배경 소개
범위(파티셔닝)는 데이터베이스 관리 및 데이터 구성을 위한 기술입니다. 분산 시스템에서는 특정 규칙에 따라 데이터를 여러 범위로 구성하고 분할 및 병합을 통해 동적 관리를 달성하여 쿼리 성능을 최적화하고 시스템의 확장성과 가용성 및 로드 밸런싱을 향상시킬 수 있습니다. 이 라이브 방송의 주요 내용은 KaiwuDB 분산 시스템의 범위 분할 및 병합입니다.
다음은 내용의 일부를 발췌한 내용입니다. 전체 내용을 보시려면 클릭하시면 전체 내용을 보실 수 있습니다. >> 전체 내용 영상 재생
KaiwuDB 범위 분할
분할 소개
SplitQueue는 범위 분할을 담당합니다. 범위 분할을 트리거하는 조건은 다음과 같습니다.
- 새 데이터베이스 또는 테이블을 만듭니다.
- 범위 크기가 range_max_bytes를 초과합니다.
- 범위의 QPS가 너무 높아 kv.range_split.load_qps_threshold(기본값 250, 구성 가능)를 초과합니다.
- 상위 수준에서 독립되도록 인덱스 또는 파티션의 구성 영역을 수정합니다. 특별한 경우에는 SplitQueue를 거치지 않고 adminSplit 분할이 직접 호출됩니다.
- 많은 양의 데이터를 가져올 때 하나의 범위가 자동으로 여러 범위로 분할됩니다.
- 데이터를 가져올 때 나중에 가져올 수 있는 데이터에 대해 빈 범위가 사전 분할됩니다.
- 수동 분할: 테이블 table_name 분할 값(key1,key2,...); 여기서 값은 기본 키 값을 나타냅니다. 공동 기본 키인 경우 여러 값을 쓸 수 있으며 개수를 초과할 수 없습니다. 기본 키 열.
분할 알고리즘 흐름도
KaiwuDB의 특정 노드에는 관련 범위 분할을 처리하기 위해 백그라운드에서 실행되는 별도의 스레드/작업자가 있습니다. 범위 분할은 2단계로 나뉩니다. 1단계 - 범위 분할 매개변수 준비 2단계 - 범위 및 해당 인덱스 구조 업데이트.

그림에 표시된 것처럼 왼쪽의 프로세스는 주로 범위 분할을 준비하는 과정입니다.
먼저 분할 범위의 키 값을 잠급니다. 이 키 값을 찾은 후 시스템은 현재 범위 범위를 조정하고 분할 키 키 값을 파티션의 종료 키 값으로 사용합니다.
프로세스는 오른쪽에 대한 새 Range를 생성하며, 시작 키 값은 분할에 사용되는 키 값이고, 끝 키 값은 원래 Range의 끝 키 값입니다. 동시에 원래 범위가 분할된 후 해당 버전은 1씩 반복적으로 업데이트되며 업데이트된 버전은 왼쪽 및 오른쪽 분할 범위에 동시에 적용됩니다.
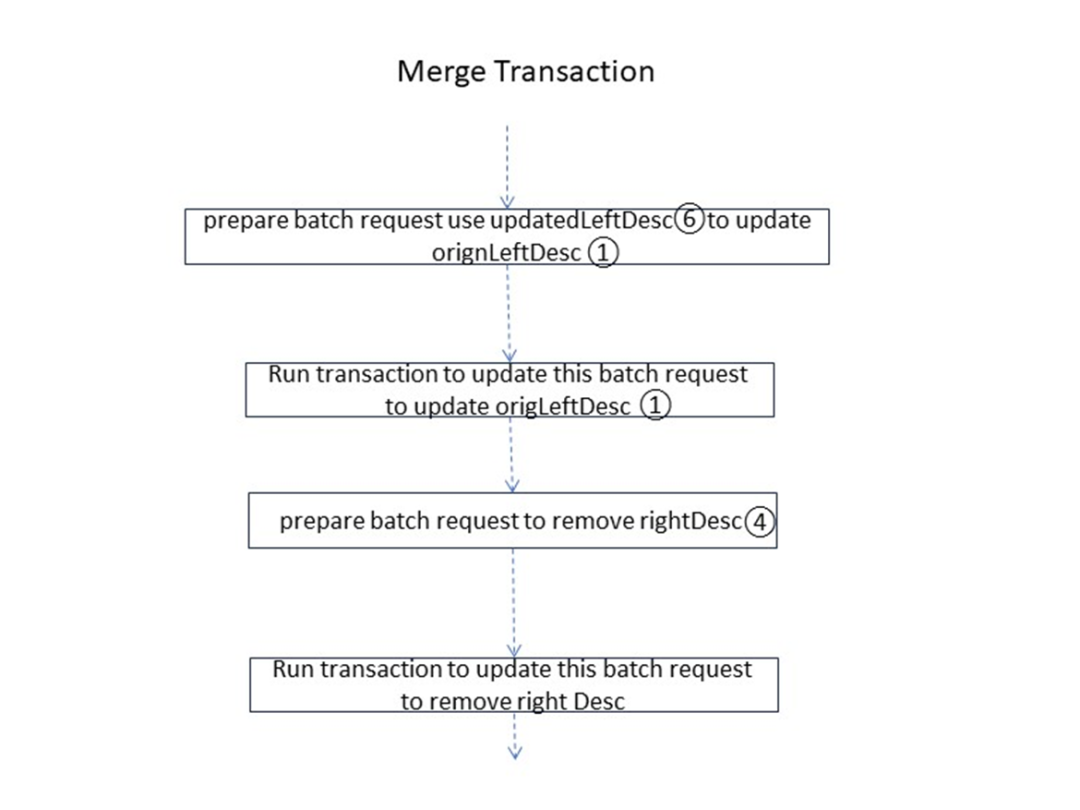
Range의 왼쪽과 오른쪽에 있는 분할 매개변수가 준비되면 프로세스가 시스템 데이터 업데이트 단계로 들어갑니다. 요약하면 쓰기 요청 및 처리 요청을 준비하는 과정이 필요하며 전체 프로세스가 연결됩니다. 거래는 다음 사항을 완료해야 합니다:
새 거래를 시작하세요. 상태는 보류 중입니다.
- 왼쪽 범위 업데이트
- 새로운 오른쪽 범위 작성
- 왼쪽 범위의 빅맥 지수의 2단계 트리 구조의 해당 검색 경로 업데이트
- 빅맥 지수의 2단계 트리 구조에 해당하는 검색 경로를 오른쪽 Range에 삽입
- 업데이트 트랜잭션의 상태는 커밋됨입니다.
- 왼쪽 및 오른쪽 범위의 MVCC 업데이트
- 글쓰기 의도를 정리하라
이 시점에서 전체 범위의 분할이 완료됩니다.
분할 트리거 예
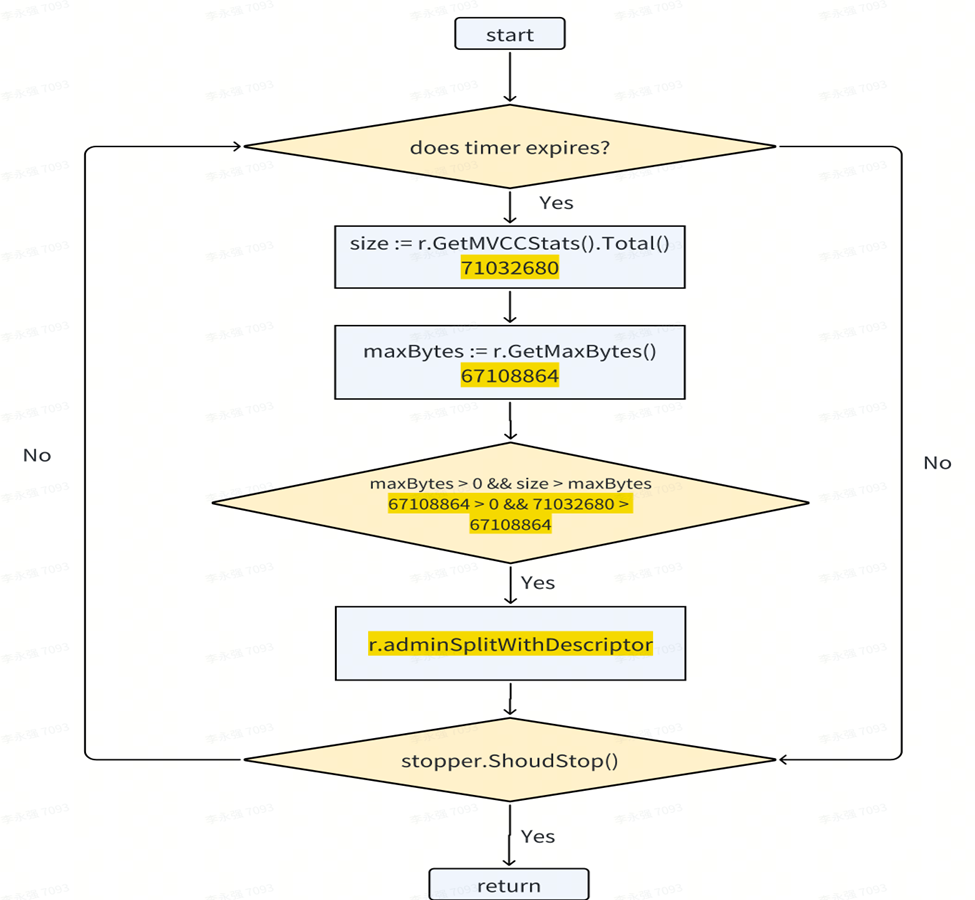
다음 디버깅 트리거 시나리오는 범위 크기가 미리 결정된 임계 값을 초과한 후에 발생합니다. 각 범위는 타이머 대기 직렬 방식으로 처리됩니다. 시계가 깨어난 후 범위 크기가 확인됩니다. 범위 크기가 약 70MB이고 미리 결정된 범위인 64M을 초과하는 것으로 확인되면 시스템은 범위 분할 기능을 트리거하여 용량 제한을 초과하는 범위를 분할합니다.
백그라운드 스레드 또는 작업자는 루프에서 처리할 모든 범위를 지속적으로 확인합니다.
KaiwuDB 범위 병합(병합)
병합 예시
그림에서 볼 수 있듯이 사용자가 많은 양의 데이터를 삭제하면 인접한 두 Range의 크기가 급격히 줄어들고 시스템에서는 이를 병합합니다.

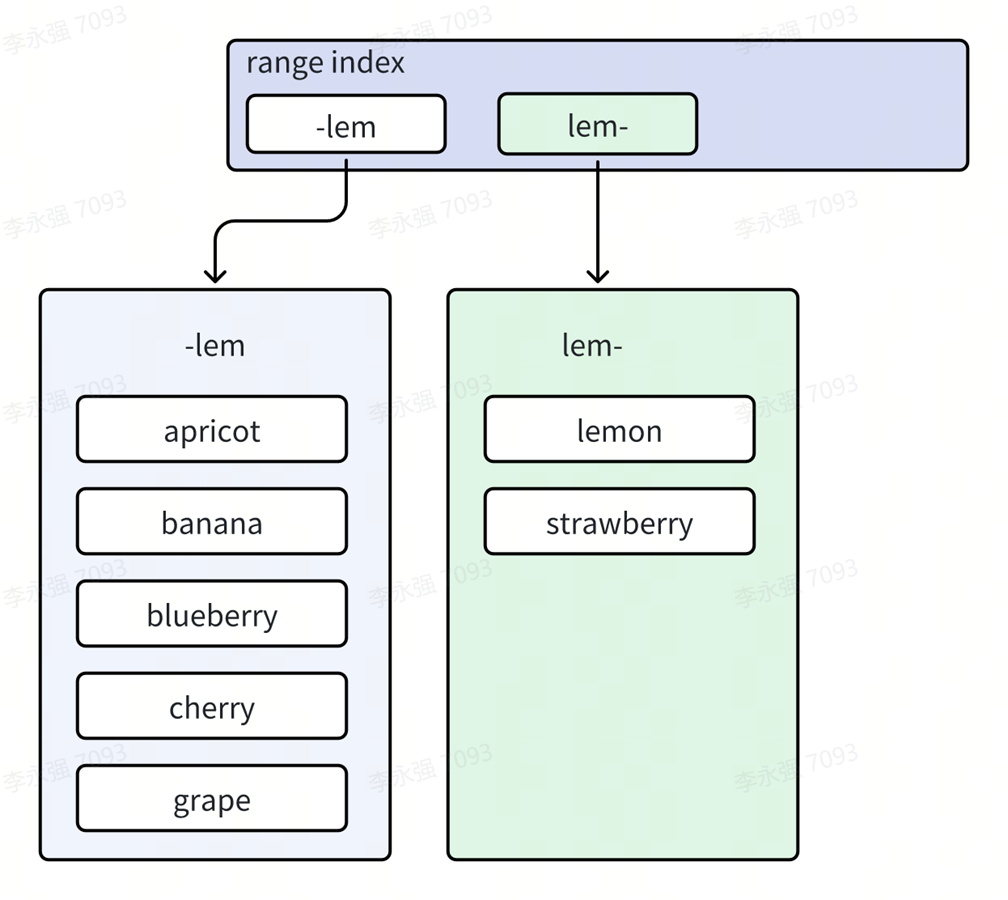
다음 그림은 이전 두 Range를 병합한 후의 효과를 보여줍니다. lem-str, str-은 병합되고, lem-만 남습니다. 원래 두 Range의 Key 값은 동일한 Range lem으로 병합되었습니다. .-. 이에 맞춰 빅맥 지수의 2차 데이터 구조도 조정돼 1차 트리 지수 구조에서 완두콩이 사라졌다.
병합 조건
범위 병합 조건은 비교적 엄격하며 주로 다음을 포함합니다. 병합이 비활성화되지 않았습니다. 다음 범위가 있고 동일한 구성 영역이 있습니다. 병합할 두 범위의 크기가 range_min_bytes보다 작습니다. 병합 후 QPS의 범위 분할이 트리거되지 않습니다.
마지막은 데이터가 위치한 Range에 핫 데이터가 있는 경우 병합이 수행되지 않음을 의미합니다. 병합으로 인해 분할이 트리거되어 시스템이 정상적으로 작동하지 못하게 되기 때문입니다.
병합 알고리즘 흐름도
그림에 표시된 대로 병합도 분할과 마찬가지로 두 단계로 나뉩니다. 첫 번째 단계 - 범위 매개변수 준비 두 번째 단계 - 범위 업데이트 처리를 위한 트랜잭션 활성화. 전체 콘텐츠를 보시려면 클릭하여 풀버전 콘텐츠를 확인해주세요 >> [풀버전 영상 재생] ( https://www.bilibili.com/video/BV11y421z7jH/?spm_id_from=333.999.0.0 )
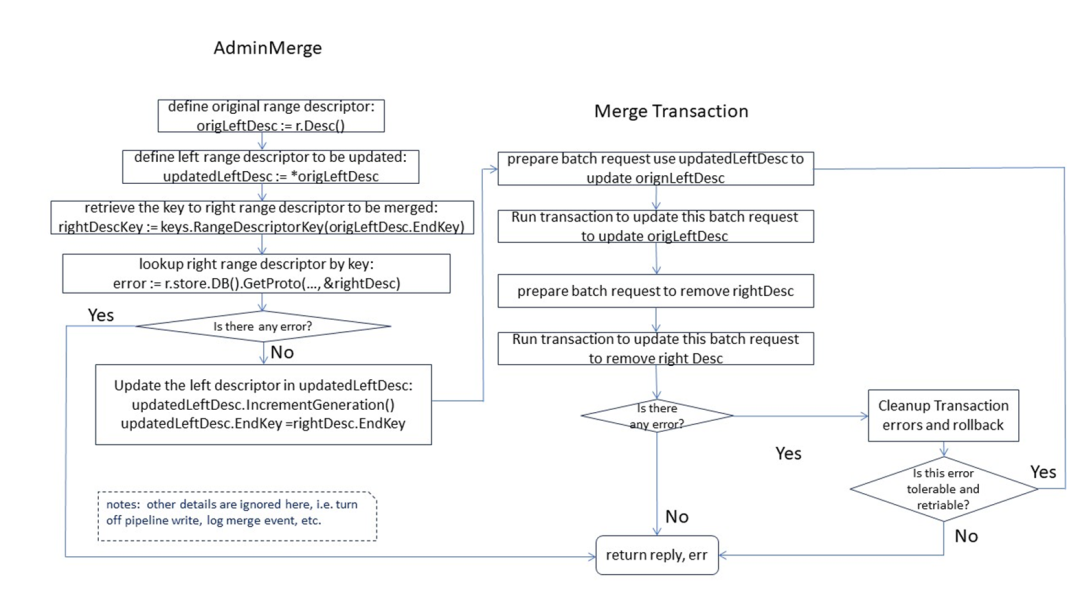
병합 디버깅 예 다음 두 개의 도식 다이어그램은 범위 병합 및 해당 범위 관련 매개변수를 디버깅하는 특정 프로세스를 보여줍니다.