
저자: vivo 인터넷 빅데이터 팀-Wu Yonggang, Li Xiong
본 글은 비보 인터넷 빅데이터팀 - 리텐션 분석 모델(Retention Analysis Model)의 "사용자 행동 분석 모델 실습" 시리즈 기사 중 네 번째 글입니다.
이 기사에서는 보유 분석 모델의 개념과 기본 원칙을 자세히 소개하고 제품에서의 구체적인 구현에 대해 설명합니다. 실제 사용 과정에서 발생하는 문제점을 고려하여 ClickHouse 리텐션 분석 모델을 기반으로 한 실용적인 솔루션을 모색했습니다.
1. 배경 요구 사항
CNNIC 통계에 따르면 중국 인터넷 사용자는 10억7900만명에 달하고 인터넷 보급률은 79.4%에 달한다. 인터넷은 여전히 빠른 속도로 성장하고 있지만 점차 사용자 수는 포화 상태에 이르고 있습니다. 인터넷은 실제로 기존 사용자 시대에 진입했습니다. 전반적인 트래픽 경쟁은 점점 더 치열해지고 있으며 신규 사용자 유치보다 사용자 유지가 점점 더 중요해지고 있습니다. 사용자. 그렇다면 충성도가 높은 사용자를 식별하고 타겟 사용자 그룹의 유지 성과를 어떻게 이해해야 할까요? 사용자 이탈을 분석하고 제품을 최적화하는 방법은 무엇입니까? 타겟 사용자가 원하는 행동을 완료했는지 여부 등을 분석하는 방법은 데이터 분석에서 중요한 주제이며, 리텐션 분석 모델은 이러한 문제를 해결하는 데 중요한 도구입니다.
2. 개요
2.1 개념 소개
리텐션 분석 모델은 주로 후속 이벤트(예: 재방문 이벤트)를 트리거하기 위해 초기 이벤트를 트리거한 사용자의 비율을 분석하는 데 사용됩니다. 이 모델은 사용자의 충성도 또는 사용자 충성도를 더 잘 반영할 수 있습니다. 보존 분석 모델에 대해 이해해야 할 몇 가지 중요한 개념이 있습니다.

유지 분석에서는 일반적으로 시작 이벤트와 재방문 이벤트를 지정해야 하지만 시작 이벤트와 재방문 이벤트는 동일하거나 다를 수 있습니다.
1. 최초 이벤트와 재방문 이벤트를 동일한 이벤트 로 선택할 수 있습니다 . 이를 통해 이벤트를 실행한 충성도 높은 사용자 수를 직관적으로 확인할 수 있습니다.
예를 들어, 로그인 과정에서 초기 이벤트는 로그인 성공이고, 재방문 이벤트는 로그인 성공입니다. 일정 시간 동안 이 이벤트를 지속적으로 트리거하는 사용자 수는 다음과 같습니다. 충성스러운 사용자.
2. 초기 이벤트와 재방문 이벤트에 대해 서로 다른 이벤트를 선택할 수 있습니다 . 이는 비교적 일반적인 프로세스에 따른 사용자 유지 데이터입니다.
예: 특정 활동에서 주문 배치부터 결제 성공까지 시작 이벤트는 주문이고 재방문 이벤트는 결제 성공입니다. 일정 기간 내에 이 두 이벤트를 트리거하는 동일한 사용자가 지정된 프로세스입니다. 사용자 유지 데이터.
2.2 분석 아이디어
유지율은 제품의 핵심 지표 중 하나입니다. 우리는 제품 성능을 향상시키고, 사용자 경험을 개선하며, 이 지표를 개선하기 위해 대상 사용자를 광범위하게 분석합니다. 예를 들어 N일의 유지율을 계산하여 특정 반복이 긍정적인지 여부를 평가할 수 있습니다. 그림 1에 표시된 것처럼 애플리케이션이 홈페이지 레이아웃을 최적화하고 새 버전 A를 출시하면 이전 버전 B와 결합하여 일일 사용자 유지율을 계산할 수 있으며 일반적으로 감소하는 유지 곡선을 형성합니다. 곡선이 느리게 쇠퇴할수록 유지율이 높아지며 이는 홈페이지 수정이 긍정적인 효과가 있음을 반영합니다. 물론, 때로는 리텐션 개선이 수십 퍼센트에 불과할 수도 있지만, 대규모 사용자 기반을 전제로 하면 약간의 질적인 변화가 발생할 수도 있습니다. 또한 특정 그룹의 사람들을 사용자 그룹으로 정의하고, 다양한 사용자 그룹에 대한 유지 분석을 수행하고, 더 충성도가 높은 사용자 그룹을 발견할 수 있습니다.
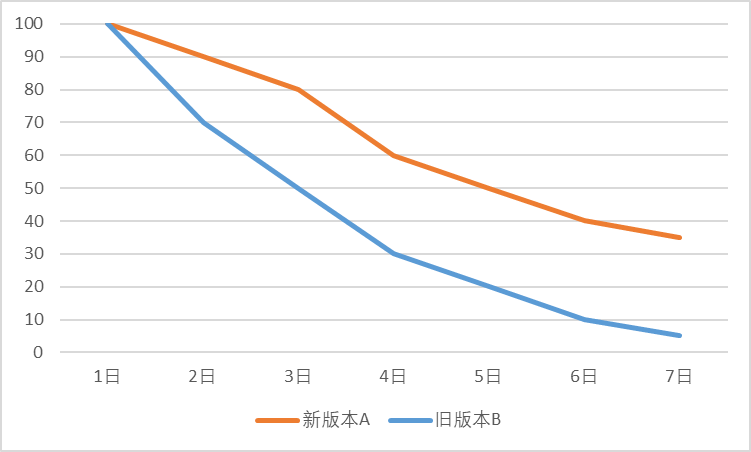
그림 1 새 버전 A와 이전 버전 B의 보존 비교
3. Retention을 활용한 데이터 분석
이제 위의 보존 모델의 기본 개념을 이해했으므로 모델을 만드는 방법을 살펴보겠습니다.
3.1 개막행사 및 재방문행사 선택
시작 이벤트: 브라우저를 엽니다.
재방문 이벤트: 브라우저를 종료합니다.
3.2 보관일 설정
보존 기간을 3일로 설정합니다.
3.3 보존 시간 간격 결정
여기서 시간 간격의 개념은 확인해야 하는 날짜 간격을 의미합니다. 예를 들어 시간 간격을 2023-01-06~2023-01-08로 선택하면 2023-01-06부터 3일만 표시됩니다. 2023-01-08로 계산되며, 매일 같은 날에 유지되고, 1일에 유지되고, 2일에 유지되고, 3일에 유지됩니다.
3.4 보유 데이터의 표시 및 계산 논리
시작 사용자 수 = 계산된 날짜에 시작 이벤트를 트리거한 사용자 수입니다.
당일 유지 사용자 수 = 당일 재방문 이벤트를 발생시킨 사용자와 당일 최초 이벤트를 발생시킨 사용자의 교차점입니다.
첫날 유지 사용자 수 = 다음날 재방문 이벤트를 발생시킨 사용자와 계산된 날짜에 시작 이벤트를 발생시킨 사용자의 교집합입니다.
2일째 유지 사용자 수 = 2일 후 재방문 이벤트를 발동한 사용자와 계산된 날짜에 시작 이벤트를 발동한 사용자의 교집합입니다.
3일째 유지 사용자 수 = 3일 후 재방문 이벤트를 발생시킨 사용자와 계산된 날짜에 시작 이벤트를 발생시킨 사용자의 교집합입니다.
당일 유지율 = 당일 유지 사용자 수 / 최초 사용자 수 * 100%입니다.
첫날 유지율 = 첫날 유지 사용자 수 / 초기 사용자 수 * 100%.
2일째 유지율 = 2일째 유지된 사용자 수/초기 사용자 수*100%입니다.
3일째 유지율 = 3일차 유지 사용자 수/최초 사용자 수*100%.
사용자 유지 수치 테이블(즉, 표 1)은 시작 이벤트가 '브라우저 열기'이고 재방문 이벤트가 '브라우저 종료'인 경우, 2023년 1월 6일부터 2023년 1월 6일까지 최근 3일 동안 유지된 사용자에 해당함을 나타냅니다. 2023-01-09.
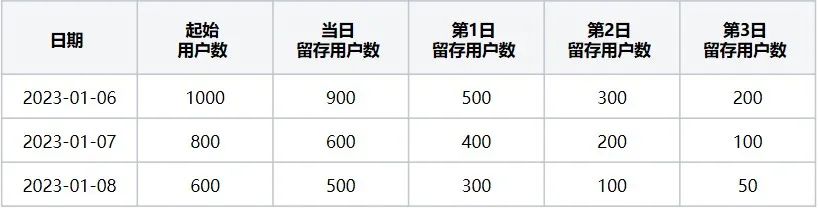
표 1 사용자 유지 번호 표
사용자 유지율 표(표 2)는 시작 이벤트가 '브라우저 열기'이고 재방문 이벤트가 '브라우저 종료'인 경우 2023년 1월 6일부터 2023년 1월 6일까지 최근 3일 동안 유지된 사용자에 해당함을 나타냅니다. 2023-01-08 비율 데이터.
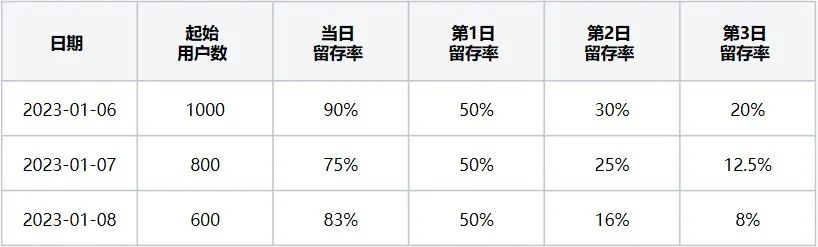
표 2 사용자 유지율 표
표 1의 2023-01-06 데이터를 예로 들면, 1월 6일 시작 사용자 수는 1,000명입니다. 즉, "브라우저 열기" 시작 이벤트를 실행한 사용자 수를 의미합니다. day: 900: 초기 이벤트 사용자 중 당일 재방문 이벤트 "브라우저 종료"를 발생시킨 사용자 수.
첫날 유지 사용자 수 : 500 : 1월 7일 재방문 이벤트를 발생시키고 1월 6일 첫 이벤트와 교차한 사용자 수, 둘째 날 유지 사용자 수 : 300 : 1월 8일 재방문 이벤트를 발동한 사용자 수와 1월 6일 시작 이벤트를 발동한 교차로 사용자 수는 300명이 되며, 이때 3일 동안 보관되는 데이터는 3일입니다. 2023-01-06이 계산되었습니다!
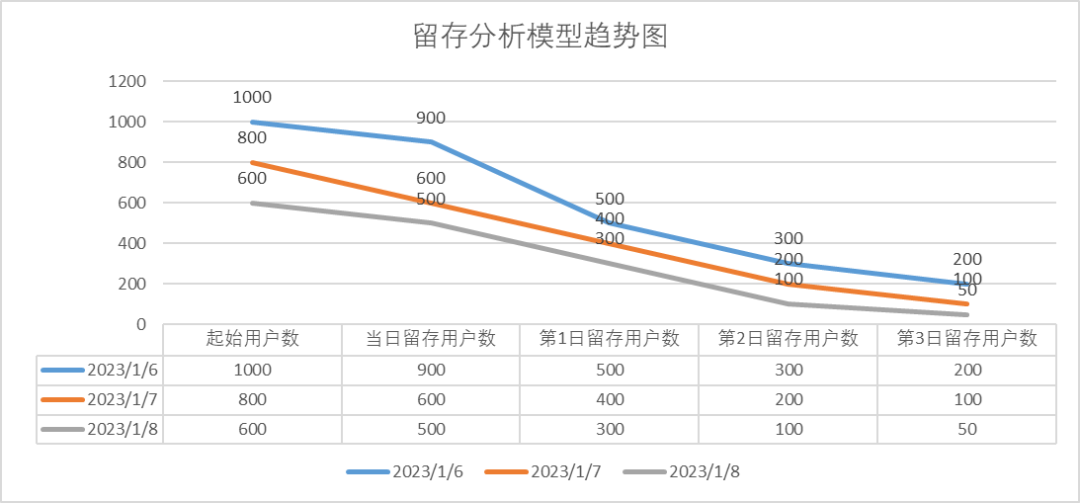
그림 2: 초기 이벤트 및 재방문 이벤트 발생에 따른 3일 이내 유지 사용자 추세 차트
4. 전반적인 기능 설계 및 유지 분석 모델 구현
4.1 (오프라인) 기능 전체 아키텍처 설계
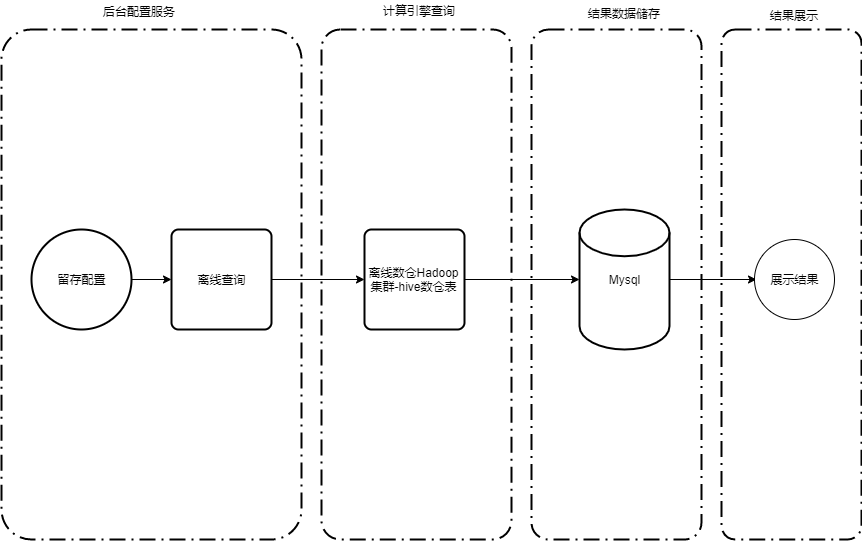
그림 3 보존 분석 모델의 Hive 아키텍처 다이어그램
전체 아키텍처는 주로 구성, 계산, 저장 및 표시의 네 단계로 나뉩니다.
1. 구성
이 단계는 주로 엔지니어링 측면의 백그라운드 서비스 구현에 관한 것입니다. 사용자는 플랫폼에서 자신의 필요에 따라 시작 이벤트 및 재방문 이벤트, 필터링 조건, 사용자 그룹 필터링, 차원 필터링 및 기타 구성을 설정할 수 있습니다. 구성 요청을 받은 후 백그라운드 서비스는 보존 분석 유형에 따라 다양한 작업 어셈블러를 선택하여 SQL 작업을 어셈블합니다.
2. 계산
플랫폼은 수신된 쿼리 방법을 기반으로 분석 및 계산을 위해 오프라인 쿼리 Spark 엔진을 선택합니다. 오프라인 계산 결과는 MySQL에 동기화됩니다.
3. 보관
오프라인 결과 세트는 MySQL 데이터베이스에 유지되며 백그라운드 서비스를 통해 사용자에게 표시될 수 있습니다.
4. 디스플레이
MySQL 결과 테이블 데이터를 쿼리하여 차트 구성 ID에 따라 오프라인 결과가 표시됩니다. 구성 후 인스턴트 쿼리가 직접 쿼리되어 표시됩니다.
4.2 (오프라인) 다양한 보존 조건에서 SQL 구현
하이브 작업 SQL의 오프라인 범용 실행
오프라인 보존 하이브 실행 SQL
SQL에서 필드의 의미는 다음과 같습니다.
[origin_day]: 보존 계산 시작 날짜
[일]: 최종 보존 계산 날짜
[diff]: 저장할 날짜
[사용자]: 시작 사용자 수
【보존】:보존번호
위 SQL의 의미는 리텐션 계산 시작일부터 시작 시간, 종료 시간까지의 기간 동안의 일자별 리텐션 데이터를 조회하는 것이며, 해당 시간 간격의 전체 리텐션 데이터는 한번에 계산할 수 없기 때문이다. 이 SQL 실행 결과는 유지된 결과 테이블을 채우는 역삼각형으로 표시됩니다.
예: 시작 이벤트와 재방문 이벤트를 설정한 후 2022-05-01부터 2022-05-05까지 매일 3일 리텐션을 계산합니다. 이때 시작 시간은 2022-05-01입니다. 종료시간은 2022-05-05이며, 보존기간은 3일입니다.
이 경우 리텐션 계산 시작 날짜는 2022-05-01~2022-05-08이어야 하므로 2022-05-01~2022-05-05까지 일자별로 3일 리텐션을 계산할 수 있습니다.
1단계 : 시작 보존 날짜 = 2022-05-01을 계산하고, 최종 보존 계산 날짜 범위는 시간 관점에서 2022-05-01부터 2022-05-05까지의 일일 보존 데이터입니다. 2022-05-01의 유지율만 계산할 수 있습니다. 실행 후 결과는 다음과 같습니다(표 3).

표 3
起始留存计算日期2022-05-01在2022-05-01~2022-05-05区间内留存详情数据
此时转换后留存数据表格为(表4):
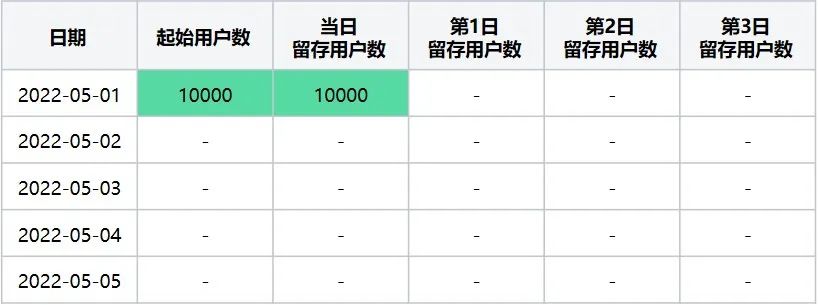
表4
起始留存计算日期2022-05-01在2022-05-01~2022-05-05区间内转换后留存数据表
第二步:计算起始留存日期 = 2022-05-02时,最终留存计算日期区间2022-05-01~2022-05-05日每天的留存数据,该起始留存计算日期可计算2022-05-01日的第1日留存用户数及2022-05-02日当日留存用户数据,执行后结果如下(表5):

表5
起始留存计算日期2022-05-02在2022-05-01~2022-05-05区间内留存详情数据
此时转换后留存数据表格为(表6):
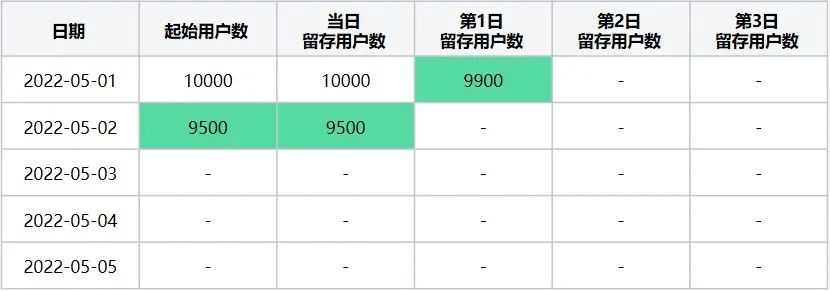
表6
起始留存计算日期2022-05-02在2022-05-01~2022-05-05区间内转换后留存数据表
第三步:计算起始留存日期 = 2022-05-03时,最终留存计算日期区间2022-05-01~2022-05-05日每天的留存数据,该起始留存计算日期可计算2022-05-01日的第2日留存用户数、2022-05-02日第1日留存用户数据、2022-05-03日当日留存用户数据,执行后结果如下(表7):
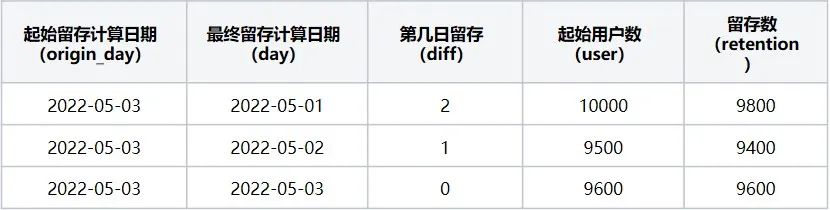
表7
起始留存计算日期2022-05-03在2022-05-01~2022-05-05区间内留存详情数据
此时转换后留存数据表格为(表8):
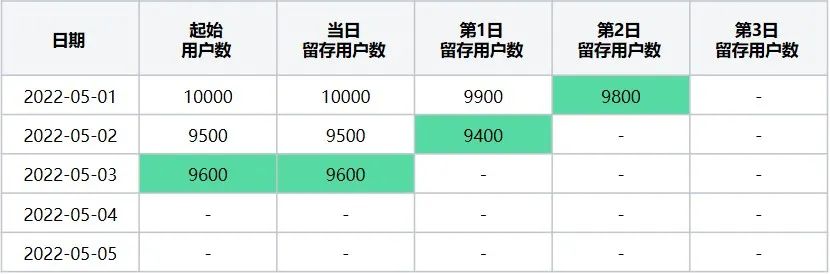
表8
起始留存计算日期2022-05-03在2022-05-01~2022-05-05区间内转换后留存数据表
第四步:以此类推,计算起始留存日期 = 2022-05-08时,最终留存计算日期区间2022-05-01~2022-05-05日每天的留存数据,该起始留存计算日期可计算2022-05-05日的第3日留存用户数,执行后结果如下(表9):

表9
起始留存计算日期2022-05-08在2022-05-01~2022-05-05区间内留存详情数据
最终数据展示完全后会是一个完整的表格(可得如下结果表10):
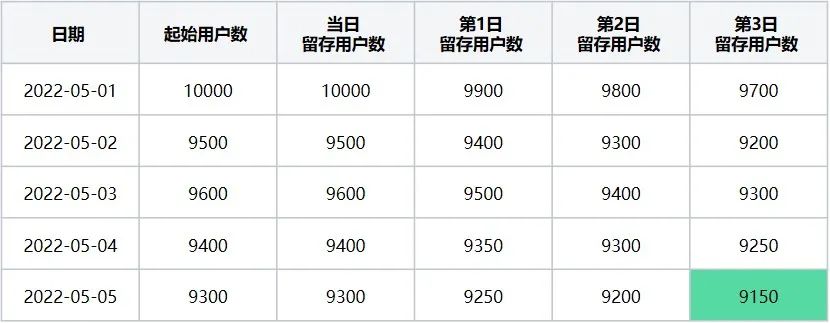
表10
2022-05-01~2022-05-05的每一天的3日留存数据表
4.3 存在的问题与下一步优化的方向
存在的问题:
用户在平台上进行报表创建后,在产出报表结果上耗时较长;当配置报表查询周期长,数据量大的情况下,存在计算资源消耗过大的情况。
优化方向:
为了优化报表生成过程,可以考虑使用ClickHouse来处理数据。ClickHouse是一个高性能、分布式、列式存储的数据库系统,特别适合处理大规模数据和复杂查询。
具体而言,可以采用以下ClickHouse特性:
将数据导入ClickHouse中,以便更快地查询和计算。ClickHouse支持高效的数据导入和压缩方式,可以大大减少数据的存储空间和查询时间。
利用ClickHouse的列式存储和分布式计算能力,实现增量计算和数据预处理。通过使用ClickHouse的分布式计算能力,可以将计算任务分配给多个节点并行处理,从而加快计算速度。同时,通过使用ClickHouse的列式存储能力,可以避免不必要的数据读取和计算,提高计算效率。
利用ClickHouse的缓存机制,提高查询效率。ClickHouse支持高效的缓存机制,可以将查询结果缓存在内存中,以便更快地响应查询请求。
利用ClickHouse的SQL查询语言,实现灵活的数据分析和报表生成。ClickHouse支持SQL查询语言,可以方便地进行数据分析和报表生成,同时也支持复杂查询和聚合操作,可以满足各种数据分析需求。
通过利用ClickHouse上述特性,进一步提高整个数据分析过程的效率和准确性。
五、基于ClickHouse的留存分析模型
5.1 利用ClickHouse查询速度快的特性改造离线留存图表产出方式
利用ClickHouse进行实时留存查询
传统的离线留存计算通常需要借助Hadoop、Spark等大数据处理框架,需要消耗大量计算资源和时间。而利用ClickHouse进行离线留存计算,可以大大提高计算速度和效率,可以实现秒级响应和高并发查询。
具体步骤如下:
将用户行为数据导入ClickHouse;
根据查询配置数据组装留存SQL用于查询;
利用ClickHouse的高速查询功能,实时查询留存率数据。
利用ClickHouse进行留存图表的产出
利用ClickHouse进行留存计算和查询后,可以通过数据可视化工具对留存数据进行图表化展示,从而更加直观地了解用户留存情况。例如:
利用数据可视化工具连接ClickHouse数据库,查看留存率数据或者通过http请求查询结果表数据;
通过数据可视化工具绘制留存图表,并进行定制化设计和样式调整。
结合hive、ClickHouse两者优点,可将架构做如下优化,对于历史较长时间日期的结果回溯进行hive查询处理,可在ClickHouse中存储的数据作为每天例行查询存储结果。
例行:是指创建一次图表每日例行执行报表任务,产出数据(例行可回溯ClickHouse中存储日期的留存数据)。
手动:是指在指定时间范围内执行,执行完成产出任务停止。
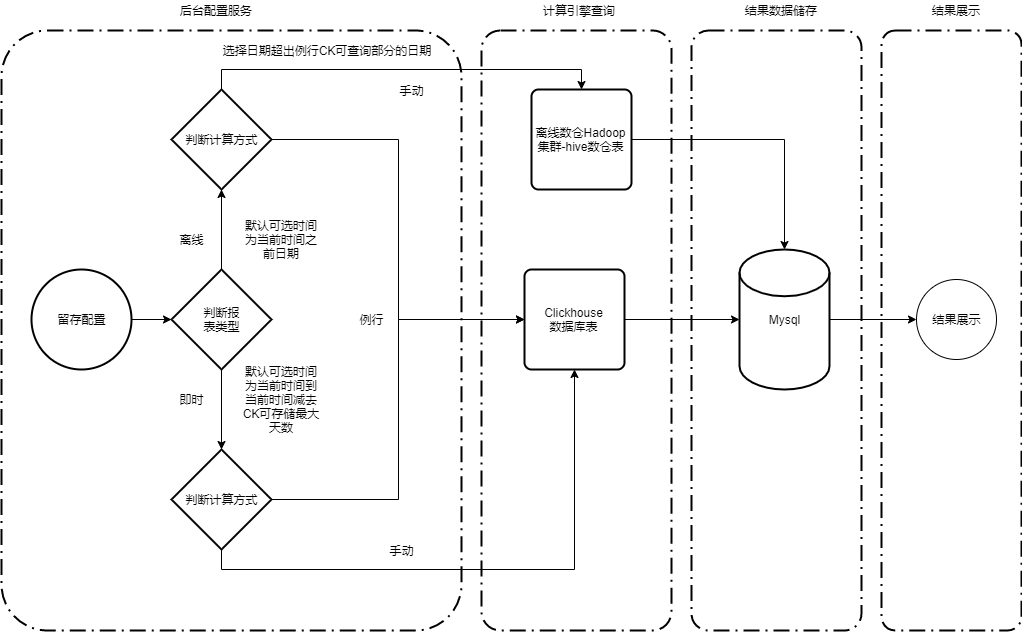
图4 结合ClickHouse、hive后留存分析模型架构图
5.2 主要函数介绍
Retention
该函数将一组条件作为参数,类型为1到32个 UInt8 类型的参数,用来表示事件是否满足特定条件。任何条件都可以指定为参数(如 WHERE)。
除了第一个以外,条件成对适用:如果第一个和第二个是真的,第二个结果将是真的,如果第一个和第三个是真的,第三个结果将是真的,等等。
① 语法
retention(cond1, cond2, ..., cond32);
② 参数
cond — 返回 UInt8 结果(1或0)的表达式。
③ 返回值
数组为1或0。
1 — 条件满足。
0 — 条件不满足。
④ 类型
UInt8
ClickHouse查询SQL
ClickHouse即时查询留存SQL
SQL 当中返回结果含义分别为:
retention_date:留存日期
user:起始用户数
retain0:当日留存用户数
retain1:第1日留存用户数
retain2:第2日留存用户数
retain3:第3日留存用户数
ratio0:当日留存率
ratio1:第1日留存率
ratio2:第2日留存率
ratio3:第3日留存率
以上SQL含义:计算出指定时间区间内3日留存信息,可一次性查询出指定区间内的所有3日留存数据,一个sql即可查询完全。
例如:我们定了起始事件和回访事件后,去计算2022-06-01~2022-06-04的每一天的3日留存,此时,起始时间是2022-06-01,结束2022-06-04,留存天数3天。
针对此案例,在不同的日期查询数据完整性不一致,我们拿2022-06-04日和2022-06-07日两日查询举例。
第一步:针对2022-06-04日进行计算2022-06-01~2022-06-04的每一天的3日留存,执行后留存数据展示结果如下(表11)。

表11
2022-06-04日计算2022-06-01~2022-06-04的每一天的3日留存数据表
第二步:针对2022-06-07日进行计算2022-06-01~2022-06-04的每一天的3日留存,执行后留存数据展示结果如下(表12)。

表12
2022-06-08日计算2022-06-01~2022-06-04的每一天的3日留存数据表
趋势结果展示(图5):
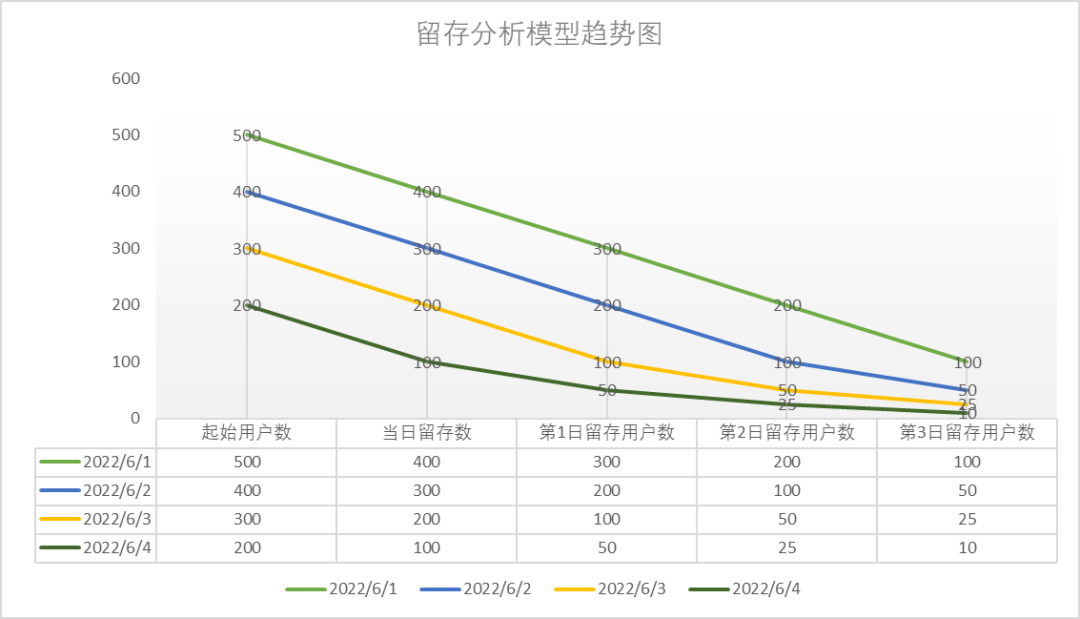
图5 留存分析模型趋势图
六、写在最后
本文介绍的留存模型就是数据分析工具箱的核心分析模型,使用的范围十分广泛。它通过计算用户在一段时间内的留存率,可以评估产品、服务或应用程序的用户体验和吸引力,提高用户留存率和活跃度。在实际的生产中,业务可根据自身具体需求和用户特征进行定制化设计,同时也可将通过留存分析得到的人群信息结合其他的数据分析方法进一步的深入分析。例如,从留存中得到的用户人群信息,我们可以进一步的使用路径分析的分析方法,分析用户的访问行为对于产品的影响。
数据分析的工具方法有很多,除了上面提到过得用于分析用户在应用上的访问行为的用户路径分析;也有衡量业务中关键事件之间转化效果的漏斗分析;还有事件分析、归因分析等等,他们共同组成的强大的数据分析工具箱,可以较为全面的分析用户行为的潜在特征与规律,帮助产品或者决策者作为更加可靠的决策。
END
猜你喜欢
本文分享自微信公众号 - vivo互联网技术(vivoVMIC)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。