
1. 배경
ZooKeeper(ZK)는 2007년에 탄생한 분산형 애플리케이션 조정 서비스입니다. 몇 가지 특별한 역사적 이유로 인해 여전히 많은 비즈니스 시나리오에서 이에 의존해야 합니다. 예를 들어 Kafka, 작업 스케줄링 등이 있습니다. 특히 Flink 혼합 배포와 ETCD 디커플링의 경우 비즈니스 측면에서는 절대적인 안정성이 필요하므로 자체 구축된 ZooKeeper를 사용하지 않는 것이 좋습니다. 안정성을 고려하여 Alibaba의 MSE-ZK가 사용됩니다. 2022년 9월부터 사용하기 시작한 이후 안정성 문제는 한 번도 발생하지 않았으며 SLA 신뢰도는 실제로 99.99%에 도달했습니다.
2023년에는 일부 기업에서 자체 구축한 ZooKeeper(ZK) 클러스터를 사용한 후 ZK가 사용 중에 여러 가지 변동을 겪었습니다. 이후 Dewu SRE는 일부 자체 구축 클러스터를 인수하기 시작하여 여러 차례 안정성 강화를 시도했습니다. 인수 과정에서 ZooKeeper가 일정 기간 동안 실행된 후에는 메모리 사용량이 계속 증가하여 메모리 부족(OOM) 문제가 쉽게 발생할 수 있다는 사실을 발견했습니다. 우리는 이 현상에 대해 매우 호기심이 많았고, 따라서 이 문제를 해결하기 위한 탐색 과정에 참여했습니다.
2. 탐색 및 분석
방향을 결정하다
문제를 해결할 때 테스트 환경에서 오류 사이트를 발견한 것은 매우 운이 좋았습니다. 클러스터의 두 노드가 OOM의 엣지 상태에 있었습니다.

결함 현장의 경우 일반적으로 성공적인 종료 지점까지 50%만 남습니다.
메모리가 높은 쪽에 있습니다. 과거 경험에 따르면 힙이 아니거나 힙에 문제가 있습니다. Flame Graph와 Jstat을 통해 Heap에 문제가 있음을 확인할 수 있습니다.
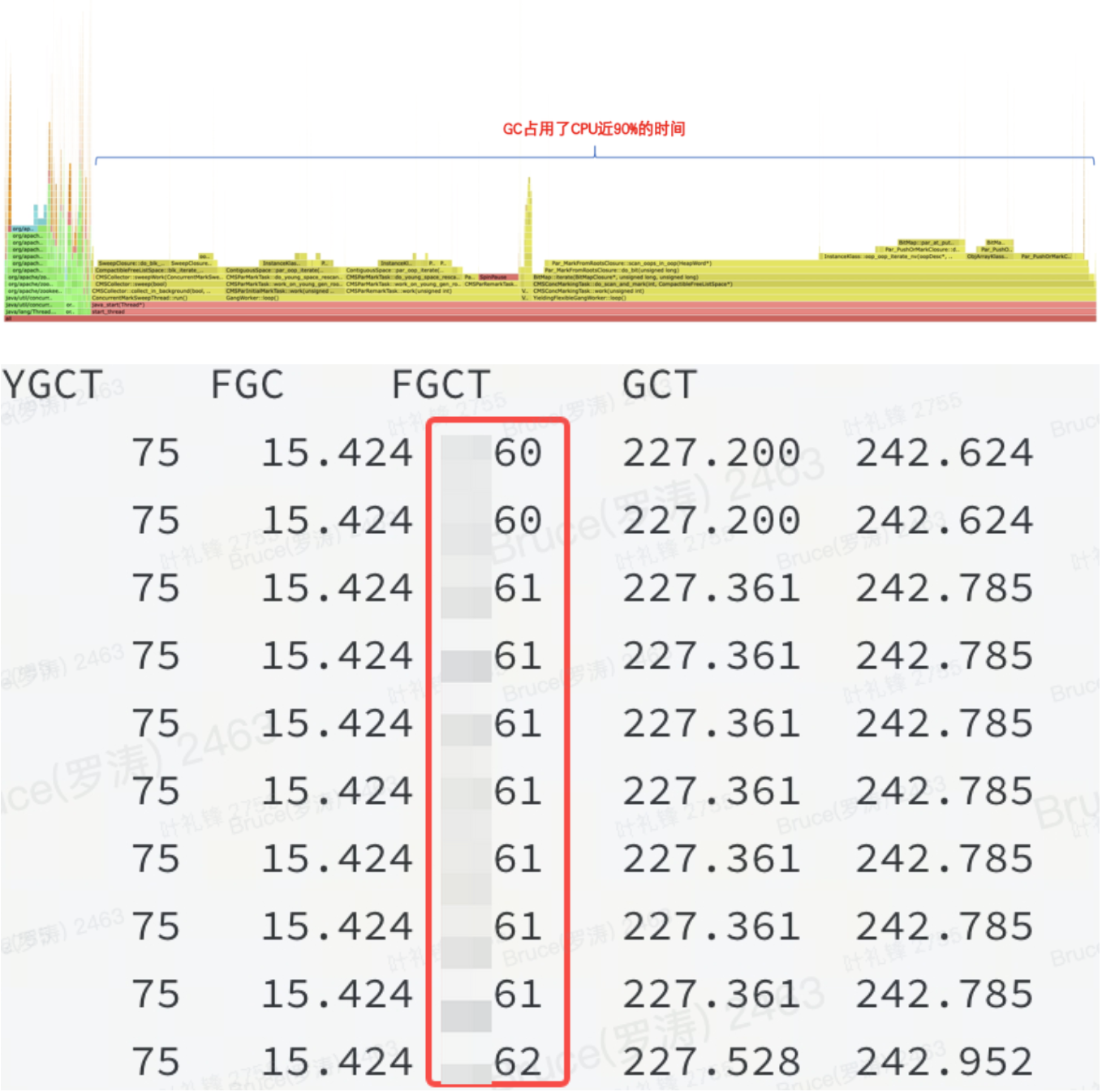
그림에 표시된 것처럼 JVM 힙의 특정 리소스가 많은 양의 메모리를 차지하고 있어 FGC가 이를 해제할 수 없음을 의미합니다.
메모리 분석
JVM 힙의 메모리 사용량 분포를 탐색하기 위해 즉시 JVM 힙 덤프를 만들었습니다. 분석 결과 JVM 메모리가 childWatches 및 dataWatches에 의해 많이 점유되는 것으로 나타났습니다.
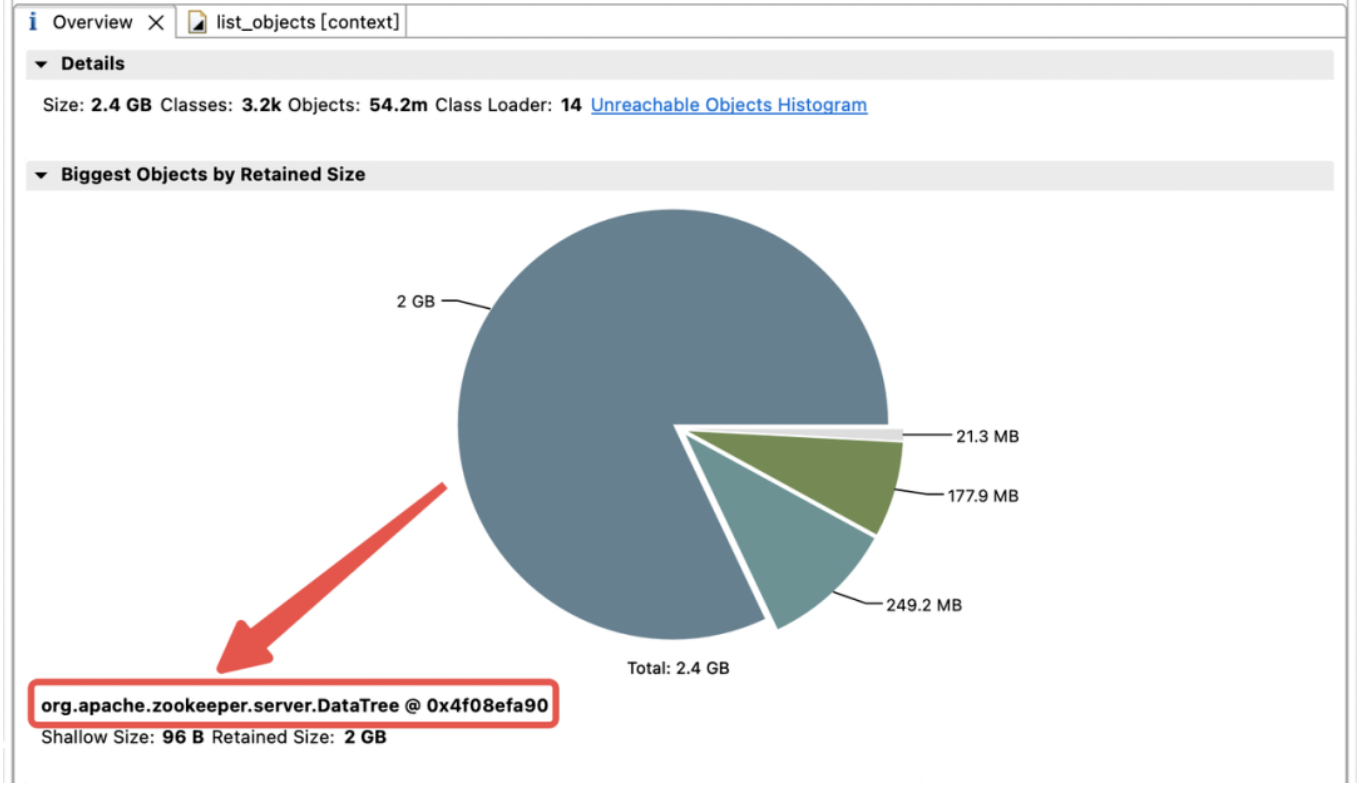
dataWatches: znode 노드 데이터의 변경 사항을 추적합니다.
childWatches: znode 노드 구조(트리)의 변경 사항을 추적합니다.
childWatches 및 dataWatches는 WatcherManager와 동일한 출처를 갖습니다.
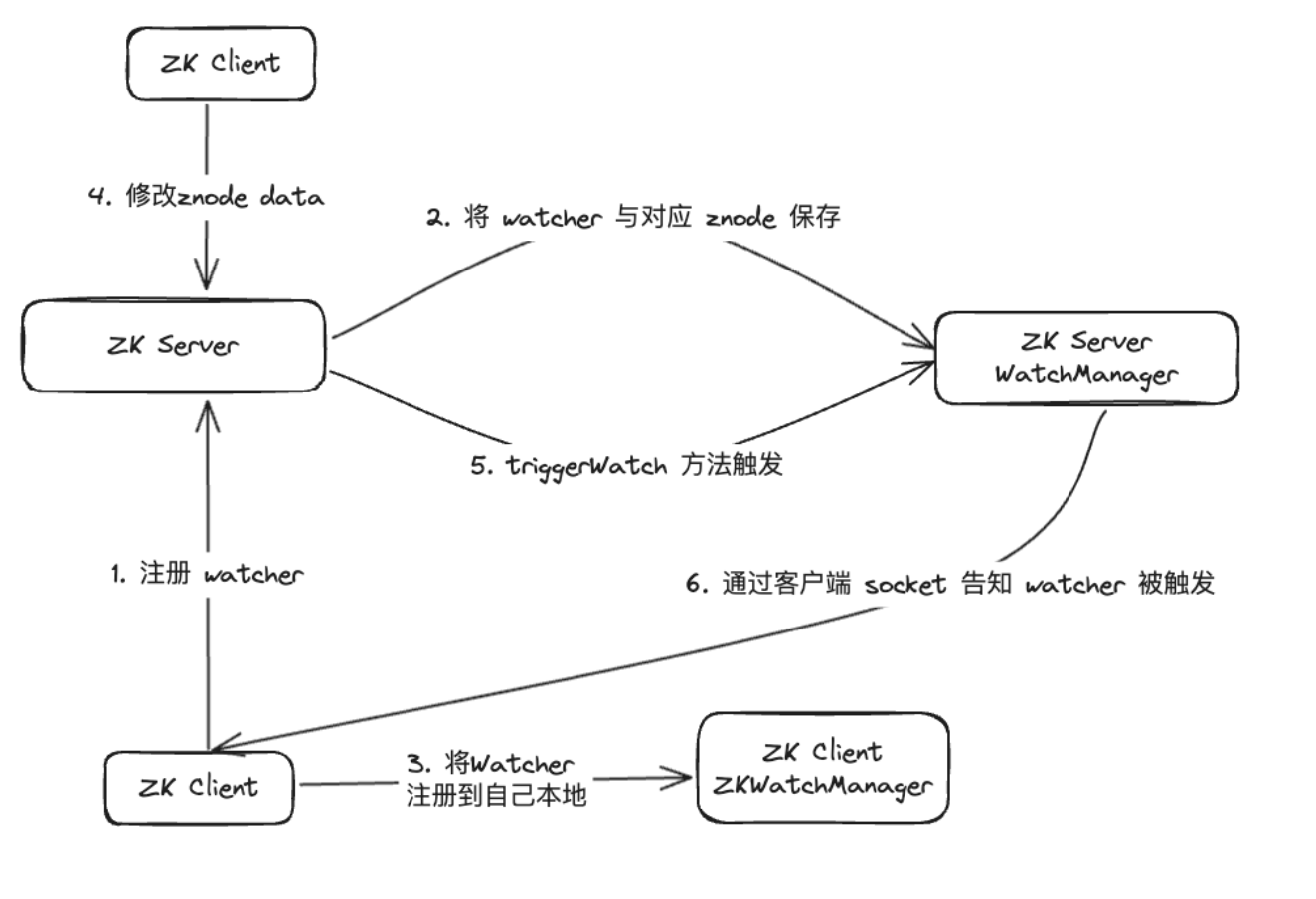
데이터 조사 결과 WatcherManager는 주로 Watcher 관리를 담당하는 것으로 나타났습니다. ZooKeeper(ZK) 클라이언트는 먼저 Watcher를 ZooKeeper 서버에 등록한 다음 ZooKeeper 서버는 WatcherManager를 사용하여 모든 Watcher를 관리합니다. Znode의 데이터가 변경되면 WatchManager는 해당 Watcher를 트리거하고 Znode에 가입된 ZooKeeper 클라이언트의 소켓과 통신합니다. 이후 클라이언트의 Watch 관리자는 관련 Watcher 콜백을 트리거하여 해당 처리 로직을 실행함으로써 전체 데이터 게시/구독 프로세스를 완료합니다.
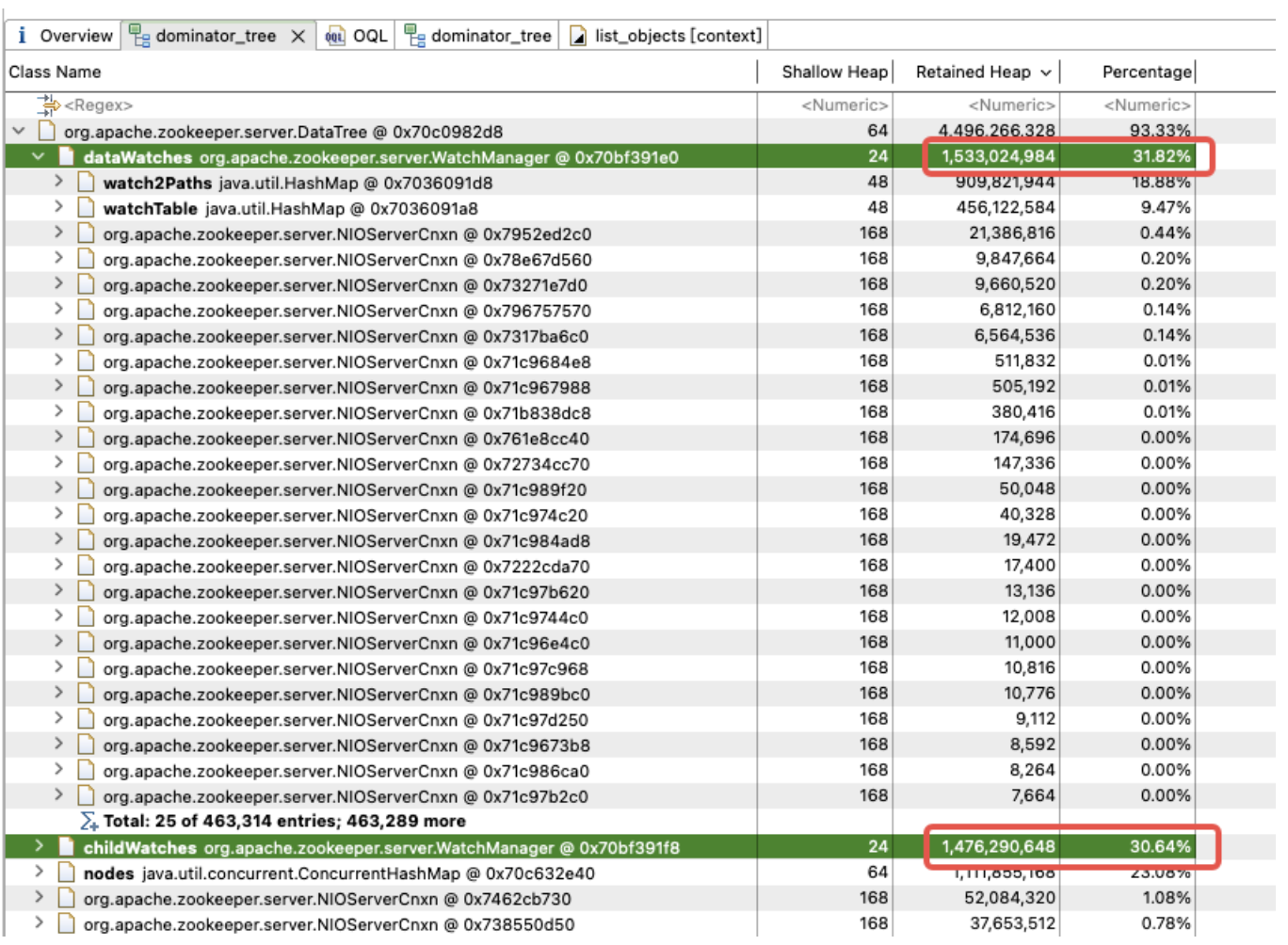
WatchManager를 추가로 분석하면 멤버 변수 Watch2Path 및 WatchTables의 메모리 비율이 (18.88+9.47)/31.82 = 90%만큼 높은 것으로 나타났습니다.
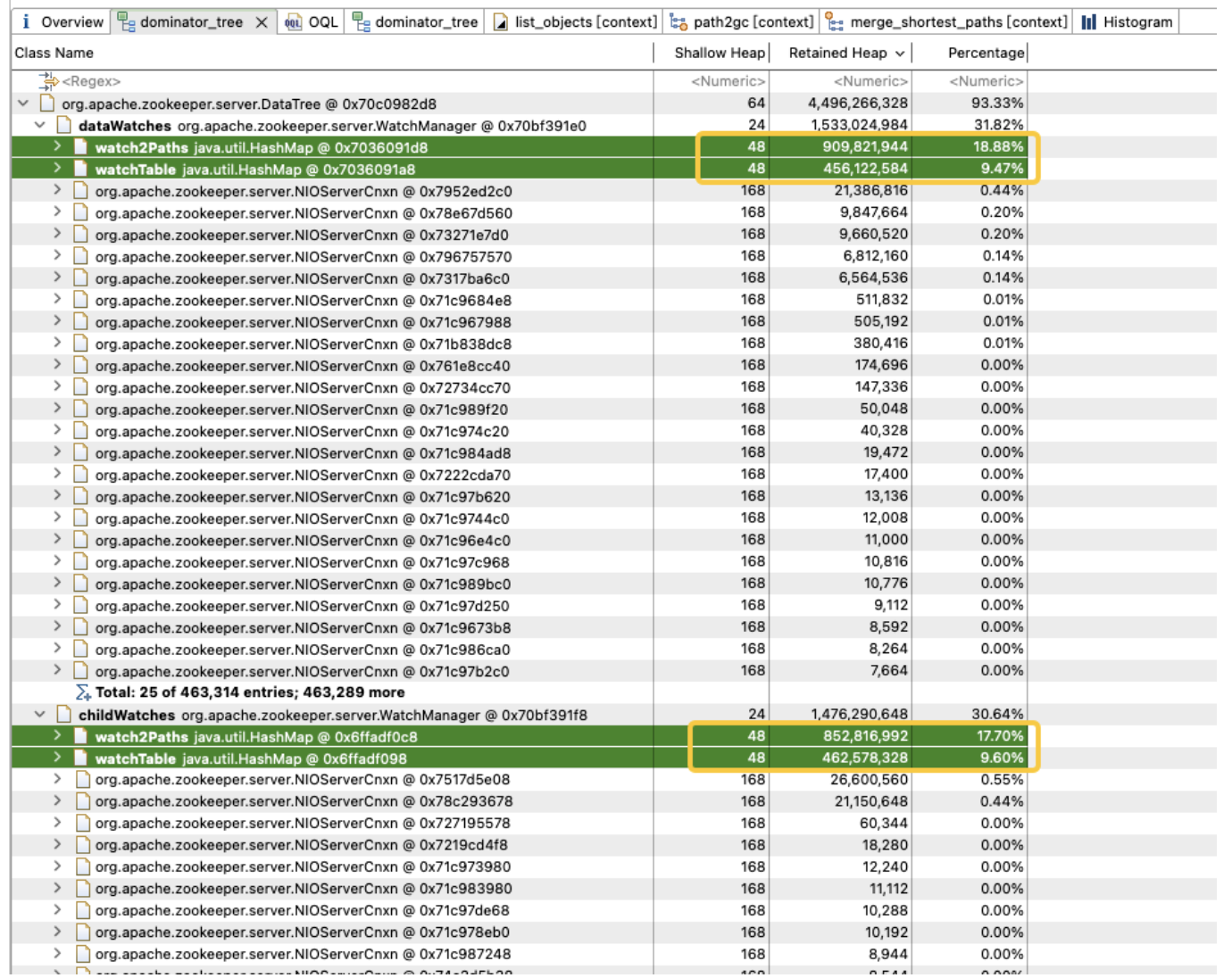
WatchTables와 Watch2Path는 스토리지 구조 다이어그램에 표시된 것처럼 ZNode와 Watcher 간의 정확한 매핑 관계를 저장합니다.
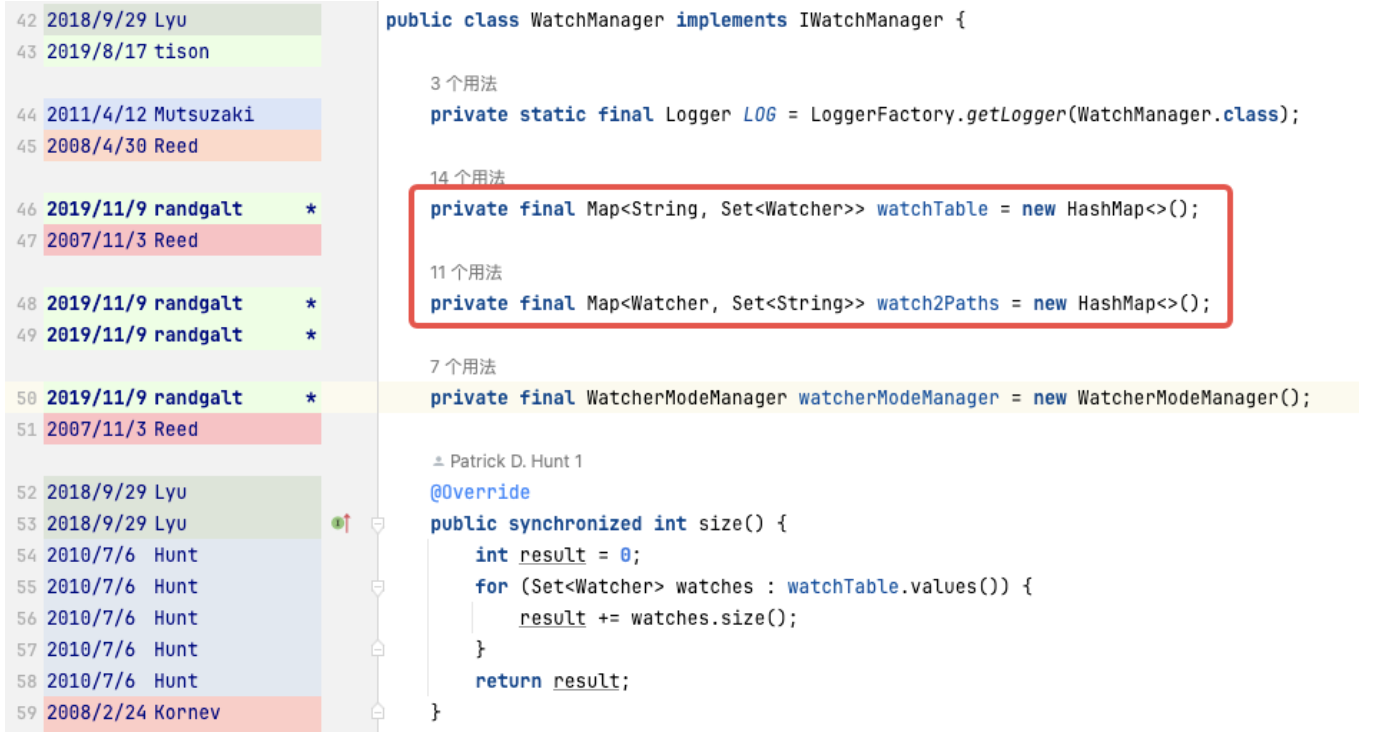
WatchTables [정방향 조회 테이블]
HashMap<ZNode, HashSet<Watcher>>
시나리오: ZNode가 변경되면 ZNode를 구독하는 Watcher가 알림을 받습니다.
논리: 이 ZNode를 사용하여 WatchTables를 통해 해당 Watcher 목록을 모두 찾은 다음 하나씩 알림을 보냅니다.
Watch2Paths [역조회 테이블]
HashMap<감시자, HashSet>
시나리오: 특정 감시자가 구독한 ZNode 계산
논리: 이 Watcher를 사용하여 Watch2Paths를 통해 해당 ZNode 목록을 모두 찾습니다.
Watcher는 기본적으로 NIOServerCnxn이며 연결 세션으로 이해될 수 있습니다.
다수의 ZNode 및 Watcher가 있고 클라이언트가 다수의 ZNode를 구독하는 경우 완전히 구독할 수도 있습니다. 이 두 개의 해시 테이블에 기록된 관계는 기하급수적으로 증가하여 결국 엄청난 양에 도달할 것입니다!
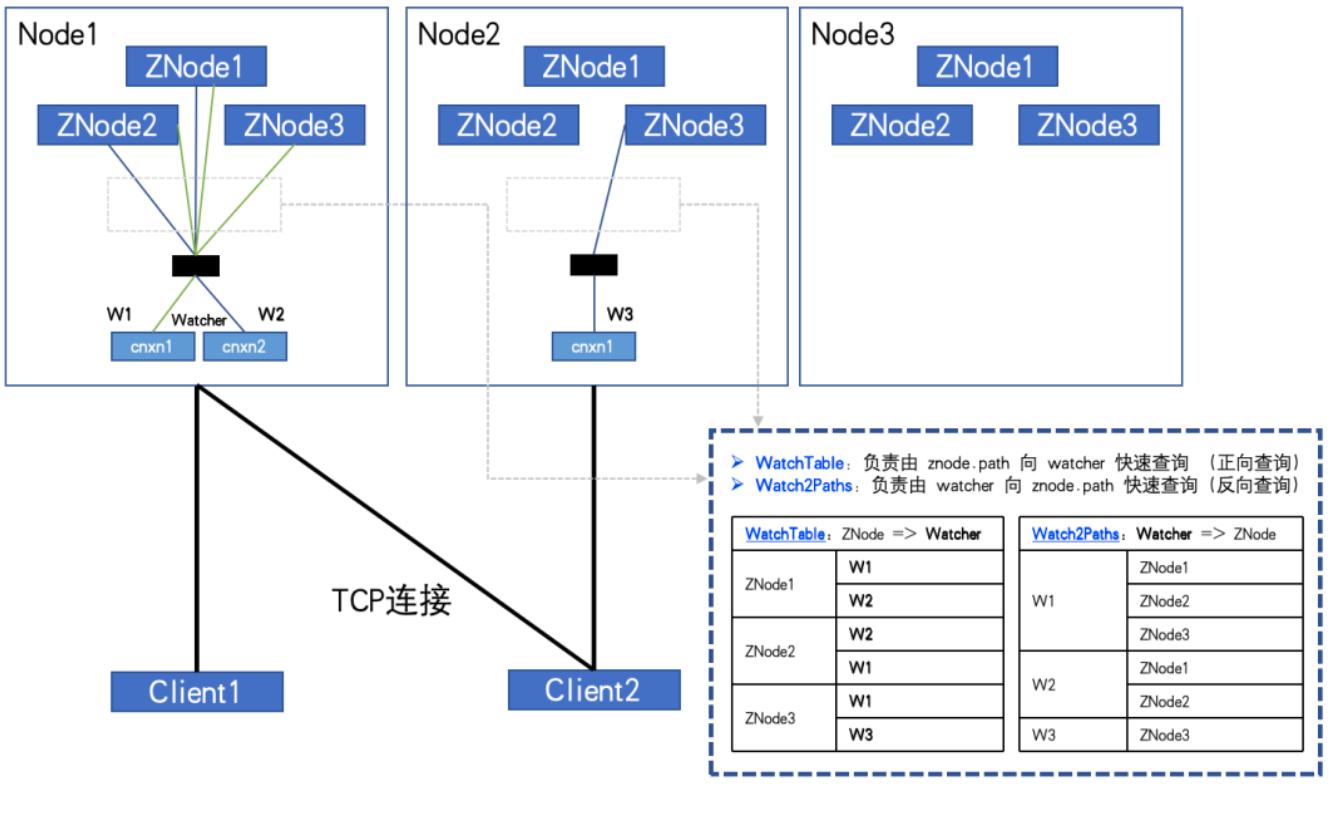
그림과 같이 완전히 구독된 경우:
ZNode 수: 3, Watcher 수: 2, WatchTables 및 Watch2Paths는 각각 6개의 관계를 갖습니다.
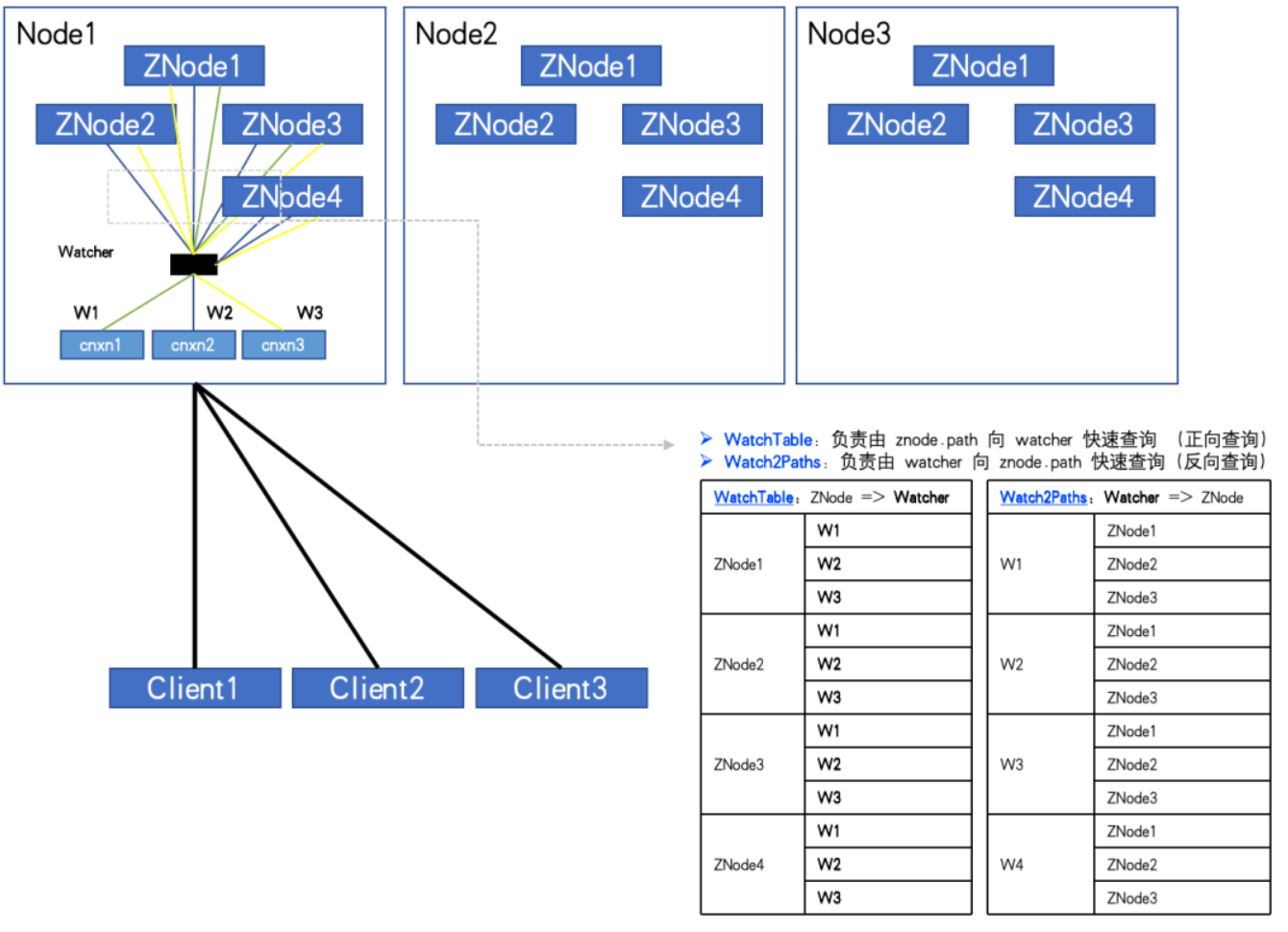
ZNode 수: 4, Watcher 수: 3, WatchTables 및 Watch2Paths는 각각 12개의 관계를 갖습니다.
모니터링 결과 비정상적인 ZK-Node를 발견하였습니다. ZNode의 수는 약 20W이고, Watcher의 수는 5,000명입니다. Watcher와 ZNode 간의 관계 수가 1억 개에 도달했습니다.
각 관계를 저장하기 위해 하나의 HashMap&Node(32Byte)가 필요한 경우 관계 테이블이 2개가 있으므로 두 배로 늘립니다. 그런 다음 다른 것을 계산하지 마십시오. 이 "쉘"에만 2*10000^2*32/1024^3 = 5.9GB의 잘못된 메모리 오버헤드가 필요합니다.
분석의 이 시점에서는 모두가 이해해야 합니다. 왜 우리의 ZK 메모리는 항상 "줄타기"를 하고 종종 OOM이 발생합니까?
뜻밖의 발견
이제 문제의 원인을 확인했으므로 문제를 해결하는 방법을 생각해 보아야 합니다.
위의 분석을 통해 클라이언트가 모든 ZNode를 완전히 구독하는 것을 방지해야 한다는 것을 알 수 있습니다. 그러나 현실은 많은 비즈니스 코드가 ZTree의 루트 노드부터 시작하여 모든 ZNode를 순회하고 이를 완전히 구독하는 논리를 가지고 있다는 것입니다.
일부 비즈니스 당사자에게 개선을 요청하도록 설득할 수는 있지만 모든 비즈니스 당사자의 사용 패턴을 강제할 수는 없습니다. 따라서 이 문제를 해결하기 위한 우리의 접근 방식은 모니터링과 예방에 있습니다. 그러나 안타깝게도 ZK 자체에서는 이러한 기능을 지원하지 않으므로 ZK 소스 코드를 수정해야 합니다.
소스 코드 추적 및 분석을 통해 문제의 소스가 WatchManager를 가리키고 있음을 발견하고 이 클래스의 논리적 세부 사항을 주의 깊게 연구했습니다. 심층적으로 파악한 결과, 이 코드의 품질은 최근 졸업생이 작성한 것으로 보이며 스레드 및 잠금을 부적절하게 사용하는 경우가 많다는 것을 발견했습니다. Git 기록을 살펴보면 이 문제가 2007년으로 거슬러 올라간다는 것을 알 수 있습니다. 그런데 흥미로운 점은 이 시기에 WatchManagerOptimized(2018)가 등장했다는 점입니다. ZK 커뮤니티의 정보를 검색해 보니 [ZOOKEEPER-1177]이 나왔습니다. 즉, 2011년에 ZK 커뮤니티에서는 이미 수많은 Watch가 존재한다는 사실을 깨달았습니다. 메모리 사용량 문제를 일으켰고 마침내 2018년에 솔루션을 제공했습니다. ZK 커뮤니티가 이미 이를 최적화한 것으로 보이는 것은 바로 이 WatchManagerOptimized 때문입니다 .
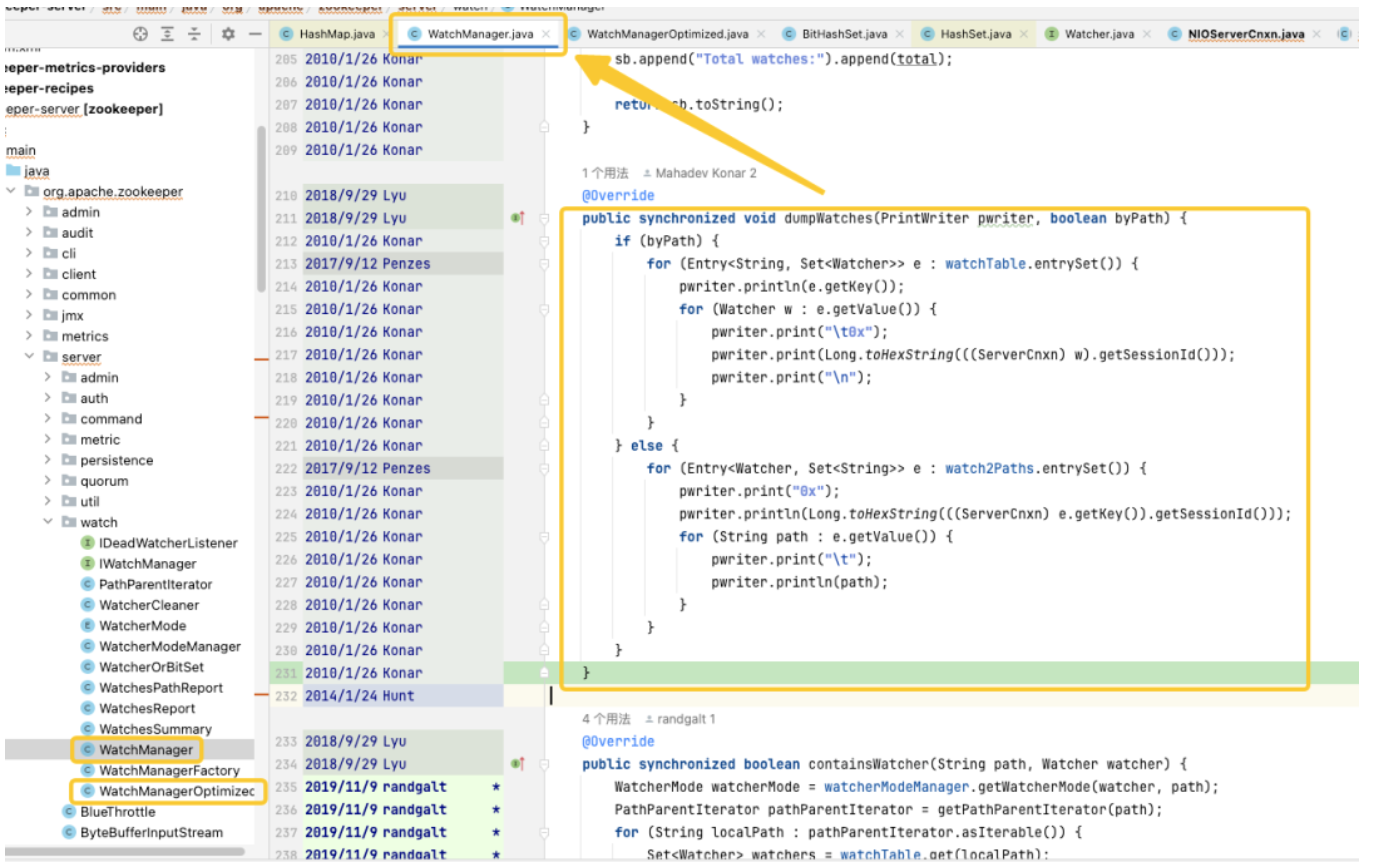
흥미롭게도 ZK는 기본적으로 이 클래스를 활성화하지 않습니다. 심지어 최신 3.9.X 버전에서도 WatchManager가 기본적으로 계속 사용됩니다. 아마도 ZK는 너무 오래되었기 때문에 사람들의 관심이 점차 줄어들고 있습니다. Alibaba의 동료들에게 문의하여 MSE-ZK가 WatchManagerOptimized도 활성화했음을 확인했으며 이를 통해 우리의 초점이 올바른 방향으로 향하고 있음을 확인했습니다. 그러므로 우리는 이 수업의 잠재력을 더 깊이 파고드는 것이 필요하다고 생각했습니다.
탐색 최적화
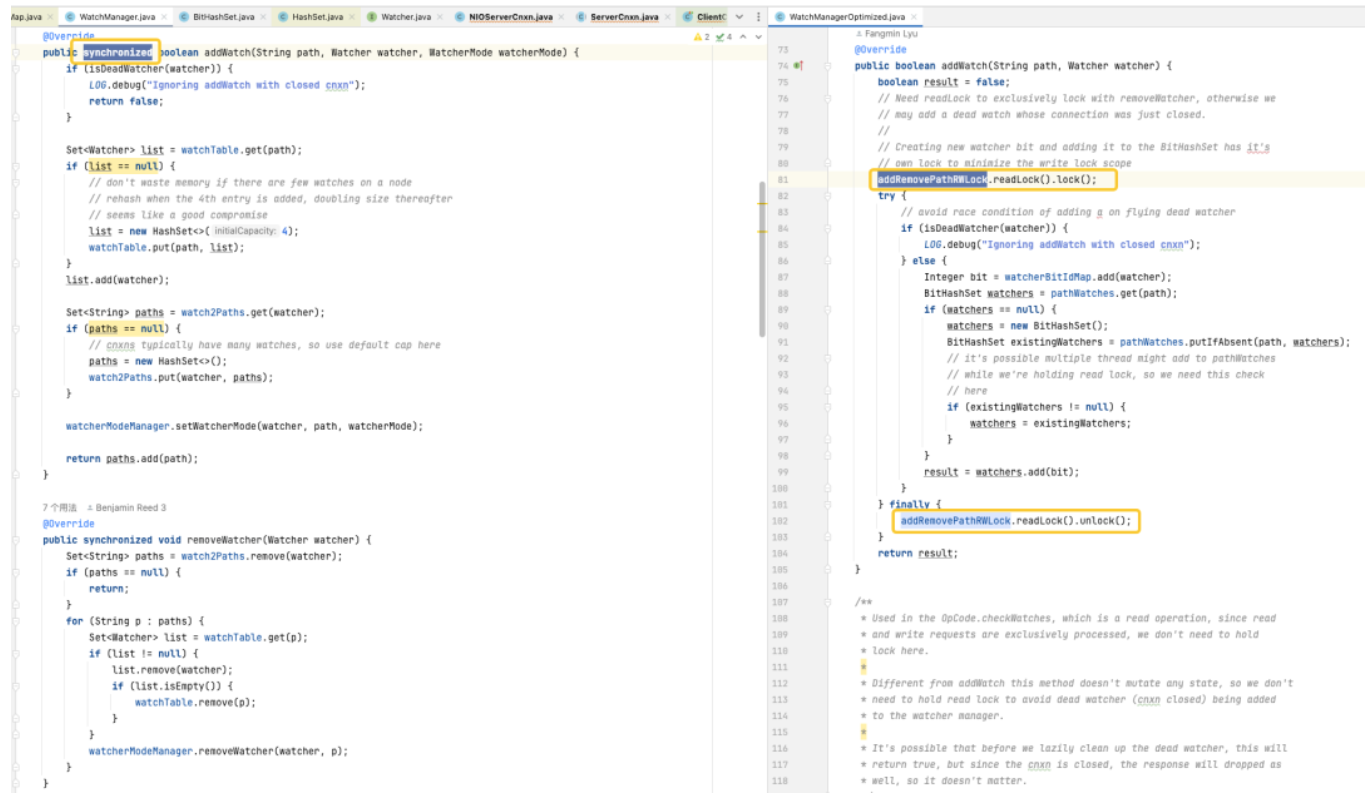
잠금 최적화
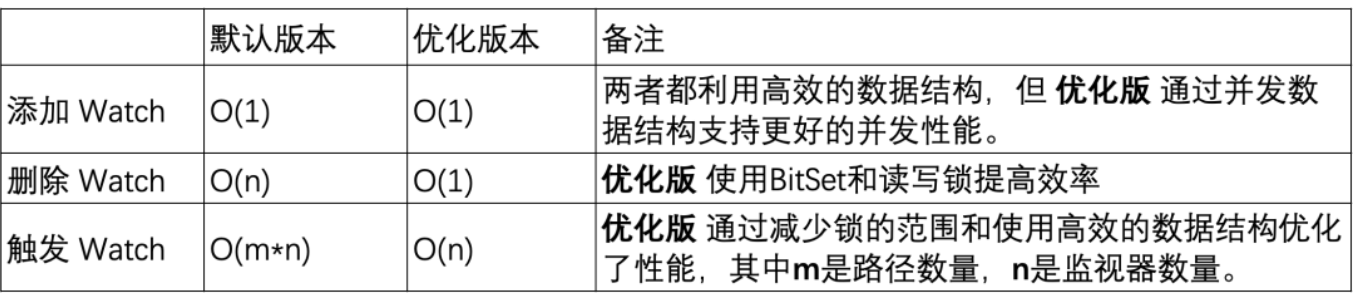
기본 버전에서 사용되는 HashSet은 스레드에 안전하지 않습니다. 이 버전에서는 addWatch, RemoveWatcher 및 TriggerWatch와 같은 관련 작업 메서드가 모두 동기화된 Heavy Lock을 메서드에 추가하여 구현됩니다. 최적화된 버전에서는 ConcurrentHashMap과 ReadWriteLock의 조합을 사용하여 잠금 메커니즘을 보다 세련된 방식으로 사용합니다. 이러한 방식으로 Watch를 추가하고 Watch를 트리거하는 과정에서 보다 효율적인 작업을 수행할 수 있습니다.
스토리지 최적화
이것이 우리의 초점입니다. WatchManager 분석을 통해 WatchTables 및 Watch2Paths 사용 시 저장 효율성이 높지 않음을 알 수 있습니다. ZNode에 구독 관계가 많은 경우 추가로 많은 양의 유효하지 않은 메모리가 소비됩니다.
놀랍게도 WatchManagerOptimized는 여기서 "블랙 기술" -> 비트맵을 사용합니다.
관계형 스토리지는 차원 축소 최적화를 달성하기 위해 비트맵을 사용하여 크게 압축됩니다.
Java BitSet의 주요 기능:
-
공간 효율성: BitSet은 비트 배열을 사용하여 데이터를 저장하므로 표준 부울 배열보다 공간이 덜 필요합니다.
-
빠른 처리: 비트 연산(예: AND, OR, XOR, 뒤집기)을 수행하는 것이 해당 부울 논리 연산보다 빠른 경우가 많습니다.
-
동적 확장: BitSet의 크기는 더 많은 비트를 수용하기 위해 필요에 따라 동적으로 커질 수 있습니다.
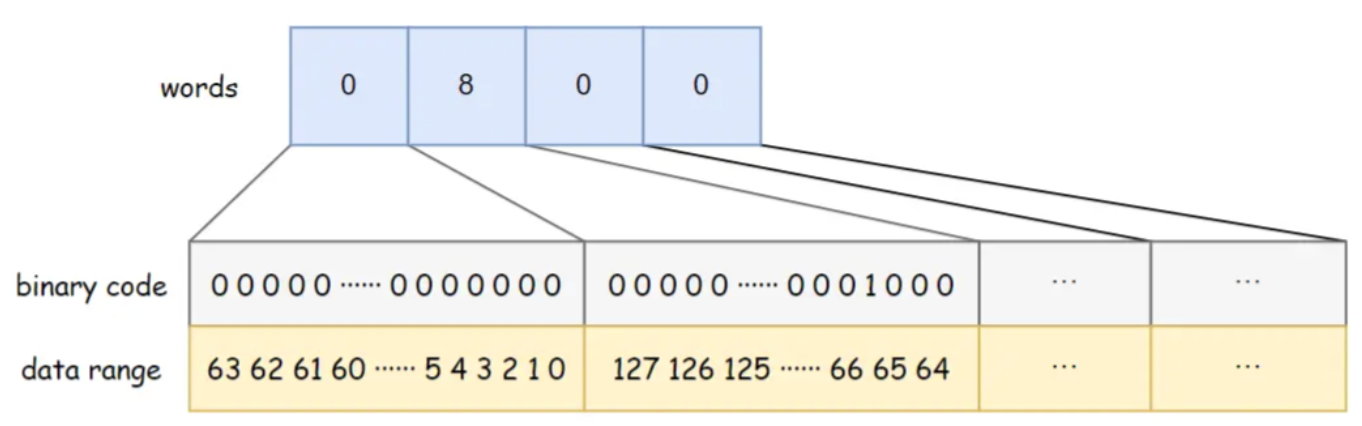
BitSet은 long[] 단어를 사용하여 데이터를 저장합니다. long 유형은 8바이트를 차지하고 64비트입니다 . 배열의 각 요소는 64 개의 데이터를 저장할 수 있습니다. 배열의 데이터 저장 순서는 왼쪽에서 오른쪽으로, 낮은 것에서 높은 것입니다 .
예를 들어, 아래 그림의 BitSet은 워드 용량이 4입니다. 낮은 것부터 높은 것까지의 워드[0]은 데이터 0~63이 존재하는지를 나타내고, 낮은 것부터 높은 것까지의 워드[1]은 64~127의 데이터가 존재하는지를 나타냅니다. 에. 그 중 word[1] = 8이고 해당 바이너리 비트 8은 1로, 이때 BitSet에 저장된 데이터 {67}이 있음을 나타낸다.
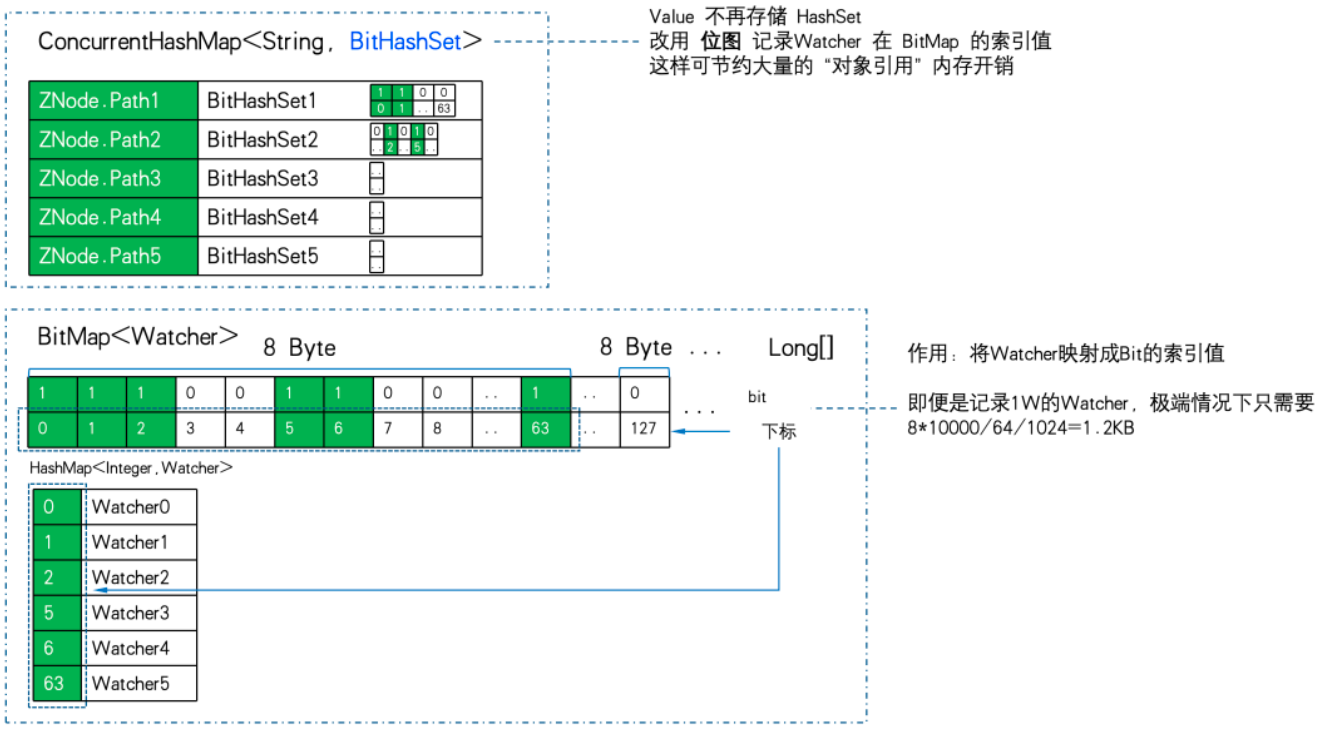
WatchManagerOptimized는 BitMap을 사용하여 모든 감시자를 저장합니다. 이런 식으로 1W Watcher가 있어도 마찬가지다. 비트맵의 메모리 소비는 8Byte*1W/64/1024= 1.2KB 에 불과합니다 . HashSet으로 바꾸면 최소 32Byte*10000/1024=305KB가 필요하고, 저장 효율도 300배 가까이 달라집니다.
WatchManager.java:private final Map<String, Set<Watcher>> watchTable = new HashMap<>();private final Map<Watcher, Set<String>> watch2Paths = new HashMap<>();
WatchManagerOptimized.java:private final ConcurrentHashMap<String, BitHashSet> pathWatches = new ConcurrentHashMap<String, BitHashSet>();private final BitMap<Watcher> watcherBitIdMap = new BitMap<Watcher>();
ZNode에서 Watcher로의 매핑 저장소가 Map<string, set>에서 ConcurrentHashMap<string, BitHashSet >으로 변경되었습니다. 즉, Set은 더 이상 저장되지 않지만 비트맵은 비트맵 인덱스 값을 저장하는 데 사용됩니다.
우리는 1W ZNode, 1W Watcher를 사용하고 극단적인 사용에서는 전체 구독(모든 Watcher가 모든 ZNode에 구독)을 사용 하여 스토리지 효율성 PK를 수행합니다.

11.7MB PK 5.9GB , 메모리 저장 효율 차이는 516배임을 알 수 있습니다 .
논리 최적화
-
모니터 추가: 두 버전 모두 일정한 시간에 작업을 완료할 수 있지만 최적화된 버전은 ConcurrentHashMap 을 사용하여 더 나은 동시성 성능을 제공합니다 .
-
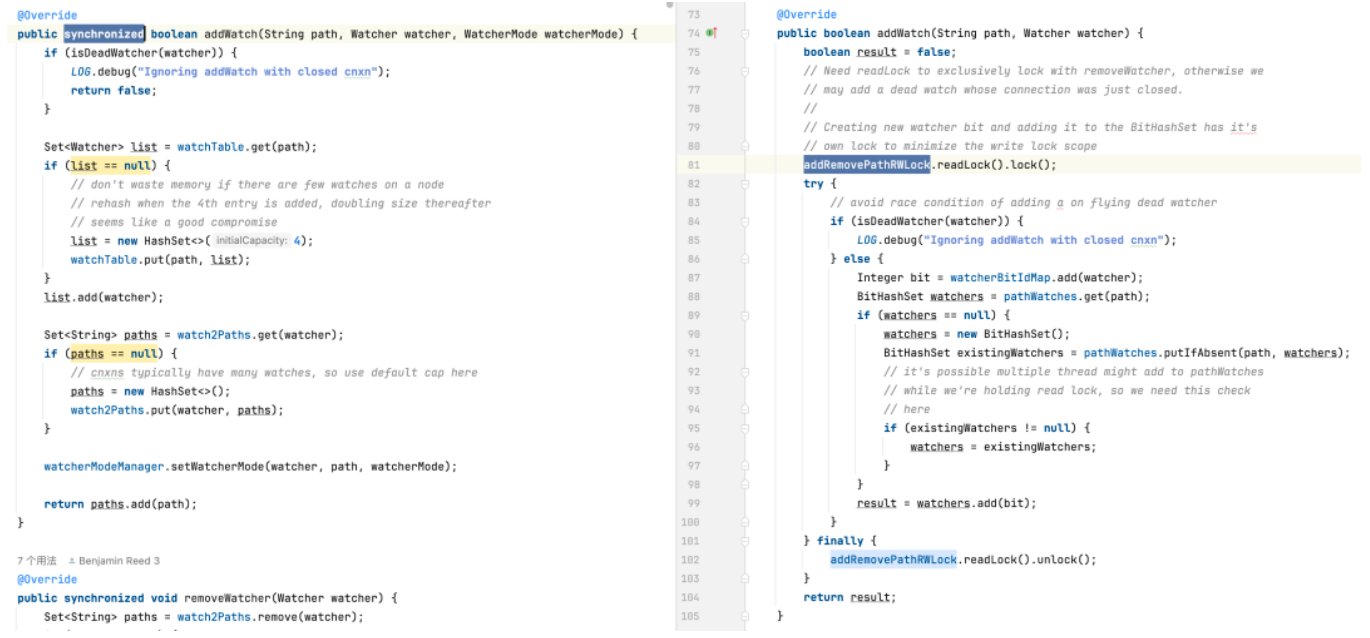
모니터 삭제: 기본 버전은 모니터를 찾아 삭제하기 위해 전체 모니터 컬렉션을 순회해야 할 수 있으므로 O(n)의 시간 복잡도가 발생합니다. 최적화된 버전은 BitSet 및 ConcurrentHashMap을 사용하여 대부분의 경우 O(1)에서 모니터를 빠르게 찾고 삭제합니다.
-
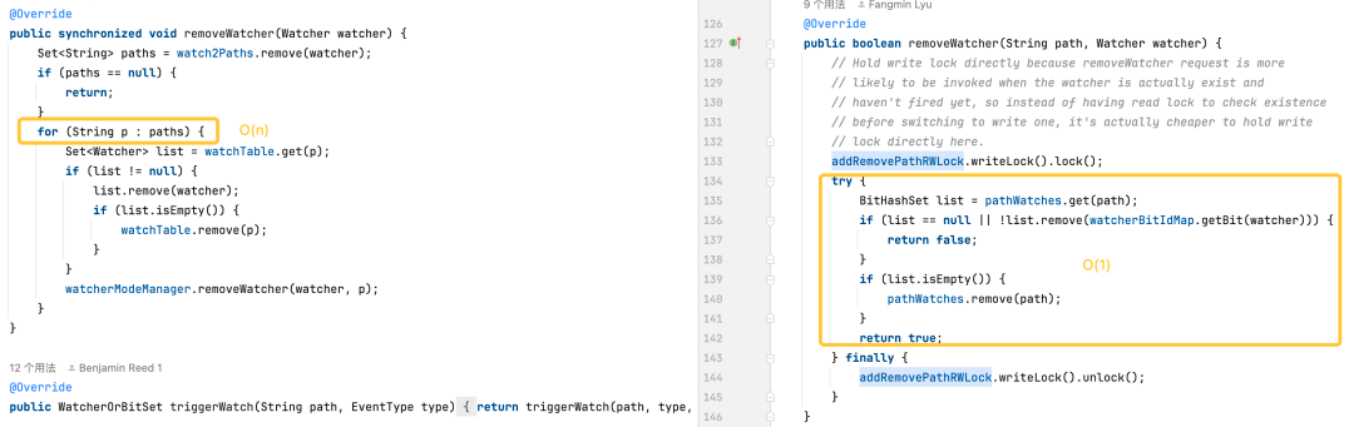
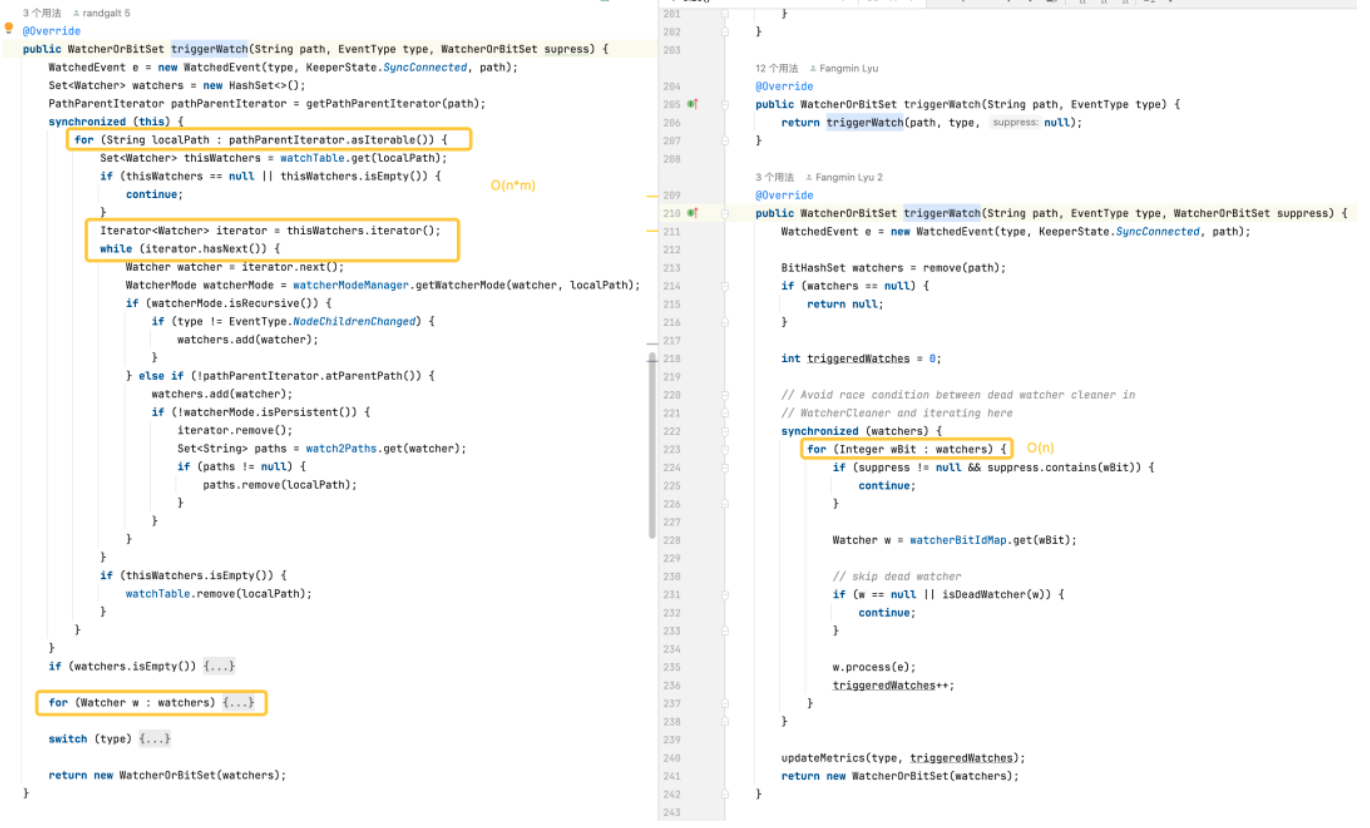
모니터 트리거: 기본 버전은 모든 경로의 모든 모니터에 대한 작업이 필요하기 때문에 더 복잡합니다. 최적화된 버전은 보다 효율적인 데이터 구조와 잠금 사용량 감소를 통해 트리거 모니터의 성능을 최적화합니다.
3. 성능 스트레스 테스트
JMH 마이크로벤치마크
Zookeeper 3.6.4 소스 코드 컴파일, JMH micor 스트레스 테스트 WatchBench.
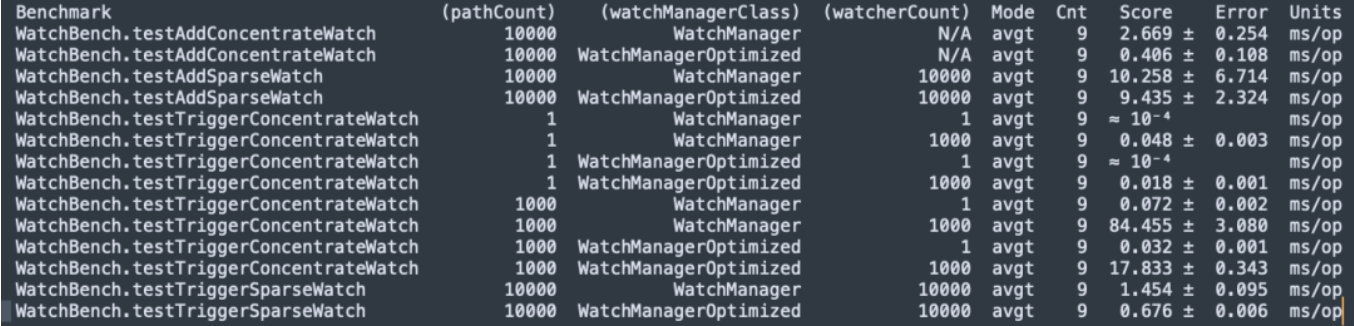
pathCount: 테스트에 사용된 ZNode 경로 수를 나타냅니다.
watchManagerClass: 테스트에 사용된 WatchManager 구현 클래스를 나타냅니다.
watcherCount: 테스트에 사용된 관찰자(Watcher)의 수를 나타냅니다.
모드: 테스트 모드를 나타냅니다. 여기서는 평균 실행 시간을 나타내는 avgt입니다.
Cnt: 테스트 실행 횟수를 나타냅니다.
점수: 테스트 점수, 즉 평균 실행 시간을 나타냅니다.
오류: 점수의 오류 범위를 나타냅니다.
단위: 점수를 나타내는 단위로, 여기서는 밀리초/작업(ms/op)입니다.
-
ZNode와 Watcher 사이에는 1백만 개의 구독이 있습니다. 기본 버전은 50MB를 사용하고, 최적화된 버전은 0.2MB만 필요하며 선형적으로 증가하지 않습니다.
-
Watch를 추가하면 최적화 버전(0.406ms/op)이 기본 버전(2.669ms/op)보다 6.5배 빠릅니다.
-
다수의 Watch가 트리거되며 최적화된 버전(17.833ms/op)은 기본 버전(84.455ms/op)보다 5배 빠릅니다.
성능 스트레스 테스트
다음으로, 용량 스트레스 테스트 비교를 수행하기 위해 최적화된 버전과 기본 버전을 사용하여 머신(32C 60G)에 3노드 Zookeeper 3.6.4 세트를 구축했습니다.
시나리오 1: 20W znode 짧은 경로
Znode 짧은 경로: /demo/znode1

시나리오 2: 20W znode 긴 경로
Znode 긴 경로: /sentinel-cluster/dev/xx-admin-interfaces/lock/_c_bb0832d5-67a5-48ab-8fe0-040b9ddea-lock/12

-
Watch 메모리 사용량은 ZNode의 경로 길이와 관련이 있습니다.
-
Watch의 수는 기본 버전에서 선형적으로 증가하고 최적화된 버전에서 매우 좋은 성능을 발휘합니다. 이는 메모리 사용량 최적화에 있어서 매우 확실한 개선입니다.
그레이스케일 테스트
이전 벤치마크 테스트 및 용량 테스트를 기반으로 최적화된 버전은 수많은 Watch 시나리오에서 메모리 최적화가 확실했습니다. 다음으로 테스트 환경에서 ZK 클러스터에 대한 그레이스케일 업그레이드 테스트 관찰을 시작했습니다.
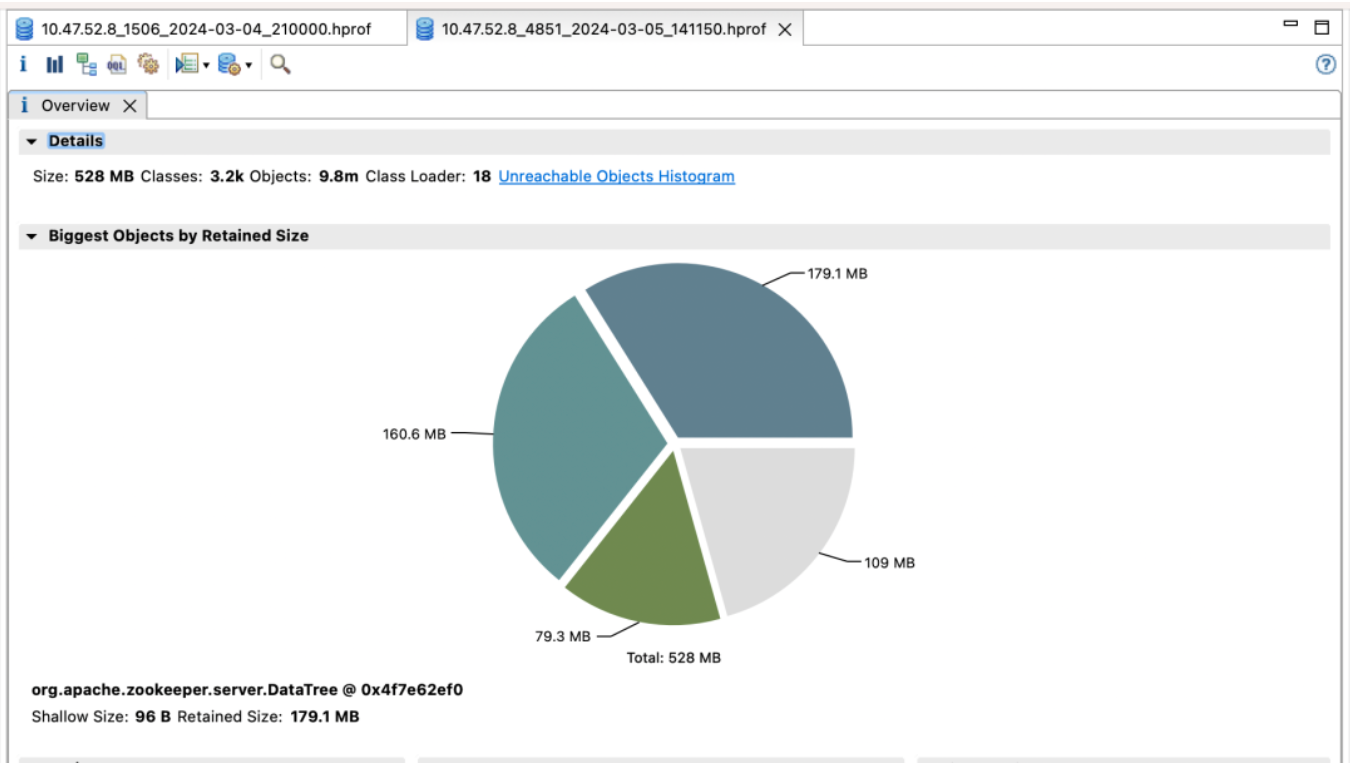
최초의 사육사 클러스터 및 혜택

기본 버전
최적화된 버전
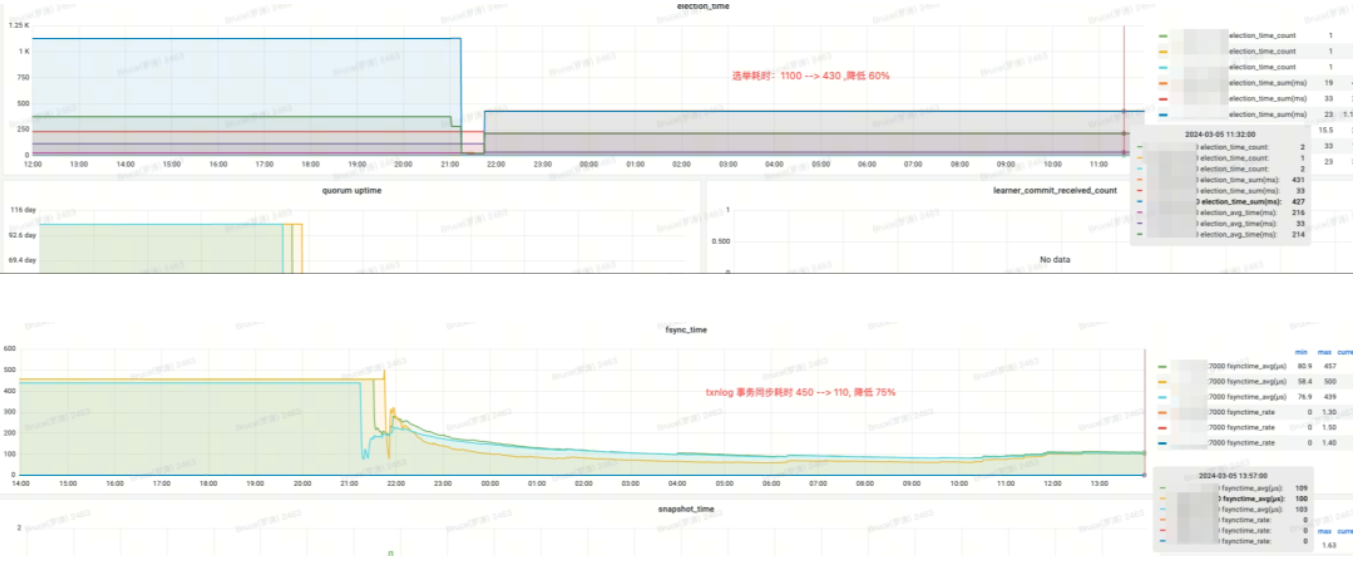
효과 수입:
-
Election_time(선거 시간): 60% 감소
-
fsync_time(트랜잭션 동기화 시간): 75% 감소
-
메모리 사용량: 91% 감소
두 번째 사육사 클러스터 및 혜택
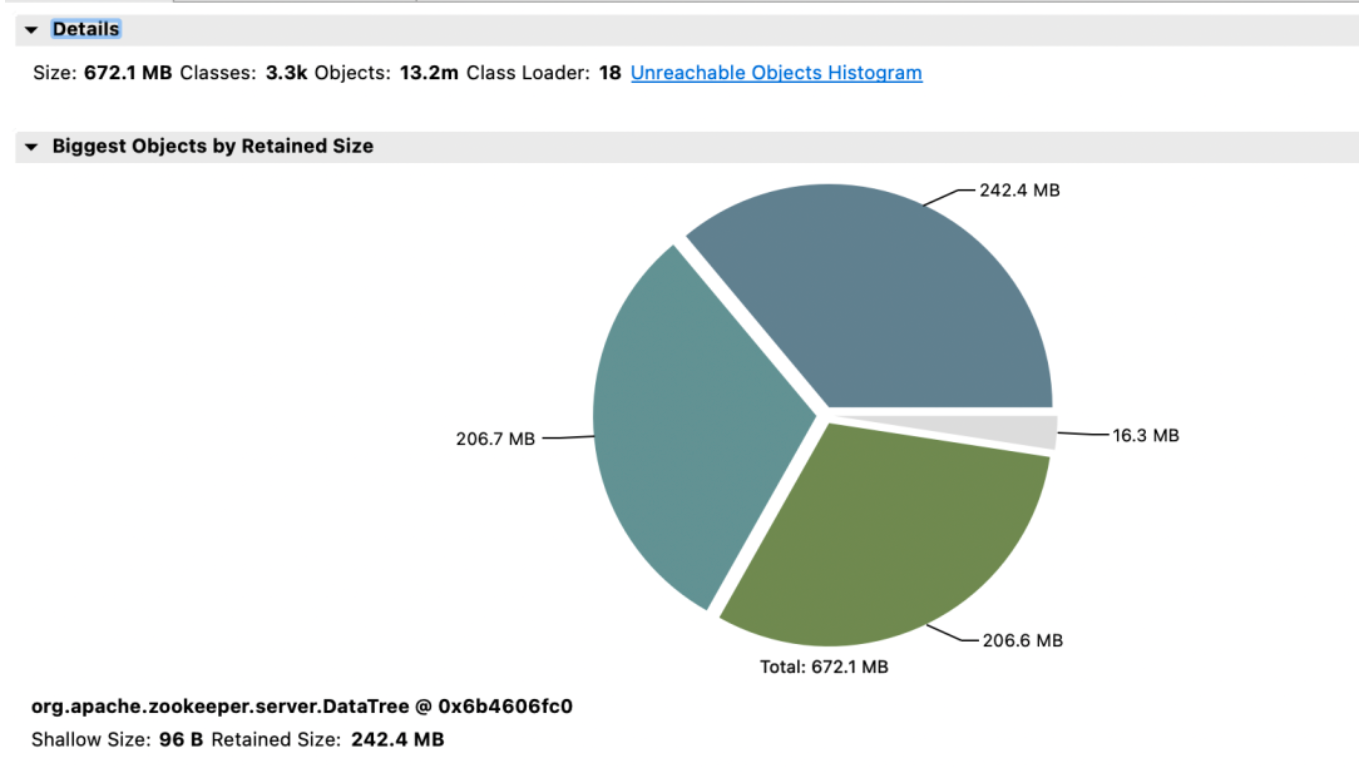
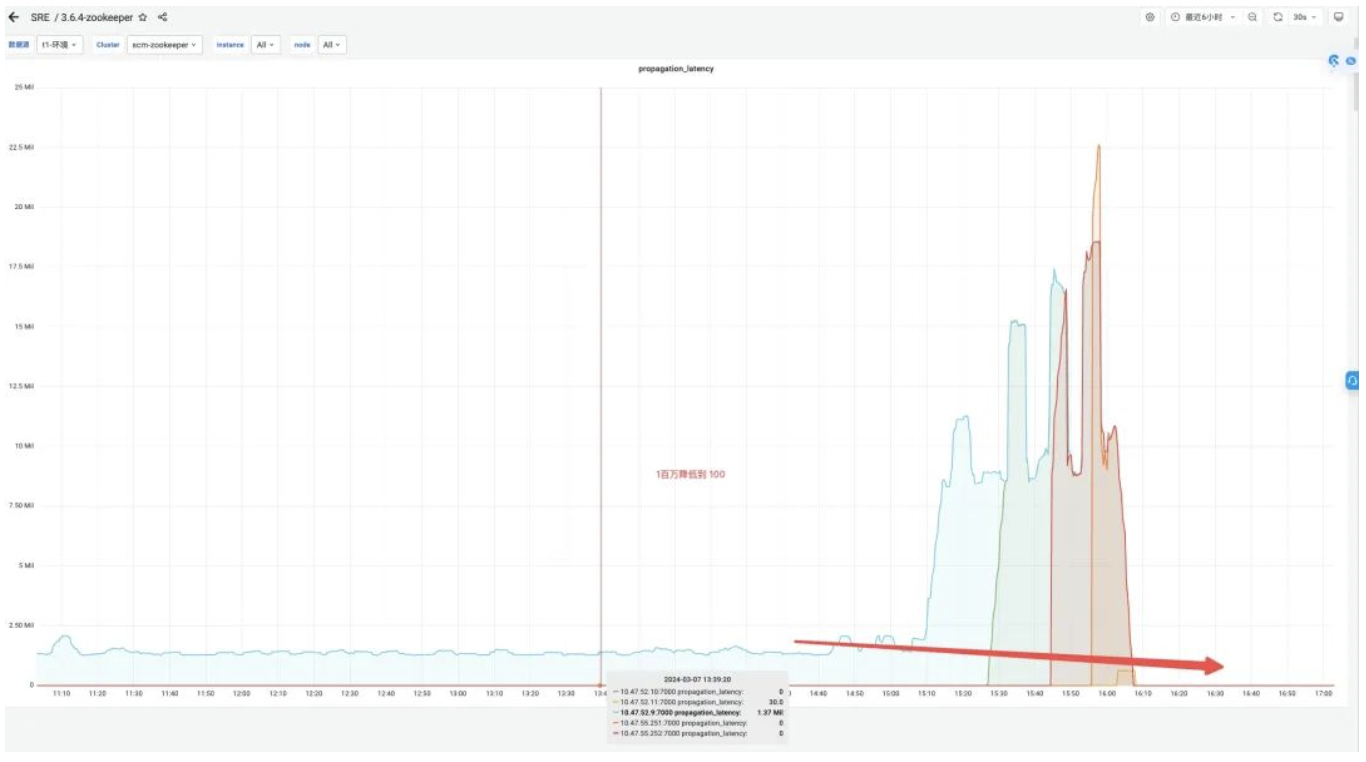
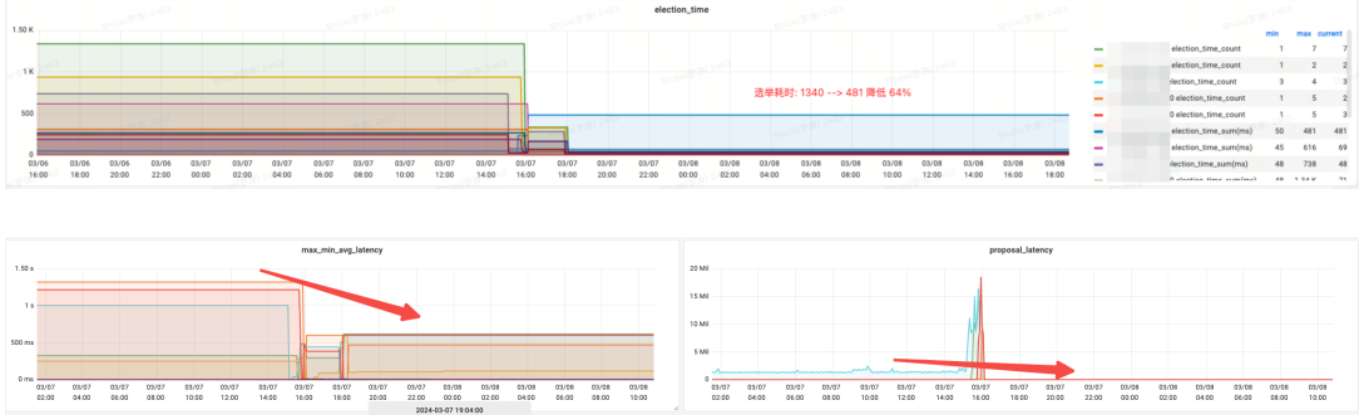
효과 수입:
-
메모리: 변경 전에는 JVM Attach 응답이 응답하지 않아 데이터 수집에 실패했습니다.
-
Election_time(선거 시간): 64% 감소.
-
max_latency(읽기 대기 시간): 53% 감소했습니다.
-
Proposal_latency(선거 처리 제안 지연): 1400000ms --> 43ms.
-
propagation_latency(데이터 전파 지연): 1400000ms --> 43ms.
세 번째 사육사 클러스터 및 혜택 세트
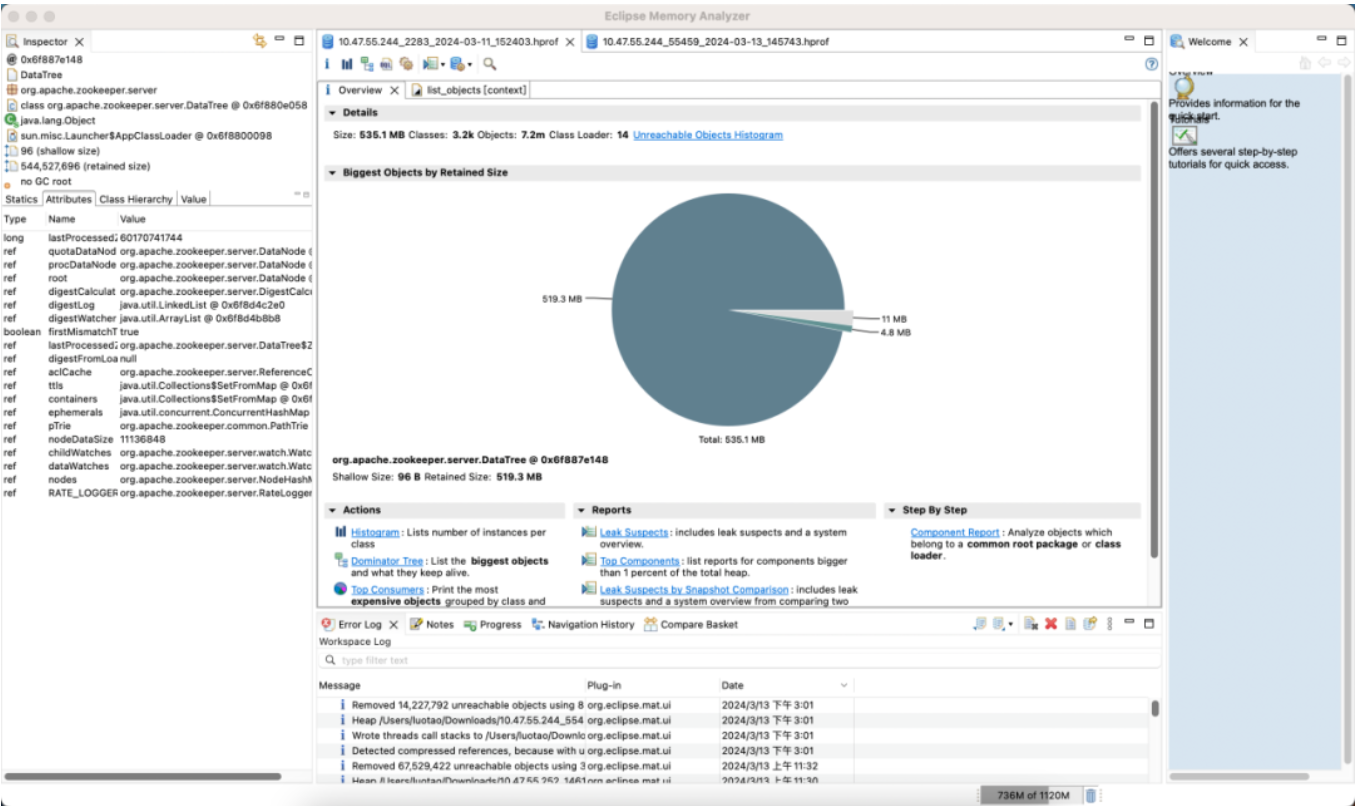
기본 버전
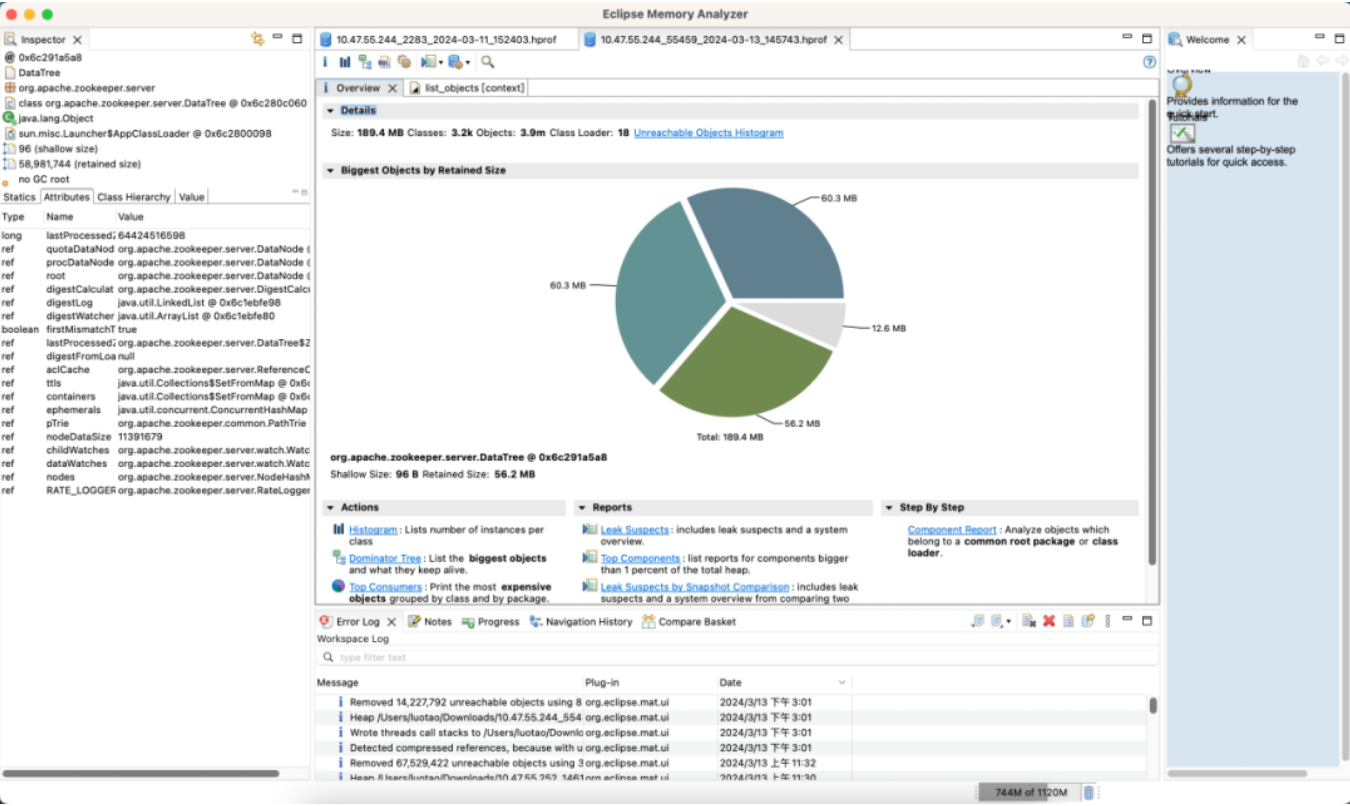
최적화된 버전
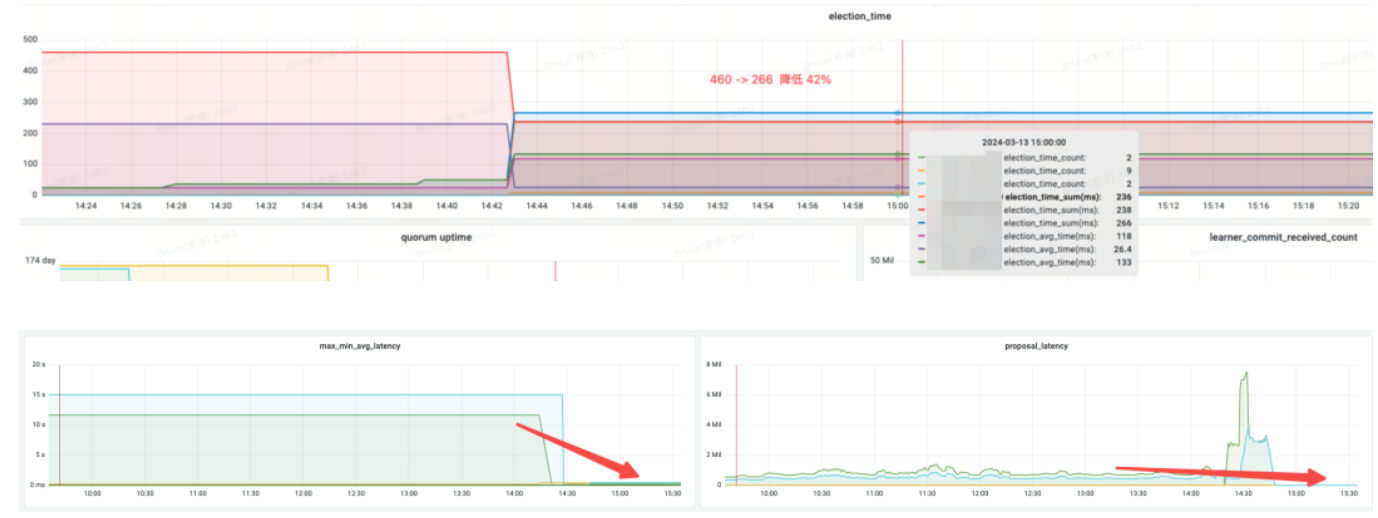
효과 수입:
-
메모리: 89% 절약
-
Election_time(선거 시간): 42% 감소
-
max_latency(읽기 지연 시간): 95% 감소
-
Proposal_latency(선거 처리 제안 지연): 679999ms --> 0.3ms
-
propagation_latency(데이터 전파 지연): 928000ms--> 5ms
4. 요약
이전 벤치마크 테스트, 성능 스트레스 테스트 및 그레이스케일 테스트를 통해 Zookeeper의 WatchManagerOptimized를 발견했습니다. 이러한 최적화는 메모리를 절약할 뿐만 아니라 잠금 최적화를 통해 노드 간 선택 및 데이터 동기화와 같은 지표를 크게 향상시켜 Zookeeper의 일관성을 향상시킵니다. 우리는 또한 Alibaba MSE의 학생들과 심도 있는 논의를 통해 극단적인 시나리오에서 시뮬레이션된 스트레스 테스트를 진행하고 다음과 같은 합의에 도달했습니다. WatchManagerOptimized는 Zookeeper의 안정성을 크게 향상시킵니다. 전반적으로 이 최적화는 Zookeeper의 SLA를 몇 배나 향상시킵니다.
ZooKeeper에는 다양한 구성 옵션이 있지만 대부분의 경우 조정이 필요하지 않습니다. 시스템 안정성을 향상하려면 다음 구성 최적화를 권장합니다.
-
dataDir(데이터 디렉터리)과 dataLogDir(트랜잭션 로그 디렉터리)를 각각 다른 디스크에 마운트하고 고성능 블록 스토리지를 사용합니다.
-
ZooKeeper 버전 3.8의 경우 JDK 17을 사용하고 ZGC 가비지 수집기를 활성화하는 것이 좋습니다. 버전 3.5 및 3.6에서는 JDK 8을 사용하고 G1 가비지 수집기를 활성화하는 것이 좋습니다. 이러한 버전의 경우 -Xms 및 -Xmx를 구성하기만 하면 됩니다.
-
SnapshotCount 매개변수 기본값인 100,000~500,000을 조정하면 ZNode가 높은 빈도로 변경될 때 디스크 압력을 크게 줄일 수 있습니다.
-
Watch Manager WatchManagerOptimized의 최적화된 버전을 사용하세요.
참조 :
https://issues.apache.org/jira/browse/ZOOKEEPER-1177
https://github.com/apache/zookeeper/pull/590
*텍스트/ 브루스
이 기사는 Dewu Technology의 원본입니다. 더 흥미로운 기사를 보려면 Dewu Technology 공식 웹사이트를 참조하세요.
Dewu Technology의 허가 없이 전재하는 것은 엄격히 금지되어 있으며, 그렇지 않을 경우 법에 따라 법적 책임을 추궁할 것입니다!
JetBrains 2024(2024.1)의 첫 번째 메이저 버전 업데이트는 오픈소스 인데 Microsoft도 비용을 지불할 계획인데 아직도 오픈소스라는 비판을 받는 이유는 무엇일까요? [복구] Tencent Cloud 백엔드 충돌: 콘솔에 로그인한 후 많은 서비스 오류가 발생하고 데이터가 없습니다. 독일도 "독립적으로 제어 가능"해야 합니다. 주 정부는 30,000대의 PC를 Windows에서 Linux deep-IDE로 마이그레이션하여 마침내 달성했습니다. 부트스트래핑! Visual Studio Code 1.88이 출시되었습니다. Tencent는 Switch를 "생각하는 학습 기계"로 전환했습니다. RustDesk 원격 데스크톱이 시작되고 웹 클라이언트를 재구성합니다. WeChat의 SQLite 기반 오픈 소스 터미널 데이터베이스인 WCDB가 크게 업그레이드되었습니다.