Java 문서 검색 엔진
- 프로젝트 운영 효과
-
- 1. 검색엔진의 개념에 대해 간단히 설명해주세요.
- 둘째, 검색 엔진 구현 아이디어
- 3. 인덱스 모듈 파서 클래스 구현
- 넷째, 인덱스 모듈 구현 - 인덱스 클래스
-
- 4.1 색인 모듈 구현 - 색인 구조 구현
- 4.2 인덱스 모듈 구현 - 정방향 인덱스 구현
- 4.3 색인 모듈 실현 - 역 색인 구성 실현
- 4.4 가중치 공식을 개선하는 방법
- 4.5 인덱스 모듈 실현 - 단어 빈도 통계 실현
- 4.6 색인 모듈 실현 - 역 색인 코드 구현 구성
- 4.7 인덱스 모듈 구현 - 인덱스 배경 저장 및 로드
- 4.8 인덱스 모듈 실현 - 인덱스 파일 저장 실현
- 4.9 인덱스 모듈 구현 - 로딩 인덱스 구현
- 4.10 인덱스 모듈 구현 - 로드 및 저장 작업에 시간 추가
- 4.11 인덱스 모듈 구현 - 파서에서 인덱스 호출
- 4.12 인덱스 모듈 구현 - 인덱스 생성 확인
- 5. 인덱스 모듈 구현 - 인덱스 모듈 최적화
- 여섯, 검색 모듈 실현 - 검색 모듈 기사
- 7. 웹 모듈 구현 - 프런트엔드 및 백엔드 상호 작용 인터페이스에 동의
-
- 7.1 웹 모듈 구현 - Servlet 기반 백엔드 구현
- 7.2 웹 모듈 인증 백엔드 인터페이스 구현
- 7.3 웹 모듈 구현 - 페이지 구조 구현
- 7.4 웹 모듈 구현 - 페이지 스타일(CSS) 구현
- 7.5 웹 모듈 구현 - ajax를 통해 검색 결과 얻기
- 7.6 웹 모듈 구현 - 빨간색 표시 논리 구현
- 7.7 웹 모듈 구현 - 더 복잡한 쿼리 용어 테스트
- 7.8 웹 모듈 구현 - 불용어 처리
- 7.9 웹 모듈 구현 - 생성된 설명의 버그 처리
- 7.10 웹 모듈 구현 - 검색 결과 수
- 7.11 웹 모듈 구현 - 중복 문서에 대한 질문
- 7.12 웹 모듈 구현 - 다중 병합을 위한 아이디어
- 7.13 웹 모듈 구현 - 다중 병합 구현
- 7.14 웹 모듈 유효성 검사 가중치 병합 구현
- 8. 검색 엔진 - springboot로 변경 - 프로젝트 생성
프로젝트 운영 효과

1. 검색엔진의 개념에 대해 간단히 설명해주세요.
검색엔진이 무엇인지 먼저 알아볼까요?
우리가 자주 사용하는 Baidu 검색 엔진이 그러한 것인데, 페이지는 매우 단순해 보이지만 내부 코드는 매우 복잡합니다.

검색했을 때 검색 엔진의 핵심 기능은 사용자가 입력한 단어나 문장의 그룹을 찾는 것이었습니다.
케이크라는 단어처럼 이라고 부르며 查询词검색하는 내용도 검색어와 관련이 있어야 합니다.

일반적으로 검색된 콘텐츠는 거의 동일하지만 일부 표시된 결과에는 콘텐츠가 조금 더 있습니다.

클릭하면 상세 페이지(랜딩 페이지)로 이동합니다.
둘째, 검색 엔진 구현 아이디어
검색 엔진의 경우 먼저 많은 웹 페이지를 얻은 다음 사용자가 입력한 검색어에 따라 이러한 웹 페이지에서 검색해야 합니다.
그러나 다음과 같은 문제가 있습니다.
- 검색 엔진은 어떻게 페이지를 얻습니까?
답변: 이것은 주로 "크롤러"와 같은 프로그램을 포함합니다. 사실 크롤러는 Http 클라이언트 프로그램이기도 합니다. 각 웹사이트는 데이터를 수집하고 처리합니다.- 사용자가 쿼리 단어를 입력한 후 쿼리 단어를 현재 웹 페이지와 일치시키는 방법은 무엇입니까?
답변: 무차별 대입 검색을 사용한다고 가정하면 현재 1억 개의 데이터가 있는 경우 1억 개의 쿼리 단어를 검색해야 합니다. 그러면 효율성이 매우 낮아 검색 엔진은 Enter 키를 한 번만 눌러야 합니다. 결과를 즉시 얻으십시오. 이것은 확실히 불가능하므로 검색 엔진에서 매우 중요한 반전 인덱스와 같은 데이터 구조를 사용하는 데이터 구조가 필요합니다.
2.1 역지수 소개
먼저 전문 용어를 알아 보겠습니다.
-
문서(document) : 검색되는 각 웹 페이지를 의미
-
긍정적인 색인:
文档id을 참조文档内容하고 해당 콘텐츠를 빠르게 찾을 수 있도록 문서 ID를 제공합니다.- 문서 ID: 많은 정보를 크롤링할 때 ID 번호와 같이 각 정보를 구별하기 위해 서로 반복되지 않는 ID를 추가해야 합니다.
-
역색인: 매핑 관계를 말함
词역文档id列表색인은 정방향 색인과 정반대임 임의의 단어를 주고 어떤 문서에 있는지 물어볼테니 내용에 나온 단어가 많을 테니 주어진 것은 목록 입니다.- 단어: 문서의 내용은 완전히 분리되어 있지 않으며 내용에는 많은 단락, 문장 및 문장의 많은 단어가 포함됩니다.
간단한 예를 들어 보겠습니다.
이제 2개의 문서가 있습니다.
- 정방향 인덱스
| 문서 ID | 기사 |
|---|---|
| 1 | Lei Jun은 Xiaomi 전화를 발표했습니다. |
| 2 | Lei Jun은 기장 두 마리를 샀습니다. |
문서 ID=1에 따르면 첫 번째 콘텐츠를 빠르게 찾을 수 있고, 문서 ID=2에 따르면 두 번째 콘텐츠를 빠르게 찾을 수 있습니다 . 이러한 구조는 다음과 같습니다.正排索引
- 역지수
| 단어 | 단어가 나타난 문서의 ID |
|---|---|
| 레이 준 | 1,2 |
| 풀어 주다 | 1 |
| 구입 | 2 |
| 위로 | 1, 2 |
| 기장 | 1,2 |
| 휴대전화 | 1 |
위에서 단어가 등장하는 문서에 따라 ID를 찾아내면 이런 과정이 형성倒排索引 됩니다.
물론 이것은 위의 협정이지만, 모두의 효과가 이런 형태로 되어 있는 것뿐이고, 어쨌든 오셔도 됩니다. 큐큐
사실 우리가 평소에 게임을 하다보면 역지수와 같은 전문적인 단어를 자주 접하게 됩니다.
예를 들어 왕의 영광을 생각해보십시오. Daji 라는 영웅이 있고 그녀는 세 가지 기술을 가지고 있습니다.
1스킬 : 집단데미지
2스킬 : 스턴스킬
3스킬 : 집단데미지
이것은 긍정적인 지수와 유사 英雄名字합니다 英雄技能
이제 어떤 영웅의 2스킬이 기절 효과가 있는지 물어봅시다 .
영웅은 다음과 같습니다: 1. Daji, 2. Little Luban(적과 가까움)...
그래서 에 英雄的技能따르면英雄的名字
2.2 프로젝트 목표
Java 설명서용 검색 엔진 구현
Baidu 및 Bing과 같은 검색 엔진은 "전체 사이트 검색"에 속하며 전체 인터넷의 모든 웹 사이트를 검색합니다.
Zhihu 및 Baidu Tieba와 같은 특정 웹 사이트 내부의 콘텐츠만 검색하는 "사이트 검색"이라는 검색 엔진 유형도 현재 우리의 목표입니다.
자바 문서 웹사이트 자바 문서 주소 를 살펴보자
하지만 이 웹사이트에는 검색 ! ! ! 그래서 하나 만들어 봅시다! ! !
–
2.3 자바 문서 얻기
방금 말씀드린 것처럼 콘텐츠를 검색하려면 웹 페이지가 있어야 하며, 그런 다음 역색인을 만들어 검색할 수 있습니다.
두 가지 방법으로 얻을 수 있습니다.
- 크롤러를 통해 문서 가져오기
- 공식 웹 사이트에서 직접 압축 패키지를 다운로드하십시오.
우리는 두 번째 것을 사용하고 직접 다운로드하기만 하면 됩니다. 이를 달성하기 위해 크롤러를 사용할 필요가 없습니다.
웹사이트 주소: 클릭하여 다운로드로 이동
다운로드 후 열어서
내부의 HTML을 열어 공식 문서와 비교하여 동일한지 확인합니다.
공식 문서:
로컬 문서:
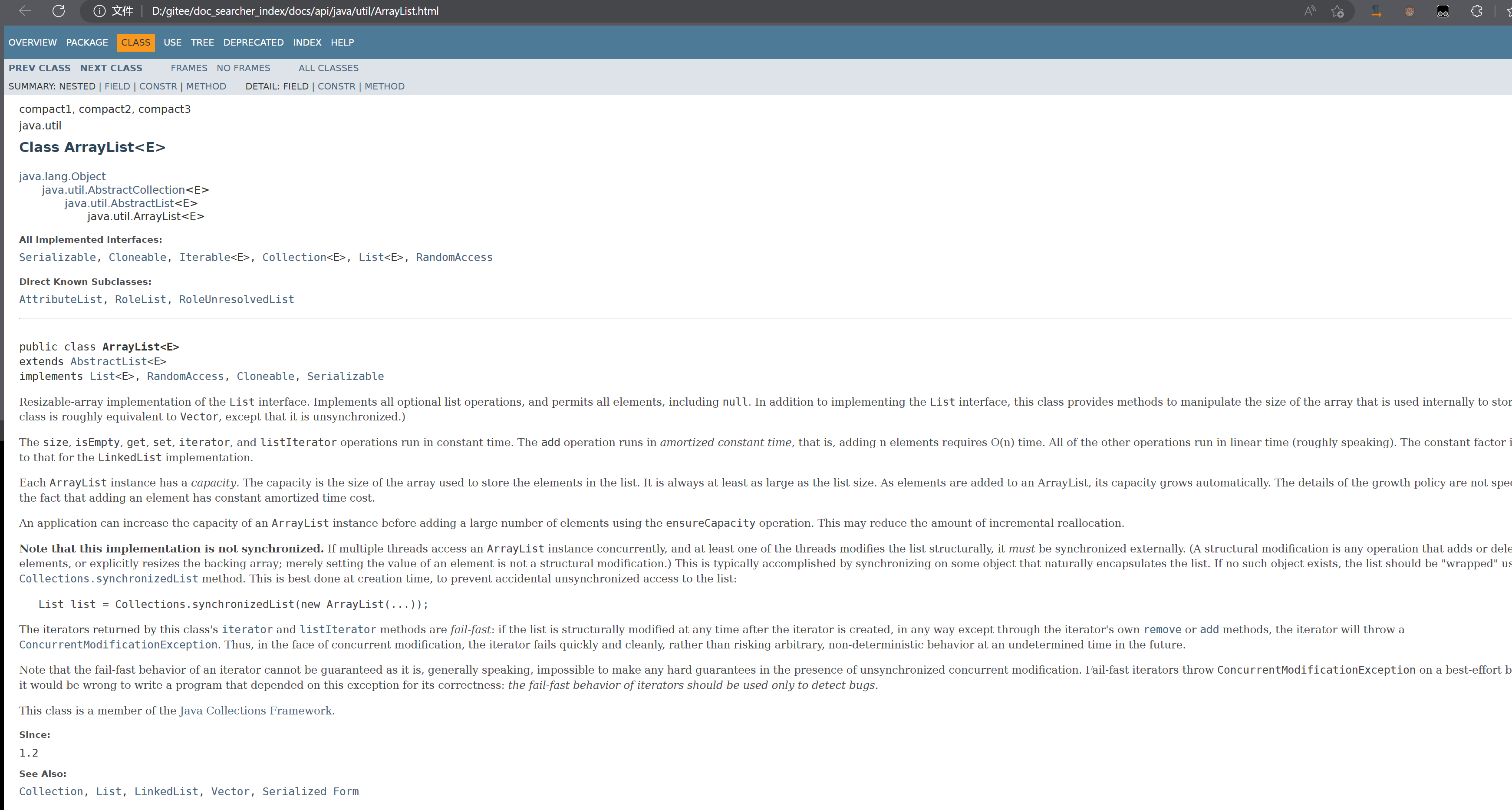
사실 핵심은 경로 간의 관계를 비교하는 것입니다: 마우스 오른쪽 버튼을 클릭하여 새 창에서 링크를 열면
여전히 특정 관계가 있음을 알 수 있습니다. 문서의 뒷면이지만 앞면은 다릅니다. 앞면은 우리 것입니다. 자신이 만든 경로입니다.
그런 관계를 위해,我们可以在本地基于离线文档来制做索引,当用户在搜索结果页点击具体的搜索结果的时候,就自动跳转到在线文档的页面。
2.4 모듈 구분
- 인덱스 모듈
1) 다운로드한 문서를 스캔하고, 문서의 내용을 분석하고, 순방향 색인 + 역방향 색인을 구축하고, 색인 내용을 파일에 저장합니다
. 기능
2. 검색 모듈
색인 모듈을 호출하여 전체 검색 프로세스 실현
입력: 사용자 쿼리
출력: 전체 검색 결과(많은 레코드 포함, 각 레코드에는 제목, 설명, 표시 URL이 있고 이동할 수 있음)
3. 웹 모듈
웹 페이지(프런트엔드 및 백엔드 포함) 형태로 사용자와 상호 작용할 수 있는 웹 모듈 프로그램 구현 필요
2.5 프로젝트 생성
Maven 프로젝트를 직접 생성하십시오.
2.6 단어 분할 이해
검색 엔진에서 사용자가 입력한 질의어는 반드시 단어일 필요는 없고 문장일 수도 있다.
단어 분할은 완전한 문장을 여러 단어로 나누는 것입니다.
I want to buy 양배추를 말로 I/want/buy/cabbage/
인간의 경우 단어 분할은 매우 간단하지만 기계의 경우 코드를 사용하여 단어를 분할해야 하므로 훨씬 더 어렵습니다.
전형적인 예:
핸들을 잡고 살고 싶은 삶을 살고 싶어
ㅋㅋㅋ 어렵지 않죠?
하지만 이와는 대조적으로 영어로 구분이라는 단어는 중간에 공백이 있기 때문에 매우 간단합니다.
이 경우 달성하기 위해 타사 라이브러리를 사용합니다.
물론 Baidu 및 기타 업체의 경우 오픈 소스 데이터베이스보다 훨씬 더 정확한 자체 단어 세분화 데이터베이스를 만드는 팀이 있습니다.
2.7 단어 분할의 원리
-
시소러스 기반
모든 "단어"를 철저히 열거하고 이러한 철저한 열거 결과를 사전 파일에
넣은 다음 문장의 내용을 순차적으로 가져오고 사전에서 다른 모든 단어를 확인하고 두 단어를 한 번에 한 번씩 확인할 수 있습니다.물론 여전히 정확하지 않은 단어가 있으며 인터넷에서 인기있는 단어는 작동하지 않습니다.
-
통계를 기반으로
"말뭉치"를 많이 모으는 것은 인위적인 기준에 해당하며, 그 단어들이 함께 있을 확률이 상대적으로 높다는 것을 알고 계실 것입니다.
단어 세분화의 실현은 "인공 지능", 훈련 모델의 전형적인 응용 시나리오입니다.
2.8 타사 단어 분할 라이브러리 사용
꽤 많은 Java 타사 단어 분할 라이브러리가 있으며 ansj 이 .
<!-- https://mvnrepository.com/artifact/org.ansj/ansj_seg -->
<dependency>
<groupId>org.ansj</groupId>
<artifactId>ansj_seg</artifactId>
<version>5.1.6</version>
</dependency>
빨간색이면 새로 고침을 클릭하고 빨간색이 아니면 다음을 클릭하십시오.
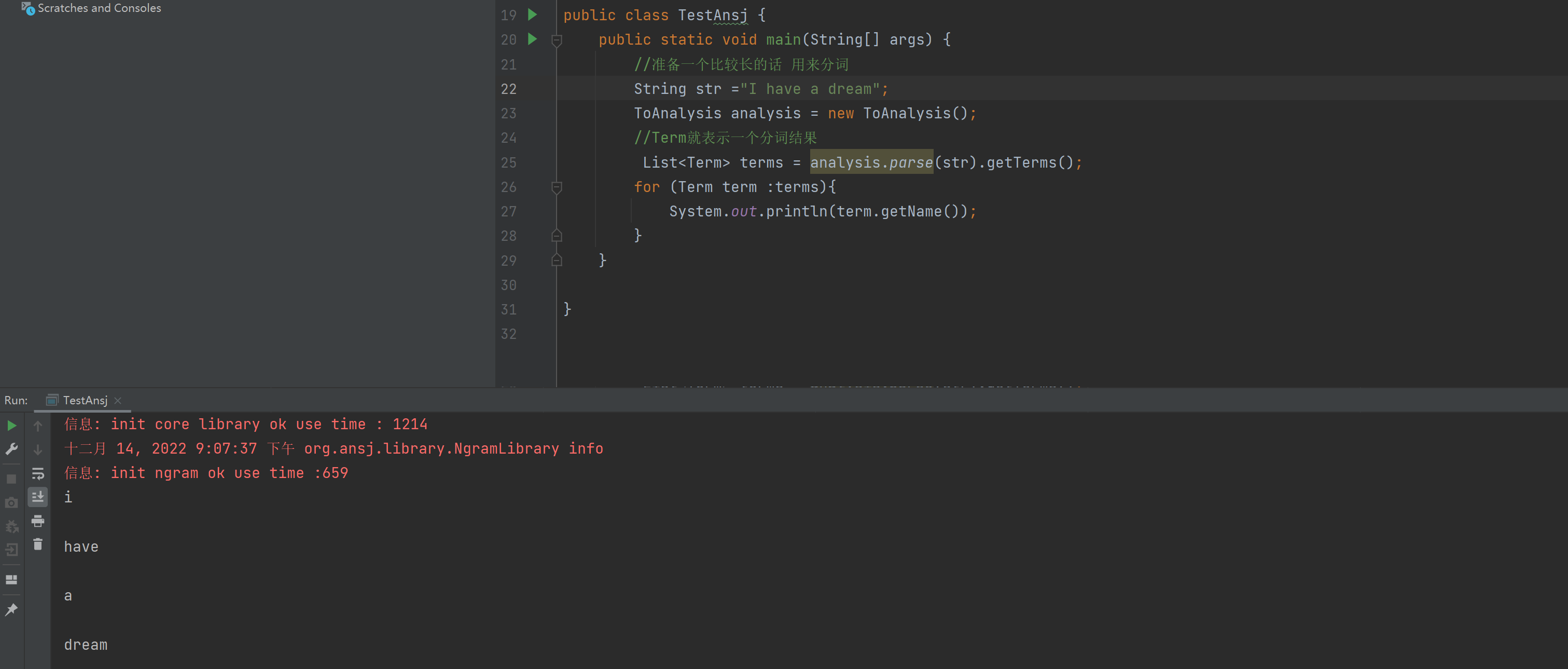
코드를 작성해 봅시다:
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.ToAnalysis;
import java.util.List;
/**
* Created by Lin
* Description:
* User: Administrator
* Date: 2022-12-14
* Time: 19:29
*/
public class TestAnsj {
public static void main(String[] args) {
//准备一个比较长的话 用来分词
String str ="小明毕业于清华大学,后来又去蓝翔技校和新东方去深照,擅长使用计算机控制挖掘机来炒菜。";
ToAnalysis analysis = new ToAnalysis();
//Term就表示一个分词结果
List<Term> terms = analysis.parse(str).getTerms();
for (Term term :terms){
System.out.println(term.getName());
}
}
}
우리는 ToAnalysis를 사용합니다. 아이디어가 대중화되면 직접 패키지를 수동으로 가져옵니다.
우리는 parse() 메서드를 사용하지만 이 메서드는 타사 동의어 사전의 Result 유형을 반환합니다. List와 유사한 컬렉션을 얻고 싶기 때문에 List 유형을 반환하는 getTerms() 메서드를 사용합니다.

그런 다음 작업 결과는 다음과 같습니다

. 단어가 분할되었지만 빨간색이 무엇인지 알 수 있습니다 ** 실제로 단어가 분할되면 일부 사전 파일이로드되어 단어 분할 속도가 빨라질 수 있습니다 그리고 정확도는 향상될 수 있지만 이러한 사전 파일이 없으면 ansj도 빠르고 정확하게 단어를 분리할 수 있습니다**,
영문 대문자는 소문자로 표시됩니다.
3. 인덱스 모듈 파서 클래스 구현
다음으로 인덱스 모듈을 구현합니다.
우리는 이 클래스가 이전에 다운로드한 문서를 읽고 인덱싱을 완료할 것으로 기대합니다.
먼저 인덱스 데이터 구조를 구현하기 위해 Parser 클래스를 만듭니다.
다음은 이 클래스가 구체적으로 수행하는 몇 가지 작업입니다.
1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到
2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引
3.把内存中构造好的索引数据结构,保存到指定的文件中
첫 번째 요점이 무엇을 의미하는지 살펴보겠습니다.
공식 문서는 api 폴더에 있으므로 해당 폴더의 모든 내용을 원합니다.
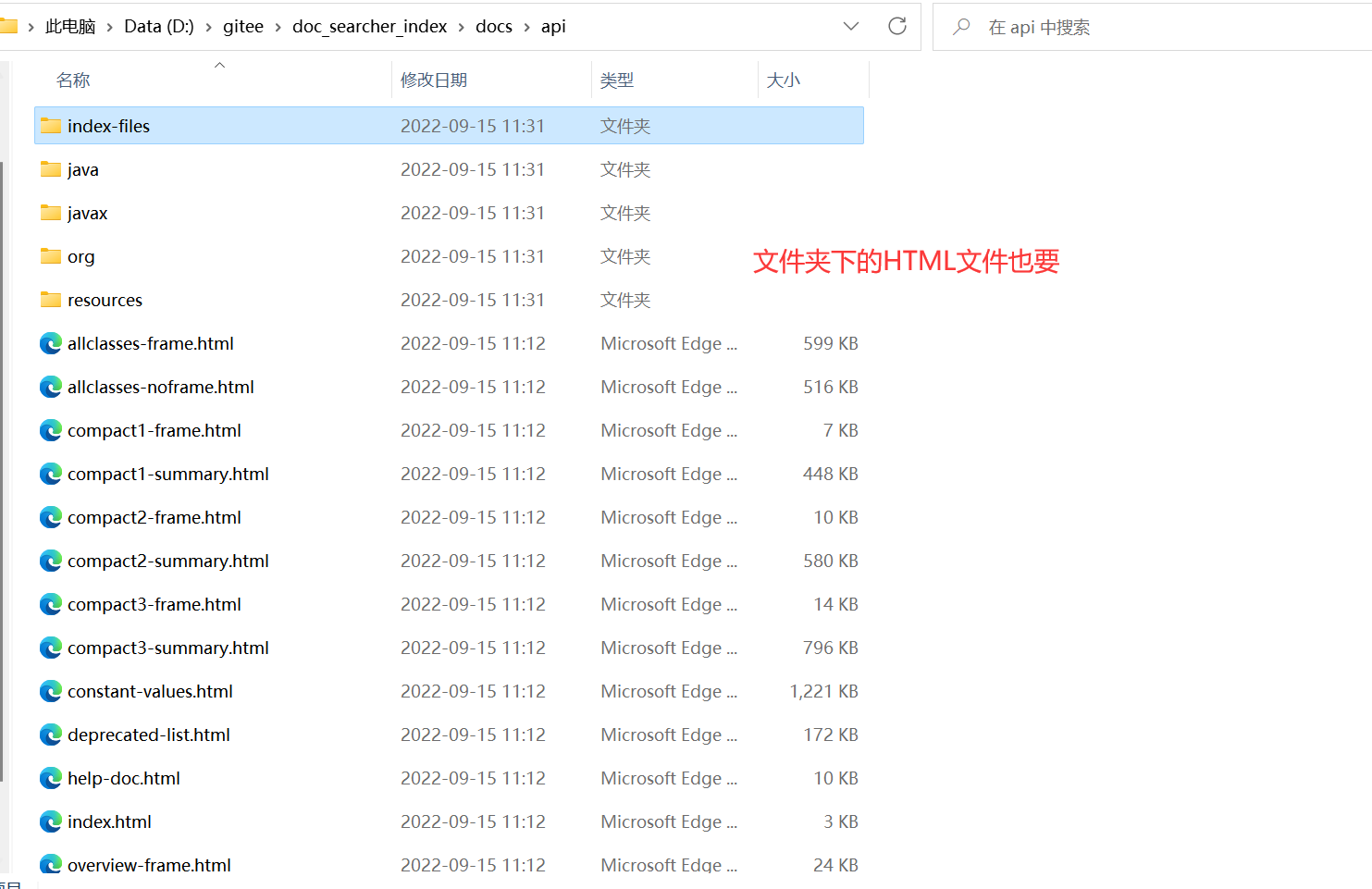
두 번째 요점의 의미: 해당 폴더 
세 번째 요점의 의미: 완성된 색인을 파일에 넣고 프로그램이 나중에 색인을 읽도록 합니다.
현재 단계 코드 블록:
public class Parser {
//先指定一个加载文档的路径 ,由于是固定路径 我们使用 static 类属性 不需要变final
private static final String INPUT_PATH ="D:\\gitee\\doc_searcher_index\\docs\\api"; // 只需要api文件夹下的文件
public void run(){
//整个Parser类的入口
//1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到
//2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引
//3.把内存中构造好的索引数据结构,保存到指定的文件中
}
public static void main(String[] args) {
//通过main方法来实现整个制作索引的过程
Parser parser = new Parser();
parser.run();
}
}
3.1 색인 모듈 구현 - 재귀적으로 파일 열거
모든 파일을 열거하고 컬렉션에 넣고 먼저 코드를 추가합니다.
import java.io.File;
import java.util.ArrayList;
/**
* Created by Lin
* Description:
* User: Administrator
* Date: 2022-12-15
* Time: 19:15
*/
public class Parser {
//先指定一个加载文档的路径 ,由于是固定路径 我们使用 static 类属性 不需要变final
private static final String INPUT_PATH ="D:\\gitee\\doc_searcher_index\\docs\\api"; // 只需要api文件夹下的文件
public void run(){
//整个Parser类的入口
//1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到
ArrayList<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH,fileList);
//2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引
//3.把内存中构造好的索引数据结构,保存到指定的文件中
System.out.println(fileList);
//看看文件个数
System.out.println(fileList.size());
}
//第一个参数表示从那个目录开始进行遍历,第二个目录表示递归得到的结果
private void enumFile(String inputPath, ArrayList<File> fileList) {
//我们需要把String类型的路径变成文件类 好操作点
File rootPath = new File(inputPath);
//listFiles()类似于Linux的ls把当前目录中包含的文件名获取到
//使用listFiles只可以看见一级目录,想看到子目录需要递归操作
File[] files = rootPath.listFiles();
for (File file : files) {
//根据当前的file的类型,觉得是否递归
//如果file是普通文件就把file加入到listFile里面
//如果file是一个目录 就递归调用enumFile这个方法,来进一步获取子目录的内容
if (file.isDirectory()){
//根路径要变
enumFile(file.getAbsolutePath(),fileList);
}else {
//普通文件
fileList.add(file);
}
}
}
public static void main(String[] args) {
//通过main方法来实现整个制作索引的过程
Parser parser = new Parser();
parser.run();
}
}
여기에서 listFile() 함수를 사용하여 대상 경로 아래의 현재 디렉토리를 가져오는 enumFile() 메서드를 만들었습니다.
모든 파일을 가져오는 아이디어는 디렉토리인지 파일인지 판단하여 파일인 경우 파일을 ArrayList에 추가 fileList = new ArrayList<>(), 디렉토리인 경우 계속 재귀 함수에서 자세한 내용은 코드 주석을 참조하십시오.
마지막으로 결과를 살펴보십시오.
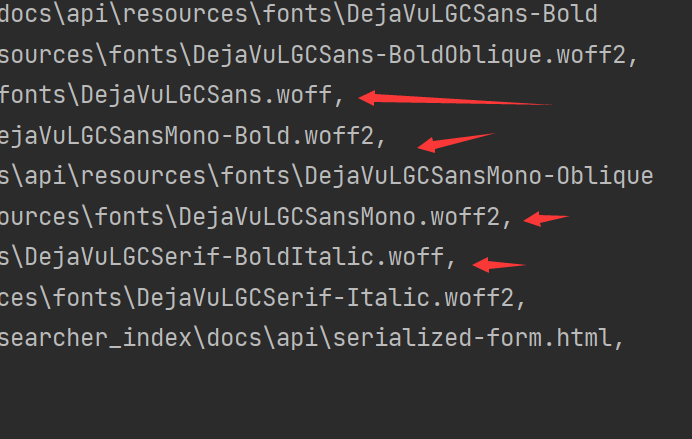
HTML 파일뿐만 아니라 다른 파일도 있는 것으로 나타났습니다. 제거해야 합니다. HTML 파일만 있습니다.
3.2 HTML이 아닌 파일 제외
비 HTML 파일을 제외하는 아이디어는 실제로 매우 간단합니다 파일의 접미사가 무엇인지 확인하고 endWith() 함수를 사용하여 식별할 수 있습니다.
import java.io.File;
import java.util.ArrayList;
/**
* Created by Lin
* Description:
* User: Administrator
* Date: 2022-12-15
* Time: 19:15
*/
public class Parser {
//先指定一个加载文档的路径 ,由于是固定路径 我们使用 static 类属性 不需要变final
private static final String INPUT_PATH ="D:\\gitee\\doc_searcher_index\\docs\\api"; // 只需要api文件夹下的文件
public void run(){
//整个Parser类的入口
//1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到
ArrayList<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH,fileList);
//2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引
//3.把内存中构造好的索引数据结构,保存到指定的文件中
System.out.println(fileList);
System.out.println(fileList.size());
}
//第一个参数表示从那个目录开始进行遍历,第二个目录表示递归得到的结果
private void enumFile(String inputPath, ArrayList<File> fileList) {
//我们需要把String类型的路径变成文件类 好操作点
File rootPath = new File(inputPath);
//listFiles()类似于Linux的ls把当前目录中包含的文件名获取到
//使用listFiles只可以看见一级目录,想看到子目录需要递归操作
File[] files = rootPath.listFiles();
for (File file : files) {
//根据当前的file的类型,觉得是否递归
//如果file是普通文件就把file加入到listFile里面
//如果file是一个目录 就递归调用enumFile这个方法,来进一步获取子目录的内容
if (file.isDirectory()){
//根路径要变
enumFile(file.getAbsolutePath(),fileList);
}else {
//只针对HTML文件
if(file.getAbsolutePath().endsWith(".html")){
//普通HTML文件
fileList.add(file);
}
}
}
}
public static void main(String[] args) {
//通过main方法来实现整个制作索引的过程
Parser parser = new Parser();
parser.run();
}
}
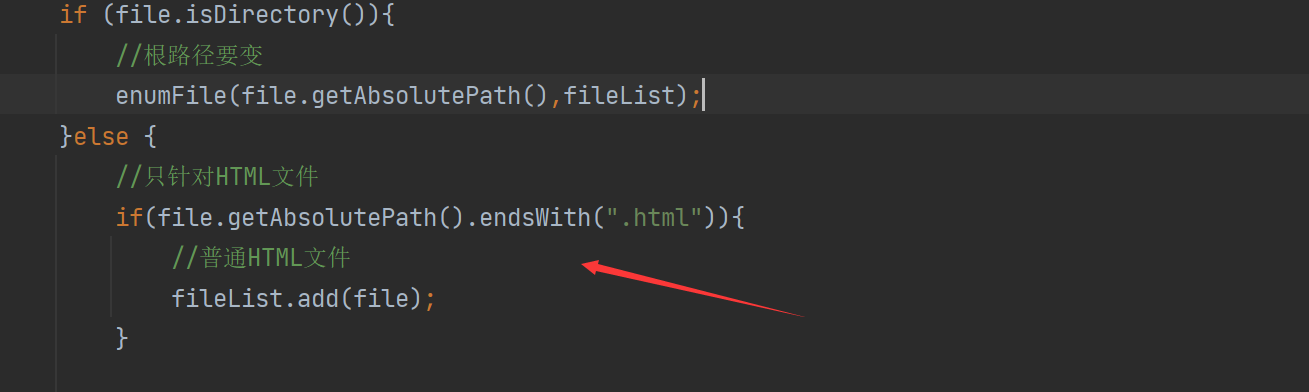
이 판단을 추가하십시오.
3.3 색인 모듈 구현 - HTML 구문 분석
HTML 구문 분석의 의미: 검색 결과 중 하나에 제목, 설명 및 표시 URL이 포함되어 있습니다. 이러한 정보는 구문 분석할 HTML에서 가져옵니다.
따라서 현재 HTML을 파싱하는 작업은 전체 HTML 파일의 제목, 설명 및 URL을 얻는 것입니다.실제로 우리의 핵심은 이것이 무엇인지 이해하는 것 描述입니다.
설명: 텍스트의 요약이라고 볼
수 있으므로 설명을 얻으려면 먼저 전체 텍스트를 가져와야 하므로 설명을 무시하고 텍스트를 먼저 얻을 수 있는 방법을 찾아봅시다.
따라서 현재 우리의 임무는 다음과 같습니다.
- HTML 제목을 구문 분석
- HTML에 해당하는 기사 파싱
- HTML에 해당하는 텍스트 파싱(텍스트가 있는 경우에만 후속 설명 있음)
import java.io.File;
import java.util.ArrayList;
/**
* Created by Lin
* Description:
* User: Administrator
* Date: 2022-12-15
* Time: 19:15
*/
public class Parser {
//先指定一个加载文档的路径 ,由于是固定路径 我们使用 static 类属性 不需要变final
private static final String INPUT_PATH ="D:\\gitee\\doc_searcher_index\\docs\\api"; // 只需要api文件夹下的文件
public void run(){
//整个Parser类的入口
//1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到
ArrayList<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH,fileList);
//2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引
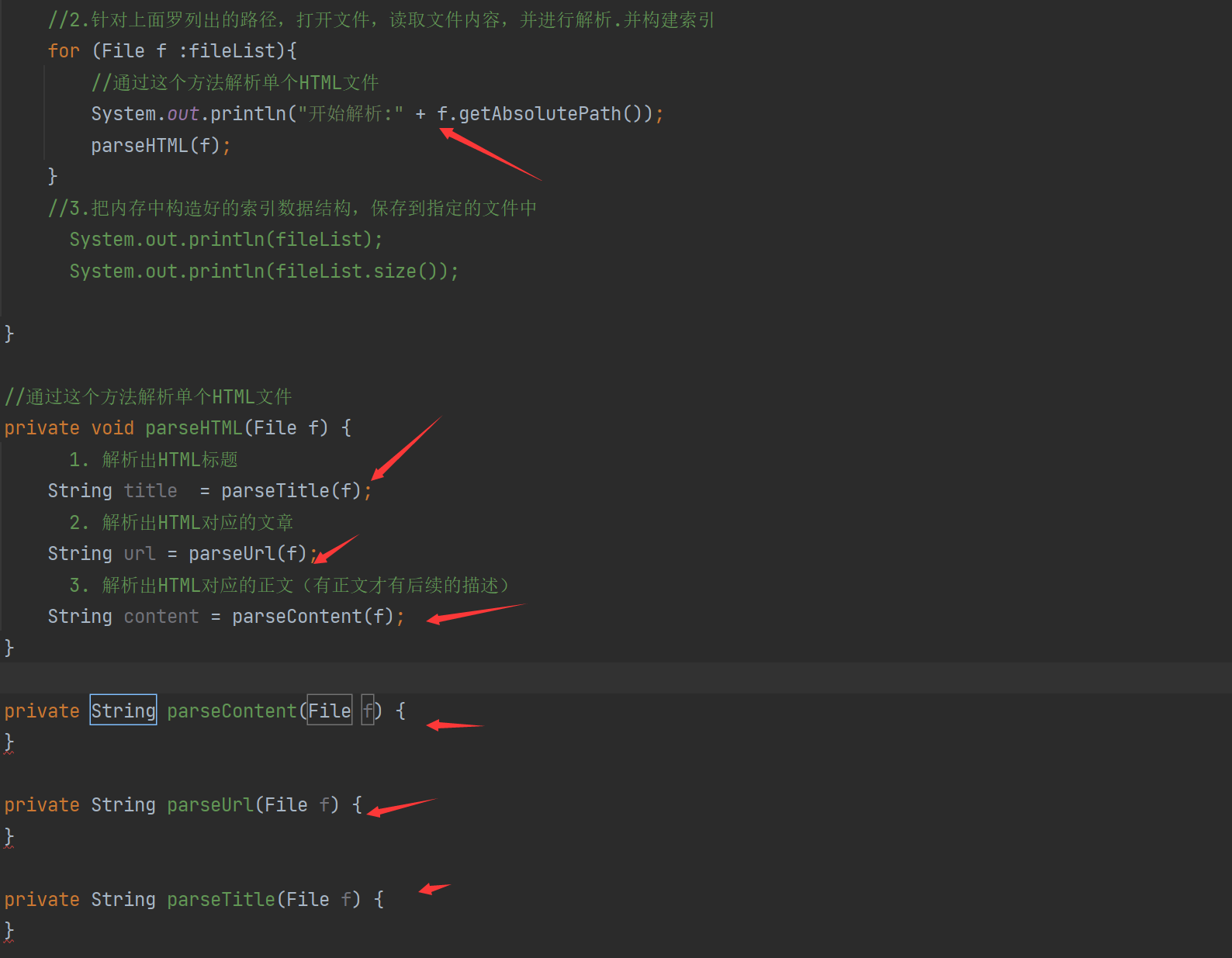
for (File f :fileList){
//通过这个方法解析单个HTML文件
System.out.println("开始解析:" + f.getAbsolutePath());
parseHTML(f);
}
//3.把内存中构造好的索引数据结构,保存到指定的文件中
// System.out.println(fileList);
// System.out.println(fileList.size());
}
//通过这个方法解析单个HTML文件
private void parseHTML(File f) {
// 1. 解析出HTML标题
String title = parseTitle(f);
// 2. 解析出HTML对应的文章
String url = parseUrl(f);
// 3. 解析出HTML对应的正文(有正文才有后续的描述)
String content = parseContent(f);
}
private String parseContent(File f) {
}
private String parseUrl(File f) {
}
private String parseTitle(File f) {
}
//第一个参数表示从那个目录开始进行遍历,第二个目录表示递归得到的结果
private void enumFile(String inputPath, ArrayList<File> fileList) {
//我们需要把String类型的路径变成文件类 好操作点
File rootPath = new File(inputPath);
//listFiles()类似于Linux的ls把当前目录中包含的文件名获取到
//使用listFiles只可以看见一级目录,想看到子目录需要递归操作
File[] files = rootPath.listFiles();
for (File file : files) {
//根据当前的file的类型,觉得是否递归
//如果file是普通文件就把file加入到listFile里面
//如果file是一个目录 就递归调用enumFile这个方法,来进一步获取子目录的内容
if (file.isDirectory()){
//根路径要变
enumFile(file.getAbsolutePath(),fileList);
}else {
//只针对HTML文件
if(file.getAbsolutePath().endsWith(".html")){
//普通HTML文件
fileList.add(file);
}
}
}
}
public static void main(String[] args) {
//通过main方法来实现整个制作索引的过程
Parser parser = new Parser();
parser.run();
}
}
이 섹션에서는 구문 분석 HTML 클래스를 추가하고 사용해야 하는 콘텐츠, 제목 및 URL 클래스를 구문 분석합니다.
3.4 색인 모듈 구현 - 제목 구문 분석
다음으로 HTML 제목 구문 분석을 시작합니다.
두 가지 아이디어가 있습니다.
- HTML 파일 의 제목 태그 와 제목 에서 내용 찾기
- 파일 이름 얻기 특정 HTML 제목을 얻으십시오. 각 파일 이름은 HTML 제목과 유사한 것 같습니다.
그래서 우리는 제목을 얻기 위해 파일 이름을 얻기로 직접 선택합니다.
여기에서는 getName() 함수를 사용합니다:

출력 결과는 HTML 파일 이름을 가져옵니다

. 필요한 검색 결과는 접미사를 붙일 필요가 없는 제목이므로 제거해야 합니다.
접미사 구현 아이디어 제거: 하위 문자열()을 사용하여 달성
여기에 작은 문제가 있습니다. 어떻게 .html를 이 하위 문자열()에는 열기 전에 닫혔다가 열리는 버전이 있습니다 找出总长度减去.html的长度. .html의 앞부분만 가져오면 됩니다.
public static void main(String[] args) {
File f = new File("D:\\gitee\\doc_searcher_index\\docs\\api\\java\\util\\ArrayList.html");
System.out.println(f.getAbsolutePath());
System.out.println(f.getName().substring(0,f.getName().length()-".html".length()));
}
.html도 문자열이며 length()를 사용할 수 있습니다.
parseTitle() 구현:
private String parseTitle(File f) {
//获取文件名
String name = f.getName();
return name.substring(0,name.length()-".html".length());
}
–
3.5 인덱스 모듈 구현 - URL 구문 분석 아이디어
사실 실제 검색엔진의 display url은 redirect url과 다릅니다: 일부는 검색엔진 서버를 먼저 통과한 다음 해당 페이지로 이동

해야 하지만 여기서는 그렇게 많이 생각할 필요 없이 그냥 하나만 사용합니다. URL을 직접 표시하고 점프합니다.
다음과 같은 이유가 있기 때문에 검색 엔진의 서버로 이동해야 하는 이유를 궁금해하는 사람들이 있습니다.
- 광고 결과일 경우 클릭수에 따라 과금이 필요합니다.
- 자연스러운 검색 결과를 위해서는 사용자 경험이 클릭을 기반으로 최적화되어야 합니다.
URL 실현에 대한 우리의 아이디어:
최종적으로 원하는 효과는 사용자가 검색 결과를 클릭하여 해당 온라인 문서 페이지로 이동할 수 있기 때문입니다.
- 그런 다음 두 개의 Java API 문서, 온라인 문서와 오프라인 문서가
있고 경로가 동일한 지점을 가지고 있음을 발견했습니다.https://docs.oracle.com/javase/8/docs/api/java/util/ArrayList.html
D:/gitee/doc_searcher_index/docs/api/java/util/ArrayList.html
은 doc 디렉토리 동일하지 않음, 다른 모든 것은 동일,
우리의 마지막 점프 목적지는 공식입니다: "https://docs.oracle.com/javase/8/docs/api/java/util/ArrayList.html"
그래서 우리는 스플라이싱 방법을 사용할 수 있습니다. 먼저 로컬 경로의 후반부를 미리 저장하고 공식 웹사이트 앞에서 고정 경로와 스플라이싱 하여 그들의 관계를 실현할 수 있습니다.
3.6 인덱스 모듈 실현 - URL 코드 구현 구문 분석
테스트 클래스를 테스트합니다.
private static final String INPUT_PATH ="D:\\gitee\\doc_searcher_index\\docs\\api"; // 只需要api文件夹下的文件
public static void main(String[] args) {
File f = new File("D:\\gitee\\doc_searcher_index\\docs\\api\\java\\util\\ArrayList.html");
//固定的前缀
String path = "https://docs.oracle.com/javase/8/docs/api/";
//只放一个参数的意思是:前面一段都不需要,取后面的一段
String path2= f.getAbsolutePath().substring(INPUT_PATH.length());
String result = path + path2;
System.out.println(result);
}
사실, 그것은 substring을 사용한 splicing입니다: INPUT_PATH우리 의 것은 앞의 공식 경로와 다른 경로입니다. 우리는 그것을 제거하고 뒤를 취한 다음 splice하면 됩니다.
코드를 브라우저에 복사한 후 브라우저가 자체적으로 분석하여 전체 URL을 일반 URL로 변환하기 때문에 직접 replaceall을 사용하여 슬래시를 바꾸거나 무시할 수도 있습니다. 주요 브라우저는 이러한 문제가 거의 없습니다.

private String parseUrl(File f) {
//固定的前缀
String path = "https://docs.oracle.com/javase/8/docs/api/";
//只放一个参数的意思是:前面一段都不需要,取后面的一段
String path2= f.getAbsolutePath().substring(INPUT_PATH.length());
return path + path2;
}
3.7 인덱스 모듈 구현 - 텍스트 구문 분석 아이디어
정규식 또는 간단하고 조잡한 방법과 같이 태그를 제거하는 방법에는 여러 가지가 있습니다.
우리는 간단하고 거칠게 사용합니다.
HTML 태그는 매우 특징적입니다.이 HTML의 각 문자를 차례로 읽고 추출된 각 문자를 판단합니다.
결과가 <(왼쪽 꺾쇠괄호)인지 확인한 다음 >(오른쪽 꺾쇠괄호)가 나올 때까지 이 위치에서 결과에 이러한 문자를 넣지 마십시오. 즉, 꺾쇠괄호가 아니면 직접 넣으십시오. 복사 현재 문자를 결과로(StringBuilder)
데모:
<div>내용입니다</div>
첫 번째 <를 읽으면 다음 내용을 복사하지 않고 >를 읽으면 다음 내용을 복사하기 시작하므로 플래그 비트를 설정할 수 있습니다. <이면 거짓으로 복사를 닫습니다. >인 경우 복사를 위해 여는 것이 true입니다.
어떤 사람들은 콘텐츠에 < 또는 > 문자가 있으면 어떻게 될까요? 실제로 htm에서는 내용의 <>를 < 또는 >로 대체해야 합니다.
3.8 인덱스 모듈 구현 - 텍스트 구문 분석 코드 구현
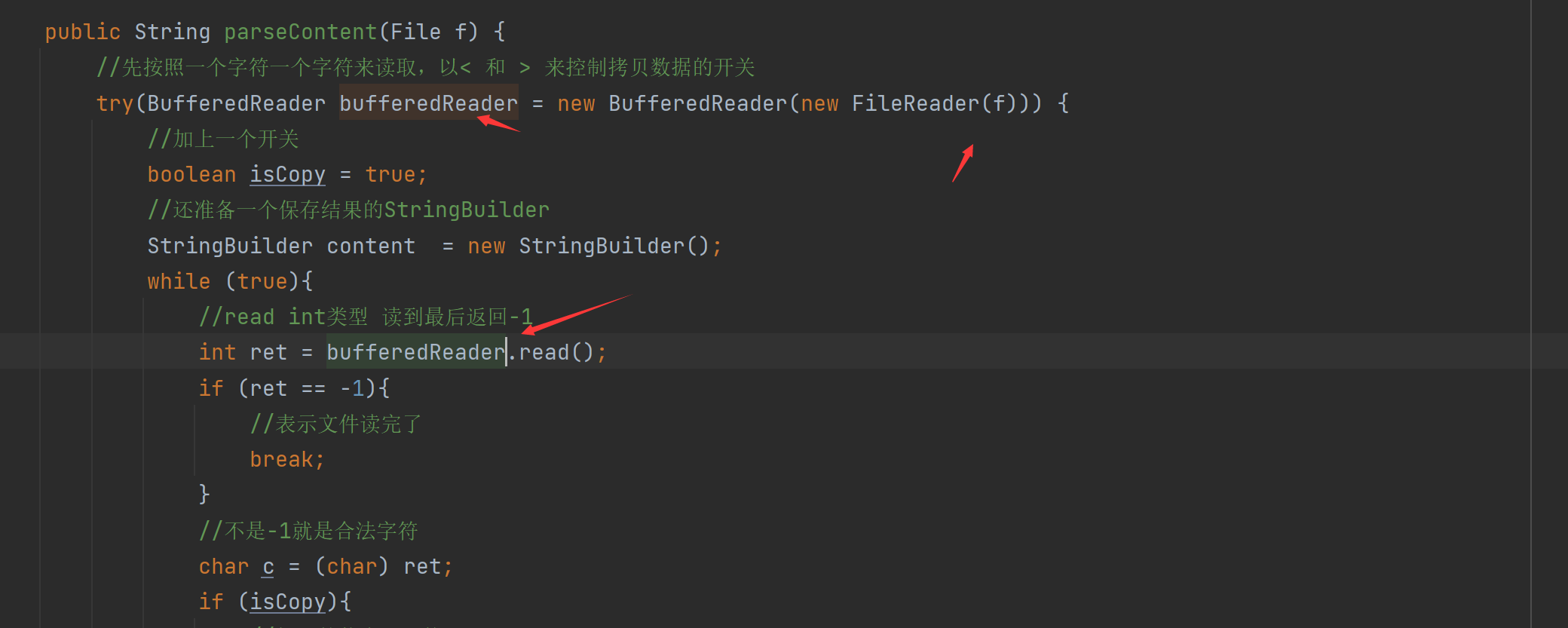
public String parseContent(File f) {
//先按照一个字符一个字符来读取,以< 和 > 来控制拷贝数据的开关
try(FileReader fileReader = new FileReader(f)) {
//加上一个开关
boolean isCopy = true;
//还准备一个保存结果的StringBuilder
StringBuilder content = new StringBuilder();
while (true){
//read int类型 读到最后返回-1
int ret = fileReader.read();
if (ret == -1){
//表示文件读完了
break;
}
//不是-1就是合法字符
char c = (char) ret;
if (isCopy){
//打开的状态可以拷贝
if (c == '<'){
isCopy =false;
continue;
}
//判断是否是换行
if (c == '\n' || c == '\r'){
// 是换行就变成空格
c = ' ';
}
//其他字符进行拷贝到StringBuilder中
content.append(c);
}else{
//
if (c=='>'){
isCopy= true;
}
}
}
return content.toString();
} catch (IOException e) {
e.printStackTrace();
}
return "";
}
이 코드에서 주의해야 할 점은 StringBuilder 문자 스트림을 닫는 것입니다. 그렇지 않으면 리소스 누수가 발생하고 닫히면 어떻게 해야 하는지, 열려 있으면 어떻게 해야 하는지 논리적인 문제입니다.
3.9 파서 클래스 요약
이제 앞으로 사용될 HTML 페이지의 제목, 내용, URL을 파싱하고
다음으로 인덱스 클래스를 생성하여 파싱된 정보를 인덱스에 넣고 메모리에 내장된 인덱스를 지정된 파일.
파서 클래스 코드:
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
/**
* Created by Lin
* Description:
* User: Administrator
* Date: 2022-12-15
* Time: 19:15
*/
public class Parser {
//先指定一个加载文档的路径 ,由于是固定路径 我们使用 static 类属性 不需要变final
private static final String INPUT_PATH ="D:\\gitee\\doc_searcher_index\\docs\\api"; // 只需要api文件夹下的文件
public void run(){
//整个Parser类的入口
//1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到
ArrayList<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH,fileList);
//2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引
for (File f :fileList){
//通过这个方法解析单个HTML文件
System.out.println("开始解析:" + f.getAbsolutePath());
parseHTML(f);
}
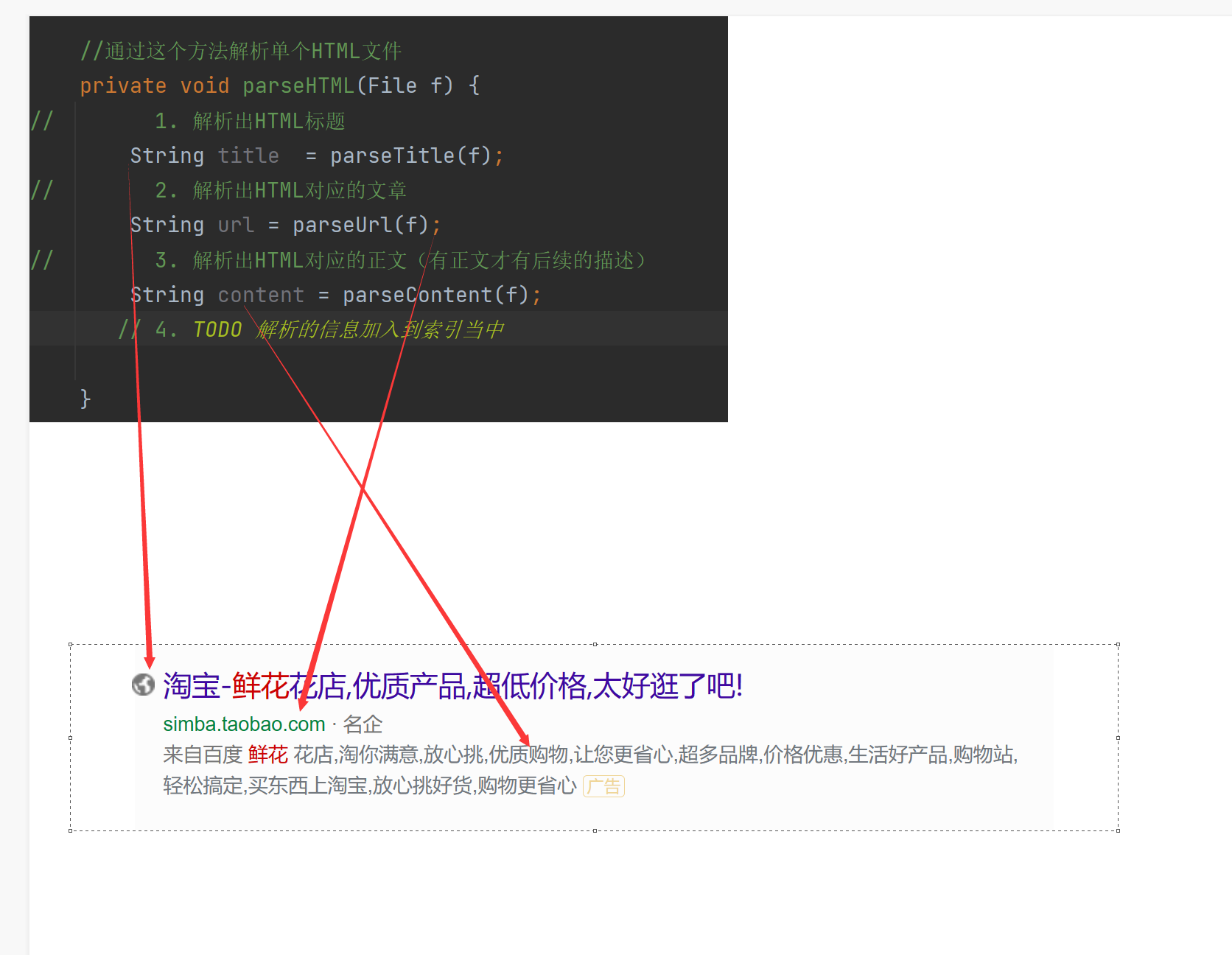
//3. TODO 把内存中构造好的索引数据结构,保存到指定的文件中
}
//通过这个方法解析单个HTML文件
private void parseHTML(File f) {
// 1. 解析出HTML标题
String title = parseTitle(f);
// 2. 解析出HTML对应的文章
String url = parseUrl(f);
// 3. 解析出HTML对应的正文(有正文才有后续的描述)
String content = parseContent(f);
// 4. TODO 解析的信息加入到索引当中
}
public String parseContent(File f) {
//先按照一个字符一个字符来读取,以< 和 > 来控制拷贝数据的开关
try(FileReader fileReader = new FileReader(f)) {
//加上一个开关
boolean isCopy = true;
//还准备一个保存结果的StringBuilder
StringBuilder content = new StringBuilder();
while (true){
//read int类型 读到最后返回-1
int ret = fileReader.read();
if (ret == -1){
//表示文件读完了
break;
}
//不是-1就是合法字符
char c = (char) ret;
if (isCopy){
//打开的状态可以拷贝
if (c == '<'){
isCopy =false;
continue;
}
//判断是否是换行
if (c == '\n' || c == '\r'){
// 是换行就变成空格
c = ' ';
}
//其他字符进行拷贝到StringBuilder中
content.append(c);
}else{
//
if (c=='>'){
isCopy= true;
}
}
}
return content.toString();
} catch (IOException e) {
e.printStackTrace();
}
return "";
}
private String parseUrl(File f) {
//固定的前缀
String path = "https://docs.oracle.com/javase/8/docs/api/";
//只放一个参数的意思是:前面一段都不需要,取后面的一段
String path2= f.getAbsolutePath().substring(INPUT_PATH.length());
return path + path2;
}
private String parseTitle(File f) {
//获取文件名
String name = f.getName();
return name.substring(0,name.length()-".html".length());
}
//第一个参数表示从那个目录开始进行遍历,第二个目录表示递归得到的结果
private void enumFile(String inputPath, ArrayList<File> fileList) {
//我们需要把String类型的路径变成文件类 好操作点
File rootPath = new File(inputPath);
//listFiles()类似于Linux的ls把当前目录中包含的文件名获取到
//使用listFiles只可以看见一级目录,想看到子目录需要递归操作
File[] files = rootPath.listFiles();
for (File file : files) {
//根据当前的file的类型,觉得是否递归
//如果file是普通文件就把file加入到listFile里面
//如果file是一个目录 就递归调用enumFile这个方法,来进一步获取子目录的内容
if (file.isDirectory()){
//根路径要变
enumFile(file.getAbsolutePath(),fileList);
}else {
//只针对HTML文件
if(file.getAbsolutePath().endsWith(".html")){
//普通HTML文件
fileList.add(file);
}
}
}
}
public static void main(String[] args) {
//通过main方法来实现整个制作索引的过程
Parser parser = new Parser();
parser.run();
}
}
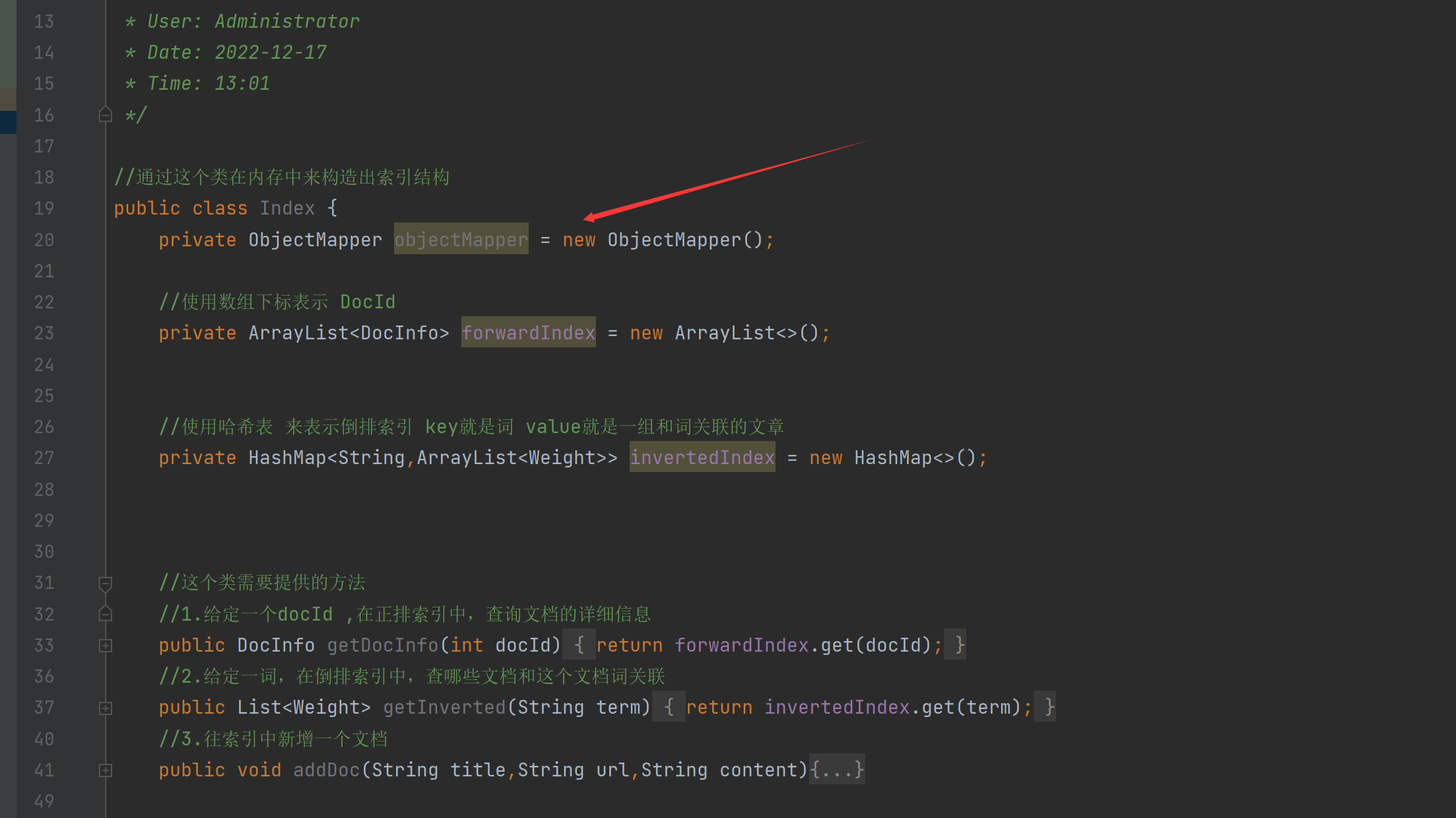
넷째, 인덱스 모듈 구현 - 인덱스 클래스
Index 클래스를 생성해야 합니다. 이 클래스의 기본 구현은 메모리에 인덱스 구조를 구성하는 것입니다.
//通过这个类在内存中来构造出索引结构
public class Index {
//这个类需要提供的方法
//1.给定一个docId ,在正排索引中,查询文档的详细信息
public DocInfo getDocInfo(int docId){
//TODO
return null;
}
//2.给定一词,在倒排索引中,查哪些文档和这个文档词关联
public List<Weight> getInverted(String term){
//TODO
return null;
}
//3.往索引中新增一个文档
public void addDoc(String title,String url,String content){
//TODO
}
//4.把内存中的索引结构保存到磁盘中
public void save(){
//TODO
}
//5.把磁盘中的索引数据加载到内存中
public void load(){
//TODO
}
}
다음으로 각 기능의 의미를 설명하겠습니다.
-
public DocInfo getDocInfo(int docId) // 给定一个docId ,在正排索引中,查询文档的详细信息이 클래스는 실제로 포지티브 인덱스이고 문서 정보 콘텐츠는 문서 ID에 대해 얻으므로 반환 값이 특정 반환 콘텐츠를 나타내기를 원하므로 새 클래스를 만듭니다.

public class DocInfo {
private int docId;
private String title;
private String url;
private String content;
public String getUrl() {
return url;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public void setUrl(String url) {
this.url = url;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public int getDocId() {
return docId;
}
public void setDocId(int docId) {
this.docId = docId;
}
}
이러한 속성은 앞서 분석한 것이며 특정 관계가 있어야 합니다.
–
-
public List<Weight> getInverted(String term) //给定一个词,在倒排索引中,查哪些文档和这个文档词关联문서 단어 는 . , 확인하러 가십시오.
List<Weight>이 가중치는 기사의 가중치입니다. 즉, 쿼리 단어가 일부 문서에 더 관련성이 있고 일부는 관련성이 낮습니다.
//文档ID和文档的相关性 权重进行包裹
public class Weight {
private int docId;
public int getDocId() {
return docId;
}
public void setDocId(int docId) {
this.docId = docId;
}
public int getWeight() {
return weight;
}
public void setWeight(int weight) {
this.weight = weight;
}
//这个weight就表示文档和词的相关性
//这个值越大,就认为相关性越强
private int weight;
}
이 가중치는 문서와 단어의 상관관계를 나타내며 값이 클수록 상관관계가 강함
-
public void addDoc(String title,String url,String content)인덱스에 문서를 추가합니다.
-
public void save()메모리 내 인덱스 구조를 디스크에 저장
-
public void load()인덱스 데이터를 디스크에서 메모리로 로드
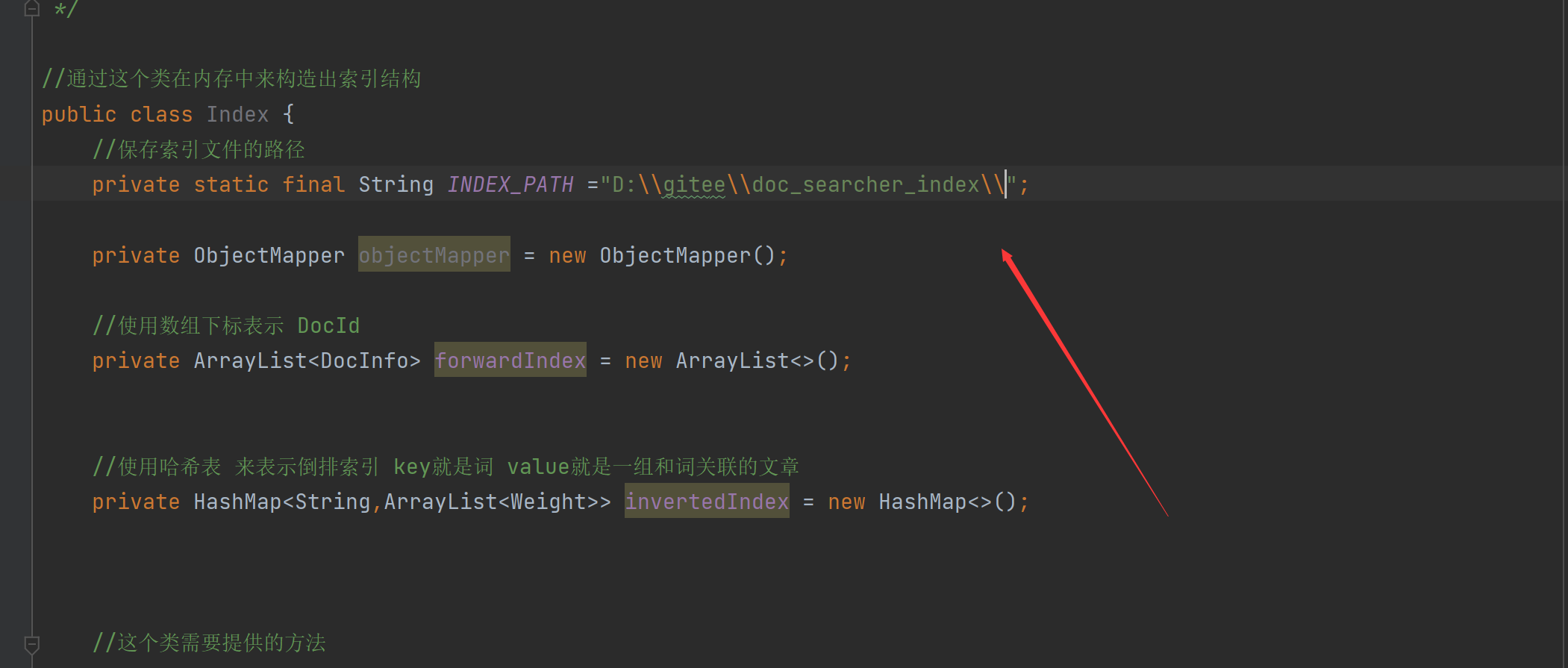
4.1 색인 모듈 구현 - 색인 구조 구현
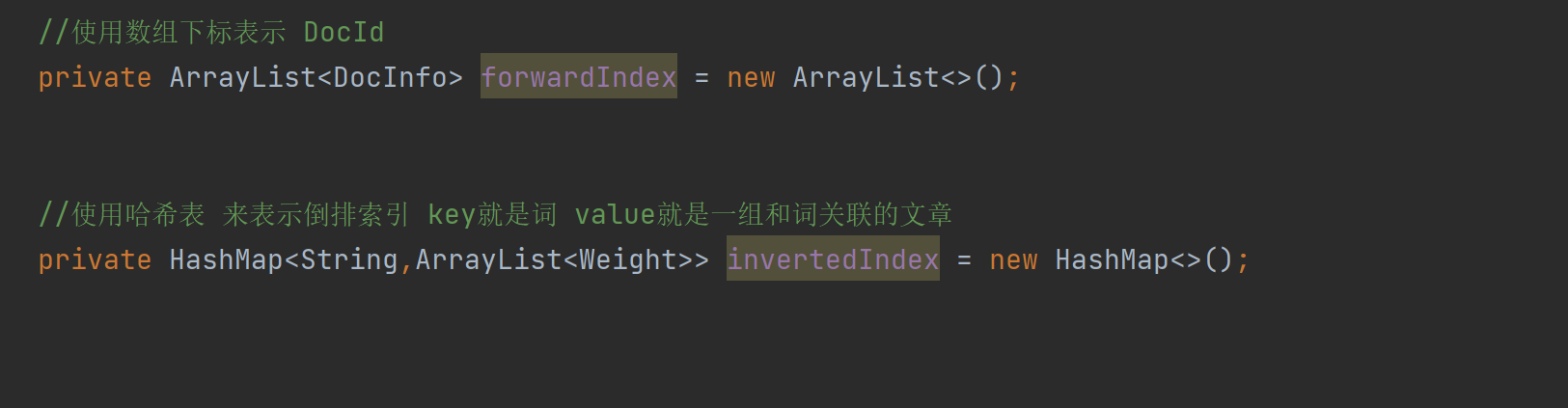
포워드 인덱스를 실현하기 위한 특정 구조:
정방향 인덱스는 ArrayList를 사용하여 DocID가 0이면 항목을 0 위치에, 100이면 100 위치에 배치하므로 ArrayList의 get 메소드를 사용하여 아래 첨자에 따라 해당 요소를 찾으십시오. 이것은 정방향 색인 표현입니다.

반전 인덱스를 실현하기 위한 특정 구조:
해시 테이블을 사용하여 반전된 인덱스 키가 검색어이고 값이 해당 단어와 관련된 기사 그룹 임을 나타내기 때문에 ArrayList를 사용합니다. Generics에 Weight를 사용하는 이유는 여기에 DocId와 관련성(가중치)이 모두 포함되어 있기 때문입니다. )

암호:
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
/**
* Created by Lin
* Description:
* User: Administrator
* Date: 2022-12-17
* Time: 13:01
*/
//通过这个类在内存中来构造出索引结构
public class Index {
//使用数组下标表示 DocId
private ArrayList<DocInfo> forwardIndex = new ArrayList<>();
//使用哈希表 来表示倒排索引 key就是词 value就是一组和词关联的文章
private HashMap<String,ArrayList<Weight>> invertedIndex = new HashMap<>();
//这个类需要提供的方法
//1.给定一个docId ,在正排索引中,查询文档的详细信息
public DocInfo getDocInfo(int docId){
return forwardIndex.get(docId);
}
//2.给定一词,在倒排索引中,查哪些文档和这个文档词关联
public List<Weight> getInverted(String term){
return invertedIndex.get(term);
}
//3.往索引中新增一个文档
public void addDoc(String title,String url,String content){
//TODO
}
//4.把内存中的索引结构保存到磁盘中
public void save(){
//TODO
}
//5.把磁盘中的索引数据加载到内存中
public void load(){
//TODO
}
}
–
4.2 인덱스 모듈 구현 - 정방향 인덱스 구현
이전에 필요한 사항을 분석했습니다:

이제 정방향 색인과 역방향 색인 모두에서 색인에 새 문서를 추가해야 합니다.이 간단한 앞줄을 살펴보겠습니다.
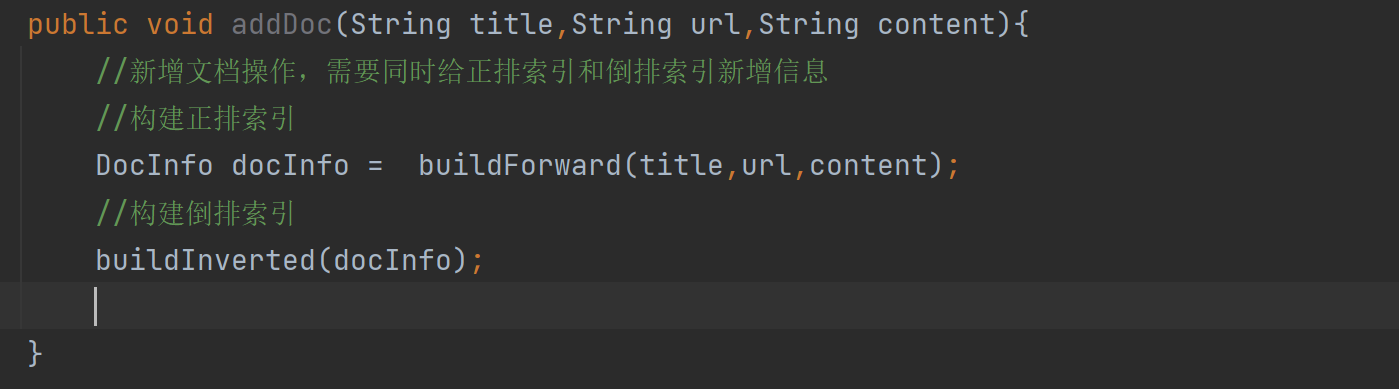
//3.往索引中新增一个文档
public void addDoc(String title,String url,String content){
//新增文档操作,需要同时给正排索引和倒排索引新增信息
//构建正排索引
DocInfo docInfo = buildForward(title,url,content);
//构建倒排索引
buildInverted(docInfo);
//TODO
}
private DocInfo buildForward(String title, String url, String content) {
DocInfo docInfo =new DocInfo();
docInfo.setDocId(forwardIndex.size());
docInfo.setTitle(title);
docInfo.setUrl(url);
docInfo.setContent(content);
forwardIndex.add(docInfo);
return docInfo;
}
주로 다음 코드를 살펴보겠습니다.正排索引
private DocInfo buildForward(String title, String url, String content) {
DocInfo docInfo =new DocInfo();
docInfo.setDocId(forwardIndex.size());
docInfo.setTitle(title);
docInfo.setUrl(url);
docInfo.setContent(content);
forwardIndex.add(docInfo);
return docInfo;
}
이 코드는 앞줄 구조가 실제로 파싱된 세 개의 매개변수를 DocInfo에 삽입하기 위한 것이기 때문에 초점은 DocId에 있으며 어떻게 0, 1, 2, 3에서 자체 증가를 달성하게 하고 나중에 우리는 실제로 그것을 발견했습니다. ArrayList가 있는 경우 값을 추가할 추가가 없을 때 size()는 0이며 forwardIndex.add(docInfo)를 수행하면 1이 됩니다. 그런 다음 더하기에서 2가 됩니다.
4.3 색인 모듈 실현 - 역 색인 구성 실현
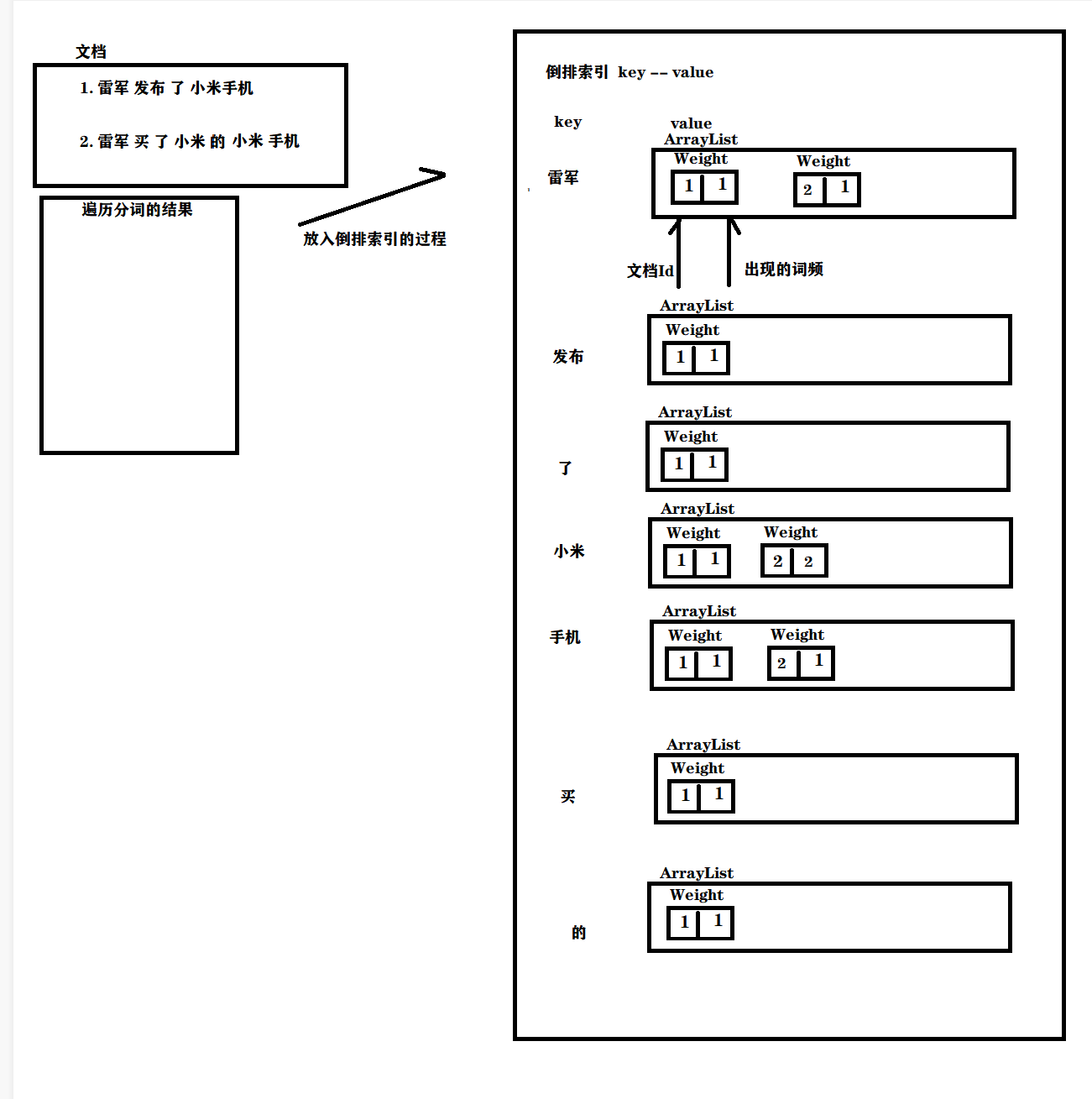
倒排索引아이디어 를 살펴 보겠습니다.
역색인은 단어와 문서 ID 간의 매핑으로, 현재 문서에 어떤 단어가 있는지 알아야 합니다.
따라서 현재 문서를 분할해야 하는데, word 분할은 제목과 텍스트 를 대상으로 하고, word 분할 결과를 합산하면 현재 문서 id가 반전된 인덱스의 키에 추가되어야 함을 알 수 있습니다.
반전된 인덱스는 키-값 쌍 구조(해시 맵)이고, 키는 단어 분할 결과(용어) 이며, 값은 단어 분할 결과에 해당하는 문서 목록의 집합임을 기억해야 합니다.
따라서 현재 문서에 대해 먼저 단어 분할을 수행한 다음 역색인으로 이동하여 단어 분할 결과에 따라 해당 값을 찾은 다음 현재 문서 ID를 해당 값 목록에 추가할 수 있습니다.
또 다른 문제가 있습니다. 우리의 거꾸로 된 인덱스는 해시 테이블뿐만 아니라 단어와 문서 간의 상관 관계를 설명하는 ArrayList<Weight>라는 매개 변수도 있습니다 .
우리의 상관관계는 다음과 같이 표현됩니다: 단어가 기사에 나오는 횟수가 많을수록 상관관계가 높아집니다. 이것은 우리만의 간단하고 조잡한 방법입니다. 실제 검색 엔진에서 상관관계는 알고리즘 팀이 하는 것입니다. .
그래서 우리가 다음에 할 일은:
- 문서 제목에 대한 단어 분할
- 단어 분할 결과 순회, 각 단어의 발생 횟수 계산
- 텍스트에 대한 단어 분할
- 단어 분할 결과 순회, 각 단어의 발생 횟수 계산
- 위의 결과를 HasMap으로 요약
최종 문서의 가중치, 제목 발생 횟수 * 10 + 본문 발생 횟수로 설정
4.4 가중치 공식을 개선하는 방법
실제 작업 환경이 어떻게 개선되는지 소개하겠습니다 구현 회사를 개선하려면 먼저 이 공식의 품질을 평가할 수 있는 방법이 있어야 합니다.
실제 검색 엔진은 종종 "클릭률"이라는 개념을 사용하여 측정합니다. 클릭률 = 클릭수 / (나누어) 노출수
예를 들어, 검색할 때 아무것도 하지 않고 브라우저를 닫으면 한 페이지가 한 화면입니다.
페이지를 검색하고 클릭하여 페이지로 이동하면 이 검색 결과의 클릭률은 100% 이므로 일반적으로 100%가 아니라 실제의 수천 분의 1일 수 있습니다. 이것도 정상입니다.. 결국 검색 결과에 수천 개의 콘텐츠가 있고 모든 콘텐츠로 이동하는 것은 불가능합니다.
클릭률과 같은 전략을 사용할 수 있으므로 다른 여러 전략도 사용할 수 있습니다.
상대적으로 트래픽이 많은 실제 검색 엔진 프로젝트의 경우 하루에 1억 방문이 있다고 가정하면 1억 방문을 여러 부분으로 나눌 수 있습니다. 30%, 30%, 40%, 처음 1 억 사용할 수 있습니다. 공식 A는 30%, 공식 B는 두 번째 30%, 공식 C는 40%를 계산한 다음 클릭률을 개별적으로 계산합니다.일련의 반복 후에 공식은 점점 더 복잡해집니다 . 마지막으로 최상의 공식을 선택하십시오. 이런 작업을 작은 흐름 실험 이라고 하며 , 수식 라인은 그 효과를 조금 증폭시킬 수 있습니다.
4.5 인덱스 모듈 실현 - 단어 빈도 통계 실현
이제 단어 빈도 통계 기능을 구현할 것입니다.
private void buildInverted(DocInfo docInfo) {
//搞一个内部类避免出现2个哈希表
class WordCnt{
//表示这个词在标题中 出现的次数
public int titleCount ;
// 表示这个词在正文出现的次数
public int contentCount;
}
//统计词频的数据结构
HashMap<String,WordCnt> wordCntHashMap =new HashMap<>();
//1,针对文档标题进行分词 为什么可以直接docInfo取值,是因为上次的正派索引里面已经有内容了
List<Term> terms = ToAnalysis.parse( docInfo.getTitle()).getTerms();
//2. 遍历分词结果,统计每个词出现的比例
for (Term term : terms){
//先判定一个term这个词是否存在,如果不存在,就创建一个新的键值对,插入进去,titleCount 设为1
//gameName()的分词的具体的词
String word = term.getName();
//哈希表的get如果不存在默认返回的是null
WordCnt wordCnt = wordCntHashMap.get(word);
if (wordCnt == null){
//词不存在
WordCnt newWordCnt = new WordCnt();
newWordCnt.titleCount =1;
newWordCnt.contentCount = 0;
wordCntHashMap.put(word,newWordCnt);
}else{
//存在就找到之前的值,然后加1
wordCnt.titleCount +=1;
}
//如果存在,就找到之前的值,然后把对应的titleCount +1
}
//3. 针对正文进行分词
terms = ToAnalysis.parse(docInfo.getContent()).getTerms();
for (Term term : terms) {
String word = term.getName();
WordCnt wordCnt = wordCntHashMap.get(word);
if (wordCnt == null){
WordCnt newWordCnt = new WordCnt();
newWordCnt.titleCount = 0;
newWordCnt.contentCount = 1;
wordCntHashMap.put(word,newWordCnt);
}else {
wordCnt.contentCount +=1;
}
}
//4. 遍历分词结果,统计每个词出现的次数
//5. 把上面的结果汇总到一个HasMap里面
// 最终的文档的权重,设置为标题的出现次数 * 10 + 正文中出现的次数
//遍历当前的HashMap,依次来更新倒排索引中的结构。
}
먼저 이 그림을 보자:
사실 단어가 없으면 역색인에 해당 단어가 있는지 먼저 확인하고, 없으면 삽입하고, 있으면 계속해서 해당 코드를 역인덱스에 저장 기존 장소:
WordCnt wordCnt = wordCntHashMap.get(word);
if (wordCnt == null){
//词不存在
WordCnt newWordCnt = new WordCnt();
newWordCnt.titleCount =1;
newWordCnt.contentCount = 0;
wordCntHashMap.put(word,newWordCnt);
}else{
//存在就找到之前的值,然后加1
wordCnt.titleCount +=1;
}
가중치를 다시 설명하겠습니다.
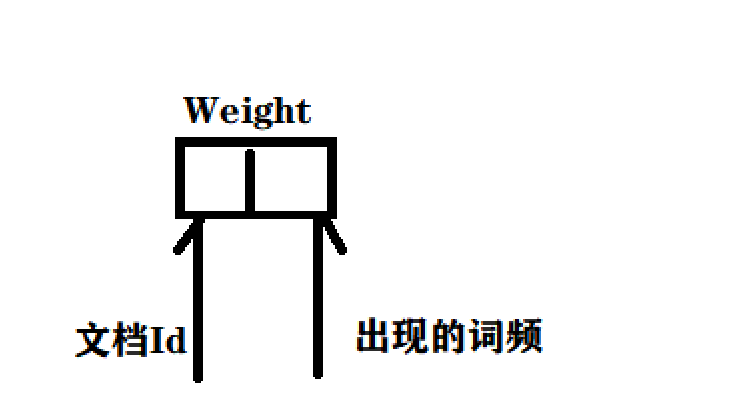
이것은 실제로 문서 ID이며 나타나는 단어의 빈도입니다.
문서 ID 번호는 2입니다. Lei Jun은 Xiaomi의 Xiaomi 휴대폰을 구입했습니다.
이것은 이러한 반전된 인덱스 부분의 그림을 얻을 것입니다.
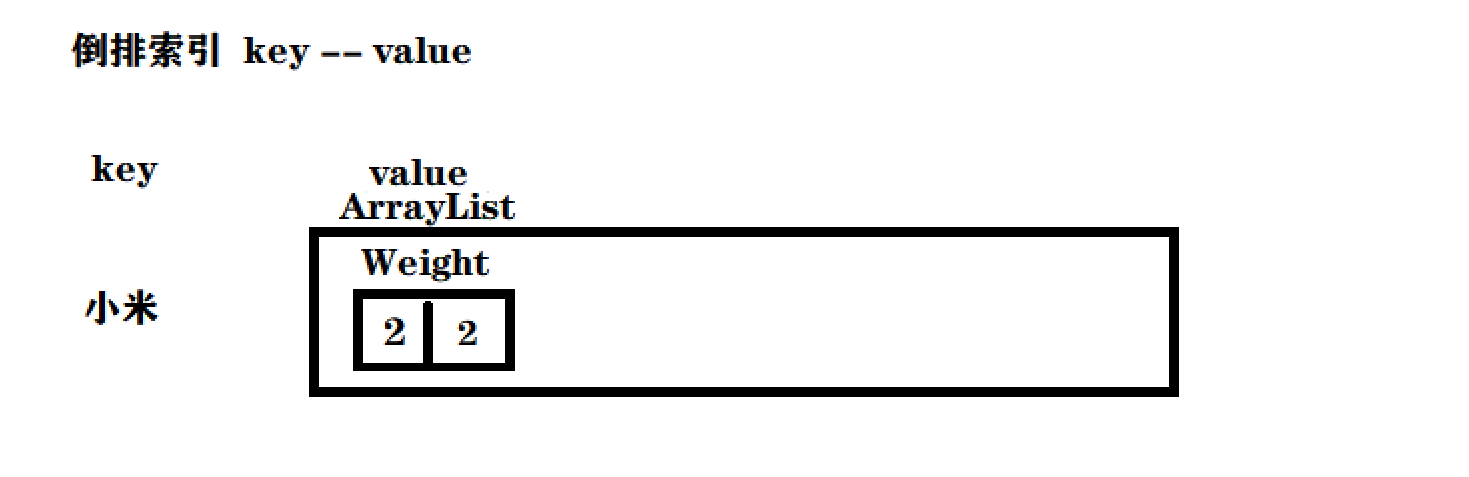
즉, Xiaomi라는 단어가 2번 기사에 두 번 등장하여 단어 빈도 통계가 실현됩니다.
4.6 색인 모듈 실현 - 역 색인 코드 구현 구성
private void buildInverted(DocInfo docInfo) {
//搞一个内部类避免出现2个哈希表
class WordCnt{
//表示这个词在标题中 出现的次数
public int titleCount ;
// 表示这个词在正文出现的次数
public int contentCount;
}
//统计词频的数据结构
HashMap<String,WordCnt> wordCntHashMap =new HashMap<>();
//1,针对文档标题进行分词
List<Term> terms = ToAnalysis.parse( docInfo.getTitle()).getTerms();
//2. 遍历分词结果,统计每个词出现的比例
for (Term term : terms){
//先判定一个term这个词是否存在,如果不存在,就创建一个新的键值对,插入进去,titleCount 设为1
//gameName()的分词的具体的词
String word = term.getName();
//哈希表的get如果不存在默认返回的是null
WordCnt wordCnt = wordCntHashMap.get(word);
if (wordCnt == null){
//词不存在
WordCnt newWordCnt = new WordCnt();
newWordCnt.titleCount =1;
newWordCnt.contentCount = 0;
wordCntHashMap.put(word,newWordCnt);
}else{
//存在就找到之前的值,然后加1
wordCnt.titleCount +=1;
}
//如果存在,就找到之前的值,然后把对应的titleCount +1
}
//3. 针对正文进行分词
terms = ToAnalysis.parse(docInfo.getContent()).getTerms();
//4. 遍历分词结果,统计每个词出现的次数
for (Term term : terms) {
String word = term.getName();
WordCnt wordCnt = wordCntHashMap.get(word);
if (wordCnt == null){
WordCnt newWordCnt = new WordCnt();
newWordCnt.titleCount = 0;
newWordCnt.contentCount = 1;
wordCntHashMap.put(word,newWordCnt);
}else {
wordCnt.contentCount +=1;
}
}
//5. 把上面的结果汇总到一个HasMap里面
// 最终的文档的权重,设置为标题的出现次数 * 10 + 正文中出现的次数
//6.遍历当前的HashMap,依次来更新倒排索引中的结构。
for(Map.Entry<String,WordCnt> entry:wordCntHashMap.entrySet()){
//先根据这里的词去倒排索引中查一查词
//倒排拉链
List<Weight> invertedList = invertedIndex.get(entry.getKey());
if (invertedList == null){
//如果为空,插入一个新的键值对
ArrayList<Weight> newInvertedList =new ArrayList<>();
Weight weight = new Weight();
weight.setDocId(docInfo.getDocId());
//权重计算公式:标题中出现的次数* 10 +正文出现的次数
weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);
newInvertedList.add(weight);
invertedIndex.put(entry.getKey(),newInvertedList);
}else{
//如果非空 ,就把当前的文档,构造出一个Weight 对象,插入到倒排拉链的后面
Weight weight = new Weight();
weight.setDocId(docInfo.getDocId());
//权重计算公式:标题中出现的次数* 10 +正文出现的次数
weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);
invertedList.add(weight);
}
}
}
이 부분은 여기에 코드를 작성합니다. 먼저 이것이 무엇인지에 대한 Map.Entrt가 필요한 이유를 파악합니다.
- 모든 코드를 반복할 수 있는 것은 아닙니다. 이 객체만 "반복 가능"하며 Iterable 인터페이스를 구현할 수 있습니다.
- 하지만 Map은 구현되지 않았습니다. Map의 의미는 키에 따라 값을 찾는 것입니다. 그러나 다행스럽게도 Set은 Iterable을 구현하므로 Map을 Set으로 변환할 수 있습니다.
- 원래 Map은 키-값 쌍으로 존재하며 키에 따라 빠르게 값을 찾을 수 있습니다.
- 여기서 설정하는 것은 Entry(엔트리)라는 키-값 쌍을 함께 묶는 클래스입니다.
- Set으로 변환한 후 키를 기반으로 값을 빠르게 찾을 수 있는 기능이 손실되지만 대신 순회할 수 있습니다.
각각은 키-값 쌍이며 항목 클래스가 됩니다.
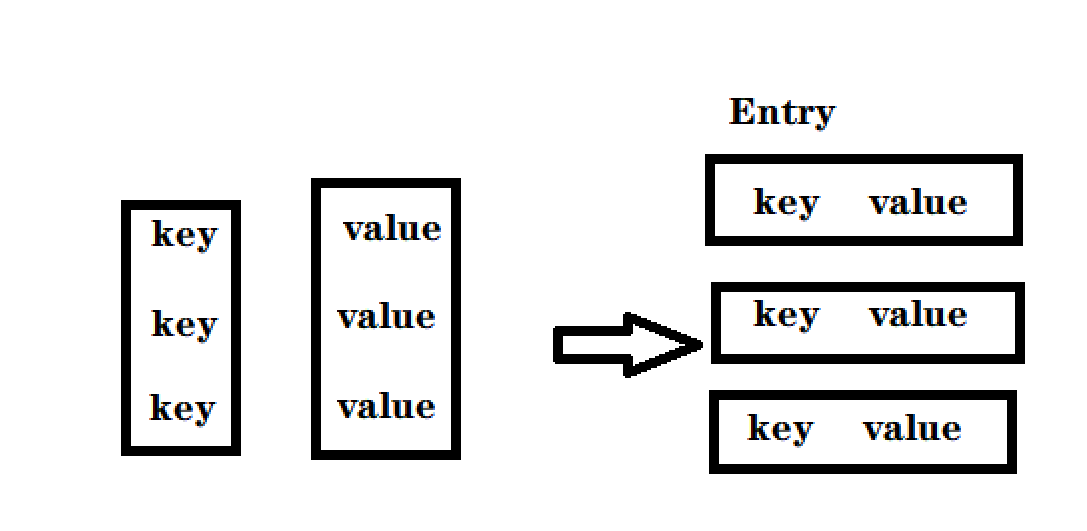
우리는 거꾸로 된 색인이 다음과 같은 구조를 가지고 있음을 알고 있습니다:

키는 단어이고 값은 문서 세트입니다.

단어에 따라 색인에 기사가 있는지 확인하고 반환 값은 기사 세트입니다.
비어 있으면 새 키-값 쌍을 만듭니다.
역색인에 필요한 것은 단어와 일련의 관사입니다.
기사에 대한 컨테이너가 없으므로 먼저 컨테이너를

생성한 다음 Weight 개체를 생성하고 이 컨테이너에 기사의 ID와 가중치를 입력해야 합니다.

여기서 가중치 설정에 주의할 필요가 있는데, 우리 Entry의 키는 문자열의 단어이고 단어는 위의 단어 빈도 통계의 클래스입니다. 단어 빈도, 그리고 가중치 공식에 따라 가중치를 설정하십시오.

마지막으로 생성된 새 키-값 쌍을 반전된 인덱스에 넣습니다.

단어가 비어 있지 않으면 docId와 weight를 설정합니다. 
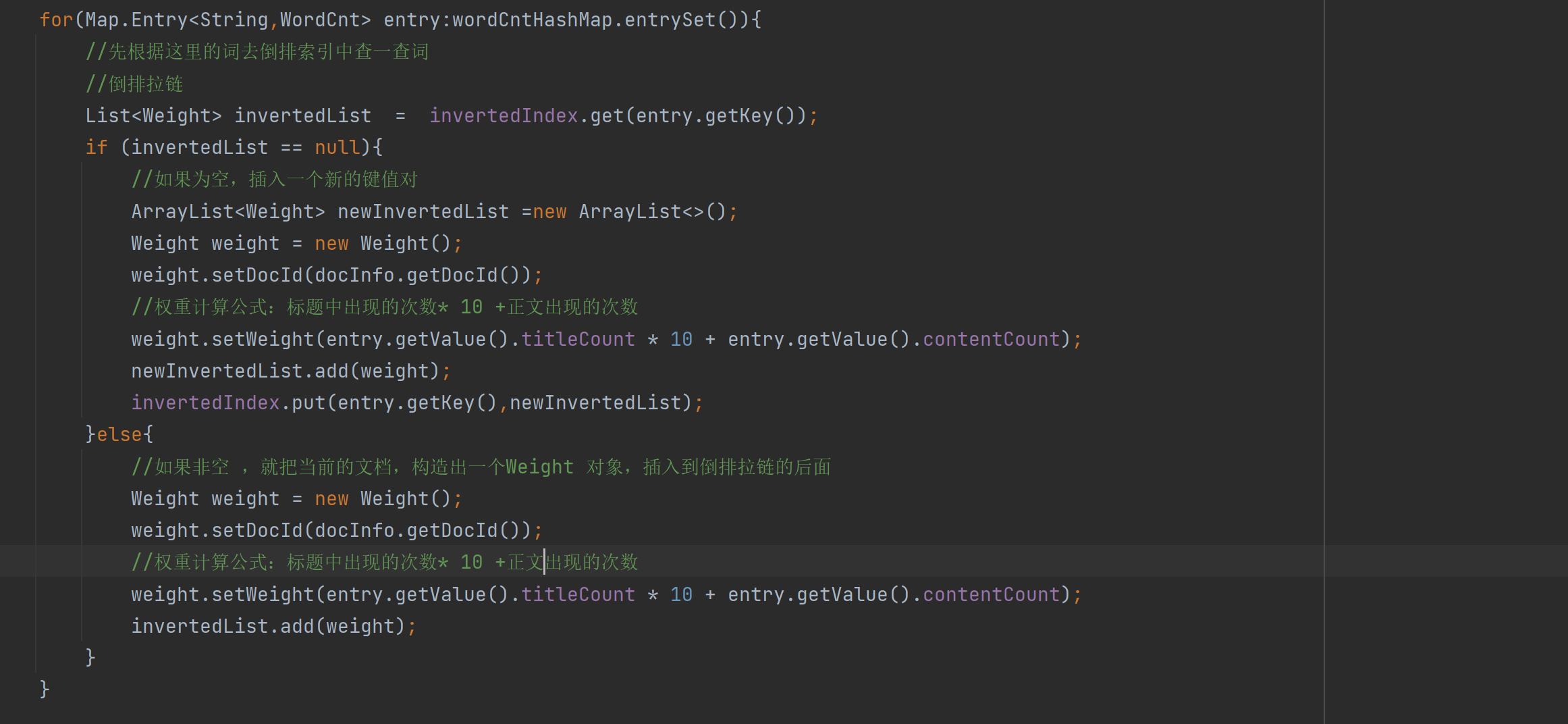
실제로 역색인의 가장 중요한 구성은 다음 코드입니다.
4.7 인덱스 모듈 구현 - 인덱스 배경 저장 및 로드
지금 색인을 만들었지만 여전히 문제가 있습니다. 우리 색인은 현재 메모리에 있지만 색인을 만드는 과정은 시간이 많이 걸리기 때문에 하드 디스크에 저장해야 합니다
. 한 번 만들어졌지만 수천 개의 문서가 있고 실제 검색 엔진 문서는 수억 또는 수십억이 될 수 있습니다. 이렇게 하면 매우 느려집니다.
따라서 서버 시작 시 인덱스를 빌드하지 않아야 합니다(서버 시작이 많이 느려질 수 있음).
그래서 시간이 많이 걸리는 이러한 작업을 분할하여 개별적으로 완료합니다. 별도의 실행 후 온라인 서버에서 구축된 인덱스를 직접 불러오도록 함
파일에 저장하는 방법? 파일은 바이너리 데이터나 텍스트 데이터에 지나지 않습니다. 직설적으로 말하면 텍스트 데이터는 "문자열"입니다. 메모리의 인덱스 구조를 문자열로 변환한 다음 파일을 작성합니다. 직렬화라고도 합니다. 역방향 결과 문자열을 일부 구조화된 데이터(클래스, 개체, 기본 데이터 구조)로 구문 분석하는 것을 역직렬화라고 할 수 있습니다.
직렬화 및 역직렬화를 위한 기성 방법이 많이 있습니다. 여기서 직렬화/역직렬화를 위해 Json 형식을 직접 사용합니다 . jackson 라이브러리를 사용하면 직렬화 및 역직렬화가 매우 간단합니다.
4.8 인덱스 모듈 실현 - 인덱스 파일 저장 실현
Jackson의 메이븐 주소: JacksonMaven 주소
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.14.1</version>
</dependency>
새로 고치다:
먼저 라이브러리의 인스턴스를 만듭니다.
인덱스 파일을 저장할 경로: (2개의 백슬래시가 필요하며 끝에 있음)
//4.把内存中的索引结构保存到磁盘中
public void save(){
//使用2个文件。分别保存正排和倒排
System.out.println("保存索引开始");
//1.先判断一下索引对应的目录是否存在
File indexPathFile =new File(INDEX_PATH);
if (!indexPathFile.exists()){
//如果路径不存在
//mkdirs()可以创建多级目录
indexPathFile.mkdirs();
}
//创建正排索引文件
File forwardIndexFile = new File(INDEX_PATH+"forward.txt");
//创建倒排索引文件
File invertedIndexFile = new File(INDEX_PATH+"inverted.txt");
try {
//writeValue的有个参数可以把对象写到文件里
objectMapper.writeValue(forwardIndexFile,forwardIndex);
objectMapper.writeValue(invertedIndexFile,invertedIndex);
}catch (IOException e){
e.printStackTrace();
}
System.out.println("保存索引完成");
}
4.9 인덱스 모듈 구현 - 로딩 인덱스 구현
저장은 메모리에 있는 데이터를 파일에 쓰는 것이고, 로드는 파일에 있는 데이터를 다시 메모리에 쓰는 것으로, 인덱스 작성 단계에서 저장해야 하고, 서버 프로그램을 사용할 때 불러와야 한다. :
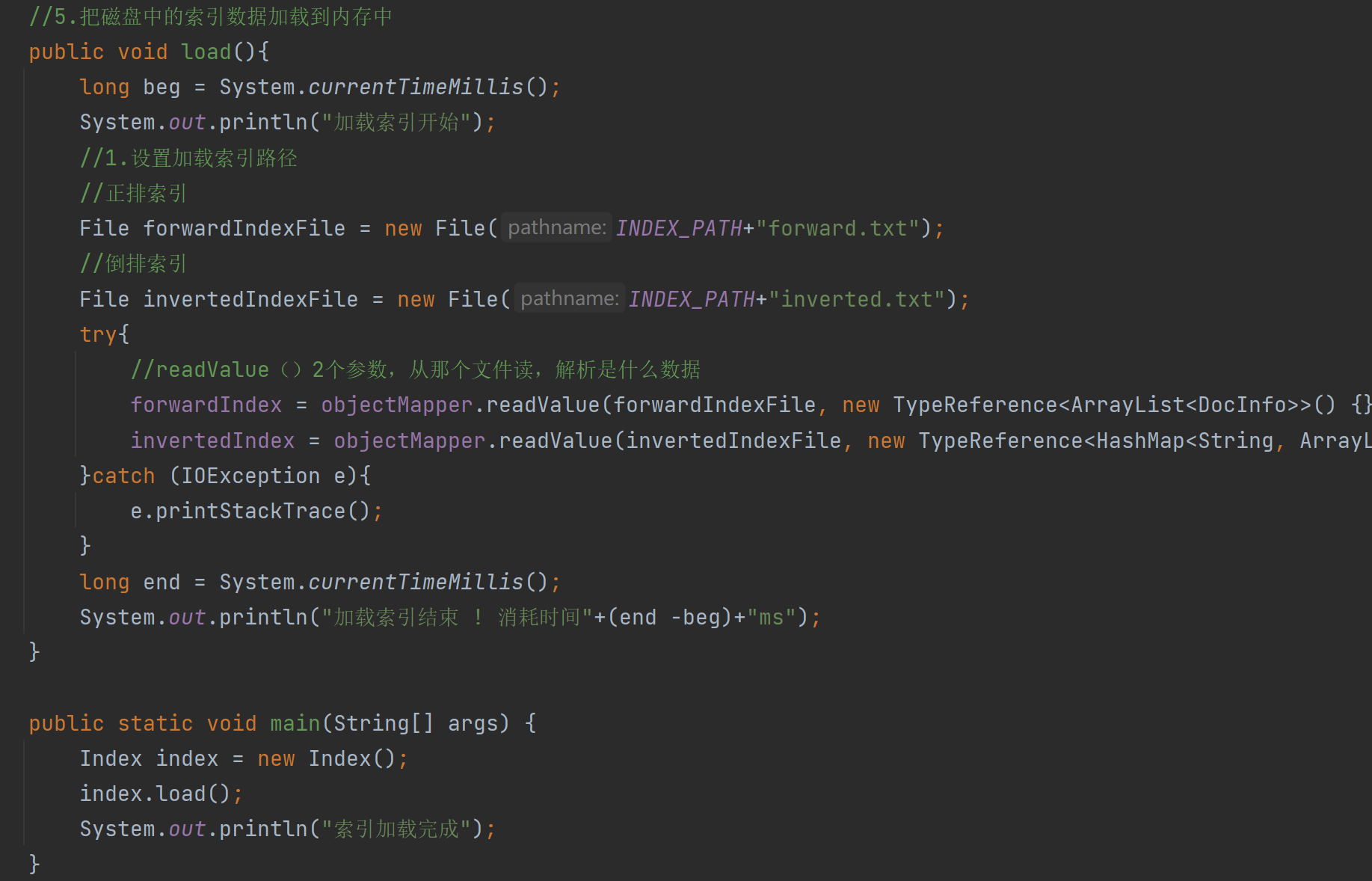
//5.把磁盘中的索引数据加载到内存中
public void load(){
System.out.println("加载索引开始");
//1.设置加载索引路径
//正排索引
File forwardIndexFile = new File(INDEX_PATH+"forward.txt");
//倒排索引
File invertedIndexFile = new File(INDEX_PATH+"inverted.txt");
try{
//readValue()2个参数,从那个文件读,解析是什么数据
forwardIndex = objectMapper.readValue(forwardIndexFile, new TypeReference<ArrayList<DocInfo>>() {
});
invertedIndex = objectMapper.readValue(invertedIndexFile, new TypeReference<HashMap<String, ArrayList<Weight>>>() {
});
}catch (IOException e){
e.printStackTrace();
}
System.out.println("加载索引结束");
}
사실, 우리는 파일의 내용을 메모리에 다시 쓰는 방법을 보고 싶을 뿐입니다. 여기서는 여전히 Jackson의 라이브러리 함수 readValue()를 사용합니다. 여기에는 2개의 매개변수가 있습니다. 하나는 읽을 위치이고 두 번째 매개변수는 어떤 종류의 형식이 구문 분석되는지, 여기서 이 라이브러리 함수는 새로운 TypeReference<>를 제공하고 구문 분석하려는 형식을 대괄호 안에 채울 수 있습니다.
4.10 인덱스 모듈 구현 - 로드 및 저장 작업에 시간 추가
//4.把内存中的索引结构保存到磁盘中
public void save(){
long beg = System.currentTimeMillis();
//使用2个文件。分别保存正排和倒排
System.out.println("保存索引开始");
//1.先判断一下索引对应的目录是否存在
File indexPathFile =new File(INDEX_PATH);
if (!indexPathFile.exists()){
//如果路径不存在
//mkdirs()可以创建多级目录
indexPathFile.mkdirs();
}
//正排索引文件
File forwardIndexFile = new File(INDEX_PATH+"forward.txt");
//倒排索引文件
File invertedIndexFile = new File(INDEX_PATH+"inverted.txt");
try {
//writeValue的有个参数可以把对象写到文件里
objectMapper.writeValue(forwardIndexFile,forwardIndex);
objectMapper.writeValue(invertedIndexFile,invertedIndex);
}catch (IOException e){
e.printStackTrace();
}
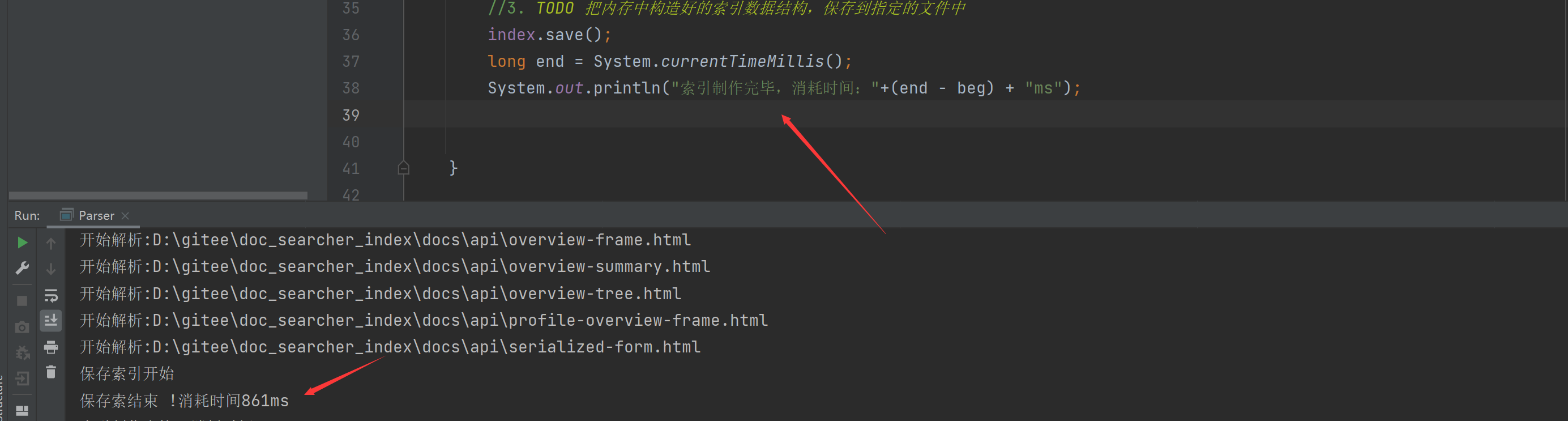
long end = System.currentTimeMillis();
System.out.println("保存索结束 !消耗时间"+(end - beg)+"ms");
}
//5.把磁盘中的索引数据加载到内存中
public void load(){
long beg = System.currentTimeMillis();
System.out.println("加载索引开始");
//1.设置加载索引路径
//正排索引
File forwardIndexFile = new File(INDEX_PATH+"forward.txt");
//倒排索引
File invertedIndexFile = new File(INDEX_PATH+"inverted.txt");
try{
//readValue()2个参数,从那个文件读,解析是什么数据
forwardIndex = objectMapper.readValue(forwardIndexFile, new TypeReference<ArrayList<DocInfo>>() {
});
invertedIndex = objectMapper.readValue(invertedIndexFile, new TypeReference<HashMap<String, ArrayList<Weight>>>() {
});
}catch (IOException e){
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("加载索引结束 ! 消耗时间"+(end -beg)+"ms");
}
시간이 많이 걸리는 부분에 시간을 추가할 수 있어 보다 직관적인 비교가 가능합니다.
4.11 인덱스 모듈 구현 - 파서에서 인덱스 호출
인덱스의 핵심 코드를 거의 작성했습니다. 인덱스 클래스를 파서 클래스와 연결해야 합니다.
이들 간의 관계는 다음과 같습니다.
Parser 클래스는 실행 가능한 프로그램에 해당하는 색인 항목을 만드는 것과 같습니다.
인덱스는 인덱스의 데이터 구조를 구현하는 것과 동일하며 상위에서 사용할 일부 API를 제공하므로 파서에서 인덱스를 호출합니다.
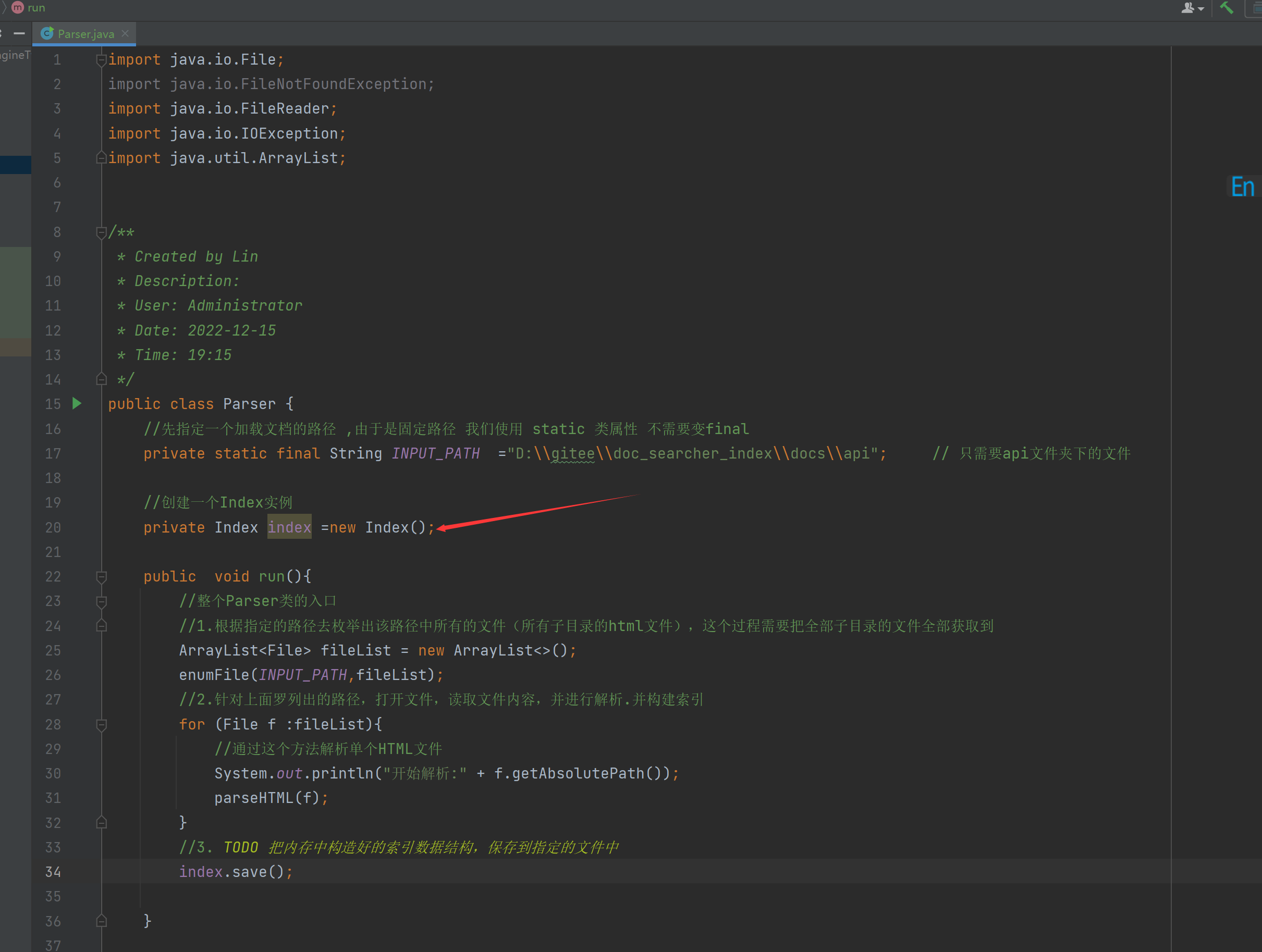
그런 다음 run 메서드에서 생성된 인덱스를 지정된 파일에 저장하고 구문 분석된 단일 HTML 파일을 인덱스에 추가합니다.
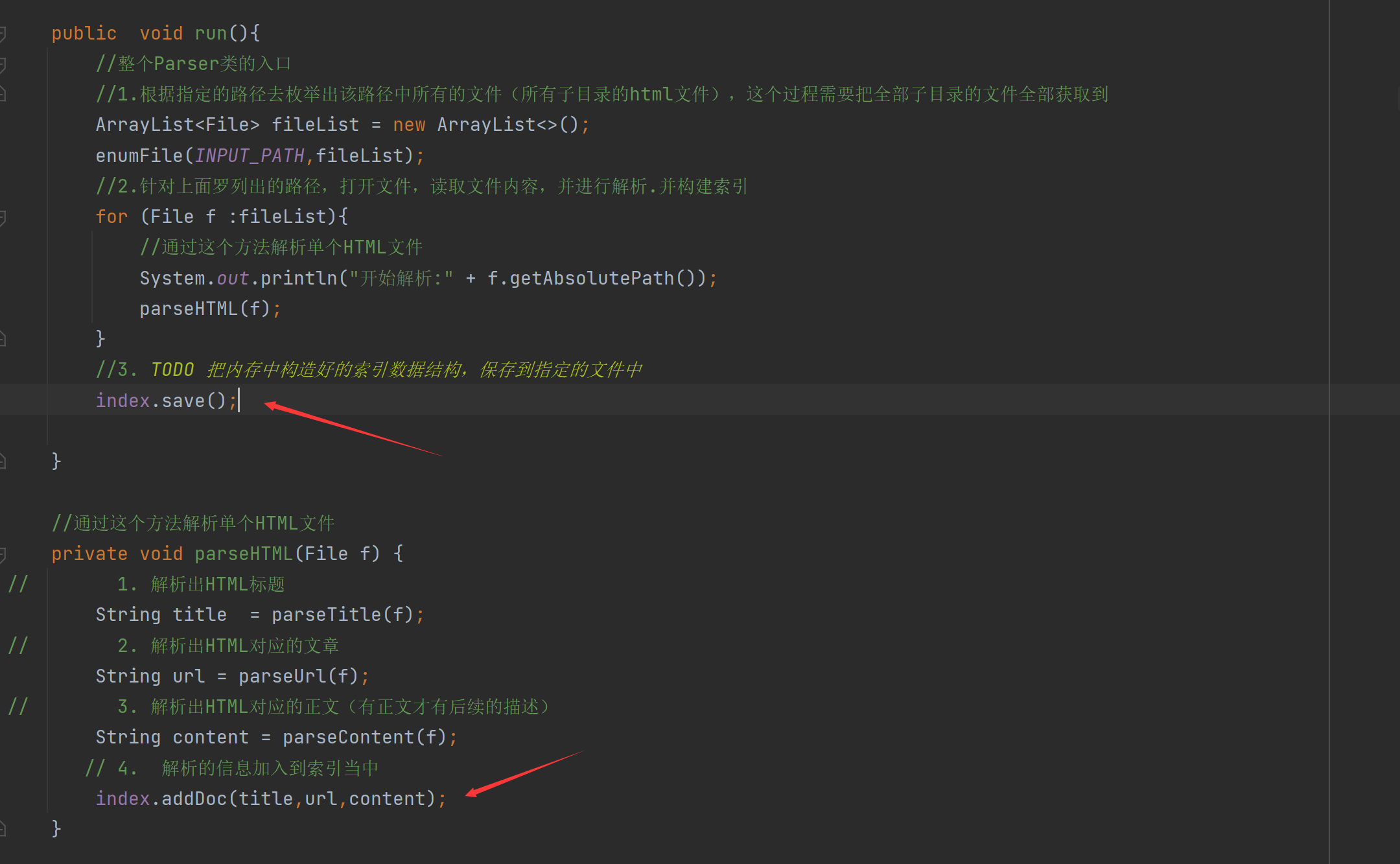
4.12 인덱스 모듈 구현 - 인덱스 생성 확인
이제 코드가 인덱스 파일을 만들 수 있는지 살펴보겠습니다. 두 클래스의 전체 코드를 릴리스합니다.
파서 클래스:
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
/**
* Created by Lin
* Description:
* User: Administrator
* Date: 2022-12-15
* Time: 19:15
*/
public class Parser {
//先指定一个加载文档的路径 ,由于是固定路径 我们使用 static 类属性 不需要变final
private static final String INPUT_PATH ="D:\\gitee\\doc_searcher_index\\docs\\api"; // 只需要api文件夹下的文件
//创建一个Index实例
private Index index =new Index();
public void run(){
//整个Parser类的入口
//1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到
ArrayList<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH,fileList);
//2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引
for (File f :fileList){
//通过这个方法解析单个HTML文件
System.out.println("开始解析:" + f.getAbsolutePath());
parseHTML(f);
}
//3. TODO 把内存中构造好的索引数据结构,保存到指定的文件中
index.save();
}
//通过这个方法解析单个HTML文件
private void parseHTML(File f) {
// 1. 解析出HTML标题
String title = parseTitle(f);
// 2. 解析出HTML对应的文章
String url = parseUrl(f);
// 3. 解析出HTML对应的正文(有正文才有后续的描述)
String content = parseContent(f);
// 4. 解析的信息加入到索引当中
index.addDoc(title,url,content);
}
public String parseContent(File f) {
//先按照一个字符一个字符来读取,以< 和 > 来控制拷贝数据的开关
try(FileReader fileReader = new FileReader(f)) {
//加上一个开关
boolean isCopy = true;
//还准备一个保存结果的StringBuilder
StringBuilder content = new StringBuilder();
while (true){
//read int类型 读到最后返回-1
int ret = fileReader.read();
if (ret == -1){
//表示文件读完了
break;
}
//不是-1就是合法字符
char c = (char) ret;
if (isCopy){
//打开的状态可以拷贝
if (c == '<'){
isCopy =false;
continue;
}
//判断是否是换行
if (c == '\n' || c == '\r'){
// 是换行就变成空格
c = ' ';
}
//其他字符进行拷贝到StringBuilder中
content.append(c);
}else{
//
if (c=='>'){
isCopy= true;
}
}
}
return content.toString();
} catch (IOException e) {
e.printStackTrace();
}
return "";
}
private String parseUrl(File f) {
//固定的前缀
String path = "https://docs.oracle.com/javase/8/docs/api/";
//只放一个参数的意思是:前面一段都不需要,取后面的一段
String path2= f.getAbsolutePath().substring(INPUT_PATH.length());
return path + path2;
}
private String parseTitle(File f) {
//获取文件名
String name = f.getName();
return name.substring(0,name.length()-".html".length());
}
//第一个参数表示从那个目录开始进行遍历,第二个目录表示递归得到的结果
private void enumFile(String inputPath, ArrayList<File> fileList) {
//我们需要把String类型的路径变成文件类 好操作点
File rootPath = new File(inputPath);
//listFiles()类似于Linux的ls把当前目录中包含的文件名获取到
//使用listFiles只可以看见一级目录,想看到子目录需要递归操作
File[] files = rootPath.listFiles();
for (File file : files) {
//根据当前的file的类型,觉得是否递归
//如果file是普通文件就把file加入到listFile里面
//如果file是一个目录 就递归调用enumFile这个方法,来进一步获取子目录的内容
if (file.isDirectory()){
//根路径要变
enumFile(file.getAbsolutePath(),fileList);
}else {
//只针对HTML文件
if(file.getAbsolutePath().endsWith(".html")){
//普通HTML文件
fileList.add(file);
}
}
}
}
public static void main(String[] args) {
//通过main方法来实现整个制作索引的过程
Parser parser = new Parser();
parser.run();
}
}
지수 등급:
import com.fasterxml.jackson.core.type.TypeReference;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.ToAnalysis;
import java.io.File;
import java.io.IOException;
import java.lang.reflect.Field;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* Created by Lin
* Description:
* User: Administrator
* Date: 2022-12-17
* Time: 13:01
*/
//通过这个类在内存中来构造出索引结构
public class Index {
//保存索引文件的路径
private static final String INDEX_PATH ="D:\\gitee\\doc_searcher_index\\";
private ObjectMapper objectMapper = new ObjectMapper();
//使用数组下标表示 DocId
private ArrayList<DocInfo> forwardIndex = new ArrayList<>();
//使用哈希表 来表示倒排索引 key就是词 value就是一组和词关联的文章
private HashMap<String,ArrayList<Weight>> invertedIndex = new HashMap<>();
//这个类需要提供的方法
//1.给定一个docId ,在正排索引中,查询文档的详细信息
public DocInfo getDocInfo(int docId){
return forwardIndex.get(docId);
}
//2.给定一词,在倒排索引中,查哪些文档和这个文档词关联
public List<Weight> getInverted(String term){
return invertedIndex.get(term);
}
//3.往索引中新增一个文档
public void addDoc(String title,String url,String content){
//新增文档操作,需要同时给正排索引和倒排索引新增信息
//构建正排索引
DocInfo docInfo = buildForward(title,url,content);
//构建倒排索引
buildInverted(docInfo);
}
private void buildInverted(DocInfo docInfo) {
//搞一个内部类避免出现2个哈希表
class WordCnt{
//表示这个词在标题中 出现的次数
public int titleCount ;
// 表示这个词在正文出现的次数
public int contentCount;
}
//统计词频的数据结构
HashMap<String,WordCnt> wordCntHashMap =new HashMap<>();
//1,针对文档标题进行分词
List<Term> terms = ToAnalysis.parse( docInfo.getTitle()).getTerms();
//2. 遍历分词结果,统计每个词出现的比例
for (Term term : terms){
//先判定一个term这个词是否存在,如果不存在,就创建一个新的键值对,插入进去,titleCount 设为1
//gameName()的分词的具体的词
String word = term.getName();
//哈希表的get如果不存在默认返回的是null
WordCnt wordCnt = wordCntHashMap.get(word);
if (wordCnt == null){
//词不存在
WordCnt newWordCnt = new WordCnt();
newWordCnt.titleCount =1;
newWordCnt.contentCount = 0;
wordCntHashMap.put(word,newWordCnt);
}else{
//存在就找到之前的值,然后加1
wordCnt.titleCount +=1;
}
//如果存在,就找到之前的值,然后把对应的titleCount +1
}
//3. 针对正文进行分词
terms = ToAnalysis.parse(docInfo.getContent()).getTerms();
//4. 遍历分词结果,统计每个词出现的次数
for (Term term : terms) {
String word = term.getName();
WordCnt wordCnt = wordCntHashMap.get(word);
if (wordCnt == null){
WordCnt newWordCnt = new WordCnt();
newWordCnt.titleCount = 0;
newWordCnt.contentCount = 1;
wordCntHashMap.put(word,newWordCnt);
}else {
wordCnt.contentCount +=1;
}
}
//5. 把上面的结果汇总到一个HasMap里面
// 最终的文档的权重,设置为标题的出现次数 * 10 + 正文中出现的次数
//6.遍历当前的HashMap,依次来更新倒排索引中的结构。
//并不是全部代码都是可以for循环的,只有这个对象是”可迭代的“,实现Iterable 接口才可以
// 但是Map并没有实现,Map存在意义,是根据key查找value,但是好在Set实现了实现Iterable,就可以把Map转换为Set
//本来Map存在的是戒键值对,可以根据key快速找到value,
//Set这里存的是一个把 键值对 打包在一起的类 称为Entry(条目)
//转成Set之后,失去了快速根据key快速查找value的只这样的能力,但是换来了可以遍历
for(Map.Entry<String,WordCnt> entry:wordCntHashMap.entrySet()){
//先根据这里的词去倒排索引中查一查词
//倒排拉链
List<Weight> invertedList = invertedIndex.get(entry.getKey());
if (invertedList == null){
//如果为空,插入一个新的键值对
ArrayList<Weight> newInvertedList =new ArrayList<>();
Weight weight = new Weight();
weight.setDocId(docInfo.getDocId());
//权重计算公式:标题中出现的次数* 10 +正文出现的次数
weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);
newInvertedList.add(weight);
invertedIndex.put(entry.getKey(),newInvertedList);
}else{
//如果非空 ,就把当前的文档,构造出一个Weight 对象,插入到倒排拉链的后面
Weight weight = new Weight();
weight.setDocId(docInfo.getDocId());
//权重计算公式:标题中出现的次数* 10 +正文出现的次数
weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);
invertedList.add(weight);
}
}
}
private DocInfo buildForward(String title, String url, String content) {
DocInfo docInfo =new DocInfo();
docInfo.setDocId(forwardIndex.size());
docInfo.setTitle(title);
docInfo.setUrl(url);
docInfo.setContent(content);
forwardIndex.add(docInfo);
return docInfo;
}
//4.把内存中的索引结构保存到磁盘中
public void save(){
long beg = System.currentTimeMillis();
//使用2个文件。分别保存正排和倒排
System.out.println("保存索引开始");
//1.先判断一下索引对应的目录是否存在
File indexPathFile =new File(INDEX_PATH);
if (!indexPathFile.exists()){
//如果路径不存在
//mkdirs()可以创建多级目录
indexPathFile.mkdirs();
}
//正排索引文件
File forwardIndexFile = new File(INDEX_PATH+"forward.txt");
//倒排索引文件
File invertedIndexFile = new File(INDEX_PATH+"inverted.txt");
try {
//writeValue的有个参数可以把对象写到文件里
objectMapper.writeValue(forwardIndexFile,forwardIndex);
objectMapper.writeValue(invertedIndexFile,invertedIndex);
}catch (IOException e){
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("保存索结束 !消耗时间"+(end - beg)+"ms");
}
//5.把磁盘中的索引数据加载到内存中
public void load(){
long beg = System.currentTimeMillis();
System.out.println("加载索引开始");
//1.设置加载索引路径
//正排索引
File forwardIndexFile = new File(INDEX_PATH+"forward.txt");
//倒排索引
File invertedIndexFile = new File(INDEX_PATH+"inverted.txt");
try{
//readValue()2个参数,从那个文件读,解析是什么数据
forwardIndex = objectMapper.readValue(forwardIndexFile, new TypeReference<ArrayList<DocInfo>>() {
});
invertedIndex = objectMapper.readValue(invertedIndexFile, new TypeReference<HashMap<String, ArrayList<Weight>>>() {
});
}catch (IOException e){
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("加载索引结束 ! 消耗时间"+(end -beg)+"ms");
}
public static void main(String[] args) {
Index index = new Index();
index.load();
System.out.println("索引加载完成");
}
}
실행할 Parser의 기본 메서드를 제공합니다.
결과:
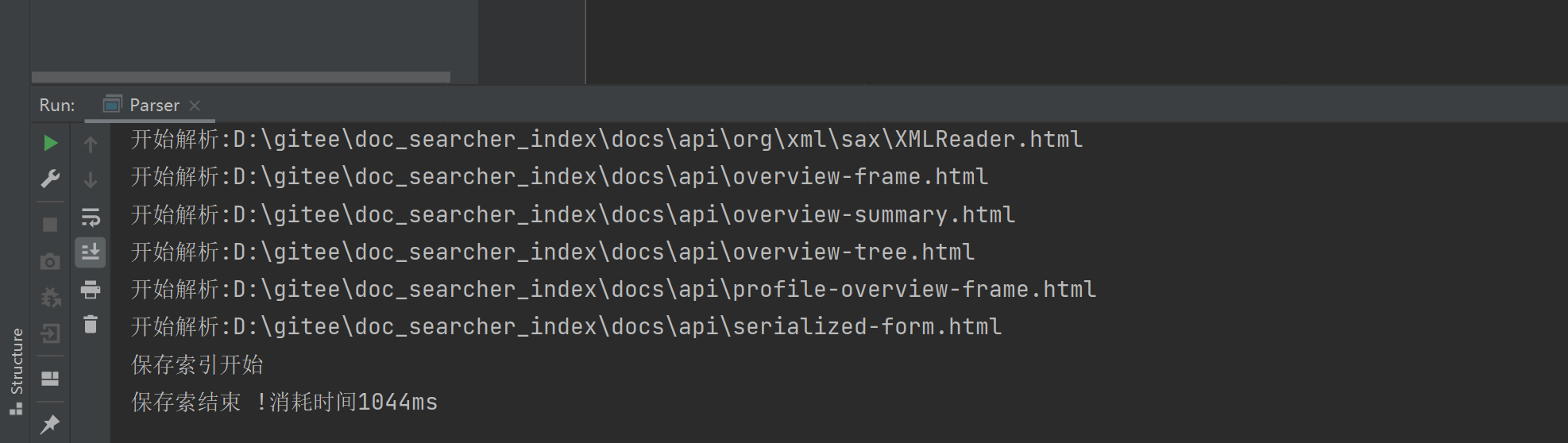
그런 다음 만든 인덱스 파일을 확인하십시오: 파일이 성공적으로 나왔습니다.

vscode를 사용하여 이 파일을 열어서 파일이 무엇인지 확인합니다: (메모장이 열리면 느립니다)

사실, 우리는 텍스트에 원하는 파일이 여전히 있고 필요한 모든 것을 가지고 있음을 발견했습니다. 반전된 파일에도 docid와 weight가

있으므로 색인 파일이 아직 완전하다고 생각할 수 있습니다.
5. 인덱스 모듈 구현 - 인덱스 모듈 최적화
5.1 인덱스 모듈 구현 - 인덱스 생성 속도에 대하여
방금 인덱스를 생성했을 때 여전히 일정 시간이 걸렸습니다.Parser 클래스의 run 메서드로 이동하여 시간 차이를 만들어 얼마나 오래 걸렸는지 명확하게 볼 수 있습니다. 최적화 후 개선되었습니다.
인덱스가 생성되는 데 거의 30초가 걸렸음을 알 수 있습니다.
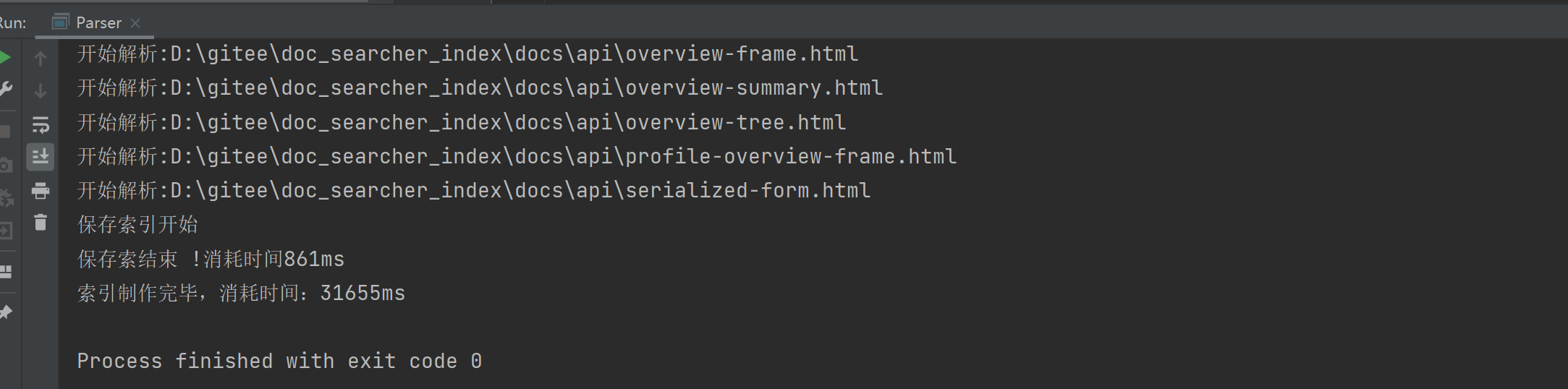
그럼 우리가 어디에 시간을 낭비하고 있는지 생각해 볼까요?
경로를 열거하고 있습니까? 사실 여기는 엄청 빨라요
색인을 저장하시겠습니까? 실제로는 0.8초에 불과합니다.
진짜 큰 머리는 여전히 루프에 있습니다.
성능을 향상시키려면 먼저 이유를 찾아야 합니다. 프로그램의 성능을 최적화하려면 다음을 찾아야 합니다. 테스트를 통해 "성능 병목 현상". 병원에 가듯이 먼저 필름을 찍어 문제를 찾은 다음 문제를 해결합니다. 테스트 방법 가장 쉬운 방법은 각 환경에 시간을 추가하여 누가 더 많이 소비하는지 확인하는 것입니다.
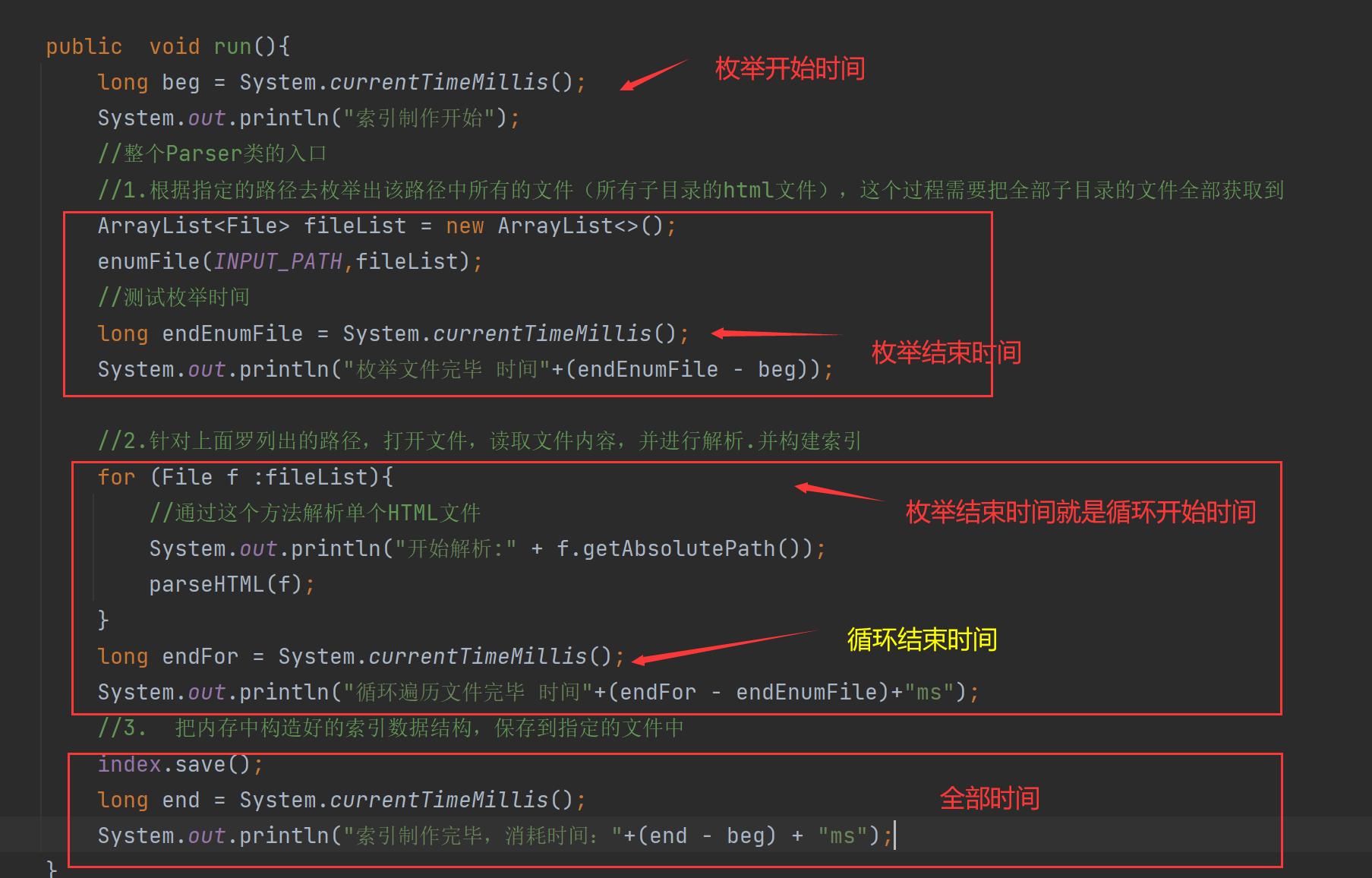
결과: 주기 시간이 가장 오래 걸립니다. 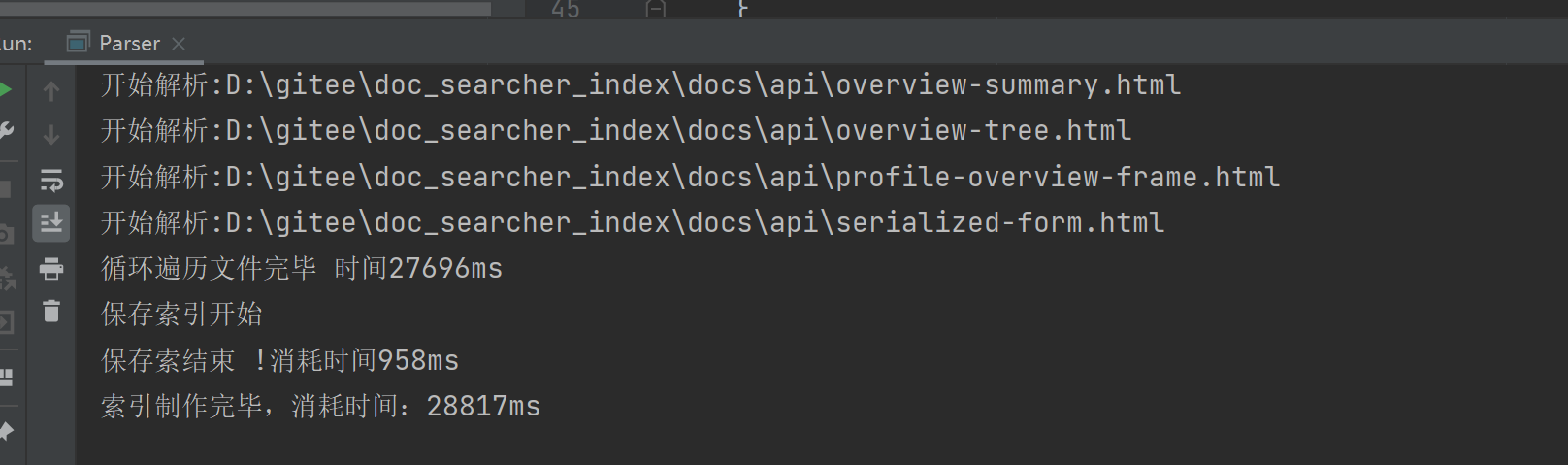
이 루프에 대한 최적화 아이디어도 매우 간단합니다. 바로 지금 테스트를 통해 주요 성능 병목 현상이 파일을 통한 루프에 있으며 각 루프가 파일을 분석해야 함을 발견했습니다. 파일 읽기 + 단어 분할 + 콘텐츠 구문 분석(주로 cpu 컴퓨팅에 갇혀 있음), 단일 스레드의 경우 이러한 작업은 직렬입니다(두 번째 파일을 구문 분석하기 전에 첫 번째 파일을 구문 분석).使用多线程提神速度,这样通过多线程制作索引,到达提升速度的目的
5.2 인덱스 모듈 구현 - 다중 스레드 인덱싱 구현
새로운 방법을 통해 다중 스레드 인덱싱을 구현합니다.
//通过这个方法实现多线程制作索引
public void runByThread() throws InterruptedException {
long beg =System.currentTimeMillis();
System.out.println("索引制作开始!");
//1.,枚举全部文件
ArrayList<File> files = new ArrayList<>();
enumFile(INPUT_PATH,files);
//2.循环遍历文件 此处为了通过多线程制作索引,就直接引入线程池
CountDownLatch latch = new CountDownLatch(files.size());
ExecutorService executorService = Executors.newFixedThreadPool(10);
for(File f:files){
//添加任务submit到线程池
executorService.submit(new Runnable() {
@Override
public void run() {
System.out.println("解析"+f.getAbsolutePath());
parseHTML(f);
//保证所有的索引制作完再保存索引
latch.countDown();
}
});
}
//latch.await()等待全部countDown完成,才阻塞结束。
latch.await();
//3.保存索引 ,可能存在还没有执行完的情况
index.save();
long end =System.currentTimeMillis();
System.out.println("索引制作结束!时间"+(end - beg)+"ms");
}
기본 아이디어는 여전히 이전과 동일하지만 모든 사람이 이해해야 하는 몇 가지 변경 사항이 있습니다.
-
스레드 풀 추가, ExecutorService는 newFixedThreadPool(10)을 사용하고 이 메서드를 사용하여 10개의 스레드를 생성한 다음 포커스가 옵니다.
-
인덱싱이 끝났다면 index.save(); 메소드를 호출해야 하는데 지금은 멀티쓰레드라서 아직 인덱스가 만들어지고 완성되지 않은 상황이 있을 수 있습니다. 다중 스레드 동시 작업인 경우 index.save()만 실행할 수 있으므로 불완전한 인덱스 파일을 얻게 됩니다.
-
이 상황에 대한 우리의 해결책은 다음과 같습니다. CountDownLatch 클래스의 countDown() 메서드를 사용합니다. 이 메서드는 완료되지 않은 작업 수를 기록하고, 모두 완료되면 await() 를 사용하여 깨우고 다음 단계를 작동합니다.
5.3 인덱스 모듈 실현 - 만들어진 인덱스 코드 잠금
멀티스레딩을 추가한 후 바로 실행할 수 있나요? 아니요, 그렇지 않습니다. 스레드 안전성이 관련되어 있기 때문에 스레드 안전성에 대해 명확히 할 필요가 있습니다 . 공용 개체의 작업과 관련된 경우 발생할 수 있습니다 . 즉 (여러 스레드가 동일한 개체를 수정하려고 시도함)
여기서는 parseHTML 메서드를 호출합니다.
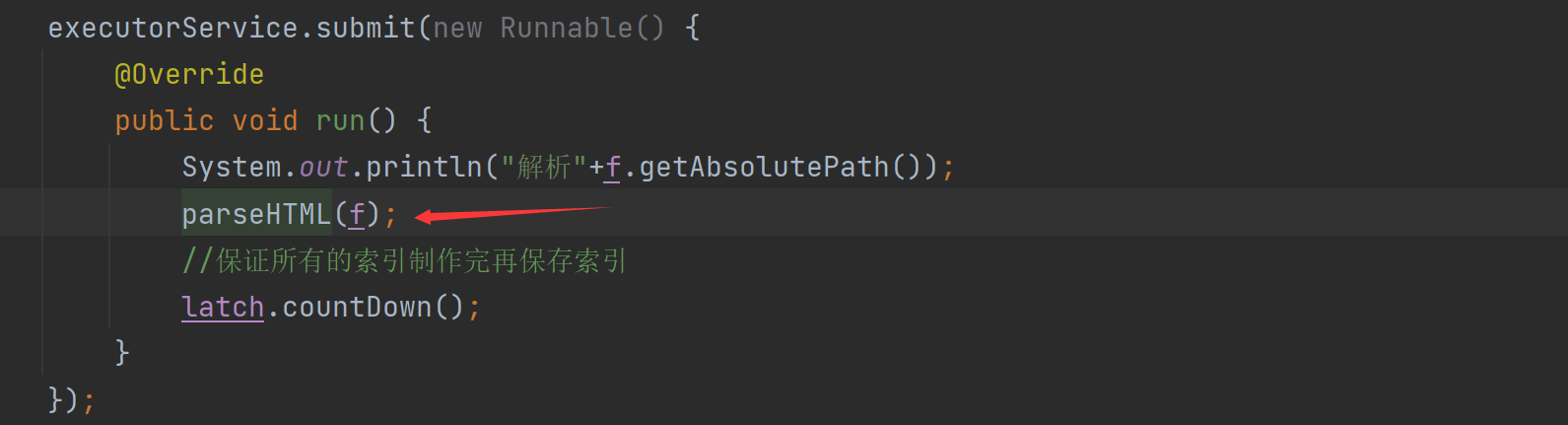
parserHTML 메소드도 다른 오퍼레이션과 addDoc 오퍼레이션이 있는데
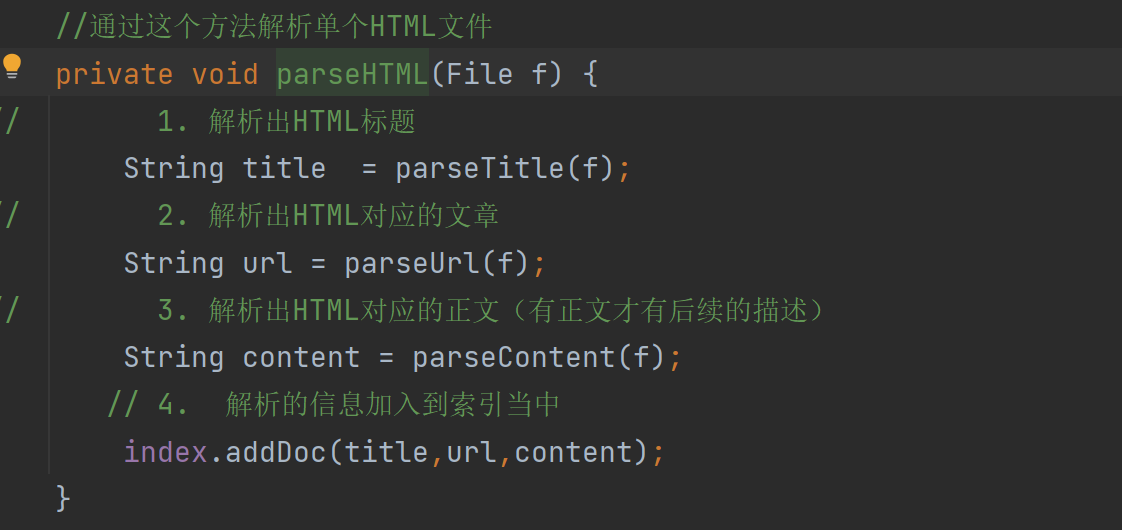
제목, url, 텍스트를 파싱하는 것은 퍼블릭 객체의 오퍼레이션이 포함되지 않는데 addDoc 메소드에 문제가 있음을 발견했습니다.
여기에서 우리는 addDoc이 정방향 및 역방향으로 구성된 색인이 있음을 발견합니다.
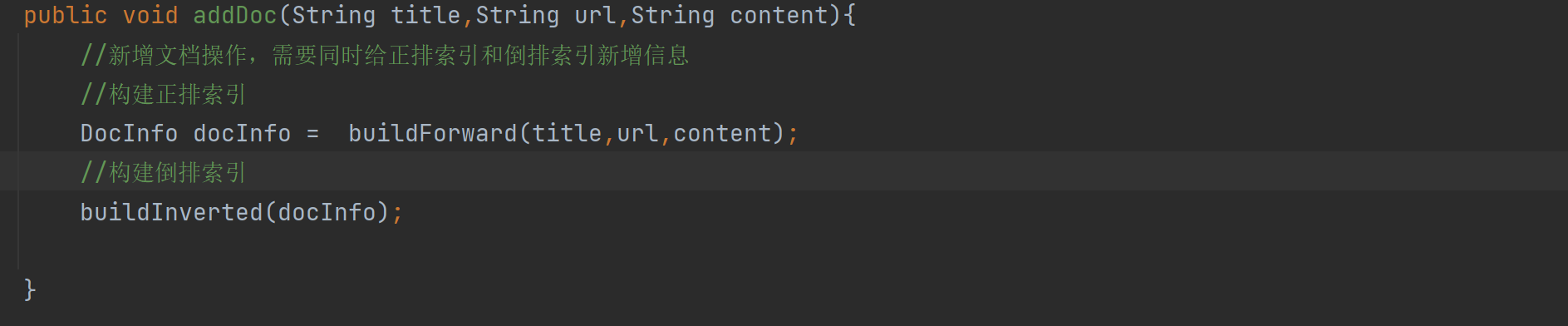
포워드 인덱스를 보면 공통 클래스가 운영되고 있는 곳이 2곳이라는 것을 알 수 있습니다.
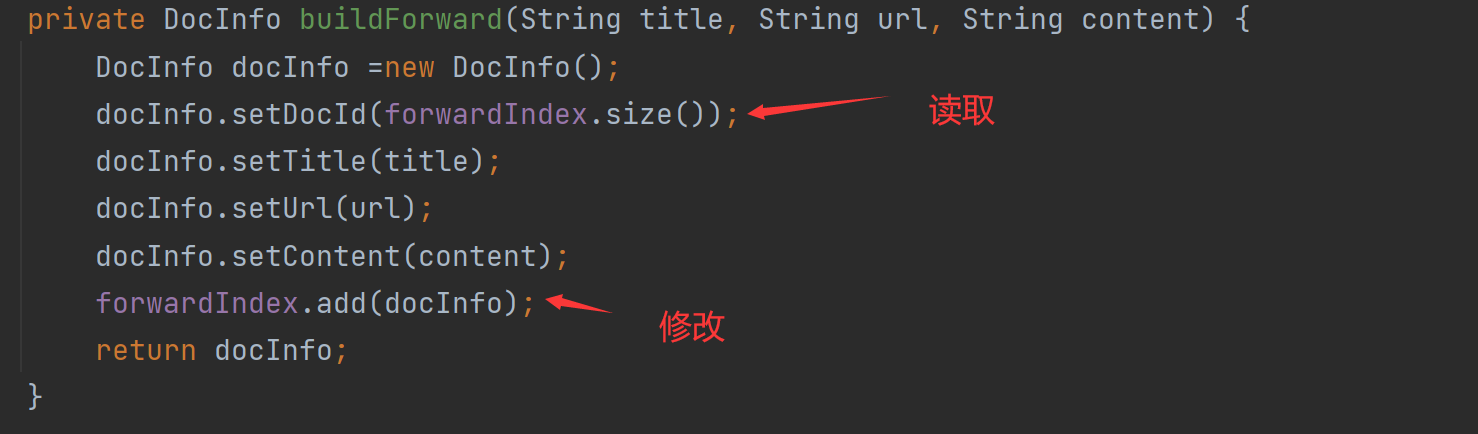
역색인을 구축하는 것도 공용 객체를 조작하는 행위를 한다:
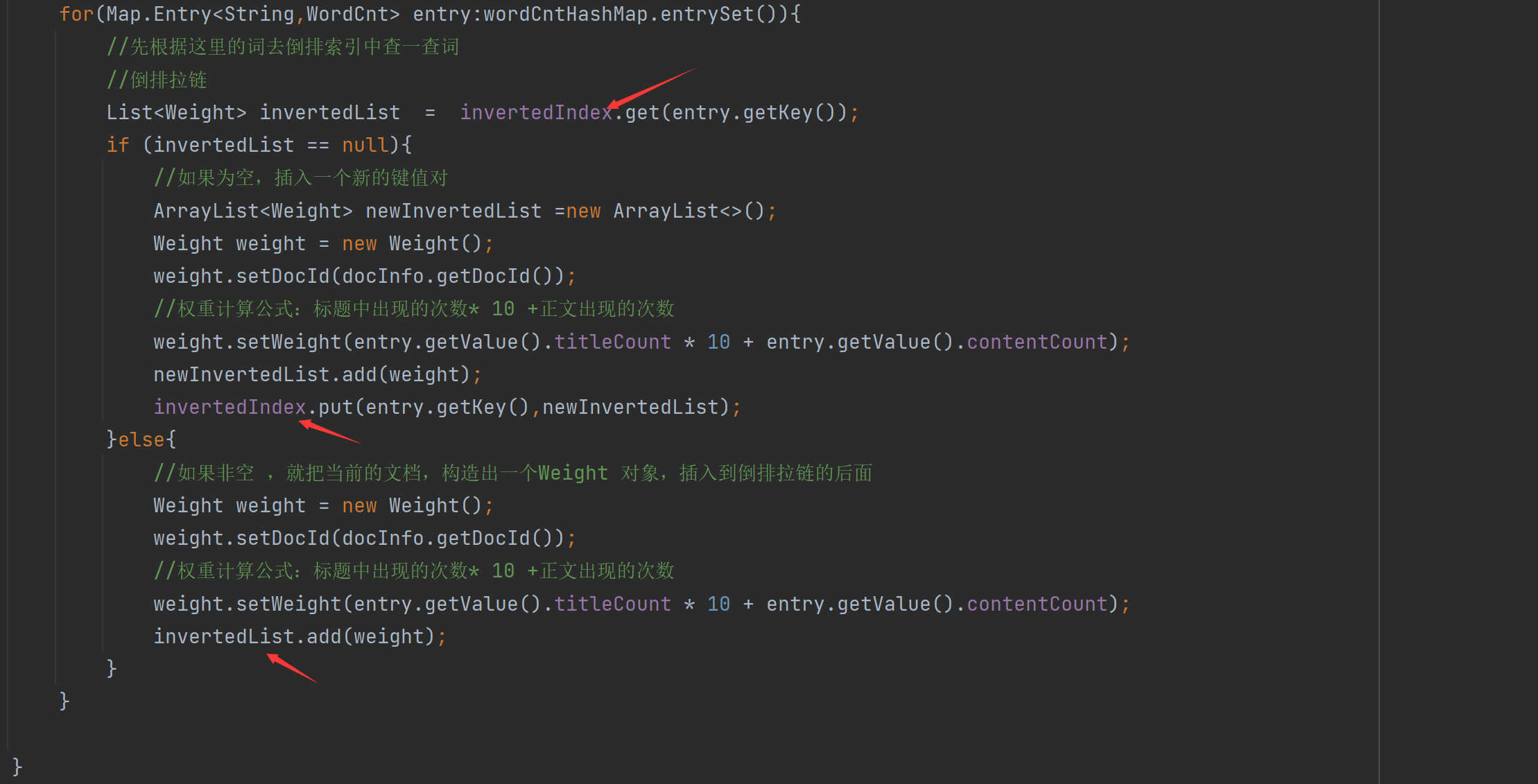
그림을 그려서 대략적인 실행 과정을 보자: forwardIndex와 invertedIndex를 동시에 수정하는 쓰레드가 4개 있어서 쓰레드 안전성 문제가 있으므로 쓰레드 안전성을 사용한다. 잠그다.
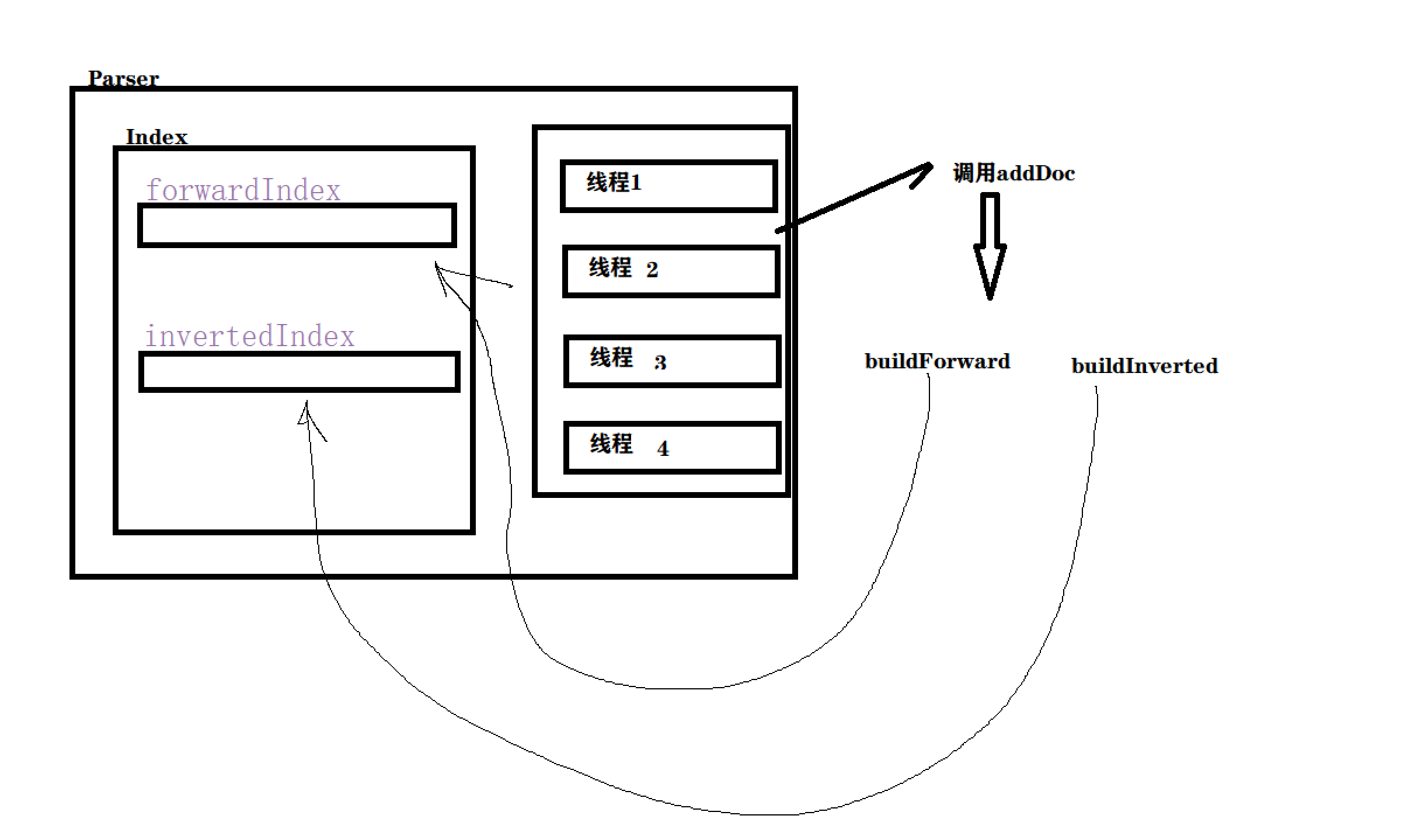
그것을 추가하는 방법? 우리는 동시에 가능한 장소를 가능한 한 동시적으로 만들고 싶고 장소를 직렬화할 수 없으며 잠금의 세분성이 너무 커서는 안 됩니다.
- addDoc을 직접 잠그시겠습니까? 여기에 잠금을 추가하면 인덱스를 직렬로만 빌드할 수 있고 방금 추가한 멀티스레딩은 의미가 없습니다.
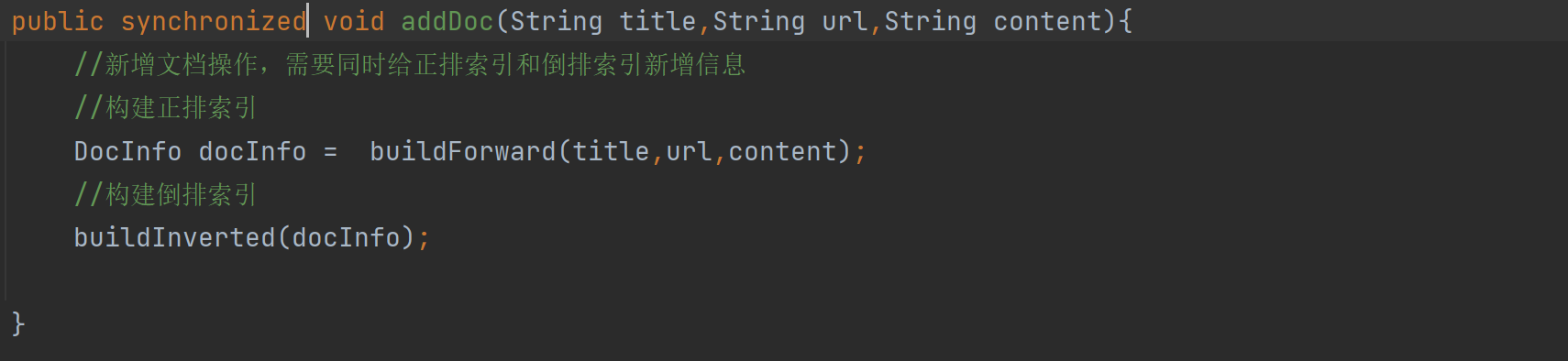
- 순서를 조정하고 양수 행 인덱스에 대한 코드 2줄을 잠급니다.
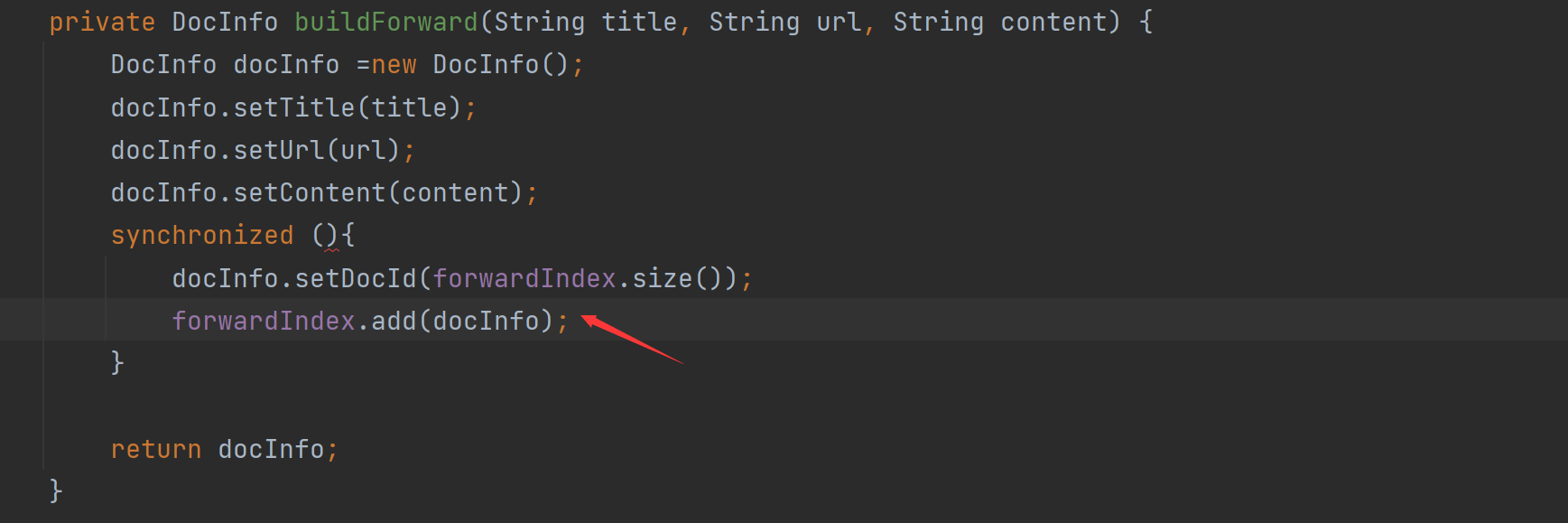
- 역 인덱스 루프 코드의 순서를 조정하고 잠그십시오.
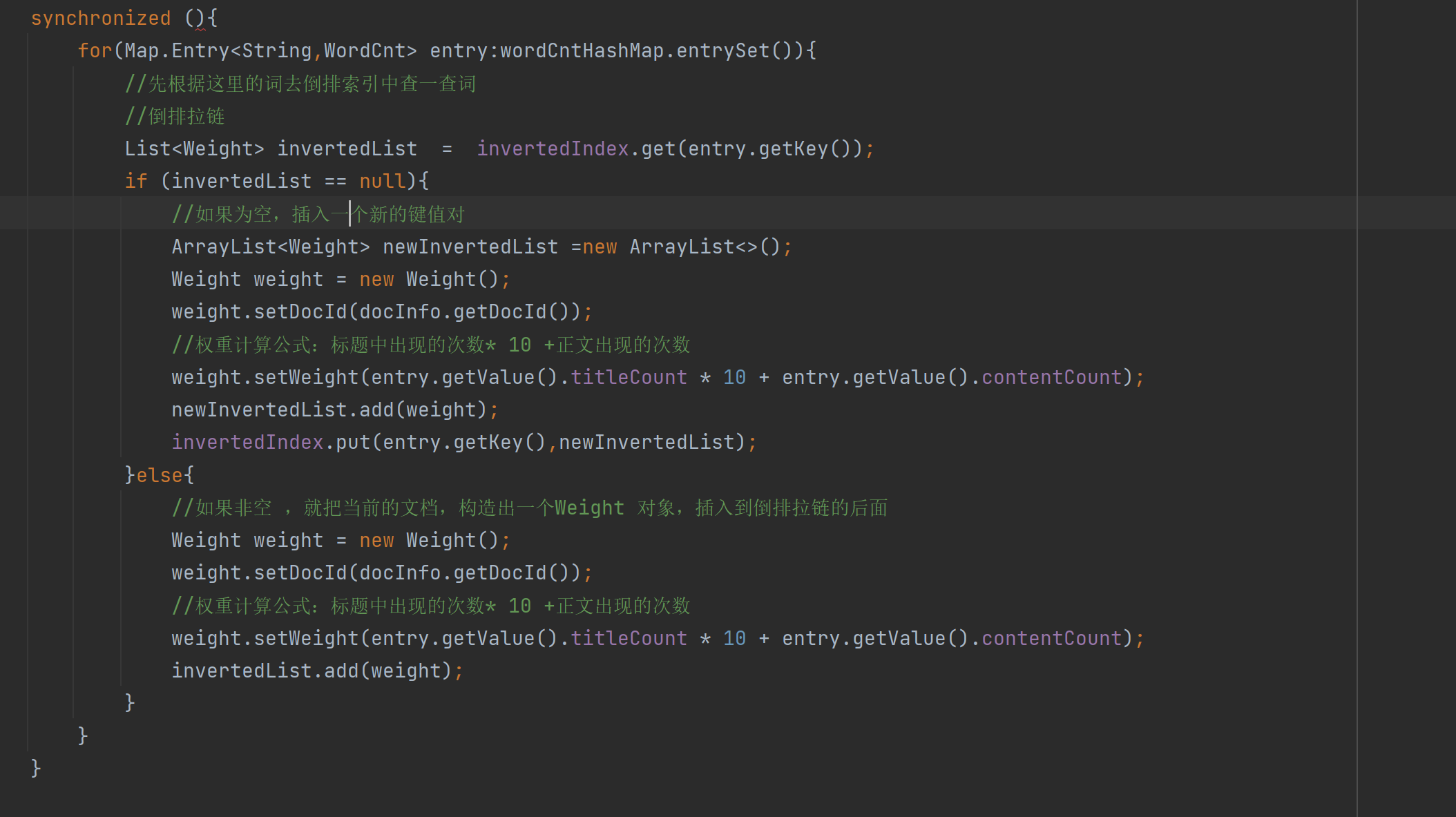
또 다른 질문이 있습니다. 잠글 필요가 있는 객체는 무엇입니까? 동기화된 매개변수
Lock 객체에 주어지면 현재 Index 클래스를 의미하지만, 이 경우 역방향 인덱스 객체 코드가 실행되기 전에 정방향 인덱스 객체가 실행되어야 하는 것으로 나타납니다.
우리는 실제로 두 개의 서로 다른 개체(정방향 인덱스 및 역방향 인덱스) 를 작동하고 있으므로 소녀 A와 소녀 B처럼 둘 다 구혼자가 있는 것처럼 잠금 경쟁을 일으키지 않아야 하며 스레드 남성 A가 소녀 A를 넣습니다. 나가서 다른 쓰레드남들은 여자A를 기다려야 합니까?그들도 여자B에게 갈 수 있습니다.여자A와 B는 2개의 다른 객체입니다.
인덱스 객체를 잠글 수 있습니다.
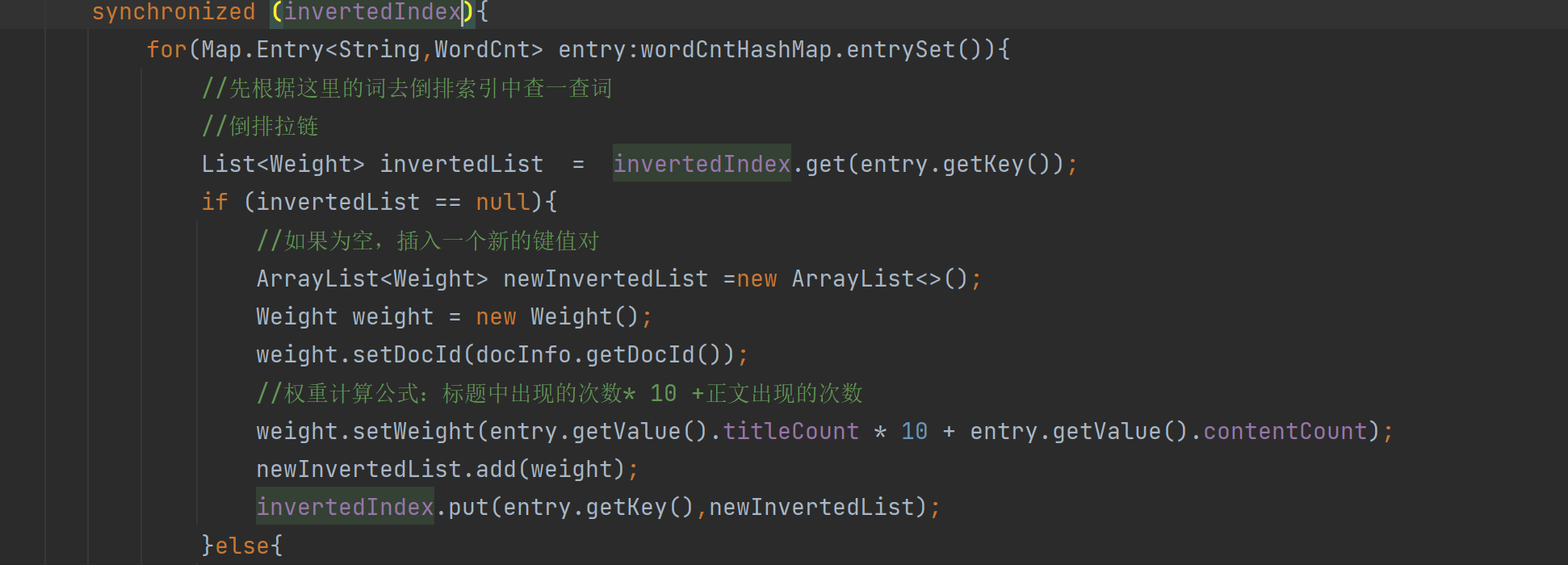
두 개의 새 잠금 개체를 만들고
코드를 변경할 수도 있습니다.
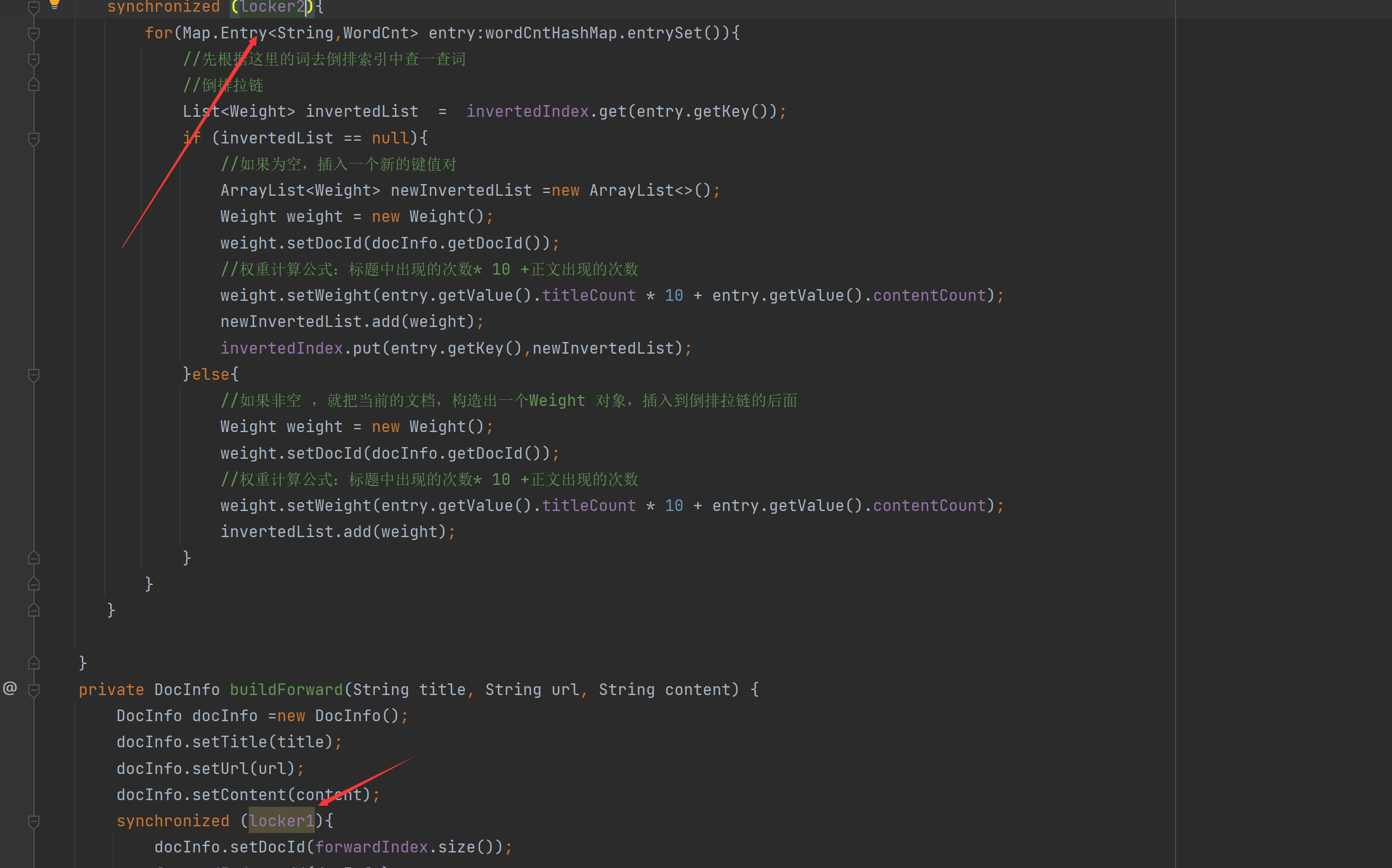
수정된 코드:
import com.fasterxml.jackson.core.type.TypeReference;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.ToAnalysis;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* Created by Lin
* Description:
* User: Administrator
* Date: 2022-12-17
* Time: 13:01
*/
//通过这个类在内存中来构造出索引结构
public class Index {
//保存索引文件的路径
private static final String INDEX_PATH ="D:\\gitee\\doc_searcher_index\\";
private ObjectMapper objectMapper = new ObjectMapper();
//使用数组下标表示 DocId
private ArrayList<DocInfo> forwardIndex = new ArrayList<>();
//使用哈希表 来表示倒排索引 key就是词 value就是一组和词关联的文章
private HashMap<String,ArrayList<Weight>> invertedIndex = new HashMap<>();
//新创建2个锁对象
private Object locker1 = new Object();
private Object locker2 = new Object();
//这个类需要提供的方法
//1.给定一个docId ,在正排索引中,查询文档的详细信息
public DocInfo getDocInfo(int docId){
return forwardIndex.get(docId);
}
//2.给定一词,在倒排索引中,查哪些文档和这个文档词关联
public List<Weight> getInverted(String term){
return invertedIndex.get(term);
}
//3.往索引中新增一个文档
public void addDoc(String title,String url,String content){
//新增文档操作,需要同时给正排索引和倒排索引新增信息
//构建正排索引
DocInfo docInfo = buildForward(title,url,content);
//构建倒排索引
buildInverted(docInfo);
}
private void buildInverted(DocInfo docInfo) {
//搞一个内部类避免出现2个哈希表
class WordCnt{
//表示这个词在标题中 出现的次数
public int titleCount ;
// 表示这个词在正文出现的次数
public int contentCount;
}
//统计词频的数据结构
HashMap<String,WordCnt> wordCntHashMap =new HashMap<>();
//1,针对文档标题进行分词
List<Term> terms = ToAnalysis.parse( docInfo.getTitle()).getTerms();
//2. 遍历分词结果,统计每个词出现的比例
for (Term term : terms){
//先判定一个term这个词是否存在,如果不存在,就创建一个新的键值对,插入进去,titleCount 设为1
//gameName()的分词的具体的词
String word = term.getName();
//哈希表的get如果不存在默认返回的是null
WordCnt wordCnt = wordCntHashMap.get(word);
if (wordCnt == null){
//词不存在
WordCnt newWordCnt = new WordCnt();
newWordCnt.titleCount =1;
newWordCnt.contentCount = 0;
wordCntHashMap.put(word,newWordCnt);
}else{
//存在就找到之前的值,然后加1
wordCnt.titleCount +=1;
}
//如果存在,就找到之前的值,然后把对应的titleCount +1
}
//3. 针对正文进行分词
terms = ToAnalysis.parse(docInfo.getContent()).getTerms();
//4. 遍历分词结果,统计每个词出现的次数
for (Term term : terms) {
String word = term.getName();
WordCnt wordCnt = wordCntHashMap.get(word);
if (wordCnt == null){
WordCnt newWordCnt = new WordCnt();
newWordCnt.titleCount = 0;
newWordCnt.contentCount = 1;
wordCntHashMap.put(word,newWordCnt);
}else {
wordCnt.contentCount +=1;
}
}
//5. 把上面的结果汇总到一个HasMap里面
// 最终的文档的权重,设置为标题的出现次数 * 10 + 正文中出现的次数
//6.遍历当前的HashMap,依次来更新倒排索引中的结构。
//并不是全部代码都是可以for循环的,只有这个对象是”可迭代的“,实现Iterable 接口才可以
// 但是Map并没有实现,Map存在意义,是根据key查找value,但是好在Set实现了实现Iterable,就可以把Map转换为Set
//本来Map存在的是戒键值对,可以根据key快速找到value,
//Set这里存的是一个把 键值对 打包在一起的类 称为Entry(条目)
//转成Set之后,失去了快速根据key快速查找value的只这样的能力,但是换来了可以遍历
synchronized (locker2){
for(Map.Entry<String,WordCnt> entry:wordCntHashMap.entrySet()){
//先根据这里的词去倒排索引中查一查词
//倒排拉链
List<Weight> invertedList = invertedIndex.get(entry.getKey());
if (invertedList == null){
//如果为空,插入一个新的键值对
ArrayList<Weight> newInvertedList =new ArrayList<>();
Weight weight = new Weight();
weight.setDocId(docInfo.getDocId());
//权重计算公式:标题中出现的次数* 10 +正文出现的次数
weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);
newInvertedList.add(weight);
invertedIndex.put(entry.getKey(),newInvertedList);
}else{
//如果非空 ,就把当前的文档,构造出一个Weight 对象,插入到倒排拉链的后面
Weight weight = new Weight();
weight.setDocId(docInfo.getDocId());
//权重计算公式:标题中出现的次数* 10 +正文出现的次数
weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);
invertedList.add(weight);
}
}
}
}
private DocInfo buildForward(String title, String url, String content) {
DocInfo docInfo =new DocInfo();
docInfo.setTitle(title);
docInfo.setUrl(url);
docInfo.setContent(content);
synchronized (locker1){
docInfo.setDocId(forwardIndex.size());
forwardIndex.add(docInfo);
}
return docInfo;
}
//4.把内存中的索引结构保存到磁盘中
public void save(){
long beg = System.currentTimeMillis();
//使用2个文件。分别保存正排和倒排
System.out.println("保存索引开始");
//1.先判断一下索引对应的目录是否存在
File indexPathFile =new File(INDEX_PATH);
if (!indexPathFile.exists()){
//如果路径不存在
//mkdirs()可以创建多级目录
indexPathFile.mkdirs();
}
//正排索引文件
File forwardIndexFile = new File(INDEX_PATH+"forward.txt");
//倒排索引文件
File invertedIndexFile = new File(INDEX_PATH+"inverted.txt");
try {
//writeValue的有个参数可以把对象写到文件里
objectMapper.writeValue(forwardIndexFile,forwardIndex);
objectMapper.writeValue(invertedIndexFile,invertedIndex);
}catch (IOException e){
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("保存索结束 !消耗时间"+(end - beg)+"ms");
}
//5.把磁盘中的索引数据加载到内存中
public void load(){
long beg = System.currentTimeMillis();
System.out.println("加载索引开始");
//1.设置加载索引路径
//正排索引
File forwardIndexFile = new File(INDEX_PATH+"forward.txt");
//倒排索引
File invertedIndexFile = new File(INDEX_PATH+"inverted.txt");
try{
//readValue()2个参数,从那个文件读,解析是什么数据
forwardIndex = objectMapper.readValue(forwardIndexFile, new TypeReference<ArrayList<DocInfo>>() {
});
invertedIndex = objectMapper.readValue(invertedIndexFile, new TypeReference<HashMap<String, ArrayList<Weight>>>() {
});
}catch (IOException e){
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("加载索引结束 ! 消耗时间"+(end -beg)+"ms");
}
public static void main(String[] args) {
Index index = new Index();
index.load();
System.out.println("索引加载完成");
}
}
5.4 인덱스 모듈 구현 - 멀티스레딩 효과 검증
다중 스레드 코드가 얼마나 빠른지 살펴보겠습니다.
멀티스레딩 전 코드 속도:

멀티 스레딩 후 코드 속도:
여전히 개선되고 있음을 확인했습니다.물론 여기서 스레드가 몇 개의 스레드를 사용한 후 몇 배로 증가한다는 의미는 아닙니다. 여기서 스레드 설정이 얼마나 적합한지 아직 실험을 통해 판단해야 합니다. 다중 스레드 코드는 완전히 동시적이지 않기 때문에 중간에 잠금 경쟁과 파일 읽기 io 작업이 포함될 수 있으며 실제로 동시성은 크게 향상되지 않고 io의 병목 현상에 갇히게 됩니다. 요컨대, 스레드가 많을수록 좋다는 것은 아닙니다.
5.4 인덱스 모듈 실현 - 프로세스가 종료되지 않는 문제 해결
우리는 실험적인 다중 스레드 프로세스가 끝나지 않았다는 것을 발견했습니다.
여기서 데몬 스레드를 언급해야 합니다.
스레드가 데몬 스레드(백그라운드 스레드)인 경우 현재 이 스레드의 실행 상태는 프로세스 결과에 영향을 미치지 않습니다.
스레드가 데몬 스레드가 아닌 경우 이 스레드의 실행 상태가 프로세스 종료에 영향을 미칩니다.
위에서 생성한 쓰레드는 데몬 쓰레드가 아니며, 메인 메소드가 실행될 때 이 쓰레드는 여전히 작동 중입니다.

스레드를 수동으로 수동으로 죽일 수 있습니다.
5.4 인덱스 모듈 구현 - 처음으로 느린 인덱스 생성 문제
기계를 다시 시작하면 첫 번째 생산 속도가 느려지고 계속해서 생산 속도가 빨라지는 것을 알 수 있습니다.그 이유는 무엇입니까?
우리는 addDoc의 구문 분석 콘텐츠가 파일을 읽기 위해 설계되었다는 것을 발견했습니다: 컴퓨터 읽기 파일은 상대적으로 비용이 많이 드는 작업입니다.
여기서 속도가 느려질 수 있다고 생각합니다.처음 실행할 때 파일 읽기 속도가 특히 느린 것 같아요?
구문 분석 콘텐츠는 다중 스레딩을 사용하기 때문에 구문 분석 시간을 정하고 인덱스에 특정 작업으로 추가하려고 시도하므로 AtomicLong을 사용하여 스레드 불안정성을 방지합니다.
시간을 개별적으로 계산합니다:
그런 다음 스레드의 끝에서 시간을 인쇄합니다.
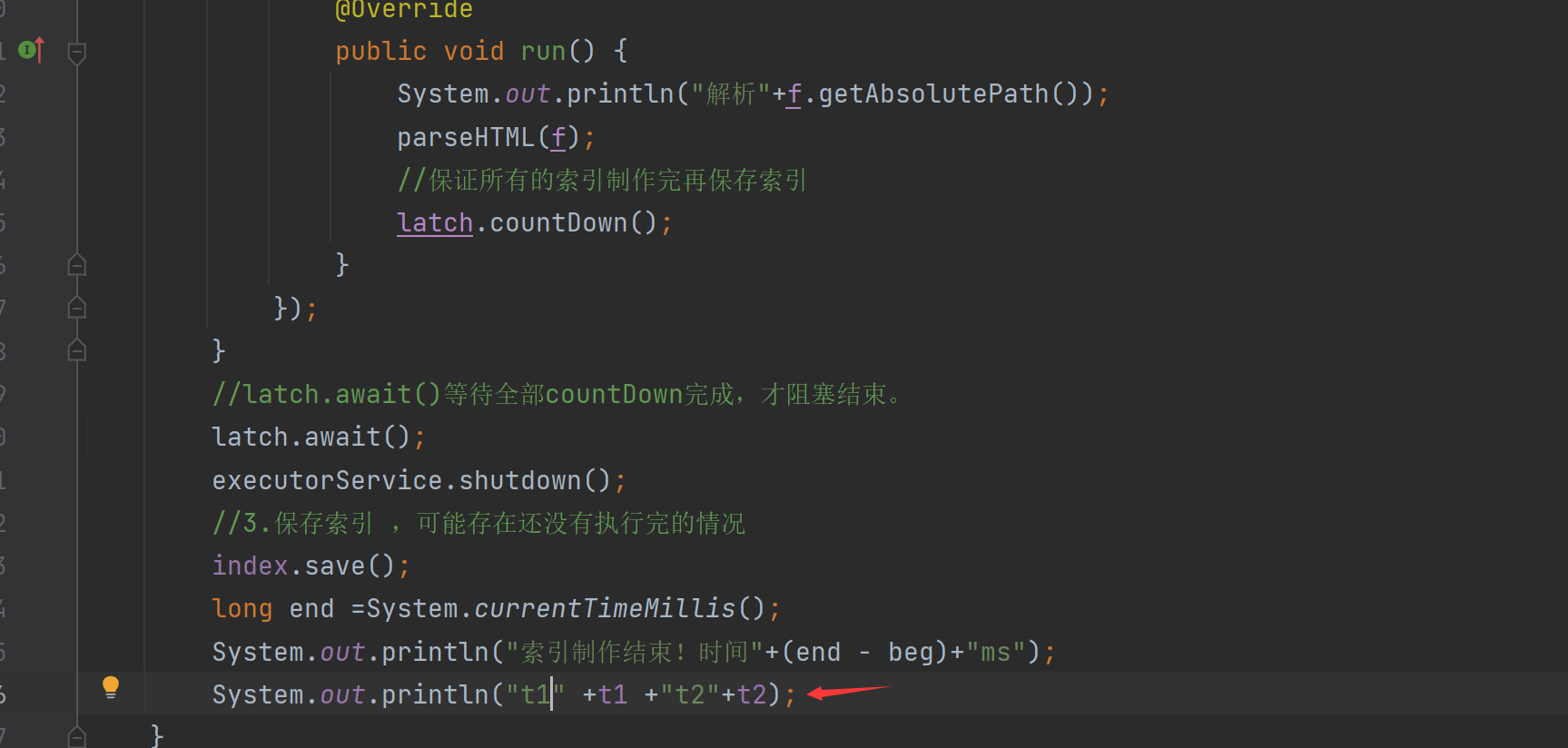
t1은 parseContent의 시간입니다.
t2는 addDoc의 시간입니다.
컴퓨터가 처음으로 다시 시작됩니다: t1은 47초이고 t2는 87초입니다.
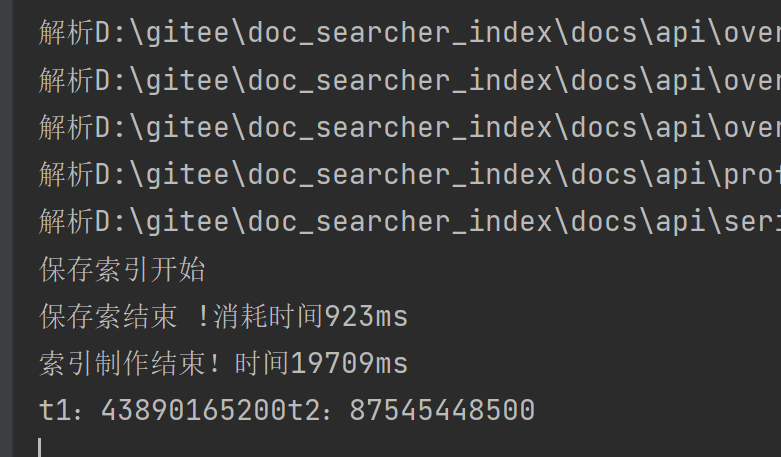
두 번째 실행이 끝났습니다.
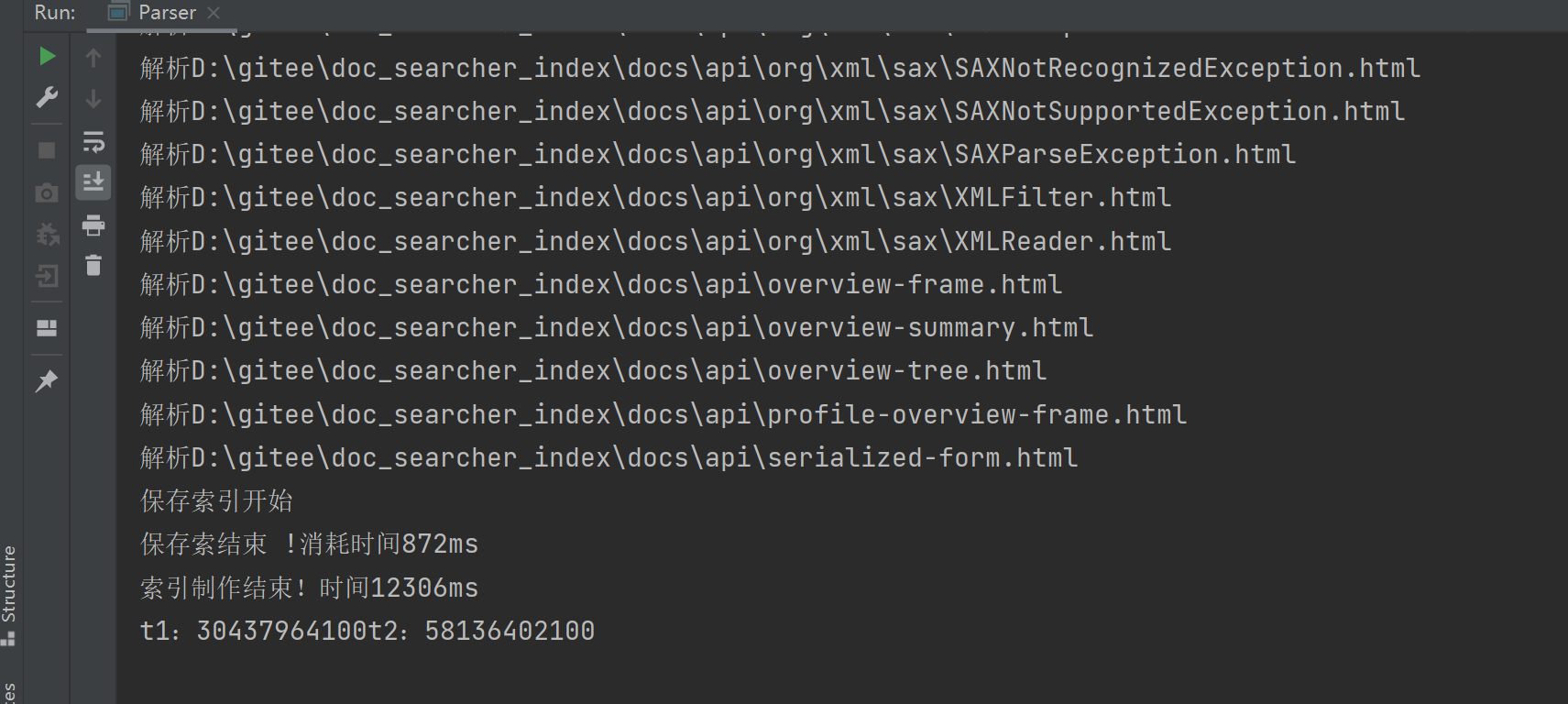
30대 및 58대 콘텐츠 구문 분석의 핵심 작업은 파일을 읽고 사전에서 액세스하는 것이며 운영 체제는 "자주 읽는 파일"을 캐시합니다.
최초 실행시 현재 Java 문서는 메모리에 캐싱되지 않아 읽기시 하드디스크에서 직접 읽기만 가능(느려짐)
나중에 다시 실행할 때 이러한 문서는 이전에 읽은 적이 있기 때문에 문서는 운영 체제의 메모리에 캐시가 있으며 두 번째 읽기는 하드 디스크를 직접 읽을 필요가 없지만 캐시를 읽으므로 직접 읽을 수 있습니다. 코드를 사용하여 문서를 캐시에 쓰는 것에 대해? 대답은 '예'입니다.
5.5 인덱스 모듈 구현 - 처음으로 느린 인덱스 생성 문제
여기서 하나씩 읽는 것이 디스크로 읽는 것임을 알 수 있습니다.
FileReader와 함께 BufferedReader를 사용하여 사용할 수 있습니다.
BufferedReader에는 FileReader의 일부 콘텐츠를 메모리로 자동으로 미리 읽을 수 있는 내장 버퍼가 있어 직접 디스크 액세스 횟수를 줄일 수 있습니다.
이 버퍼가 8k에 불과하다는 것을 알 수 있습니다. 각 html 파일은 10k 이상이며 구성 매개변수를 사용하여 여기에서 더 크게 만들 수 있습니다.

운영 체제가 이미 읽은 파일을 캐시했기 때문에 성능을 향상시키기 위해 수동으로 캐시를 설정하고 버퍼 영역을 운영 체제가 크게 개선되지 않을 수 있습니다. 문제가 발생하면 약간의 도움이 없는 것보다 낫습니다.
5.5 인덱스 모듈 구현 - 인덱스 로딩 로직 확인
이 로드의 로딩 로직을 살펴보고 유용한지 살펴보겠습니다.
index 클래스에 main 메소드를 만들어서 사용해보자
결과:
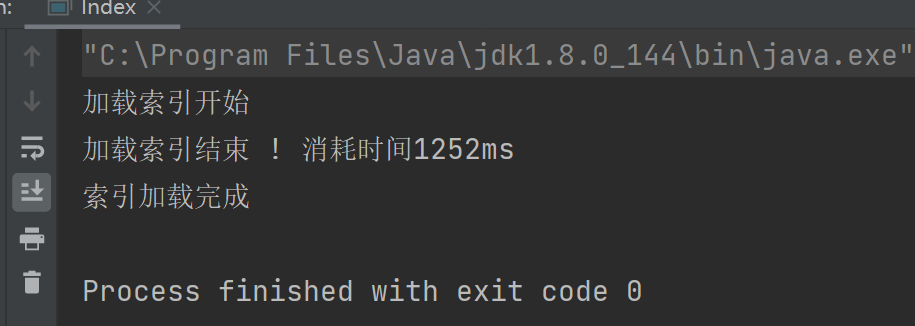
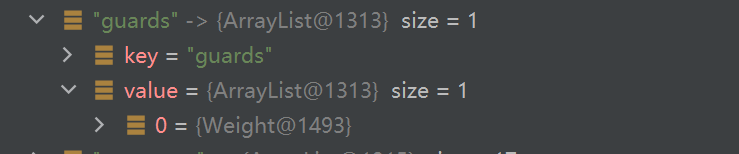
로드한 인덱스가 어떻게 보이는지 디버그해 봅시다.
이것은 정방향 색인입니다.

이것은 역방향 색인입니다.
5.6 색인 모듈 구현 - 색인 모듈 요약
우리 모두 어떤 일을 했습니까? 요약하자면
- Parser 클래스 구현
- 모든 HTML 파일을 재귀적으로 열거
- 여기에서 각 HTML에 대한 구문 분석 작업을 수행합니다.
- 제목: HTML 파일 제목을 직접 사용
- URL: 파일의 경로(오프라인 문서와 온라인 문서 경로 간의 관계)를 기반으로 한 단순 스플라이싱
- 텍스트: 태그를 제거하려면 간단하고 무례한 방식으로 < >를 사용하여 복사 여부를 판단합니다.
- 파싱된 결과를 인덱스 클래스(addDoc)에 넣습니다.
Parser 클래스를 통해 가장 중요한 것은 Index 클래스가 인덱스 생성을 완료하도록 돕는 것입니다.
싱글스레드 제작으로 시작해서 멀티스레드로 전환했는데 멀티스레드도 잘 처리해야 하고 모든 문서가 처리되어야 인덱스를 저장할 수 있습니다.
다른 하나는 파일을 읽는 속도인데요, 처음 실험을 통해 인덱스를 만들었을 때는 디스크에 직접 접근하고 캐시에 도달하지 못해서 너무 느렸습니다. 나중에 BufferedReader로 변경했습니다.
- Parser 클래스
의 핵심 속성 을 구현했습니다.- 정방향 인덱스: ArrayList 각 DocInfo는 id, 제목, URL, 내용을 포함하는 문서를 나타냅니다.
- 반전된 인덱스: HashMap<String,ArrayList> 각 키-값 쌍은 단어가 나타난 문서를 나타냅니다.
- Weight에는 문서 ID뿐만 아니라 무게도 포함됩니다.
- 가중치는 현재 해당 단어가 문서에만 나타날 수 있는 빈도(제목이 나타나는 횟수 * 10 + 텍스트가 나타나는 횟수)로 계산됩니다.
핵심 방법:
- 양수 행을 확인하고 아래 첨자에 따라 ArrayList의 요소를 직접 가져옵니다.
- 역 행을 확인하고 키에 따라 HashMap<String, ArrayList>의 값을 직접 가져옵니다.
- 문서를 추가하면 Parser 클래스가 인덱스를 만들 때 이 메서드를 호출합니다.
- 앞줄 만들기: docInfo 개체를 구성하고 앞줄 인덱스 끝에 추가합니다.
- 반전 행 만들기: 먼저 단어 분할을 수행하고, 단어 빈도를 계산하고, 단어 분할 결과를 트래버스하고, 반전 인덱스의 해당 반전 지퍼를 업데이트합니다.
공용 객체는 스레드 안전성을 고려해야 합니다.
- 인덱스 저장, 인덱스 데이터를 json 형식을 기반으로 지정된 파일에 저장
- 인덱스를 로드하고, json 형식을 기반으로 데이터를 분석하고, 파일의 내용을 읽어 메모리에 파싱합니다.
여섯, 검색 모듈 실현 - 검색 모듈 기사
색인 모듈을 호출하여 검색의 핵심 프로세스 완료
- 사용자가 입력한 질의어 에 대한 단어 분할 (사용자가 입력한 질의어는 단어가 아니라 문장일 수 있음)
- 트리거, 단어 세그먼테이션 결과 얻기, 역색인에서 검색, 관련 문서 찾기~ (색인 클래스를 호출하여 역방향 방법 확인)
- 정렬, 위에서 트리거된 결과 정렬(관련성, 내림차순)
- 패키징 결과는 정렬된 결과에 따라 포지티브 행을 차례로 확인하고 각 문서의 상세 정보를 획득하여 특정 구조로 패키징된 데이터를 반환합니다.
물론 여기에서 우리는 단순한 검색 엔진 일 뿐이며 실제 검색 엔진과 비교할 수 없습니다.
6.1 검색 모듈 구현 - DocSearcher 클래스 생성
이 클래스를 통해 전체 검색 프로세스를 완료하십시오.
import java.util.List;
/**
* Created by Lin
* Description:
* User: Administrator
* Date: 2022-12-21
* Time: 13:22
*/
public class DocSearcher {
private Index index = new Index();
public DocSearcher(){
//一开始要加载
index.load();
}
//完成整个搜索过程的方法
//参数(输入部分)就是用户给出的查询词
//返回值(输出部分)就是搜索结果的集合
public List<Result> search(String query){
//1.[分词]针对query这个查询词进行分词
//2.[触发]针对分词结果来查倒排
//3.[排序]针对触发的结果按照权重降序排序
//4.[包装结果]针对排序的结果,去查正排,构造出要返回的数据
return null;
}
}
필요한 반환 값은 많은 검색 결과입니다.
또한 인덱스 로드를 완료해야 합니다. 구성 메서드에서 직접 사용합니다.
검색 결과를 나타내는 클래스를 만들고 있습니다.
/**
* Created by Lin
* Description:
* User: Administrator
* Date: 2022-12-21
* Time: 13:24
*/
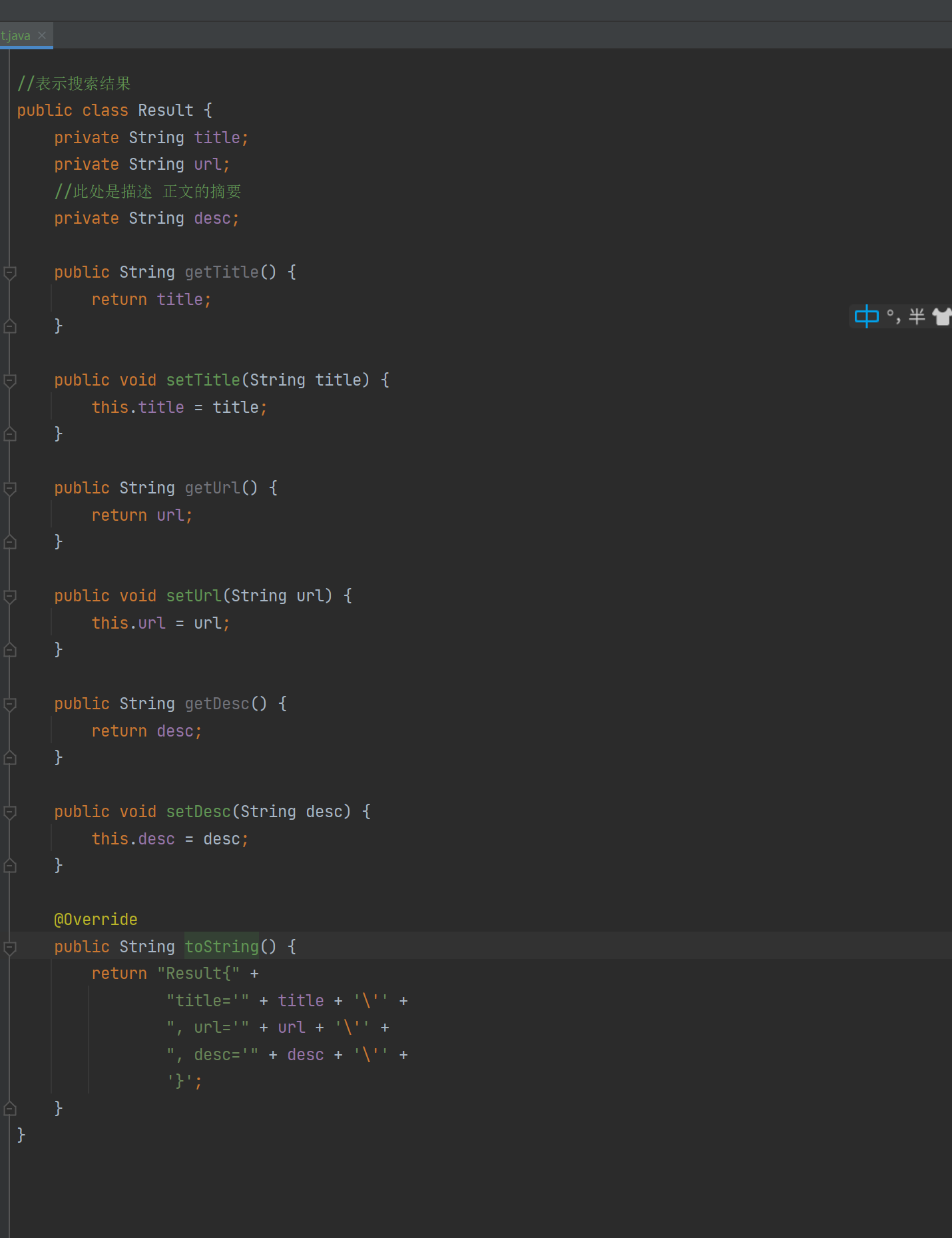
//表示搜索结果
public class Result {
private String title;
private String url;
//此处是描述 正文的摘要
private String desc;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
}
본문의 일부를 표시하고 있으므로 Result 클래스는 제목, URL 및 요약입니다.
6.2 검색 모듈 구현 - 검색 방법 구현 (1)
첫 번째 부분에서 구현하려는 작업은 다음과 같습니다.
-
단어 분할 : 질의 단어 질의를 위한 단어 분할
-
트리거 : 단어 분할 결과에 대한 역순위 확인
-
Sorting : 가중치 내림차순으로 트리거 결과 정렬
-
패키징 결과 : 정렬된 결과는 양수 행을 확인하고 반환할 데이터를 구성합니다.
public List<Result> search(String query) {
//1.[分词]针对query这个查询词进行分词
List<Term> terms = ToAnalysis.parse(query).getTerms();
//2.[触发]针对分词结果来查倒排
List<Weight> allTermResult = new ArrayList<>();
for (Term term : terms) {
String word = term.getName();
List<Weight> invertedList = index.getInverted(word);
if (invertedList == null) {
//说明词不存在
continue;
}
allTermResult.addAll(invertedList);
}
// 3.[排序]针对触发的结果按照权重降序排序
allTermResult.sort(new Comparator<Weight>() {
@Override
public int compare(Weight o1, Weight o2) {
//降序排序 return o2.getWeight-01.getWeight 升序反之
return o2.getWeight() - o1.getWeight();
}
});
//4.[包装结果]针对排序的结果,去查正排,构造出要返回的数据
List<Result> results = new ArrayList<>();
for (Weight weight : allTermResult) {
DocInfo docInfo = index.getDocInfo(weight.getDocId());
Result result = new Result();
result.setTitle(docInfo.getTitle());
result.setUrl(docInfo.getUrl());
result.setDesc(GenDesc(docInfo.getContent(),terms));
results.add(result);
}
return results;
}
여기서 우리는 네 번째 단계에 주목해야 합니다. 역순위에서 일부 가중치와 문서 ID만 얻었기 때문에 세부 내용을 알지 못하고 세부 내용은 여전히 정방향 인덱스로 이동해야 합니다.
우리의 초록도 있습니다. 우리가 찾은 것은 모든 기사입니다. 최종 결과를 구성하는 데 필요한 것은 설명입니다. 이 설명은 본문에서 가져오며 쿼리 단어의 일부도 포함합니다.
다음으로 설명을 생성하겠습니다.
6.2 검색 모듈 구현 - 검색 방법 구현 (2)
위의 설명 세대에 대해 말하면 우리의 아이디어는 먼저 다음과 같이 작성됩니다.
- 모든 단어 분할 결과를 얻고 단어 분할 결과를 탐색할 수 있습니다.
- 텍스트에 어떤 결과가 나타나는지 확인하십시오. 현재 문서에는 모든 단어 세분화 결과가 포함되어 있지 않을 수 있습니다.
- 이 포함된 결과의 경우 텍스트로 이동하여 현재 쿼리 단어의 해당 위치를 찾습니다.
- 설명을 생성하려면 현재 위치보다 앞의 60자를 설명의 시작으로 사용할 수 있으며 시작 후 160자를 전체 설명으로 가로 챌 수 있습니다.

private String GenDesc(String content, List<Term> terms) {
//先遍历结果,看看哪个结果是在content中存在
int firstPos = -1;
for (Term term : terms) {
String word = term.getName();
//因为分词结果是会把正文转成小写,所以我们要把查询词也转成小写
//为了搜索结果独立成词 所以加" "
firstPos =content.toLowerCase().indexOf(" " + word + " ");
if (firstPos >= 0){
break;
}
if(firstPos ==-1){
//所有的分词结果都不在正文中存在 极端情况
return content.substring(0,160)+"...";
}
}
//从firstPos 作为基准,往前找60个字符,作为描述的起始位置
String desc ="";
//如果当前位置少于60个字符开始位置就是第一个 否则开始位置 在查询词前60个
int descBeg = firstPos < 60 ? 0 : firstPos -60;
if (descBeg+160 > content.length()){
//判断是否超过正文长度
//从开始位置到最后
desc = content.substring(descBeg);
}else {
desc =content.substring(descBeg,descBeg + 160)+"...";
}
return desc;
}
이 단락에서 설명을 생성하는 코드의 핵심 아이디어는
문서 단어가 위치한 기사의 위치를 찾고 쿼리 단어의 처음 60자 및 뒤의 160자에 따라 문서 설명을 가로채는 것입니다. 검색어;
6.3 검색 모듈 구현 - 단순 유효성 검사
먼저 Reslut 결과에 toString을 추가하여 확인하겠습니다.
현재 검색 클래스의 모든 코드
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.ToAnalysis;
import java.util.*;
/**
* Created by Lin
* Description:
* User: Administrator
* Date: 2022-12-21
* Time: 13:22
*/
public class DocSearcher {
private Index index = new Index();
public DocSearcher() {
//一开始要加载
index.load();
}
//完成整个搜索过程的方法
//参数(输入部分)就是用户给出的查询词
//返回值(输出部分)就是搜索结果的集合
public List<Result> search(String query) {
//1.[分词]针对query这个查询词进行分词
List<Term> terms = ToAnalysis.parse(query).getTerms();
//2.[触发]针对分词结果来查倒排
List<Weight> allTermResult = new ArrayList<>();
for (Term term : terms) {
String word = term.getName();
List<Weight> invertedList = index.getInverted(word);
if (invertedList == null) {
//说明词不存在
continue;
}
allTermResult.addAll(invertedList);
}
// 3.[排序]针对触发的结果按照权重降序排序
allTermResult.sort(new Comparator<Weight>() {
@Override
public int compare(Weight o1, Weight o2) {
//降序排序 return o2.getWeight-01.getWeight 升序反之
return o2.getWeight() - o1.getWeight();
}
});
//4.[包装结果]针对排序的结果,去查正排,构造出要返回的数据
List<Result> results = new ArrayList<>();
for (Weight weight : allTermResult) {
DocInfo docInfo = index.getDocInfo(weight.getDocId());
Result result = new Result();
result.setTitle(docInfo.getTitle());
result.setUrl(docInfo.getUrl());
result.setDesc(GenDesc(docInfo.getContent(),terms));
results.add(result);
}
return results;
}
private String GenDesc(String content, List<Term> terms) {
//先遍历结果,看看哪个结果是在content中存在
int firstPos = -1;
for (Term term : terms) {
String word = term.getName();
//因为分词结果是会把正文转成小写,所以我们要把查询词也转成小写
//为了搜索结果独立成词 所以加" "
firstPos =content.toLowerCase().indexOf(" " + word + " ");
if (firstPos >= 0){
break;
}
if(firstPos ==-1){
//所有的分词结果都不在正文中存在 极端情况
return content.substring(0,160)+"...";
}
}
//从firstPos 作为基准,往前找60个字符,作为描述的起始位置
String desc ="";
//如果当前位置少于60个字符开始位置就是第一个 否则开始位置 在查询词前60个
int descBeg = firstPos < 60 ? 0 : firstPos -60;
if (descBeg+160 > content.length()){
//判断是否超过正文长度
//从开始位置到最后
desc = content.substring(descBeg);
}else {
desc =content.substring(descBeg,descBeg + 160)+"...";
}
return desc;
}
public static void main(String[] args) {
DocSearcher docSearcher = new DocSearcher();
Scanner scanner = new Scanner(System.in);
while (true) {
System.out.print("->");
String query = scanner.next();
List<Result> results = docSearcher.search(query);
for (Result result : results) {
System.out.println("======================================");
System.out.println(result);
}
}
}
}
결과: ArrayList를 찾아보니 정렬과 필요한 것은 다 있었는데 노란색 박스에 표시된게 있었는데 사실은 js 코드라는 것을 유심히 찾았습니다.

왜 나타납니까? 우리는 HTML 페이지에서 태그를 제거하기만 하지만 일부 HTML에는 <script> 태그가 포함되어 있어 태그를 제거해도 js 코드로 연결됩니다. 나중에 이 문제를 차례로 해결하겠습니다.
6.4 검색 모듈 구현 - 정규식 사용
위의 스크립트 태그의 경우 태그와 콘텐츠를 모두 제거해야 합니다. 여기서는 정규식을 사용합니다.
Java의 String에는 일반 indexOf, replace, replaceAll, split 등을 지원하는 많은 메서드가 있습니다.
일반 부품 기호 규칙을 간단히 소개하겠습니다.
.는 개행 문자가 아닌 문자와 일치함을 의미합니다(\n 또는 \r이 아님).
* 이전 문자가 여러 번 나타날 수 있음을 나타냅니다.
.* 줄 바꿈이 아닌 문자의 여러 항목과 일치합니다.
? non-greedy 매칭, 조건에 맞는 가장 짧은 결과 매칭 (greedy: 최대한 길게 매칭, 조건에 맞는 가장 긴 결과 매칭)
이제 <.*> 규칙이 있다고 가정하고 문서는 <div>aaa</div> <div>bbb</div>이며 탐욕적인 일치인 경우 모든 파란색 장소와 일치합니다.

테스트 사이트로 이동하여 살펴볼 수도 있습니다.
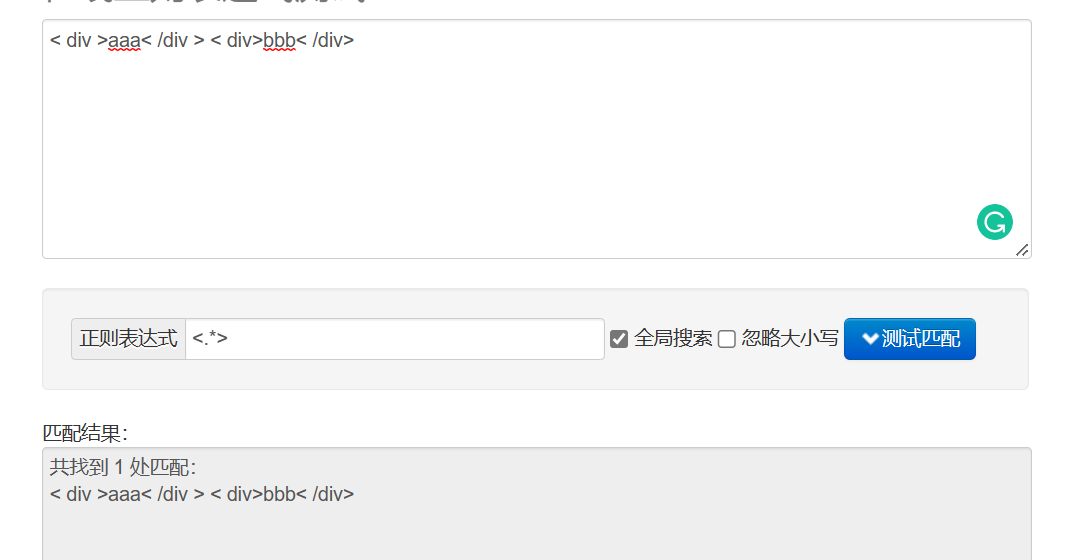
탐욕스럽지 않은 일치 <.*?>를 추가하는 경우:
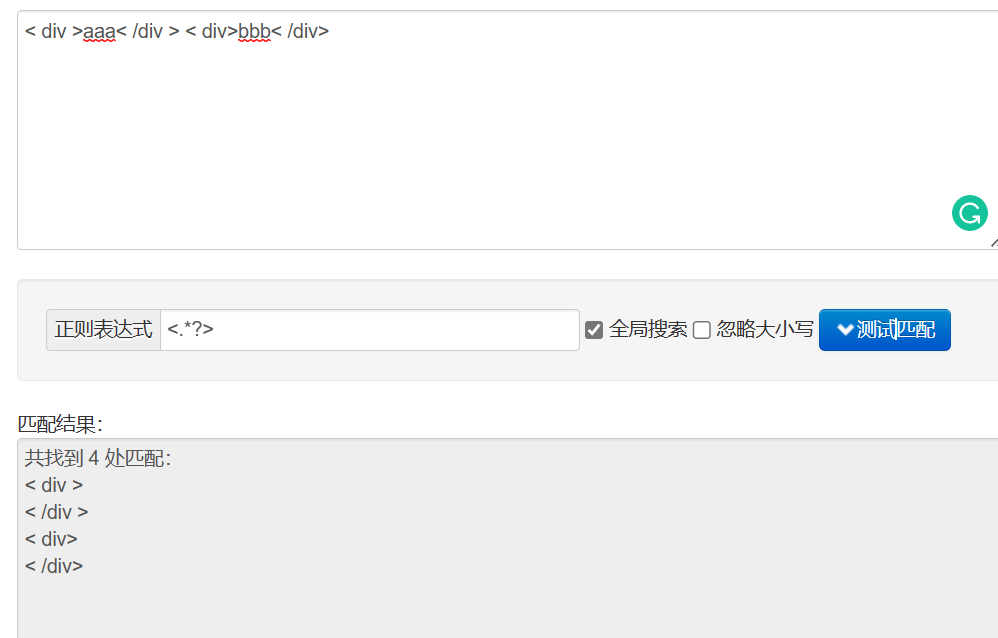
공백으로 대체하는 효과: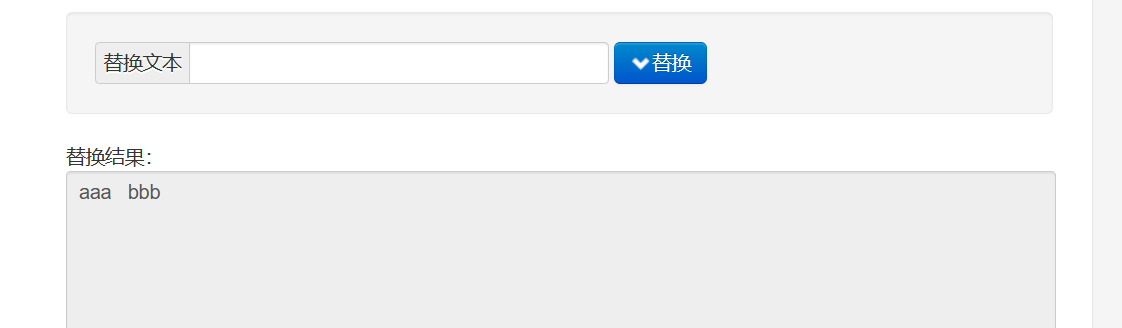
스크립트 태그 및 콘텐츠 정규화를 제거하려면 다음과 같이 작성할 수 있습니다.
< script. >(. )</script> 특성과 콘텐츠를 문자 일치로 처리
콘텐츠를 제거하지 않고 일반 태그 제거
<.* >는 시작 태그와 종료 태그 모두와 일치할 수 있습니다.
6.5 검색 모듈 구현 - 스크립트 태그 및 해당 콘텐츠 교체
다음을 교체해 보겠습니다.
private String readFile(File f){
try(BufferedReader bufferedReader = new BufferedReader(new FileReader(f))){
StringBuilder content = new StringBuilder();
while(true){
int ret = bufferedReader.read();
if (ret==-1){
break;
}
char c = (char) ret;
if (c=='\n' || c == '\r'){
c= ' ';
}
content.append(c);
}
return content.toString();
}catch (IOException e){
e.printStackTrace();
}return "";
}
public String parseContentRegex(File f){
//1.先把整个文件都读取到String里面
String content = readFile(f);
//2.替换script标签
content = content.replaceAll("<script.*?>(.*?)</script>"," ");
//3.替换普通的HTML标签
content = content.replaceAll("<.*?>"," ");
//4.使用正则把多个空格,合并成一个空格
content = content.replaceAll("\\s+"," ");
return content;
}
여기서 주목해야 할 것은 대체 순서입니다.script 태그는 먼저 html 태그에 있어야 합니다. 그렇지 않으면 문제가 발생합니다.마지막으로 비교 효과를 테스트해 보겠습니다.

js 코드가 사라진 것을 알 수 있습니다. 이 공간에 공백이 너무 많습니다. 이 부분도 저희가 조정했습니다. /s+는 한 번 이상 쿼리하라는 의미입니다.
그런 다음 교체하고 다시 인덱싱합니다.
Parser 클래스의 모든 코드:
import com.sun.org.apache.regexp.internal.RE;
import java.io.*;
import java.util.ArrayList;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicLong;
/**
* Created by Lin
* Description:
* User: Administrator
* Date: 2022-12-15
* Time: 19:15
*/
public class Parser {
//先指定一个加载文档的路径 ,由于是固定路径 我们使用 static 类属性 不需要变final
private static final String INPUT_PATH ="D:\\gitee\\doc_searcher_index\\docs\\api"; // 只需要api文件夹下的文件
//创建一个Index实例
private Index index =new Index();
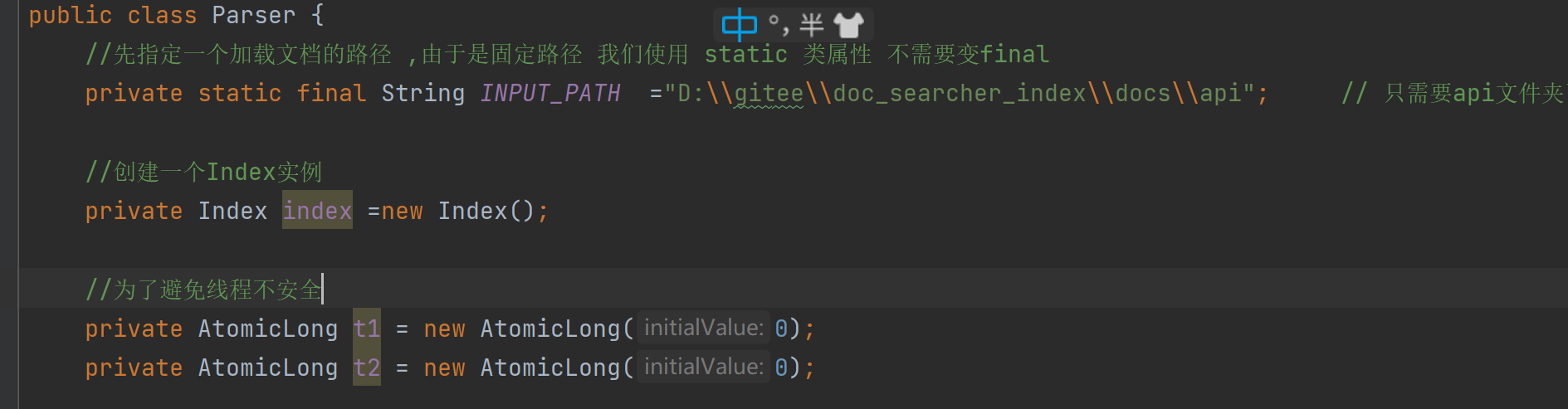
//为了避免线程不安全
private AtomicLong t1 = new AtomicLong(0);
private AtomicLong t2 = new AtomicLong(0);
//通过这个方法实现单线程制作索引
public void run(){
long beg = System.currentTimeMillis();
System.out.println("索引制作开始");
//整个Parser类的入口
//1.根据指定的路径去枚举出该路径中所有的文件(所有子目录的html文件),这个过程需要把全部子目录的文件全部获取到
ArrayList<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH,fileList);
//测试枚举时间
long endEnumFile = System.currentTimeMillis();
System.out.println("枚举文件完毕 时间"+(endEnumFile - beg));
//2.针对上面罗列出的路径,打开文件,读取文件内容,并进行解析.并构建索引
for (File f :fileList){
//通过这个方法解析单个HTML文件
System.out.println("开始解析:" + f.getAbsolutePath());
parseHTML(f);
}
long endFor = System.currentTimeMillis();
System.out.println("循环遍历文件完毕 时间"+(endFor - endEnumFile)+"ms");
//3. 把内存中构造好的索引数据结构,保存到指定的文件中
index.save();
long end = System.currentTimeMillis();
System.out.println("索引制作完毕,消耗时间:"+(end - beg) + "ms");
}
//通过这个方法实现多线程制作索引
public void runByThread() throws InterruptedException {
long beg =System.currentTimeMillis();
System.out.println("索引制作开始!");
//1.,枚举全部文件
ArrayList<File> files = new ArrayList<>();
enumFile(INPUT_PATH,files);
//2.循环遍历文件 此处为了通过多线程制作索引,就直接引入线程池
CountDownLatch latch = new CountDownLatch(files.size());
ExecutorService executorService = Executors.newFixedThreadPool(8);
for(File f:files){
//添加任务submit到线程池
executorService.submit(new Runnable() {
@Override
public void run() {
System.out.println("解析"+f.getAbsolutePath());
parseHTML(f);
//保证所有的索引制作完再保存索引
latch.countDown();
}
});
}
//latch.await()等待全部countDown完成,才阻塞结束。
latch.await();
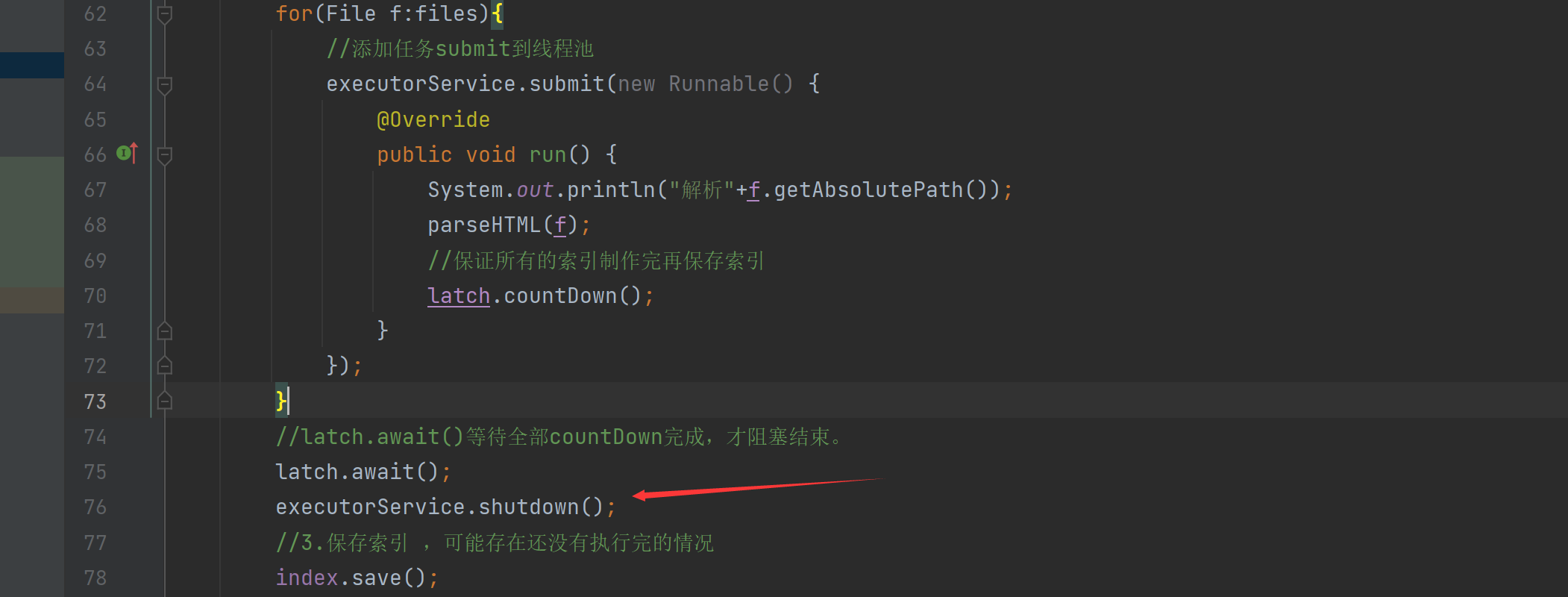
executorService.shutdown();
//3.保存索引 ,可能存在还没有执行完的情况
index.save();
long end =System.currentTimeMillis();
System.out.println("索引制作结束!时间"+(end - beg)+"ms");
System.out.println("t1:" +t1 +"t2:"+t2);
}
//通过这个方法解析单个HTML文件
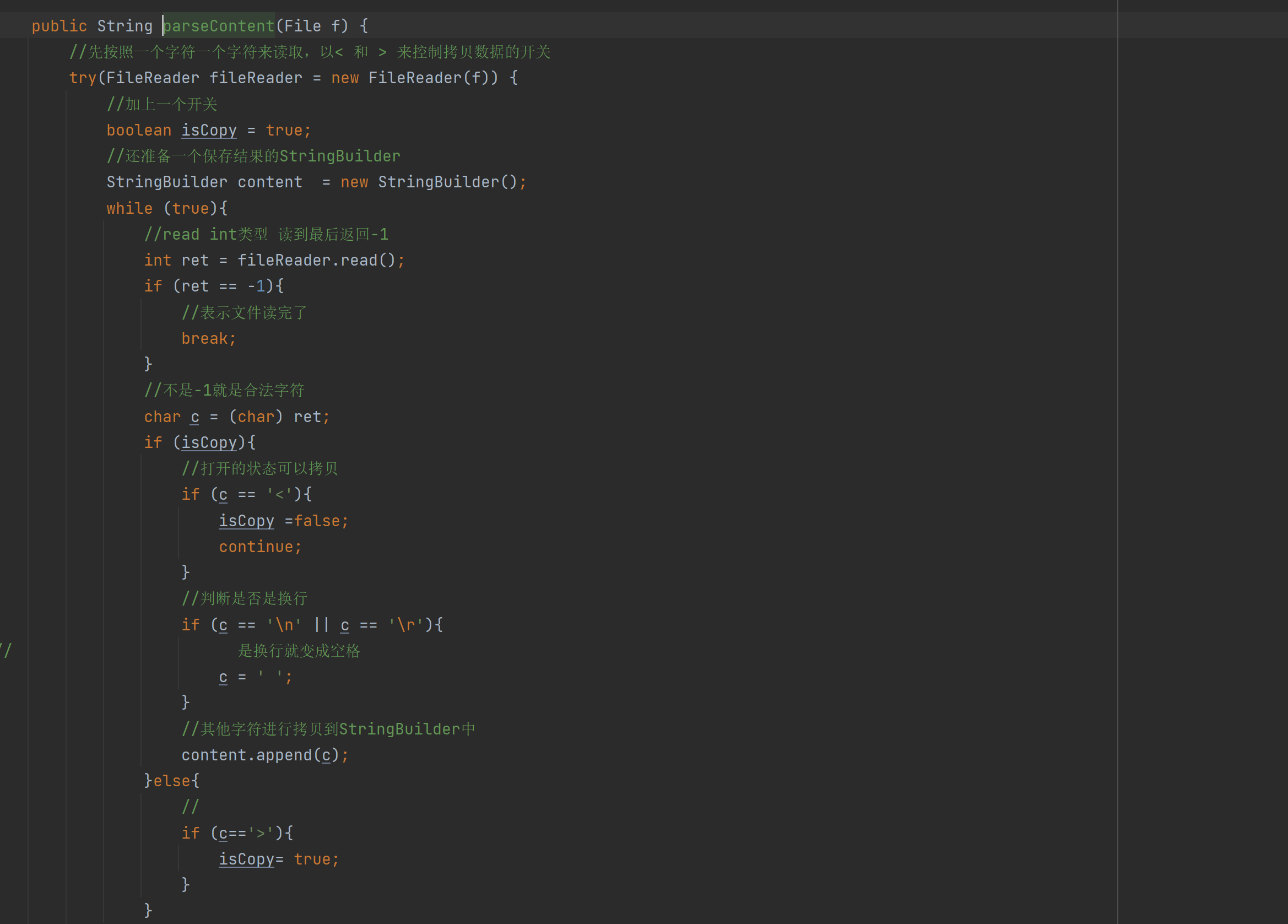
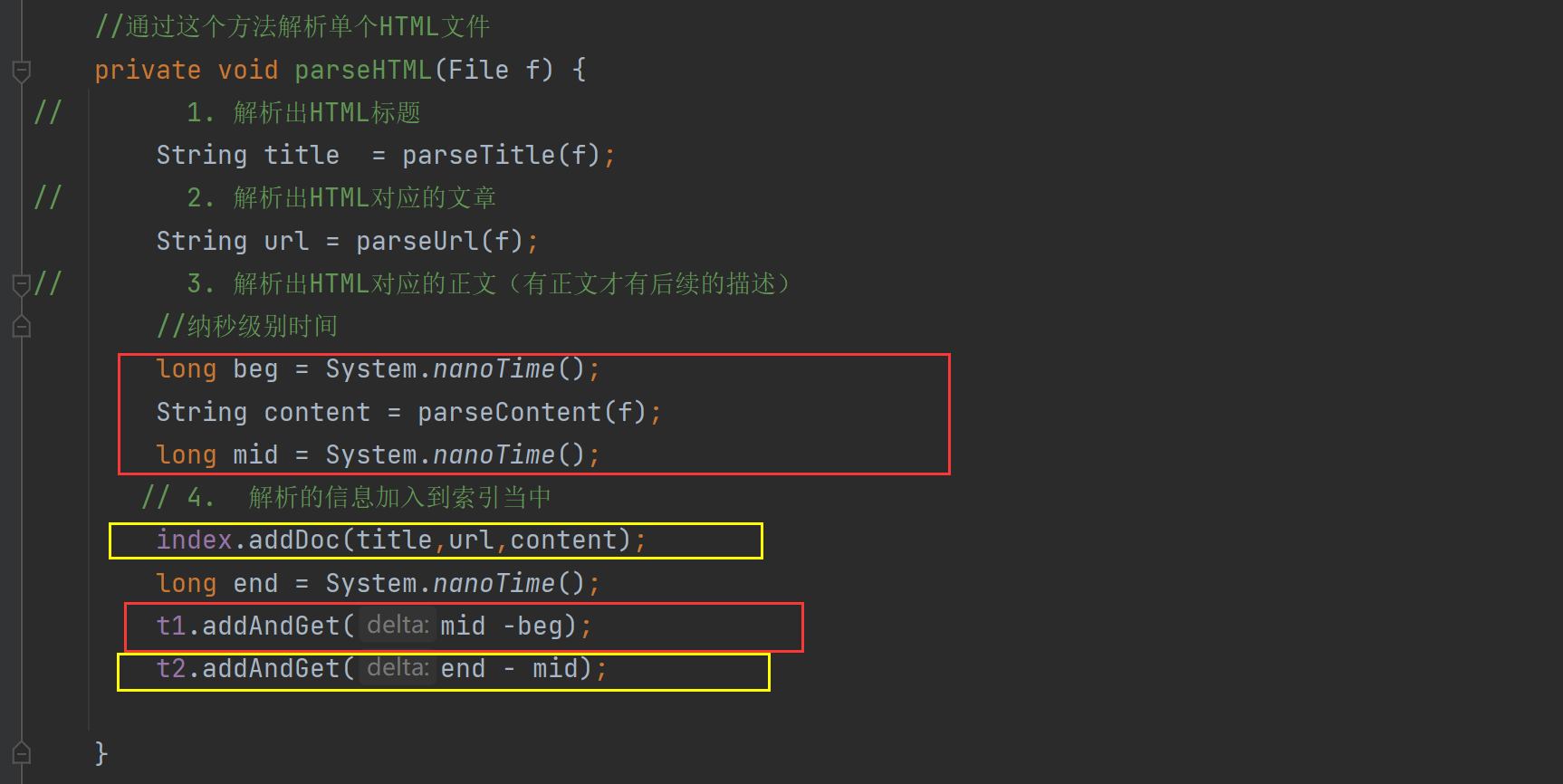
private void parseHTML(File f) {
// 1. 解析出HTML标题
String title = parseTitle(f);
// 2. 解析出HTML对应的文章
String url = parseUrl(f);
// 3. 解析出HTML对应的正文(有正文才有后续的描述)
//纳秒级别时间
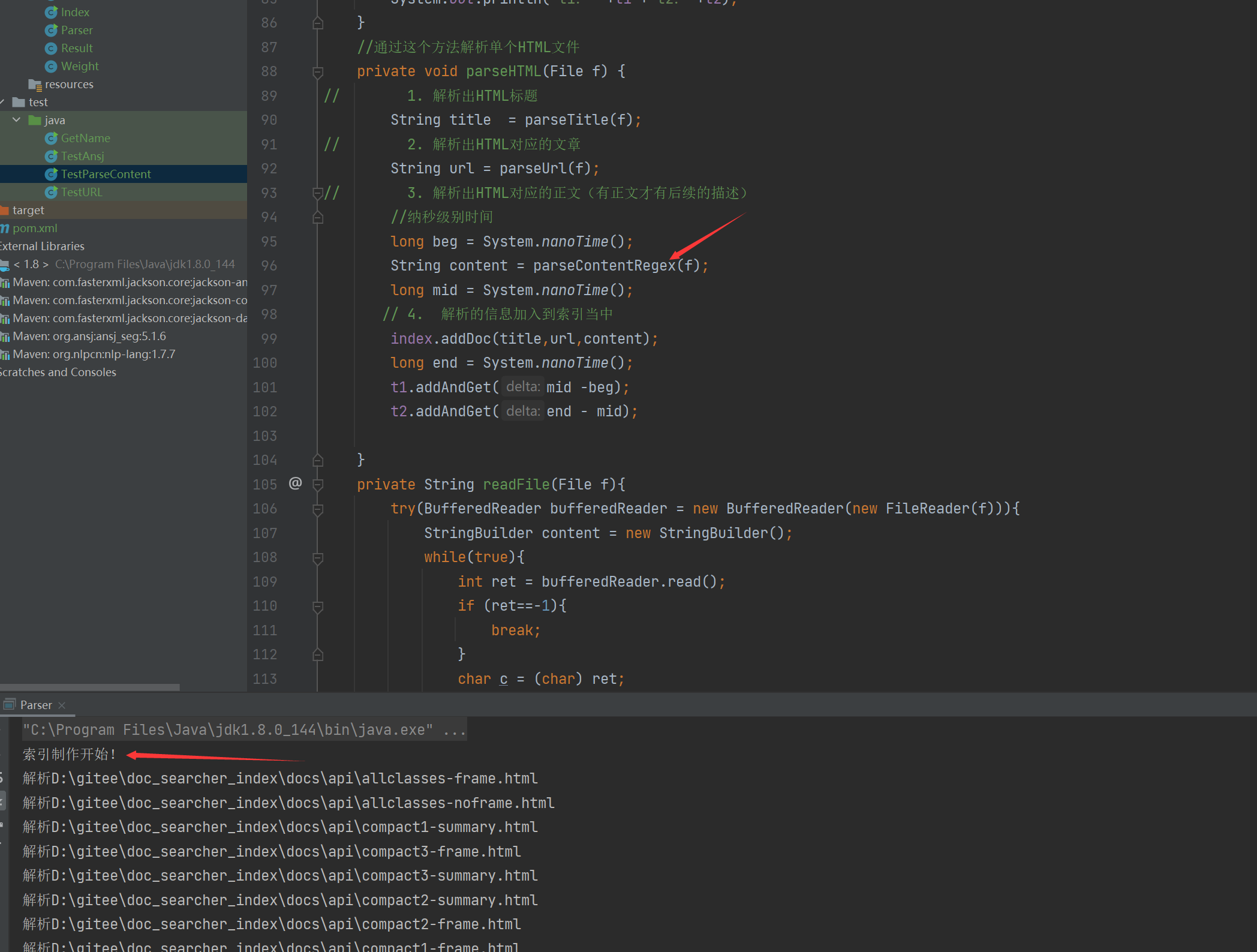
long beg = System.nanoTime();
String content = parseContentRegex(f);
long mid = System.nanoTime();
// 4. 解析的信息加入到索引当中
index.addDoc(title,url,content);
long end = System.nanoTime();
t1.addAndGet(mid -beg);
t2.addAndGet(end - mid);
}
private String readFile(File f){
try(BufferedReader bufferedReader = new BufferedReader(new FileReader(f))){
StringBuilder content = new StringBuilder();
while(true){
int ret = bufferedReader.read();
if (ret==-1){
break;
}
char c = (char) ret;
if (c=='\n' || c == '\r'){
c= ' ';
}
content.append(c);
}
return content.toString();
}catch (IOException e){
e.printStackTrace();
}return "";
}
public String parseContentRegex(File f){
//1.先把整个文件都读取到String里面
String content = readFile(f);
//2.替换script标签
content = content.replaceAll("<script.*?>(.*?)</script>"," ");
//3.替换普通的HTML标签
content = content.replaceAll("<.*?>"," ");
//4.使用正则把多个空格,合并成一个空格
content = content.replaceAll("\\s+"," ");
return content;
}
public String parseContent(File f) {
//先按照一个字符一个字符来读取,以< 和 > 来控制拷贝数据的开关
try(BufferedReader bufferedReader = new BufferedReader(new FileReader(f),1024 *1024)) {
//加上一个开关
boolean isCopy = true;
//还准备一个保存结果的StringBuilder
StringBuilder content = new StringBuilder();
while (true){
//read int类型 读到最后返回-1
int ret = bufferedReader.read();
if (ret == -1){
//表示文件读完了
break;
}
//不是-1就是合法字符
char c = (char) ret;
if (isCopy){
//打开的状态可以拷贝
if (c == '<'){
isCopy =false;
continue;
}
//判断是否是换行
if (c == '\n' || c == '\r'){
// 是换行就变成空格
c = ' ';
}
//其他字符进行拷贝到StringBuilder中
content.append(c);
}else{
//
if (c=='>'){
isCopy= true;
}
}
}
return content.toString();
} catch (IOException e) {
e.printStackTrace();
}
return "";
}
private String parseUrl(File f) {
//固定的前缀
String path = "https://docs.oracle.com/javase/8/docs/api/";
//只放一个参数的意思是:前面一段都不需要,取后面的一段
String path2= f.getAbsolutePath().substring(INPUT_PATH.length());
return path + path2;
}
private String parseTitle(File f) {
//获取文件名
String name = f.getName();
return name.substring(0,name.length()-".html".length());
}
//第一个参数表示从那个目录开始进行遍历,第二个目录表示递归得到的结果
private void enumFile(String inputPath, ArrayList<File> fileList) {
//我们需要把String类型的路径变成文件类 好操作点
File rootPath = new File(inputPath);
//listFiles()类似于Linux的ls把当前目录中包含的文件名获取到
//使用listFiles只可以看见一级目录,想看到子目录需要递归操作
File[] files = rootPath.listFiles();
for (File file : files) {
//根据当前的file的类型,觉得是否递归
//如果file是普通文件就把file加入到listFile里面
//如果file是一个目录 就递归调用enumFile这个方法,来进一步获取子目录的内容
if (file.isDirectory()){
//根路径要变
enumFile(file.getAbsolutePath(),fileList);
}else {
//只针对HTML文件
if(file.getAbsolutePath().endsWith(".html")){
//普通HTML文件
fileList.add(file);
}
}
}
}
public static void main(String[] args) throws InterruptedException {
//通过main方法来实现整个制作索引的过程
Parser parser = new Parser();
parser.runByThread();
}
}

완벽한 솔루션 을 보려면 검색 카테고리로 돌아가십시오 .
6.6 검색 모듈 구현 - 검색 모듈 요약
검색 모듈은 주로 Searcher 클래스의 검색 방법을 구현하는 것입니다.
1. 세분화 2. 트리거 3. 정렬 4. 결과 패키징 이전에 구현된 준비된 작업을 함께 묶습니다.
지금 우리가 얼마나 간단한지는 아직 비즈니스 로직이 없기 때문입니다.
여기 다른 사람들도 사진, 지역 등을 표시하고 다양한 사용자 경험이 가득합니다.
미래에 우리가 실제로 기술을 개발할 때 여전히 비즈니스에 서비스를 제공해야 합니다. 다음으로 웹 모듈 구현을 시작합니다.
7. 웹 모듈 구현 - 프런트엔드 및 백엔드 상호 작용 인터페이스에 동의
다음으로 웹 모듈을 구현하고 웹 인터페이스를 제공하고 프로그램을 사용자에게 제공해야 합니다.
프런트엔드(HTML+css+js) + 백엔드(java, servlet / Spring):
여기에서는 인터페이스를 구현하기만 하면 됩니다. 인터페이스를 검색하기만 하면 됩니다.

7.1 웹 모듈 구현 - Servlet 기반 백엔드 구현
먼저 서블릿을 사용하여 구현한 다음 스프링 부트를 변경합니다.
내 Tomcat은 8.5.x이므로 서블릿 버전 3.1을 사용합니다.
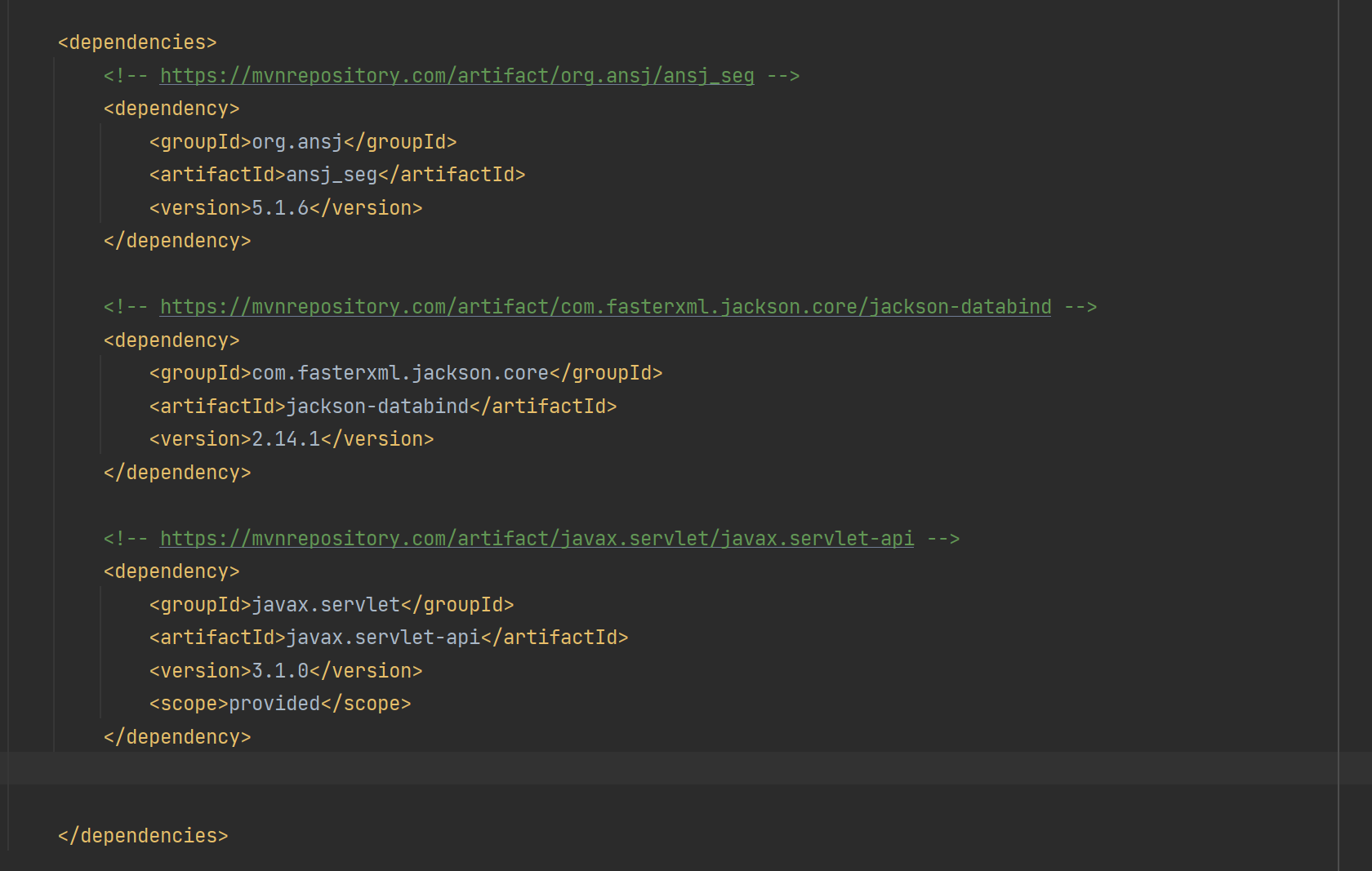
package api;
import com.fasterxml.jackson.databind.ObjectMapper;
import searcher.DocSearcher;
import searcher.Result;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.util.List;
/**
* Created by Lin
* Description:
* User: Administrator
* Date: 2022-12-23
* Time: 15:15
*/
@WebServlet("/search")
public class DocSearcherServlet extends HttpServlet {
//此处的DocSearcher 对象应该是全局唯一的,所以给static修饰
private static DocSearcher docSearcher = new DocSearcher();
private ObjectMapper objectMapper = new ObjectMapper();
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//1.先解析请求,拿到用户提交的查询词
String query = req.getParameter("query");
if(query == null || query.equals("")){
String msg = "你的参数非法!没有获取到query的值";
resp.sendError(404,msg);
return;
}
//2. 打印记录一下query的值
System.out.println("query="+query);
//3.调用搜索模块,来进行搜索
List<Result> results = docSearcher.search(query);
//4.把当前的搜索结果进行打包
resp.setContentType("application/json;charset=utf-8");
objectMapper.writeValue(resp.getWriter(),results);
}
}
디렉토리 구조도 약간 변경되었습니다.
7.2 웹 모듈 인증 백엔드 인터페이스 구현
여기 우리는 커뮤니티 버전이고 smartTomcat 구성을 사용하여 실행합니다
.이 URL을 입력하십시오:

우리 서버는 현재 예비 단계에서 데이터를 반환할 수 있습니다 .

7.3 웹 모듈 구현 - 페이지 구조 구현
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Java文档搜索</title>
</head>
<body>
<!-- 1.搜索框 和搜索按钮 -->
<!-- 2.显示搜索结果 -->
<!-- 通过.container来表示整个页面的元素的容器 -->
<div class="container">
<!-- 搜索框加搜索按钮 -->
<div class="header">
<input type="text">
<button id="search-btn">搜索</button>
</div>
<!-- 显示搜索结果 -->
<div class="result">
<!-- 包含了很多记录 -->
<!-- 通过访问服务器的方式获取搜索结果 -->
<div class="item">
<a href="#">我是标题</a>
<div class="class">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>
<div class="url">http://www.baidu.com</div>
</div>
<div class="item">
<a href="#">我是标题</a>
<div class="class">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>
<div class="url">http://www.baidu.com</div>
</div>
<div class="item">
<a href="#">我是标题</a>
<div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>
<div class="url">http://www.baidu.com</div>
</div>
<div class="item">
<a href="#">我是标题</a>
<div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>
<div class="url">http://www.baidu.com</div>
</div>
<div class="item">
<a href="#">我是标题</a>
<div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>
<div class="url">http://www.baidu.com</div>
</div>
</div>
</div>
</body>
</html>
가장 기본적인 페이지는 다음과 같습니다.

7.4 웹 모듈 구현 - 페이지 스타일(CSS) 구현
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Java文档搜索</title>
</head>
<body>
<!-- 1.搜索框 和搜索按钮 -->
<!-- 2.显示搜索结果 -->
<!-- 通过.container来表示整个页面的元素的容器 -->
<div class="container">
<!-- 搜索框加搜索按钮 -->
<div class="header">
<input type="text">
<button id="search-btn">搜索</button>
</div>
<!-- 显示搜索结果 -->
<div class="result">
<!-- 包含了很多记录 -->
<!-- 通过访问服务器的方式获取搜索结果 -->
<div class="item">
<a href="#">我是标题</a>
<div class="class">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>
<div class="url">http://www.baidu.com</div>
</div>
<div class="item">
<a href="#">我是标题</a>
<div class="class">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>
<div class="url">http://www.baidu.com</div>
</div>
<div class="item">
<a href="#">我是标题</a>
<div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>
<div class="url">http://www.baidu.com</div>
</div>
<div class="item">
<a href="#">我是标题</a>
<div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>
<div class="url">http://www.baidu.com</div>
</div>
<div class="item">
<a href="#">我是标题</a>
<div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>
<div class="url">http://www.baidu.com</div>
</div>
</div>
</div>
<style >
/* 这部分代码来写样式 */
/* 先去掉浏览器默认的样式 */
*{
margin: 0;
padding: 0;
box-sizing: border-box;
}
/* 给整体的页面指定一个高度(和浏览器窗口一样高) */
html,body{
height: 100%;
/* 设置背景图 */
background-image: url(image/bjt.jpg);
/* 设置背景图不平铺 */
background-repeat: no-repeat;
/* 设置背景图的大小 */
background-size: cover;
/* 设置背景图的位置 */
background-position: center center;
}
/* 针对.container 也设置样式,实现版心效果 */
.container{
width: 1135px;
height: 100%;
/* 设置水平居中 */
margin: 0 auto;
/* 设置背景色,让版心和背景图能够区分开 */
background-color:rgba(255, 255, 255, 0.8);
/* 设置圆角矩形 */
border-radius: 10px;
/* 设置内边距 避免文章内容紧填边界 */
padding: 15px;
/* 超出元素的部分,自动生成一个滚动条 */
overflow: auto;
}
.header{
width: 100%;
height: 50px;
display: flex;
justify-content: space-between;
align-items: center;
}
.header> input{
height: 30px;
width: 1000px;
font-size: 22px;
line-height: 50px;
padding-left: 10px;
border-radius: 10px;
}
.header>button{
height: 30px;
width: 100px;
background-color: antiquewhite;
color: black;
border-radius: 10px;
}
.result .count{
color: darkblue;
margin-top: 10px;
}
.header>button:active{
background: gray;
}
.item{
width:100%;
margin-top: 20px;
}
.item a{
display: block;
height: 40px;
font-size: 22px;
line-height: 40px;
font-weight: 700;
color: rgb(42, 107, 205);
}
.item .desc{
font-size: 18px;
}
.item .url{
font-size: 18px;
color: rgb(0, 130, 0);
}
.item>.desc>i {
color: red;
/* 去掉斜体 */
font-style: normal;
}
</style>
</body>
</html>

7.5 웹 모듈 구현 - ajax를 통해 검색 결과 얻기
위에서 본 데이터는 실제로 죽었고 실제 데이터는 여전히 서버를 통해 반환되어야 합니다. 우리는 ajax를 사용하여 발생합니다.
사용자가 검색 버튼을 클릭하면 브라우저는 검색 상자의 내용을 가져와서 ajax를 기반으로 요청을 구성한 다음 검색 서버로 보냅니다.브라우저가 검색 결과를 얻으면 다음에 따라 페이지를 생성합니다. 결과의 json 데이터 우리는 jquery를 사용합니다.
<script src="http://libs.baidu.com/jquery/2.0.0/jquery.min.js"></script>
이것을 복사하면 작동합니다.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Java文档搜索</title>
</head>
<body>
<!-- 1.搜索框 和搜索按钮 -->
<!-- 2.显示搜索结果 -->
<!-- 通过.container来表示整个页面的元素的容器 -->
<div class="container">
<!-- 搜索框加搜索按钮 -->
<div class="header">
<input type="text">
<button id="search-btn">搜索</button>
</div>
<!-- 显示搜索结果 -->
<div class="result">
<!-- 包含了很多记录 -->
<!-- 通过访问服务器的方式获取搜索结果 -->
<!-- <div class="item">-->
<!-- <a href="#">我是标题</a>-->
<!-- <div class="class">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>-->
<!-- <div class="url">http://www.baidu.com</div>-->
<!-- </div>-->
<!-- <div class="item">-->
<!-- <a href="#">我是标题</a>-->
<!-- <div class="class">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>-->
<!-- <div class="url">http://www.baidu.com</div>-->
<!-- </div>-->
<!-- -->
<!-- <div class="item">-->
<!-- <a href="#">我是标题</a>-->
<!-- <div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>-->
<!-- <div class="url">http://www.baidu.com</div>-->
<!-- </div>-->
<!-- <div class="item">-->
<!-- <a href="#">我是标题</a>-->
<!-- <div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>-->
<!-- <div class="url">http://www.baidu.com</div>-->
<!-- </div>-->
<!-- <div class="item">-->
<!-- <a href="#">我是标题</a>-->
<!-- <div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>-->
<!-- <div class="url">http://www.baidu.com</div>-->
<!-- </div>-->
</div>
</div>
<style >
/* 这部分代码来写样式 */
/* 先去掉浏览器默认的样式 */
*{
margin: 0;
padding: 0;
box-sizing: border-box;
}
/* 给整体的页面指定一个高度(和浏览器窗口一样高) */
html,body{
height: 100%;
/* 设置背景图 */
background-image: url(image/bjt.jpg);
/* 设置背景图不平铺 */
background-repeat: no-repeat;
/* 设置背景图的大小 */
background-size: cover;
/* 设置背景图的位置 */
background-position: center center;
}
/* 针对.container 也设置样式,实现版心效果 */
.container{
width: 1135px;
height: 100%;
/* 设置水平居中 */
margin: 0 auto;
/* 设置背景色,让版心和背景图能够区分开 */
background-color:rgba(255, 255, 255, 0.8);
/* 设置圆角矩形 */
border-radius: 10px;
/* 设置内边距 避免文章内容紧填边界 */
padding: 15px;
/* 超出元素的部分,自动生成一个滚动条 */
overflow: auto;
}
.header{
width: 100%;
height: 50px;
display: flex;
justify-content: space-between;
align-items: center;
}
.header> input{
height: 30px;
width: 1000px;
font-size: 22px;
line-height: 50px;
padding-left: 10px;
border-radius: 10px;
}
.header>button{
height: 30px;
width: 100px;
background-color: antiquewhite;
color: black;
border-radius: 10px;
}
.result .count{
color: darkblue;
margin-top: 10px;
}
.header>button:active{
background: gray;
}
.item{
width:100%;
margin-top: 20px;
}
.item a{
display: block;
height: 40px;
font-size: 22px;
line-height: 40px;
font-weight: 700;
color: rgb(42, 107, 205);
}
.item .desc{
font-size: 18px;
}
.item .url{
font-size: 18px;
color: rgb(0, 130, 0);
}
.item>.desc>i {
color: red;
/* 去掉斜体 */
font-style: normal;
}
</style>
<script src="http://libs.baidu.com/jquery/2.0.0/jquery.min.js"></script>
<script>
//放置用户自己写的js代码
let button = document.querySelector("#search-btn");
button.onclick =function(){
// 先获取输入框的内容
let input =document.querySelector(".header input");
let query = input.value;
//然后构造ajax的请求
$.ajax({
type:"GET",
url:"search?query="+query,
success:function(data,status){
// success会在请求成功后调用
//data参数就是表示拿到的结果数据
//status参数就表示的HTTP状态码
//根据收到的数据结果,构造出页面内容
//console.log(data);
buildResult(data);
}
})
}
function buildResult(data) {
//通过这个函数,来把响应数据给构造成页面内容
//遍历data中的元素,针对每个元素都创建一个div.item,然后把标题,url,描述构造好
//再把这个div.item 给加入到div.result中
//这些操作都是基于DOM API来展开
//获取到.result这个标签
let result = document.querySelector('.result');
//清空上次结果
result.innerHTML=' ';
//先构造一个div用来显示结果的个数
let countDiv = document.createElement("div");
countDiv.innerHTML = '当前找到约' + data.length + '个结果!';
countDiv.className = 'count';
result.appendChild(countDiv);
//此处得到的item分别代表data的每个元素
for(let item of data){
let itemDiv = document.createElement('div');
itemDiv.className = 'item';
//构造一个标题
let title = document.createElement('a');
title.href=item.url;
title.innerHTML = item.title;
title.target='_blank';
itemDiv.appendChild(title);
//构造一个描述
let desc = document.createElement('div');
desc.className='desc';
desc.innerHTML=item.desc;
itemDiv.appendChild(desc);
//构造一个url
let url = document.createElement('div');
url.className = 'url';
url.innerHTML = item.url;
itemDiv.appendChild(url);
// 把itemDiv加入到result里面
result.appendChild(itemDiv);
}
}
</script>
</body>
</html>
7.6 웹 모듈 구현 - 빨간색 표시 논리 구현
우리는 다음과 유사한 효과를 얻고자 합니다.

아이디어:
- 백엔드 코드 수정, 검색 결과 생성 시(설명 부분 생성), i 태그 추가 등 검색어 부분에 태그 추가
- 그런 다음 프런트 엔드 는 레이블의 스타일을 설정합니다.
private String GenDesc(String content, List<Term> terms) {
//先遍历结果,看看哪个结果是在content中存在
int firstPos = -1;
for (Term term : terms) {
String word = term.getName();
//因为分词结果是会把正文转成小写,所以我们要把查询词也转成小写
//为了搜索结果独立成词 所以加" "
firstPos =content.toLowerCase().indexOf(" " + word + " ");
if (firstPos >= 0){
break;
}
if(firstPos ==-1){
//所有的分词结果都不在正文中存在 极端情况
return content.substring(0,160)+"...";
}
}
//从firstPos 作为基准,往前找60个字符,作为描述的起始位置
String desc ="";
//如果当前位置少于60个字符开始位置就是第一个 否则开始位置 在查询词前60个
int descBeg = firstPos < 60 ? 0 : firstPos -60;
if (descBeg+160 > content.length()){
//判断是否超过正文长度
//从开始位置到最后
desc = content.substring(descBeg);
}else {
desc =content.substring(descBeg,descBeg + 160)+"...";
}
//在此处加上一个替换操作,把描述中的分词结果相同的部分,给加上一层<i>标签,就可以通过replace的方式实现
for (Term term : terms){
String word = term.getName();
//只有是全部是一个查询词 才加上 i 标签 正则规则(?i)大小写全部匹配
desc = desc.replaceAll("(?i)"+word+" ","<i> " + word + " </i>");
}
return desc;
}
최종 코드 부분:
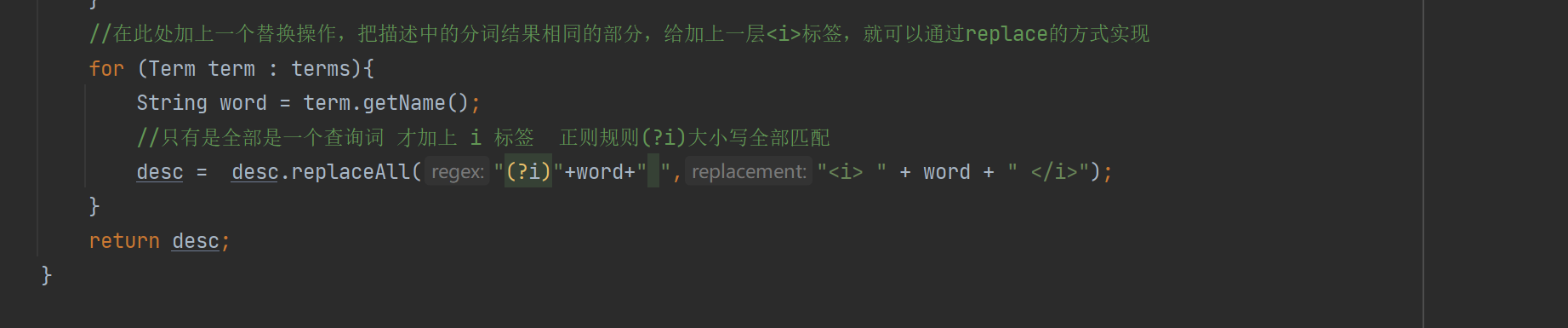
최종 효과:

7.7 웹 모듈 구현 - 더 복잡한 쿼리 용어 테스트
검색창에서 단어를 분리하려 했더니 서버에서 500오류가 뜨네요 왜
이러죠 상세정보 :

알고보니 우리의 극단 루트였습니다 총 길이가 160이 아니라 160자를 가로채서 오류 보고
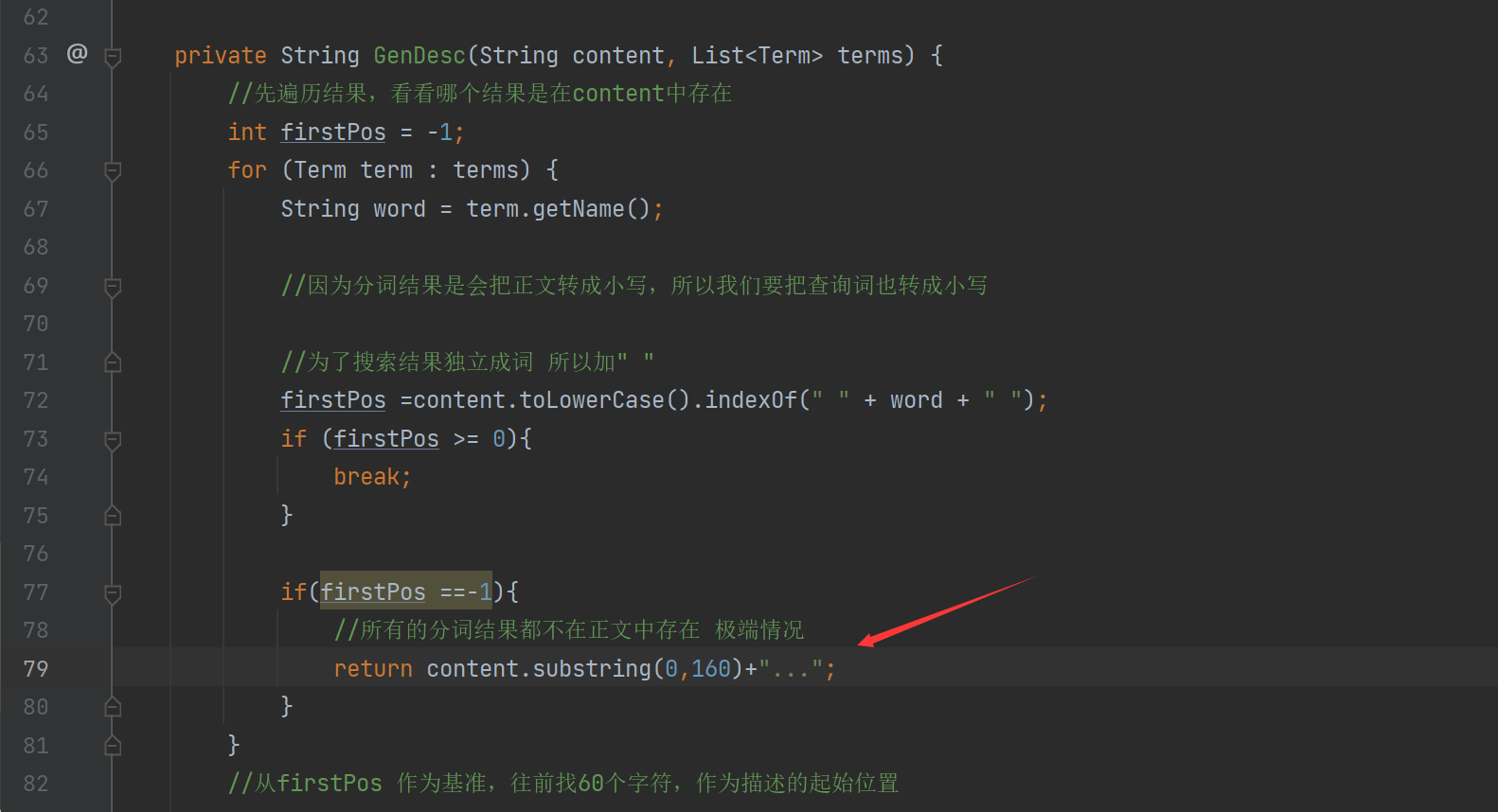
코드를 변경해 보겠습니다.
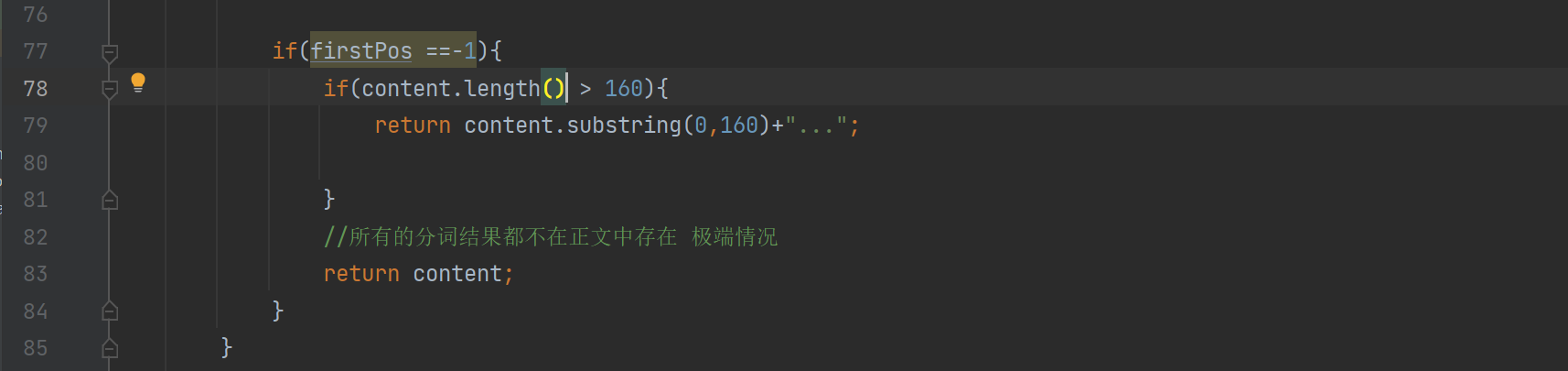
준비되었습니다.

그러나 우리는 또 다른 문제를 발견했습니다. 검색어와 관련이 없는 용어가 많이 있습니다.

왜 이런거야?
방금 언급한 쿼리 용어는 Array List 뿐만 아니라 Array, space 및 List 이므로 코드는 공백을 사용하여 반전된 인덱스를 쿼리합니다! , 그래서 우리는 공백을 제거할 것입니다. 여기서 우리는 특별한 것을 소개합니다.
단어 일시 중지 : 빈도가 높지만 의미 없는 콘텐츠가 있는 경우가 있습니다.
예: a is have One is yes, 우리는 이 클래스가 코드 쿼리를 트리거하지 않기를 원합니다.
7.8 웹 모듈 구현 - 불용어 처리
기성 정지 어휘를 찾기 위해 인터넷에 갈 수 있습니다. 여기서 첫 번째 일시정지 단어 목록은 공백입니다.
다음으로, 검색 프로그램이 이 불용어 목록을 메모리에 로드하도록 하고, hashSet을 사용하여 이러한 단어를 저장한 다음, 불용어 목록에서 단어 세분화 결과를 필터링합니다. 결과가 단어 목록에 있으면 그냥 죽입니다. .
여기에 우리는 그것을 txt 텍스트에 넣습니다.
package searcher;
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.ToAnalysis;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.*;
/**
* Created by Lin
* Description:
* User: Administrator
* Date: 2022-12-21
* Time: 13:22
*/
public class DocSearcher {
private static final String STOP_WORD_PATH ="D:\\gitee\\doc_searcher_index\\stop_word.txt";
//使用这个HashSet 来保存停用词
private HashSet<String> stopWords = new HashSet<>();
private Index index = new Index();
public DocSearcher() {
//一开始要加载
index.load();
loadStopWords();
}
//完成整个搜索过程的方法
//参数(输入部分)就是用户给出的查询词
//返回值(输出部分)就是搜索结果的集合
public List<Result> search(String query) {
//1.[分词]针对query这个查询词进行分词
List<Term> oldTerms = ToAnalysis.parse(query).getTerms();
List<Term> terms = new ArrayList<>();
//针对分词结果,使用暂停词表
for (Term term : oldTerms){
if (stopWords.contains(term.getName())){
//是暂停词就不拷贝
continue;
}
terms.add(term);
}
//2.[触发]针对分词结果来查倒排
List<Weight> allTermResult = new ArrayList<>();
for (Term term : terms) {
String word = term.getName();
List<Weight> invertedList = index.getInverted(word);
if (invertedList == null) {
//说明词不存在
continue;
}
allTermResult.addAll(invertedList);
}
// 3.[排序]针对触发的结果按照权重降序排序
allTermResult.sort(new Comparator<Weight>() {
@Override
public int compare(Weight o1, Weight o2) {
//降序排序 return o2.getWeight-01.getWeight 升序反之
return o2.getWeight() - o1.getWeight();
}
});
//4.[包装结果]针对排序的结果,去查正排,构造出要返回的数据
List<Result> results = new ArrayList<>();
for (Weight weight : allTermResult) {
DocInfo docInfo = index.getDocInfo(weight.getDocId());
Result result = new Result();
result.setTitle(docInfo.getTitle());
result.setUrl(docInfo.getUrl());
result.setDesc(GenDesc(docInfo.getContent(),terms));
results.add(result);
}
return results;
}
private String GenDesc(String content, List<Term> terms) {
//先遍历结果,看看哪个结果是在content中存在
int firstPos = -1;
for (Term term : terms) {
String word = term.getName();
//因为分词结果是会把正文转成小写,所以我们要把查询词也转成小写
//为了搜索结果独立成词 所以加" "
firstPos =content.toLowerCase().indexOf(" " + word + " ");
if (firstPos >= 0){
break;
}
if(firstPos ==-1){
if(content.length() > 160){
return content.substring(0,160)+"...";
}
//所有的分词结果都不在正文中存在 极端情况
return content;
}
}
//从firstPos 作为基准,往前找60个字符,作为描述的起始位置
String desc ="";
//如果当前位置少于60个字符开始位置就是第一个 否则开始位置 在查询词前60个
int descBeg = firstPos < 60 ? 0 : firstPos -60;
if (descBeg+160 > content.length()){
//判断是否超过正文长度
//从开始位置到最后
desc = content.substring(descBeg);
}else {
desc =content.substring(descBeg,descBeg + 160)+"...";
}
//在此处加上一个替换操作,把描述中的分词结果相同的部分,给加上一层<i>标签,就可以通过replace的方式实现
for (Term term : terms){
String word = term.getName();
//只有是全部是一个查询词 才加上 i 标签 正则规则(?i)大小写全部匹配
desc = desc.replaceAll("(?i)"+word+" ","<i> " + word + " </i>");
}
return desc;
}
public void loadStopWords (){
System.out.println("加载暂停词表");
try(BufferedReader bufferedReader = new BufferedReader(new FileReader(STOP_WORD_PATH))){
while (true){
String line = bufferedReader.readLine();
if (line == null){
//读取文件完毕
break;
}
stopWords.add(line);
}
}catch (IOException e){
e.printStackTrace();
}
}
public static void main(String[] args) {
DocSearcher docSearcher = new DocSearcher();
Scanner scanner = new Scanner(System.in);
while (true) {
System.out.print("->");
String query = scanner.next();
List<Result> results = docSearcher.search(query);
for (Result result : results) {
System.out.println("======================================");
System.out.println(result);
}
}
}
}
일시 중지 단어를 HashSet에 로드:
검색 방법에서도 변경: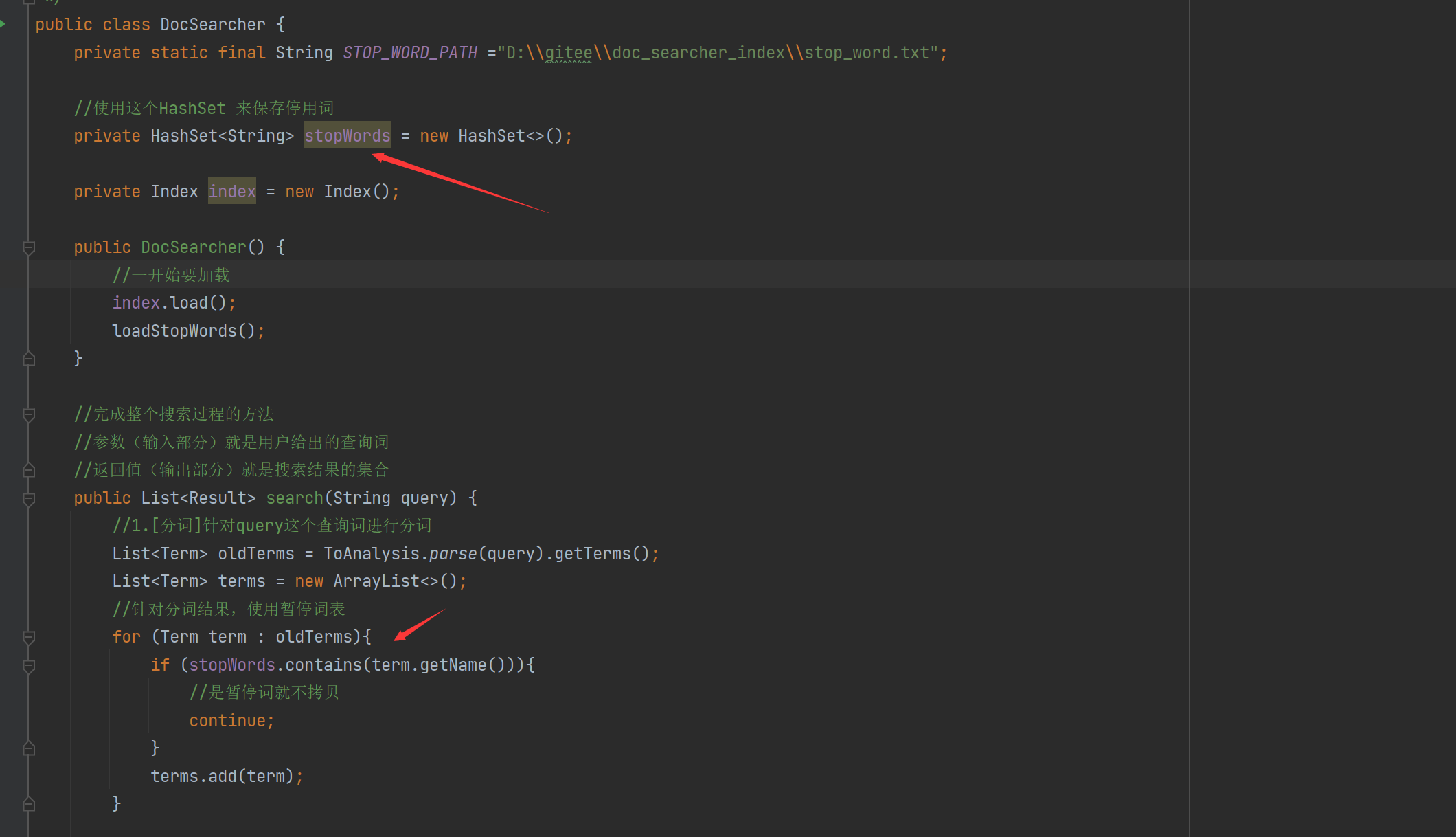
일시정지 단어에 세트에 추가하지 않음이 포함된 경우
7.9 웹 모듈 구현 - 생성된 설명의 버그 처리
여기에서 설명 생성은 처음부터 우리의 규칙에 따르지 않고 생성됩니다.

우리는 그들의 설명자를 이런 식으로 보지 않았지만 나타납니다.문제가 무엇입니까?
그것도 포함되나요? 페이지로 이동해 보겠습니다.
실제로 여기에 일부가 있음을 알 수 있지만 생성된 설명은 문제가 있습니다. 이전에 한 단어를 찾았습니다.

텍스트에 List라는 단어가 있습니다. List를 ArrayList의 일부와 일치시키지 않아야 합니다. 독립적인 단어(a List b)를 일치시킬 수 있지만 여전히 (a List.)와 같은 몇 가지 문제가 있습니다. 문장 부호가 뒤따릅니다. 그것은 정확하지 않을 것입니다,
이 문제를 해결하기 위한 솔루션은 여전히 정규 표현식입니다.
\b: 기호 구두점을 포함하여 단어 경계와 일치
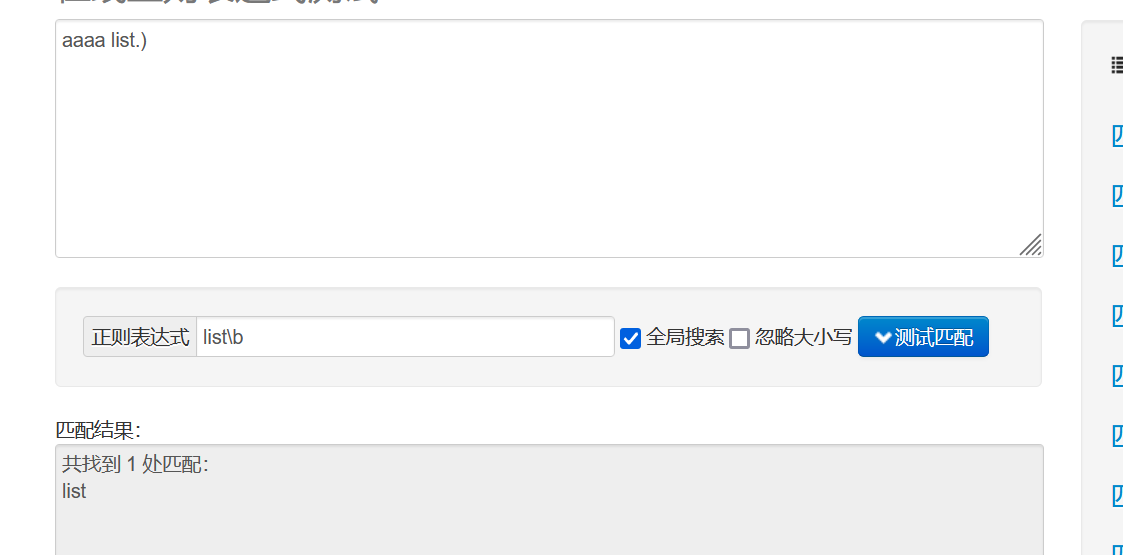
하지만 이 규칙성을 어떻게 달성할 수 있을까요?
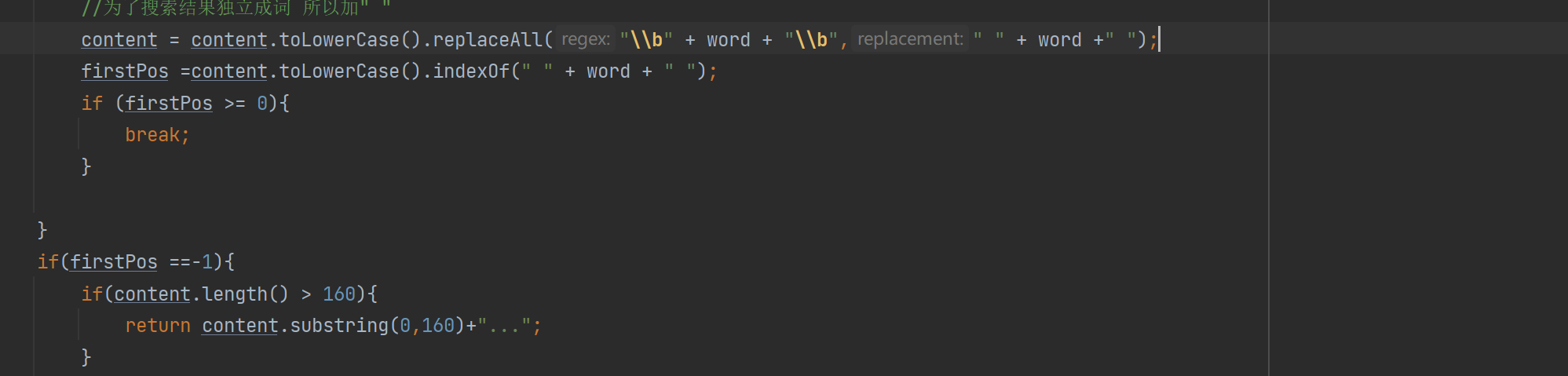
원칙은 경계가 있는 단어를 먼저 변환하여 공백을 추가한 다음 공백이 있는 단어에 대해 연산하는 것입니다.

여기에 설명된 대로 성공적입니까?
7.10 웹 모듈 구현 - 검색 결과 수
우리는 다음과 같은 효과를 얻고 싶습니다:

우리는 2가지 방법이 있습니다:
- 서버측에서 직접 수치를 계산하여 브라우저에 반환
- 브라우저 측에서는 수신된 결과 배열의 길이에 따라 숫자가 자동으로 표시됩니다.
두 번째 옵션을 선택합니다.
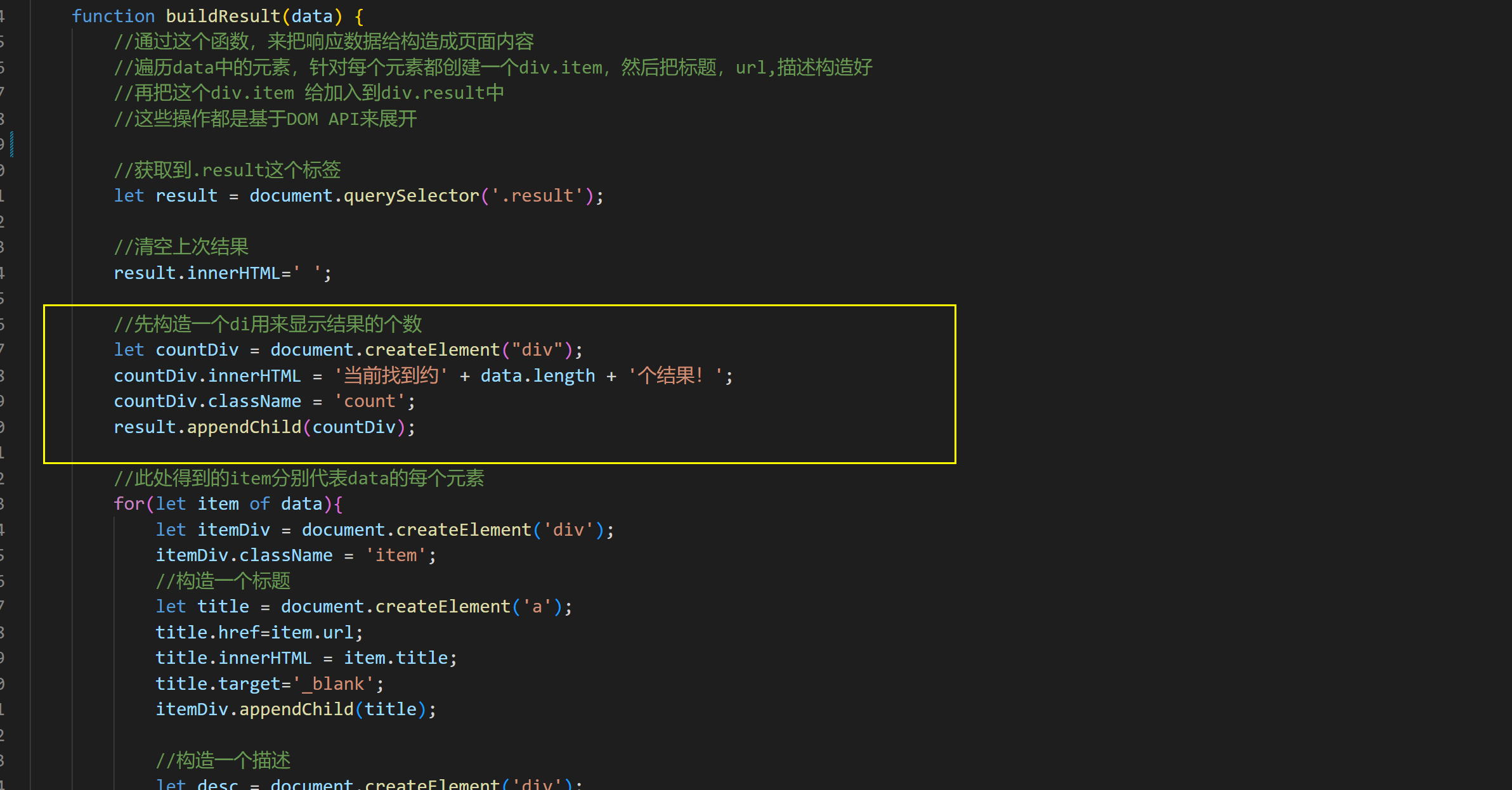
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Java文档搜索</title>
</head>
<body>
<!-- 1.搜索框 和搜索按钮 -->
<!-- 2.显示搜索结果 -->
<!-- 通过.container来表示整个页面的元素的容器 -->
<div class="container">
<!-- 搜索框加搜索按钮 -->
<div class="header">
<input type="text">
<button id="search-btn">搜索</button>
</div>
<!-- 显示搜索结果 -->
<div class="result">
<!-- 包含了很多记录 -->
<!-- 通过访问服务器的方式获取搜索结果 -->
<!-- <div class="item">-->
<!-- <a href="#">我是标题</a>-->
<!-- <div class="class">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>-->
<!-- <div class="url">http://www.baidu.com</div>-->
<!-- </div>-->
<!-- <div class="item">-->
<!-- <a href="#">我是标题</a>-->
<!-- <div class="class">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>-->
<!-- <div class="url">http://www.baidu.com</div>-->
<!-- </div>-->
<!-- -->
<!-- <div class="item">-->
<!-- <a href="#">我是标题</a>-->
<!-- <div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>-->
<!-- <div class="url">http://www.baidu.com</div>-->
<!-- </div>-->
<!-- <div class="item">-->
<!-- <a href="#">我是标题</a>-->
<!-- <div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>-->
<!-- <div class="url">http://www.baidu.com</div>-->
<!-- </div>-->
<!-- <div class="item">-->
<!-- <a href="#">我是标题</a>-->
<!-- <div class="desc">我是一段描述: Lorem ipsum dolor sit, amet consectetur adipisicing elit. Cumque sunt maxime eveniet ducimus error nihil quidem assumenda eius soluta esse, officiis, dolores tenetur sit temporibus. Ea aliquam culpa beatae vitae.</div>-->
<!-- <div class="url">http://www.baidu.com</div>-->
<!-- </div>-->
</div>
</div>
<style >
/* 这部分代码来写样式 */
/* 先去掉浏览器默认的样式 */
*{
margin: 0;
padding: 0;
box-sizing: border-box;
}
/* 给整体的页面指定一个高度(和浏览器窗口一样高) */
html,body{
height: 100%;
/* 设置背景图 */
background-image: url(image/bjt.jpg);
/* 设置背景图不平铺 */
background-repeat: no-repeat;
/* 设置背景图的大小 */
background-size: cover;
/* 设置背景图的位置 */
background-position: center center;
}
/* 针对.container 也设置样式,实现版心效果 */
.container{
width: 1135px;
height: 100%;
/* 设置水平居中 */
margin: 0 auto;
/* 设置背景色,让版心和背景图能够区分开 */
background-color:rgba(255, 255, 255, 0.8);
/* 设置圆角矩形 */
border-radius: 10px;
/* 设置内边距 避免文章内容紧填边界 */
padding: 15px;
/* 超出元素的部分,自动生成一个滚动条 */
overflow: auto;
}
.header{
width: 100%;
height: 50px;
display: flex;
justify-content: space-between;
align-items: center;
}
.header> input{
height: 30px;
width: 1000px;
font-size: 22px;
line-height: 50px;
padding-left: 10px;
border-radius: 10px;
}
.header>button{
height: 30px;
width: 100px;
background-color: antiquewhite;
color: black;
border-radius: 10px;
}
.result .count{
color: darkblue;
margin-top: 10px;
}
.header>button:active{
background: gray;
}
.item{
width:100%;
margin-top: 20px;
}
.item a{
display: block;
height: 40px;
font-size: 22px;
line-height: 40px;
font-weight: 700;
color: rgb(42, 107, 205);
}
.item .desc{
font-size: 18px;
}
.item .url{
font-size: 18px;
color: rgb(0, 130, 0);
}
.item>.desc>i {
color: red;
/* 去掉斜体 */
font-style: normal;
}
</style>
<script src="http://libs.baidu.com/jquery/2.0.0/jquery.min.js"></script>
<script>
//放置用户自己写的js代码
let button = document.querySelector("#search-btn");
button.onclick =function(){
// 先获取输入框的内容
let input =document.querySelector(".header input");
let query = input.value;
//然后构造ajax的请求
$.ajax({
type:"GET",
url:"search?query="+query,
success:function(data,status){
// success会在请求成功后调用
//data参数就是表示拿到的结果数据
//status参数就表示的HTTP状态码
//根据收到的数据结果,构造出页面内容
//console.log(data);
buildResult(data);
}
})
}
function buildResult(data) {
//通过这个函数,来把响应数据给构造成页面内容
//遍历data中的元素,针对每个元素都创建一个div.item,然后把标题,url,描述构造好
//再把这个div.item 给加入到div.result中
//这些操作都是基于DOM API来展开
//获取到.result这个标签
let result = document.querySelector('.result');
//清空上次结果
result.innerHTML=' ';
//先构造一个di用来显示结果的个数
let countDiv = document.createElement("div");
countDiv.innerHTML = '当前找到约' + data.length + '个结果!';
countDiv.className = 'count';
result.appendChild(countDiv);
//此处得到的item分别代表data的每个元素
for(let item of data){
let itemDiv = document.createElement('div');
itemDiv.className = 'item';
//构造一个标题
let title = document.createElement('a');
title.href=item.url;
title.innerHTML = item.title;
title.target='_blank';
itemDiv.appendChild(title);
//构造一个描述
let desc = document.createElement('div');
desc.className='desc';
desc.innerHTML=item.desc;
itemDiv.appendChild(desc);
//构造一个url
let url = document.createElement('div');
url.className = 'url';
url.innerHTML = item.url;
itemDiv.appendChild(url);
// 把itemDiv加入到result里面
result.appendChild(itemDiv);
}
}
</script>
</body>
</html>
7.11 웹 모듈 구현 - 중복 문서에 대한 질문
Array: 1598
List: 1381
ArrayList: 2979
마지막으로 Array List의 개수는 앞의 두 결과를 더한 결과임을 알 수 있으며 중복된 문서가 나타나는 또 다른 문제가 있습니다. 예를
들어 이 Collections는 두 번 나타납니다 .
첫 번째 발생:

두 번째 발생 위치:
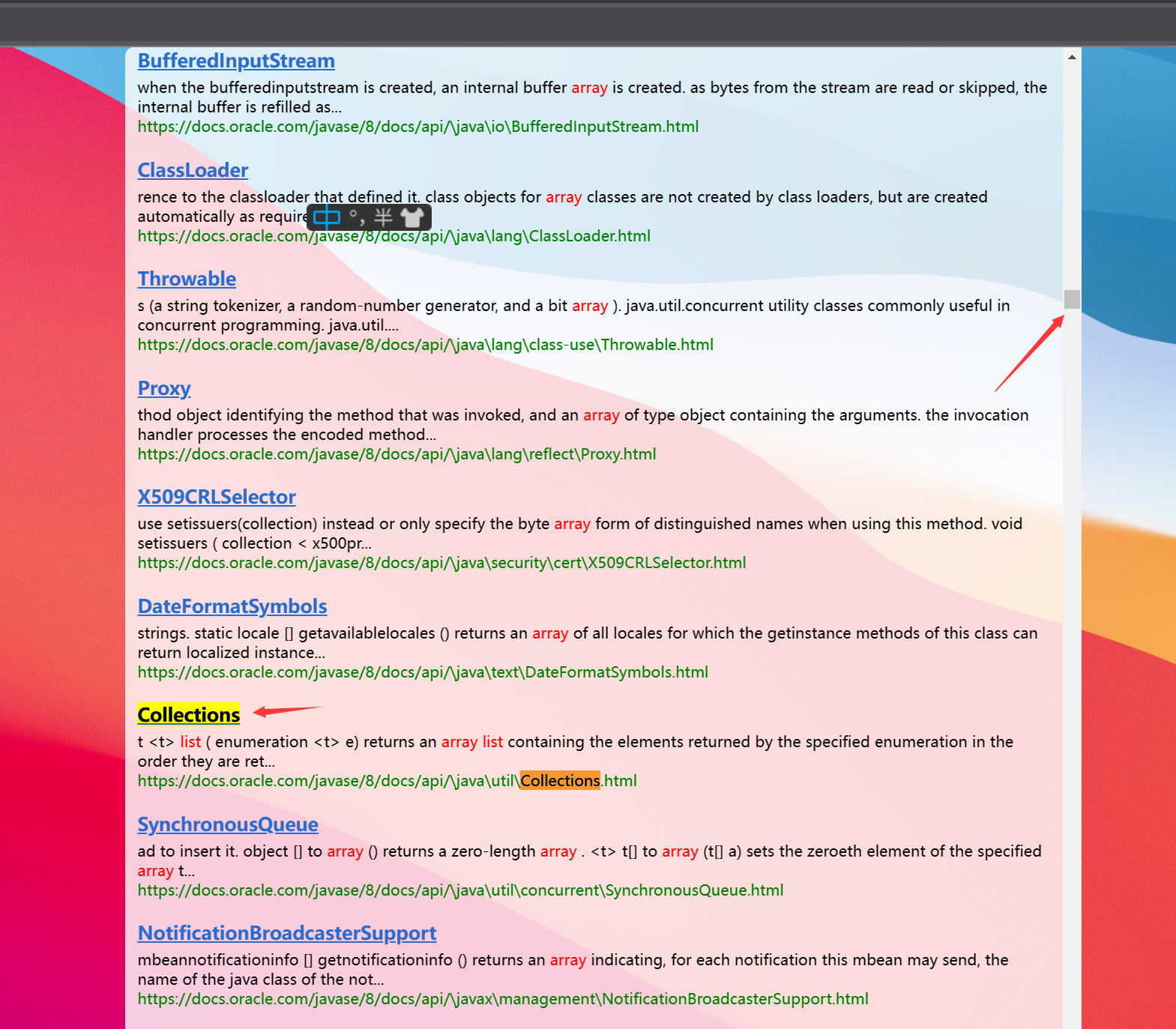
우리는 그것들이 두 번 나타나게 해서는 안 되며, 또한 이것이 두 번 나타나는 가중치를 더 높여야 합니다.
문제가 무엇입니까?
단어 세분화 결과에 대해 가중치와 트리거를 순차적으로 계산합니다.
배열은 일련의 docId
목록을 트리거합니다. 일련의 docId를 트리거합니다.
이제 컬렉션은 배열과 목록 모두에 의해 한 번 트리거됩니다.
우리의 솔루션:
가중치를 추가하는 방법을 찾습니다. 예를 들어 첫 번째 가중치 그룹은 10이고 두 번째 트리거 그룹은 5이므로 가중치는 10+5입니다.
이 효과를 얻으려면 트리거 결과를 결합해야 합니다.
트리거 결과의 두 세트가 동일한 docId를 가질 수 있으므로 병합할 결과가 여전히 많으므로 동시에 가중치를 중복 제거하고 병합해야 합니다.
그렇다면 중복 제거는 어떻게 해야 할까요?
중복 제거의 핵심 아이디어:
우리가 배운 데이터 구조에는 연결 목록이 있습니다. 연결 목록의 고전적인 문제는 두 개의 순서가 지정된 연결 목록을 병합하는 것 입니다. 유사한 방식으로 두 배열을 병합할 수 있습니다.
두 개의 순서가 있는 연결 목록을 병합합니다. 두 개의 연결 목록은 각각 두 개의 포인터를 사용하여 각각의 헤드를 가리킨 다음 가리키는 노드를 비교하여 값이 더 작은지 확인하고 새 노드에 삽입합니다.
우리의 일반적인 생각은 다음과 같습니다.
먼저 단어 세그먼테이션 결과(docId 오름차순)를 순서대로 정렬한 후 병합을 시작합니다. 병합 시 동일한 docId 값에 따라 추가할 수 있습니다. 삽입 시 id가 It인지 확인하십시오. 지난번에 삽입한 id와 같지 않고 같으면 반복된다는 뜻이고, 반복되면 가중치가 더해집니다.
여기에 또 다른 문제가 있는데, 사용자 쿼리의 단어 분할 결과가 반드시 두 부분으로 구성되는 것은 아니며 여러 단어 분할 결과일 수 있으며 N개의 배열로 결합됩니다.
7.12 웹 모듈 구현 - 다중 병합을 위한 아이디어
양방향 배열 병합의 경우: 핵심은 가리키는 두 요소 간의 크기 관계를 비교하고 가장 작은 것을 찾아 결과에 삽입하는 것입니다.
다방향 배열 병합의 경우: 핵심은 여러 요소의 크기 관계를 비교하고 가리키고 작은 것을 찾아 결과에 삽입하는 것입니다.
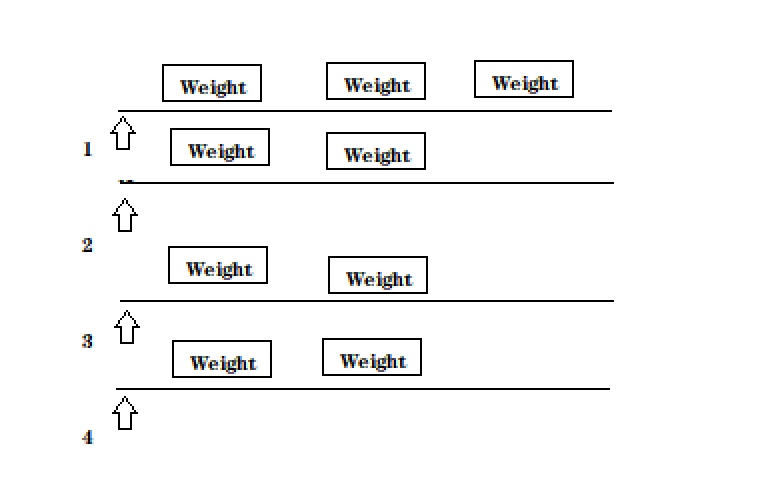
2차원 배열:

위의 그림에서 가장 작은 해당 값을 가진 사람을 찾아 가장 작은 값을 빼서 결과 배열에 삽입하고 동시에 첨자 ++를 수행해야 합니다. 여기서 가장 작은 값을 찾기 위해 힙 또는 우선순위 큐를 사용합니다.
위의 그림은 각 docid와 Weight 객체를 나타낸 것으로, 첫 번째 는 1이고 각 행의 Weight는 열로 간주 할 수 있습니다. 정렬.
코드를 살펴보자
7.13 웹 모듈 구현 - 다중 병합 구현
문서 검색기
package searcher;
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.ToAnalysis;
import org.omg.CORBA.INTERNAL;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.*;
/**
* Created by Lin
* Description:
* User: Administrator
* Date: 2022-12-21
* Time: 13:22
*/
public class DocSearcher {
private static final String STOP_WORD_PATH ="D:\\gitee\\doc_searcher_index\\stop_word.txt";
//使用这个HashSet 来保存停用词
private HashSet<String> stopWords = new HashSet<>();
private Index index = new Index();
public DocSearcher() {
//一开始要加载
index.load();
loadStopWords();
}
//完成整个搜索过程的方法
//参数(输入部分)就是用户给出的查询词
//返回值(输出部分)就是搜索结果的集合
public List<Result> search(String query) {
//1.[分词]针对query这个查询词进行分词
List<Term> oldTerms = ToAnalysis.parse(query).getTerms();
List<Term> terms = new ArrayList<>();
//针对分词结果,使用暂停词表
for (Term term : oldTerms){
if (stopWords.contains(term.getName())){
//是暂停词就不拷贝
continue;
}
terms.add(term);
}
//2.[触发]针对分词结果来查倒排
//二维数组
List<List<Weight>> termResult = new ArrayList<>();
for (Term term : terms) {
String word = term.getName();
List<Weight> invertedList = index.getInverted(word);
if (invertedList == null) {
//说明词不存在
continue;
}
termResult.add(invertedList);
}
//3.[合并]针对多个分词结果触发出的相同文档进行权重合并 去重
List<Weight> allTermResult = mergeResult(termResult);
// 4.[排序]针对触发的结果按照权重降序排序
allTermResult.sort(new Comparator<Weight>() {
@Override
public int compare(Weight o1, Weight o2) {
//降序排序 return o2.getWeight-01.getWeight 升序反之
return o2.getWeight() - o1.getWeight();
}
});
//5.[包装结果]针对排序的结果,去查正排,构造出要返回的数据
List<Result> results = new ArrayList<>();
for (Weight weight : allTermResult) {
DocInfo docInfo = index.getDocInfo(weight.getDocId());
Result result = new Result();
result.setTitle(docInfo.getTitle());
result.setUrl(docInfo.getUrl());
result.setDesc(GenDesc(docInfo.getContent(),terms));
results.add(result);
}
return results;
}
//进行合并的时候把多个行合并成为一行,
//合并过程要操作二维数组的每个元素 所以我们把行和列创建好
static class Pos{
public int row;
public int col;
public Pos(int row, int col) {
this.row = row;
this.col = col;
}
}
private List<Weight> mergeResult(List<List<Weight>> source) {
//1.先针对每一行进行排序(按照id进行升序)不然没办法合并
for(List<Weight> curRow :source){
curRow.sort(new Comparator<Weight>() {
@Override
public int compare(Weight o1, Weight o2) {
return o1.getDocId() - o2.getDocId();
}
});
}
//2.借助优先队列,针对这些进行合并
// target 表示合并的结果
List<Weight> target = new ArrayList<>();
// 搞一个优先队列 要找到对应的Weight对象位置
// 优先队列存在的意义就是:为了能够找出每一行对应的最小的docid对象,把最小的对象插入到target里面,同时把对应的下标给往后移动
PriorityQueue<Pos> queue = new PriorityQueue<>(new Comparator<Pos>() {
@Override
public int compare(Pos o1, Pos o2) {
// 找到Weight对象 然后再根据Weight 的docId来排序
// 第一个对象
Weight w1 = source.get(o1.row).get(o1.col);
Weight w2 = source.get(o2.row).get(o2.col);
return w1.getDocId() - w2.getDocId();
}
});
// 初始化队列,把每一行的第一个元素放到队列中
for (int row = 0; row<source.size();row++){
queue.offer(new Pos(row,0)); //把每一行的第一个元素放到队列中
}
// 循环取队首元素 (当前若干行最小的元素)
while (!queue.isEmpty()){
Pos minPos = queue.poll();
//获取最小weight对象
Weight curWeight = source.get(minPos.row).get(minPos.col);
//判断当前取到的对象,是否和前一个插入到target中的结果是相同的 docId
// 如果是就合并
if (target.size() >0){
//取出上次插入的元素
Weight lastWeight = target.get(target.size()-1);
if (lastWeight.getDocId() == curWeight.getDocId()){
//遇到了相同的文档
lastWeight.setWeight(lastWeight.getWeight()+curWeight.getWeight());
}else{
//如果不相同的话
target.add(curWeight);
}
}else {
// 如果当前是空着的 直接插入即可
target.add(curWeight);
}
// 把当前的元素处理完了之后,要把对应这个元素的光标往后移动 取下一个元素
Pos newPos = new Pos(minPos.row, minPos.col+1);
if (newPos.col >= source.get(newPos.row).size()){
//如果移动光标之后,超过了这一行的列数,就说明到达了末尾 处理完毕
continue;
}
// 优先队列 自己放到合适的地方
queue.offer(newPos);
}
return target;
}
private String GenDesc(String content, List<Term> terms) {
//先遍历结果,看看哪个结果是在content中存在
int firstPos = -1;
for (Term term : terms) {
String word = term.getName();
//因为分词结果是会把正文转成小写,所以我们要把查询词也转成小写
//为了搜索结果独立成词 所以加" "
content = content.toLowerCase().replaceAll("\\b" + word + "\\b"," " + word +" ");
firstPos =content.toLowerCase().indexOf(" " + word + " ");
if (firstPos >= 0){
break;
}
}
if(firstPos ==-1){
if(content.length() > 160){
return content.substring(0,160)+"...";
}
//所有的分词结果都不在正文中存在 极端情况
return content;
}
//从firstPos 作为基准,往前找60个字符,作为描述的起始位置
String desc ="";
//如果当前位置少于60个字符开始位置就是第一个 否则开始位置 在查询词前60个
int descBeg = firstPos < 60 ? 0 : firstPos -60;
if (descBeg+160 > content.length()){
//判断是否超过正文长度
//从开始位置到最后
desc = content.substring(descBeg);
}else {
desc =content.substring(descBeg,descBeg + 160)+"...";
}
//在此处加上一个替换操作,把描述中的分词结果相同的部分,给加上一层<i>标签,就可以通过replace的方式实现
for (Term term : terms){
String word = term.getName();
//只有是全部是一个查询词 才加上 i 标签 正则规则(?i)大小写全部匹配
desc = desc.replaceAll("(?i)"+word+" ","<i> " + word + " </i>");
}
return desc;
}
public void loadStopWords (){
System.out.println("加载暂停词表");
try(BufferedReader bufferedReader = new BufferedReader(new FileReader(STOP_WORD_PATH))){
while (true){
String line = bufferedReader.readLine();
if (line == null){
//读取文件完毕
break;
}
stopWords.add(line);
}
}catch (IOException e){
e.printStackTrace();
}
}
public static void main(String[] args) {
DocSearcher docSearcher = new DocSearcher();
Scanner scanner = new Scanner(System.in);
while (true) {
System.out.print("->");
String query = scanner.next();
List<Result> results = docSearcher.search(query);
for (Result result : results) {
System.out.println("======================================");
System.out.println(result);
}
}
}
}
코드 변경 사항은 search 메서드와 mergeResult 메서드에 있습니다.
코드의 중요한 부분을 설명하자면,
다음은 행의 Weight 객체를 연산하기 위해 변환된 2차원 배열입니다. 이것은
재정렬 후
mergeResult에 대한 설명입니다 .
우리는 2차원 배열을 사용하여 작업 개체에 행과 열이 필요한지 확인하므로 내부 클래스 Pos가 있습니다.
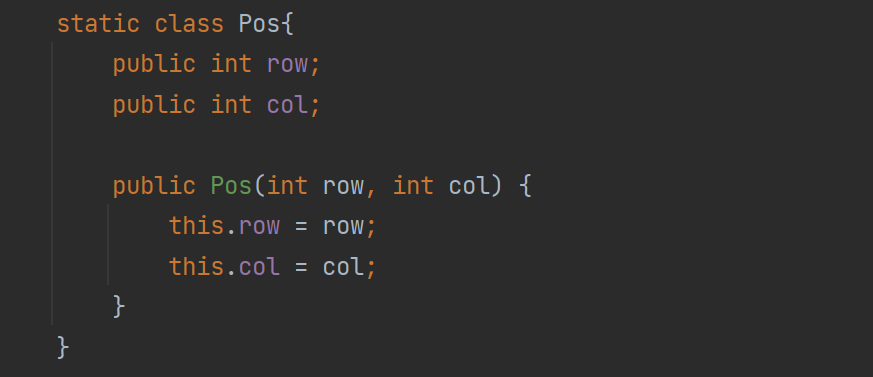
여기서는 두 개의 정렬된 연결 목록을 병합하는 작업을 사용합니다. 순서를 지정하려면 docId에 따라 먼저 정렬해야 합니다.
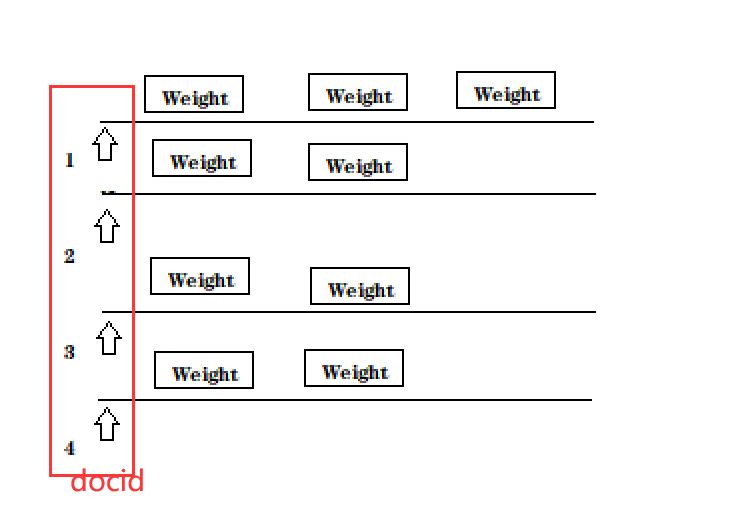
target은 새로운 컬렉션입니다. 작업이 끝나면 반환해야 합니다. 여기에서 우선 순위 대기열이 있습니다. Pos 객체의 어느 라인이 가장 작은지 찾아 결과에 추가합니다. 우선 순위 큐의 의미는 각 행에 해당하는 가장 작은 docid 개체를 찾기 위해 가장 작은 개체를 대상에 삽입하고 해당 첨자를 뒤로 이동하는 것입니다.
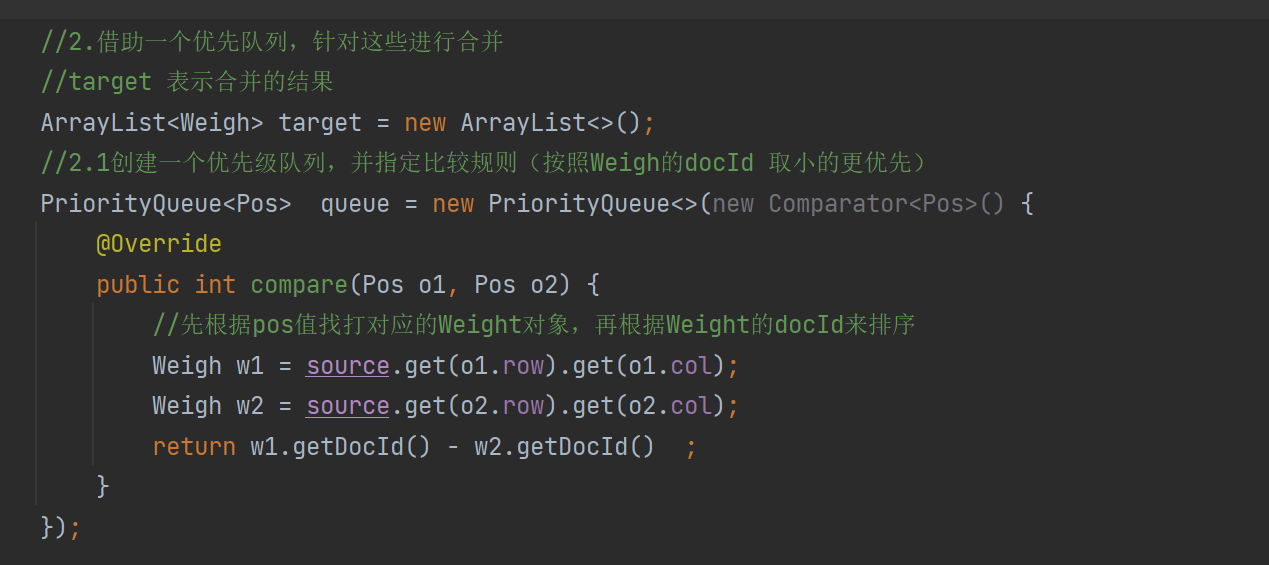
각 줄의 첫 번째:

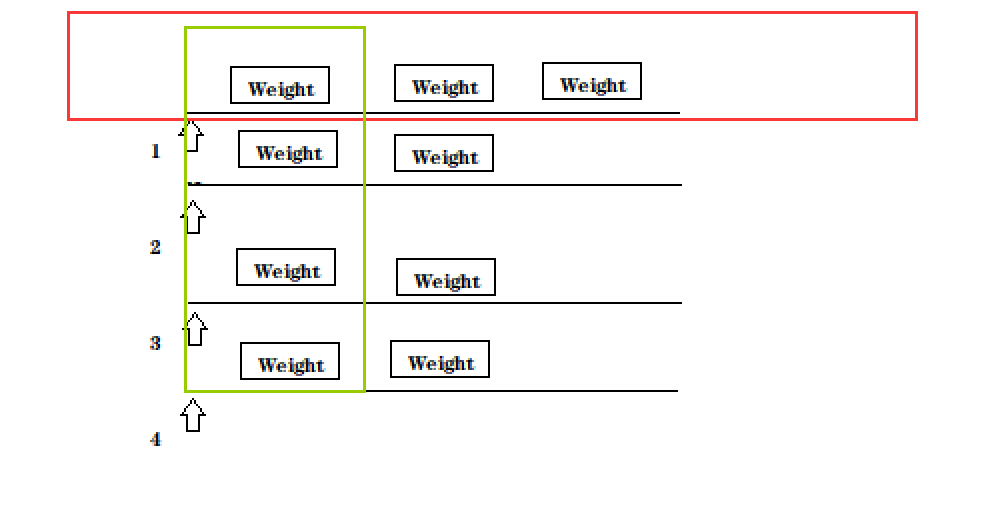
루프의 첫 번째 요소(현재 행에서 가장 작은 요소)를 가져오기 위해 폴링 작업은 요소를 꺼낸 다음 로컬 ID의 Weight 개체를 가져오는 것입니다. 비어 있는 경우 직접 Weight 개체를 추가합니다. 배열에 마지막으로 삽입된 요소를 찾습니다. 이번에 요소를 비교하여 id가 같으면 가중치를 추가합니다.
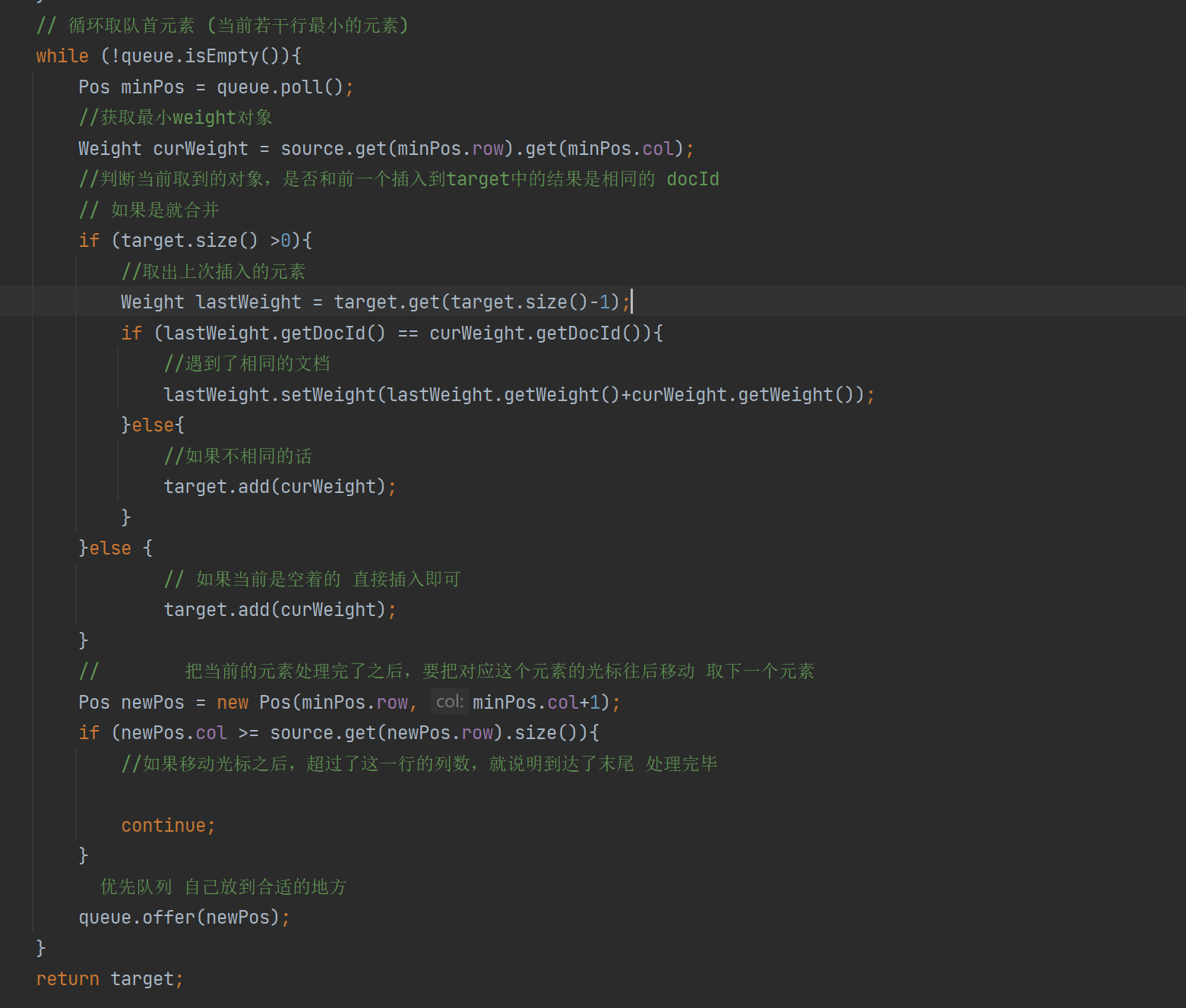
여기에서 커서의 이동은 현재 행이며 다음 열에 1을 더한 다음 마지막 열을 건너뛰고 마지막으로 대상으로 돌아갑니다.
7.14 웹 모듈 유효성 검사 가중치 병합 구현
첫 번째 검색 결과: 반복적이고 중복됩니다. 
코드 수정 후 결과: 중복 및 중복 결과가 제거되고 가중치가 변경됨: 다른 문서의 가중치도 증가할 수 있으므로 가중치가 여전히 낮은 것을 발견했습니까? 크게 의심할 여지가 없습니다.
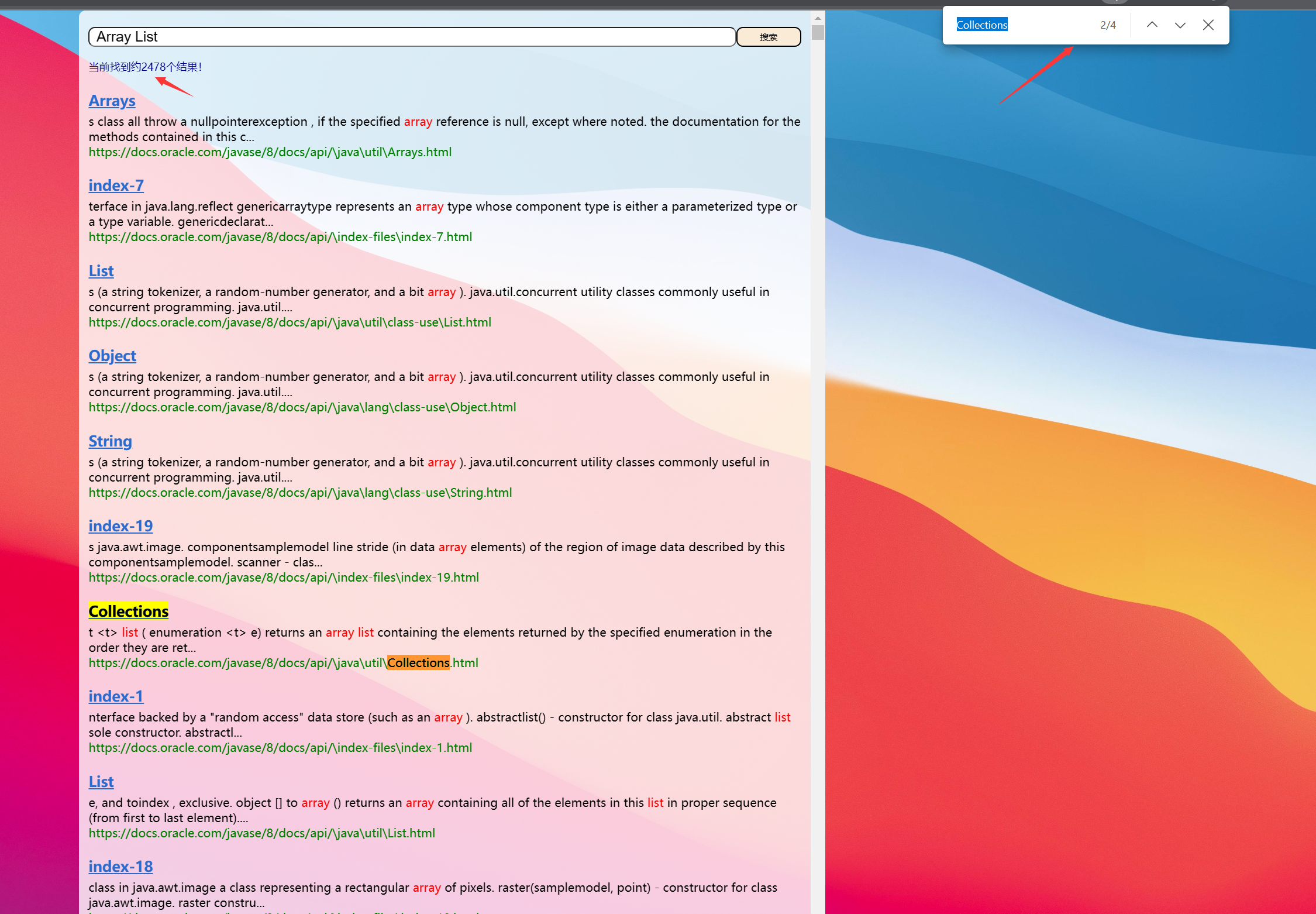
8. 검색 엔진 - springboot로 변경 - 프로젝트 생성
현재 Servlet 버전을 Spring 버전으로 변경합니다.
온라인 웹사이트를 사용하여 springboot 프로젝트 만들기: 웹사이트 주소
8.1 검색 엔진 - springboot로 변경 - 새 프로젝트에 코드 복사
- pom.xml 파일의 내용 복사
ansj와 jackson을 복사하십시오.
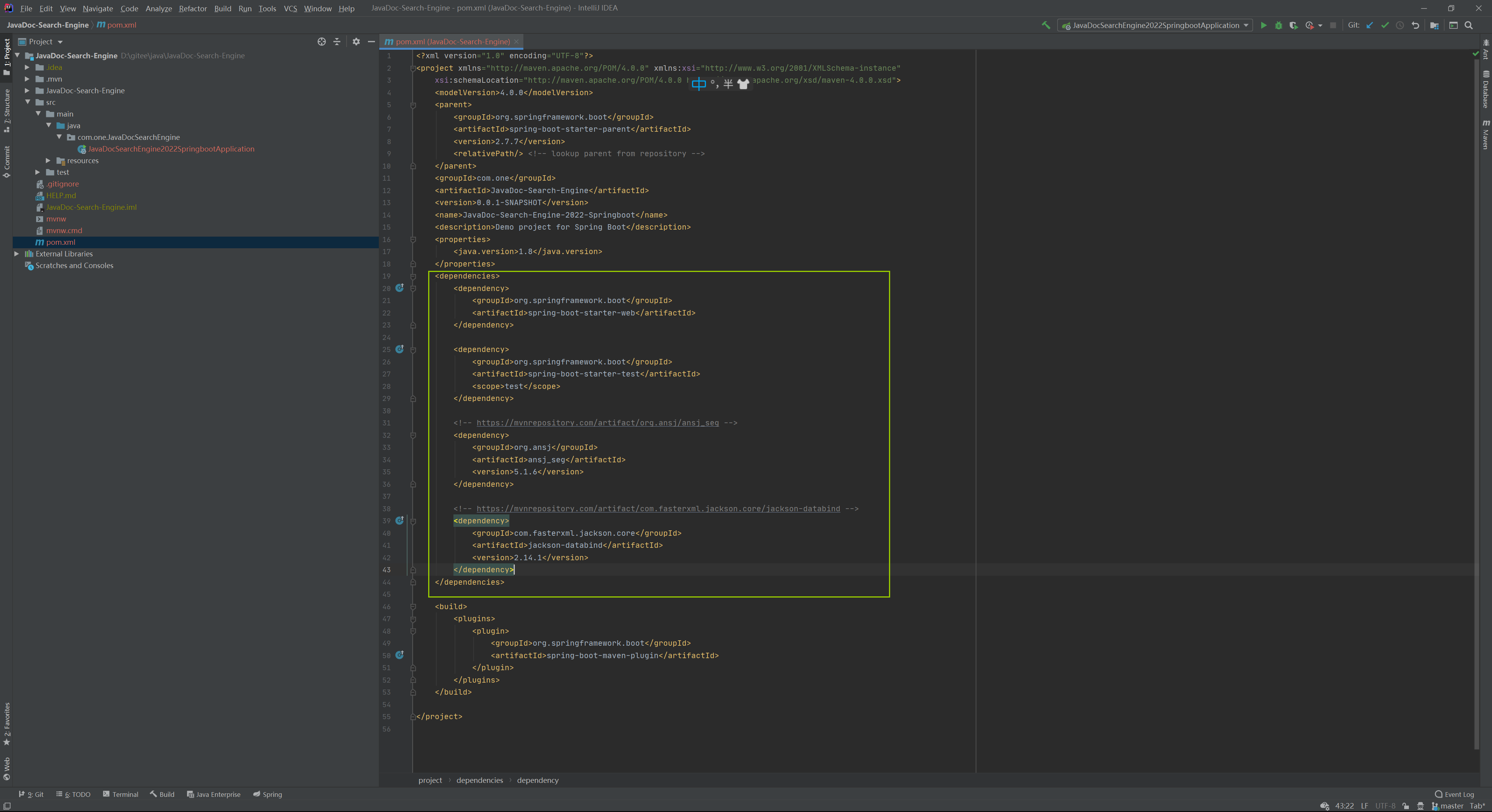
- 코드를 복사하고 경로에 주의
하십시오. searcher 패키지 아래의 모든 코드를 직접 복사하십시오.
- 프런트 엔드 정적 리소스 복사
자원의 정적 디렉토리에 위치합니다.
8.2 검색 엔진 - springboot로 변경 - 컨트롤러 레이어 구현
package com.one.JavaDocSearchEngine.controller;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.one.JavaDocSearchEngine.searcher.DocSearcher;
import com.one.JavaDocSearchEngine.searcher.Result;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController
public class DocSearcherController {
private static DocSearcher searcher = new DocSearcher();
private ObjectMapper objectMapper = new ObjectMapper();
@RequestMapping(value = "/search",produces = "application/json;charset=utf-8")
public String search(@RequestParam("query") String query) throws JsonProcessingException {
//参数是查询词,返回是响应内容
//参数的query 来自请求的url,querystring的query的值
List<Result> results = searcher.search(query);
return objectMapper.writeValueAsString(results);
}
}
직접 실행하십시오.
8.3 검색 엔진 - springboot로 변경 - 경로 스위치 만들기
우리 프로젝트는 서버에 배포할 예정인데 인덱스와 멈춤 단어는 모두 로컬 경로에 있고 코드의 경로도 로컬이지만 서버에 인덱스 파일이 없기 때문에 파일을 On에 넣습니다. 생성된 서버 경로:

서버 경로:

프로그램이 실행할 위치를 생각할 때 경로 전환 스위치를 만들 수 있습니다. 스위치를 켜고 끌 수 있습니다.
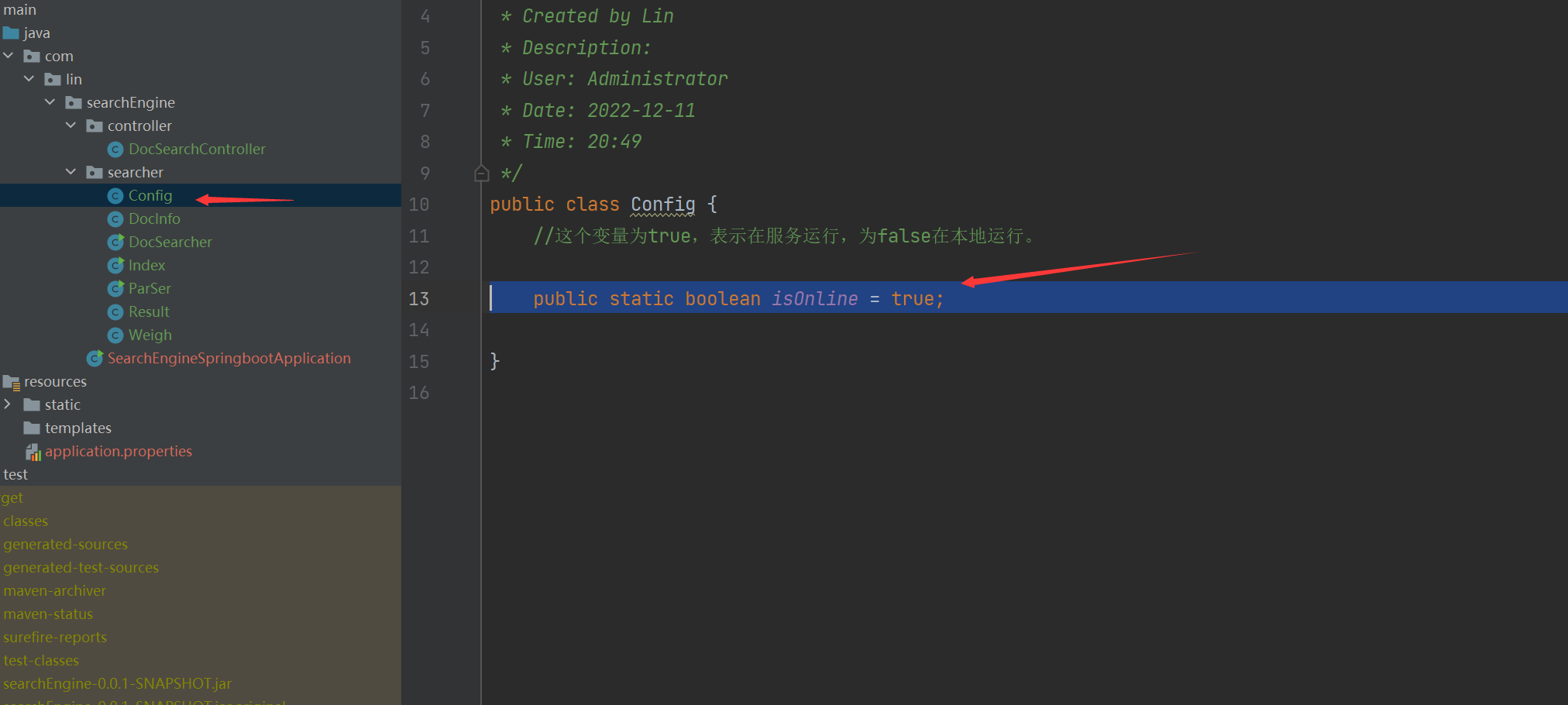
인덱싱된 파일 경로 스위치:
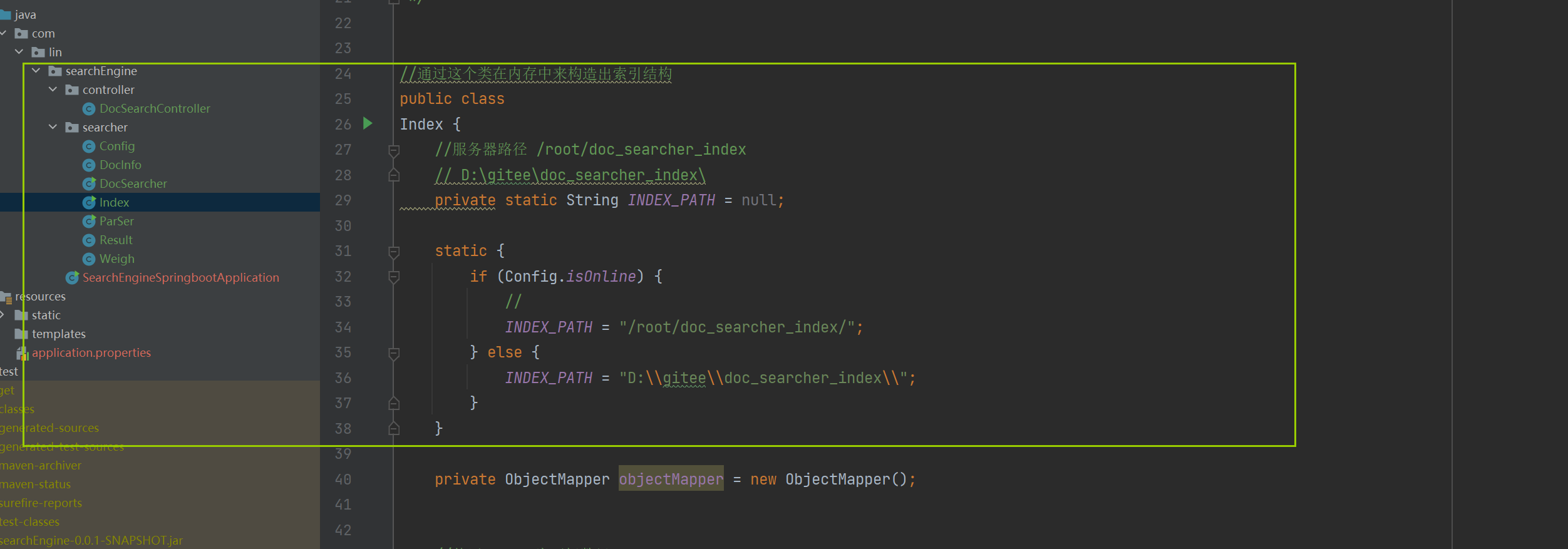
일시 중지 단어 파일 경로 스위치:
원리도 매우 간단하여 플래그 비트에 따라 전환할 플래그 비트를 판단하는 것입니다.
8.4 검색 엔진 - springboot로 변경 - 서버에 배포
우선 서버가 있어야 합니다. Huawei Cloud, Tencent Cloud가 좋습니다.
서버 주의사항 : 서버 시스템 방화벽 포트 추가, 서버 진입 규칙 추가
익숙하지 않은 경우 파고다를 설치하여 더 편리하게 만들 수 있습니다.

다음:

광산은 8084입니다. 포트 충돌이 있는 경우 이를 변경
한 다음 jar 패키지로 패키징할 수 있습니다.
실행: projectName을 자신의 프로젝트 이름으로 변경
nohup 자바 -jar 프로젝트 이름.jar &
이 명령은 계속 실행되며 닫히지 않습니다.
위에서 탄성 IP 및 포트를 통해 프로젝트에 액세스할 수 있습니다.