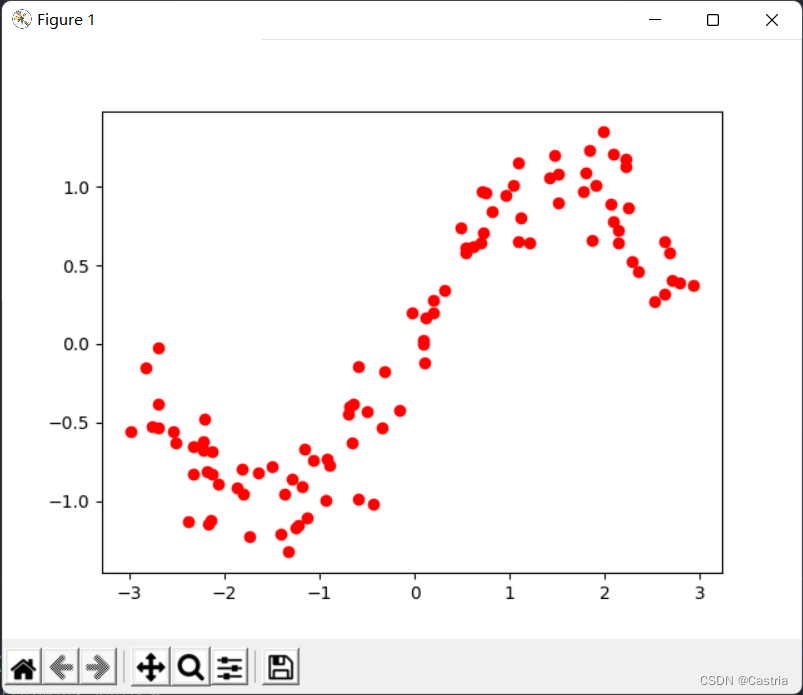
막연하게 사인 함수의 형태입니다. 위의 이미지를 생성하는 코드는 다음과 같습니다.
dataset = get_dataset(bound = (-3, 3))
# 绘制数据集散点图
for [x, y] in dataset:
plt.scatter(x, y, color = 'red')
plt.show()
최소 제곱 피팅
아래에서 우리는 위의 섭동 사인 곡선을 다항식으로 맞추기 위해 네 가지 방법(최소 제곱, 정규 항/릿지 회귀, 기울기 하강, 켤레 기울기)을 사용합니다.
분석 솔루션 유도
최소 제곱법의 원리를 간단히 상기하십시오. 이제 mm 를 사용하려고 합니다.차수의 다항식 f ( x ) = w
0 + w 1 x + w 2 x 2 + ... + wmxmf(x)=w_0+w_1x+w_2x^2+...+w_mx^m에프 ( x )=안에0+안에1엑스+안에2엑스2+...+안에m엑스m
은 실제 함수y = sin x .y=\sin x를 근사화합니다.와이=죄x . 우리의 목표는 데이터 세트( x 1 , y 1 ) , ( x 2 , y 2 ) , ... , ( x N , y N ) (x_1,y_1),(x_2,y_2), . .,(x_N,y_N)( x1,와이1) ,( x2,와이2) ,... ,( x엔,와이엔) 손실LLL (손실), 여기서 손실 함수는 제곱 오차를 취합니다.
L = ∑ i = 1 N [ yi − f ( xi ) ] 2 L=\sum\limits_{i=1}^N[y_i-f(x_i) ]^ 2엘=나는 = 1∑엔[ 그리고나는-에프 ( x나는) ]2
매개변수w 0 , w 1 , ... , wm , w_0,w_1,...,w_m,안에0,안에1,... ,안에m, 손실 LL찾아야 합니다.L关于w 0 , w 1 , . . . , wm w_0,w_1,...,w_m안에0,안에1,... ,안에m의 파생물. 편의상 선형 대수 표기법을 사용합니다.
X = ( 1 x 1 x 1 2 ⋯ x 1 m 1 x 2 x 2 2 ⋯ x 2 m ⋮ ⋮ 1 x N x N 2 ⋯ x N m ) N × ( m + 1 ) , Y = ( y 1 y 2 ⋮ y N ) N × 1 , W = ( w 0 w 1 ⋮ wm ) ( m + 1 ) × 1 . X=\begin{pmatrix}1 & x_1 & x_1 ^2 & \cdots & x_1^m\\ 1 & x_2 & x_2^2 & \cdots & x_2^m\\ \vdots & & & & &\vdots\\ 1 & x_N & x_N^2 & \cdots & x_N^ m\ \\end{pmatrix}_{N\times(m+1)},Y=\begin{pmatrix}y_1 \\ y_2 \\ \vdots \\y_N\end{pmatrix}_{N\times1}, W= \begin{pmatrix}w_0 \\ w_1 \\ \vdots \\w_m\end{pmatrix}_{(m+1)\times1}.엑스=⎝
⎛11⋮1엑스1엑스2엑스엔엑스12엑스22엑스N2⋯⋯⋯엑스1m엑스2m⋮엑스Nm⎠
⎞N × ( m + 1 ),와이=⎝
⎛와이1와이2⋮와이엔⎠
⎞N × 1,~ 안에=⎝
⎛안에0안에1⋮안에m⎠
⎞( m + 1 ) × 1이
표현에서
( f ( x 1 ) f ( x 2 ) ⋮ f ( x N ) ) = XW . \begin{pmatrix}f(x_1)\\ f(x_2) \\ \vdots \\ f(x_N )\end{pmatrix}= XW.⎝
⎛에프 ( x1)에프 ( x2)⋮에프 ( x엔)⎠
⎞=X W.
의문점이 있으면 행렬 곱셈으로 직접 확인할 수 있습니다 . 계속해서, 오차항의 합은
( f ( x 1 ) − y 1 f ( x 2 ) − y 2 ⋮ f ( x N ) − y N ) = XW − Y 로 표현될 수 있습니다. \begin{pmatrix}f (x_1) -y_1 \\ f(x_2)-y_2 \\ \vdots \\ f(x_N)-y_N\end{pmatrix}=XW-Y.⎝
⎛에프 ( x1)-와이1에프 ( x2)-와이2⋮에프 ( x엔)-와이엔⎠
⎞=X 여-
따라서 손실 함수 L = ( XW − Y )
T ( XW − Y ) L=(XW-Y)^T(XW-Y).엘=( X W-그리고 )티 (XW_-Y ) .
(벡터x = ( x 1 , x 2 , . . . , x N ) T \pmb x=(x_1,x_2,...,x_N)^T를 구하려면엑스엑스=( x1,엑스2,... ,엑스엔)x \pmb x 에 사용할 수 있는 T 의 구성요소 제곱의 합엑스x 는 내적, 즉x T x . \pmb x^T \pmb x입니다.엑스엑스티엑스x . )LL
을 얻기 위해L 최소WW여 (이WWW 는 열 벡터임), 다음을 수행해야합니다.L 의 편도함수를 찾아0:00:
∂ L ∂ W = ∂ ∂ W [ ( XW − Y ) T ( XW − Y ) ] = ∂ ∂ W [ ( WTXT − YT ) ( XW − Y ) ] = ∂ ∂ W ( WTXTXW − WTXTY − YTXW ) = ∂ ∂ W ( WTXTXW − 2 YTXW + YTY ) ( 容易验证 , WTXTY = YTXW , 因而可以将其合并 ) = 2 XTXW − 2 XTY \fragin}{\aligned &=\frac{\partial}{\partial W}[(XW-Y)^T(XW-Y)]\\ &=\frac{\partial}{\partial W}[(W^TX^TY^ T)(XW-Y)] \\ &=\frac{\partial}{\partial W}(W^TX^TXW-W^TX^TY-Y^TXW+Y^TY)\\ &=\frac {\partial}{\partial W}(W^TX^TXW-2Y^TXW+Y^TY)(容易验证,W^TX^TY=Y^TXW,因而可以将其合并)\\ &=2X^ TXW-2X^TY\end{정렬}∂ 여∂ 패=∂ 여∂[( X W-그리고 )티 (XW_-예 )]=∂ 여∂[( 여TX _티-와이티 )(XW-예 )]=∂ 여∂( W.TX _T XW-~ 안에TX _T Y-와이T XW+와이티 )_=∂ 여∂( W.TX _T XW-2 년T XW+와이T Y)(확인하기 쉽고,~ 안에TX _T Y=와이T XW,따라서 결합될 수 있습니다 )=2 XT XW-2 XT Y
설명: (1) WTXTYW^TX^TY
로 인해 3행에서 4행으로~ 안에TX _T Y와YTXWY^TXW와이T XW는 모두 숫자입니다(또는1 × 1 1\times11×1 행렬)에서 두 개는 서로 전치되어 값이 동일하고 하나의 항목으로 결합될 수 있습니다.
(2) 4행에서 5행으로 행렬의 유도, 첫 번째 항∂ ∂ W ( WT ( XTX ) W ) \frac{\partial}{\partial W}(W^T(X^TX)W )∂ 여∂( W.티 (XT X)W)약WWW 의 2차 형식 , 그 미분은2 XTXW . 2X^TXW 입니다.2 XT XW.(
3) 1차 항의 경우− 2 YTXW -2Y^TXW- 2 년T XW의 유도는 실수 필드에 따른 유도가-2 YTX .-2Y^TX 를 얻어야 합니다.- 2 년T X.그러나 행렬의 유형이 올바르지 않은지 확인하고 전치해야 합니다. 이는 − 2 XTY . -2X^TY가 됩니다.- 2 XT Y.
행렬 선형 대수학은 수업에서 체계적으로 가르치지 않았으며 여기에 나타나는 내용만 설명합니다. ( 더 있으면 안 하겠습니다 )
편미분을 0으로 하고
XTXW = YTX , X^TXW=Y^TX,엑스T XW=와이T X,
왼쪽 곱하기( XTX ) − 1 (X^TX)^{-1}( 엑스T X)− 1(XTXX^TX엑스T X의 가역성에 대해서는 아래 보충 설명을 참조하고
W = ( XTX ) − 1 XTY . W=(X^TX)^{-1}X^TY를 얻습니다.~ 안에=( 엑스T X)- 1 XT Y가
원하는WWW 의 분석 솔루션의 경우 이 값을 계산하는 함수만 호출하면 됩니다.
'''
最小二乘求出解析解, m 为多项式次数
最小二乘误差为 (XW - Y)^T*(XW - Y)
- dataset 数据集
- m 多项式次数, 默认为 5
'''
def fit(dataset, m = 5):
X = np.array([dataset[:, 0] ** i for i in range(m + 1)]).T
Y = dataset[:, 1]
return np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), Y)
코드를 약간 설명하십시오. 첫 번째 줄 은 위에서 동의한 XX 를 생성합니다.dataset[:,0]데이터세트의 0번째 열인 X 행렬( x 1 , x 2 , ... , x N ) T (x_1,x_2,...,x_N)^T( x1,엑스2,... ,엑스엔)T ; 두 번째 줄은YYY 행렬, 세 번째 행은 위의 분석 솔루션을 반환합니다. (파이썬 구문이나 라이브러리에 익숙하지 않다면numpy상당히 비우호적입니다)
우리가 완료한 함수의 결과를 확인하기만 하면 됩니다. 이를 위해 먼저 draw얻은 WW 를 변환하는 함수를 작성합니다.W 에 대응하는 다항식f ( x ) f(x)pyplot라이브러리 이미지 에 f ( x ) 를 그 립니다
'''
绘制给定系数W的, 在数据集上的多项式函数图像
- dataset 数据集
- w 通过上面四种方法求得的系数
- color 绘制颜色, 默认为 red
- label 图像的标签
'''
def draw(dataset, w, color = 'red', label = ''):
X = np.array([dataset[:, 0] ** i for i in range(len(w))]).T
Y = np.dot(X, w)
plt.plot(dataset[:, 0], Y, c = color, label = label)
그런 다음 주요 기능:
if __name__ == '__main__':
dataset = get_dataset(bound = (-3, 3))
# 绘制数据集散点图
for [x, y] in dataset:
plt.scatter(x, y, color = 'red')
# 最小二乘
coef1 = fit(dataset)
draw(dataset, coef1, color = 'black', label = 'OLS')
# 绘制图像
plt.legend()
plt.show()
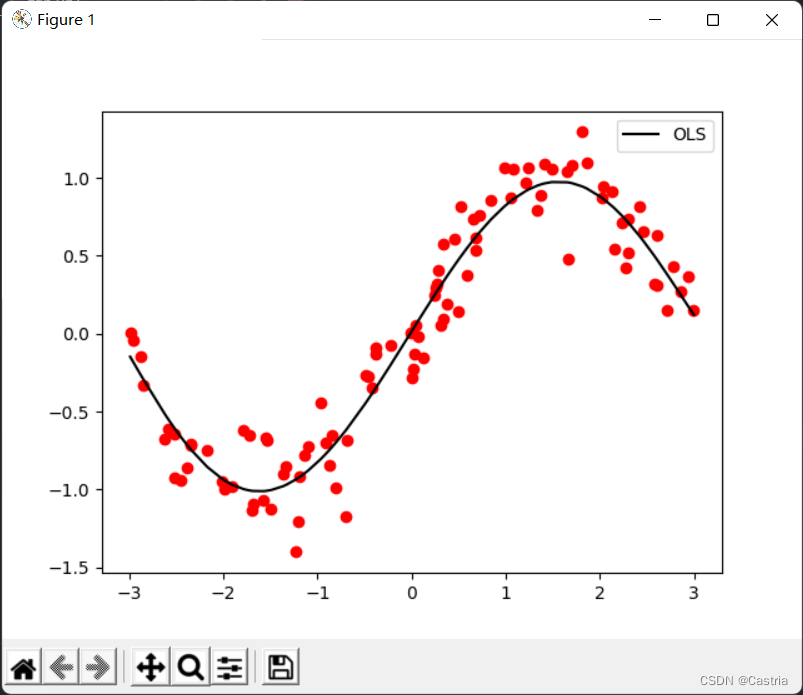
5차 다항식 피팅의 효과가 꽤 좋은 것을 알 수 있습니다(데이터 세트는 매번 무작위로 생성되므로 첫 번째 그림과 다릅니다).
이 부분의 모든 코드에서 동일한 이름의 다음 기능은 더 이상 설명되지 않습니다.
import numpy as np
import matplotlib.pyplot as plt
'''
返回数据集,形如[[x_1, y_1], [x_2, y_2], ..., [x_N, y_N]]
保证 bound[0] <= x_i < bound[1].
- N 数据集大小, 默认为 100
- bound 产生数据横坐标的上下界, 应满足 bound[0] < bound[1]
'''
def get_dataset(N = 100, bound = (0, 10)):
l, r = bound
x = sorted(np.random.rand(N) * (r - l) + l)
y = np.sin(x) + np.random.randn(N) / 5
return np.array([x,y]).T
'''
最小二乘求出解析解, m 为多项式次数
最小二乘误差为 (XW - Y)^T*(XW - Y)
- dataset 数据集
- m 多项式次数, 默认为 5
'''
def fit(dataset, m = 5):
X = np.array([dataset[:, 0] ** i for i in range(m + 1)]).T
Y = dataset[:, 1]
return np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), Y)
'''
绘制给定系数W的, 在数据集上的多项式函数图像
- dataset 数据集
- w 通过上面四种方法求得的系数
- color 绘制颜色, 默认为 red
- label 图像的标签
'''
def draw(dataset, w, color = 'red', label = ''):
X = np.array([dataset[:, 0] ** i for i in range(len(w))]).T
Y = np.dot(X, w)
plt.plot(dataset[:, 0], Y, c = color, label = label)
if __name__ == '__main__':
dataset = get_dataset(bound = (-3, 3))
# 绘制数据集散点图
for [x, y] in dataset:
plt.scatter(x, y, color = 'red')
coef1 = fit(dataset)
draw(dataset, coef1, color = 'black', label = 'OLS')
plt.legend()
plt.show()
추가 지침
위의 덜 엄격한 부분이 있습니다. 행렬 XX 의 경우X 의 경우XTXX^TX엑스T X는 반드시 가역적인 것은 아닙니다. 그러나 이 실험에서는 역행렬임을 알 수 있습니다. 이 수업은 선형 대수학 수업이 아니기 때문에 이것에 대해 너무 많은 공간을 사용하지 않을 것입니다. 간단한 알림:
(1)XXX 는N × ( m + 1 ) N\times(m+1)N×( m+1 ) 매트릭스. 여기서 데이터 수는NNN 은 다항식 차수 mm보다 훨씬 큽니다.m ,N > m + 1, N > m+1, N > m+1이 있습니다.N>중+1 ;
(2)XTXX^TX엑스T X는 가역적이므로 설명해야 합니다.( XTX ) ( m + 1 ) × ( m + 1 ) (X^TX)_{(m+1)\times(m+1)}( 엑스T X)( m + 1 ) × ( m + 1 )전체 순위, 즉, R( XTX ) = m + 1 ; R(X^TX)=m+1;R ( XT X)=중+1 ;
(3) 선형 대수학에서 우리는R ( X ) = R ( XT ) = R ( XTX ) = R ( XXT ) ; R(X)=R(X^T)=R(X^TX )=R(XX^T);R ( X )=R ( X티 )=R ( XT X)=R ( X X티 );
(4)XXX 는Vandermonde 행렬입니다. min\{N,m+1\}=m+1.내 {
N ,중+1 }=중+1.
정규화 항 추가(릿지 회귀)
최소 제곱법은 과적합되기 쉽습니다. 이 결함을 설명하기 위해 생성된 데이터 세트의 처음 50개 지점을 학습용으로 사용합니다(샘플링이 충분히 균일하지 않도록 여기에서는 과적합을 설명하기 위한 것입니다). 매개변수를 얻은 다음 전체 기능 이미지를 그립니다. 피팅 효과를 확인하려면:
if __name__ == '__main__':
dataset = get_dataset(bound = (-3, 3))
# 绘制数据集散点图
for [x, y] in dataset:
plt.scatter(x, y, color = 'red')
# 取前50个点进行训练
coef1 = fit(dataset[:50], m = 3)
# 再画出整个数据集上的图像
draw(dataset, coef1, color = 'black', label = 'OLS')
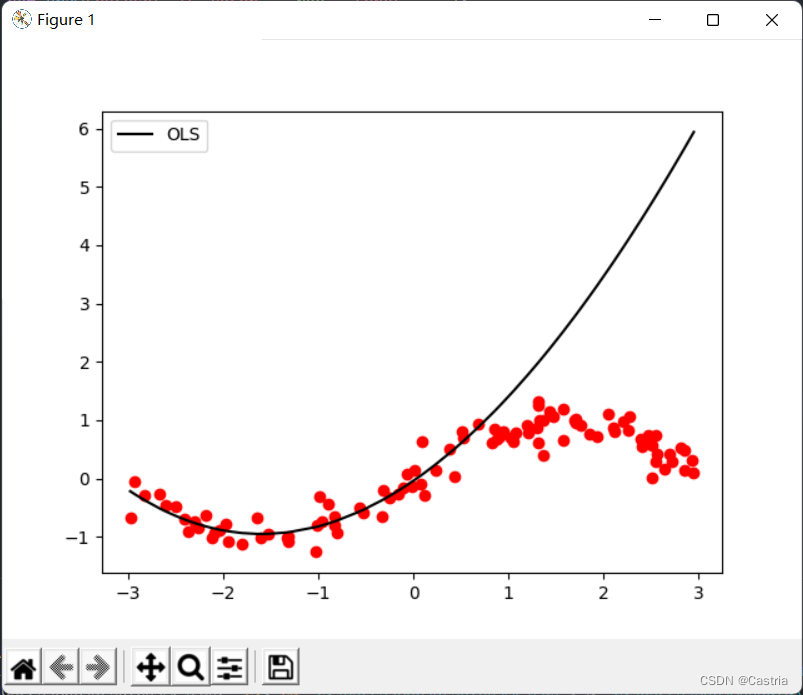
과적합( mm )이것은 m 이 클 때 특히 심각합니다( 위 이미지에서 m = 3 m = 3중=3 시). 다항식 차수가 증가함에 따라 주어진 데이터 세트에 최대한 가깝게 하기 위해 계산된 계수의 크기는 점점 더 커지고 보이지 않는 샘플에 대한 성능은 더 나빠질 것입니다. 위에 표시된 것처럼 피팅이 처음 50개 점(대략 가로좌표[ − 3 , 0 ] [-3,0]에 있음을 알 수 있습니다.[ - 3 ,0 ] ) 매우 좋음; 테스트 세트에서 성능이 매우 나쁨([ 0 , 3 ] [0,3][ 0 ,3 ] ). 과적합을 방지하기 위해 정규화 항을 도입할 수 있습니다. 이때 손실함수LLL变为
L = ( XW − Y ) T ( XW − Y ) + λ ∣ ∣ W ∣ ∣ 2 2 L=(XW-Y)^T(XW-Y)+\lambda||W||_2^2엘=( X W-그리고 )티 (XW_-그리고 )+λ ∣∣ W ∣ ∣22
여기서 ∣ ∣ ⋅ ∣ ∣ 2 2 ||\cdot||_2^2∣∣⋅∣ ∣22L 2 L_2를 나타냅니다 .엘2노름의 제곱, 이 경우 WTW ; λ W^TW;\lambda~ 안에트 와이스 ;λ 는 정규화 계수입니다. 이 공식을 능선 회귀라고도 합니다. 그 아이디어는 손실 함수와 결과 매개변수WWW 의 모듈로 길이 (L 2 L_2엘2규범), WW 방지W 의 매개변수 가 너무 큽니다.
예를 들어(숫자는 무작위로 구성됨): 정규화 계수가 1인 경우 11 , 데이터 세트에 대한 방식 1의 제곱 오차가0.5, 0.5인 경우0.5 , 이때W = ( 100 , − 200 , 300 , 150 ) TW=(100,-200,300,150)^T~ 안에=( 100 ,- 200 ,300 ,150 )T ; 데이터 세트에 대한 계획 2의 제곱 오차는10, 10,10 , 이때W = ( 1 , − 3 , 2 , 1 ) W=(1,-3,2,1)~ 안에=( 1 ,- 3 ,2 ,1 ) 그런 다음 W.W를 선택합니다W. 정규화 계수λ \lambdaλ 는 WW에 대해 이것을 특성화합니다.W 계수 길이의 중요성:λ \lambdaλ 가 클수록WWW 의 모듈 길이가 길수록 패널티가 커집니다. λ = 0일 때\lambda=0,엘=0 이면 능선 회귀가 일반 최소 자승법이 됩니다. 능선 회귀와 유사하게 LASSO는 정규화 항을L 1 L_1엘1표준.
위의 유도를 반복하면 W = ( XTX + λ E m + 1 ) − 1 XTY . W=(X^TX+\lambda E_{m+1})^{-1}X^TY 와 같은 분석 솔루션을 얻을 수 있습니다 .
.~ 안에=( 엑스TX _+λ Em + 1)- 1 XT Y.
여기서E m + 1 E_{m+1}그리고m + 1m + 1m+1중+1 차 단위 행렬. 구하기 쉽습니다( XTX + λ E m + 1 ) (X^TX+\lambda E_{m+1})( 엑스TX _+λ Em + 1) 또한 가역적입니다.
코드의 이 부분은 다음과 같습니다.
'''
岭回归求解析解, m 为多项式次数, l 为 lambda 即正则项系数
岭回归误差为 (XW - Y)^T*(XW - Y) + λ(W^T)*W
- dataset 数据集
- m 多项式次数, 默认为 5
- l 正则化参数 lambda, 默认为 0.5
'''
def ridge_regression(dataset, m = 5, l = 0.5):
X = np.array([dataset[:, 0] ** i for i in range(m + 1)]).T
Y = dataset[:, 1]
return np.dot(np.dot(np.linalg.inv(np.dot(X.T, X) + l * np.eye(m + 1)), X.T), Y)
두 방법의 비교는 다음과 같습니다.
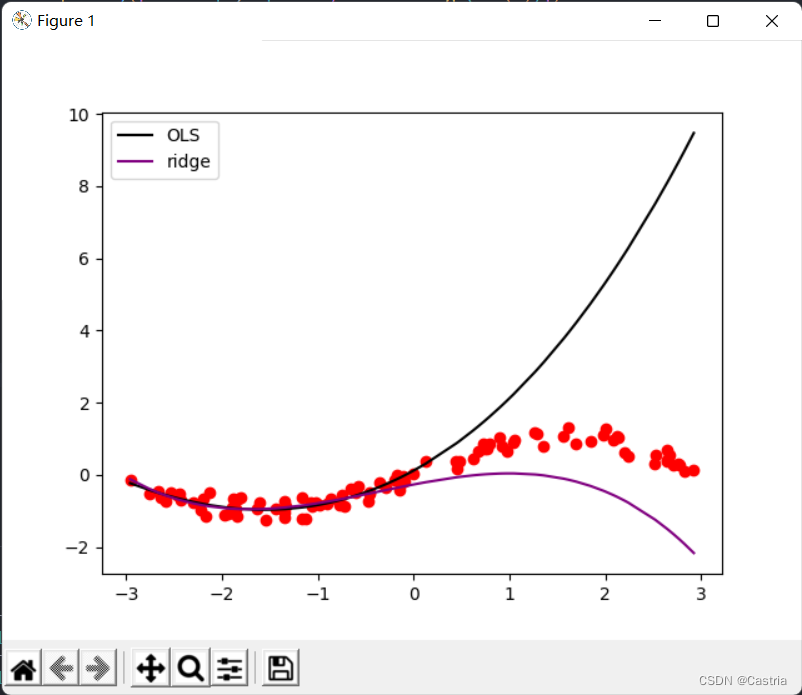
비교에서 ridge 회귀가 과적합을 크게 줄이는 것을 알 수 있습니다(이때 m = 3 , λ = 0.3 m=3, \lambda=0.3중=3 ,엘=0.3 ).
경사하강법
경사하강법은 이 문제를 해결하는 가장 좋은 방법이 아니며 쉽게 수렴에 실패할 수 있습니다. 먼저 기울기 하강법의 기본 아이디어를 간략하게 소개합니다. 복소수 함수 f( x ) f(x) 를 찾으려면f ( x ) 의 최소값(최대점)xxx 는 벡터 등일 수 있음), 즉
xmin = arg min xf ( x ) x_{min}=\argmin_{x}f(x)엑스분=엑스인수분f ( x )
경사 하강법은 다음 작업을 반복합니다.
(0) (무작위로)x 0 ( t = 0 ) x_0(t=0엑스0( t=0 ) ;
(1)f ( x ) f(x)f ( x ) xtx_t엑스티( xx 일 때 기울기x 가 1차원이면 도함수)∇ f ( xt ) \nabla f(x_t)∇ f ( x티);
(2)xt + 1 = xt − η ∇ f ( xt ) x_{t+1}=x_t-\eta\nabla f(x_t)엑스t + 1=엑스티-η ∇ f ( x티)
(3)xt + 1 x_{t+1}인엑스t + 1xt x_t 와 함께엑스티차이가 거의 없거나(미리 설정된 범위에 도달) 반복 횟수가 미리 설정된 상한에 도달하면 알고리즘을 중지하고, 그렇지 않으면 (1)(2)를 반복합니다.
其中η \etaη 는 경사하강법의 단계 크기를 결정하는 학습률입니다. 다음은 y = x 2 y=x^2
를 찾는 경사하강법입니다.와이=엑스2 의 최소 포인트에 대한 예제 프로그램
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return x ** 2
def draw():
x = np.linspace(-3, 3)
y = f(x)
plt.plot(x, y, c = 'red')
cnt = 0
# 初始化 x
x = np.random.rand(1) * 3
learning_rate = 0.05
while True:
grad = 2 * x
# -----------作图用,非算法部分-----------
plt.scatter(x, f(x), c = 'black')
plt.text(x + 0.3, f(x) + 0.3, str(cnt))
# -------------------------------------
new_x = x - grad * learning_rate
# 判断收敛
if abs(new_x - x) < 1e-3:
break
x = new_x
cnt += 1
draw()
plt.show()
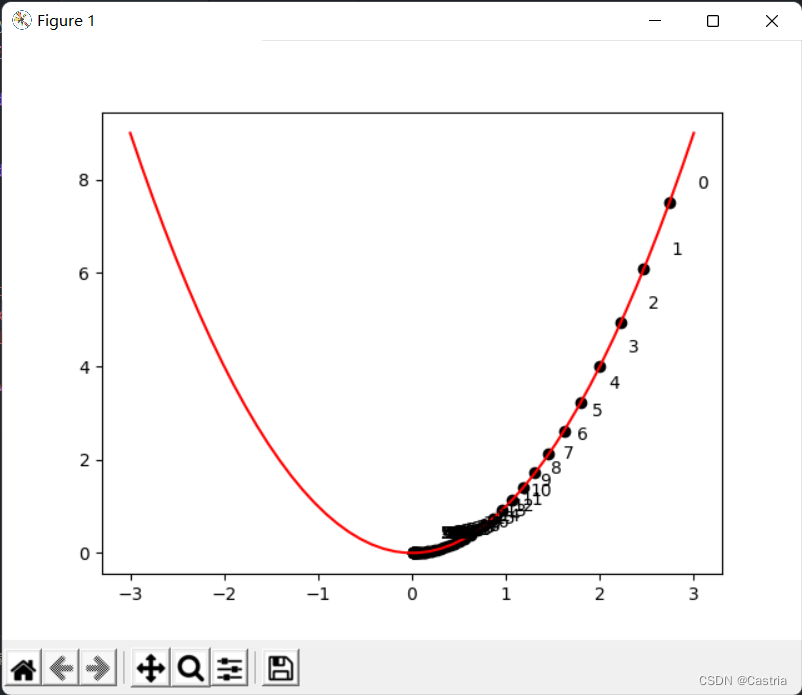
위의 그림은 xx 를 나타냅니다.x 반복이 진행됨에 따라 xx를 볼 수 있습니다.x 는 양의 반축을 따라 0에 계속 접근합니다. 학습률이 너무 클 수는 없으며(위 프로그램에서는 학습률이 약간 작게 설정됨) 수동으로 조정해야 합니다. 그렇지 않으면 상상하기 쉽습니다.xxx 는 양의 반축과 음의 반축에서 앞뒤로 진동하여 수렴하기 어렵습니다.
최소 제곱에서 최적화해야 하는 함수는 손실 함수
L = ( XW − Y ) T ( XW − Y ) L=(XW-Y)^T(XW-Y)입니다.엘=( X W-그리고 )티 (XW_-Y )
다음으로 경사하강법 문제를 해결합니다 . 위의 유도에서
∂ L ∂ W = 2 XTXW − 2 XTY , \begin{aligned}\frac{\partial L}{\partial W}=2X^TXW-2X^TY\end{aligned},∂ 여∂ 패=2 XT XW-2 XT Y, 그래서 우리가 WW
에서 반복을 수행할 때마다W 는 매개변수 WW까지 이 기울기를 뺍니다.W 는 수렴합니다. 그러나 실험 후에 제곱 오차로 인해 기울기가 너무 커져 프로세스가 수렴할 수 없으므로 이를 대체하기 위해 평균 제곱 오차(MSE)가 사용되며, 이는 원래 공식을NN엔 :
'''
梯度下降法(Gradient Descent, GD)求优化解, m 为多项式次数, max_iteration 为最大迭代次数, lr 为学习率
注: 此时拟合次数不宜太高(m <= 3), 且数据集的数据范围不能太大(这里设置为(-3, 3)), 否则很难收敛
- dataset 数据集
- m 多项式次数, 默认为 3(太高会溢出, 无法收敛)
- max_iteration 最大迭代次数, 默认为 1000
- lr 梯度下降的学习率, 默认为 0.01
'''
def GD(dataset, m = 3, max_iteration = 1000, lr = 0.01):
# 初始化参数
w = np.random.rand(m + 1)
N = len(dataset)
X = np.array([dataset[:, 0] ** i for i in range(len(w))]).T
Y = dataset[:, 1]
try:
for i in range(max_iteration):
pred_Y = np.dot(X, w)
# 均方误差(省略系数2)
grad = np.dot(X.T, pred_Y - Y) / N
w -= lr * grad
'''
为了能捕获这个溢出的 Warning,需要import warnings并在主程序中加上:
warnings.simplefilter('error')
'''
except RuntimeWarning:
print('梯度下降法溢出, 无法收敛')
return w
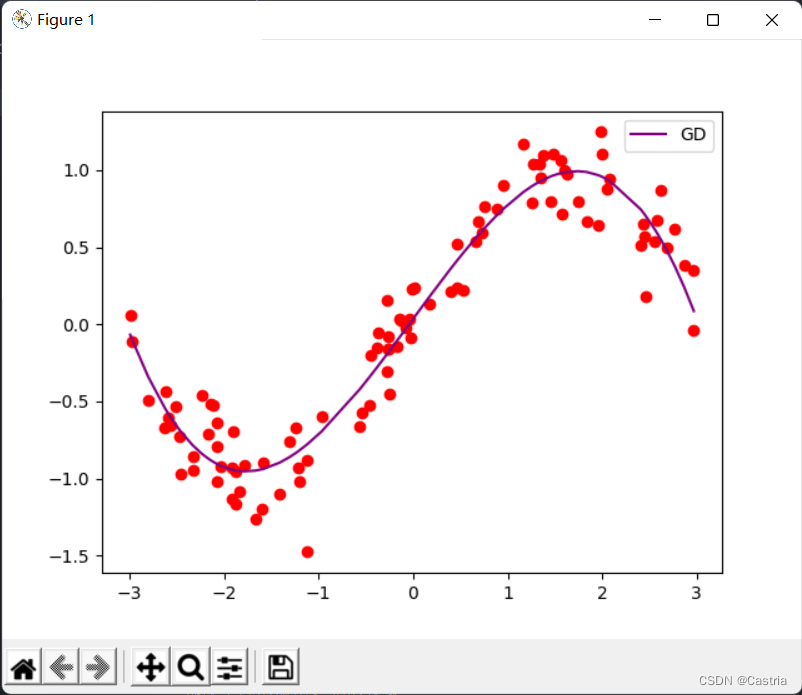
이 때 mm 이면m 이 조금 더 크게 설정되면(예: 4), 그래디언트가 반복 중에 오버플로되어 매개변수를 수렴할 수 없게 됩니다. 수렴할 때 피팅 효과는 정상입니다.
켤레 기울기 방법
켤레 기울기를 사용하여 A x = b A\pmb x=\pmb b 형식을 풀 수 있습니다.ㅏ엑스엑스=비b 에 대한 연립방정식f ( x ) = 1 2 x TA x − b T x + c . f(\pmb x)=\frac12\pmb x^TA\pmb x-\pmb b^ T \pmb x+c.에프 (엑스x )=21엑스엑스타 _엑스엑스-비비티엑스엑스+c . (양의 정부호AAA , 둘은 동등함) 여기서AAA 는양의 정부호행렬입니다. 이 문제에서 우리는 XTXW = YTX , X^TXW=Y^TX,엑스T XW=와이T X,
그러면A ( m + 1 ) × ( m + 1 ) = XTX , b = YT . A_{(m+1)\times(m+1)}=X^TX,\pmb b=Y^ T .ㅏ( m + 1 ) × ( m + 1 )=엑스TX ,_비비=와이T .정규항을 추가하면 해가
( XTX + λ E ) W = YTX . (X^TX+\lambda E)W=Y^TX가 됩니다.( 엑스TX _+λ E ) 승=와이T X.
먼저 설명하겠습니다:XTXX^TX엑스T X는 반드시 양의 정부호가 아니라 양의 준정부호여야 합니다(참조). 그러나 실험에서 우리는 기본적으로 이 문제에 대해 걱정할 필요가 없습니다. 왜냐하면XTXX^TX엑스T X는 양의 정부호일 가능성이 매우 높으며, 코드에 주장만 추가하고 이 조건에 많은 관심을 기울이지 않습니다.
conjugate gradient 방법의 아이디어와 증명 과정은 상대적으로 길다.이 시리즈.여기에는 알고리즘 단계 만 제공됩니다 (위에 링크 된 세 번째 기사의 시작 부분).
(0) 초기화 x( 0 ), x_{(0)};엑스( 0 )(
1) 초기화d( 0 ) = r ( 0 ) = b − A x ( 0 ) ; d_{(0)}=r_{(0)}=b-Ax_{(0)};디( 0 )=아르 자형( 0 )=비-엑스 _( 0 );
(2) 令α ( i ) = r ( i ) T r ( i ) d ( i ) TA d ( i ) ; \alpha_{(i)}=\frac{r_{(i)}^Tr_{(i)}}{d_{(i)}^TAd_{(i)}};ㅏ( 나는 )=디( 나는 )티광고 _( 나는 )아르 자형( 나는 )티아르 자형( 나는 );
(3) 迭代x ( i + 1 ) = x ( i ) + α ( i ) d ( i ) ; x_{(i+1)}=x_{(i)}+\alpha_{(i)}d_{(i)};엑스( 나는 + 1 )=엑스( 나는 )+ㅏ( 나는 )디( 나는 );
(4) 令r ( i + 1 ) = r ( i ) − α ( i ) A d ( i ) ; r_{(i+1)}=r_{(i)}-\alpha_{(i)}광고_{(i)};아르 자형( 나는 + 1 )=아르 자형( 나는 )-ㅏ( 나는 )광고 _( 나는 );
(5) 令β ( i + 1 ) = r ( i + 1 ) T r ( i + 1 ) r ( i ) T r ( i ) , d ( i + 1 ) = r ( i + 1 ) + β ( 나는 + 1 ) d ( 나는 ) . \베타_{(i+1)}=\frac{r_{(i+1)}^Tr_{(i+1)}}{r_{(i)}^Tr_{(i)}},d_{( i+1)}=r_{(i+1)}+\베타_{(i+1)}d_{(i)}.비( 나는 + 1 )=아르 자형( 나는 )티아르 자형( 나는 )아르 자형( 나는 + 1 )티아르 자형( 나는 + 1 ),디( 나는 + 1 )=아르 자형( 나는 + 1 )+비( 나는 + 1 )디( 나는 ).
(6)当∣ ∣ r ( i ) ∣ ∣ ∣ ∣ r ( 0 ) ∣ ∣ < ϵ \frac{||r_{(i)}||}{||r_{(0)}||}<\ 입실론∣∣ r( 0 )∣∣∣∣ r( 나는 )∣∣<ϵ , 알고리즘을 중지하고, 그렇지 않으면 (2)에서 계속 반복합니다. ϵ 엡실론ϵ 는 미리 설정된 작은 값이며 여기에서1 0 − 5 . 10^{-5}를 사용합니다.1 0− 5. 아래에서는 코드 를
구현하기 위해 이 프로세스를 따릅니다.
'''
共轭梯度法(Conjugate Gradients, CG)求优化解, m 为多项式次数
- dataset 数据集
- m 多项式次数, 默认为 5
- regularize 正则化参数, 若为 0 则不进行正则化
'''
def CG(dataset, m = 5, regularize = 0):
X = np.array([dataset[:, 0] ** i for i in range(m + 1)]).T
A = np.dot(X.T, X) + regularize * np.eye(m + 1)
assert np.all(np.linalg.eigvals(A) > 0), '矩阵不满足正定!'
b = np.dot(X.T, dataset[:, 1])
w = np.random.rand(m + 1)
epsilon = 1e-5
# 初始化参数
d = r = b - np.dot(A, w)
r0 = r
while True:
alpha = np.dot(r.T, r) / np.dot(np.dot(d, A), d)
w += alpha * d
new_r = r - alpha * np.dot(A, d)
beta = np.dot(new_r.T, new_r) / np.dot(r.T, r)
d = beta * d + new_r
r = new_r
# 基本收敛,停止迭代
if np.linalg.norm(r) / np.linalg.norm(r0) < epsilon:
break
return w
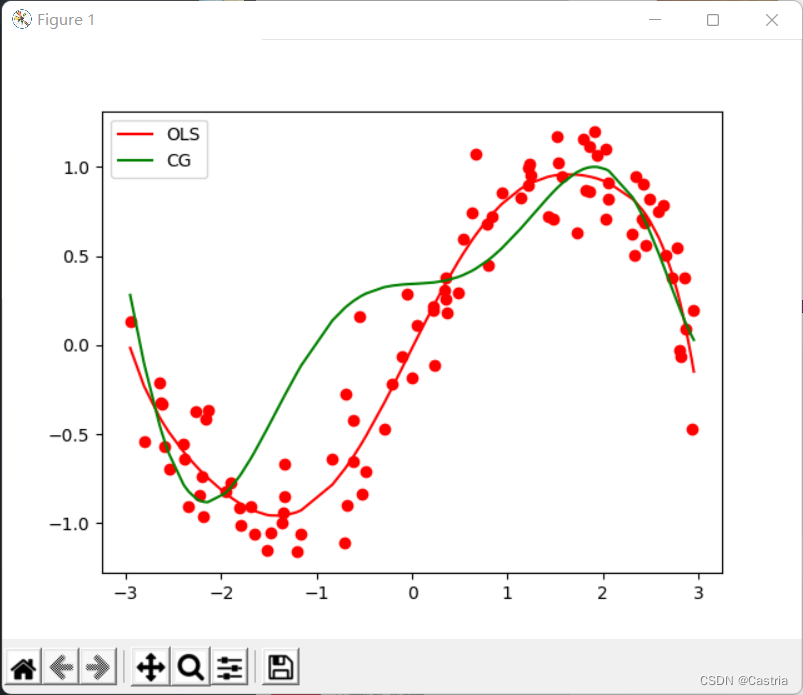
naive gradient descent 방법에 비해 conjugate gradient 방법은 빠르고 안정적으로 수렴합니다. 그러나 다항식의 차수가 증가함에 따라 적합도가 더 나빠집니다. m = 7에서 m=7중=도 7 을 참조하면, 다음과 같이 최소 자승법과 비교한다.
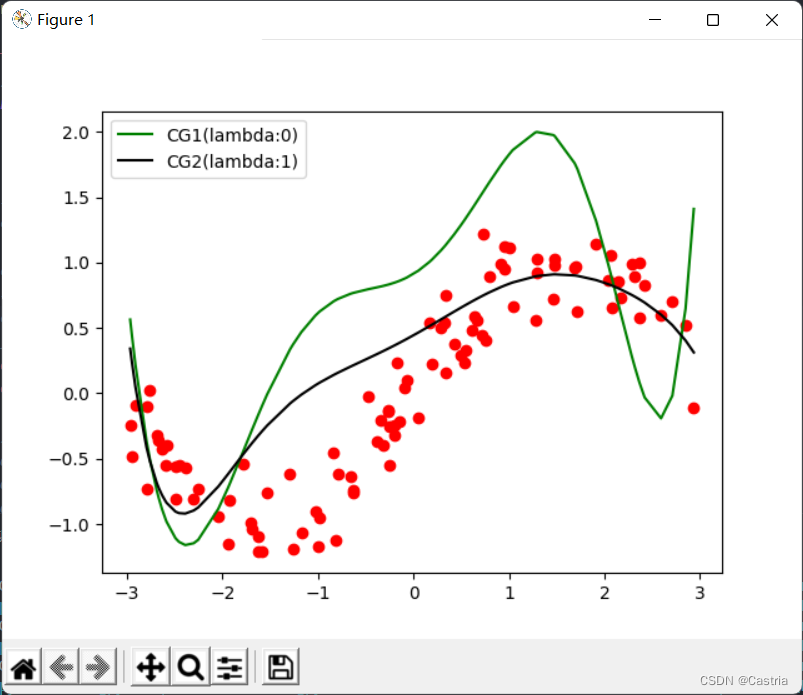
이때, 정규항에 의해 여전히 부분적으로 완화될 수 있다(도식은m = 7, λ = 1 m=7,\lambda=1중=7 ,엘=1 ):
마지막으로 4가지 방법(기본적으로 동일)의 피팅 이미지와 주요 기능이 첨부되었으며 매개변수는 실험 요구 사항에 따라 조정할 수 있습니다.
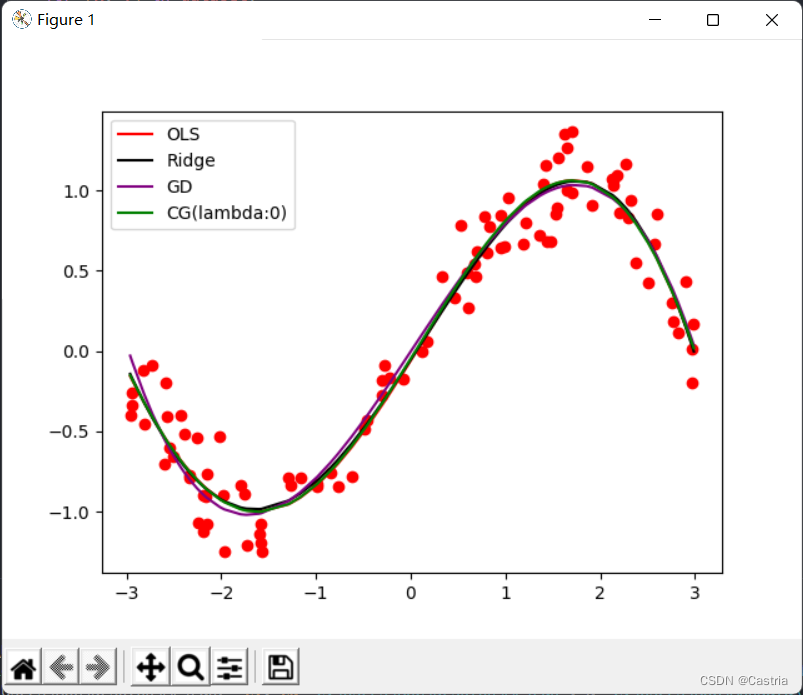
if __name__ == '__main__':
warnings.simplefilter('error')
dataset = get_dataset(bound = (-3, 3))
# 绘制数据集散点图
for [x, y] in dataset:
plt.scatter(x, y, color = 'red')
# 最小二乘法
coef1 = fit(dataset)
# 岭回归
coef2 = ridge_regression(dataset)
# 梯度下降法
coef3 = GD(dataset, m = 3)
# 共轭梯度法
coef4 = CG(dataset)
# 绘制出四种方法的曲线
draw(dataset, coef1, color = 'red', label = 'OLS')
draw(dataset, coef2, color = 'black', label = 'Ridge')
draw(dataset, coef3, color = 'purple', label = 'GD')
draw(dataset, coef4, color = 'green', label = 'CG(lambda:0)')
# 绘制标签, 显示图像
plt.legend()
plt.show()