SeaweedFS는 효율적인 분산 파일 저장 시스템으로 초기 디자인 프로토타입은 작은 데이터 블록을 빠르게 읽고 쓸 수 있는 Facebook의 Haystack을 참조합니다. 이 기사는 SeaweedFS와 JuiceFS의 디자인 및 기능 차이점을 비교하여 독자가 보다 적합한 선택을 할 수 있도록 도와줍니다.
SeaweedFS 시스템 구조
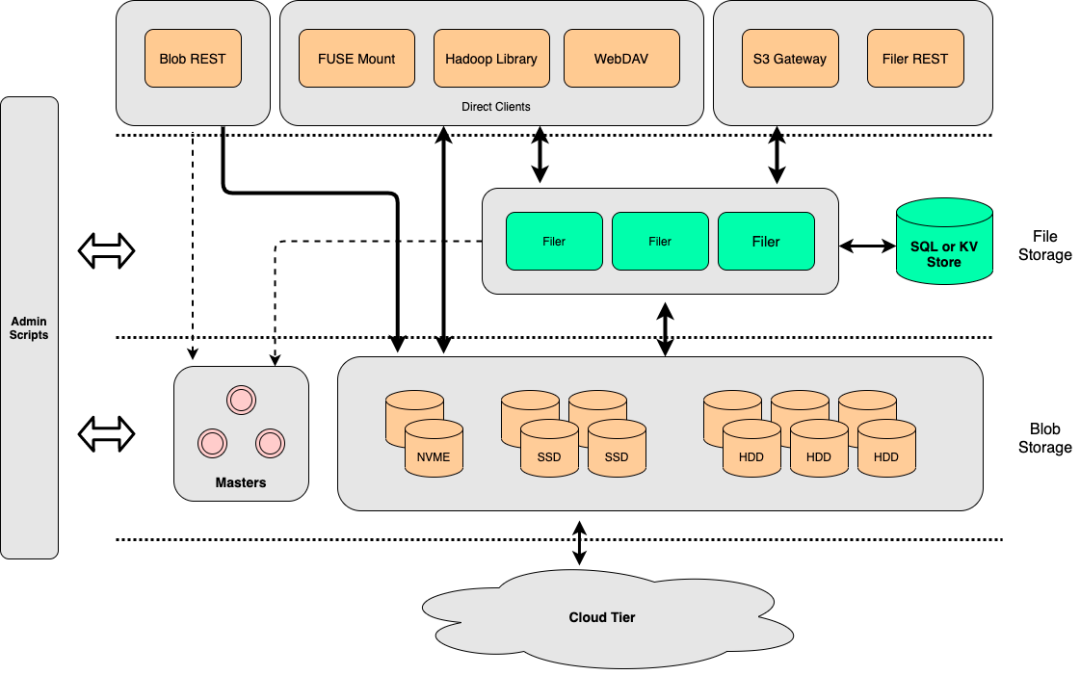
SeaweedFS는 기본 파일 저장을 위한 볼륨 서버, 클러스터 관리를 위한 마스터 서버, 더 많은 기능을 제공하는 선택적 파일러 구성 요소의 세 부분으로 구성됩니다.
볼륨 서버 与 마스터 서버
시스템 운영 측면에서 볼륨 서버와 마스터 서버는 함께 파일 저장 역할을 합니다. 볼륨 서버는 데이터 쓰기 및 읽기에 중점을 두는 반면 마스터 서버는 클러스터 및 볼륨 관리 서비스인 경향이 있습니다.
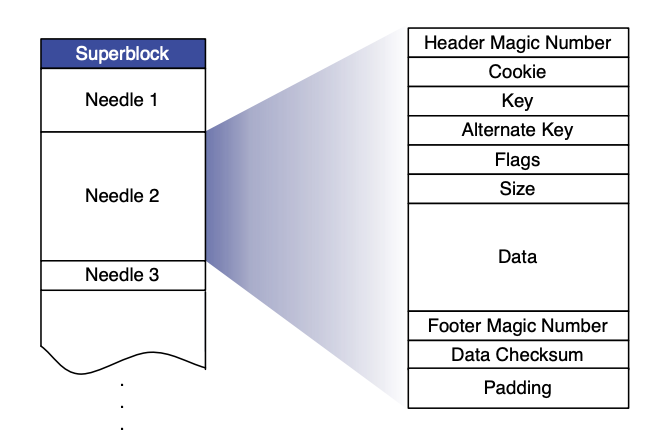
데이터를 읽고 쓸 때 SeaweedFS의 구현은 Haystack과 유사하며 사용자가 생성한 볼륨은 대용량 디스크 파일입니다(아래 그림의 Superblock). 이 볼륨에는 사용자가 작성한 모든 파일(아래 그림의 바늘)이 이 대용량 디스크 파일로 병합됩니다.
데이터 쓰기를 시작하기 전에 호출자는 SeaweedFS(마스터 서버)에 신청해야 하며 SeaweedFS는 현재 데이터 볼륨에 따라 파일 ID(볼륨 ID와 오프셋으로 구성)를 반환합니다. 메타데이터 정보(파일 길이, 청크 및 기타 정보)도 작성되며, 작성이 완료되면 호출자는 파일과 반환된 파일 ID를 외부 시스템(예: MySQL)에 연결하고 저장해야 합니다. 데이터를 읽을 때 파일 ID에는 이미 파일 위치(오프셋)를 계산하기 위한 모든 정보가 포함되어 있으므로 파일의 내용을 효율적으로 읽을 수 있습니다.
파일러
위에서 언급한 기본 저장 장치 위에 SeaweedFS는 Filer라는 구성 요소를 제공합니다. Volume Server와 Master Server를 하향 연결하여 풍부한 기능(POSIX 지원, WebDAV, S3 인터페이스 등)을 제공합니다. JuiceFS와 마찬가지로 Filer도 외부 데이터베이스에 연결하여 메타데이터 정보를 저장해야 합니다.
설명의 편의를 위해 아래에서 언급하는 SeaweedFS는 Filer 컴포넌트를 포함하고 있습니다.
JuiceFS 시스템 구조
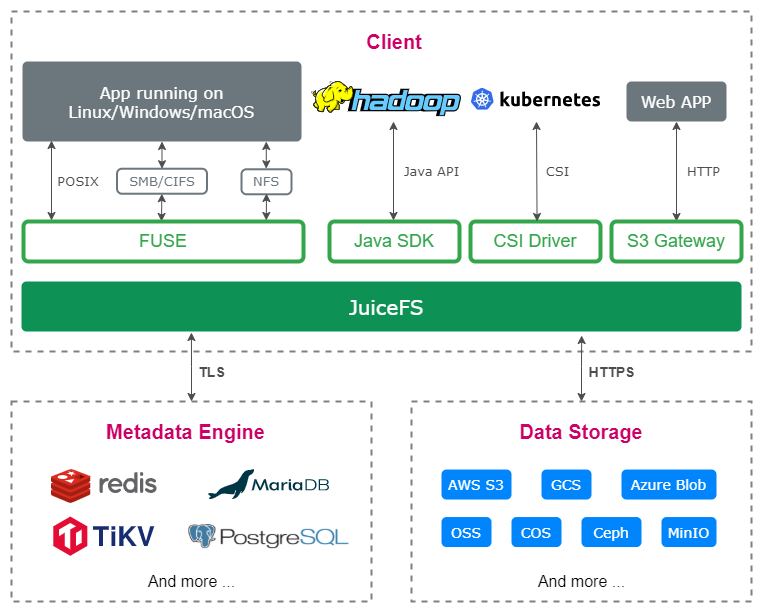
JuiceFS는 "데이터"와 "메타데이터"에 대해 별도의 스토리지 아키텍처를 채택합니다. 파일 데이터 자체는 세그먼트화되어 객체 스토리지(예: Amazon S3)에 저장되며 메타데이터는 사용자가 선택한 데이터베이스(예: 레디스, MySQL). 동일한 데이터베이스와 개체 저장소를 공유함으로써 JuiceFS는 강력한 일관성 보장을 통해 분산 파일 시스템을 구현하고 "완전한 POSIX 호환성" 및 "고성능"과 같은 많은 기능도 갖추고 있습니다.
메타데이터 비교
SeaweedFS와 JuiceFS는 모두 외부 데이터베이스를 통해 파일 시스템의 메타데이터 정보 저장을 지원합니다. 데이터베이스 지원 측면에서 SeaweedFS는 최대 24개의 데이터베이스를 지원합니다. JuiceFS는 데이터베이스 트랜잭션 기능에 대한 요구 사항이 높으며(아래 참조) 현재 총 3가지 유형의 트랜잭션 데이터베이스를 지원합니다.
원자 연산
모든 메타데이터 작업의 원자성을 보장하기 위해 JuiceFS는 구현 수준에서 트랜잭션 처리 기능이 있는 데이터베이스를 사용해야 합니다. 그러나 SeaweedFS는 이름 바꾸기 작업을 수행할 때 일부 데이터베이스(SQL, ArangoDB 및 TiKV)의 트랜잭션만 활성화하고 데이터베이스의 트랜잭션 기능에 대한 요구 사항이 낮습니다. 동시에 Seaweed FS는 이름 변경 작업 중에 메타데이터를 복사할 때 원래 디렉터리나 파일을 잠그지 않기 때문에 프로세스에서 업데이트된 데이터가 손실될 수 있습니다.
변경 로그
SeaweedFS는 모든 메타데이터 작업에 대한 변경 로그를 생성하며 이 로그는 데이터 복제(아래 참조), 작업 감사 및 기타 기능에 추가로 사용될 수 있지만 JuiceFS는 아직 이 기능을 구현하지 않았습니다.
스토리지 비교
위에서 언급한 바와 같이 SeaweedFS의 데이터 저장소는 볼륨 서버 + 마스터 서버로 구현되며 작은 데이터 블록의 "병합 저장소" 및 "삭제 코드"와 같은 기능을 지원합니다. JuiceFS의 데이터 저장소는 객체 저장소 서비스를 기반으로 하며 관련 기능도 사용자가 선택한 객체 저장소에 의해 제공됩니다.
파일 분할
데이터를 저장할 때 SeaweedFS와 JuiceFS는 파일을 여러 개의 작은 블록으로 분할하고 기본 데이터 시스템에 유지합니다. SeaweedFS는 파일을 8MB 블록으로 분할하고 매우 큰 파일(8GB 이상)의 경우 Chunk 인덱스도 기본 데이터 시스템에 저장합니다. JuiceFS는 먼저 64MB Chunk로 디스어셈블된 후 4MB Object로 디스어셈블되며 내부 Slice 개념을 통해 임의 쓰기, 순차 읽기 및 반복 쓰기 성능이 최적화됩니다. (자세한 내용은 읽기 청산 요청 처리 흐름 참조 )
계층적 스토리지
새로 생성된 볼륨의 경우 SeaweedFS는 데이터를 로컬에 저장하고 이전 볼륨의 경우 SeaweedFS는 핫 데이터와 콜드 데이터를 분리하기 위해 클라우드에 업로드하는 것을 지원합니다 . 이와 관련하여 JuiceFS는 외부 서비스에 의존해야 합니다.
데이터 압축
JuiceFS는 LZ4 또는 ZStandard를 사용하여 기록된 모든 데이터를 압축하는 것을 지원하는 반면 SeaweedFS는 기록된 파일의 확장자와 파일 유형에 따라 압축할지 여부를 선택합니다.
스토리지 암호화
JuiceFS는 전송 중 암호화(전송 중 암호화) 및 미사용 암호화(미사용 암호화)를 지원합니다.사용자가 정적 암호화를 활성화하면 사용자는 자체 관리 키를 전달해야 하며 기록된 모든 데이터는 이 키를 기반으로 합니다.암호화 . 자세한 내용은 " 데이터 암호화 "를 참조하십시오.
SeaweedFS는 또한 전송 중 암호화 및 미사용 암호화를 지원합니다. 데이터 암호화가 활성화된 후 볼륨 서버에 기록된 모든 데이터는 임의 키로 암호화되며 해당 임의 키 정보는 "메타데이터"를 유지하는 "파일러"에서 관리합니다.
액세스 동의
POSIX 호환성
JuiceFS 는 POSIX와 완벽하게 호환되는 반면 SeaweedFS는 부분적으로만 POSIX와 호환되며( "Issue 1558" 및 Wiki ) 기능은 계속 개선되고 있습니다.
S3 프로토콜
JuiceFS는 MinIO S3 게이트웨이를 통해 S3 게이트웨이 의 기능을 구현합니다 . JuiceFS의 파일에 대해 S3 호환 RESTful API를 제공하며 탑재가 불편한 경우 s3cmd, AWS CLI, MinIO Client(mc) 및 기타 도구를 사용하여 JuiceFS에 저장된 파일을 관리할 수 있습니다.
SeaweedFS는 현재 읽기, 쓰기, 쿼리 및 삭제와 같이 일반적으로 사용되는 요청을 다루는 약 20개의 S3 API를 지원하며 일부 특정 요청(예: 읽기)에 대한 기능 확장도 만들었습니다.자세한 내용은 Amazon-S3-API를 참조 하십시오 .
WebDAV 프로토콜
JuiceFS와 SeaweedFS 모두 WebDAV 프로토콜을 지원합니다.
HDFS 호환성
JuiceFS 는 HDFS API와 완벽하게 호환됩니다 . Hadoop 2.x 및 Hadoop 3.x와 호환될 뿐만 아니라 Hadoop 생태계의 다양한 구성 요소와도 호환됩니다. SeaweedFS는 HDFS API와의 기본적인 호환성을 제공 하지만 아직 일부 작업(turncate, concat, checksum 및 확장 속성 등)을 지원하지 않습니다.
CSI 드라이버
JuiceFS 와 SeaweedFS 모두 "Kubernetes CSI 드라이버"를 제공하여 사용자가 Kubernetes 에코시스템에서 해당 파일 시스템을 사용할 수 있도록 도와줍니다.
확장
클라이언트 캐시
JuiceFS에는 메타데이터에서 데이터 캐싱에 이르는 모든 부분을 다루는 다양한 클라이언트 측 캐싱 전략이 있어 사용자가 자신의 애플리케이션 시나리오(세부 정보 ) 에 따라 조정할 수 있는 반면 SeaweedFS에는 클라이언트 측 캐싱 기능이 없습니다.
클러스터 데이터 복제
여러 클러스터 간의 데이터 복제를 위해 SeaweedFS는 "활성-활성" 및 "활성-수동"의 두 가지 비동기 복제 모드를 지원합니다. 두 모드 모두 변경 로그를 전달하고 메커니즘을 다시 적용하여 서로 다른 클러스터의 데이터 간에 일관성을 달성합니다. 동일한 수정이 여러 번 순환되지 않도록 하는 서명 정보. 클러스터에 2개 이상의 노드가 있는 활성-활성 모드에서 SeaweedFS의 일부 작업(예: 디렉터리 이름 변경)에는 일부 제한이 적용됩니다.
JuiceFS는 기본적으로 클러스터 간의 데이터 동기화를 지원하지 않으며 메타데이터 엔진과 객체 스토리지의 자체 데이터 복제 기능에 의존해야 합니다.
클라우드의 데이터 캐시
SeaweedFS는 클라우드에서 개체 스토리지를 위한 캐시로 사용할 수 있으며 명령을 통해 수동 데이터 예열을 지원합니다. 캐시된 데이터에 대한 수정 사항은 객체 스토리지에 비동기식으로 동기화됩니다. JuiceFS는 개체 저장소에 파일을 청크로 저장해야 하며 이미 개체 저장소에 있는 데이터에 대한 캐싱 가속을 아직 지원하지 않습니다.
쓰레기통
JuiceFS는 기본적으로 휴지통 기능을 활성화하여 사용자가 삭제한 파일을 자동으로 JuiceFS 루트 디렉터리 아래의 .trash 디렉터리로 이동하고 데이터를 정리하기 전에 지정된 시간 동안 데이터를 보관합니다. SeaweedFS는 아직 이 기능을 지원하지 않습니다.
운영 및 유지 보수 도구
JuiceFS는 juciefs stats 및 juicefs profile이라는 두 가지 하위 명령을 제공하여 사용자가 실시간으로 특정 기간 동안 현재 또는 재생 성능 지표를 볼 수 있도록 합니다. 동시에 JuiceFS는 메트릭 인터페이스를 외부적으로 개발하고 사용자는 모니터링 데이터를 Prometheus 및 Grafana에 쉽게 연결할 수 있습니다.
SeaweedFS는 Prometheus와 Grafana를 동시에 연결하는 두 가지 방법인 Push 및 Pull을 실현 하고 사용자가 일련의 운영 및 유지 관리 작업(예: 현재 클러스터 상태 보기, 파일 목록 나열 등)을 수행할 수 있도록 weed shell 의 대화형 도구를 제공합니다. , 등.).
다른
-
출시 시간 측면에서 SeaweedFS는 2015년 4월에 출시되었으며 현재 총 16,400개의 별을 보유하고 있으며 JuiceFS는 2021년 1월에 출시되었으며 지금까지 총 7,300개의 별을 보유하고 있습니다.
-
프로젝트 측면에서 JuiceFS와 SeaweedFS는 모두 상업적으로 더 친숙한 Apache License 2.0을 채택합니다. SeaweedFS는 주로 Chris Lu가 관리하고 JuiceFS는 주로 Juicedata가 관리합니다.
-
JuiceFS와 SeaweedFS는 모두 Go 언어로 작성되었습니다.
비교 목록
| 해초FS | 주스FS | |
|---|---|---|
| 메타데이터 | 다중 엔진 | 다중 엔진 |
| 메타데이터 작업의 원자성 | 보장되지 않음 | 데이터베이스 트랜잭션으로 보장 |
| 변경 로그 | 가지다 | 없음 |
| 데이터 저장고 | 포함하다 | 외부 서비스 |
| 삭제 코드 | 지원하다 | 외부 서비스에 의존 |
| 데이터 병합 | 지원하다 | 외부 서비스에 의존 |
| 파일 분할 | 8MB | 64MB + 4MB |
| 계층적 스토리지 | 지원하다 | 외부 서비스에 의존 |
| 데이터 압축 | 지원(확장자 기준) | 지원(글로벌 설정) |
| 스토리지 암호화 | 지원하다 | 지원하다 |
| POSIX 호환성 | 기초적인 | 전체 |
| S3 프로토콜 | 기초적인 | 기초적인 |
| WebDAV 프로토콜 | 지원하다 | 지원하다 |
| HDFS 호환성 | 기초적인 | 전체 |
| CSI 드라이버 | 지원하다 | 지원하다 |
| 클라이언트 캐시 | 지원하지 | 지원하다 |
| 클러스터 데이터 복제 | 양방향 비동기, 다중 모드 | 지원하지 |
| 클라우드의 데이터 캐시 | 지원(수동 동기화) | 지원하지 |
| 쓰레기통 | 지원하지 | 지원하다 |
| 운영 및 유지 보수 도구 | 공급 | 공급 |
| 출시 시간 | 2015.4 | 2021.1 |
| 메인테이너 | 개인(크리스 루) | 회사(주이스데이터 Inc) |
| 언어 | 가다 | 가다 |
| 오픈 소스 계약 | 아파치 라이선스 2.0 | 아파치 라이선스 2.0 |
도움이 되셨다면 저희 프로젝트 Juicedata/JuiceFS 에 주목해주세요 ! (0ᴗ0✿)