
데이터베이스 인덱스는 모든 데이터베이스 시스템의 성능을 최적화하는 핵심 구성 요소입니다. 효과적인 인덱스가 없으면 데이터베이스 쿼리가 느리고 비효율적이어서 사용자 경험이 저하되고 생산성이 저하될 수 있습니다. 이 문서에서는 데이터베이스 인덱스를 만들고 사용하는 몇 가지 모범 사례를 살펴보겠습니다.
저자: 자바 트레일
이 기사와 표지의 출처: https://medium.com/, Axon 오픈 소스 커뮤니티에서 번역.
이 글은 약 2,700 단어로, 읽는 데 9분 정도 소요될 것으로 예상됩니다.
쿼리 성능을 향상시키기 위해 데이터베이스에서는 다양한 인덱싱 알고리즘이 사용됩니다. 다음은 가장 일반적으로 사용되는 인덱싱 알고리즘 중 일부입니다.
B-트리 인덱스
B-트리 인덱스는 데이터 순서를 유지하고 로그 시간 내에 검색, 순차 액세스, 삽입 및 삭제를 허용하는 자체 균형 트리 데이터 구조입니다. B-Tree 인덱스 구조는 데이터베이스와 파일 시스템에서 널리 사용됩니다. B-Tree 인덱스는 MySQL, PostgreSQL과 같은 관계형 데이터베이스에서 널리 사용됩니다.
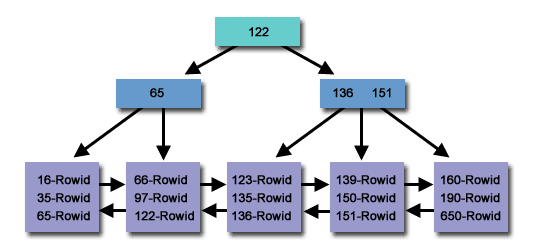
B-트리 인덱스는 값 범위 내의 모든 레코드를 효율적으로 찾을 수 있기 때문에 범위 쿼리에 최적화되어 있습니다. 이는 레코드가 인덱스에 정렬된 순서로 저장되기 때문입니다. =, >, >=, <또는 연산자 <=를 사용하는 표현식에서 열 비교를 활용하세요 BETWEEN.
예를 들어 다음과 같은 테이블 구조를 가진 제품 테이블이 있다고 가정합니다.
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(255),
price DECIMAL(10,2)
);
다음 SQL 문을 통해 필드에 priceB-Tree 인덱스를 추가 할 수 있습니다.
CREATE INDEX products_price_index ON products (price);
해시 인덱스
해시 인덱스는 쿼리 속도를 높이는 데 사용되는 또 다른 인기 있는 인덱싱 알고리즘입니다. 해시 인덱스는 해시 함수를 사용하여 키를 인덱스 위치에 매핑합니다. 이 인덱싱 알고리즘은 기본 키 값을 기반으로 특정 레코드를 검색하는 것과 같은 정확한 일치 쿼리에 가장 유용합니다 . 해시 인덱스는 Redis와 같은 인메모리 데이터베이스에서 일반적으로 사용됩니다.
해시 인덱스는 테이블의 각 레코드를 해시 값을 기반으로 고유한 버킷에 매핑하는 방식으로 작동합니다. 해시 값은 데이터 항목을 입력으로 받아 고유한 정수 값을 반환하는 수학 함수인 해시 함수를 사용하여 계산됩니다.
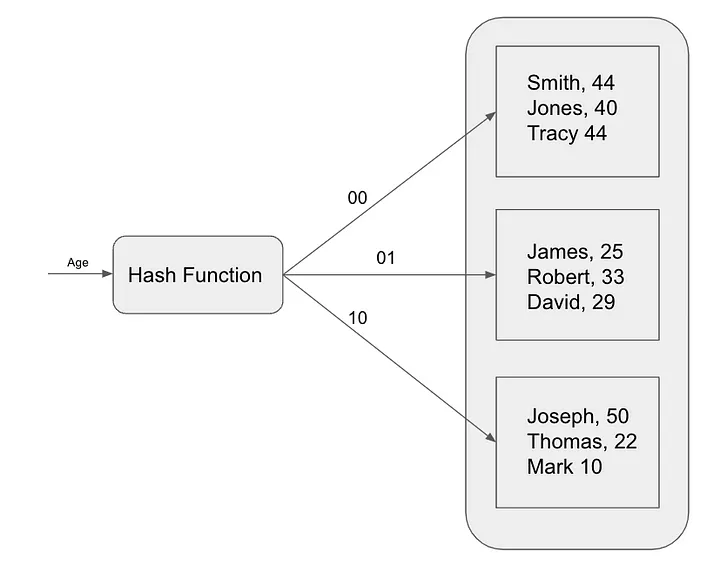
해시된 인덱스에서 레코드를 찾기 위해 데이터베이스는 검색 키의 해시를 계산한 다음 해당 버킷을 조회합니다. 레코드가 버킷에 있으면 데이터베이스는 해당 레코드를 반환합니다. 그렇지 않으면 데이터베이스는 전체 테이블 스캔을 수행합니다.
해시 인덱스는 조회 속도가 매우 빠르지만 데이터 범위를 효율적으로 쿼리하는 데는 사용할 수 없습니다 . 이는 해시 함수가 테이블의 레코드 간 순서를 유지하지 않기 때문입니다.
해시 인덱스를 사용하여 쿼리를 실행하려면 다음 안내를 따르세요.
- 데이터베이스는 쿼리 기준의 해시 값을 계산합니다.
- 해시 테이블에서 해당 해시 버킷을 찾습니다.
- 그런 다음 데이터베이스는 해당 해시 값이 있는 테이블의 행에 대한 포인터를 검색합니다.
- 이 포인터를 사용하여 테이블에서 실제 행을 검색합니다.
다음과 같은 테이블 구조를 가진 제품 테이블이 있다고 가정해 보겠습니다.
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(255),
price DECIMAL(10,2)
);
Q: 해시 인덱스는 B-Tree처럼 최적화되지 않습니까?
해시 인덱스가 최선의 선택이 아닐 수 있는 몇 가지 상황이 있습니다.
=해시 인덱스는 조회( 또는 연산자를 사용한 동일성 비교)를 위한 트리 인덱스보다 빠르지만<=>데이터 범위를 효율적으로 쿼리하는 데 사용할 수 없습니다.- 트리 인덱스는 검색 시 해시 인덱스보다 느리지만 데이터 범위를 효율적으로 쿼리하는 데 사용할 수 있습니다.
범위 쿼리: 해시 인덱스는 값 범위 내에서 레코드를 찾아야 하는 범위 쿼리에 최적화되지 않습니다( =, >, >=, <또는 연산자 <=사용 BETWEEN). 이 경우에는 B-Tree 인덱스가 더 적합합니다.
정렬: 해시 인덱스는 정렬에 최적화되어 있지 않으므로 특정 열을 기준으로 레코드를 정렬해야 합니다. 이 경우에는 B-Tree 인덱스나 Clustered 인덱스가 더 적합합니다.
대규모 데이터 세트: 해시 인덱스는 메모리 집약적일 수 있으므로 메모리 사용량이 중요한 대규모 데이터 세트에는 적합하지 않을 수 있습니다.
name다음 명령을 사용하여 해당 열에 해시 인덱스를 생성 할 수 있습니다 .
CREATE INDEX products_name_hash ON products (name);
SELECT * FROM products WHERE name = 'iPhone 13 Pro';
CREATE INDEX products_name_tree ON products (name);
SELECT * FROM products WHERE name = 'iPhone 13 Pro';
해시 인덱스를 사용하면 데이터베이스는 검색 키 "iPhone 13 Pro"의 해시 값을 계산 한 다음 해당 버킷을 조회합니다. 해시 함수는 결정적이므로 데이터베이스는 레코드가 테이블에 저장된 순서에 관계없이 항상 동일한 버킷에서 레코드를 찾습니다.
트리 인덱스를 사용하는 경우 데이터베이스는 트리의 루트에서 시작하여 검색 키 "iPhone 13 Pro"를 루트에 저장된 키 값과 비교합니다 . 트리가 정렬되어 있으므로 데이터베이스는 검색 키가 포함된 레코드를 빠르게 찾습니다.
Q: B-Tree가 해시 인덱스보다 Range 쿼리에 더 최적화된 이유는 무엇입니까?
이제 가격이 100달러에서 200달러 사이인 모든 제품을 찾고 싶다고 가정해 보겠습니다. 다음 쿼리를 사용할 수 있습니다.
SELECT * FROM products WHERE price BETWEEN 100 AND 200;
작동 원리
B-트리
B-트리 인덱스는 레코드를 정렬된 순서로 저장하여 작동합니다. B-Tree 인덱스에서 레코드를 찾으려면,
- 데이터베이스는 트리의 루트에서 시작하여 검색 키를 루트에 저장된 키 값과 비교합니다.
- 검색 키가 루트 키와 같으면 데이터베이스는 해당 레코드를 반환합니다.
- 그렇지 않으면 데이터베이스는 비교 결과에 따라 다음에 검색할 하위 트리를 결정합니다.
해시시
해시 인덱스는 테이블의 각 레코드를 해시 값을 기반으로 고유한 버킷에 매핑하는 방식으로 작동합니다. 해시 값은 해시 함수를 사용하여 계산됩니다. 해시 인덱스는 버킷 전체에 데이터를 무작위로 배포하므로 범위 쿼리가 비효율적입니다. 100달러에서 200달러 사이의 가격과 같은 값 범위를 검색하려면 해당 범위의 모든 버킷을 검색해야 하며, 이로 인해 전체 테이블 검색이 효과적으로 수행됩니다. 해시 인덱스는 빠르고 정확한 일치 조회에 적합하지만 효율적인 범위 쿼리에 필요한 데이터 순서 지정이 부족합니다.
질문, 정렬 시 B-Tree 인덱스가 Hash 인덱스보다 더 최적화되는 이유는 무엇입니까?
B-트리 트리 인덱스는 레코드를 정렬된 순서로 저장하기 때문에 해시 인덱스보다 데이터를 더 효율적으로 정렬합니다. 이를 통해 데이터베이스는 정렬된 순서로 레코드를 빠르게 반복할 수 있습니다.
해시 인덱스는 테이블의 각 레코드를 해시 값을 기반으로 고유한 버킷에 매핑하는 방식으로 작동합니다. 이는 버킷의 레코드 순서가 무작위임을 의미합니다. 레코드를 정렬하려면 데이터베이스가 모든 버킷을 반복한 다음 각 버킷의 레코드를 정렬해야 합니다. 이는 레코드를 정렬된 순서로 저장하는 B-Tree 인덱스를 사용하는 것보다 느립니다.
price다음 명령을 사용하여 열에 B-트리 인덱스를 생성 할 수 있습니다 .
CREATE INDEX products_price_index ON products (price);
이제 제품을 가격별로 오름차순으로 정렬한다고 가정해 보겠습니다. 다음 쿼리를 사용할 수 있습니다.
SELECT * FROM products ORDER BY price ASC;
데이터베이스는 B-트리 인덱스를 사용하여 정렬된 순서로 제품을 빠르게 반복합니다.
해시 인덱스의 단점:
- 해시 인덱스는 범위 쿼리 또는 정렬을 지원하지 않습니다.
- 해시 인덱스는 많은 메모리를 소비합니다.
- 해시 인덱스는 자주 업데이트되는 데이터베이스에는 적합하지 않습니다.
비트맵 인덱스
비트맵 인덱스는 부울 또는 성별 열과 같이 고유 값 수가 적은 열에 사용됩니다. 비트맵 인덱스는 낮은 카디널리티 열에 대해 매우 컴팩트하고 효율적입니다.
SELECT * FROM employees WHERE gender = 'Female';
비트맵 인덱스는 낮은 카디널리티 열에서 매우 효율적이므로 합집합 및 교차와 같은 빠른 집합 작업이 가능합니다. 임시 보고 및 데이터 웨어하우징에 적합합니다.
전체 텍스트 색인
전체 텍스트 인덱싱은 문서나 웹 페이지와 같은 대량의 텍스트 데이터를 인덱싱하는 데 사용됩니다. 이 인덱싱 알고리즘은 텍스트를 단어나 토큰으로 나누고 효율적인 검색 작업이 가능한 방식으로 인덱싱합니다. 전체 텍스트 인덱스는 텍스트에서 특정 단어나 구를 검색하는 쿼리에 가장 유용합니다. 전체 텍스트 인덱싱은 일반적으로 Elasticsearch와 같은 검색 엔진에서 사용됩니다.
전자상거래 전체 텍스트 인덱싱 사용 사례:
전체 텍스트 인덱싱을 통해 전자 상거래 애플리케이션은 사용자가 입력한 검색어를 기반으로 대규모 제품 카탈로그를 신속하게 검색할 수 있습니다. 전체 텍스트 인덱싱을 사용하면 철자 오류, 동의어, 심지어 관련 개념까지 포함하여 여러 단어와 구를 기반으로 검색할 수 있습니다. 이를 통해 사용자는 정확한 제품 이름이나 설명을 모르더라도 원하는 것을 더 쉽게 찾을 수 있습니다.
예를 들어, 고객이 새 운동화를 찾고 있다고 가정해 보세요. 검색창에 '런닝화'를 입력합니다. 전체 텍스트 색인을 사용하면 전자 상거래 애플리케이션에서 모든 제품 설명, 이름 및 라벨을 빠르게 검색하여 운동화와 관련된 모든 제품을 찾을 수 있습니다. 검색 결과는 관련성에 따라 정렬되며, 관련성은 제품 정보에 검색어가 나타나는 빈도에 따라 결정됩니다.
전체 텍스트 인덱싱이 없으면 제품 설명이나 라벨 등 고객과 관련될 수 있는 다른 요소를 고려하지 않고 제품 이름만 검색할 수 있습니다. 또한 검색에서는 "조깅화" 또는 "운동화"와 같은 철자 오류나 관련 개념을 처리하지 못할 수도 있습니다.
, 및 이라는 products열로 명명된 테이블이 있다고 가정합니다 .idnamedescriptiontags
CREATE FULLTEXT INDEX products_ft_index ON products(name, description, tags);
이제 고객이 '런닝화'를 검색한다고 가정해 보겠습니다. 다음 쿼리를 사용하여 검색어와 관련된 제품을 검색할 수 있습니다.
SELECT id, name, description, MATCH(name, description, tags) AGAINST('running shoes') as relevance
FROM products
WHERE MATCH(name, description, tags) AGAINST('running shoes' IN BOOLEAN MODE)
ORDER BY relevance DESC
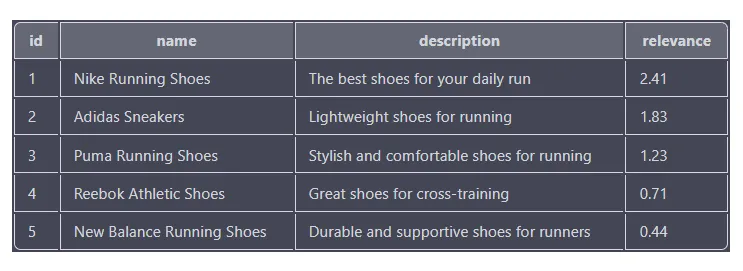
관련성 점수는 각 제품이 검색어와 얼마나 일치하는지를 기준으로 하며, 점수가 높을수록 더 가까운 일치를 나타냅니다. 결과는 관련성 점수를 기준으로 내림차순으로 정렬되므로 관련성 점수가 가장 높은 제품(Nike 운동화)이 목록 상단에 표시됩니다.
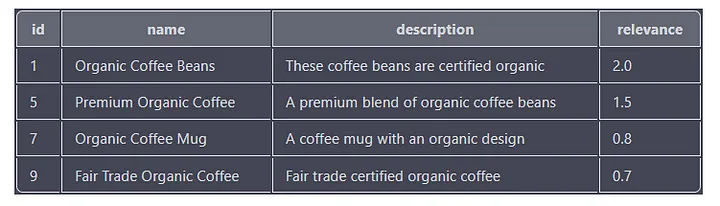
다음은 "유기농" 및 "커피"라는 단어가 포함된 제품을 검색하는 또 다른 쿼리 예입니다.
SELECT id, name, description, MATCH(name, description, tags) AGAINST('+"organic" +"coffee"') as relevance
FROM products
WHERE MATCH(name, description, tags) AGAINST('+"organic" +"coffee"' IN BOOLEAN MODE)
ORDER BY relevance DESC;
이 쿼리는 이름, 설명 또는 라벨 열에 "유기농" 및 "커피" 키워드가 모두 포함된 모든 제품을 검색합니다. 각 결과의 관련성 점수도 해당 열의 키워드 위치와 횟수를 기준으로 계산됩니다.
출력에는 "id", "name", "description" 및 "relevance" 열이 포함되며 결과는 "relevance" 열을 기준으로 내림차순으로 정렬됩니다.
이점
- 전체 텍스트 인덱스는 텍스트 기반 열에 매우 잘 작동합니다.
- 검색 엔진 및 콘텐츠 관리 시스템에 적합
- 검색 결과의 관련성 순위 지원
결점
- 전체 텍스트 인덱싱은 많은 저장 공간을 차지합니다.
- 매우 큰 데이터 세트의 경우 성능이 저하될 수 있습니다.
- 전체 텍스트 인덱싱은 숫자 또는 범주형 데이터에 적합하지 않습니다.
더 많은 기술 기사를 보려면 https://opensource.actionsky.com/을 방문하세요.
SQLE 소개
SQLE는 개발부터 프로덕션 환경까지 SQL 감사 및 관리를 포괄하는 포괄적인 SQL 품질 관리 플랫폼입니다. 주류 오픈소스, 상용 및 국내 데이터베이스를 지원하고 개발, 운영 및 유지 관리를 위한 프로세스 자동화 기능을 제공하고 온라인 효율성을 향상시키며 데이터 품질을 향상시킵니다.