접두사 조정: 생성을 위한 연속 프롬프트 최적화

기사 디렉토리
컨퍼런스: ACL2021
작업: 자연어 생성
소스 코드: 링크
원본: 링크
추상적인
본 논문은 언어 모델의 매개변수를 고정하고 대신 접두사라고 하는 일련의 연속 작업별(작업별) 벡터를 최적화하는 미세 조정을 대체할 수 있는 NLG 작업을 위한 경량 방법인 Prefix-Tuning을 제안합니다. 접두사 미세 조정은 힌트 학습에서 영감을 얻어 가상 단어인 것처럼 이 접두사에 주의를 기울이도록 후속 토큰을 안내합니다. 이 문서는 접두사 미세 조정을 사용하고 테이블-텍스트 작업에 GPT-2를 사용하며 텍스트 요약 작업에 BART를 사용합니다. 실험 결과는 단 0.1%의 매개변수 수정으로 접두사 조정이 전체 데이터 세트에서 비슷한 성능을 달성하고 데이터 세트가 적은 조건에서 미세 조정보다 성능이 우수하며 훈련 중에 발견되지 않은 오류에 대해 더 나은 외삽을 수행한다는 것을 보여줍니다.
동기 부여
-
미세 조정은 비용이 많이 드는 전체 LM의 매개변수를 업데이트하고 저장해야 합니다.
-
GPT3는 어떠한 파라미터도 업데이트하지 않는 프롬프트 형태의 상황 내 학습(in-context learning)을 제안하지만, 트랜스포머는 제한된 길이(예: GPT3의 최대 길이는 2048 토큰)가 있는 컨텍스트에만 기반할 수 있기 때문에 온라인 학습은 아주 작은 훈련 세트.
-
접두사: 입력 앞에 추가할 작업별 연속 벡터 시퀀스입니다. 프롬프트와 달리 접두어는 전적으로 자유 매개변수로 구성되며 실제 단어와 관련이 없습니다.
-
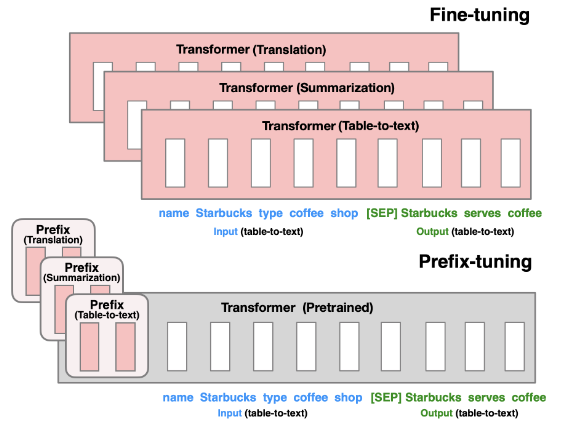
미세 조정 대 접두사 조정: 미세 조정은 모든 LM 매개변수를 업데이트하므로 각 작업에 대해 저장할 미세 조정 모델 매개변수의 사본이 필요합니다. 접두사 조정은 접두사만 최적화합니다. 따라서 우리는 하나의 LM 사본과 하나의 학습된 작업별 접두사만 저장하면 되므로 각 추가 작업에 대한 오버헤드가 거의 발생하지 않습니다. 작은 매개변수 집합만 있습니다. 핵심 질문은 LM 구조를 어떻게 보강하고 사전 훈련된 매개변수의 하위 집합을 조정해야 하는지 결정하는 것입니다 .
-
미세 조정과 비교하여 접두사 조정도 모듈화할 수 있습니다. 언어 모델을 안내하기 위해 다운스트림 접두사를 훈련하므로 단일 LM이 동시에 여러 작업을 지원할 수 있습니다. 또한 접두사 기반 아키텍처를 사용하면 다른 경량 미세 조정 방법(어댑터 조정)으로는 불가능한 단일 배치에서 여러 사용자/작업의 예제를 처리할 수 있습니다.
주요 아이디어
그림과 같이 hij h_i^{j}시간나ji번째 시간 단계에서 모델의 j번째 레이어의 숨겨진 벡터를 나타냅니다.

직관
프롬프트는 매개 변수를 업데이트하지 않고 적절한 컨텍스트를 기반으로 언어 모델을 부트스트랩할 수 있음을 나타냅니다. 예를 들어, LM이 단어(예: Obama)를 생성하도록 하려면 공통 배치를 컨텍스트(예: Barack)로 미리 설정할 수 있으며 LM은 원하는 단어에 더 큰 확률을 할당합니다. 단일 단어나 문장을 생성하는 것 이상으로 이 직관을 확장하여 LM이 NLG 작업을 해결하도록 안내하는 컨텍스트를 찾을 수 있기를 바랍니다 . 직관적으로 컨텍스트는 x에서 무엇을 추출할지 안내하여 작업 입력 x의 인코딩에 영향을 미치고 다음 단어 분포를 안내하여 작업 출력 y의 생성에 영향을 줄 수 있습니다. 그러나 그러한 컨텍스트가 존재하는지 여부는 즉각적으로 명확하고 직관적이지 않습니다. 자연 언어 작업 지침을 가이드 컨텍스트로 직접 사용하는 것은 중간 규모의 모델에는 효과적이지 않습니다(이 백서의 실험에서는 GPT3에는 효과적이지만 GPT2 및 BART에는 효과적이지 않음이 밝혀졌습니다). 불연속 명령어에 대한 최적화가 도움이 될 수 있지만 불연속 최적화는 계산적으로 까다롭습니다.
문맥 지침을 연속적인 단어 임베딩으로 처리하여 최적화할 것을 제안합니다. 이는 변환기의 활성화 계층까지 전파되고 후속 단어로 바로 전파될 수 있습니다 . 이것은 콘텐츠 단어 임베딩으로 제한된 개별 단서보다 훨씬 더 표현력이 뛰어납니다. Prefix-tuning은 레이어를 포함하는 것뿐만 아니라 모든 레이어의 활성화를 최적화하여 표현력을 향상시키는 데 한 단계 더 나아갑니다. 또한 Prefix-tuning은 네트워크에서 더 깊은 표현을 직접 수정할 수 있으므로 네트워크 깊이에서 긴 계산 경로를 피할 수 있습니다.
방법
자동 회귀 LM의 경우 입력 앞에 접두사를 직접 연결합니다. 즉, z = [ PREFIX ; x ; y ] z = [PREFIX; x; y]지=[ 기본 설정 X ;x ;y ] ; 인코더-디코더 LM의 경우 인코더와 디코더 모두 앞에 접두사가 붙습니다. 즉,z = [ PREFIX ; x ; PREFIX ' ; y ] z = [PREFIX; x; PREFIX'; y]지=[ 기본 설정 X ;x ;PREF IX ' ; _y ] .∣ Pidx ∣ |P_{idx}|∣ 피나는 x _∣ 는 접두사 길이P idx P_{idx}를피나는 x _접두사 인덱스를 나타냅니다. 피θ피_θ피나훈련할 수 있는 프리픽스 프리 파라미터, 크기는 ∣ P idx ∣ × dim ( hi ) |P_{idx}| × dim(h_i)∣ 피나는 x _∣×디엠 ( 시간 _나)。
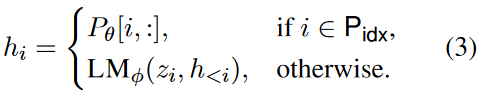
当i ∈ P idxi ∈ P_{idx}나∈피나는 x _, P θ P_θ 에서 직접피나매개변수를 hi h_i 에 복사시간나, 반대로 hi h_i시간나또한 P θ P_θ 에 따라 달라집니다.피나, 접두사는 항상 왼쪽의 컨텍스트이기 때문에 오른쪽의 숨겨진 상태에 영향을 미칩니다.
본질적으로 각 레이어의 각 토큰의 K 및 V 벡터 앞에 Prefix 벡터를 실제로 접합하는 것입니다.인터넷에서 찾은 두 장의 사진이 이를 명확하게 설명합니다.


매개변수화
저자는 예비 실험에서 접두사의 직접 최적화가 초기화에 매우 민감하다는 것을 발견했습니다. 따라서 이 매개변수 행렬을 직접 업데이트하면 최적화가 불안정해지고 성능이 약간 저하됩니다. 따라서 행렬 P' θ P'_θ를 통해피 '나재매개변수화를 위해 행렬은 대규모 정방향 전파 신경망으로 구성됩니다. P θ [ i , : ] = MLP θ ( P ′ θ [ i , : ] ) P_θ[i, :] = MLP_θ(P ′ _θ[i, :])피나[ 나는 ,:]=MLP _ _나( 피 ′나[ 나는 ,:]) . 그런 다음 훈련 가능한 매개변수에는P θ ′ P'_θ가피나′와 MLP θ MLP_θMLP _ _나. 학습이 완료되면 재매개변수화 매개변수를 제거할 수 있으며 접두사 매개변수 P θ P_θ 만피나저장해야합니다. P θ P_θ피나和Pθ' P'_θ피나′동일한 수의 행(즉, 접두사 길이)을 가집니다.
실험
테이블-텍스트
GPT-2-medium 및 GPT2-large를 사용하면 비용 절감 및 효율성 향상이 반영됩니다. 작업별 매개변수의 0.1%만 업데이트하면 성능이 경량 미세 조정을 능가하며 기본적으로 전체 미세 조정과 동일합니다. 또한 DART 데이터 세트에서 우수한 성능을 달성하면 접두사 튜닝이 도메인이 다르고 관계가 많은 테이블로 일반화될 수 있음을 알 수 있습니다. 그리고 규모가 확장되어도 성능이 유지될 수 있어 Prefix 튜닝이 대형 모델로 확장될 수 있음을 나타냅니다.
요약
BART-large, %2 매개변수를 사용하면 table-to-text에 비해 데이터 세트가 크고 문장이 길고 작업이 더 복잡하기 때문에 전체 미세 조정보다 성능이 약간 낮습니다.
낮은 데이터 설정
퓨샷 학습과 유사하게 리소스가 적은 시나리오에서 접두사 조정은 미세 조정보다 성능이 우수하고 더 적은 매개변수가 필요하지만 데이터 세트의 크기가 커짐에 따라 격차가 줄어듭니다.
외삽법
제로샷 학습과 유사하게 이 실험은 알려지지 않은 주제에 대한 Prefix-tuning의 효과를 검증하는 데 사용됩니다. 실험 결과 두 작업의 모든 지표에서 접두사 조정이 미세 조정보다 우수한 것으로 나타났습니다. 그리고 실험 결과 어댑터 튜닝이 상대적으로 Prefix 튜닝과 동등한 더 나은 성능을 달성했으며, 이는 LM의 매개변수를 유지하는 것이 외삽에 긍정적인 영향을 미친다는 것을 보여줍니다.
본질적인 평가
접두사 길이
접두어가 길수록 훈련 가능한 매개변수가 많다는 것을 의미하며, 실험 결과 접두어 길이가 증가할수록 모델의 성능이 증가하고 특정 임계값에서 감소하기 시작합니다. 임계값보다 크면 훈련 손실이 낮아지고 테스트 세트의 성능이 약간 감소하여 과적합을 나타냅니다.
.
전체 대 임베딩 전용
임베딩 전용: 단어 임베딩 레이어는 자유 매개변수이며 나머지는 변환기에 의해 계산됩니다.
표현력: 불연속 프롬팅 < 임베딩만 < 프리픽스 튜닝.
접두사 조정 대 중위 조정
중위 조정은 x와 y 사이에 벡터를 배치하는 것을 말합니다. 즉 [x; INFIX; y]) [x; INFIX; y])[ 엑스 ;INFIX ; _ _ _와이 ]) . 실험 결과는 중위 튜닝 성능이 접두사 튜닝보다 약간 낮다는 것을 보여줍니다. 왜냐하면 접두사는 x와 y의 활성화에 영향을 미칠 수 있는 반면 중위는 y에만 영향을 미칠 수 있기 때문입니다.
초기화
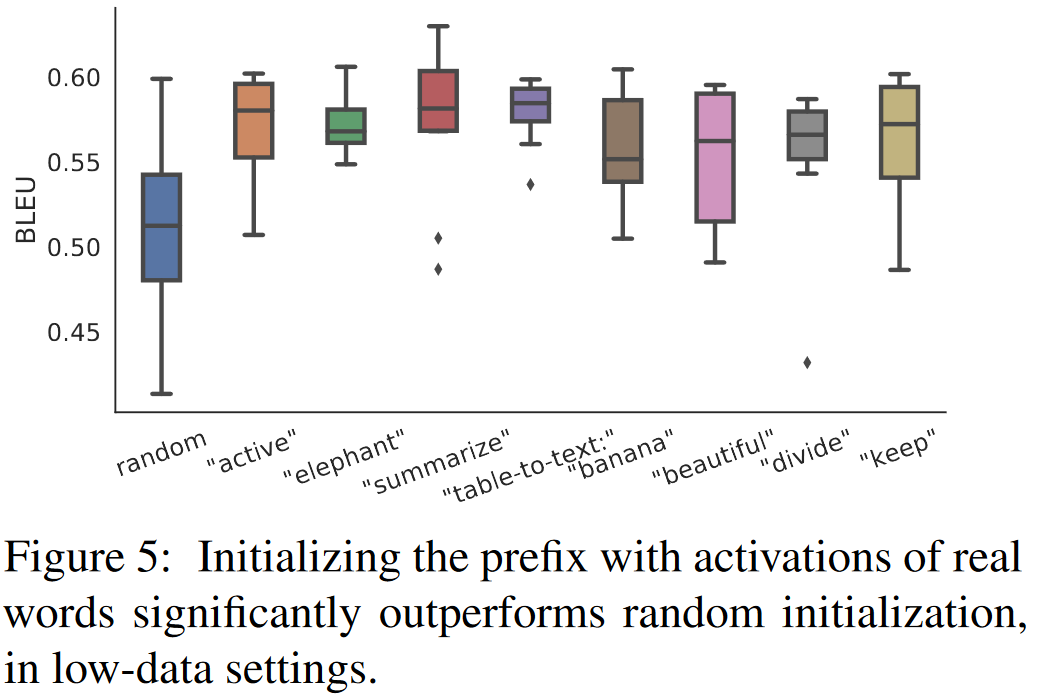
이 기사에서는 접두사를 초기화하는 방법이 리소스가 적은 시나리오에서 모델 성능에 큰 영향을 미치고 무작위 초기화는 높은 분산으로 낮은 성능으로 이어진다는 것을 발견했습니다. 접두사를 실제 단어로 초기화하면 생성이 크게 향상되고 작업 관련 실제 단어로 초기화하면 관련 없는 단어보다 성능이 높아지지만 여전히 실제 단어를 사용하는 것이 임의 초기화보다 낫습니다.
또한 전체 데이터 시나리오에서는 초기화 트릭이 효과가 없으며 무작위 초기화가 평균 성능을 달성합니다.
우리는 접두사를 초기화하기 위해 LM에 의해 계산된 실제 단어 활성화를 사용하기 때문에 이 초기화 전략은 접두사 조정의 아이디어를 따릅니다. 사전 훈련된 LM을 최대한 보존합니다.
데이터 효율성
데이터 양이 20% 이상일 때 프리픽스 튜닝이 파인 튜닝보다 성능이 좋고, 데이터 크기가 10%일 때 저자원에서 성능 향상을 위해 초기화 트릭이 필요하다. 시나리오.
논의
접두사 조정은 개인 정보 보호와 같은 많은 수의 독립적인 작업 시나리오에 적합합니다. 접두사 조정을 통해 서로 다른 접두사 지원이 있는 경우에도 다른 사용자의 쿼리를 일괄 처리할 수 있습니다. 일괄 처리의 이점은 또한 각 사용자가 미리 설정된 접두사를 입력할 때 동일한 작업에 대해 훈련된 여러 접두사의 효율적인 앙상블을 만드는 데 도움이 될 수 있습니다.
대형 LM은 범용 말뭉치에 대해 교육을 받고 매개변수를 저장하면 알 수 없는 도메인으로 일반화하는 데 도움이 됩니다.
또한 접두사 조정은 비슷한 성능을 유지하면서 어댑터 조정보다 훨씬 적은 수의 매개변수를 필요로 합니다. 이는 "매개변수 효율성"의 이점을 얻을 수 있습니다. 접두사 조정은 LM의 매개변수를 가능한 고정된 상태로 유지하므로 LM을 보다 효율적으로 발견할 수 있습니다 . 여기서 개인적인 이해는 Prefix가 Adapter-tuning보다 더 유용한 매개변수를 학습할 수 있음을 의미합니다.