GPT モデル
GPT モデル: Generative Pre-Training
全体の構造:
監視されていない事前トレーニング
下流のタスクのための監視された微調整
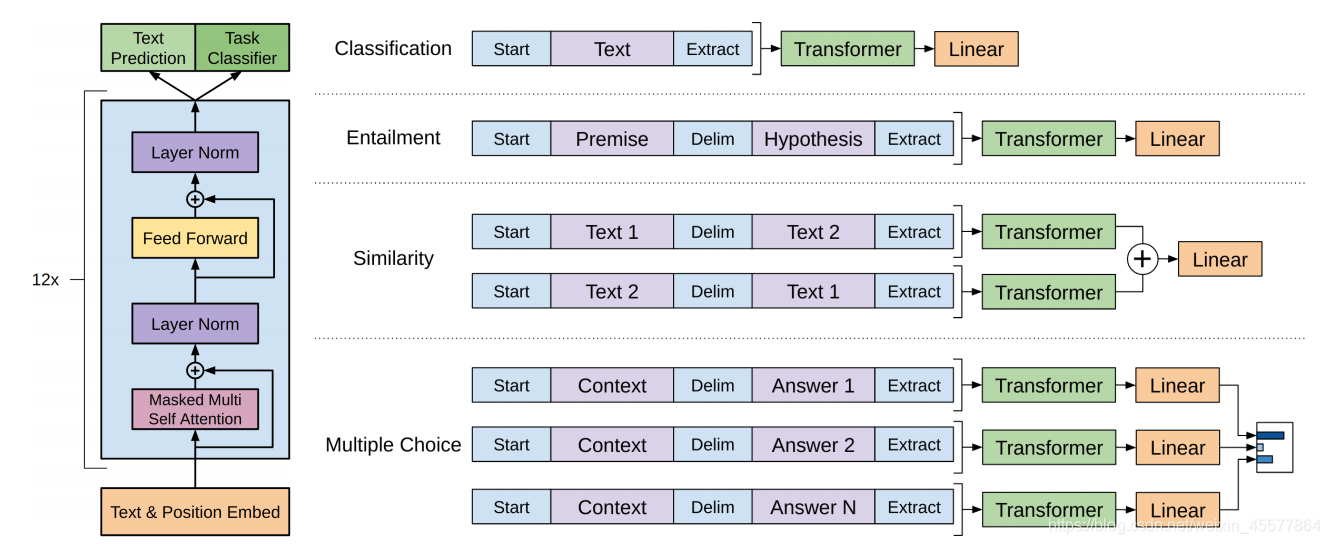
コア構造: 中間部分は、主に 12 個の Transformer Decoder ブロックが積み重ねられて構成されています
次の図は、モデルの全体的な構造をより直感的に反映しています。
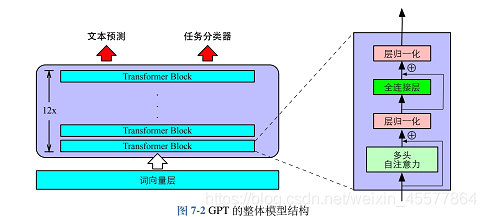
モデルの説明
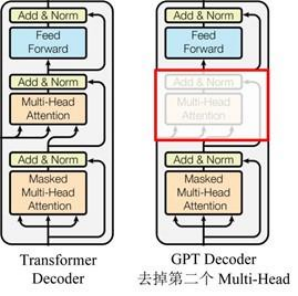
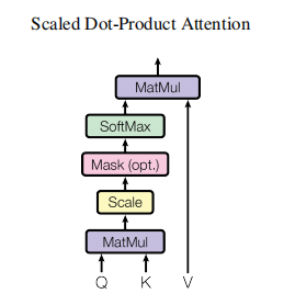
GPT はTransformerの Decoder 構造を使用し、Transformer Decoder にいくつかの変更を加えます. 元の Decoder には 2 つの Multi-Head Attention 構造が含まれており、GPT は Mask Multi-Head Attention のみを保持します (下図を参照)。
(デコーダーのマスク機構を利用しているため、デコーダーの構造に似ているというデータが多いのですが、それ以外は実際にはエンコーダーに近い感じがするので、エンコーダーを調整して実装する場合もあります。 Python GPT 実装コードを気にしないでください)
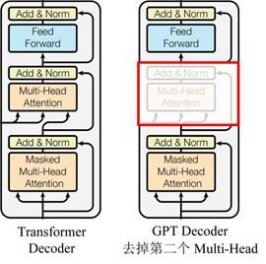
純正トランスの構造との比較
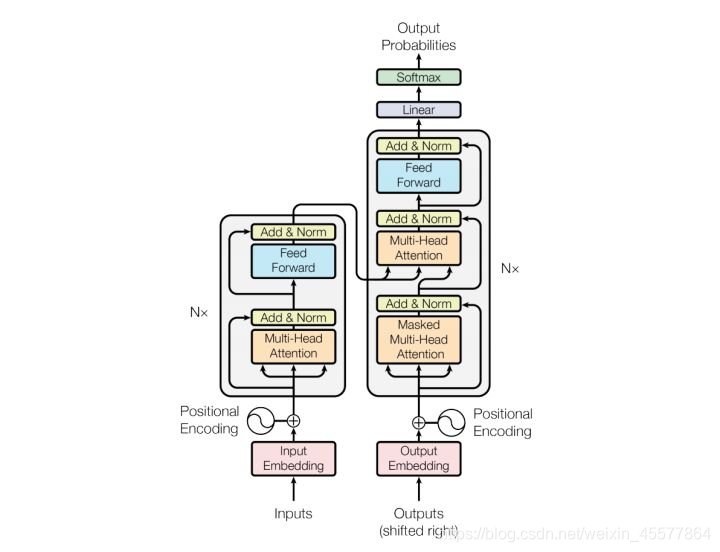
ステージ説明
事前トレーニング段階:



事前トレーニング段階はテキスト予測、つまり、既存の歴史的な単語に基づいて現在の単語を予測する. 3 つの式 7-2、7-3、および 7-4 は、以前の GPT 構造図に対応し、出力 P (x) が出力であり、各単語が予測される確率であり、7-1 式を使用して最尤関数を計算し、これに基づいて損失関数を構築する、つまり言語モデルを最適化できます。
下流タスクの微調整段階

損失関数
下流のタスクと上流のタスクの損失の線形結合

計算プロセス:
- 入力
- 埋め込み
- 多層トランスブロック
- 2 つの出力結果を取得する
- 損失を計算する
- 誤差逆伝播法
- パラメータの更新
具体的な GPT のコード例:
GPT モデルの forward 関数では、最初に Embedding 操作が実行され、次に 12 層トランスフォーマーのブロックで操作が実行され、最終的な計算値が次の方法で取得されることがわかります。 2 つの線形変換 (テキスト予測用に 1 つ、タスク分類子用に 1 つ)、コードは最初に示したモデル構造図と一致しています。参考: PythonのGPT実装コードは
気にしないで計算ステップ2と3に注目しましょう
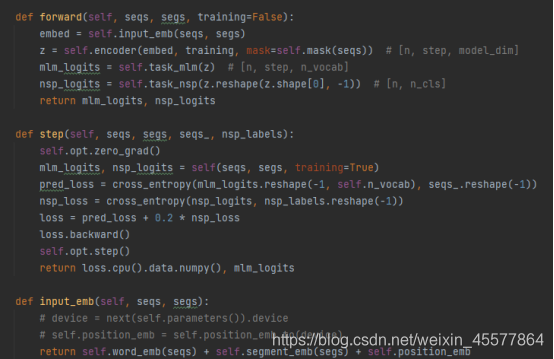
計算の詳細:
[埋め込みレイヤー]:
テーブル ルックアップ操作の埋め込み層
は、1 つのホットが入力として、中間層ノードが単語ベクトルの次元として含まれる全結合層です。そして、この全結合層のパラメータが「ワードベクトルテーブル」です。

one hot 型の行列乗算は表引きに相当するため、行列に書き込んで計算するのではなく、表引きをそのまま演算として使用するため、計算量が大幅に削減されます。計算量の削減は単語ベクトルの出現によるものではなく、1 つのホット マトリックス演算がテーブル ルックアップ演算に単純化されたためであることを再度強調します。
[GPT のトランスに似たデコーダ層]:
各デコーダ層には 2 つのサブ層が含まれます
- sublayer1: マスク用のマルチヘッド アテンション レイヤー
- sublayer2: ffn (フィードフォワード ネットワーク) フィードフォワード ネットワーク (多層パーセプトロン)
sublayer1: マスクのマルチヘッド アテンション レイヤー
输入:q, k, v, mask
计算注意力:Linear (行列乗算)→Scaled Dot-Product Attention→Concat (複数の注意結果、変形)→Linear(行列乗算)
残差连接和归一化操作:ドロップアウト操作 → 残留接続 → レイヤーの正規化操作
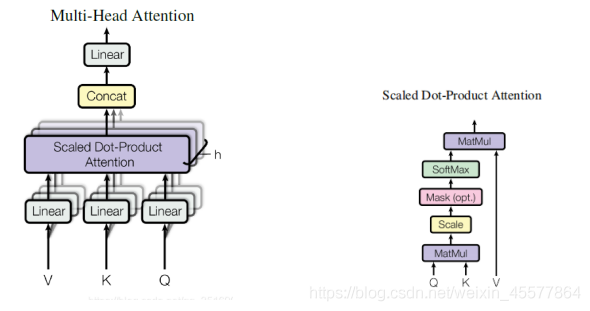
計算プロセス:
次の段落では、注意を計算する全体的なプロセスについて説明します。

爆発の指示:
マスク多頭注意
1. 行列の乗算:
入力q、k、vを変換します
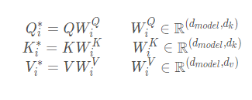
2.スケーリングされた内積の注意
主なものは注意の計算とマスクの操作を実行することです.
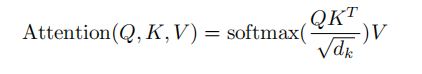
マスク操作: masked_fill_(mask, value)
マスク操作は、マスクの値 1 に対応するテンソルの要素を値で埋めます. マスクの形状は、塗りつぶされるテンソルの形状と一致する必要があります。(ここでは、-inf パディングが使用されているため、softmax は 0 になります。これは、次の単語が表示されないことと同じです)
トランスフォーマーでのマスク操作
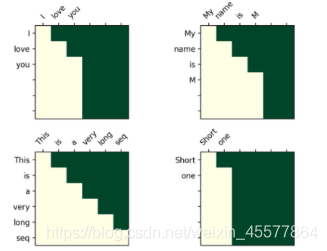
マスク後の視覚化マトリックス:
直感的な理解では、各単語はその前の単語しか見ることができません (目的は未来の単語を予測することであるため、表示されている場合は予測する必要はありません)
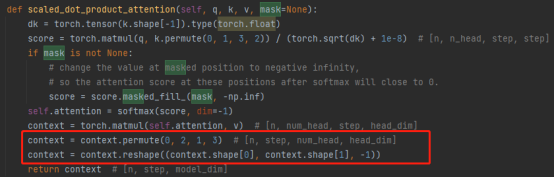
3. 連結操作:
複数のアテンション ヘッドの結果を組み合わせると、実際に行列が変換されます。並べ替え、変形操作、および次元削減です。(下図赤枠内)
4. 行列乗算: 注意の結果を線形に変換する線形レイヤー
マスク全体のマルチヘッド注意層代码:
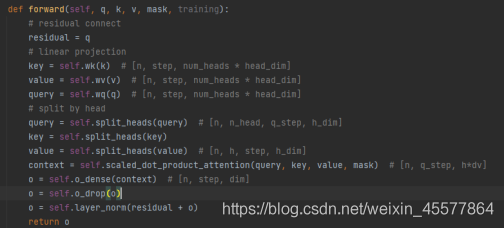
注: 上記のコードの次の行は、残差连接和归一化操作
注意結果のプロセスを説明するためのものです。
残りの接続と正規化操作:
5.ドロップアウトレイヤー
6. 行列の追加
7.レイヤーの正規化
バッチ正規化は、異なるトレーニング データ間で単一のニューロンを正規化することであり、レイヤー正規化は、特定のレイヤーのすべてのニューロン間で単一のトレーニング データを正規化することです。
入力正規化、バッチ正規化 (BN)、レイヤー正規化 (LN)
代码展示:
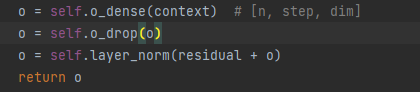
sublayer2: ffn (フィードフォワード ネットワーク) フィードフォワード ネットワーク
1. 線形層 (行列乗算)
2.Relu機能発動
3. 線形層 (行列乗算)
4.ドロップアウト操作
5.レイヤーの正規化
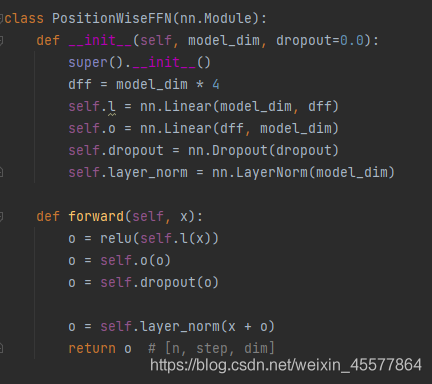
[線形レイヤー]:
多層ブロックの出力結果は、変換のために 2 つの線形層に入れられます。これは比較的単純であり、詳細には説明しません。
補足:注目層フロー図
参考文献
1. 参考文献: Radford et al. "Improving Language Undersatnding by Generative Pre-Training"
2. 参考書: "Natural Language Processing Based on Pre-training Model Method" Che Wanxiang、Guo Jiang、Cui Yiming
3.この記事のコード : Python GPT 実装コードを気にしないでください
4. その他の参照リンク (ブログ投稿で言及されている部分):
単語埋め込み計算プロセス分析
Transformer の行列次元分析とマスクの詳細な説明