
읽기 및 쓰기 프로세스, 복사 일관성 메커니즘, 저장 메커니즘, 고가용성 메커니즘 등에 대한 Apache Doris의 일반적인 질문을 기반으로 정리하여 질문과 답변 형식으로 답변합니다. 시작하기 전에 먼저 이 기사와 관련된 용어를 설명 하겠습니다.
-
FE : Frontend, Doris의 프런트엔드 노드입니다. 클라이언트 요청, 메타데이터, 클러스터 관리, 쿼리 계획 생성 등을 수신하고 반환하는 일을 주로 담당합니다.
-
BE : Doris의 백엔드 노드인 Backend. 데이터 저장 및 관리, 쿼리 계획 실행 등을 주로 담당합니다.
-
BDBJE : Oracle Berkeley DB Java Edition Doris에서 BDBJE는 메타데이터 작업 로그의 지속성, FE 고가용성 및 기타 기능을 완료하는 데 사용됩니다.
-
태블릿(Tablet) : 태블릿은 테이블의 실제 물리적 저장 단위로, BE가 파티션과 버킷별로 구성한 분산 저장 계층에 태블릿 단위로 테이블이 저장되며, 각 태블릿에는 메타 정보와 여러 연속된 RowSet이 포함된다.
-
RowSet : RowSet은 Tablet의 데이터 변경에 대한 데이터 모음으로, 데이터 변경에는 데이터 가져오기, 삭제, 업데이트 등이 포함됩니다. RowSet은 버전 정보별로 기록합니다. 각 변경사항은 버전을 생성합니다.
-
Version : Start, End 두 가지 속성으로 구성되며, 데이터 변경에 대한 기록 정보를 유지합니다. 일반적으로 RowSet의 버전 범위를 나타내는 데 사용됩니다. 새 가져오기 후에는 Start와 End가 동일한 RowSet이 생성됩니다. 압축 후에는 범위가 지정된 RowSet 버전이 생성됩니다.
-
Segment : RowSet의 데이터 세그먼트를 나타내며 여러 세그먼트가 RowSet을 구성합니다.
-
Compaction : RowSet의 연속 버전을 병합하는 프로세스를 Compaction이라고 하며 병합 프로세스 중에 데이터가 압축됩니다.
-
Key 컬럼, Value 컬럼 : Doris에서는 데이터를 테이블 형태로 논리적으로 기술합니다. 테이블은 행(Row)과 열(Column)을 포함하며, 행은 사용자 데이터의 행이고, 열은 데이터 행의 다양한 필드를 설명하는 데 사용됩니다. 열은 키와 값의 두 가지 범주로 나눌 수 있습니다. 비즈니스 관점에서 키와 값은 각각 차원 열과 표시기 열에 해당할 수 있습니다. Doris의 Key 컬럼은 테이블 생성문에서 지정한 컬럼으로, 테이블 생성문에서 키워드 고유키, 집계키, 중복키 뒤에 오는 컬럼이 Key 컬럼이고, Key 컬럼 외에 나머지는 Value이다. 열.
-
데이터 모델 : Doris의 데이터 모델은 크게 Aggregate, Unique, Duplicate의 세 가지 범주로 구분됩니다.
-
베이스 테이블(Base table) : Doris에서는 사용자가 테이블 생성문을 통해 생성한 테이블을 베이스 테이블(Base Table)이라고 하며, 베이스 테이블에는 사용자의 테이블 생성문에서 지정한 방식으로 저장된 기본 데이터가 저장된다.
-
ROLLUP 테이블 : 기본 테이블 위에 사용자는 ROLLUP 테이블을 원하는 만큼 생성할 수 있습니다. 이러한 ROLLUP 데이터는 기본 테이블을 기반으로 생성되며 물리적으로 독립적으로 저장됩니다. ROLLUP 테이블의 기본 기능은 구체화된 뷰와 유사하게 기본 테이블을 기반으로 대략적인 집계 데이터를 얻는 것입니다.
Q1: Doris 파티셔닝과 버킷팅의 차이점은 무엇입니까?
Doris는 두 가지 수준의 데이터 분할을 지원합니다.
-
첫 번째 레이어는 Range 및 List 분할 방법을 지원하는 Partition입니다(MySQL의 파티션 테이블 개념과 유사). 여러 개의 파티션이 하나의 테이블을 형성하며, 파티션은 가장 작은 논리적 관리 단위라고 볼 수 있습니다. 하나의 파티션에 대해서만 데이터를 가져오고 삭제할 수 있습니다.
-
두 번째 레이어는 Bucket(태블릿은 버킷팅이라고도 함)으로 Hash 및 Random 분할 방법을 지원합니다. 각 태블릿에는 여러 행의 데이터가 포함되어 있으며 태블릿 간의 데이터는 교차점이 없으며 물리적으로 독립적으로 저장됩니다. 태블릿은 데이터 이동, 복사 등의 작업을 위한 가장 작은 물리적 저장 장치입니다.
한 가지 수준의 파티셔닝만 사용할 수도 있습니다. 테이블을 생성할 때 파티셔닝 문을 작성하지 않으면 Doris는 사용자에게 투명한 기본 파티션을 생성합니다.
표시는 다음과 같습니다.
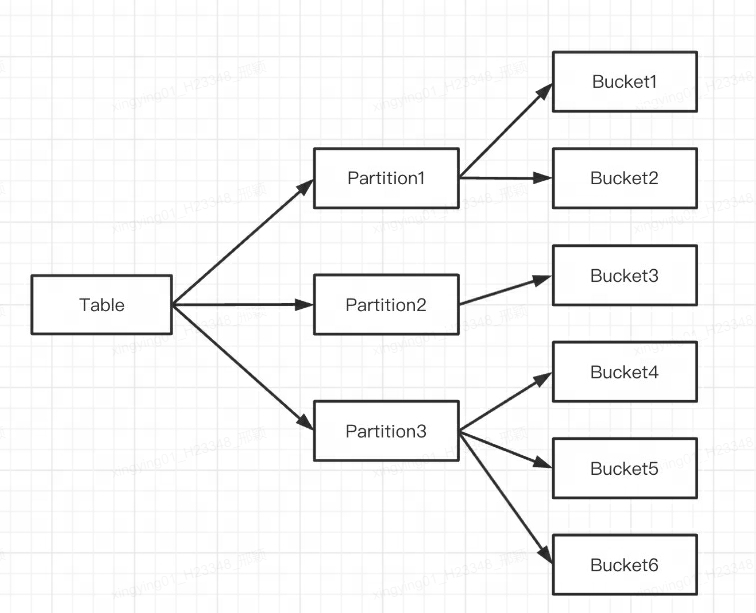
여러 태블릿은 논리적으로 서로 다른 파티션 (파티션) 에 속합니다 . 하나의 태블릿은 하나의 파티션에만 속하고 하나의 파티션에는 여러 태블릿이 포함됩니다. 태블릿은 물리적으로 독립적으로 저장되기 때문에 파티션도 물리적으로 독립적이라고 볼 수 있습니다.
논리적으로 말하면, 분할과 버킷팅의 가장 큰 차이점은 버킷팅은 데이터베이스를 무작위로 분할하는 반면, 분할은 데이터베이스를 무작위로 분할하지 않는다는 것입니다.
여러 데이터 사본을 확보하는 방법은 무엇입니까?
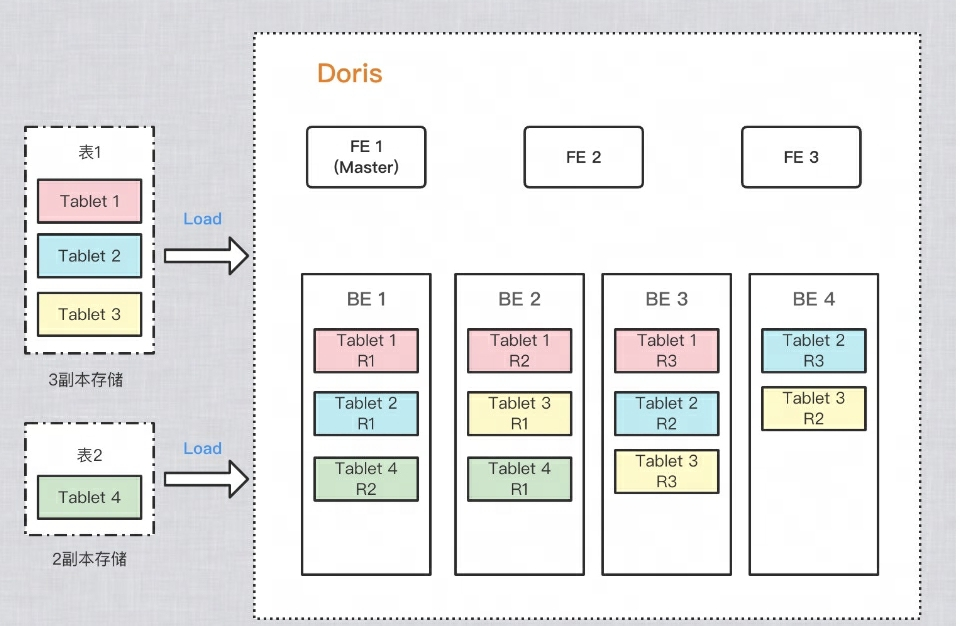
데이터 저장의 신뢰성과 계산 성능을 향상시키기 위해 Doris는 각 테이블의 복사본을 여러 개 만들어 저장합니다. 각 데이터 복사본을 복사본이라고 합니다. Doris는 태블릿을 데이터 복사본을 저장하는 기본 단위로 사용하며, 기본적으로 샤드에는 3개의 복사본이 있습니다. 테이블을 생성할 때 PROPERTIES다음 위치에서 복사본 수를 설정할 수 있습니다.
PROPERTIES
(
"replication_num" = "3"
);
아래 그림의 예를 들면, 두 개의 테이블을 각각 Doris로 임포트하는데, 테이블 1은 임포트 후 3개의 사본에 저장되고, 테이블 2는 임포트 후 2개의 사본에 저장됩니다. 데이터 분포는 다음과 같습니다.
Q2: 버킷팅이 필요한 이유는 무엇입니까?
버킷을 줄이고 데이터 왜곡을 방지하고 읽기 IO를 분산하고 쿼리 성능을 향상시키기 위해 태블릿의 여러 복사본을 여러 컴퓨터에 분산할 수 있으므로 쿼리 중에 여러 컴퓨터의 IO 성능을 완전히 활용할 수 있습니다.
Q3: 물리적 파일의 저장 구조와 형식은 무엇입니까?
Doris의 각 가져오기는 트랜잭션으로 간주될 수 있으며 RowSet이 생성됩니다. 그리고 RowSet에는 여러 세그먼트, 즉 Tablet-->Rowset-->Segment. 그렇다면 BE는 이러한 파일을 어떻게 저장합니까?
도리스의 저장구조
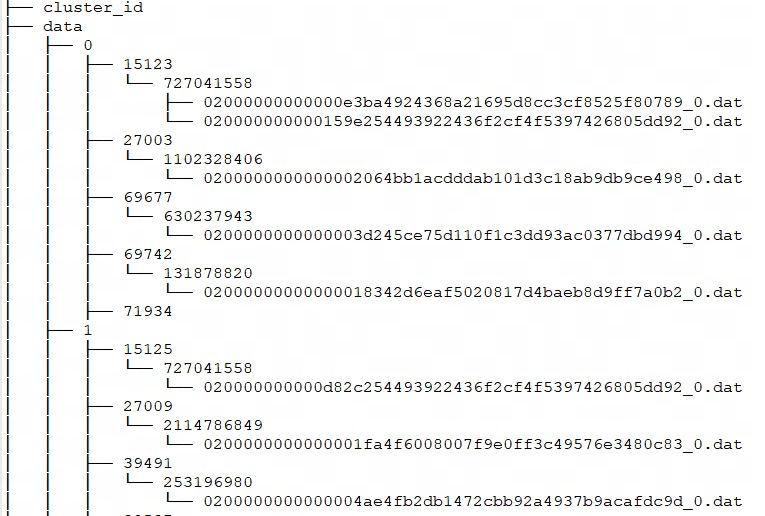
Doris는 를 storage_root_path통해 저장 경로를 구성하고, Segment 파일은 tablet_id해당 디렉토리에 저장되어 SchemaHash에 의해 관리됩니다. 여러 개의 세그먼트 파일이 있을 수 있으며 일반적으로 크기에 따라 구분되며 기본값은 256MB입니다. 저장소 디렉터리 및 세그먼트 파일 명명 규칙은 다음과 같습니다.
${storage_root_path}/data/${shard}/${tablet_id}/${schema_hash}/${rowset_id}_${segment_id}.dat
storage_root_path디렉토리를 입력하면 다음과 같은 저장 구조를 볼 수 있습니다.
-
${shard}: 위 그림에서는 0, 1 입니다. BE에 의해 저장소 디렉터리에 자동으로 생성되며 무작위입니다. 데이터가 늘어나면 늘어나겠죠. -
${tablet_id}: 즉, 위 그림에서는 15123, 27003 등이 위에서 언급한 Bucket의 ID이다. -
${schema_hash}: 즉, 위 사진의 727041558, 1102328406 등입니다. 테이블의 구조는 변경될 수 있으므로 각 스키마 버전에 대해 하나가 생성되어SchemaHash해당 버전의 데이터를 식별합니다. -
${segment_id}.dat: 첫 번째는rowset_id위 그림의 02000000000000e3ba4924368a21695d8cc3cf8525f80789 이며, 0부터 시작하여 증가하는${segment_id}현재 RowSet 입니다 .segment_id
세그먼트 파일 저장 형식
Segment의 전체 파일 형식은 다음 그림과 같이 데이터 영역, 색인 영역 및 바닥글의 세 부분으로 나뉩니다.

-
데이터 영역: 각 열의 데이터 정보를 저장하는 데 사용됩니다. 여기에 있는 데이터는 요청 시 페이지에 로드됩니다. 페이지에는 열 데이터가 포함되며 각 페이지는 64k입니다.
-
Index Region: Doris는 Index Region에 각 컬럼의 Index 데이터를 저장하는데, 이곳의 데이터는 컬럼 단위에 따라 로딩되기 때문에 컬럼 데이터 정보와는 별도로 저장된다.
-
바닥글 정보: 파일의 메타데이터 정보, 콘텐츠의 체크섬 등이 포함됩니다.
Q4: Doris의 다양한 테이블 모델에 대한 DML 제한 사항은 무엇입니까?
-
업데이트: Update 문은 현재 UNIQUE KEY 모델만 지원하고 값 열 업데이트만 지원합니다.
-
삭제: 1) 테이블 모델이 집계 클래스(AGGREGATE, UNIQUE)를 사용하는 경우 삭제 작업은 키 열의 조건만 지정할 수 있습니다. 2) 이 작업은 이 기본 인덱스와 관련된 롤업 인덱스의 데이터도 삭제합니다.
-
삽입: 모든 데이터 모델을 삽입할 수 있습니다.
삽입을 구현하는 방법은 무엇입니까? 데이터를 삽입한 후 어떻게 쿼리할 수 있나요?
-
AGGREGATE 모델 : Insert 단계에서는 Append 메소드로 증분 데이터를 RowSet에 기록하고, 쿼리 단계에서는 Merge on Read 메소드를 사용하여 병합한다. 즉, import 시 새로운 RowSet에 데이터를 먼저 쓰고, write 후에는 중복 제거를 수행하지 않으며, 다중 동시 정렬은 쿼리가 시작될 때만 수행됩니다. 데이터가 정렬되고 키가 함께 정렬되어 집계됩니다. 더 높은 버전의 키가 더 낮은 버전의 키를 덮어쓰게 되며 궁극적으로 가장 높은 버전의 기록만 사용자에게 반환됩니다.
-
DUPLICATE 모델 : 이 모델은 위와 유사하게 작성되었으며 읽기 단계에서는 집계 작업이 없습니다.
-
UNIQUE 모델 : 버전 1.2 이전에 이 모델은 기본적으로 집계 모델의 특수한 경우였으며 동작은 AGGREGATE 모델과 일치했습니다. 집계 모델은 Merge on Read 로 구현되므로 일부 집계 쿼리의 성능이 저하됩니다. Doris는 버전 1.2 이후에 덮어쓰거나 업데이트된 데이터를 기록할 때 표시하고 삭제하는 Merge on Write 라는 고유 모델의 새로운 구현을 도입했습니다 . 쿼리 중에 표시되고 삭제된 데이터는 모두 삭제됩니다. 데이터는 파일 수준에서 필터링됩니다. 읽기 데이터는 최신 데이터이므로 읽기 시 병합 시 데이터 집계 프로세스가 필요 없으며 많은 경우 여러 조건자의 푸시다운을 지원할 수 있습니다.
간단히 말해서 쓰기 시 병합의 처리 흐름은 다음과 같습니다.
-
각 키에 대해 기본 데이터(RowSetid + Segmentid + 행 번호)에서 해당 위치를 찾습니다. [쿼리 속도를 높이기 위해 세그먼트 수준 기본 키 간격 트리가 메모리에 유지됩니다.]
-
키가 존재하는 경우 삭제할 데이터 행을 표시합니다. 삭제 표시된 정보는 삭제 비트맵에 기록되며, 각 세그먼트에는 해당 삭제 비트맵이 있습니다.
-
업데이트된 데이터를 새 RowSet에 쓰고, 트랜잭션을 완료하고, 새 데이터를 표시합니다. 즉, 사용자가 쿼리할 수 있습니다.
-
쿼리 시 삭제 비트맵을 읽고, 삭제 표시된 행을 필터링하고, 유효한 데이터만 반환합니다. [모든 히트 세그먼트에 대해 버전이 높은 것부터 낮은 순으로 쿼리]
다음은 쓰기 과정과 읽기 과정의 구현을 소개합니다.
쓰기 과정 : 데이터 쓰기 시 각 Segment의 기본 키 인덱스가 먼저 생성된 후 삭제 비트맵이 업데이트됩니다.
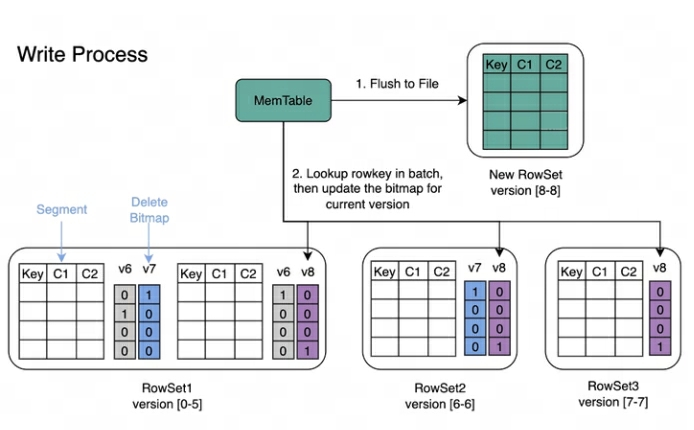
읽기 과정 : Bitmap의 읽기 과정은 아래 그림과 같습니다. 그림에서 우리는 알 수 있습니다:
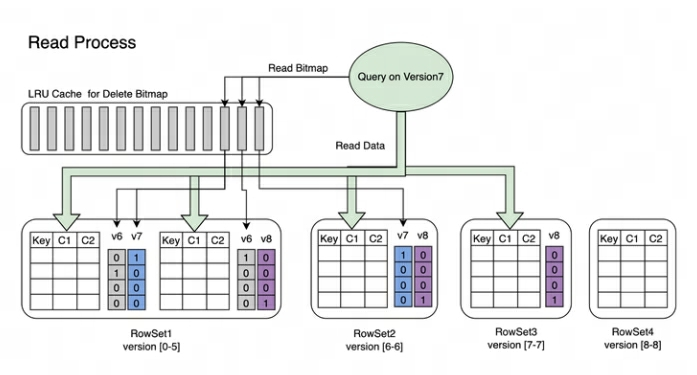
-
버전 7을 요청하는 쿼리에는 버전 7에 해당하는 데이터만 표시됩니다.
-
RowSet5의 데이터를 읽을 때 V6 및 V7 수정으로 생성된 비트맵은 함께 병합되어 데이터 필터링에 사용되는 Version7에 해당하는 완전한 DeleteBitmap을 얻습니다.
-
위의 예에서 버전 8 가져오기는 RowSet1의 Segment2에 있는 데이터 부분을 다루지만 버전 7을 요청하는 쿼리는 여전히 데이터를 읽을 수 있습니다.
업데이트는 어떻게 구현되나요?
UNIQUE 모델 업데이트 프로세스는 본질적으로 선택+삽입입니다.
-
Update는 쿼리 엔진 자체의 Where 필터링 로직을 사용하여 업데이트할 테이블에서 업데이트가 필요한 행을 필터링하고, 이를 기반으로 삭제 비트맵을 유지하고 새로 삽입되는 데이터를 생성합니다.
-
그런 다음 Insert 논리를 실행합니다.구체적인 프로세스는 위에서 언급한 UNIQUE 모델 작성 논리와 유사합니다.
Q5: Doris의 삭제는 어떻게 구현되나요? RowSet도 생성됩니까? 해당 데이터를 삭제하는 방법은 무엇입니까?
-
Doris의 삭제 역시 RowSet을 생성하는데, DELETE 모드에서는 실제로 데이터가 삭제되지는 않지만 데이터 삭제 조건이 기록된다. 메타정보에 저장됩니다. Base Compaction 실행 시 삭제 조건이 Base 버전에 병합됩니다.
-
Doris는 또한 UNIQUE KEY 모델에서 LOAD_DELETE를 지원합니다. 이를 통해 삭제할 키를 일괄 가져와 데이터를 삭제할 수 있으며 대규모 데이터 삭제 기능도 지원할 수 있습니다. 전반적인 아이디어는 삭제 상태 식별자를 데이터 레코드에 추가하고 삭제된 키는 압축 프로세스 중에 압축되는 것입니다. 압축은 주로 여러 RowSet 버전을 병합하는 작업을 담당합니다.
Q6: Doris에는 어떤 인덱스가 있나요?
현재 Doris는 주로 두 가지 유형의 인덱스를 지원합니다.
-
접두사 색인 및 ZoneMap 색인을 포함한 내장형 스마트 색인.
-
사용자가 수동으로 생성한 보조 인덱스에는 반전 인덱스, Bloomfilter 인덱스, Ngram Bloomfilter 인덱스 및 Bitmap 인덱스가 포함됩니다.
ZoneMap 인덱스는 Min/Max, Null 값의 개수 등을 포함하는 컬럼 저장 형식으로 각 컬럼별로 자동으로 유지되는 인덱스 정보입니다. 이 인덱싱은 사용자에게 투명합니다.
지수는 몇등급인가요?
-
이제 Doris의 모든 인덱스는 반전 인덱스, Bloomfilter 인덱스, Ngram Bloomfilter 인덱스 및 비트맵 인덱스, 접두사 인덱스 및 ZoneMap 인덱스 등과 같은 BE 수준 로컬입니다.
-
Doris에는 글로벌 인덱스가 없습니다. 넓은 의미에서 파티션 + 버킷 키도 글로벌로 간주될 수 있지만 상대적으로 세분화되어 있습니다.
인덱스의 저장 형식은 무엇입니까?
Doris에서는 각 컬럼의 Index 데이터가 Segment 파일의 Index Region에 균일하게 저장되는데, 이곳의 데이터는 컬럼 단위에 따라 로드되므로 컬럼 데이터 정보와는 별도로 저장됩니다. 여기서는 Short Key Index 접두사 인덱스를 예로 들어 보겠습니다.
Short Key Index 접두사 인덱스는 주어진 접두사 열을 기준으로 데이터를 빠르게 쿼리하기 위한 Key(AGGREGATE KEY, UNIQ KEY 및 DUPLICATE KEY) 정렬 기반의 인덱스 방법입니다. 여기의 Short Key Index 인덱스도 희소 인덱스 구조를 채택하고 있으며, 데이터 쓰기 과정에서 특정 행 수마다 인덱스 항목이 생성됩니다. 이 행 수는 인덱스 세분성으로, 기본값은 1024개 행이며 구성 가능합니다. 프로세스는 아래와 같습니다.
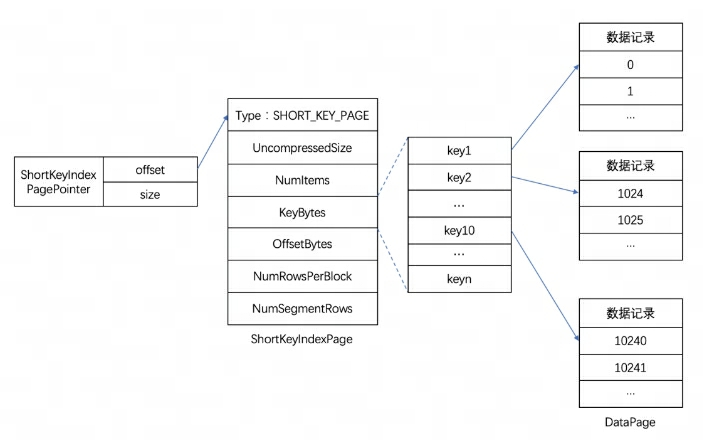
그 중 KeyBytes는 인덱스 항목 데이터를 저장하고, OffsetBytes는 인덱스 항목의 오프셋을 KeyBytes에 저장합니다.
짧은 키 인덱스는 처음 36바이트를 이 데이터 행의 접두사 인덱스로 사용합니다. VARCHAR 유형이 발견되면 접두사 인덱스가 직접 잘립니다. 짧은 키 인덱스는 처음 36바이트를 이 데이터 행의 접두사 인덱스로 사용합니다. VARCHAR 유형이 발견되면 접두사 인덱스가 직접 잘립니다.
읽기 과정이 어떻게 색인에 도달하나요?
Segment 내 데이터를 쿼리할 때 실행된 쿼리 조건에 따라 먼저 필드 인덱스를 기준으로 데이터를 필터링합니다. 그런 다음 데이터를 읽으면 전체 쿼리 프로세스는 다음과 같습니다.
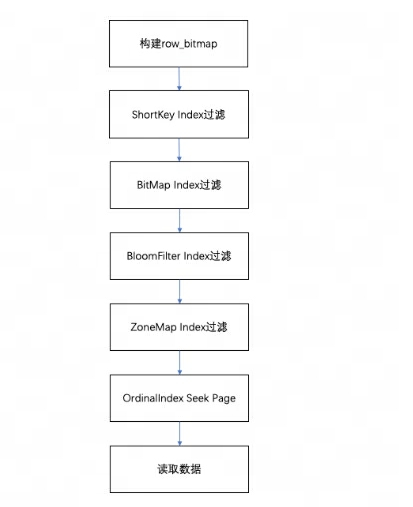
-
row_bitmap먼저, 읽어야 할 데이터를 나타내기 위해 세그먼트의 행 수에 따라 하나를 구성합니다 . 모든 데이터는 인덱스를 사용하지 않고 읽어야 합니다. -
Prefix index 규칙에 따라 쿼리 조건에 Key를 사용하면 ShortKey Index를 먼저 필터링하고 ShortKey Index에서 일치할 수 있는 Oordinal 행 번호 범위를 로 합칩니다
row_bitmap. -
쿼리 조건의 컬럼 필드에 BitMap Index 인덱스가 있는 경우, 조건에 맞는 Ordinal 행 번호를 BitMap 인덱스에 따라 직접 찾아낸 후 row_bitmap과 교차하여 필터링합니다. 여기의 필터링은 정확합니다. 나중에 쿼리 조건이 제거되면 이 필드는 후속 인덱스에 대해 필터링되지 않습니다.
-
쿼리 조건의 열 필드에 BloomFilter 인덱스가 있고 조건이 동일(eq, in, is)인 경우 BloomFilter 인덱스에 따라 필터링됩니다. 여기서 모든 인덱스가 탐색되고 각 페이지의 BloomFilter가 필터링됩니다. 필터링하여 쿼리 조건을 확인할 수 있습니다.모든 페이지. 인덱스 정보와 서수 행 번호 범위의
row_bitmap교차점을 필터링합니다 . -
쿼리 조건의 컬럼 필드에 ZoneMap 인덱스가 있는 경우 ZoneMap 인덱스에 따라 필터링되며, 여기서도 모든 인덱스를 실행하여 쿼리 조건과 ZoneMap이 교차할 수 있는 모든 페이지를 찾습니다. 인덱스 정보와 서수 행 번호 범위의
row_bitmap교차점을 필터링합니다 . -
생성 후
row_bitmap각 Column의 OrdinalIndex를 일괄적으로 통해 특정 Data Page를 찾아낸다. -
각 컬럼의 컬럼 데이터 페이지 데이터를 일괄적으로 읽어옵니다. 읽을 때 Null 값이 있는 페이지의 경우 Null 값 비트맵을 기준으로 현재 행이 Null인지 여부를 확인하고, Null이면 직접 채웁니다.
Q7: Doris는 어떻게 압축을 수행합니까?
Doris는 성능 향상을 위해 RowSet 파일을 점진적으로 집계하기 위해 Compaction을 사용합니다. RowSet의 버전 정보는 병합된 Rowset의 버전 범위를 나타내기 위해 Start와 End라는 두 개의 필드로 설계되었습니다. 병합되지 않은 Cumulative RowSet의 Start 및 End 버전은 동일합니다. Compaction 중에 인접한 RowSet을 병합하여 새로운 RowSet을 생성하고, 버전 정보의 시작 및 끝도 병합하여 더 큰 버전을 구성합니다. 반면에 Compaction 프로세스는 RowSet 파일 수를 크게 줄이고 쿼리 효율성을 향상시킵니다.
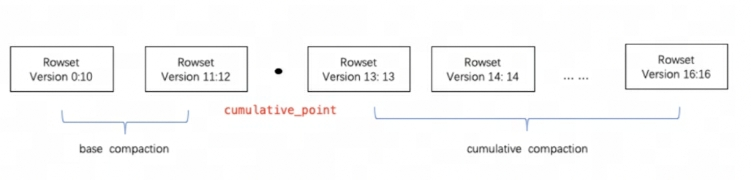
위 그림과 같이 Compaction 작업은 Base Compaction과 Cumulative Compaction의 두 가지 유형으로 구분됩니다. cumulative_point두 가지 전략을 분리하는 것이 핵심입니다.
다음과 같이 이해될 수 있습니다.
-
cumulative_point오른쪽에는 병합된 적이 없는 증분 RowSet가 있으며, 각 RowSet의 시작 및 끝 버전은 동일합니다. -
cumulative_point왼쪽에는 병합된 RowSet이 있으며 시작 버전과 끝 버전이 다릅니다. -
Base Compaction과 Cumulative Compaction의 작업 프로세스는 기본적으로 동일하며, 병합할 InputRowSet을 선택하는 로직만 다르다.
압축은 어떤 키를 기반으로 합니까?
-
Segment에는 항상 Key 정렬 순서(AGGREGATE KEY, UNIQ KEY, DUPLICATE KEY)로 데이터가 저장되는데, 즉 Key 정렬에 따라 데이터 저장의 물리적 구조가 결정되고, 컬럼 데이터의 물리적 구조 순서가 결정된다.
-
따라서 Doris 압축 프로세스는 AGGREGATE KEY, UNIQ KEY 및 DUPLICATE KEY를 기반으로 합니다.
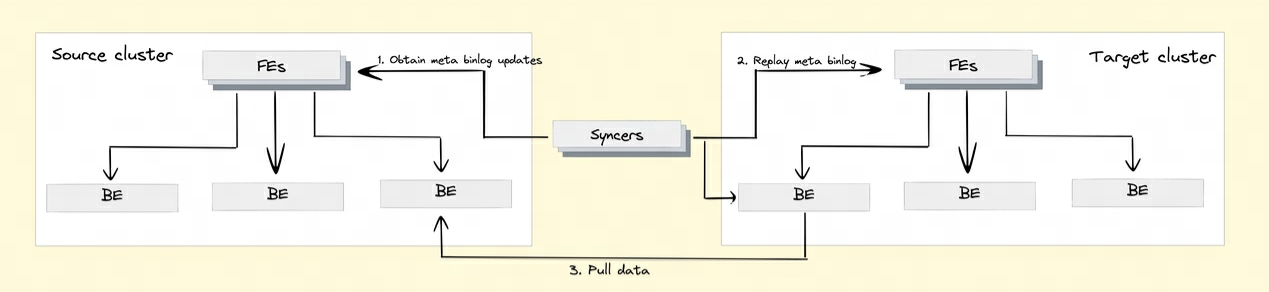
Q8: Doris는 클러스터 간 데이터 복제를 어떻게 구현합니까?
클러스터 간 데이터 복제 기능을 실현하기 위해 Doris는 Binlog 메커니즘을 도입했습니다. 데이터 수정 기록 및 작업은 Binlog 메커니즘을 통해 자동으로 기록되어 데이터 추적성을 확보하며, Binlog 재생 메커니즘을 기반으로 데이터 재생 및 복구도 수행할 수 있습니다.
Binlog는 어떻게 기록되나요?
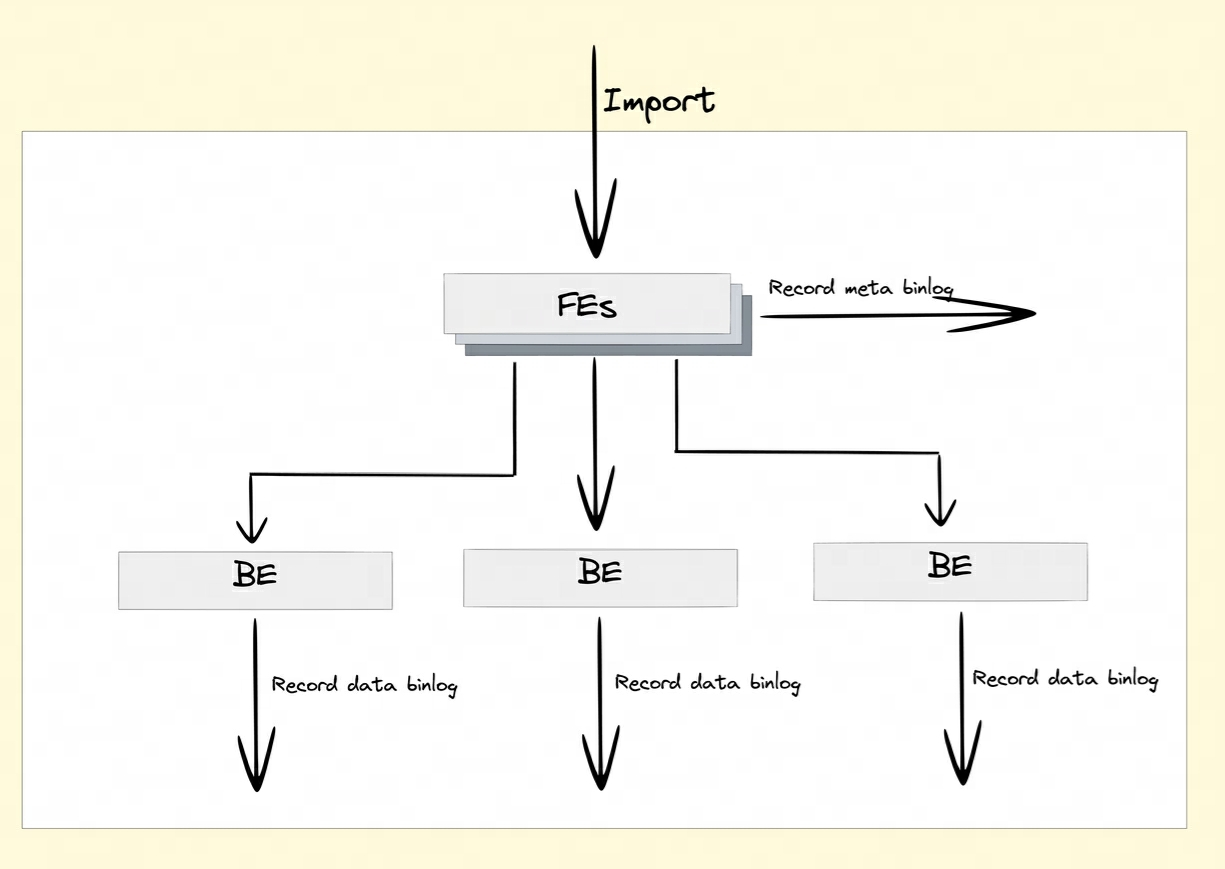
Binlog 속성을 활성화한 후 FE와 BE는 DDL/DML 작업의 수정 기록을 Meta Binlog 및 Data Binlog에 유지합니다.
-
Meta Binlog: Doris는 로그의 질서를 보장하기 위해 EditLog 구현을 향상했습니다. LogID의 증가하는 시퀀스를 구성함으로써 각 작업이 정확하게 기록되고 순서대로 유지됩니다. 이 정렬된 지속성 메커니즘은 데이터 일관성을 보장하는 데 도움이 됩니다.
-
데이터 Binlog: FE가 게시 트랜잭션을 시작하면 BE는 해당 게시 작업을 수행합니다. BE는 RowSet
rowset_meta과 하고 이를 메타 저장소에 유지합니다. 제출 후 가져온 세그먼트 파일은 다음과 같습니다. Binlog 폴더에 연결됩니다.
Binlog 생성:
BInlog 데이터 재생:
Q9: Doris의 테이블에는 여러 개의 복사본이 있습니다. 쓰기 단계에서 여러 개의 복사본을 확보하는 방법은 무엇입니까? 마스터-슬레이브 개념이 있습니까? 다수 이후 쓰기 성공을 반환해야 합니까?
-
Doris BE의 3개 사본은 마스터-슬레이브 개념이 없으며 Quorum 알고리즘을 사용하여 다중 사본 작성을 보장합니다.
-
쓰기 과정에서 FE는 데이터 쓰기에 성공한 각 태블릿의 복사본 수가 전체 태블릿 복사본 수의 절반을 초과하는지 여부를 확인합니다. 데이터 쓰기에 성공한 각 태블릿의 복사본 수가 전체 태블릿 복사본 수의 절반을 초과하는 경우 복사본(대부분 성공)인 경우 커밋 트랜잭션이 성공하고 트랜잭션 상태가 COMMITTED로 설정됩니다. COMMITTED 상태는 데이터가 성공적으로 기록되었지만 데이터가 아직 표시되지 않았으며 버전 게시 작업을 계속해야 함을 나타냅니다. .그 이후에는 트랜잭션을 롤백할 수 없습니다.
-
FE는 성공적인 커밋 트랜잭션을 위해 게시 버전을 실행하기 위한 별도의 스레드를 갖습니다. FE가 게시 버전을 실행하면 Thrift RPC를 통해 트랜잭션과 관련된 모든 Executor BE 노드에 게시 버전 요청을 보냅니다. 버전 게시 작업은 각 노드에서 비동기식으로 실행됩니다. Executor BE 노드 생성된 RowSet으로 데이터를 가져오고 이를 가시적인 데이터 버전으로 만듭니다.
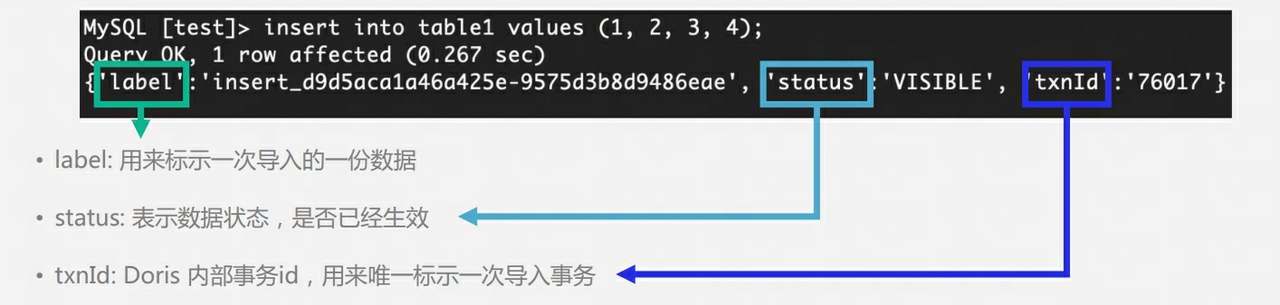
게시 메커니즘이 있는 이유 : MVCC와 마찬가지로 게시 메커니즘이 없으면 사용자는 아직 제출되지 않은 데이터를 읽을 수 있습니다.
테이블에 3개의 복사본이 있고 1개의 복사본만 성공적으로 기록되면 어떻게 될까요 ? 이때 트랜잭션은 중단됩니다.
테이블에 3개의 복사본이 있고 2개의 복사본만 성공적으로 기록되면 어떻게 될까요 ? 이때 트랜잭션은 COMMITTED가 되며 Doris FE는 정기적으로 태블릿 모니터링 및 검사를 수행합니다. 태블릿 복사본에 이상이 발견되면 Clone을 수행합니다. 새 복사본을 복제하기 위한 작업이 생성됩니다.
사용자가 Insert In을 실행한 후 즉시 쿼리를 실행했는데 결과가 비어 있을 수 있는 이유는 트랜잭션이 아직 게시되지 않았기 때문입니다.
Q10: Doris의 FE는 어떻게 고가용성을 보장합니까?
메타데이터 수준에서 Doris는 Paxos 프로토콜과 메모리 + 체크포인트 + 저널 메커니즘을 사용하여 메타데이터의 고성능과 높은 신뢰성을 보장합니다.
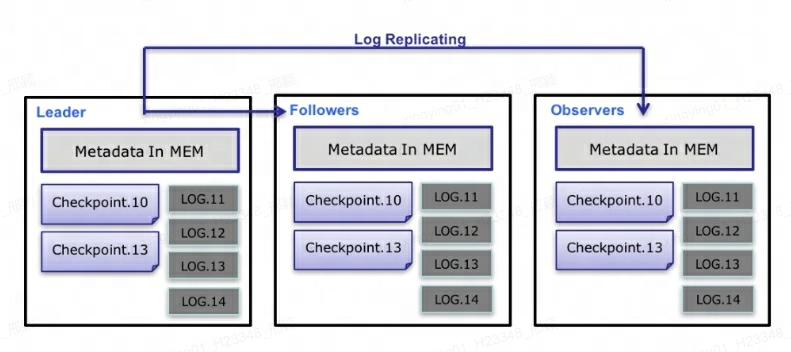
메타데이터 데이터 흐름의 구체적인 프로세스는 다음과 같습니다 .
-
Leader FE만 메타데이터를 쓸 수 있습니다. 쓰기 작업이 Leader의 메모리를 수정한 후에는 Log로 직렬화되어
key-valueBDBJE에 . 키는 연속된 정수이고log id값은 직렬화된 작업 로그입니다. -
로그가 BDBJE에 기록된 후 BDBJE는 정책(다수 쓰기/전체 쓰기)에 따라 다른 Non-Leader FE 노드에 로그를 복사합니다. Non-Leader FE 노드는 리더 노드와의 메타데이터 동기화를 완료하기 위해 로그를 재생하여 자체 메타데이터 메모리 이미지를 수정합니다.
-
Leader 노드의 로그 수가 임계값(기본 100,000개)에 도달하고 Checkpoint 스레드 실행 주기(기본 60초)를 충족합니다. 체크포인트는 기존 이미지 파일과 후속 로그를 읽고 메모리에서 새 메타데이터 이미지 복사본을 재생합니다. 그런 다음 복사본이 디스크에 기록되어 새 이미지를 형성합니다. 기존 이미지를 이미지로 쓰는 대신 이미지 복사본을 다시 생성하는 이유는 주로 이미지에 쓰고 읽기 잠금을 추가하면 쓰기 작업이 차단되기 때문입니다. 따라서 각 체크포인트는 두 배의 메모리 공간을 차지하게 됩니다.
-
이미지 파일이 생성된 후 리더 노드는 다른 비리더 노드에 새 이미지가 생성되었음을 알립니다. Non-Leader는 HTTP를 통해 최신 이미지 파일을 적극적으로 가져와 이전 로컬 파일을 대체합니다.
-
BDBJE 로그의 경우, 이미지가 완성된 후 정기적으로 오래된 로그가 삭제됩니다.
설명하다 :
-
각 메타데이터 업데이트는 먼저 디스크의 로그 파일에 기록된 다음 메모리에 기록되고 마지막으로 주기적으로 로컬 디스크에 체크포인트됩니다.
-
이는 순수 메모리 구조와 동일합니다. 즉, 모든 메타데이터가 메모리에 캐시되므로 FE가 메타데이터 손실 없이 충돌 후 메타데이터를 신속하게 복원할 수 있음을 보장합니다.
-
Leader, Follower, Observer 세 개가 안정적인 서비스를 구성합니다. 단일 노드가 실패할 경우 기본적으로 3개면 충분합니다. 왜냐하면 결국 FE 노드는 메타데이터 복사본을 하나만 저장하고 그 부담이 크지 않기 때문입니다. FE가 너무 많으면 시스템 리소스를 소비하게 되므로 대부분의 경우 가용성이 높은 메타데이터 서비스를 구현하는 데 3개면 충분합니다.
-
사용자는 MySQL을 사용하여 메타데이터에 대한 읽기 및 쓰기 액세스를 위해 모든 FE 노드에 연결할 수 있습니다. 비리더 노드에 대한 연결인 경우 노드는 쓰기 작업을 리더 노드로 전달합니다.
작가에 대해
Invisible(Xing Ying)은 NetEase의 수석 데이터베이스 커널 엔지니어로 졸업 후 데이터베이스 커널 개발에 종사해 왔으며 현재는 주로 MySQL 및 Apache Doris의 개발, 유지 관리 및 비즈니스 지원에 참여하고 있습니다. MySQL 커널 기여자로서 그는 MySQL에 대한 50개 이상의 버그와 최적화 항목을 보고했으며 여러 제출 사항이 MySQL 8.0 버전에 통합되었습니다. 2023년부터 Apache Doris 커뮤니티에 합류한 Apache Doris Active Contributor는 커뮤니티를 위해 수십 개의 커밋을 제출하고 병합했습니다.
실제로 Nintendo Wii의 사례인 "지능형 대화형 카타르시스 장치"를 구입한 중학교 TIOBE 2023 올해의 프로그래밍 언어: C# Kingsoft WPS 충돌 Linux의 Rust 실험 성공, Firefox가 기회를 잡을 수 있을까요... 10가지 예측 오픈소스 여성 임원 해고 사건 후속조치 : 회사 회장은 직원들을 '상습범'이라 칭하고 '허위 이력서'를 문제시했다 . 악성공격 건수 2024 프론트엔드계 '올해의 전투' : React는 구멍을 파지 못하는데 문서로 채워야 하나? Linux Kernel 6.7이 공식적으로 출시되었습니다. "포스트 오픈 소스" 시대가 도래했습니다. 라이센스가 유효하지 않으며 일반 대중에게 서비스를 제공할 수 없습니다. 여성 임원은 불법적으로 해고되었습니다. 직원들은 불법 복제된 EDA 도구 사용에 반대하는 목소리를 내고 표적이 되었습니다. 디자인 칩.