배경소개하다
GPU는 현재 iQiyi 딥러닝 플랫폼에서 널리 사용되고 있습니다. GPU는 수백, 수천 개의 처리 코어를 갖고 있어 수많은 명령을 병렬로 실행할 수 있어 딥러닝 관련 계산에 매우 적합합니다. GPU는 CV(컴퓨터 비전) 및 NLP(자연어 처리) 모델에 널리 사용되어 왔으며, CPU에 비해 일반적으로 모델 훈련 및 추론을 더 빠르고 경제적으로 완료할 수 있습니다.
CTR(Click Trough Rate) 모델은 사용자가 광고나 동영상을 클릭할 확률을 추정하기 위해 추천, 광고, 검색 및 기타 시나리오에서 널리 사용됩니다. GPU는 CTR 모델의 훈련 시나리오에 광범위하게 사용되어 훈련 속도를 향상시키고 필요한 서버 비용을 줄입니다.
그러나 추론 시나리오에서 훈련된 모델을 Tensorflow-serving을 통해 GPU에 직접 배포하면 추론 효과가 이상적이지 않다는 것을 알 수 있습니다. 다음에 나타납니다:
-
추론 지연 시간은 일반적으로 최종 사용자 중심이며 추론 지연 시간에 매우 민감합니다.
-
GPU 활용도가 낮고 컴퓨팅 성능이 완전히 활용되지 않습니다.
원인 분석
분석 도구
-
텐서플로우에서 공식적으로 제공하는 도구인 텐서플로우 보드(Tensorflow Board)는 각 단계에서 소요되는 시간을 계산 흐름 그래프로 시각적으로 확인하고, 운영자의 전체 소요 시간을 요약할 수 있습니다.
-
Nsight는 CUDA 개발자를 위해 NVIDIA에서 제공하는 개발 도구 모음으로, CUDA 프로그램의 상대적으로 낮은 수준의 추적, 디버깅 및 성능 분석을 수행할 수 있습니다.
분석 결론
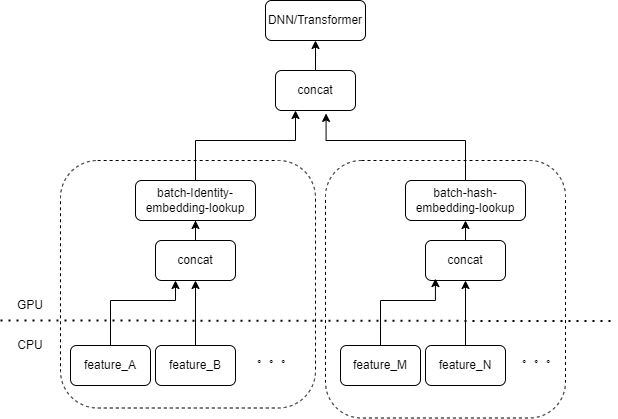
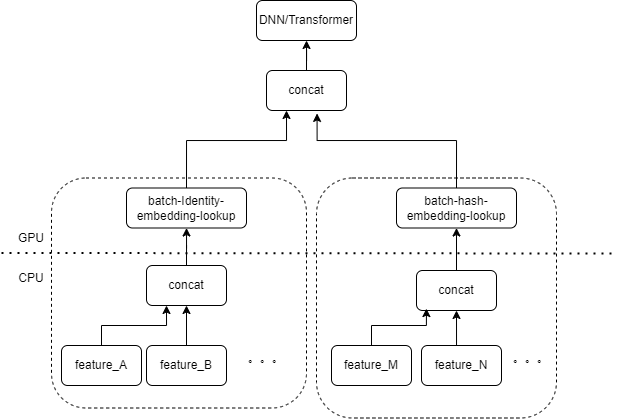
일반적인 CTR 모델 입력에는 다수의 희소 기능(예: 장치 ID, 최근 본 동영상 ID 등)이 포함되어 있습니다. Tensorflow의 FeatureColumn은 이러한 기능을 처리합니다. 먼저, 임베딩 테이블의 인덱스를 얻기 위해 ID/해시 작업이 수행됩니다. 임베딩 조회 및 평균화 작업 후에 해당 임베딩 텐서를 얻습니다. 여러 기능에 해당하는 임베딩 텐서를 접합한 후 새로운 텐서를 얻은 다음 후속 DNN/Transformer 및 기타 구조에 들어갑니다.
따라서 각 희소 기능은 모델의 입력 레이어에서 여러 연산자를 활성화합니다. 각 연산자는 하나 이상의 GPU 계산, 즉 cuda 커널에 해당합니다. 각 cuda 커널에는 cuda 커널 시작(커널을 시작하는 데 필요한 오버헤드)과 커널 실행(실제로 cuda 코어에서 행렬 계산 수행)의 두 단계가 포함됩니다. 희소 특성 ID/해시/임베딩 조회에 해당하는 연산자는 계산량이 적고 실행 커널이 커널 실행 시간보다 더 많은 시간이 걸리는 경우가 많습니다. 일반적으로 CTR 모델에는 수십에서 수백 개의 희소한 기능이 포함되어 있으며 이론적으로는 수백 개의 출시 커널이 있을 것이며 이는 현재 주요 성능 병목 현상입니다.
GPU를 사용하여 CTR 모델을 학습할 때는 이 문제가 발생하지 않았습니다. 훈련 자체는 오프라인 작업이고 지연에 주의를 기울이지 않기 때문에 훈련 중 배치 크기가 매우 클 수 있습니다. 실행 커널은 여전히 여러 번 수행되지만, 커널 실행 시 계산된 샘플 수가 충분히 크면 실행 커널의 각 샘플에 소요되는 평균 시간은 매우 작습니다. 온라인 추론 시나리오의 경우 Tensorflow Serving이 계산을 수행하기 전에 충분한 추론 요청을 수신하고 배치를 병합해야 하는 경우 추론 지연 시간이 매우 길어집니다.
최적화
우리의 목표는 훈련 코드나 서비스 프레임워크를 기본적으로 변경하지 않고 성능을 최적화하는 것입니다. 우리는 자연스럽게 시작되는 커널 수를 줄이는 것과 커널 시작 속도를 높이는 두 가지 방법을 생각합니다.
오퍼레이터 융합
기본 작업은 여러 연속 작업 또는 연산자를 단일 연산자로 병합하는 것입니다. 한편으로는 Cuda 커널 시작 횟수를 줄일 수 있는 반면, 계산 프로세스 중 일부 중간 결과는 레지스터에 저장되거나 공유될 수 있습니다. 메모리 및 계산에서만 하위 섹션이 끝나면 계산 결과가 전역 cuda 메모리에 기록됩니다.
-
-
자동 융합
우리는 TVM/TensorRT/XLA와 같은 다양한 딥러닝 컴파일러를 시도했으며 실제 테스트에서는 연속 MatrixMat/ADD/Relu와 같은 DNN의 소수 연산자의 융합을 달성할 수 있습니다. TVM/TensorRT는 onnx와 같은 중간 형식을 내보내야 하기 때문에 원본 모델의 온라인 프로세스를 수정해야 합니다. 그래서 우리는 융합을 위해 tensorflow의 내장 XLA를 활성화하기 위해 tf.ConfigProto()를 사용합니다.
그러나 자동 융합은 희소 특징과 관련된 연산자에 대해서는 좋은 융합 효과를 나타내지 않습니다.
수동 작업자 융합
입력 레이어에 동일한 유형의 FeatureColumn 조합으로 처리되는 여러 기능이 있는 경우 여러 기능의 입력을 연산자의 입력으로 배열로 연결하는 연산자를 구현할 수 있다고 자연스럽게 생각합니다. 연산자의 출력은 텐서이며, 이 텐서의 모양은 원래의 특징을 별도로 계산한 후 이를 결합하여 얻은 텐서의 모양과 일치합니다.
원래 IdentityCategoricalColumn + EmbeddingColumn 조합을 예로 들어 BatchIdentiyEmbeddingLookup 연산자를 구현하여 동일한 계산 논리를 달성했습니다.
알고리즘 학생들의 사용을 용이하게 하기 위해 우리는 융합 연산자를 포함하는 것 외에도 기본 FeatureLayer를 대체하기 위해 새로운 FusedFeatureLayer를 캡슐화했으며 다음 논리도 구현되었습니다.
-
융합된 논리는 추론 중에 적용되고, 원래 논리는 훈련 중에 사용됩니다.
-
동일한 유형의 기능을 함께 정렬할 수 있도록 기능을 정렬해야 합니다.
-
각 기능의 입력은 가변 길이이므로 여기서는 입력 배열의 각 요소가 속한 기능을 표시하기 위해 추가 인덱스 배열을 생성합니다.
비즈니스의 경우 통합 효과를 얻으려면 원래 FeatureLayer만 교체하면 됩니다.
원래 수백 번 테스트했던 런치 커널이 수동 퓨전 이후 10번 미만으로 줄었습니다. 커널 시작에 따른 오버헤드가 크게 줄어듭니다.
MultiStream은 실행 효율성을 향상시킵니다.
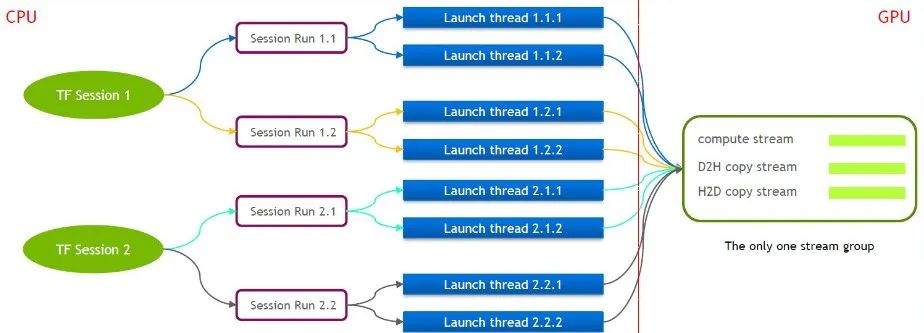
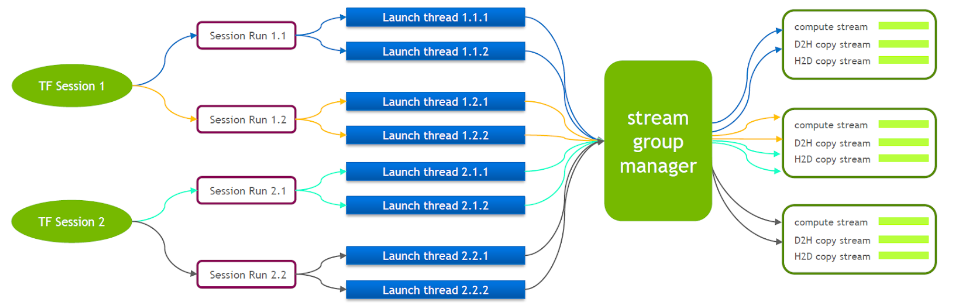
TensorFlow 자체는 하나의 Cuda Stream Group(Compute Stream, H2D Stream, D2H Stream 및 D2D Stream으로 구성)만 포함하는 단일 스트림 모델입니다. 여러 커널은 동일한 Compute Stream에서만 직렬로 실행할 수 있으므로 비효율적입니다. 여러 텐서플로우 세션을 통해 cuda 커널이 시작되더라도 GPU 측에서는 여전히 큐잉이 필요합니다.
이러한 이유로 NVIDIA의 기술 팀은 여러 스트림 그룹의 동시 실행을 지원하기 위해 자체 Tensorflow 지점을 유지합니다. 이는 cuda 커널 실행의 효율성을 향상시키는 데 사용됩니다. 우리는 이 기능을 Tensorflow Serving에 이식했습니다.
Tensorflow Serving이 실행 중일 때 여러 CUDA 컨텍스트 간의 상호 간섭을 줄이기 위해 Nvidia MPS를 켜야 합니다.
작은 데이터 복사 최적화
이전 최적화를 기반으로 소규모 데이터 사본을 더욱 최적화했습니다. Tensorflow Serving은 요청의 각 기능 값을 역직렬화한 후 cudamemcpy를 여러 번 호출하여 호스트에서 장치로 데이터를 복사합니다. 호출 횟수는 기능 수에 따라 다릅니다.
대부분의 CTR 서비스의 경우 실제로 배치 크기가 작은 경우 호스트 측에서 데이터를 먼저 연결한 다음 cudamemcpy를 한꺼번에 호출하는 것이 더 효율적이라고 측정됩니다.
배치 병합
GPU 시나리오에서는 일괄 병합을 활성화해야 합니다. 기본적으로 Tensorflow Serving은 요청을 병합하지 않습니다. GPU의 병렬 컴퓨팅 기능을 더 잘 활용하기 위해 하나의 순방향 계산에 더 많은 샘플을 포함할 수 있습니다. 여러 요청을 일괄 병합하기 위해 런타임에 Tensorflow Serving의 활성화_배칭 옵션을 켰습니다. 동시에 다음 매개변수 구성에 중점을 둔 배치 구성 파일을 제공해야 합니다. 다음은 우리의 경험 중 일부입니다.
-
max_batch_size: 일괄 처리에 허용되는 최대 요청 수(약간 더 클 수 있음)
-
Batch_timeout_micros: 배치 병합을 기다리는 최대 시간입니다. 배치 수가 max_batch_size에 도달하지 않더라도 즉시 계산됩니다. (단위는 마이크로초) 이론적으로 지연 요구 사항이 높을수록 여기서 설정은 작아집니다. 5밀리초 미만으로 설정하는 것이 가장 좋습니다.
-
num_batch_threads: 최대 동시 추론 스레드. MPS를 켠 후 1~4로 설정할 수 있습니다. 그 이상일수록 지연이 늘어납니다.
여기서는 CTR 클래스 모델에 입력되는 대부분의 희소 특성이 가변 길이 특성이라는 점에 유의해야 합니다. 클라이언트가 특별한 합의를 하지 않으면 여러 요청에서 특정 기능의 길이가 일치하지 않을 수 있습니다. Tensorflow Serving에는 더 짧은 요청을 위해 해당 기능을 0으로 채우는 기본 패딩 논리가 있습니다. 가변 길이 기능의 경우 -1은 null을 나타내는 데 사용됩니다. 기본 패딩 0은 실제로 원래 요청의 의미를 변경합니다.
예를 들어 사용자 A가 가장 최근에 시청한 동영상의 ID는 [3,5]이고, 사용자 B가 가장 최근에 시청한 동영상의 ID는 [7,9,10]입니다. 기본적으로 완료되면 요청은 [[3,5,0], [7,9,10]]이 됩니다. 후속 처리에서 모델은 A가 최근 ID가 3, 5, 0인 3개의 동영상을 시청했다고 간주합니다.
따라서 Tensorflow Serving 응답의 완료 로직을 수정했습니다. 이 경우 완료 로직은 [[3,5,-1], [7,9,10]]이 됩니다. 첫 번째 줄의 의미는 여전히 동영상 3과 5를 시청했다는 것입니다.
최종 효과
위에서 언급한 다양한 최적화를 통해 대기 시간과 처리량이 우리의 요구 사항을 충족했으며 권장되는 개인화된 푸시 및 워터폴 스트리밍 서비스에 구현되었습니다. 사업실적은 다음과 같습니다.
-
기본 Tensorflow GPU 컨테이너에 비해 처리량이 6배 이상 증가합니다.
-
지연 시간은 기본적으로 CPU와 동일하므로 비즈니스 요구 사항을 충족합니다.
-
동일한 QPS 지원 시 비용이 40% 이상 절감됩니다.
이 기사는 WeChat 공개 계정인 iQIYI 기술 제품 팀(iQIYI-TP)에서 공유되었습니다.
침해가 있는 경우 [email protected]에 연락하여 삭제를 요청하세요. 이 글은 " OSC 소스 생성 계획
" 에 참여하고 있습니다 . 이 글을 읽고 계신 여러분의 많은 참여와 공유 부탁드립니다.