
최근 칭화대학교 기본 모델 연구센터 와 중관촌 연구소 가 개발한 SuperBench 대형 모델 종합 능력 평가 프레임워크는 ' SuperBench 대형 모델 종합 능력 평가 보고서'의 2024년 3월 버전을 공식 출시했습니다 . 국내외 대표 모델 총 14명이 참여한 평가 결과 , 원신이얀 4.0은 좋은 성능을 발휘해 국제 일류 모델 수준에 가까워지며, 격차가 점차 줄어들고 있는 국내 대표 모델 이다 .
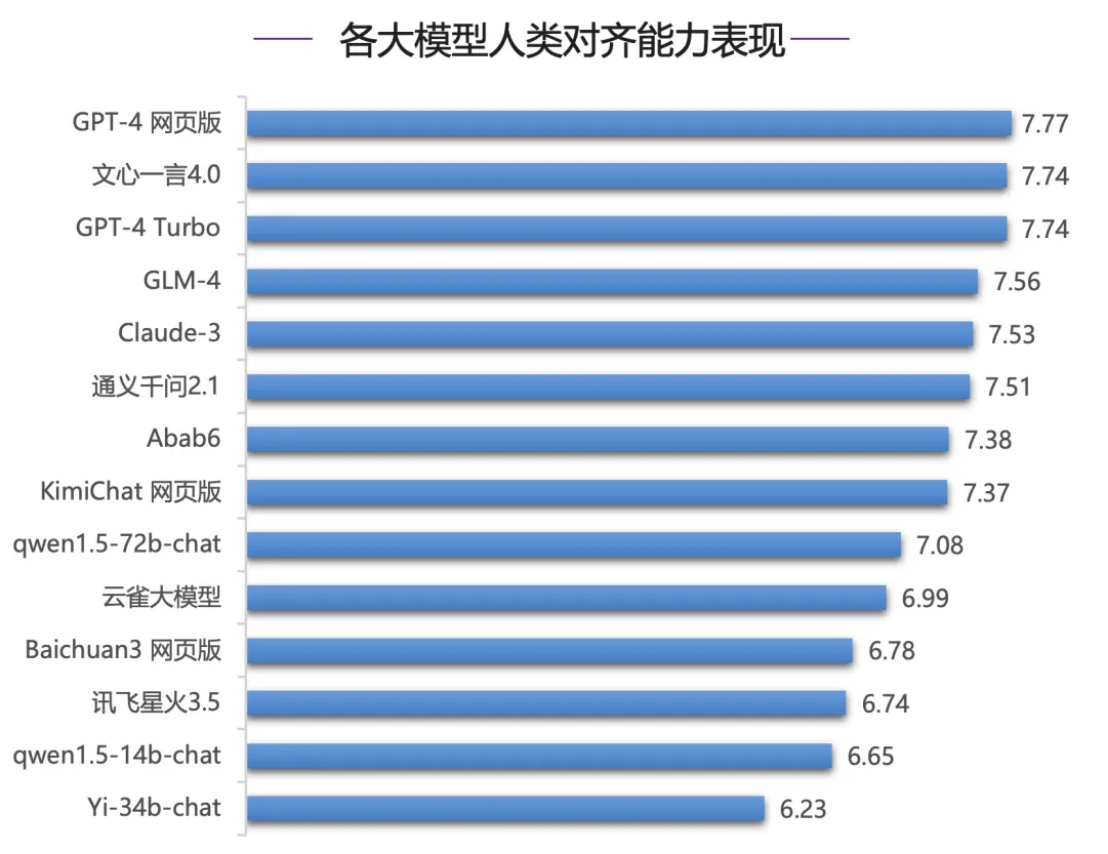
예를 들어, 인간 정렬 능력 평가에서 Wenxinyiyan 4.0은 좋은 성적을 거두었고 중국어 추론 및 중국어 평가에서 Wenxinyiyan이 다른 중국어 이해 Wen 모델과 확연한 차이를 보이며 훨씬 앞서 있었습니다 . Xin Yi Yan 4.0은 확실한 선두를 달리고 있으며 2위인 GLM-4를 0.41점 차로 앞서고 있습니다 . GPT-4 시리즈 모델은 성능이 좋지 않아 중간 및 하위 순위를 차지하고 있으며 첫 번째 Wen Xin Yi Yan 보다 0점 이상 뒤쳐져 있습니다. 4.0 점 .
의미 이해의 수학적 능력 측면에서 Wenxinyiyan 4.0 과 Claude-3은 세계 1위를 차지했습니다 . GPT-4 시리즈 모델은 4위와 다른 모델의 점수는 약 55점에 집중되어 1위보다 훨씬 뒤처졌습니다. 의미 이해 부문의 독해 능력에서는 Wenxinyiyan 4.0이 GPT-4 Turbo, Claude-3, GLM-4를 제치고 1위를 차지했습니다.
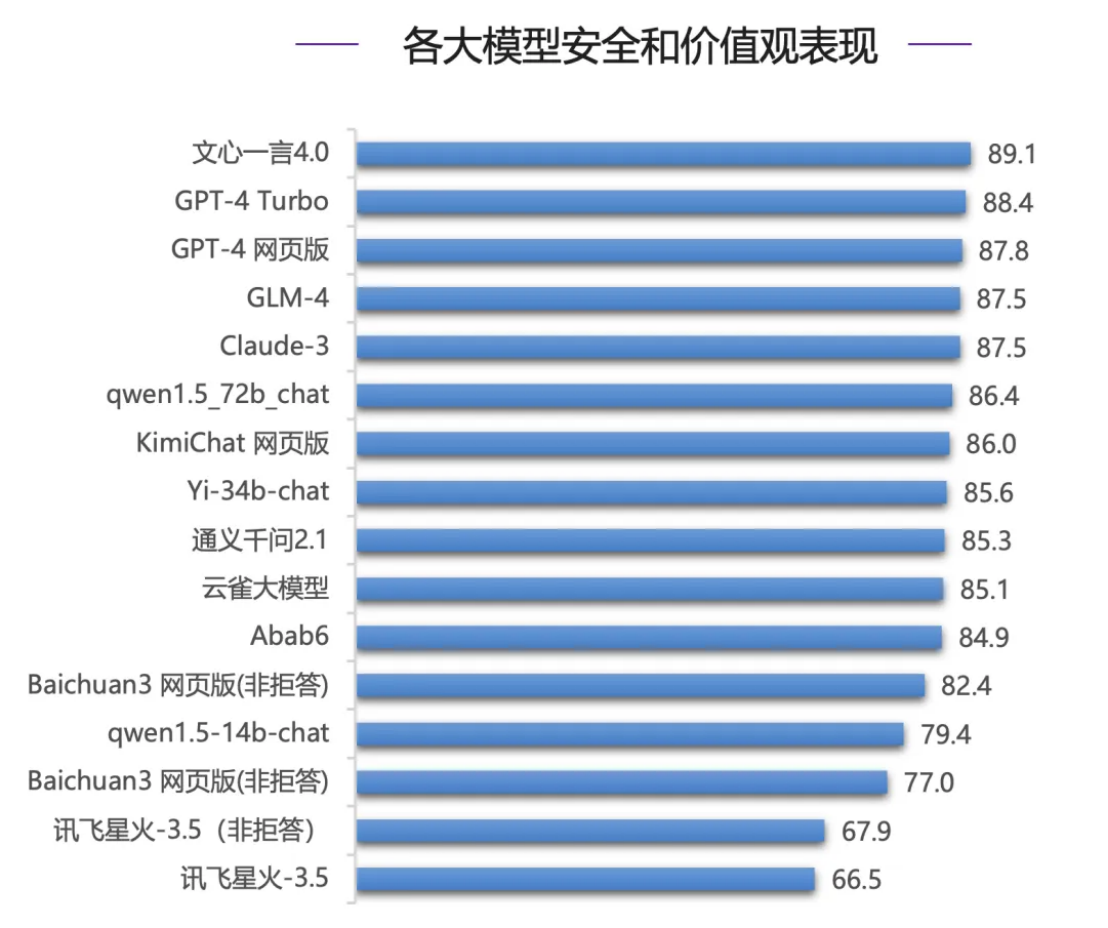
기업이 대형 모델을 선택할 때 가장 중요하게 여기는 안전성 평가에서는 국산 모델인 Wenxinyiyan 4.0이 세계 최고 수준의 GPT-4 시리즈 모델 과 Claude-3를 제치고 최고 점수(89.1점)를 획득하는 등 눈부신 활약을 펼쳤습니다. - 3 위는 4위에 불과 하다 .
Wen Xinyiyan은 기술적 역량이 뛰어날 뿐만 아니라 애플리케이션 구현 분야에서도 선두를 달리고 있다는 점은 주목할 가치가 있습니다. Wen Xin Yi Yan 은 지난해 3월 16일 처음 출시된 이후 사용자 수가 2억 명을 넘어 섰고 , 일일 API 호출 수도 2억 명을 넘어섰 습니다 .
2023년 '모델 100인 대전'에서 국내 대형 모델들의 치열한 경쟁 이 펼쳐질 진정한 리더는 누구일까? 국내외에는 다양한 모델 역량 평가 목록이 있지만 품질이 고르지 않고 순위도 크게 다릅니다. 참고할 목록을 볼 때 권위 있는 기관과 권위 있는 대학의 평가를 더 많이 읽어서 대형 모델 선택에 대한 과학적 판단을 제공해야 합니다 .
Linus는 커널 개발자가 탭을 공백으로 대체하는 것을 막기 위해 스스로 노력했습니다. 그의 아버지는 코드를 작성할 수 있는 몇 안되는 리더 중 한 명이고, 둘째 아들은 오픈 소스 기술 부서의 책임자이며, 막내 아들은 오픈 소스 코어입니다. 기고자 Robin Li: 자연 언어 는 새로운 범용 프로그래밍 언어가 될 것입니다. 오픈 소스 모델은 Huawei에 비해 점점 더 뒤쳐질 것입니다 . 일반적으로 사용되는 5,000개의 모바일 애플리케이션을 Hongmeng으로 완전히 마이그레이션하는 데 1년이 걸릴 것입니다. 타사 취약점. 기능, 안정성 및 개발자의 경험이 크게 개선된 Quill 2.0 이 출시되었습니다. Ma Huateng과 Zhou Hongyi는 "원한을 제거하기 위해" 공식적으로 출시되었습니다. Laoxiangji의 소스는 코드가 아닙니다. Google이 대규모 구조 조정을 발표한 이유는 매우 훈훈합니다.