
저자 : 비보인터넷빅데이터팀 예지동
본 글에서는 FileSystem 클래스에 의한 온라인 메모리 누수로 인한 메모리 오버플로 문제를 분석하고 해결하는 전 과정을 주로 소개한다.
메모리 누수 정의 : 프로그램에서 더 이상 사용하지 않는 객체나 변수가 여전히 메모리의 저장 공간을 차지하고 있으며, JVM은 변경된 객체나 변수를 제대로 회수할 수 없습니다. 단일 메모리 누수는 큰 영향을 미치지 않는 것처럼 보이지만 메모리 누수가 누적되면 메모리 오버플로가 발생합니다.
메모리 오버플로(out of memory) : 프로그램 실행 중 할당된 메모리 공간이 부족하거나 부적절한 사용으로 인해 프로그램을 계속 실행할 수 없는 오류를 말합니다. 소위 메모리 오버플로.
1. 배경
Xiaoye는 주말에 Canyon of Kings에서 사람들을 죽이고 있었는데, 그의 전화기는 갑자기 많은 수의 기계 CPU 알람을 받았습니다. CPU 사용량이 80%를 초과하면 동시에 전체 GC 알람도 수신됩니다. 서비스를 위해. 이 서비스는 Xiaoye 프로젝트 팀에게 매우 중요한 서비스입니다. Xiaoye는 신속하게 Kings를 내려놓고 컴퓨터를 켜서 문제를 확인했습니다.


그림 1.1 CPU 알람 Full GC 알람
2. 문제 발견
2.1 모니터링 및 보기
서비스 CPU와 Full GC가 알람이 발생했기 때문에 서비스 모니터링을 열어서 CPU 모니터링과 Full GC 모니터링을 보면 동시에 CPU 알람이 발생하는 것을 볼 수 있습니다. 특히 Full GC가 자주 발생하는데, 이는 Full GC 로 인해 CPU 사용량 증가 경보가 발생하는 것으로 추측됩니다.
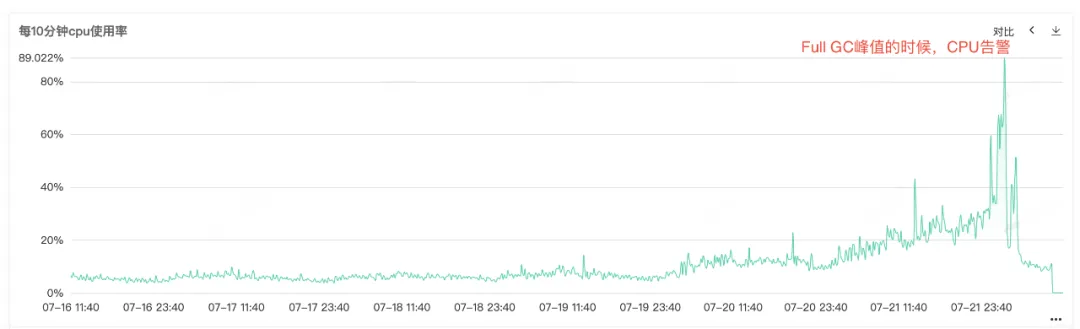
그림 2.1 CPU 사용량
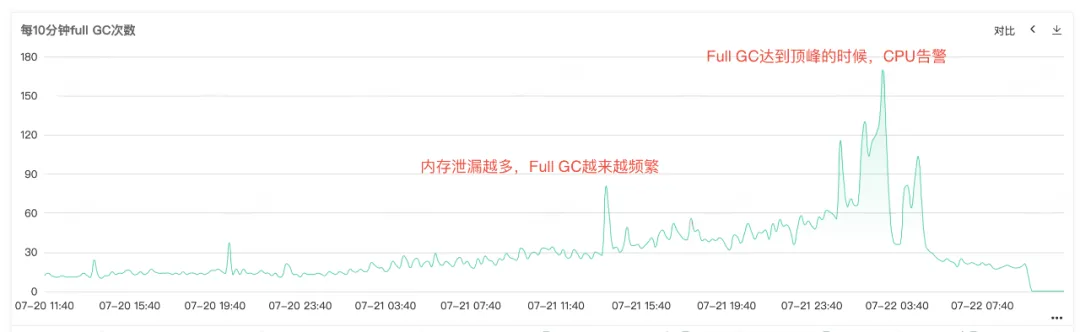
그림 2.2 전체 GC 시간
2.2 메모리 누수
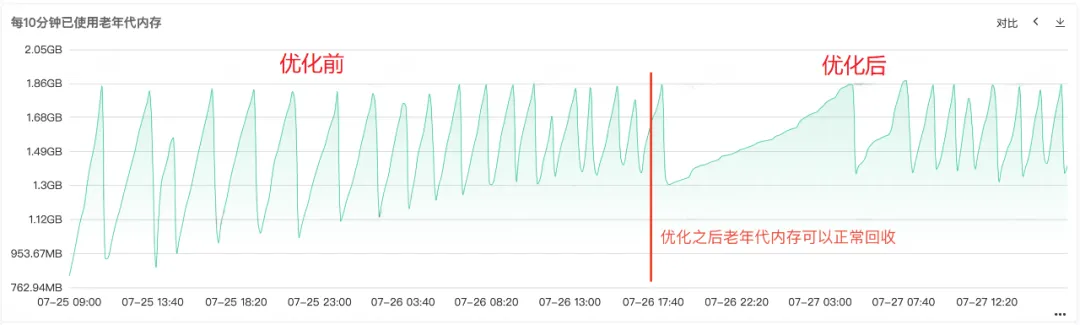
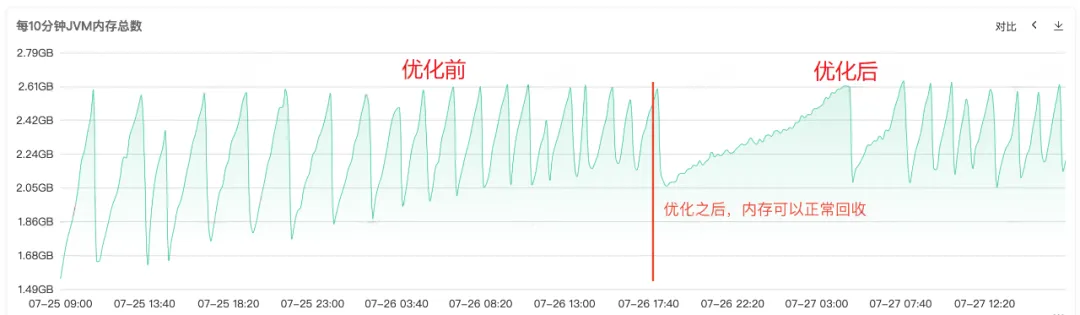
빈번한 Full Gc를 통해 서비스의 메모리 재활용에 문제가 있음을 알 수 있으므로 서비스의 상주 메모리 다이어그램에서 힙 메모리, Old Generation 메모리 및 Young Generation 메모리에 대한 모니터링을 확인합니다. Old 세대의 상주 메모리가 점점 더 커지고 있음을 알 수 있습니다. Old 세대의 객체가 점점 더 많아지고 재활용할 수 없게 되어 결국 상주 메모리가 모두 점유되어 명백한 메모리 누수가 발생하는 것을 볼 수 있습니다. .
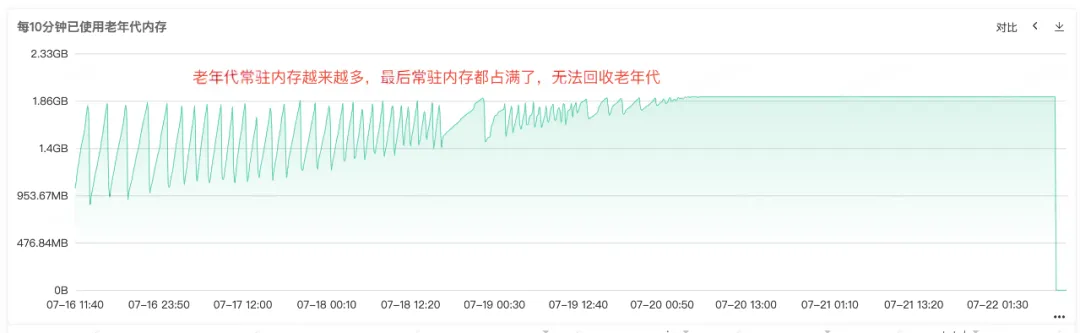
그림 2.3 구세대 메모리
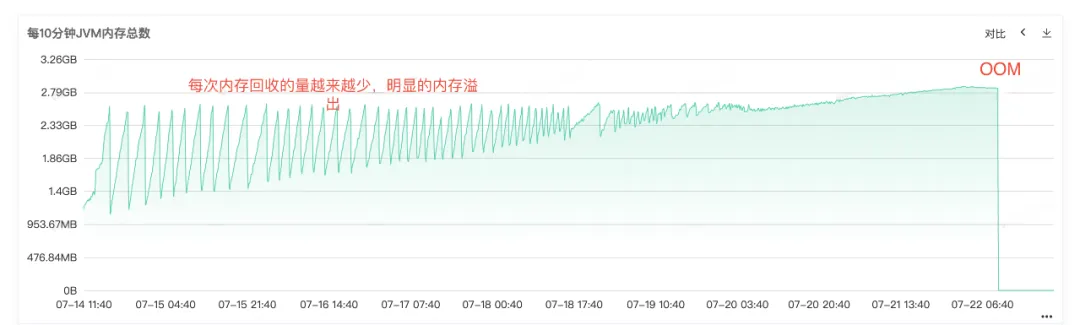
그림 2.4 JVM 메모리
2.3 메모리 오버플로
온라인 오류 로그에서도 서비스가 OOM으로 종료되었음을 명확히 알 수 있으므로 문제의 근본 원인은 메모리 누수 로 인해 메모리 오버플로 OOM이 발생하여 결국 서비스를 사용할 수 없게 된 것입니다 .

그림 2.5 OOM 로그
3. 문제 해결
3.1 힙 메모리 분석
문제의 원인이 메모리 누수라는 것이 밝혀진 후, 우리는 즉시 서비스 메모리 스냅샷을 덤프하고 덤프 파일을 MAT(Eclipse Memory Analyser)로 가져와서 분석했습니다. 누출 의심 누출 의심 지점 보기를 입력합니다.
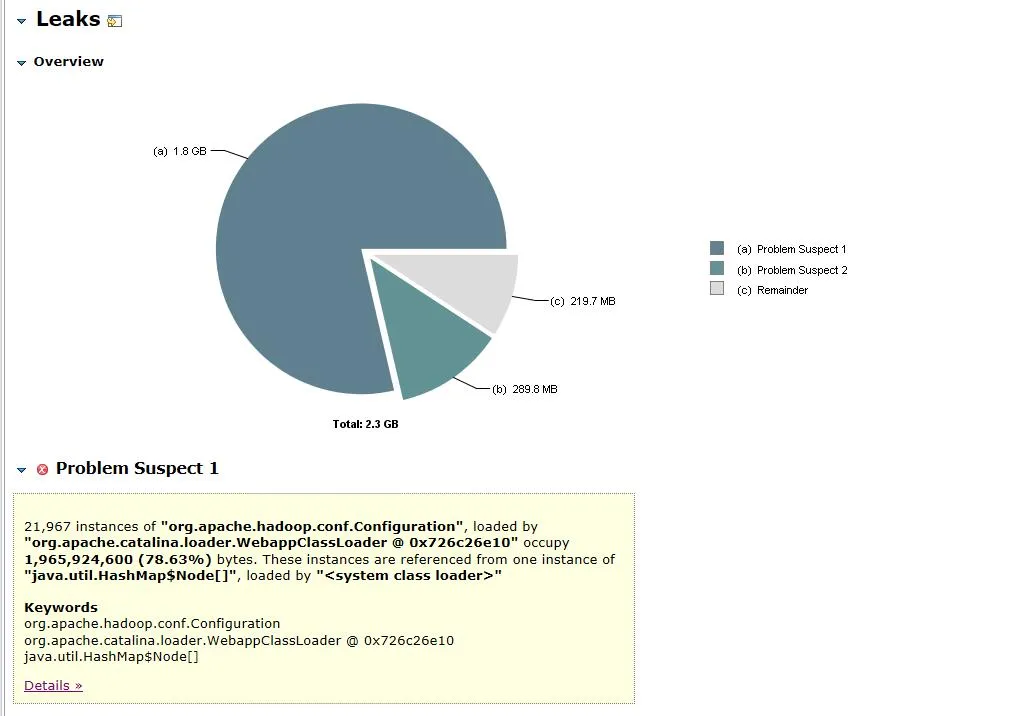
그림 3.1 메모리 객체 분석
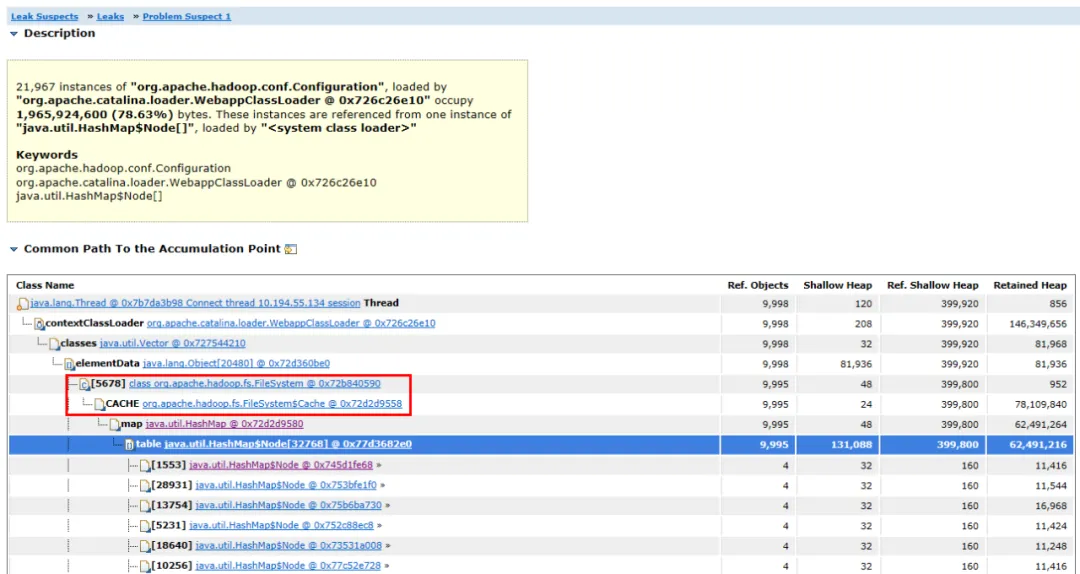
그림 3.2 객체 링크 다이어그램
열린 덤프 파일은 그림 3.1에 나와 있습니다. org.apache.hadoop.conf.Configuration 개체는 2.3G 힙 메모리 중 1.8G를 차지하며 전체 힙 메모리의 78.63%를 차지합니다 .
연관된 객체와 객체의 경로를 확장하면 주요 점유 객체가 HashMap 이고 HashMap 은 FileSystem.Cache 객체가 보유하고 있으며 상위 계층은 FileSystem 입니다 . 메모리 누수는 FileSystem과 관련이 있을 가능성이 가장 높다고 추측할 수 있습니다.
3.2 소스코드 분석
메모리 누수 객체를 찾은 후 다음 단계는 메모리 누수 코드를 찾는 것입니다.
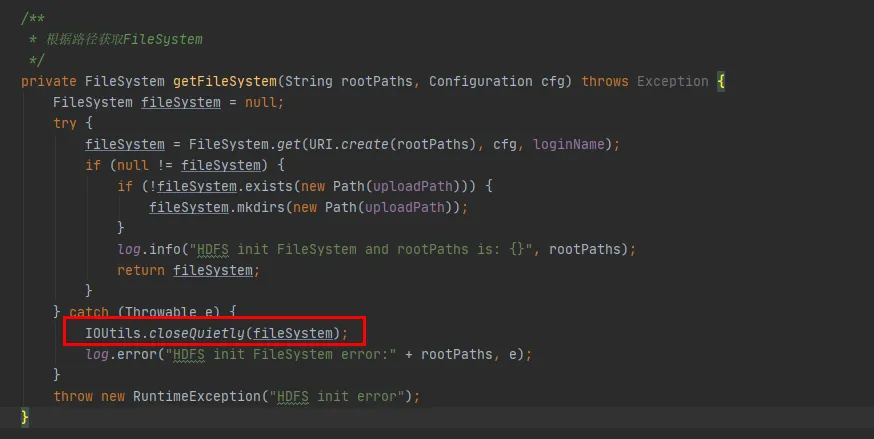
그림 3.3에서는 코드에서 hdfs와 상호 작용할 때마다 hdfs와의 연결을 설정하고 FileSystem 객체를 생성하는 코드 조각을 찾을 수 있습니다. 그러나 FileSystem 객체를 사용한 후 연결을 해제하기 위해 close() 메서드가 호출되지 않았습니다.
그러나 여기의 Configuration 인스턴스와 FileSystem 인스턴스 는 모두 로컬 변수입니다. 메소드가 실행된 후 이 두 객체는 JVM에서 재활용 가능해야 합니다. 어떻게 메모리 누수가 발생할 수 있습니까?
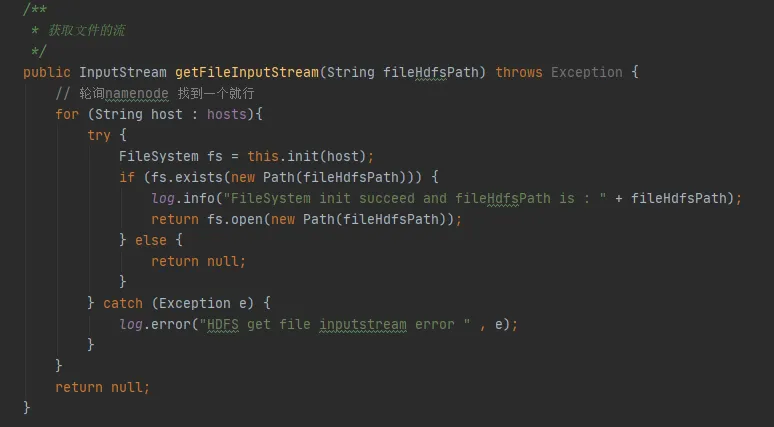
그림 3.3
(1) 추측 1: FileSystem에는 상수 개체가 있습니까?
다음으로 FileSystem 클래스의 소스 코드를 살펴보겠습니다. FileSystem의 init 및 get 메소드는 다음과 같습니다.
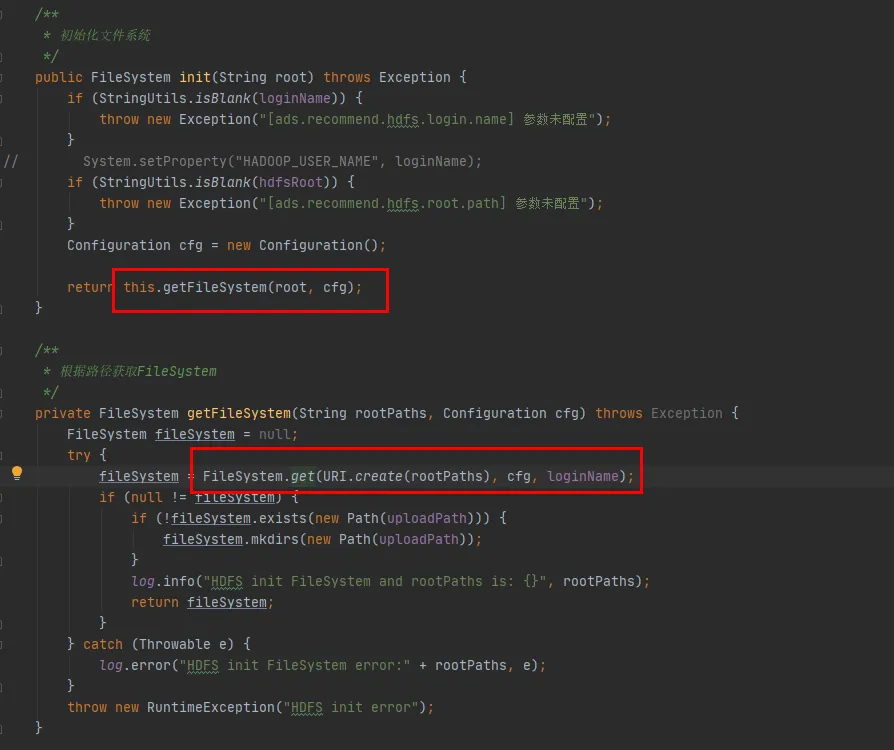

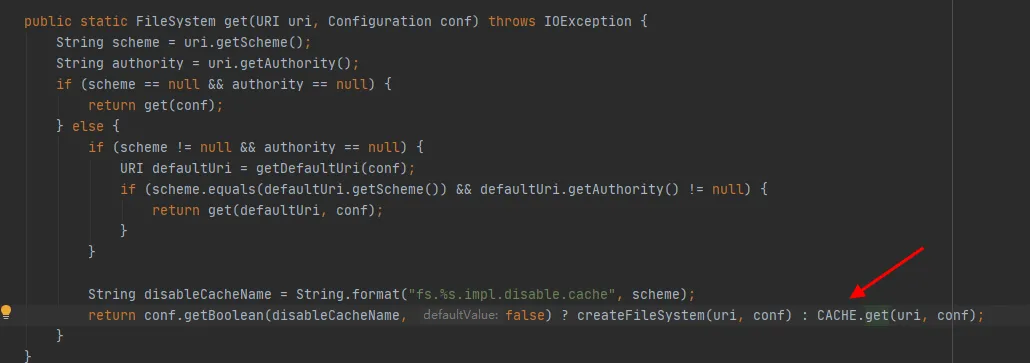
그림 3.4
그림 3.4의 마지막 코드 줄에서 볼 수 있듯이 FileSystem 클래스에는 CACHE가 있으며, 비활성화CacheName은 캐시에서 개체를 가져올지 여부를 제어하는 데 사용됩니다 . 이 매개변수의 기본값은 false입니다. 즉, FileSystem은 기본적으로 CACHE 객체를 통해 반환됩니다 .

그림 3.5
그림 3.5에서 CACHE는 FileSystem 클래스의 정적 개체임을 알 수 있습니다. 즉, CACHE 개체는 항상 존재하며 재활용되지 않습니다. 상수 개체 CACHE가 존재하며 추측이 확인되었습니다.
그런 다음 CACHE.get 메소드를 살펴보십시오.
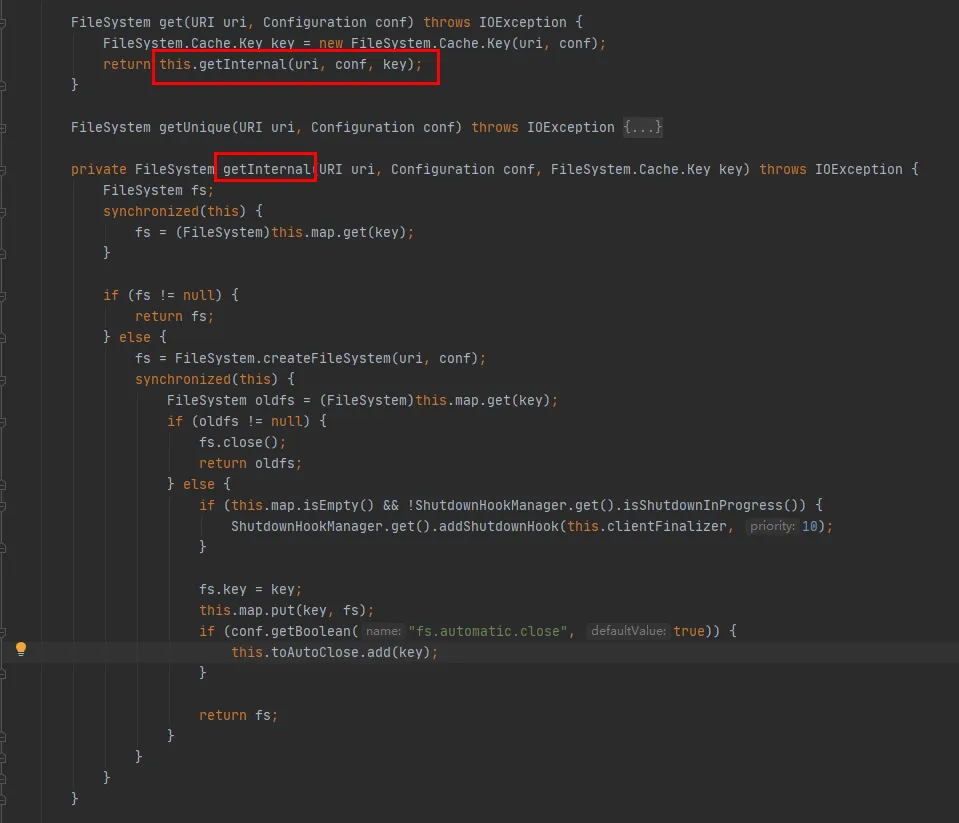
이 코드에서 볼 수 있듯이:
-
Map은 연결된 FileSystem 개체를 캐시하는 데 사용되는 Cache 클래스 내에서 유지 관리됩니다. Map의 Key는 Cache.Key 개체입니다. FileSystem은 매번 Cache.Key를 통해 획득됩니다. 획득하지 못한 경우 생성 프로세스가 계속됩니다.
-
Set(toAutoClose)는 자동으로 닫혀야 하는 연결을 저장하는 데 사용되는 Cache 클래스 내부에서 유지됩니다. 이 컬렉션의 연결은 클라이언트가 닫힐 때 자동으로 닫힙니다.
-
생성된 각 FileSystem은 Cache.Key를 키로, FileSystem을 값으로 사용하여 Cache 클래스의 Map에 저장됩니다. 캐싱 중에 동일한 hdfs URI에 대해 여러 개의 캐시가 있는지 여부는 Cache.Key의 hashCode 메서드를 확인해야 합니다.
Cache.Key의 hashCode 메서드는 다음과 같습니다.

스키마 및 권한 변수는 문자열 유형입니다. 동일한 URI에 있는 경우 해당 hashCode는 일관됩니다. 고유 매개변수의 값은 매번 0입니다. 그런 다음 Cache.Key의 hashCode는 ugi.hashCode() 에 의해 결정됩니다 .
위의 코드 분석을 통해 다음을 정리할 수 있습니다.
-
비즈니스 코드와 HDFS 간의 상호 작용 중에 각 상호 작용에 대해 FileSystem 연결이 생성되고 FileSystem 연결은 마지막에 닫히지 않습니다.
-
FileSystem에는 내장된 정적 Cache 가 있으며 , Cache 내부에는 연결을 생성한 FileSystem을 캐시하는 맵이 있습니다.
-
fs.hdfs.impl.disable.cache 매개변수는 FileSystem을 캐시해야 하는지 여부를 제어하는 데 사용됩니다. 기본적으로 이는 캐싱을 의미하는 false입니다.
-
캐시의 맵, Key는 Cache.Key의 hashCode 메서드에 표시된 대로 구성표, 권한, ugi 및 고유의 네 가지 매개 변수를 통해 키를 결정하는 Cache.Key 클래스입니다 .
(2) 추측 2: FileSystem이 동일한 hdfs URI를 여러 번 캐시합니까?
FileSystem.Cache.Key 생성자는 다음과 같습니다. ugi는 UserGroupInformation의 getCurrentUser()에 의해 결정됩니다.

다음과 같이 UserGroupInformation의 getCurrentUser() 메서드를 계속 살펴보세요.

중요한 것은 AccessControlContext를 통해 Subject 객체를 얻을 수 있는지 여부입니다. 이 예에서는 디버깅 중에 get(최종 URI uri, 최종 구성 conf, 최종 문자열 사용자)을 통해 얻을 때마다 여기에서 새로운 주제 개체를 얻을 수 있음을 알 수 있습니다. 즉, 동일한 hdfs 경로는 매번 FileSystem 객체를 캐시합니다 .
추측 2가 확인되었습니다. 동일한 HDFS URI가 여러 번 캐시되어 캐시가 빠르게 확장되고 캐시가 만료 시간 및 제거 정책을 설정하지 않아 결국 메모리 오버플로가 발생합니다.
(3) FileSystem이 반복적으로 캐시하는 이유는 무엇입니까?
그렇다면 매번 새로운 Subject 객체를 얻는 이유는 무엇입니까? 다음과 같이 AccessControlContext를 얻는 코드를 살펴보겠습니다.
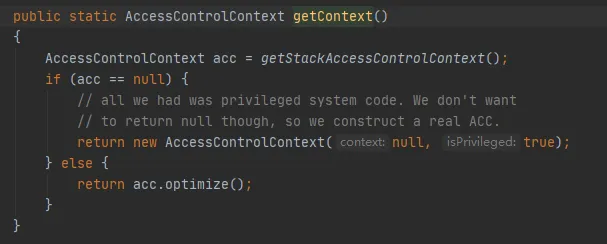
핵심은 다음과 같이 Native 메서드를 호출하는 getStackAccessControlContext 메서드입니다.

이 메서드는 현재 스택의 보호 도메인 권한에 대한 AccessControlContext 개체를 반환합니다.
그림 3.6의 get(final URI uri, final Configuration conf, final String user) 메소드를 통해 다음과 같이 이를 확인할 수 있습니다 .
-
먼저 UserGroupInformation.getBestUGI 메소드를 통해 UserGroupInformation 객체를 얻습니다 .
-
그런 다음 UserGroupInformation 의 doAs 메소드를 통해 get(URI uri, Configuration conf) 메소드가 호출됩니다 .
-
그림 3.7 UserGroupInformation.getBestUGI 메소드 구현 여기서는 전달된 두 매개변수인 ticketCachePath 및 user 에 중점을 둡니다 . ticketCachePath는 hadoop.security.kerberos.ticket.cache.path를 구성하여 얻은 값입니다. 이 예에서는 이 매개변수가 구성되지 않았으므로 ticketCachePath가 비어 있습니다. user 매개변수는 이 예에 전달된 사용자 이름입니다.
-
ticketCachePath는 비어 있고 user는 비어 있지 않으므로 결국 그림 3.7의 createRemoteUser 메서드가 실행됩니다.

그림 3.6

그림 3.7
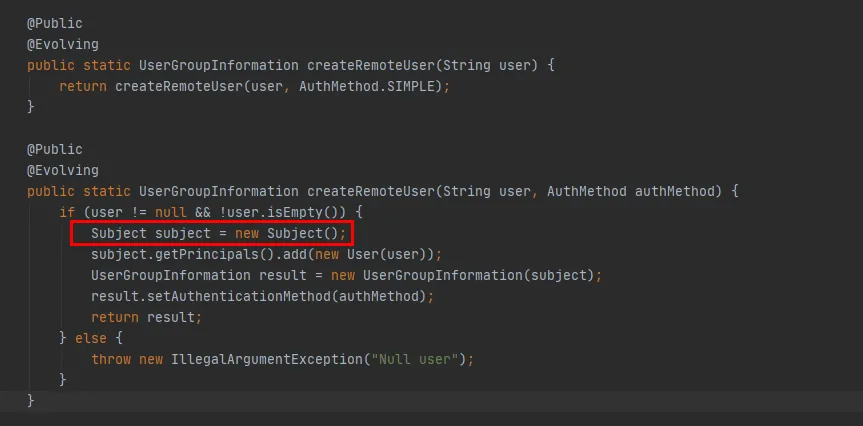
그림 3.8
그림 3.8의 빨간색 코드를 보면 createRemoteUser 메소드에서 새로운 Subject 객체가 생성되고, 이 객체를 통해 UserGroupInformation 객체가 생성되는 것을 확인할 수 있습니다 . 이 시점에서 UserGroupInformation.getBestUGI 메소드 실행이 완료됩니다.
다음으로 UserGroupInformation.doAs 메소드(FileSystem.get(최종 URI uri, 최종 구성 conf, 최종 문자열 사용자)에 의해 실행되는 마지막 메소드)를 살펴보세요 .
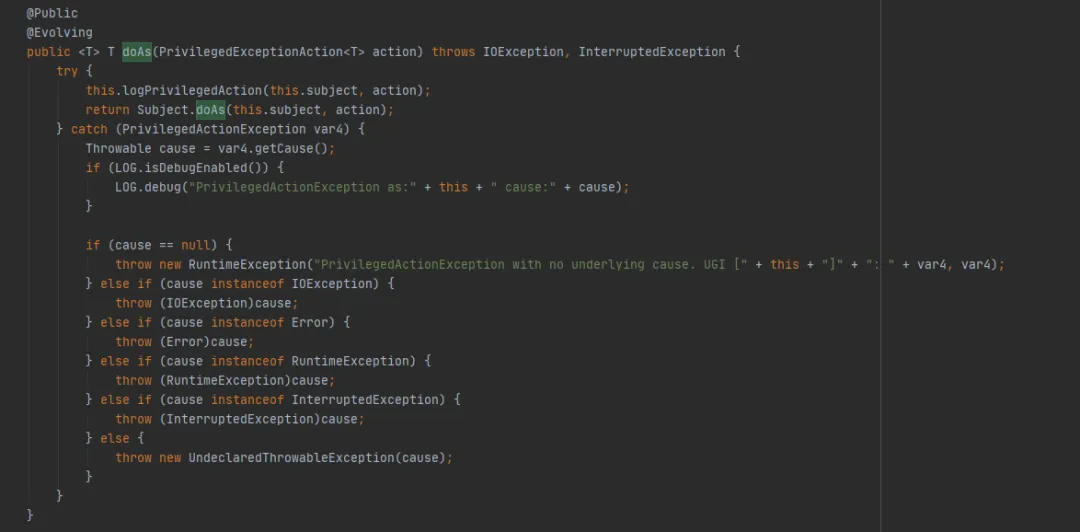
그런 다음 다음과 같이 Subject.doAs 메소드를 호출하십시오.
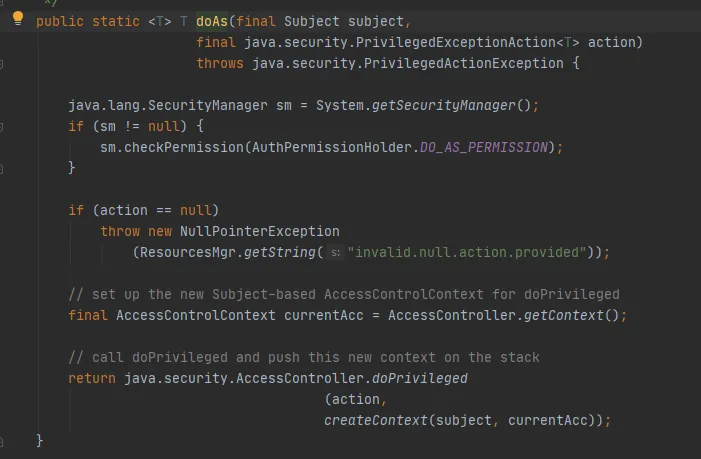
마지막으로 다음과 같이 AccessController.doPrivileged 메서드를 호출합니다.
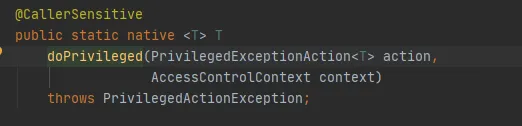
이 메소드는 지정된 AccessControlContext를 사용하여 PrivilegedExceptionAction을 실행하는 기본 메소드입니다. 즉, 구현의 실행 메소드를 호출합니다. 이것이 FileSystem.get(uri, conf) 메소드입니다.
이때, 이 예에서는 get(final URI uri, final Configuration conf, final String user) 메소드를 통해 FileSystem을 생성할 때 FileSystem의 Cache에 저장된 Cache.key의 hashCode가 매번 일치하지 않는다고 설명할 수 있습니다. .
요약:
-
get(final URI uri, final Configuration conf, final String user) 메소드를 통해 FileSystem을 생성 하면 매번 새로운 UserGroupInformation 및 Subject 객체가 생성됩니다.
-
Cache.Key 개체가 hashCode 를 계산할 때 계산 결과에 영향을 미치는 것은 UserGroupInformation.hashCode 메서드 에 대한 호출입니다 .
-
UserGroupInformation.hashCode 메서드는 System.identityHashCode(subject) 로 계산됩니다 . 즉, Subject가 동일한 객체이면 동일한 hashCode가 반환되는데, 이 예시에서는 매번 다르기 때문에 계산된 hashCode가 일치하지 않습니다.
-
정리하자면 매번 계산된 Cache.key의 hashCode가 일치하지 않아 FileSystem의 Cache가 반복적으로 쓰여지게 됩니다.
(4) FileSystem의 올바른 사용법
위의 분석에서 FileSystem.Cache가 제 역할을 하지 않는데 왜 이 Cache를 설계해야 할까요? 사실 우리의 사용법이 올바르지 않을 뿐입니다.
FileSystem에는 두 가지 오버로드된 get 메서드가 있습니다.
public static FileSystem get(final URI uri, final Configuration conf, final String user)
public static FileSystem get(URI uri, Configuration conf)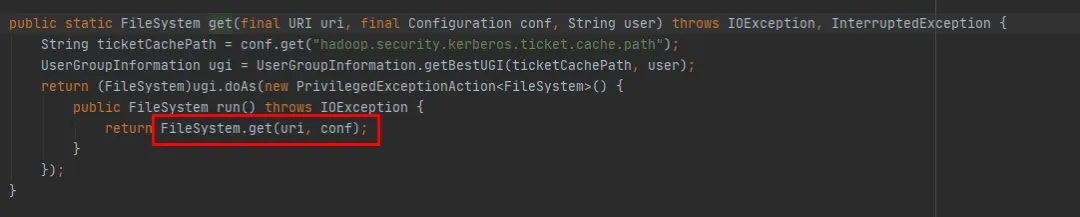
FileSystem get(final URI uri, final Configuration conf, final String user) 메소드가 최종적으로 FileSystem get(URI uri, Configuration conf) 메소드를 호출하는 것을 볼 수 있습니다. 차이점은 FileSystem get(URI uri, Configuration conf) 메소드입니다. 매번 새로운 주제를 생성하는 작업이 부족합니다.

그림 3.9
새 주제를 생성하는 작업이 없으면 그림 3.9의 주제는 null이고 마지막 getLoginUser 메소드를 사용하여 loginUser를 얻습니다. LoginUser는 정적 변수이므로 loginUser 개체가 성공적으로 초기화되면 해당 개체는 나중에 사용됩니다. UserGroupInformation.hashCode 메소드는 동일한 hashCode 값을 반환합니다. 즉, FileSystem에 캐시된 Cache를 성공적으로 사용할 수 있습니다.

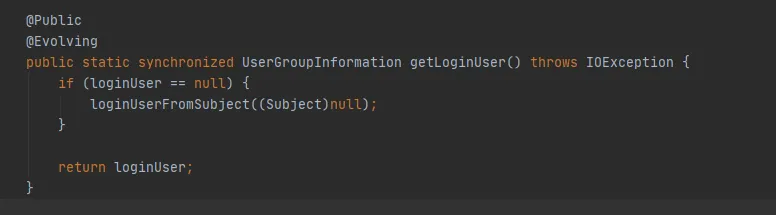
그림 3.10
4. 솔루션
이전 소개 이후 FileSystem의 메모리 누수 문제를 해결하려면 다음 두 가지 방법이 있습니다.
(1) public static FileSystem get(URI uri, Configuration conf)을 사용합니다.
-
이 방법은 FileSystem Cache를 사용할 수 있습니다. 이는 동일한 hdfs URI에 대해 하나의 FileSystem 연결 개체만 있음을 의미합니다.
-
System.setProperty("HADOOP_USER_NAME", "hive")를 통해 액세스 사용자를 설정합니다.
-
기본적으로 fs.automatic.close=true입니다. 즉, ShutdownHook을 통해 모든 연결이 닫힙니다.
(2) public static FileSystem get(최종 URI uri, 최종 구성 conf, 최종 문자열 사용자)을 사용합니다.
-
위에서 분석한 대로 이 방법을 사용하면 FileSystem의 Cache가 무효화되고, 매번 Cache의 Map에 추가되어 재활용되지 않게 됩니다.
-
이를 사용할 때 한 가지 해결책은 동일한 hdfs URI에 대해 FileSystem 연결 개체가 하나만 있는지 확인하는 것입니다.
-
또 다른 해결책은 FileSystem을 사용할 때마다 close 메소드를 호출하여 캐시에서 FileSystem을 삭제하는 것입니다.
기존 기록 코드에 대한 최소한의 변경을 전제로 두 번째 수정 방법을 선택했습니다. FileSystem을 사용할 때마다 FileSystem 개체를 닫습니다.
5. 최적화 결과
코드가 복구되어 온라인에 공개된 후 아래 그림 1과 같이 복구 후 이전 세대의 메모리가 정상적으로 재활용될 수 있는 것을 확인할 수 있으며, 이 시점에서 문제가 최종적으로 해결됩니다.
6. 요약
메모리 오버플로는 Java 개발에서 가장 일반적인 문제 중 하나입니다. 그 이유는 일반적으로 메모리가 정상적으로 재활용되지 못하게 하는 메모리 누수 로 인해 발생합니다. 우리 기사에서는 완전한 온라인 메모리 오버플로 처리 프로세스를 자세히 소개합니다.
메모리 오버플로가 발생할 경우 일반적인 해결 방법을 요약해 보세요.
(1) 힙 메모리 파일 생성 :
서비스 시작 명령에 추가
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/baseOOM이 발생할 때 서비스가 자동으로 메모리 파일을 덤프하도록 하거나 jam 명령을 사용하여 메모리 파일을 덤프합니다.
(2) 힙 메모리 분석 : 메모리 분석 도구를 사용하면 메모리 오버플로 문제를 더 깊이 분석하고 메모리 오버플로의 원인을 찾을 수 있습니다. 다음은 일반적으로 사용되는 몇 가지 메모리 분석 도구입니다.
-
Eclipse 메모리 분석기 : 메모리 누수를 빠르게 찾는 데 도움이 되는 오픈 소스 Java 메모리 분석 도구입니다.
-
VisualVM 메모리 분석기 : Java 애플리케이션의 메모리 사용량을 분석하는 데 도움이 되는 그래픽 인터페이스 기반 도구입니다.
(3) 힙 메모리 분석을 기반으로 특정 메모리 누수 코드를 찾습니다.
(4) 메모리 누수 코드를 수정하고 검증을 위해 다시 릴리스합니다.
메모리 누수는 메모리 오버플로의 일반적인 원인이지만 이것이 유일한 원인은 아닙니다. 메모리 오버플로 문제의 일반적인 원인에는 너무 큰 개체, 너무 작은 힙 메모리 할당, 무한 루프 호출 등이 포함되며, 이는 모두 메모리 오버플로 문제로 이어질 수 있습니다.
메모리 오버플로 문제가 발생하면 여러 측면에서 생각하고 다양한 각도에서 문제를 분석해야 합니다. 위에서 언급한 방법과 도구, 그리고 다양한 모니터링을 통해 문제를 신속하게 찾아 해결하고 시스템의 안정성과 가용성을 향상시키는 데 도움을 줄 수 있습니다.
1990년대에 태어난 프로그래머가 비디오 포팅 소프트웨어를 개발하여 1년도 안 되어 700만 개 이상의 수익을 올렸습니다. 결말은 매우 처참했습니다! 고등학생들이 성인식으로 자신만의 오픈소스 프로그래밍 언어 만든다 - 네티즌 날카로운 지적: 만연한 사기로 러스트데스크 의존, 가사 서비스 타오바오(taobao.com)가 가사 서비스를 중단하고 웹 버전 최적화 작업 재개 자바 17은 가장 일반적으로 사용되는 Java LTS 버전입니다. Windows 10 시장 점유율 70%에 도달, Windows 11은 계속해서 Open Source Daily를 지원합니다. Google은 Docker가 지원하는 오픈 소스 Rabbit R1을 지원합니다. Electric, 개방형 플랫폼 종료 Apple, M4 칩 출시 Google, Android 범용 커널(ACK) 삭제 RISC-V 아키텍처 지원 Yunfeng은 Alibaba에서 사임하고 향후 Windows 플랫폼에서 독립 게임을 제작할 계획