자원 활용도를 높이고 비용을 절감하기 위한 솔루션으로 코로케이션은 일반적으로 업계에서 인정받고 있습니다. 클라우드 네이티브화와 비용 절감 및 효율성 향상 과정에서 iQiyi는 빅데이터 오프라인 컴퓨팅, 오디오 및 비디오 콘텐츠 처리 및 기타 워크로드를 온라인 비즈니스와 성공적으로 혼합하여 단계적인 이익을 달성했습니다. 본 글에서는 빅데이터를 예로 들어 0에서 1까지의 혼합배치 시스템을 구현하는 실무과정을 소개한다.
배경
iQIYI 빅데이터는 운영 의사결정, 사용자 성장, 광고 배포, 동영상 추천, 검색, 회사 내 멤버십 등 중요한 시나리오를 지원하여 비즈니스를 위한 데이터 중심 엔진을 제공합니다. 비즈니스 수요가 증가함에 따라 필요한 컴퓨팅 리소스의 양이 날로 증가하고 있으며 비용 관리 및 리소스 공급에 대한 압박이 더욱 커지고 있습니다.
iQIYI의 빅 데이터 컴퓨팅은 오프라인 컴퓨팅과 실시간 컴퓨팅이라는 두 가지 데이터 처리 링크로 구분됩니다.
-
오프라인 컴퓨팅에는 Spark 기반 데이터 처리, Hive 기반 시간별 또는 일별 데이터 웨어하우스 구축 및 해당 보고서 쿼리 및 분석이 포함됩니다. 이러한 유형의 계산은 일반적으로 매일 이른 아침에 시작하여 전날의 데이터를 계산하고 종료됩니다. 아침. 매일 0시부터 8시는 컴퓨팅 리소스 수요가 가장 많은 시간입니다. 클러스터의 전체 리소스가 부족한 경우가 많으며, 낮 동안 작업이 대기열에 추가되거나 백로그되는 경우가 많습니다. 자원 낭비.
-
실시간 컴퓨팅에는 Kafka + Flink로 대표되는 실시간 데이터 스트림 처리가 포함되며, 이는 상대적으로 안정적인 리소스 요구 사항을 갖습니다.
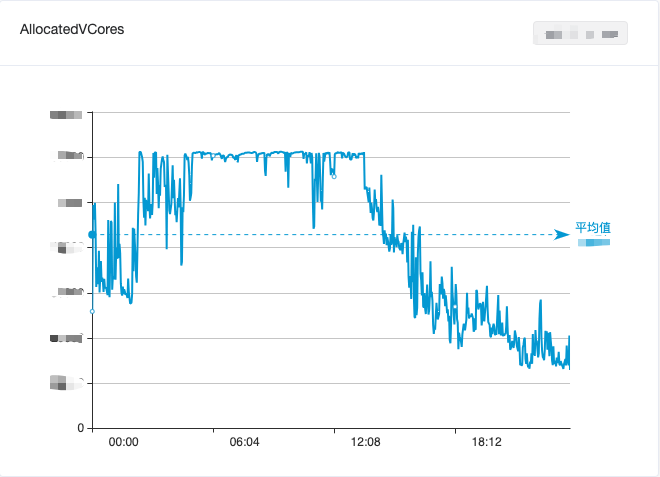
빅데이터 자원 활용의 균형을 맞추기 위해 오프라인 컴퓨팅과 실시간 컴퓨팅을 혼합하여 낮 동안의 유휴 자원 낭비를 어느 정도 완화했지만 여전히 효과적으로 피크를 줄이고 밸리를 채우지 못했습니다. 빅데이터 컴퓨팅 자원의 전반적인 활용은 여전히 보였습니다. "낮의 최저점과 이른 아침의 최고점"의 조수 현상은 그림 1에 나와 있습니다.
그림 1. 하루 동안 빅데이터 컴퓨팅 클러스터의 CPU 사용량 변화
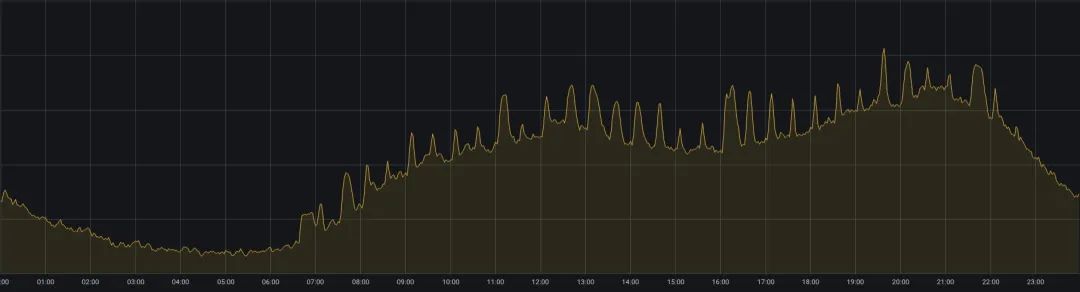
iQiyi의 온라인 비즈니스는 서비스 품질과 리소스 활용 간의 균형이라는 또 다른 문제에 직면해 있습니다. 온라인 비즈니스는 주로 iQiyi 비디오 재생과 같은 시나리오를 제공합니다. 정오와 저녁에 비디오를 시청하는 사용자가 더 많고 리소스 사용량은 "낮에 최고점, 이른 아침에 최저점"이라는 조수 현상을 보입니다(그림 2 참조). . 피크 기간 동안 서비스 품질을 보장하기 위해 온라인 비즈니스는 일반적으로 더 많은 리소스를 예약하므로 리소스 활용도가 매우 만족스럽지 않습니다.
그림 2. 하루 동안 온라인 비즈니스 클러스터의 CPU 사용량 변화
활용도를 높이기 위해 iQiyi가 개발한 이전 세대 컨테이너 플랫폼은 CPU 정적 초과 예약 전략을 채택했습니다. 이 방법은 활용도 향상에 상당한 효과가 있지만 핵심 기능 등의 요인으로 인해 제한되며 단일 서비스 간 중단을 피할 수 없습니다. 간헐적으로 발생하는 리소스 경쟁 문제로 인해 온라인 비즈니스 서비스 품질이 불안정해지는 현상도 발생했으며, 이 문제는 제대로 해결되지 않았습니다.
클라우드 네이티브화가 발전함에 따라 iQiyi 컨테이너 플랫폼은 점차 Kubernetes(이하 "K8s") 기술 스택으로 전환되었습니다. 최근 몇 년 동안 K8s 커뮤니티에는 공동 배포와 관련된 많은 오픈 소스 프로젝트가 등장했으며 업계에서도 일부 공동 배포 관행이 있습니다 [1] . 이러한 배경에서 컴퓨팅 플랫폼 팀은 업무 방향을 '정적 초과 예약'에서 '동적 초과 예약 + 혼합 배포'로 조정했습니다.
가장 대표적인 오프라인 비즈니스로서 빅데이터는 코로케이션 구현을 시도하는 선구자이다. 한편, 빅데이터는 대용량이고 상대적으로 안정적인 컴퓨팅 리소스 요구 사항을 갖고 있는 반면, 빅데이터 비즈니스와 온라인 비즈니스는 다방면에서 상호 보완적인 효과를 얻을 수 있으며, 코로케이션을 통해 리소스 활용도를 완전히 향상시킬 수 있습니다.
위의 분석을 바탕으로 iQiyi 컴퓨팅 플랫폼 팀과 빅 데이터 팀은 코로케이션을 탐색하기 시작했습니다.
혼합 위치 계획 설계
iQiyi 빅 데이터 시스템은 오픈 소스 Apache Hadoop 생태계를 기반으로 구축되었으며 YARN을 컴퓨팅 리소스 스케줄링 시스템으로 사용합니다. 온라인 비즈니스는 두 개의 서로 다른 리소스 스케줄링 시스템을 연결하는 방법이 가장 먼저 해결되어야 합니다. 코로케이션 솔루션.
업계에는 일반적으로 두 가지 공동 배치 솔루션이 있습니다.
-
옵션 1: K8s에서 빅데이터 작업(Spark, Flink 등, MapReduce는 지원되지 않음)을 직접 실행하고 기본 스케줄러를 사용합니다.
-
옵션 2: K8s에서 YARN의 NodeManager(이하 "NM")를 실행하고 빅데이터 작업은 여전히 YARN을 통해 예약됩니다.
신중한 고려 끝에 우리는 다음 두 가지 주요 이유로 옵션 2를 선택했습니다.
-
현재 회사의 빅 데이터 컴퓨팅 작업의 대부분은 YARN을 기반으로 예약됩니다. YARN은 강력한 예약 기능(멀티 테넌트 다중 대기열, 랙 인식), 뛰어난 예약 성능(5k+ 컨테이너/초) 및 완벽한 보안 메커니즘을 갖추고 있습니다. ( Kerberos, Delegation Tokens)이며 MapReduce, Spark 및 Flink와 같은 거의 모든 빅 데이터 컴퓨팅 프레임워크를 지원합니다. 2014년 YARN을 도입한 이후 iQiyi 빅 데이터 팀은 개발, 운영 및 유지 관리, 컴퓨팅 거버넌스 등을 위한 일련의 플랫폼을 구축하여 내부 사용자에게 편리한 빅 데이터 개발 프로세스를 제공했습니다. 따라서 YARN API와의 호환성은 하이브리드 솔루션을 선택할 때 중요한 고려 사항 중 하나입니다.
-
K8s에는 배치 스케줄러가 있지만 충분히 성숙되지 않았고 스케줄링 성능(<1,000개 컨테이너/초)에 병목 현상이 있어 빅 데이터 시나리오의 요구 사항을 지원하기에 충분하지 않습니다.
K8s 수준에서 양 당사자는 공동 위치 리소스를 관리하고 사용하기 위한 일련의 표준 인터페이스가 필요합니다. 커뮤니티에는 Alibaba의 오픈소스 Koordinator[2], Tencent의 오픈소스 FinOps 프로젝트 Crane[3], ByteDance의 오픈소스 프로젝트 Katalyst[4] 등 우수한 프로젝트가 많이 있습니다. 그중 Koordinator는 Dragon Lizard 운영 체제(iQiyi가 시도하는 CentOS 대안 중 하나)에 대한 "자연스러운" 적응성을 갖추고 있으며 협업하여 온라인 비즈니스 로드 모니터링, 유휴 리소스 초과 할당, 작업 계층적 스케줄링 및 오프라인 작업 부하 QoS 보장을 달성할 수 있습니다. 등은 iQiyi의 요구 사항을 충족합니다.
위의 기술 선택을 바탕으로 심층적인 변환을 통해 YARN NM을 컨테이너화하여 K8s Pod에서 실행하고, 동적으로 변화하는 Koordinator의 초고해상도 컴퓨팅 리소스를 실시간으로 감지하여 자동 수평 및 수직 확장 및 축소를 달성하고, 혼합 리소스 활용도 극대화.
공동 배치 스케줄링 전략의 진화
빅데이터와 온라인 비즈니스의 공존은 여러 단계의 기술 진화를 거쳐 왔으며, 이에 대해 아래에서 자세히 소개하겠습니다.
1단계: 야간 시분할 다중화
솔루션을 빠르게 검증하기 위해 먼저 K8s Pod에서 NM의 컨테이너화 변환을 완료하고(이 단계에서는 Koordinator를 사용하지 않았습니다) 이를 기존 Hadoop 클러스터에 탄력적 노드로 확장했습니다. 빅 데이터 수준에서 이러한 K8s NM은 다른 물리적 시스템의 NM과 함께 YARN에 의해 균일하게 예약됩니다. 이러한 탄력적 노드는 매일 정기적으로 시작 및 중지되며 0시~9시 사이에만 실행됩니다.
이 단계에서 우리는 20개 이상의 개조 작업을 완료했습니다. 다음은 5가지 주요 개조 사항입니다.
개선 포인트 1: 고정 IP 풀
기존 NM은 물리적 머신에 배포되며 머신의 IP와 도메인 이름은 고정되어 있습니다. 노드 화이트리스트(슬레이브 파일)는 노드가 YARN ResourceManager(이하 "RM"이라고 함)에 구성됩니다. 무리. 동시에 YARN 클러스터는 Kerberos를 사용하여 보안 인증을 구현합니다. 배포 전에 keytab 파일을 Kerberos KDC에서 생성하고 NM 노드에 배포해야 합니다.
YARN의 화이트리스트 및 보안 인증 메커니즘에 적응하기 위해 자체 구축된 클러스터에 대해 자체 개발한 고정 IP 기능을 사용합니다. 각 고정 IP에는 해당 K8s StaticIP 리소스가 있어 동시에 Pod와 IP 간의 해당 관계를 기록합니다. 향후에는 퍼블릭 클라우드 기반으로 자체 개발한 StaticIP CRD를 클러스터에 배치하고, 고정 IP별로 StaticIP 리소스를 생성하여 자체 구축 클러스터와 동일한 용도의 고정 IP 풀을 YARN에 제공할 예정입니다. . NM 시작 시 필요한 구성을 빠르게 얻을 수 있도록 고정 IP 풀의 IP를 기반으로 DNS 레코드와 키탭 파일을 미리 생성합니다.
전환점 2: Elastic YARN Operator
사용자가 탄력적 노드 도입을 인식하지 못하도록 기존 Hadoop YARN 클러스터에 탄력적 NM을 추가했습니다. 이후 혼합 배포에서 동적으로 인식되는 리소스의 복잡성을 고려하여 우리는 Elastic NM의 수명 주기를 더 잘 관리하기 위해 자체 개발한 Elastic YARN Operator를 선택했습니다.
이 단계에서 Elastic YARN Operator가 지원하는 전략은 다음과 같습니다.
-
按需启动:应对离线任务的突发流量,包括寒暑假、节假日、重要活动等场景
-
周期性上下线:利用在线服务每天凌晨的资源利用率低谷期,运行大数据任务
改造点 3:Node Label - 弹性与固定资源隔离
由于 Flink 等大数据实时流计算任务是 7x24 小时不间断常驻运行的,对 NM 的稳定性的要求比批处理更高,弹性 NM 节点的缩容或资源量调整会使得流计算任务重启,导致实时数据波动。为此,我们引入了 YARN Node Label 特性 [5],将集群分为固定节点(物理机 NM)和弹性节点(K8s NM)。批处理任务可以使用任意节点,流任务则只能使用固定节点运行。
此外,批处理任务容错的基础在于 YARN Application Master 的稳定性。我们的解决方案是,给 YARN 新增了一个配置,用于设置 Application Master 默认使用的 label,确保 Application Master 不被分配到弹性 NM 节点上。这一功能已经合并到社区:
YARN-11084
、
YARN-11088
。
改造点 4:NM Graceful Decommission
我们采用了弹性节点固定时间上下线,来对在离线资源进行削峰填谷。弹性 NM 的上线由 YARN Operator 来启动,一旦启动完成,任务就可被调度上。弹性 NM 的下线则略微复杂些,因为任务仍然运行在上面,我们需要尽可能保证任务在下线的时间区间内已经结束。
例如我们周期性部署策略为:0 - 8 点弹性 NM 上线,8 - 9 点为下线时间区间,9 - 24 点为节点离线状态。通过使用 YARN graceful decommission [6] 的机制,将增量 container 请求避免分配到 decommissioning 的节点上,在下线时间区间内等待任务缓慢结束即可。
但是在我们集群中,批处理任务大部分是 Spark 3.1.1 版本,因为 Spark 申请的 YARN container 是作为 task 的 executor 来使用,在大部分情况下,1 个小时的下线区间往往是不够的。因此我们引入了 SPARK-20624 的一系列优化 [7],通过 executor 响应 YARN decommission 事件来将 executor 尽可能快速退出。
改造点 5:引入 Remote Shuffle Service - Uniffle
Shuffle 作为离线任务中的重要一环,我们采用 Spark ESS on NodeManager 的部署模式。但在引入弹性节点后,因为弹性 NM 生命周期短,无法保证在 YARN graceful decommmission 的时间区间内,任务所在节点的 shuffle 数据被消费完,导致作业整体失败。
基于这一点,我们引入了 Apache Uniffle (incubating) [8] 实现 remote shuffle service 来解耦 Spark shuffle 数据与 NM 的生命周期,NM 被转变为单纯的计算,不存储中间 shuffle 数据,从而实现 NM 快速平滑下线。
另外一方面,弹性 NM 挂载的云盘性能一般,无法承载高 IO 和高并发的随机读写,同时也会对在线服务产生影响。通过独立构建高性能 IO 的 Uniffle 集群,提供更快速的 shuffle 服务。
爱奇艺作为 Uniffle 的深度参与者,贡献了 100+ 改进和 30+ 特性,包括 Spark AQE 优化 [9] 、Kerberos 的支持 [10] 和超大分区优化 [11] 等。
阶段二:资源超分
在阶段一,我们仅使用 K8s 资源池剩余未分配资源实现了初步的混部。为了最大限度地利用空闲资源,我们引入 Koordinator 进行资源的超分配。
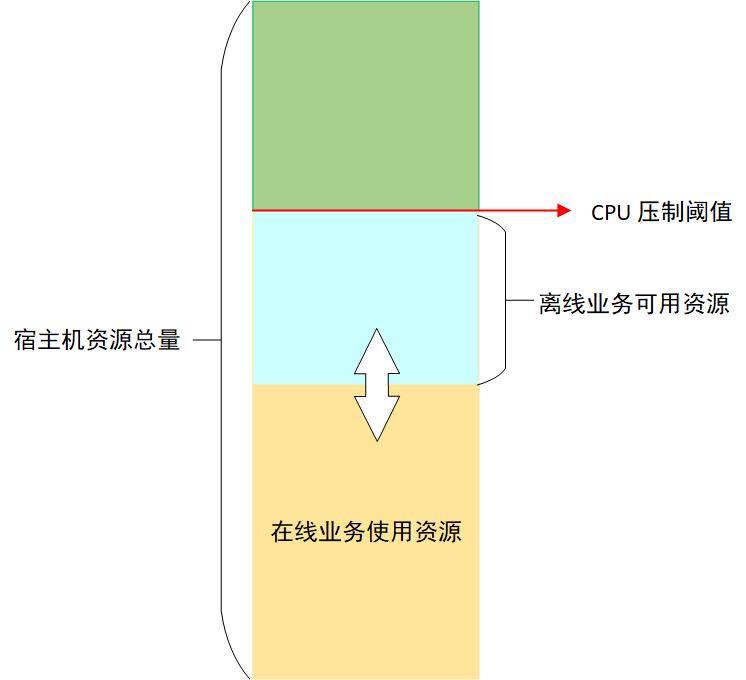
我们对弹性 NM 的资源容量采用了固定规格限制:10 核 batch-cpu、30 GB batch-memory(batch-cpu 和 batch-memory 是 Koordinator 超分出来的扩展资源),NM 保证离线任务使用的资源总量不会超过这些限制。
为了保证在线业务的稳定性,Koordinator 会对节点上离线任务能够使用的 CPU 进行压制 [12],压制结果由压制阈值和在线业务 CPU 实际用量(不是 request 请求)的差值决定,这个差值就是离线业务能够使用的最大 CPU 资源,由于在线业务 CPU 实际使用量不断变化,所以离线业务能够使用的 CPU 也在不断变化,如图 3 所示:
对离线任务的 CPU 压制保证了在线业务的稳定性,但是离线任务执行时间就会被拉长。如果某个节点上离线任务被压制程度比较严重,就可能会导致等待的发生,从而拖慢整体任务的运行速度。为了避免这种情况,Koordinator 提供了基于 CPU 满足度的驱逐功能 [13],当离线任务使用的 CPU 被压制到用户指定的满足度以下时,就会触发离线任务的驱逐。离线任务被驱逐后,可以调度到其他资源充足的机器上运行,避免等待。
在经过一段时间的测试验证后,我们发现在线业务运行稳定,集群 CPU 7 天平均利用率提升了 5%。但是节点上的 NM Pod 被驱逐的情况时有发生。NM 被驱逐之后,RM 不能及时感知到驱逐情况的发生,会导致失败的任务延迟重新调度。为了解决这个问题,我们开发了 NM 动态感知节点离线 CPU 资源的功能。
阶段三:从夜间分时复用到全天候实时弹性
与其触发 Koordinator 的驱逐操作,不如让 NM 主动感知节点上离线资源的变化,在离线资源充足时,调度较多任务,离线资源不足时,停止调度任务,甚至主动杀死一些离线 container 任务,避免 NM 被 Koordinator 驱逐。
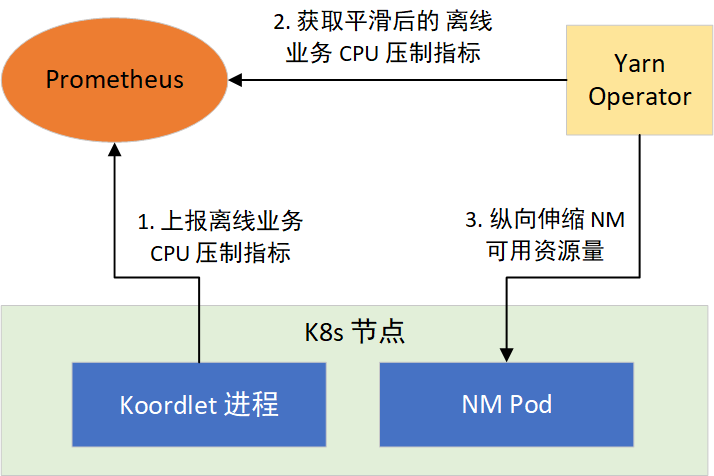
根据这个思路,我们通过 YARN Operator 动态感知节点所能利用的资源,来纵向伸缩 NM 可用资源量。分两步实现:1)提供离线任务 CPU 压制指标;2)让 NM 感知 CPU 压制指标,采取措施。如图 4 所示:
CPU 压制指标
Koordinator 的 Koordlet 组件,运行于 K8s 的节点上,负责执行离线任务 CPU 压制、Pod 驱逐等操作,它以 Prometheus 格式提供了 CPU 压制指标,经过采集后就可以通过 Prometheus 对外提供。CPU 压制指标默认每隔 1 秒更新 1 次,会随着在线业务负载的变化而变化,波动较大。而 Prometheus 的指标抓取周期一般都大于 1 秒,这会造成部分数据的丢失,为了平滑波动,我们对 Koordlet 进行了修改,提供了 1 min、5 min、10 min CPU 压制指标的均值、方差、最大值和最小值等指标供 NM 选择使用。
YARN Operator 动态感知和纵向伸缩
在 NM 常驻的部署模式下,YARN Operator 提供了新的策略。通过在 YARN Operator 接收到当前部署的节点 10 min 内可利用的资源指标,用来决策是否对所在宿主机上的 NM 进行纵向伸缩。
对于扩容,一旦超过 3 核,则向 RM 进行节点的资源更新。扩容过程如图 5 所示:
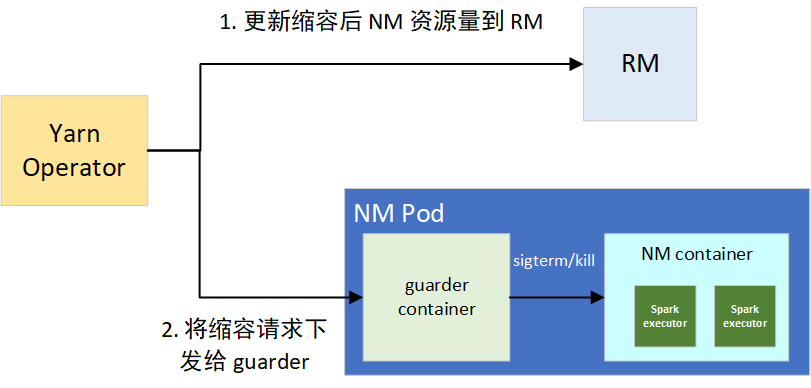
缩容的话,如果抑制率控制在 10% 以内的波动,我们默认忽略。一旦超过阈值,则会触发缩容操作,分为两个步骤:1)更新节点在 RM 上的可用资源,用来堵住增量的 container 分配需求;2)将缩容请求下发给 NM 的 guarder sidecar 容器,来对部分资源超用的 container 的平滑和强制下线,避免因占用过多 CPU 资源导致整个 NM 被驱逐。
guarder 在拿到目标可用资源后,会对当前所有的 YARN container 进程进行排序,包括框架类型、运行时长、资源使用量三者,决策拿到要 kill 的进程。在 kill 前,会进行 SIGPWR 信号的发送,用来平滑下线任务,Spark Executor 接收到此信号,会尽可能平滑退出。缩容过程如图 6 所示:
通常节点的资源量变动幅度不是很大,且 NM 可使用的资源量维持在较高的水平(平均有 20 core),部分 container 的存活周期为 10 秒级,因此很快就能降至目标可用资源量值。涉及到变动幅度频繁的节点,通过 guarder 的平滑下线和 kill 决策,container 失败数非常低,从线上来看,按天统计平均 force kill container 数目为 5 左右,guarder 发送的平滑下线信号有 500+,可以看到效果比较好。
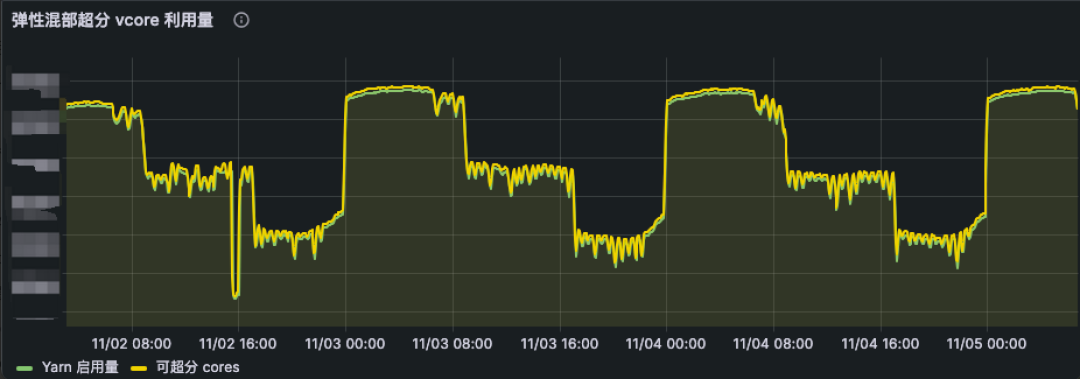
在离线 CPU 资源感知功能全面上线后,NM Pod 被驱逐的情况基本消失。因此,我们逐步将混部时间由凌晨的 0 点至 8 点,扩展到全天 24h 运行,并根据在线业务负载分布情况,在一天的不同时段采用不同的 CPU 资源超分比,从而实现全天候实时弹性调度策略。伴随着全天 24h 的稳定运行,集群 CPU 利用率再度提升了 10%。从线上混部 K8s 集群来看(如图 7 所示),弹性 NM 的 vcore 使用资源量(绿线)也是动态贴合可超分的资源(黄线)。
阶段四:提升资源超分率
为了提供更多的离线资源,我们开始逐步调高 CPU 资源的超分比,而 NM Pod 被驱逐的情况再次发生了,这一次的原因是内存驱逐。我们将物理机器的内存超分比设置为 90%,从集群总体情况看,物理机器上的内存资源比较充足,刚开始我们只关注了 CPU 资源,没有关注内存资源。而 NM 的 CPU 和内存按照 1:4 的比例来使用,随着 CPU 超分比的提高,YARN 任务需要的内存也在提升,最终当 K8s 节点内存使用量超过设定的阈值时,就会触发 Koordinator 的驱逐操作。
经过观察,我们发现内存驱逐在某些节点上发生的概率特别高,这些节点的内存比其他节点内存小,而 CPU 数量是相同的,因此这些节点在 CPU 超分比相同的情况下,更容易因为内存原因被驱逐,它们能提供的离线内存更少。因此,guarder 容器也需要感知节点的离线内存资源用量,并根据资源用量采取相应的措施,这个过程与 CPU 离线资源的感知一样的,不再赘述。
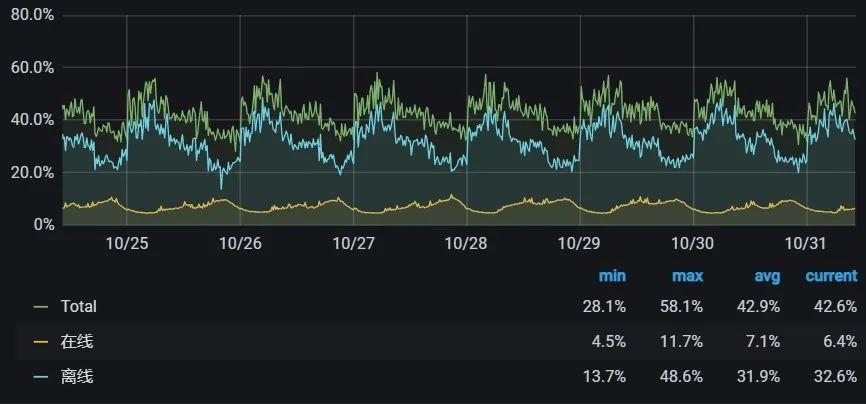
内存感知功能上线后,我们又逐步提升了 CPU 的超分比,当前在线业务集群的 CPU 利用率已经提升到全天平均 40%+、夜间 58% 左右。
效果
通过大数据离线计算与在线业务的混部,我们将在线业务集群 CPU 平均利用率从 9% 提升到 40%+,在不增加机器采购的同时满足了部分大数据弹性计算的资源需求,每年节省数千万元成本。
同时,我们也将这套框架应用到大数据 OLAP 分析场景,实现了 Impala/Trino on K8s 弹性架构,满足数据分析师日常动态查询需求,支持了寒暑假、春晚直播、广告 618 与双 11 等重要活动期间临时大批量资源扩容需求,保障了广告、BI、会员等数据分析场景的稳定、高效。
未来计划
当前,大数据离在线混部已稳定运行一年多,并取得阶段性成果,未来我们将基于这套框架进一步推进大数据云原生化:
-
完善离在线混部可观测性:建立精细化的 QoS 监控,保障在线服务、大数据弹性计算任务的稳定性。
-
加大离在线混部力度:K8s 层面,继续提高宿主机资源利用率,提供更多的弹性计算资源供大数据使用。大数据层面,进一步提升通过离在线混部框架调度的弹性计算资源占比,节省更多成本。
-
大数据混合云计算:目前我们主要使用爱奇艺内部的 K8s 进行混部,随着公司混合云战略的推进,我们计划将混部推广到公有云 K8s 集群中,实现大数据计算的多云调度。
-
探索云原生的混部模式:尽管复用 YARN 的调度器能让我们快速利用混部资源,但它也带来了额外的资源管理和调度开销。后续我们也将探索云原生的混部模式,尝试将大数据的计算任务直接使用 K8s 的离线调度器进行调度,进一步优化调度速度和资源利用率。
参考资料
[1] 一文看懂业界在离线混部技术. https://www.infoq.cn/article/knqswz6qrggwmv6axwqu
[2] Koordinator: QoS-based Scheduling for Colocating on Kubernetes. https://koordinator.sh/
[3] Crane: Cloud Resource Analytics and Economics in Kubernetes clusters. https://gocrane.io/
[4] Katalyst: a universal solution to help improve resource utilization and optimize the overall costs in the cloud. https://github.com/kubewharf/katalyst-core
[5] Apache Hadoop YARN - Node Labels. https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/NodeLabel.html
[6] Apache Hadoop YARN - Graceful Decommission of YARN Nodes. https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/GracefulDecommission.html
[7] Apache Spark - Add better handling for node shutdown. https://issues.apache.org/jira/browse/SPARK-20624
[8] Apache Uniffle: Remote Shuffle Service. https://uniffle.apache.org/
[9] Apache Uniffle - Support getting memory data skip by upstream task ids. https://github.com/apache/incubator-uniffle/pull/358
[10] Apache Uniffle - Support storing shuffle data to secured dfs cluster. https://github.com/apache/incubator-uniffle/pull/53
[11] Apache Uniffle - Huge partition optimization. https://github.com/apache/incubator-uniffle/issues/378
[12] Koordinator - CPU Suppress. https://koordinator.sh/docs/user-manuals/cpu-suppress/
[13] Koordinator - Eviction Strategy based on CPU Satisfaction. https://koordinator.sh/docs/user-manuals/cpu-evict/

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。