더 많은 기술 교류 및 구직 기회를 얻으려면 ByteDance 데이터 플랫폼의 WeChat 공식 계정을 주목하고 [1]로 회신하여 공식 교류 그룹에 들어가십시오.
ByteHouse는 Volcano Engine의 클라우드 네이티브 데이터 웨어하우스로 사용자에게 매우 빠른 분석 경험을 제공하고 실시간 데이터 분석 및 대규모 오프라인 데이터 분석을 지원할 수 있습니다. 편리한 탄력적 확장 및 수축 기능, 최고의 분석 성능 및 풍부한 엔터프라이즈급 기능 , 고객의 디지털 혁신을 지원합니다.
이 기사에서는 수요 동기, 기술 구현 및 실제 적용의 관점에서 다양한 아키텍처를 기반으로 하는 ByteHouse 실시간 가져오기 기술의 진화를 소개합니다.
내부 업무의 실시간 가져오기 요구 사항
ByteHouse의 실시간 가져오기 기술 진화 동기는 ByteDance 내부 비즈니스의 요구에서 비롯되었습니다.
Byte 내부에서 ByteHouse는 실시간 가져오기를 위한 기본 데이터 소스로 Kafka를 주로 사용합니다( 이 문서에서는 설명을 확장하기 위해 Kafka 가져오기를 예로 사용하며 아래에서 반복하지 않습니다 ). 대부분의 내부 사용자의 경우 데이터 양이 상대적으로 크기 때문에 사용자는 데이터 가져오기 성능, 서비스 안정성 및 가져오기 기능의 확장성에 더 많은 관심을 기울입니다. 데이터 대기 시간의 경우, 대부분의 사용자는 몇 초 만에 볼 수 있는 한 요구 사항을 충족할 수 있습니다. 이러한 시나리오를 바탕으로 ByteHouse는 맞춤형 최적화를 진행했습니다.
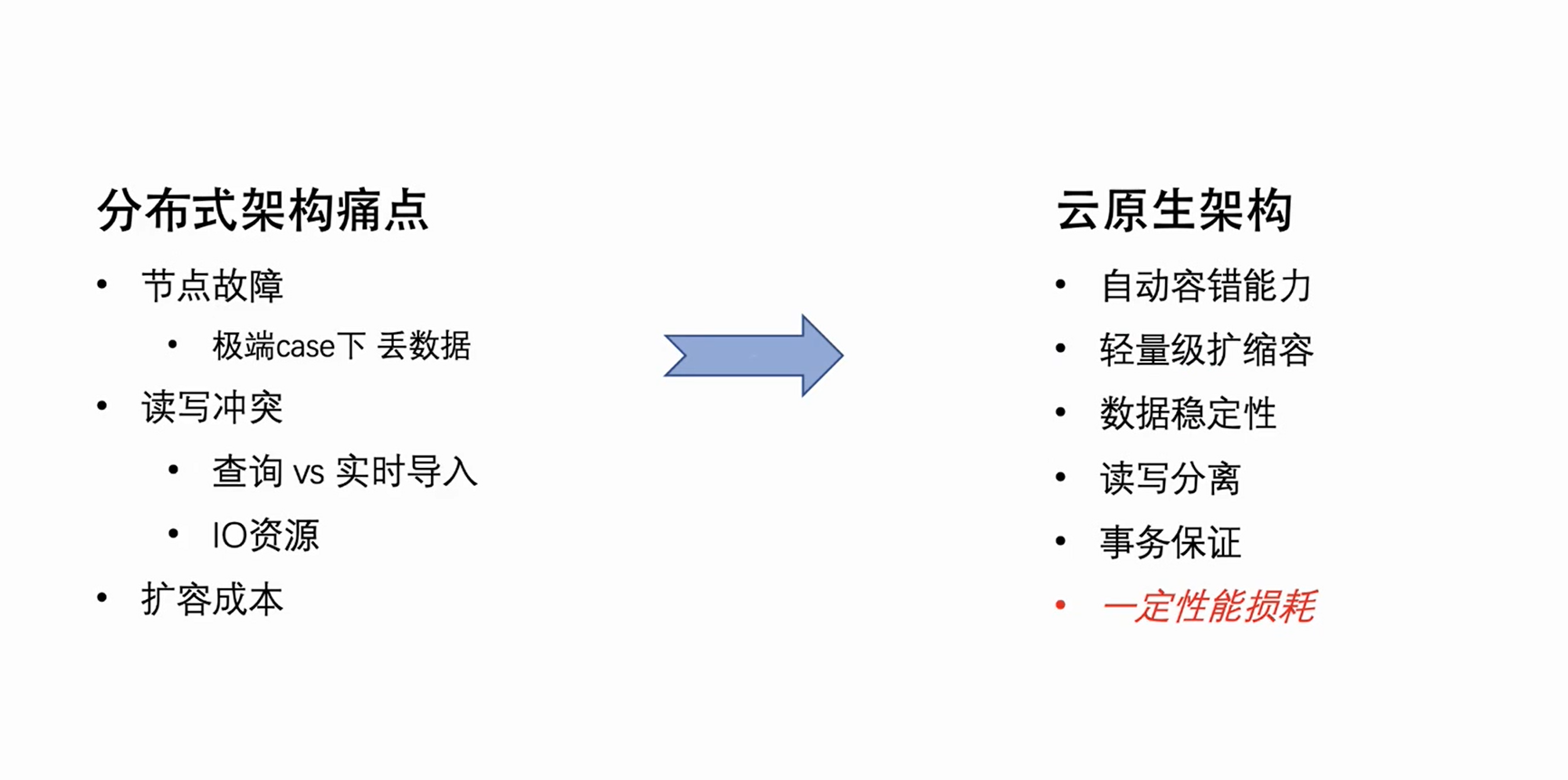
분산 아키텍처에서의 고가용성

커뮤니티 네이티브 분산 아키텍처
ByteHouse는 먼저 Clickhouse 커뮤니티의 분산 아키텍처를 따랐지만 분산 아키텍처에는 자연적인 아키텍처 결함이 있습니다.이러한 문제점은 주로 세 가지 측면에서 나타납니다.
-
노드 장애: 클러스터 머신의 수가 일정 규모에 도달하면 매주 수동으로 노드 장애를 처리해야 합니다. 단일 복사본 클러스터의 경우 일부 극단적인 경우 노드 장애로 인해 데이터 손실이 발생할 수도 있습니다.
-
읽기-쓰기 충돌: 분산 아키텍처의 읽기-쓰기 결합으로 인해 클러스터 로드가 특정 수준에 도달하면 사용자 쿼리 및 실시간 가져오기에서 리소스 충돌이 발생합니다. 특히 CPU 및 IO, 가져오기에 영향을 미치고 소비 지연이 발생합니다.
-
확장 비용: 분산 구조의 데이터는 기본적으로 로컬에 저장되기 때문에 확장 후 데이터를 다시 섞을 수 없습니다.새로 확장된 시스템에는 데이터가 거의 없으며 이전 시스템의 디스크는 거의 가득 차서 고르지 않은 클러스터가 발생할 수 있습니다. , 확장으로 이어지는 것은 효과적인 효과를 낼 수 없습니다.
이들은 분산 아키텍처의 자연스러운 문제점이지만 자연스러운 동시성 특성과 로컬 디스크 데이터 읽기 및 쓰기의 극단적인 성능 최적화로 인해 장점과 단점이 있다고 할 수 있습니다.
커뮤니티 실시간 가져오기 디자인
-
고급 소비 모드: 소비 로드 밸런싱을 위해 Kafka 자체 재조정 메커니즘에 의존합니다.
-
두 가지 수준의 동시성
분산 아키텍처를 기반으로 하는 실시간 가져오기 핵심 설계는 실제로 2단계 동시성입니다.
CH 클러스터에는 일반적으로 여러 샤드가 있으며 각 샤드는 동시에 사용하고 가져옵니다. 이는 첫 번째 수준 샤드 간의 다중 프로세스 동시성입니다.
또한 각 샤드는 여러 스레드를 사용하여 동시에 사용할 수 있으므로 고성능 처리량을 달성할 수 있습니다.
-
일괄 쓰기
단일 스레드에 관한 한 기본 소비 모드는 배치로 쓰는 것입니다. 일정량의 데이터를 소비하거나 일정 시간이 지난 후 한 번에 쓰는 것입니다. 일괄 쓰기는 성능 최적화를 더 잘 달성하고, 쿼리 성능을 개선하고, 백그라운드 병합 스레드에 대한 부담을 줄일 수 있습니다.
충족되지 않은 필요
위 커뮤니티의 설계 및 구현은 여전히 사용자의 일부 고급 요구 사항을 충족할 수 없습니다.
-
우선 일부 고급 사용자는 데이터 배포에 대한 요구 사항이 비교적 엄격합니다.예를 들어 일부 특정 데이터에 대한 특정 키가 있으며 동일한 키를 가진 데이터가 동일한 샤드에 배치되기를 바랍니다(예: 고유 키 요구 사항). 이 경우 커뮤니티 High Level의 소비 모델을 만족할 수 없습니다.
-
둘째, 높은 수준의 소비 형태 재조정은 제어할 수 없으며, 이로 인해 다양한 샤드 간에 Clickhouse 클러스터로 가져온 데이터가 고르지 않게 분포될 수 있습니다.
-
물론 소비 작업의 할당은 알 수 없으며 일부 비정상적인 소비 시나리오에서는 문제를 해결하기가 매우 어려워지므로 엔터프라이즈 수준 애플리케이션에서는 허용되지 않습니다.
자체 개발한 분산 아키텍처 소비 엔진 HaKafka
위의 요구 사항을 해결하기 위해 ByteHouse 팀은 분산 아키텍처를 기반으로 하는 소비 엔진인 HaKafka를 개발했습니다.
고가용성(Ha)
HaKafka는 커뮤니티에서 원래 Kafka 테이블 엔진의 소비 이점을 계승한 다음 고가용성 Ha 최적화에 중점을 둡니다.
분산 아키텍처에 관한 한 실제로 각 샤드에는 여러 복사본이 있을 수 있으며 각 복사본에서 HaKafka 테이블을 만들 수 있습니다. 그러나 ByteHouse는 ZK를 통해서만 리더를 선택하고 리더가 실제로 소비 프로세스를 실행하도록 하며 다른 노드는 대기 상태에 있습니다. 리더 노드를 사용할 수 없는 경우 ZK는 몇 초 만에 리더를 대기 노드로 전환하여 계속 사용함으로써 고가용성을 달성할 수 있습니다.
낮음 - 수준 소비 모드
HaKafka의 소비 모드가 High Level에서 Low Level로 조정되었습니다. 저수준 모드는 토픽 파티션이 클러스터의 각 샤드에 질서 있고 균일한 방식으로 분산되도록 보장할 수 있으며, 동시에 샤드 내에서 멀티스레딩을 다시 사용할 수 있어 각 스레드가 다른 파티션을 사용할 수 있습니다. 따라서 커뮤니티 Kafka 테이블 엔진의 2단계 동시성 이점을 완전히 상속합니다.
낮은 수준 소비 모드에서 업스트림 사용자가 주제에 쓸 때 데이터 왜곡이 없는 한 HaKafka를 통해 Clickhouse로 가져온 데이터는 샤드 간에 고르게 분산되어야 합니다.
동시에, 동일한 키의 데이터를 동일한 샤드에 쓰는 특별한 데이터 배포 요구 사항이 있는 고급 사용자의 경우, 업스트림에서 동일한 키의 데이터가 동일한 파티션에 쓰여지는 것을 확인한 다음 ByteHouse를 가져옵니다. 사용자의 요구를 완전히 충족시킬 수 있으며 매우 쉽습니다. 고유 키와 같은 시나리오를 잘 지원합니다.
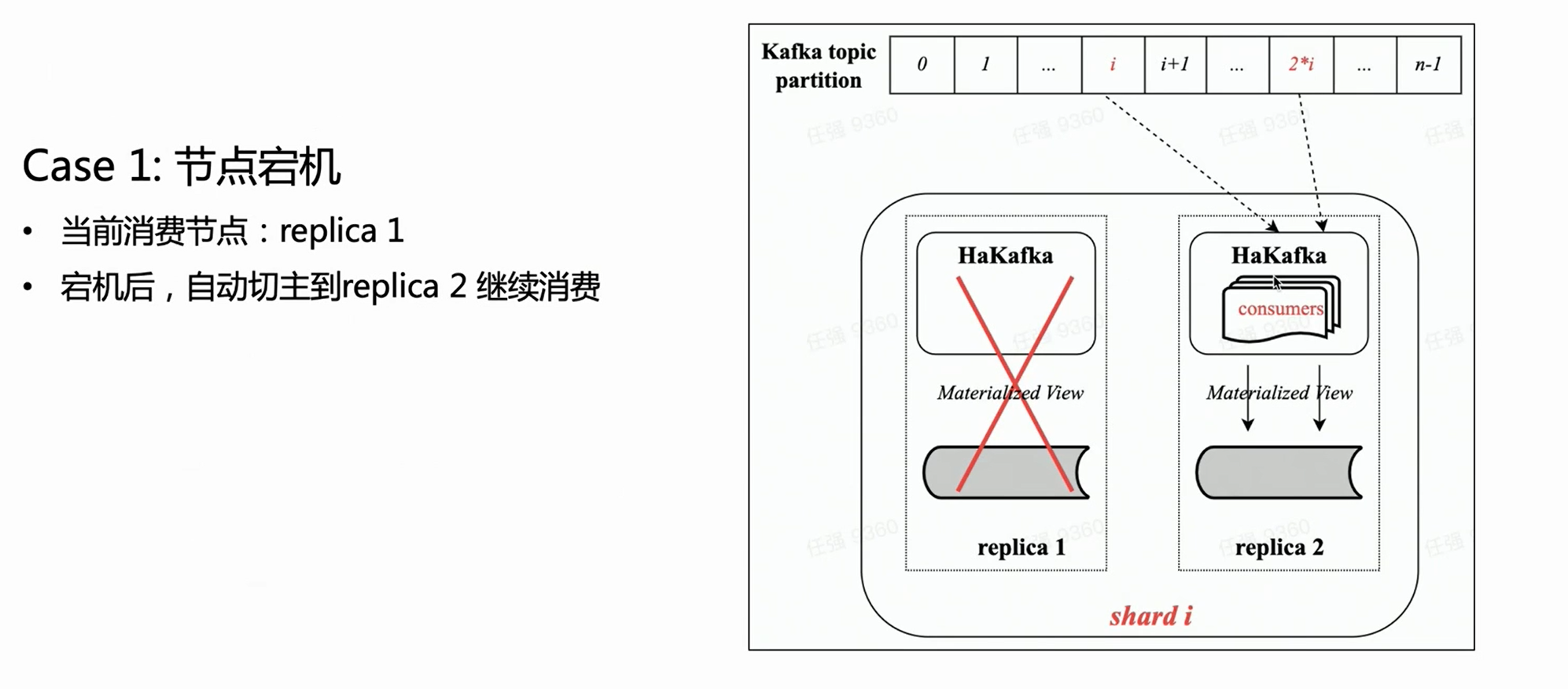
장면 1:
위의 그림을 기반으로 두 개의 복사본이 있는 샤드가 있다고 가정하면 각 복사본은 Ready 상태의 동일한 HaKafka 테이블을 갖게 됩니다. 그러나 ZK를 통해 리더를 성공적으로 선출한 리더 노드에서만 HaKafka가 해당 소비 프로세스를 실행합니다. 리더 노드가 다운되면 복제본 Replica 2가 자동으로 새로운 리더로 다시 선택되어 계속 소비되므로 고가용성이 보장됩니다.
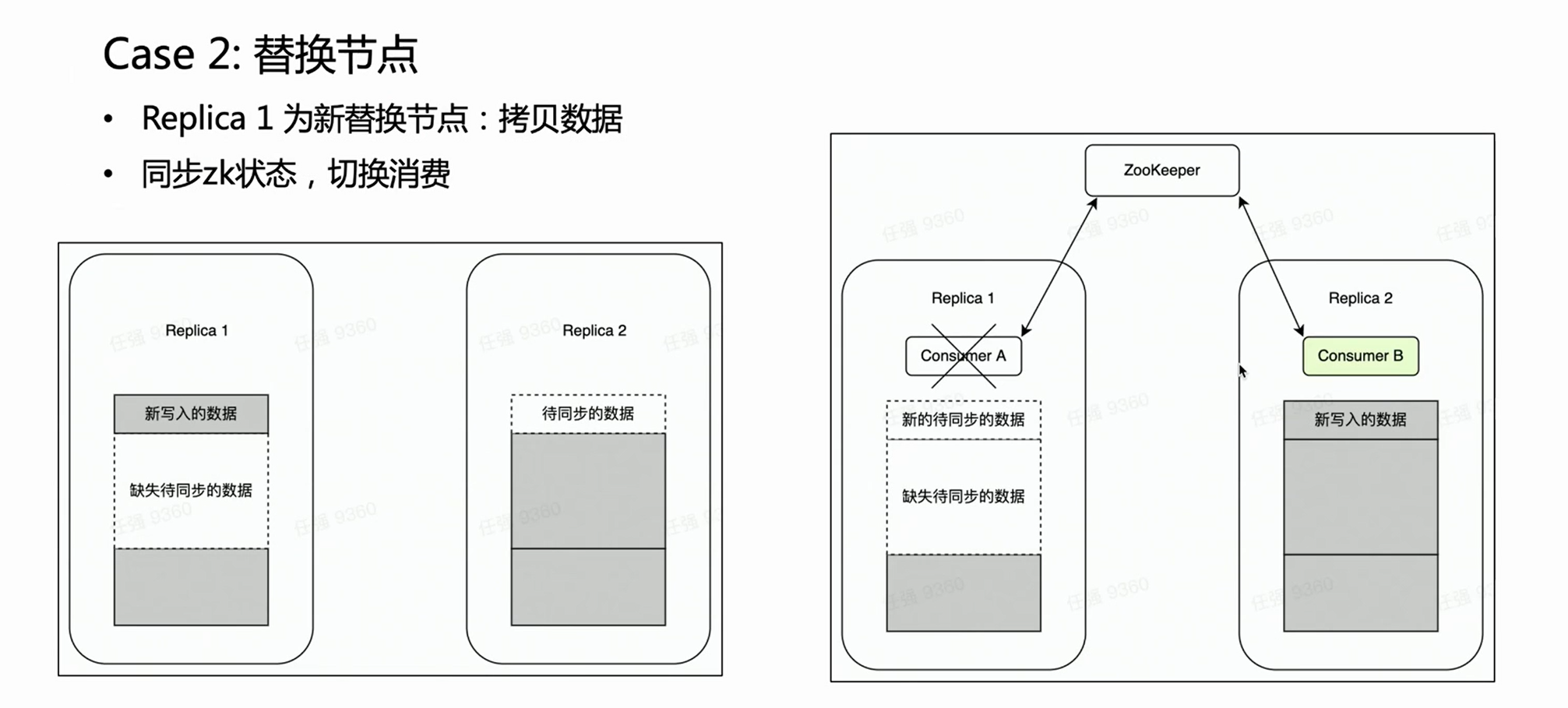
장면 2:
노드 장애의 경우 일반적으로 노드 교체 프로세스를 수행해야 합니다. 분산 노드 교체를 위한 매우 무거운 작업인 데이터 복사가 있습니다.
다중 복제 클러스터인 경우 하나의 복사본이 실패하고 다른 복사본은 손상되지 않습니다. 우리는 당연히 노드 교체 단계에서 Kafka 소비가 원래 데이터가 완전하기 때문에 온전한 복제본 Replica 2에 배치되기를 바랍니다. 이러한 방식으로 Replica 2는 항상 완전한 데이터 세트이며 외부 서비스를 정상적으로 제공할 수 있습니다. HaKafka는 이것을 보장할 수 있습니다. HaKafka가 리더를 선출할 때 특정 노드가 노드를 교체하는 중이라고 판단되면 리더로 선정되지 않습니다.
가져오기 성능 최적화: 메모리 테이블
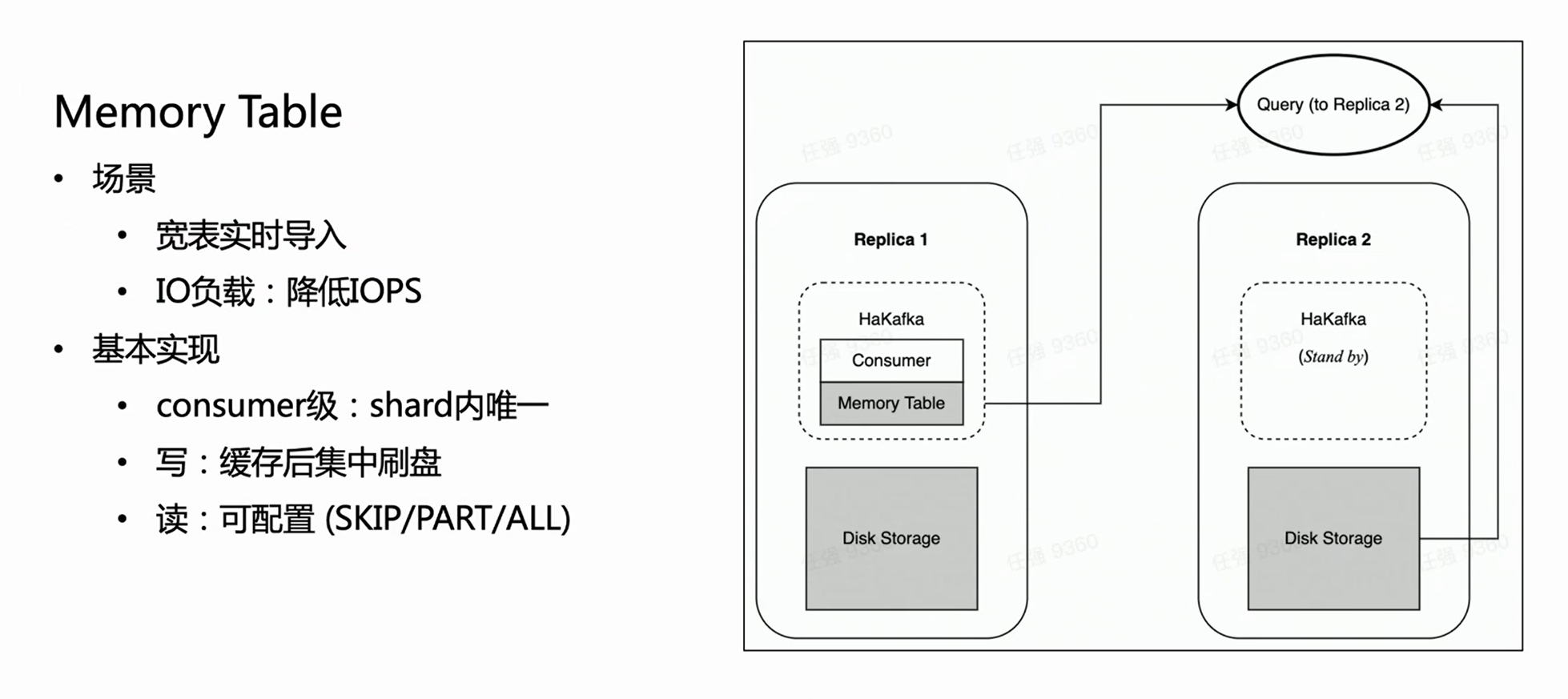
HaKafka는 메모리 테이블도 최적화합니다.
이러한 시나리오를 고려하십시오. 비즈니스에는 수백 개의 필드 또는 수천 개의 맵 키가 있을 수 있는 크고 넓은 테이블이 있습니다. ClickHouse의 각 열은 특정 파일에 해당하므로 열이 많을수록 가져올 때마다 더 많은 파일이 작성됩니다. 그러면 동일한 소비 시간 내에서 많은 조각난 파일이 자주 작성되어 시스템의 IO에 큰 부담이 되고 동시에 MERGE에 많은 부담을 주게 되며 심한 경우에는 심지어 클러스터를 사용할 수 없게 만듭니다. 이 시나리오를 해결하기 위해 가져오기 성능을 최적화하도록 메모리 테이블을 설계했습니다.
Memory Table 방식은 가져온 데이터를 매번 직접 플래싱하지 않고 메모리에 저장하고, 데이터가 일정량에 도달하면 디스크에 집중시켜 입출력 작업을 줄이는 방식이다. 메모리 테이블은 외부 쿼리 서비스를 제공할 수 있으며 쿼리는 메모리 테이블의 데이터를 읽기 위해 소비자 노드가 있는 복사본으로 라우팅되므로 데이터 가져오기 지연이 영향을 받지 않습니다. 내부 경험에서 메모리 테이블은 크고 넓은 테이블의 일부 비즈니스 가져오기 요구 사항을 충족할 뿐만 아니라 가져오기 성능을 최대 3배까지 향상시킵니다.
클라우드 네이티브 새 아키텍처
위에서 설명한 분산 아키텍처의 자연스러운 결함을 고려하여 ByteHouse 팀은 아키텍처를 업그레이드하는 작업을 해왔습니다. 우리는 비즈니스의 주류인 클라우드 네이티브 아키텍처를 선택했으며, 새로운 아키텍처는 2021년 초에 Byte의 내부 비즈니스에 서비스를 시작하고 2023년 초에 코드(ByConity)를 오픈 소스화할 예정입니다 .
클라우드 네이티브 아키텍처 자체에는 자연스러운 자동 내결함성과 경량 확장 기능이 있습니다. 동시에 데이터가 클라우드에 저장되기 때문에 스토리지와 컴퓨팅의 분리를 실현할 뿐만 아니라 데이터의 보안과 안정성도 향상됩니다. 물론 클라우드 네이티브 아키텍처에 단점이 없는 것은 아닙니다. 원래 로컬 읽기 및 쓰기를 원격 읽기 및 쓰기로 변경하면 불가피하게 읽기 및 쓰기 성능이 어느 정도 손실됩니다. 그러나 어느 정도의 성능 손실을 아키텍처의 합리성과 맞바꾸고 운영 및 유지 관리 비용을 줄이는 것이 실제로는 단점보다 큽니다.
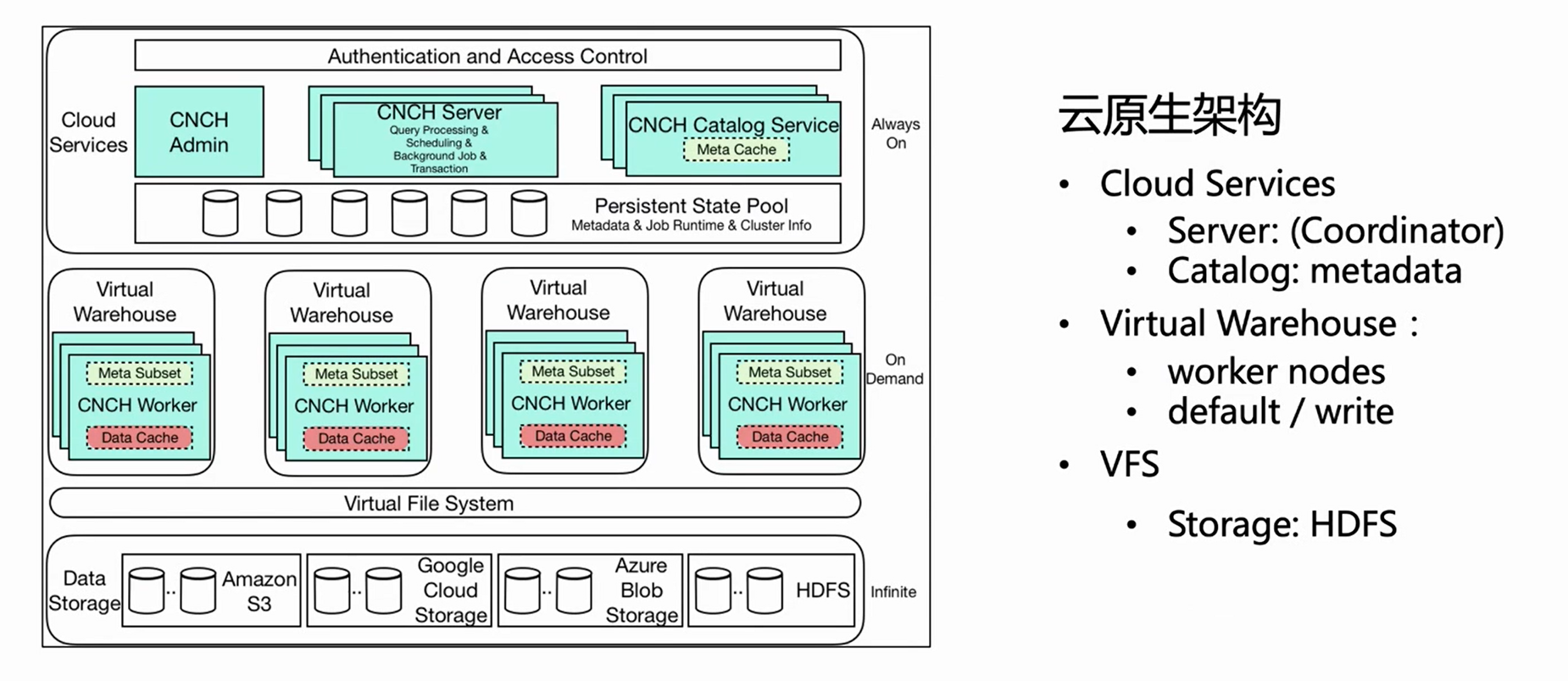
위의 그림은 ByteHouse 클라우드 네이티브 아키텍처의 아키텍처 다이어그램입니다.이 기사에서는 실시간 가져오기를 위한 몇 가지 중요한 관련 구성 요소를 소개합니다.
-
클라우드 서비스
먼저 전체 아키텍처는 3개 레이어로 나뉘는데, 첫 번째 레이어는 Cloud Service로 주로 Server와 Catlog의 두 가지 구성 요소를 포함합니다. 이 계층은 서비스 입구이며 쿼리 가져오기를 포함한 모든 사용자 요청은 서버에서 입력됩니다. 서버는 요청을 전처리만 할 뿐 실행하지는 않으며, Catlog가 메타 정보를 조회한 후 전처리된 요청과 메타 정보를 Virtual Warehouse로 전송하여 실행합니다.
-
가상 창고
Virtual Warehouse는 실행 계층입니다. 서로 다른 비즈니스는 리소스 격리를 달성하기 위해 독립적인 가상 창고를 가질 수 있습니다. 이제 Virtual Warehouse는 주로 Default와 Write의 두 가지 범주로 나뉘며 Default는 주로 쿼리에 사용하고 Write는 Import에 사용하여 읽기와 쓰기의 분리를 실현합니다.
-
VFS
맨 아래 계층은 HDFS, S3 및 aws와 같은 클라우드 스토리지 구성 요소를 지원하는 VFS(데이터 스토리지)입니다.
클라우드 네이티브 아키텍처 기반 실시간 가져오기 설계
클라우드 네이티브 아키텍처에서 서버는 특정 가져오기 실행을 수행하지 않고 작업만 관리합니다. 따라서 서버 측에서 각 소비 테이블에는 모든 소비 실행 작업을 관리하고 가상 창고에서 실행되도록 예약하는 관리자가 있습니다.
HaKafka의 낮은 수준 소비 모드를 상속하기 때문에 Manager는 구성된 소비 작업 수에 따라 주제 파티션을 각 작업에 균등하게 분배합니다. 소비 작업 수는 구성 가능하며 상한은 주제 파티션의 수입니다.
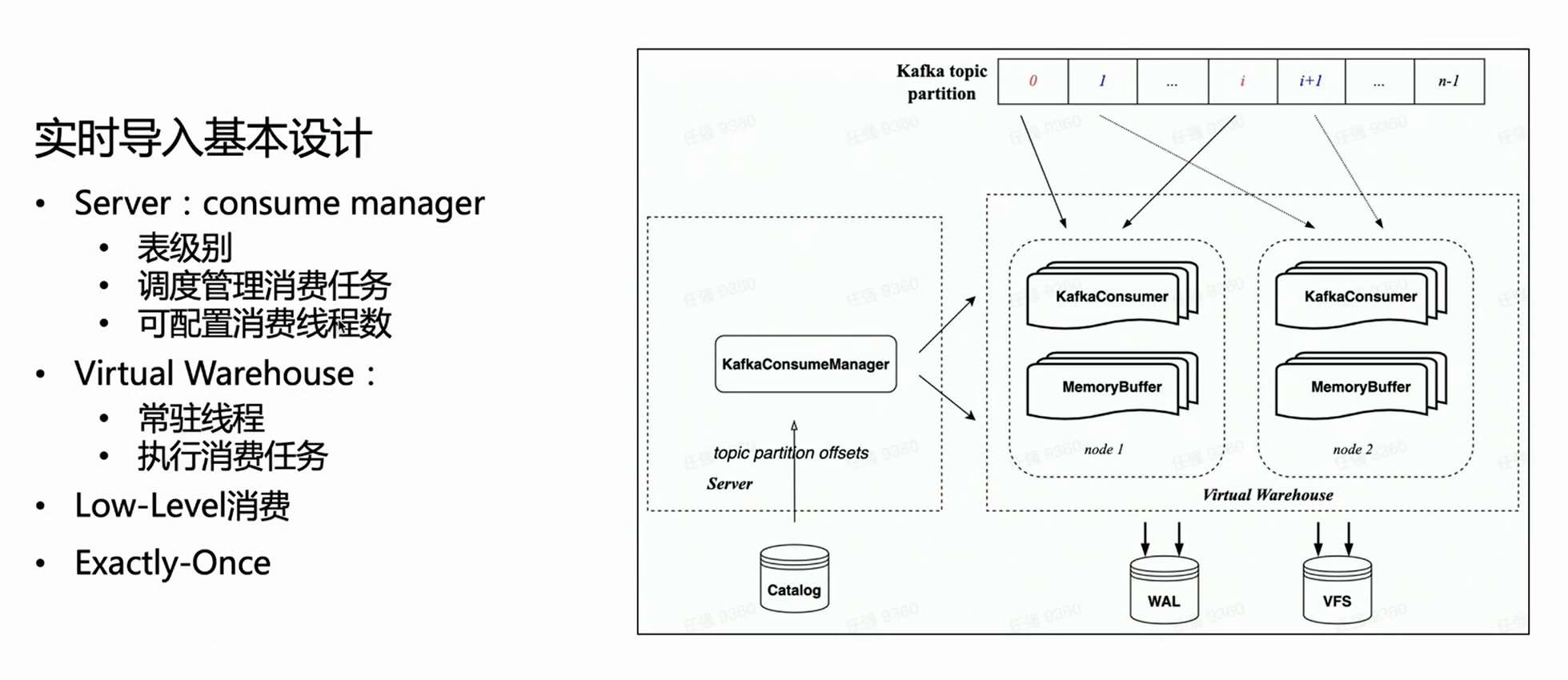
위 그림을 기준으로 왼쪽의 Manager는 카탈로그에서 해당 Offset을 가져온 다음 지정된 소비 작업 수에 따라 해당 소비 파티션을 할당하고 가상 창고의 다른 노드에 스케줄링하는 것을 볼 수 있습니다. 실행.
새로운 소비 실행 프로세스
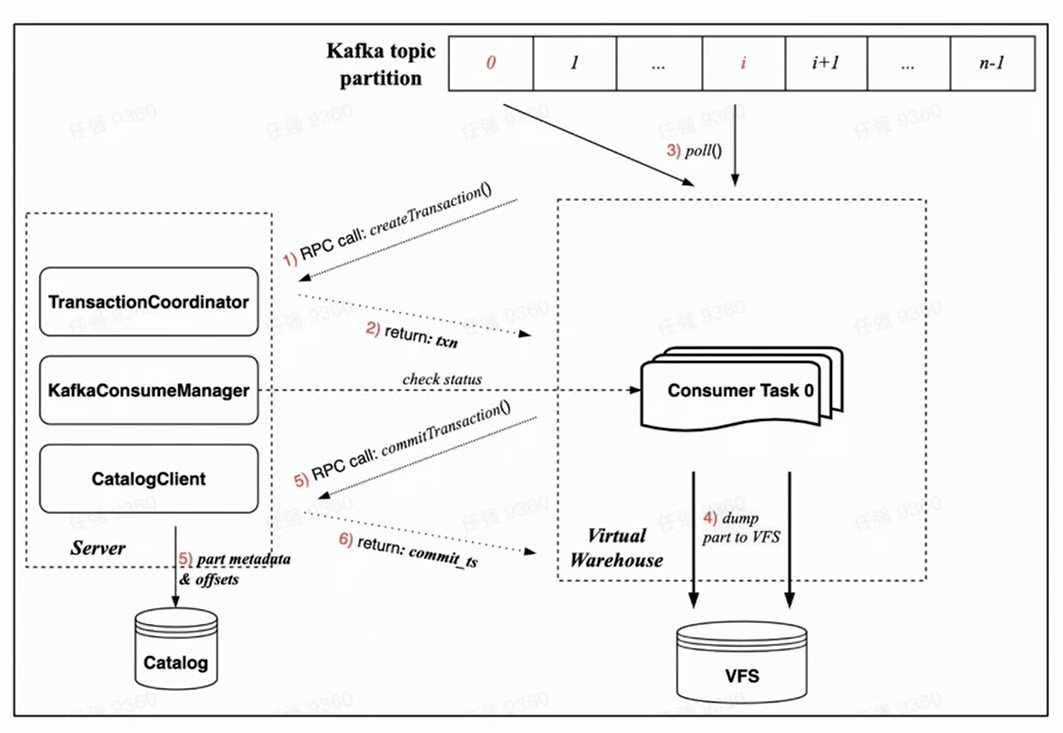
새로운 클라우드 네이티브 아키텍처는 Transaction에 의해 보장되기 때문에 모든 작업은 하나의 트랜잭션 내에서 완료될 것으로 예상되며 이는 보다 합리적입니다.
새로운 클라우드 네이티브 아키텍처에서 트랜잭션 구현에 따라 각 소비 작업의 소비 프로세스는 주로 다음 단계를 포함합니다.
-
소비가 시작되기 전에 작업자 측 작업은 먼저 서버 측에 RPC 요청을 통해 트랜잭션을 생성하도록 요청합니다.
-
rdkafka::poll()을 실행하여 일정 시간(기본적으로 8초) 또는 충분한 크기의 블록을 사용합니다.
-
블록을 부품으로 변환하고 VFS로 덤프합니다( 데이터는 현재 표시되지 않음 ).
-
RPC 요청을 통해 서버에 트랜잭션 커밋 요청 시작
(트랜잭션의 커밋 데이터에는 덤프 완료된 부분 메타데이터 및 해당 Kafka 오프셋이 포함됨)
-
트랜잭션이 성공적으로 커밋되었습니다( 데이터가 표시됨 ).
내결함성 보장
위의 소비 프로세스에서 우리는 새로운 클라우드 네이티브 아키텍처에서 내결함성 소비 보장이 주로 관리자와 작업의 양방향 하트비트와 빠른 실패 전략을 기반으로 한다는 것을 알 수 있습니다.
-
Manager 자체는 정기적인 프로빙을 가지며 예약된 작업이 RPC를 통해 정상적으로 실행되고 있는지 확인합니다.
-
동시에 각 작업은 트랜잭션 RPC 요청을 사용하여 소비 중에 유효성을 확인합니다. 확인에 실패하면 자동으로 종료될 수 있습니다.
-
관리자가 활동성을 감지하지 못하면 즉시 새로운 소비 작업을 시작하여 두 번째 수준의 내결함성을 보장합니다.
소비 전력
소비 용량은 위에서 언급한 대로 확장 가능하며 소비 작업의 수는 주제의 파티션 수까지 사용자가 구성할 수 있습니다. Virtual Warehouse의 노드 부하가 높으면 노드도 아주 가볍게 확장할 수 있습니다.
물론 Manager 예약 작업은 기본적인 로드 밸런싱 보장을 구현합니다. Resource Manager를 사용하여 작업을 관리하고 예약합니다.
의미 향상: 정확히 - 한 번
마지막으로, 분산 도서 아키텍처의 At-Least-Once에서 Exactly-Once 로 새로운 클라우드 네이티브 아키텍처의 소비 시맨틱도 향상되었습니다 .
분산 아키텍처는 트랜잭션이 없기 때문에 At-Least-Once만 달성할 수 있습니다. 즉, 어떤 상황에서도 데이터가 손실되지 않지만 극단적인 경우 반복 소비가 발생할 수 있습니다. 클라우드 네이티브 아키텍처에서 트랜잭션 구현 덕분에 각 소비는 트랜잭션을 통해 Part 및 Offset을 원자적으로 커밋하여 Exactly-Once의 의미론적 향상을 달성할 수 있습니다.
메모리 버퍼
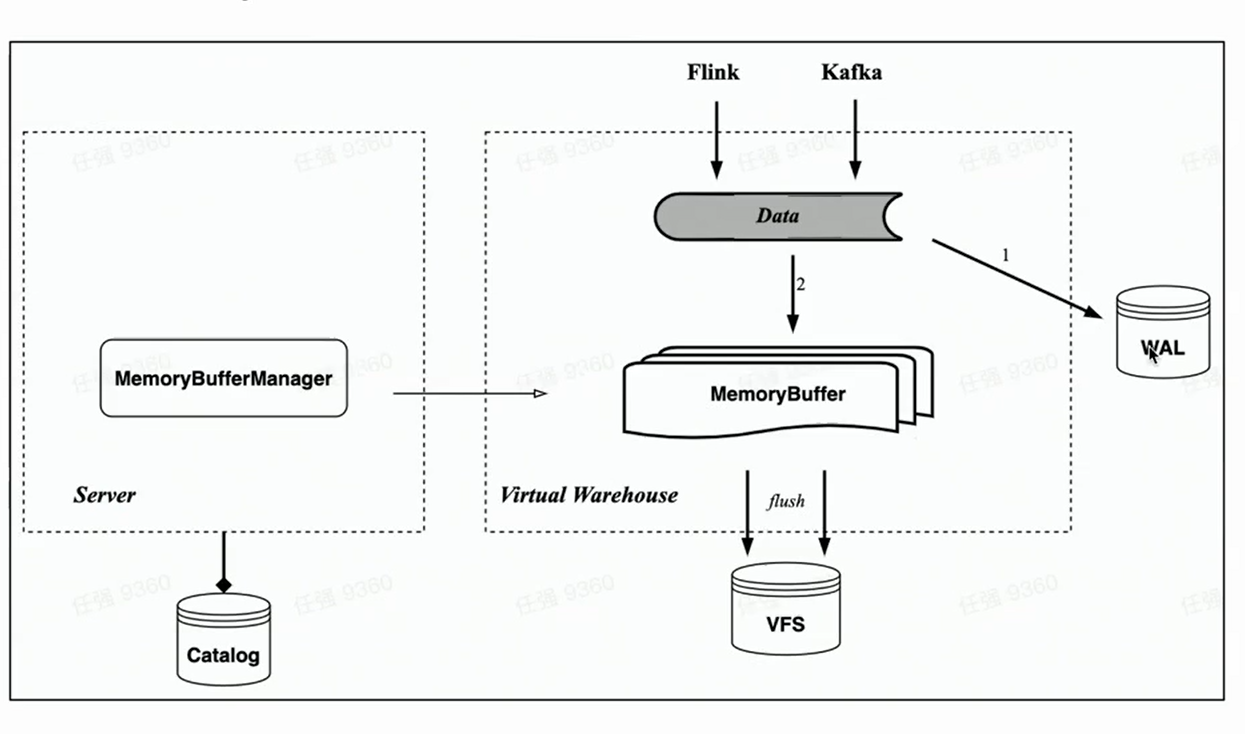
HaKafka의 메모리 테이블에 해당하는 클라우드 네이티브 아키텍처는 메모리 캐시 메모리 버퍼 가져오기도 구현합니다.
메모리 테이블과 달리 메모리 버퍼는 더 이상 Kafka의 소비 작업에 바인딩되지 않지만 스토리지 테이블에 대한 캐시 계층으로 구현됩니다. 이런 식으로 Memory Buffer는 Kafka 가져오기뿐만 아니라 Flink와 같은 소규모 일괄 가져오기에도 사용할 수 있어 더욱 다재다능합니다.
동시에 새로운 구성 요소 WAL을 도입했습니다. 데이터를 가져올 때 WAL을 먼저 쓰고 쓰기가 성공하면 데이터 가져오기가 성공한 것으로 간주할 수 있습니다. 서비스가 시작될 때 WAL에서 플래시되지 않은 데이터를 먼저 복원할 수 있습니다. 메모리 버퍼를 쓰고 성공적인 쓰기 후에 데이터를 볼 수 있습니다 —— 메모리 버퍼는 사용자가 쿼리할 수 있기 때문입니다. 메모리 버퍼의 데이터도 주기적으로 플러시되며 플러시 후 WAL에서 지울 수 있습니다.
비즈니스 응용 및 미래 사고
마지막으로 Byte에서 실시간 가져오기의 현재 상태와 차세대 실시간 가져오기 기술의 가능한 최적화 방향을 간략하게 소개합니다.
ByteHouse의 실시간 가져오기 기술은 Kafka를 기반으로 하며 일일 데이터 처리량은 PB 수준이며 가져온 단일 스레드 또는 단일 소비자 처리량의 경험 값은 10-20MiB/s입니다. (여기서 실증적 값을 강조한 것은 이 값이 고정된 값도 아니고 피크 값도 아니기 때문에 소비 처리량은 주로 사용자 테이블의 복잡도에 따라 달라지며 테이블 열의 수가 증가할수록 가져오기 성능이 크게 저하될 수 있습니다. 감소, 정확한 계산식을 사용할 수 없기 때문에 여기서의 경험치는 바이트 내부 대부분의 테이블 임포트 성능 경험치 이상입니다.)
Kafka 외에도 Byte는 실제로 RocketMQ, Pulsar, MySQL(MaterializedMySQL), Flink 직접 쓰기 등 다른 데이터 소스의 실시간 가져오기를 지원합니다.
차세대 실시간 가져오기 기술에 대한 간단한 생각:
-
보다 일반적인 실시간 가져오기 기술을 통해 사용자는 더 많은 가져오기 데이터 소스를 지원할 수 있습니다.
-
데이터 가시성은 대기 시간과 성능 간의 균형입니다.
자세히 알아보려면 클릭하여 ByteHouse 클라우드 네이티브 데이터 웨어하우스 로 이동하세요.