

이 기사에서는 장점과 단점, 사용 방법, 카탈로그 솔루션과의 비교를 포함하여 Databend 개방형 테이블 형식 엔진의 지원을 소개합니다. 또한 Databend Cloud를 사용하여 개체 스토리지에 있는 Delta Table을 분석하는 방법을 소개하는 간단한 워크샵이 포함되어 있습니다.
Databend는 최근 서로 다른 기술 스택을 기반으로 하는 최신 데이터 레이크 솔루션의 고급 분석 요구 사항을 충족하기 위해 가장 널리 사용되는 두 가지 개방형 테이블 형식을 지원하기 위해 Apache Iceberg와 Delta Table이라는 두 가지 테이블 엔진을 출시했습니다.
Databend/Databend Cloud 기반의 원스톱 솔루션을 사용하면 공개 테이블 형식 데이터에 대한 통찰력을 얻고 추가 Spark/Databricks 서비스를 활성화하지 않고도 배포 아키텍처 및 분석 프로세스를 단순화할 수 있습니다. 또한 Apache OpenDAL™을 기반으로 구축된 Databend/Databend Cloud의 데이터 액세스 솔루션을 사용하면 개체 스토리지, HDFS, 심지어 IPFS까지 포함한 수십 가지 스토리지 서비스에 쉽게 액세스할 수 있으며 기존 기술 스택과 쉽게 통합될 수 있습니다.
이점
-
오픈 테이블 형식 엔진을 사용할 경우 테이블 엔진의 종류(
Delta또는Iceberg)와 데이터 파일이 저장되는 위치만 지정하면 해당 테이블에 직접 접근하여 Databend를 사용해 쿼리할 수 있다. -
Databend의 개방형 테이블 형식 엔진을 사용하면 다양한 데이터 소스와 데이터를 다양한 테이블 형식으로 혼합하는 시나리오를 쉽게 처리할 수 있습니다.
- 동일한 데이터베이스 객체 내에서 다양한 형식으로 요약된 데이터 테이블을 쿼리하고 분석합니다.
- Databend의 풍부한 스토리지 백엔드 통합을 통해 다양한 스토리지 백엔드의 데이터 액세스 요구 사항을 처리할 수 있습니다.
불충분하다
- 현재 Apache Iceberg 및 Delta Lake 엔진은 읽기 전용 작업만 지원합니다. 즉, 데이터를 쿼리할 수만 있고 테이블에 데이터를 쓸 수는 없습니다.
- 테이블의 스키마는 테이블이 생성될 때 결정됩니다. 원본 테이블의 스키마가 수정되면 데이터 일관성과 동기화를 보장하기 위해 Databend에서 테이블을 다시 생성해야 합니다.
지침
-- Set up connection
CREATE [ OR REPLACE ] CONNECTION [ IF NOT EXISTS ] <connection_name>
STORAGE_TYPE = '<type>'
[ <storage_params> ]
-- Create table with Open Table Format engine
CREATE TABLE <table_name>
ENGINE = [Delta | Iceberg]
LOCATION = '<location_to_table>'
CONNECTION_NAME = '<connection_name>'
팁: Databend에서
CONNECTION액세스 자격 증명, 엔드포인트 URL, 스토리지 유형 등 외부 스토리지 서비스와 상호 작용하는 데 필요한 세부 정보를 관리하는 데 사용하세요. 을 지정하면CONNECTION_NAME리소스 생성 시 이를 재사용할 수 있어CONNECTION스토리지 구성의 관리 및 사용이 단순화됩니다.
카탈로그 솔루션과 비교
Databend는 이전에 Catalog를 통해 Iceberg 및 Hive에 대한 지원을 제공했습니다. 테이블 엔진과 비교하여 Catalog는 전체 도킹 관련 생태와 한 번에 여러 데이터베이스 및 테이블을 마운트하는 데 더 적합합니다.
새로운 오픈 테이블 형식 엔진은 경험 측면에서 더욱 유연해졌으며, 동일한 데이터베이스에서 다양한 데이터 소스와 다양한 테이블 형식의 데이터를 집계 및 혼합하고 효과적인 분석과 통찰력을 수행할 수 있습니다.
워크샵: Databend Cloud를 사용하여 Delta Table의 데이터 분석
이 예에서는 Databend Cloud를 사용하여 객체 스토리지에 있는 델타 테이블을 로드하고 분석하는 방법을 보여줍니다.
우리는 전통적인 펭귄 몸체 특징 데이터 세트(펭귄)를 사용하여 이를 델타 테이블로 변환하고 S3 호환 객체 스토리지에 배치할 것입니다. 이 데이터 세트에는 특성 변수 7개, 범주형 변수 1개 등 총 8개 변수가 포함되어 있으며 총 344개 샘플이 포함되어 있습니다.
- 범주형 변수는 딱딱한 꼬리 펭귄 속의 3개 하위 속 , 즉 Adélie, Chinstrap 및 Gentoo에 속하는 펭귄 종(종)입니다.
- 포함된 3마리 펭귄의 6가지 특성은 섬(island), 부리 길이(bill_length_mm), 부리 깊이(bill_length_mm), 지느러미 길이(flipper_length_mm), 체중(body_mass_g), 성별(sex)입니다.
아직 Databend Cloud 계정이 없다면 https://app.databend.cn/register를 방문하여 등록하고 무료 할당량을 받으세요. 또는 https://docs.databend.com/guides/deploy/ 를 참조하여 Databend를 로컬로 배포할 수 있습니다.
이 문서에서는 개체 스토리지 사용에 대해서도 다루며, 무료 할당량으로 Cloudflare R2를 사용하여 버킷을 생성해 볼 수도 있습니다.
객체 스토리지에 데이터 쓰기
원시 데이터 제공, 데이터를 델타 테이블로 변환 및 S3에 쓰는 작업을 seaborn담당하는 해당 Python 패키지를 설치해야 합니다 .deltalake
pip install deltalake seaborn
그런 다음 아래 코드를 편집하고 해당 액세스 자격 증명을 구성한 후 다음과 같이 저장합니다 writedata.py.
import seaborn as sns
from deltalake.writer import write_deltalake
ACCESS_KEY_ID = '<your-key-id>'
SECRET_ACCESS_KEY = '<your-access-key>'
ENDPOINT_URL = '<your-endpoint-url>'
storage_options = {
"AWS_ACCESS_KEY_ID": ACCESS_KEY_ID,
"AWS_SECRET_ACCESS_KEY": SECRET_ACCESS_KEY,
"AWS_ENDPOINT_URL": ENDPOINT_URL,
"AWS_S3_ALLOW_UNSAFE_RENAME": 'true',
}
penguins = sns.load_dataset('penguins')
write_deltalake("s3://penguins/", penguins, storage_options=storage_options)
위의 Python 스크립트를 실행하여 객체 스토리지에 데이터를 씁니다.
python writedata.py
Delta 테이블 엔진을 사용하여 데이터에 액세스
Databend에서 해당 액세스 자격 증명을 만듭니다.
--Set up connection
CREATE CONNECTION my_r2_conn
STORAGE_TYPE = 's3'
SECRET_ACCESS_KEY = '<your-access-key>'
ACCESS_KEY_ID = '<your-key-id>'
ENDPOINT_URL = '<your-endpoint-url>';
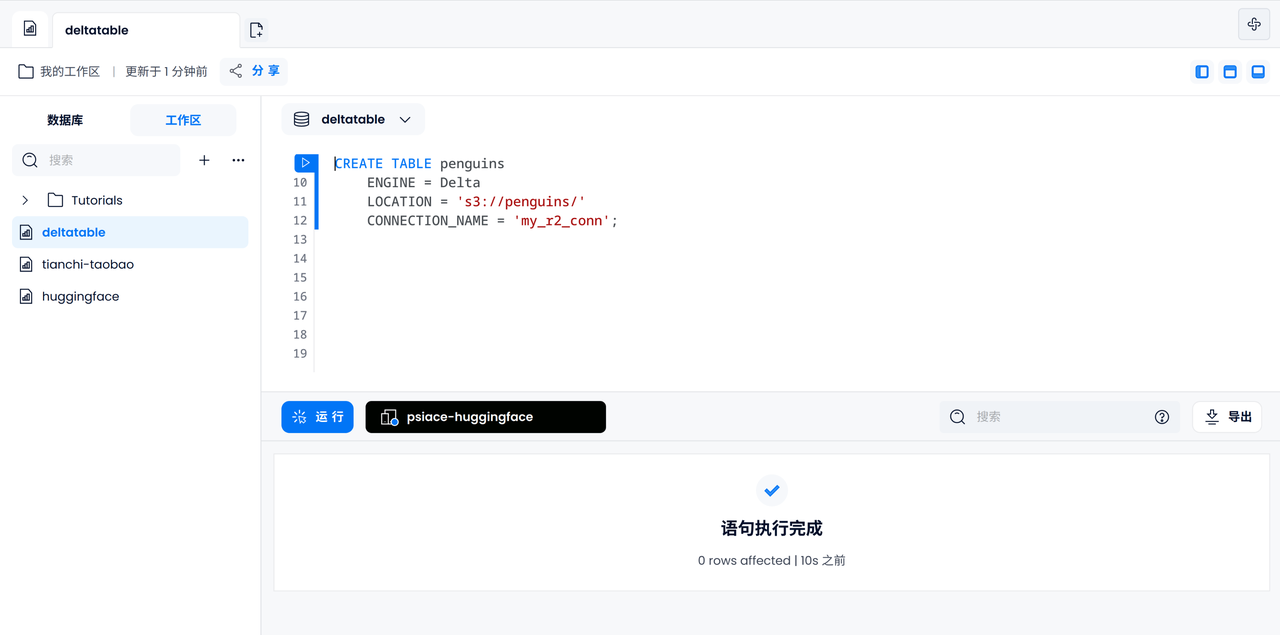
Delta 테이블 엔진으로 구동되는 데이터 테이블을 만듭니다.
-- Create table with Open Table Format engine
CREATE TABLE penguins
ENGINE = Delta
LOCATION = 's3://penguins/'
CONNECTION_NAME = 'my_r2_conn';
SQL을 사용하여 테이블의 데이터 쿼리 및 분석
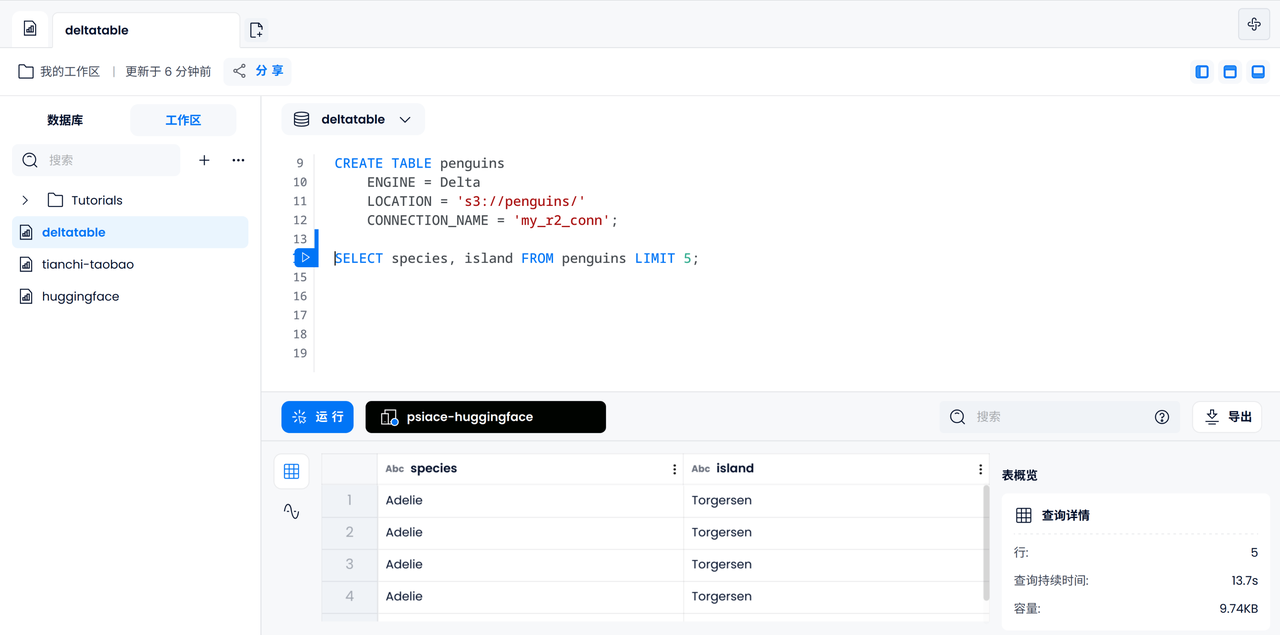
데이터 접근성 확인
먼저 5마리의 펭귄의 종과 섬을 출력하여 Delta Table의 데이터에 올바르게 접근할 수 있는지 확인해 보겠습니다.
SELECT species, island FROM penguins LIMIT 5;
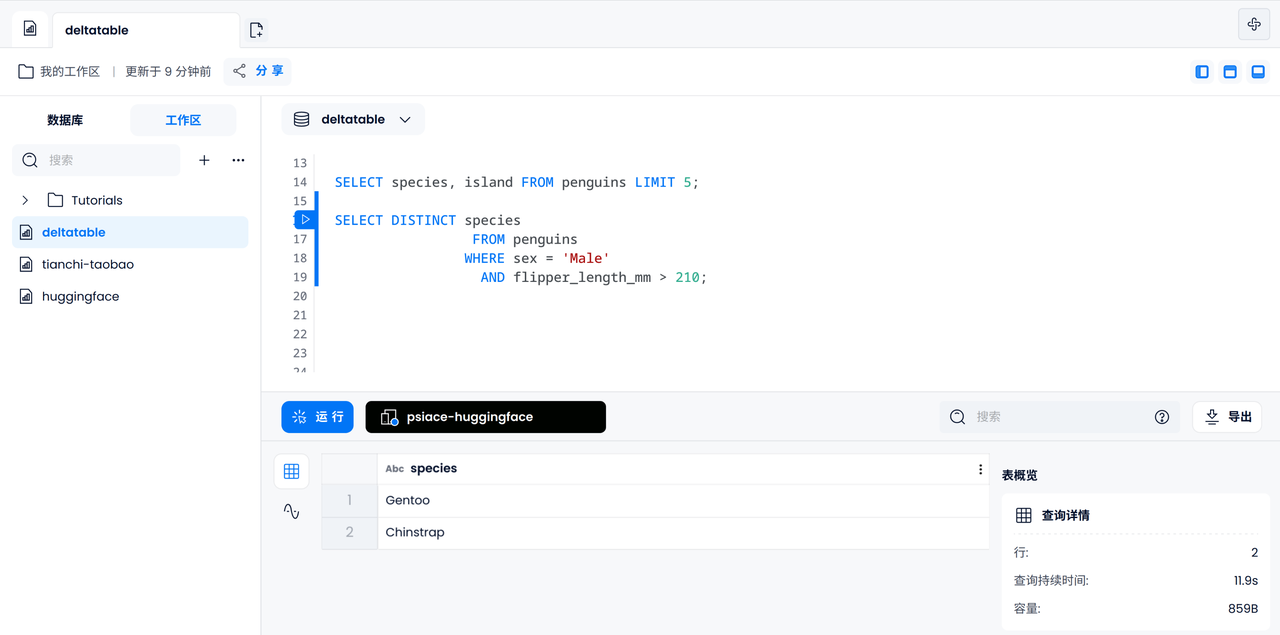
데이터 필터링
다음으로 지느러미 길이가 210mm를 초과하는 수컷 펭귄이 속할 수 있는 아속을 찾는 등 몇 가지 기본 데이터 필터링 작업을 수행할 수 있습니다.
SELECT DISTINCT species
FROM penguins
WHERE sex = 'Male'
AND flipper_length_mm > 210;
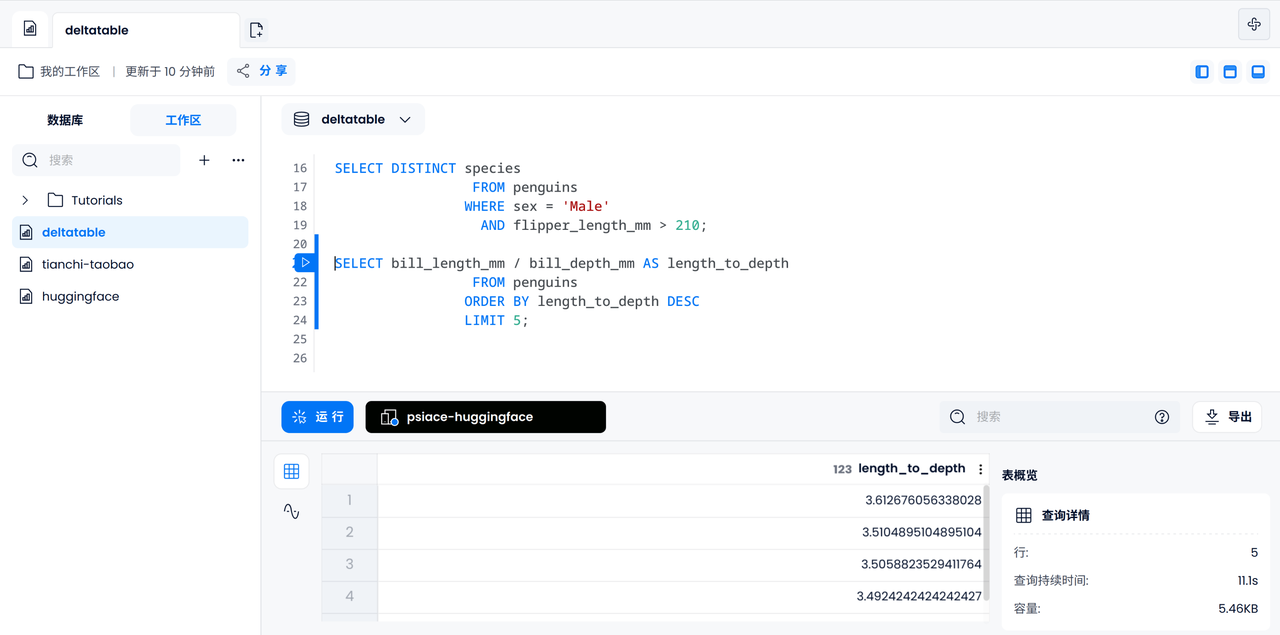
데이터 분석
마찬가지로 각 펭귄의 부리 길이와 깊이의 비율을 계산하여 가장 큰 펭귄 5개를 출력할 수 있습니다.
SELECT bill_length_mm / bill_depth_mm AS length_to_depth
FROM penguins
ORDER BY length_to_depth DESC
LIMIT 5;
혼합 데이터 소스 사례: 펭귄 관찰 로그
이제 흥미로운 부분을 입력하겠습니다. 과학 연구소에서 관찰 기록을 찾았다고 가정하고, 동일한 데이터베이스에 이 데이터를 입력하고 간단한 데이터 분석을 수행해 보겠습니다. 특정 성별의 새가 무엇입니까? 펭귄이 과학자에 의해 태그될 확률.
관찰 로그 테이블 생성
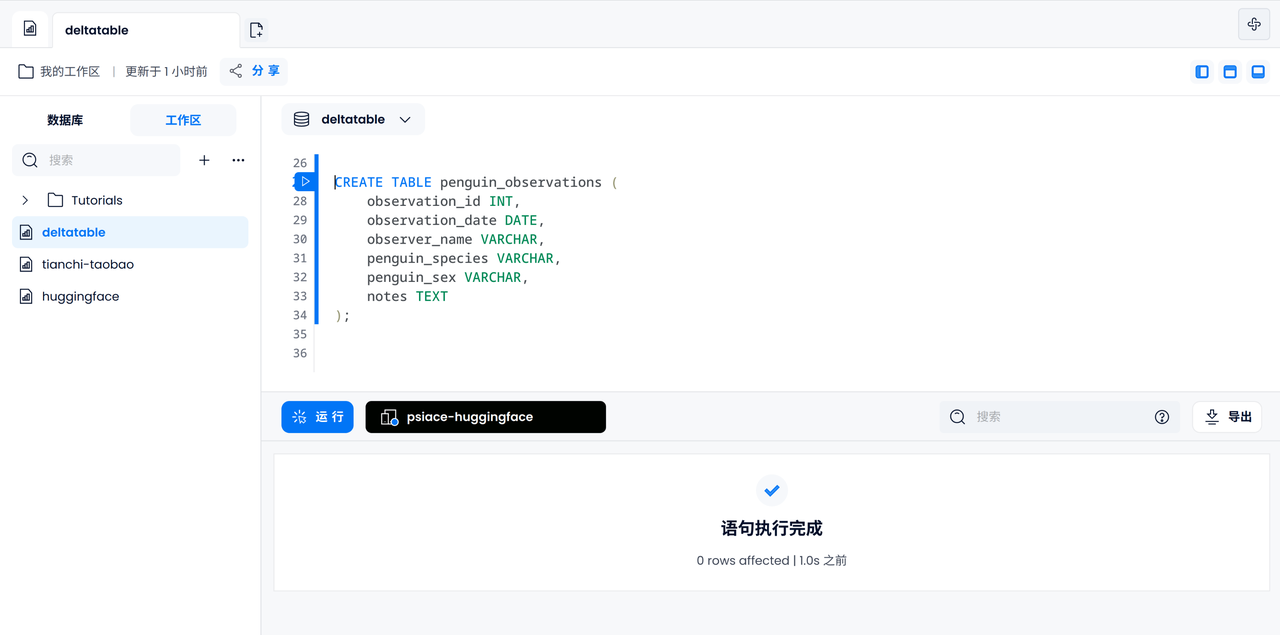
기본 FUSE 엔진을 사용하여 penguin_observationsID, 날짜, 이름, 펭귄 종 및 성별, 비고 및 기타 정보가 포함된 테이블을 만듭니다.
CREATE TABLE penguin_observations (
observation_id INT,
observation_date DATE,
observer_name VARCHAR,
penguin_species VARCHAR,
penguin_sex VARCHAR,
notes TEXT,
);
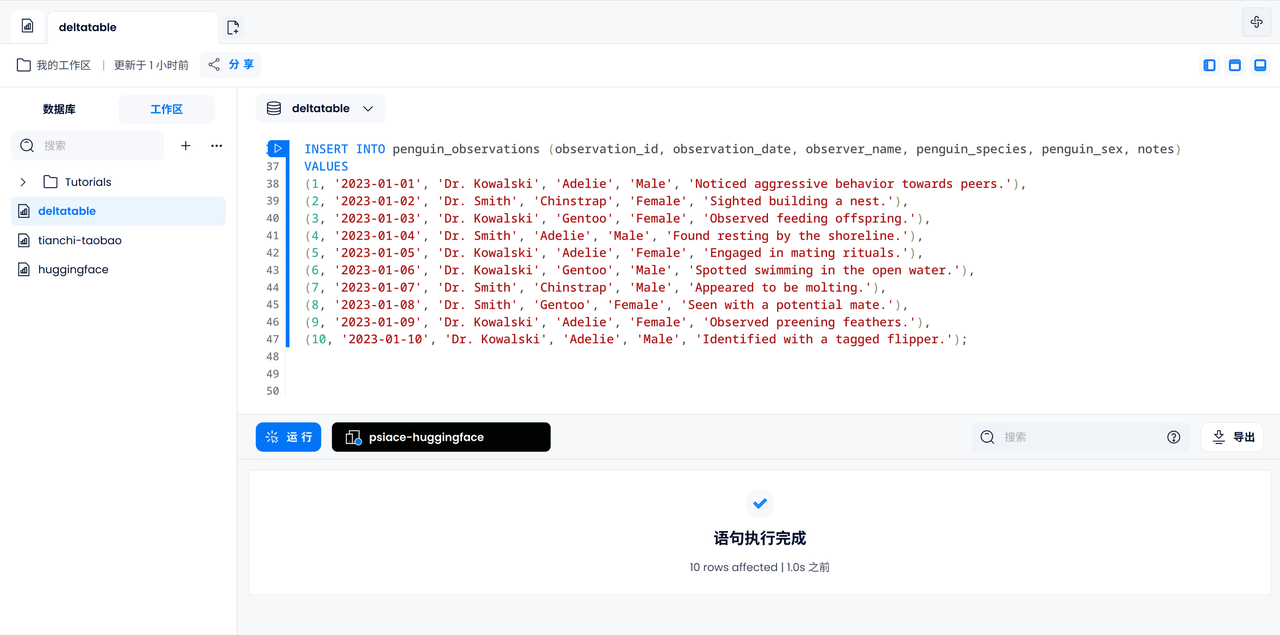
관찰 기록을 입력하세요
10개의 로그를 모두 수동으로 입력해 보겠습니다. 로그기록에 등장하는 펭귄은 서로 다른 것으로 알려져 있다.
INSERT INTO penguin_observations (observation_id, observation_date, observer_name, penguin_species, penguin_sex, notes)
VALUES
(1, '2023-01-01', 'Dr. Kowalski', 'Adelie', 'Male', 'Noticed aggressive behavior towards peers.'),
(2, '2023-01-02', 'Dr. Smith', 'Chinstrap', 'Female', 'Sighted building a nest.'),
(3, '2023-01-03', 'Dr. Kowalski', 'Gentoo', 'Female', 'Observed feeding offspring.'),
(4, '2023-01-04', 'Dr. Smith', 'Adelie', 'Male', 'Found resting by the shoreline.'),
(5, '2023-01-05', 'Dr. Kowalski', 'Adelie', 'Female', 'Engaged in mating rituals.'),
(6, '2023-01-06', 'Dr. Kowalski', 'Gentoo', 'Male', 'Spotted swimming in the open water.'),
(7, '2023-01-07', 'Dr. Smith', 'Chinstrap', 'Male', 'Appeared to be molting.'),
(8, '2023-01-08', 'Dr. Smith', 'Gentoo', 'Female', 'Seen with a potential mate.'),
(9, '2023-01-09', 'Dr. Kowalski', 'Adelie', 'Female', 'Observed preening feathers.'),
(10, '2023-01-10', 'Dr. Kowalski', 'Adelie', 'Male', 'Identified with a tagged flipper.');
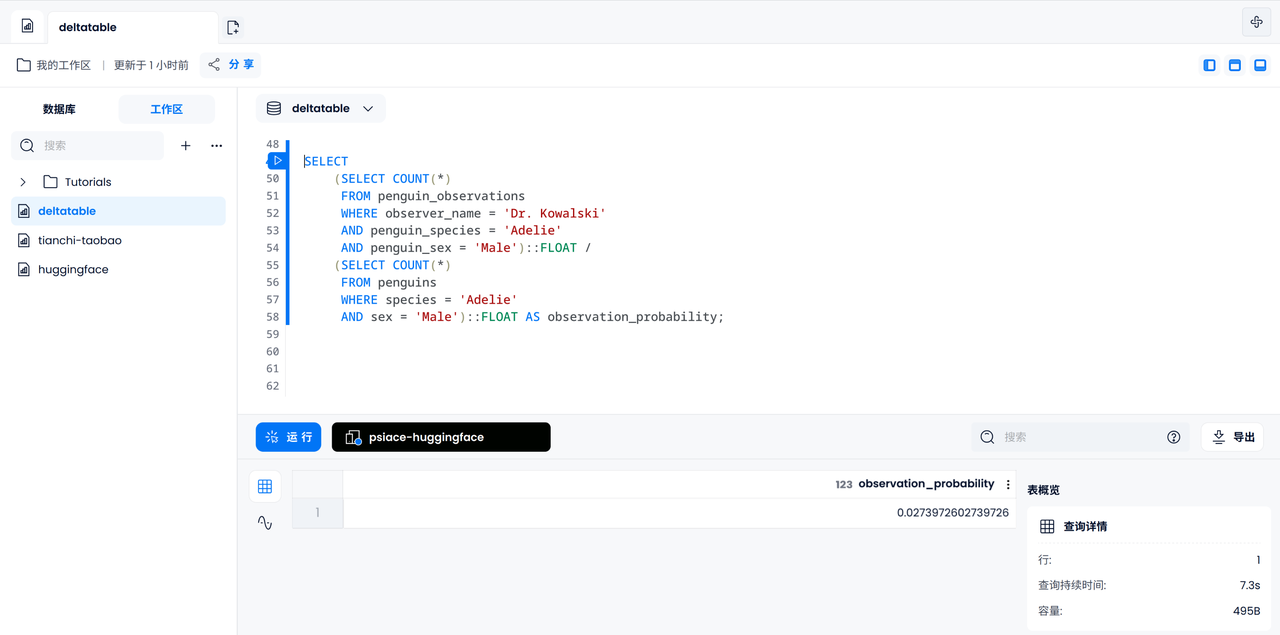
채점 확률 계산
이제 코왈스키 박사가 모든 펭귄 중에서 특정 수컷 아델리 펭귄을 관찰할 확률을 계산해 보겠습니다. 먼저 코왈스키 박사가 관찰한 수컷 아델리펭귄의 수를 세고, 기록된 모든 수컷 아델리펭귄의 수를 세고, 마지막으로 나누어서 결과를 얻어야 합니다.
SELECT
(SELECT COUNT(*)
FROM penguin_observations
WHERE observer_name = 'Dr. Kowalski'
AND species = 'Adelie'
AND sex = 'Male')::FLOAT /
(SELECT COUNT(*)
FROM penguins
WHERE species = 'Adelie'
AND sex = 'Male')::FLOAT AS observation_probability;
요약하다
쿼리를 위해 다양한 테이블 엔진을 결합함으로써 Databend/Databend Cloud는 분석 및 쿼리를 위해 동일한 데이터베이스에서 다양한 형식의 테이블 혼합을 지원할 수 있습니다. 이 문서에서는 모든 사람이 기능과 사용법을 경험할 수 있는 기본 워크샵만 제공합니다. 이 사례를 기반으로 확장하고 데이터 분석을 위해 Iceberg와 Delta Table을 결합하는 더 많은 시나리오와 더 많은 잠재적인 실제 응용 프로그램을 탐색할 수 있습니다.