목차
머리말:
이전 블로그에서 우리는 이미 "Heap"에 대한 예비 개념을 갖고 있었고, "Heap"을 사용하여 일상 생활의 문제를 해결할 수 있습니다. 이 기사에서는 각각 일반적으로 사용되는 두 가지 응용 프로그램 시나리오를 제공합니다. 그것은 "Sort"입니다. " 및 "Top-k 문제". 이전 블로그는 "Heap"의 시뮬레이션 구현 에 있습니다. -CSDN 블로그
"힙 정렬" 정보:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
void swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
void AdjustDown(int* arr, int sz, int parent)
{
int child = parent * 2 + 1;
while (child < sz)
{
if (child + 1 < sz && arr[child] < arr[child + 1])
{
child++;
}
if (arr[child] > arr[parent])
{
swap(&arr[child], &arr[parent]);
parent = child;
child = 2 * parent + 1;
}
else
{
break;
}
}
}
void AdjustUp(int* arr, int sz, int child)
{
while (child > 0)
{
int parent = (child - 1) / 2;
if (arr[parent] < arr[child])
{
swap(&arr[parent], &arr[child]);
}
child = parent;
}
}
int main()
{
int arr[] = { 2, 6, 9, 3, 1, 7 };
int sz = sizeof(arr) / sizeof(arr[0]);
for (int i = (sz - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(arr, sz, i);
}//向下调整算法
//for (int i = 1; i<sz; i++)
//{
// AdjustUp(arr, sz, i);
//}//向上调整算法
int end = sz - 1;
while (end > 0)
{
swap(&arr[0], &arr[end]);
AdjustDown(arr, end, 0);
--end;
}
return 0;
}1단계: 더미 쌓기
"힙"을 사용하면 주어진 비순차적 배열을 쉽게 정렬할 수 있습니다. 먼저 정렬 작업을 위해 큰 힙을 선택해야 합니다.
힙을 구축하기 위해 작은 힙을 사용하는 것을 선택하면 어떨까요?
이전 블로그의 "Heap"에 대한 설명에 따르면, 작은 힙은 최상위 요소가 가장 작은 요소이고, 다른 노드의 개수가 첫 번째 요소보다 적다는 것을 의미합니다. 다음으로 가장 작은 요소를 찾으려면 나머지 요소들 사이에 힙을 만들고 이 사이클을 반복하여 정렬을 완료해야 합니다. 이는 시간 복잡도가 높아 정렬에 도움이 되지 않습니다.
따라서 우리는 큰 힙을 사용하여 힙을 구축하기로 결정했으며, 큰 힙을 구현한 후 첫 번째와 마지막 요소를 교환한 다음 하향 조정 방법을 사용하여 나머지 n-1개의 요소를 조정한 후 교환합니다. 정렬을 달성할 수 있습니다.
int arr[] = { 2, 6, 9, 3, 1, 7 };
int sz = sizeof(arr) / sizeof(arr[0]);
for (int i = 1; i<sz; i++)
{
AdjustUp(arr, sz, i);
}힙을 구축하려면 위 그림과 같이 배열을 조정하십시오.

2단계: 정렬
먼저 첫 번째 요소와 마지막 요소를 바꿉니다.
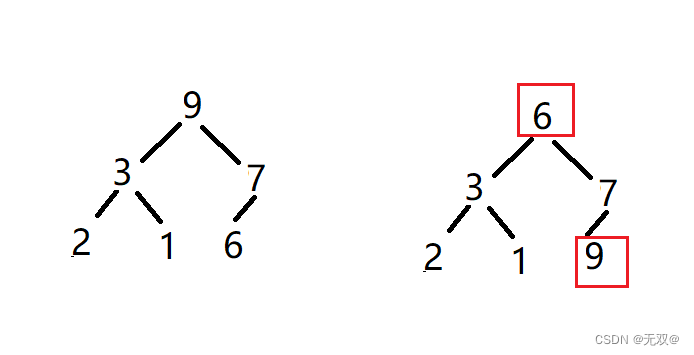
큰 파일로 계속 이어가려면 마지막 요소를 제외한 모든 요소를 아래쪽으로 조정하세요.


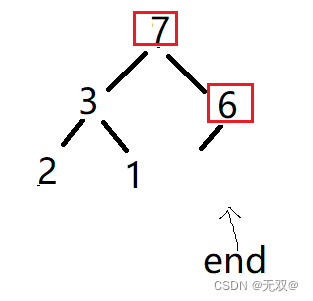
위 단계를 반복하세요.
최종 힙은 다음과 같습니다.

이것으로 힙 정렬이 완료됩니다.
"탑케이 문제"
Top-k 질문에 관하여:
즉, 데이터 조합에서 처음 K개의 가장 큰 요소 또는 가장 작은 요소를 찾는 것입니다. 일반적으로 데이터의 양이 상대적으로 많습니다 .
예: 상위 10명의 전문가, Fortune 500대 기업, 부자 목록, 게임 내 활성 플레이어 상위 100명 등 설명하기 위해 n 데이터에서 처음 K개의 가장 큰 요소를 찾는 예를 들어보겠습니다. (n=10000으로 가정) (k=10으로 가정)
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
const char* file = "data.txt";
void swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
void AdjustDown(int* arr, int sz, int parent)
{
int child = 2 * parent + 1;
while (child < sz)
{
if (child + 1 < sz && arr[child + 1] < arr[child])
{
child++;
}
if (arr[child] < arr[parent])
{
swap(&arr[child], &arr[parent]);
parent = child;
child = 2 * parent + 1;
}
else
{
break;
}
}
}
void CreateFile()
{
//创建随机数的种子
srand((unsigned int)time(NULL));
FILE* Fin = fopen(file, "w");
if (Fin == NULL)
{
perror("Fopen error");
exit(-1);
}
int n = 10000000;
for (int i = 0; i < n; i++)
{
int x = (rand() + i) % n;
fprintf(Fin, "%d\n", x);
}
fclose(Fin);
Fin = NULL;
}
void Print()
{
FILE* Fout = fopen(file, "r");
if (Fout == NULL)
{
perror("Fout error");
exit(-1);
}
//取前k个数进小堆
int* minheap = (int*)malloc(sizeof(int) * 5);
if (minheap == NULL)
{
perror("minheap -> malloc");
return;
}
for (int i = 0; i < 5; i++)
{
fscanf(Fout, "%d", &minheap[i]);
}
for (int i = (5-1-1)/2; i >=0; --i)
{
AdjustDown(minheap, 5, i);
}
//读取数据
int x = 0;
while (fscanf(Fout, "%d", &x) != EOF)
{
if (minheap[0] < x)
{
minheap[0] = x;
}
AdjustDown(minheap, 5, 0);
}
for (int i = 0; i < 5; i++)
{
printf("%d ", minheap[i]);
}
fclose(Fout);
Fout = NULL;
}
int main()
{
//CreateFile();
Print();
return 0;
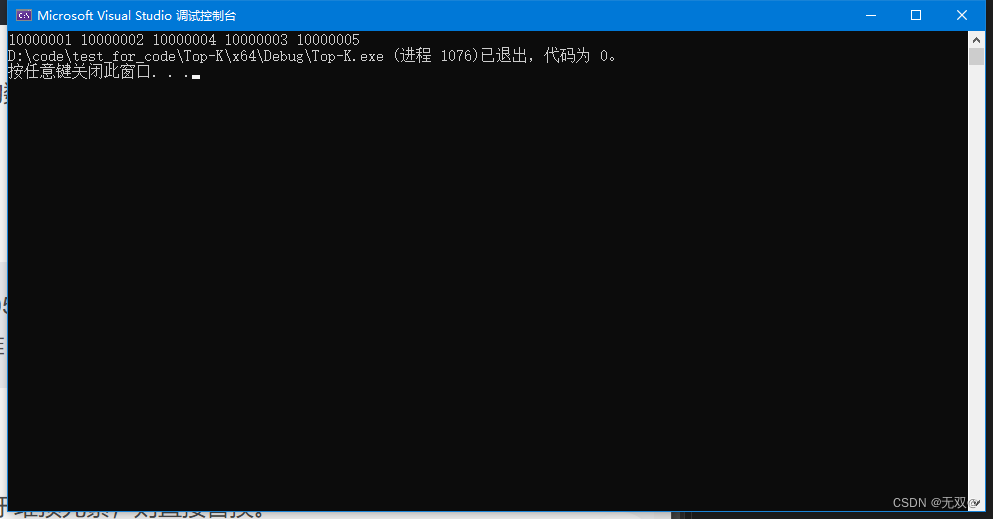
}먼저 10000000개의 난수를 생성한 후 숫자를 수정하고 무작위로 5개의 숫자를 선택하여 다음과 같이 수정합니다.
10000001,10000002,10000003,10000004,10000005
또 다른 작은 더미를 쌓으세요 . 이것은 작은 더미여야 한다는 점에 유의하세요!
큰 힙을 구축할 때 데이터를 먼저 검색해서 10000005가 나오면 그 숫자가 힙의 맨 위에 있어야 하고, 다음으로 작은 숫자를 찾으면 힙에 들어갈 수 없기 때문에 작은 힙을 사용합니다. !
그런 다음 데이터의 처음 5개 요소를 작은 힙에 넣습니다.
그런 다음 나머지 9999995개 숫자를 순회하여 비교하고, 힙의 최상위 요소보다 큰 경우 직접 교체합니다.
교체 후 다시 아래쪽으로 조정하면 전체 데이터를 순회한 후 힙이 삽입됩니다.
10000001,10000002,10000003,10000004,10000005