
배경 소개
최근 비즈니스 시스템에서는 슬레이브 데이터베이스가 지연된 상태로 마스터 데이터베이스를 따라잡지 못해 비즈니스 위험이 더 커졌습니다. 리소스 측면에서 슬레이브 라이브러리의 CPU, IO, 네트워크 사용량이 낮으며, 슬레이브 라이브러리에서 show processlist를 실행하면 과도한 서버 압력으로 인해 재생이 느려지는 상황이 없습니다. 라이브러리에 재생 스레드가 없음이 표시됩니다. 차단, 재생이 계속됨, 릴레이 로그 파일 분석 중 대규모 트랜잭션 재생이 없음이 발견되었습니다.
프로세스 분석
현상 확인
운영 및 유지 관리 동료로부터 슬레이브 라이브러리 한 세트가 매우 지연된다는 피드백을 받았습니다. show slave status지연에 대한 스크린샷 정보를 제공했습니다.
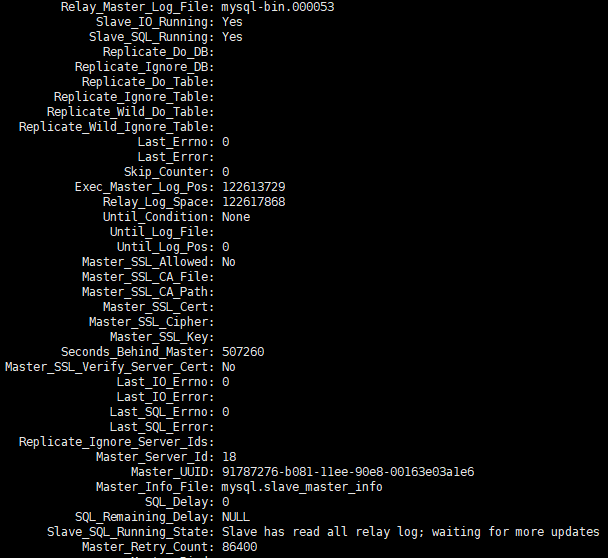
show slave status한동안 계속해서 변화를 관찰한 결과 , POS 포인트 정보가 지속적으로 변화하고 있고, Seconds_Behind_master도 지속적으로 변화하고 있으며, 전반적인 추세가 계속해서 성장하고 있음을 발견했습니다.
자원 사용
서버 리소스 사용량을 관찰한 결과 사용량이 매우 낮다는 것을 알 수 있습니다.

슬레이브 프로세스를 관찰하면 기본적으로 작업을 재생하는 하나의 스레드만 볼 수 있습니다.
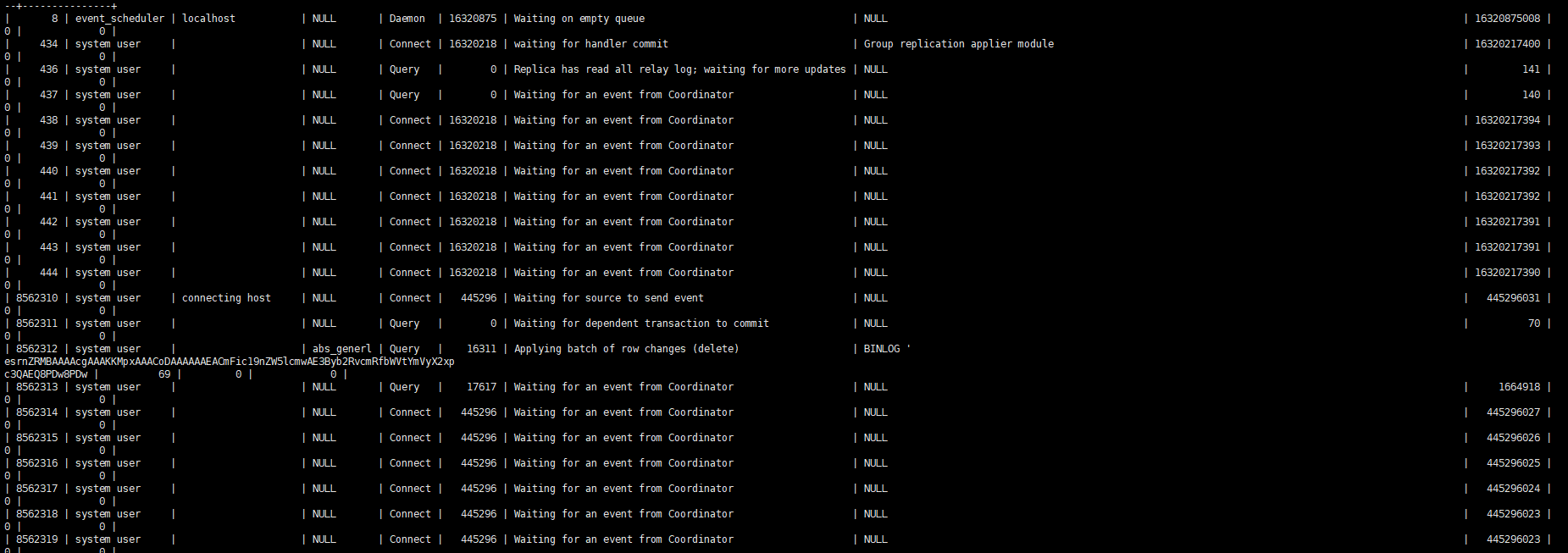
병렬 재생 매개변수 설명
메인 라이브러리에 설정binlog_transaction_dependency_tracking=WRITESET
슬레이브 라이브러리에서는 slave_parallel_type=LOGICAL_CLOCK및slave_parallel_workers=64
오류 로그 비교
분석을 위해 오류 로그에서 병렬 재생 로그를 가져옵니다.
$ grep 010559 100werror3306.log | tail -n 3
2024-01-31T14:07:50.172007+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3318582273; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348754579743300 waited (count) when Workers occupied = 34529247 waited when Workers occupied = 76847369713200
2024-01-31T14:09:50.078829+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3319256065; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348851330164000 waited (count) when Workers occupied = 34535857 waited when Workers occupied = 76866419841900
2024-01-31T14:11:50.060510+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3319894017; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348943740455400 waited (count) when Workers occupied = 34542790 waited when Workers occupied = 76890229805500
위 정보에 대한 자세한 설명은 MTS 성능 모니터링 얼마나 알고 계십니까? 를 참조하십시오.
발생 빈도가 낮은 통계를 제거하고 일부 주요 데이터의 비교를 표시했습니다.
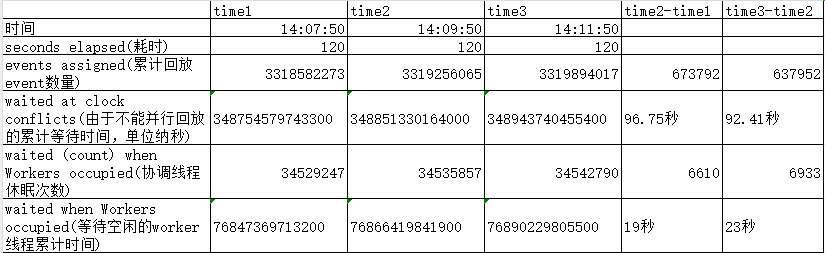
자연 시간 120에서는 재생 조정 스레드가 병렬로 재생할 수 없기 때문에 90초 이상 대기하고 대기할 유휴 작업 스레드가 없기 때문에 거의 20초를 기다리는 것을 알 수 있습니다. 이는 약 10초에 불과합니다. 조정 스레드가 작동하려면
병렬성 통계
우리 모두 알고 있듯이, 라이브러리의 mysql 병렬 재생은 주로 binlog의 last_committed에 의존하여 판단합니다. 트랜잭션의 last_committed가 동일하면 기본적으로 이러한 트랜잭션이 병렬로 재생될 수 있다고 간주할 수 있습니다. 병렬 재생을 위해 환경에서 릴레이 로그를 얻는 대략적인 통계입니다.
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>=1 && $2 <11){sum+=$2}} END {print sum}'
235703
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>10){sum+=$2}} END {print sum}'
314694
위의 첫 번째 명령은 동일한 last_committed를 가진 트랜잭션 수를 1부터 10까지 계산합니다. 즉, 병렬 재생 수준이 낮거나 병렬로 재생할 수 없는 트랜잭션 수는 총 235703개로 43%를 차지합니다. 상대적으로 병렬 재생 수준이 낮은 트랜잭션에 대한 자세한 분석 트랜잭션 분포를 보면 last_committed의 이 부분은 기본적으로 단일 트랜잭션임을 알 수 있습니다. 이로 인해 이전 로그에서 관찰된 조정 스레드 대기가 병렬로 재생할 수 없게 되고 시간이 상대적으로 길어지면 대기 상태로 들어갑니다.
$ mysqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>=1 && $2 <11) {print $2}}' | sort | uniq -c
200863 1
17236 2
98 3
13 4
3 5
1 7
두 번째 명령은 동일한 last_committed 트랜잭션이 10개 이상인 총 트랜잭션 수를 계산하며, 그 수는 57%를 차지하며, 이러한 트랜잭션을 비교적 높은 수준의 병렬 재생으로 분석한 것을 확인할 수 있습니다. 6500에서 9000 사이. 거래 수
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>11){print $0}}' | column -t
last_commited group_count Percentage
1 7340 1.33%
11938 7226 1.31%
23558 7249 1.32%
35248 6848 1.24%
46421 7720 1.40%
59128 7481 1.36%
70789 7598 1.38%
82474 6538 1.19%
93366 6988 1.27%
104628 7968 1.45%
116890 7190 1.31%
128034 6750 1.23%
138849 7513 1.37%
150522 6966 1.27%
161989 7972 1.45%
175599 8315 1.51%
189320 8235 1.50%
202845 8415 1.53%
218077 8690 1.58%
234248 8623 1.57%
249647 8551 1.55%
264860 8958 1.63%
280962 8900 1.62%
297724 8768 1.59%
313092 8620 1.57%
327972 9179 1.67%
344435 8416 1.53%
359580 8924 1.62%
375314 8160 1.48%
390564 9333 1.70%
407106 8637 1.57%
422777 8493 1.54%
438500 8046 1.46%
453607 8948 1.63%
470939 8553 1.55%
486706 8339 1.52%
503562 8385 1.52%
520179 8313 1.51%
535929 7546 1.37%
last_committed 메커니즘 소개
메인 라이브러리의 매개변수는 binlog_transaction_dependency_tracking슬레이브 라이브러리가 병렬로 실행할 수 있는 트랜잭션을 결정하는 데 도움이 되도록 바이너리 로그에 기록된 종속성 정보를 생성하는 방법을 지정하는 데 사용됩니다. 즉, 이 매개변수는 last_committed의 생성 메커니즘을 제어하는 데 사용됩니다. 매개변수의 선택값은 COMMIT_ORDER, WRITESET, SESSION_WRITESET이다. 다음 코드에서 세 가지 매개변수 관계를 쉽게 확인할 수 있습니다.
- 기본 알고리즘은 COMMIT_ORDER입니다.
- WRITESET 알고리즘은 COMMIT_ORDER를 기반으로 다시 계산됩니다.
- SESSION_WRITESET 알고리즘은 WRITESET을 기반으로 다시 계산됩니다.
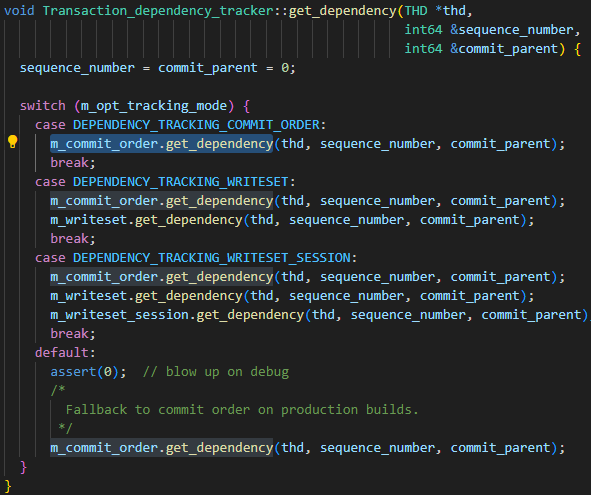
내 인스턴스가 WRITESET으로 설정되어 있으므로 COMMIT_ORDER 알고리즘과 WRITESET 알고리즘에만 집중하세요.
COMMIT_ORDER
COMMIT_ORDER 계산 규칙: 두 개의 트랜잭션이 마스터 노드에서 동시에 제출되면 두 트랜잭션의 데이터 간에 충돌이 없으며 슬레이브 노드에서도 병렬로 실행될 수 있음을 의미합니다. 다음과 같다.
| 세션-1 | 세션-2 |
|---|---|
| 시작하다 | 시작하다 |
| t1 값 삽입(1) | |
| t2 값 삽입(2) | |
| 커밋(그룹_커밋) | 커밋(그룹_커밋) |
그러나 MySQL의 경우 group_commit은 내부 동작입니다. session-1과 session-2가 동시에 커밋을 실행하는 한, 내부적으로 group_commit에 병합되었는지 여부에 관계없이 두 트랜잭션의 데이터는 본질적으로 충돌이 없습니다. 한 단계 뒤로 물러서서, 세션 1이 커밋을 실행하고 새 데이터가 세션 2에 기록되지 않는 한 두 트랜잭션은 여전히 데이터 충돌이 없으며 병렬로 복제될 수 있습니다.
| 세션-1 | 세션-2 |
|---|---|
| 시작하다 | 시작하다 |
| t1 값 삽입(1) | |
| t2 값 삽입(2) | |
| 저지르다 | |
| 저지르다 |
더 많은 동시 스레드가 있는 시나리오의 경우 이러한 스레드는 동시에 병렬로 복제할 수 없지만 일부 트랜잭션은 가능합니다. 다음 실행 순서를 예로 들면, 세션 3이 커밋된 후 세션 2에는 새로운 쓰기가 없으므로 세션 3이 커밋된 후 두 트랜잭션이 병렬로 복제될 수 있으며 세션 1은 새 데이터를 삽입하고 데이터 충돌이 발생합니다. 현재로서는 확인할 수 없으므로 세션-3과 세션-1의 트랜잭션을 병렬로 복제할 수 없지만 세션-2가 제출된 후에는 세션-1 이후에 새 데이터가 기록되지 않으므로 세션-2와 세션-1 다시 병렬로 복제될 수 있습니다. 따라서 이 시나리오에서는 세션 2가 세션 1 및 세션 3과 각각 병렬로 복제될 수 있지만 세 개의 트랜잭션이 동시에 병렬로 복제될 수는 없습니다.
| 세션-1 | 세션-2 | 세션-3 |
|---|---|---|
| 시작하다 | 시작하다 | 시작하다 |
| t1 값 삽입(1) | t2 값 삽입(1) | t3 값 삽입(1) |
| t1 값 삽입(2) | t2 값 삽입(2) | |
| 저지르다 | ||
| t1 값 삽입(3) | ||
| 저지르다 | ||
| 저지르다 |
쓰기 세트
실제로는 commit_order+writeset의 조합입니다. 먼저 commit_order를 통해 last_committed 값을 계산한 다음 writeset을 통해 새 값을 계산하고 마지막으로 둘 중 더 작은 값을 최종 트랜잭션 gtid의 last_committed 값으로 사용합니다.
MySQL에서 writeset은 본질적으로 Schema_name + table_name + Primary_key/unique_key에 대해 계산된 해시 값입니다. DML 문을 실행하는 동안 binlog_log_row를 통해 row_event를 생성하기 전에 DML 문의 모든 기본 키/고유 키에는 해시 값이 계산됩니다. 별도로 트랜잭션 자체의 쓰기 세트 목록에 추가됩니다. 그리고 기본 키/고유 인덱스가 없는 테이블이 있는 경우 해당 트랜잭션에 대해 has_missing_keys=true도 설정됩니다.
매개변수가 WRITESET으로 설정되어 있지만 사용할 수는 없습니다. 제한 사항은 다음과 같습니다.
- 기본 키, 고유 키 또는 빈 트랜잭션이 있는 비DDL 문 또는 테이블
- 현재 세션에서 사용하는 해시 알고리즘은 해시 맵의 알고리즘과 일치합니다.
- 외래 키가 사용되지 않음
- 해시맵의 용량은 binlog_transaction_dependent_history_size 설정을 초과하지 않으며, 위 4가지 조건을 모두 만족하는 경우 WRITESET 알고리즘을 사용할 수 있으며, 조건 중 하나라도 만족하지 않으면 COMMIT_ORDER 계산 방식으로 퇴화된다.
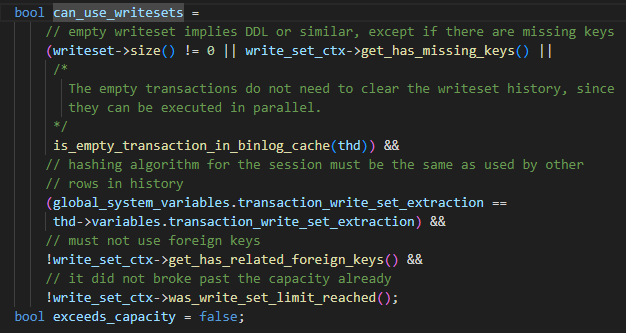
트랜잭션이 제출될 때 특정 WRITESET 알고리즘은 다음과 같습니다.
-
last_committed는 m_writeset_history_start로 설정됩니다. 이 값은 m_writeset_history 목록에서 가장 작은 시퀀스_번호입니다.
-
트랜잭션의 쓰기 세트 목록을 탐색합니다.
a 글로벌 m_writeset_history에 쓰기 세트가 없으면 현재 트랜잭션의 pair<writeset, 시퀀스_번호> 객체를 구성하고 이를 글로벌 m_writeset_history 목록에 삽입합니다.
b. 존재하는 경우 last_committed=max(last_committed, 기록 쓰기 세트의 시퀀스_번호 값)와 동시에 m_writeset_history의 쓰기 세트에 해당하는 시퀀스_번호를 현재 트랜잭션 값으로 업데이트합니다.
-
has_missing_keys=false, 즉 트랜잭션의 모든 데이터 테이블에 기본 키 또는 고유 인덱스가 포함된 경우 commit_order 및 writeset에 의해 계산된 최소값이 최종 last_committed 값으로 사용됩니다.
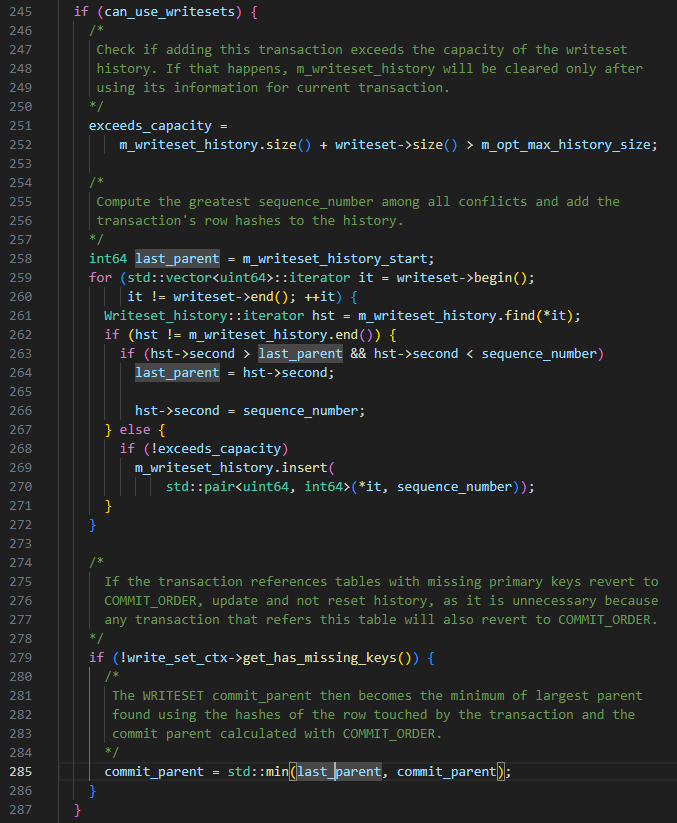
TIPS: 위의 WRITESET 규칙에 따라 나중에 제출된 트랜잭션의 last_committed가 먼저 제출된 트랜잭션보다 작은 상황이 발생합니다.
결론 분석
결론 설명
WRITESET의 사용 제한에 따라 Relay-log와 트랜잭션에 관련된 테이블 구조를 비교하고, Single last_committed의 트랜잭션 구성을 분석한 결과 다음과 같은 두 가지 상황을 발견했다.
- 단일 last_committed 트랜잭션과 시퀀스_번호에 관련된 데이터 간에 데이터 충돌이 있습니다.
- 단일 last_committed 트랜잭션과 관련된 테이블에는 기본 키가 없으며 이러한 트랜잭션이 많이 있습니다.
위의 분석을 통해 기본 키가 없는 테이블에 트랜잭션이 너무 많아 WRITESET이 COMMIT_ORDER로 변질된다는 결론을 내릴 수 있습니다. 데이터베이스는 TP 애플리케이션이므로 트랜잭션이 빠르게 제출되며 여러 트랜잭션 제출을 보장할 수 없습니다. 하나의 커밋 주기 내에 있기 때문에 COMMIT_ORDER가 발생합니다. 메커니즘에 의해 생성된 last_committed 반복 읽기가 매우 낮습니다. 슬레이브 라이브러리는 이러한 트랜잭션을 순차적으로만 재생할 수 있으므로 재생 지연이 발생합니다.
최적화 조치
- 비즈니스 측면에서 테이블을 수정하고 가능한 경우 관련 테이블에 기본 키를 추가합니다.
- binlog_group_commit_sync_delay 및 binlog_group_commit_sync_no_delay_count 매개변수를 0에서 10000으로 늘리십시오. 특별한 환경 제한으로 인해 이 조정은 시나리오에 따라 적용되지 않을 수 있습니다.
GreatSQL을 즐겨보세요 :)
GreatSQL 소개
GreatSQL은 금융 수준의 애플리케이션에 적합한 국내 독립 오픈소스 데이터베이스로, 고성능, 높은 신뢰성, 높은 사용 편의성, 높은 보안성 등 많은 핵심 기능을 갖추고 있으며 MySQL 또는 Percona Server를 대체하여 사용할 수 있습니다. 온라인 생산 환경에서 사용되며 완전 무료이며 MySQL 또는 Percona Server와 호환됩니다.
관련 링크: GreatSQL 커뮤니티 Gitee GitHub Bilibili
GreatSQL 커뮤니티:

커뮤니티 보상 제안 및 피드백: https://greatsql.cn/thread-54-1-1.html
커뮤니티 블로그 수상작 제출 세부정보: https://greatsql.cn/thread-100-1-1.html
(기사에 대해 궁금한 점이 있거나 남다른 통찰력이 있다면 공식 커뮤니티 홈페이지에 가서 질문하거나 공유해 보세요~)
기술교류그룹:
위챗 & QQ 그룹:
QQ 그룹: 533341697
WeChat 그룹: GreatSQL 커뮤니티 도우미(WeChat ID: wanlidbc)를 친구로 추가하고 커뮤니티 도우미가 귀하를 그룹에 추가할 때까지 기다립니다.