
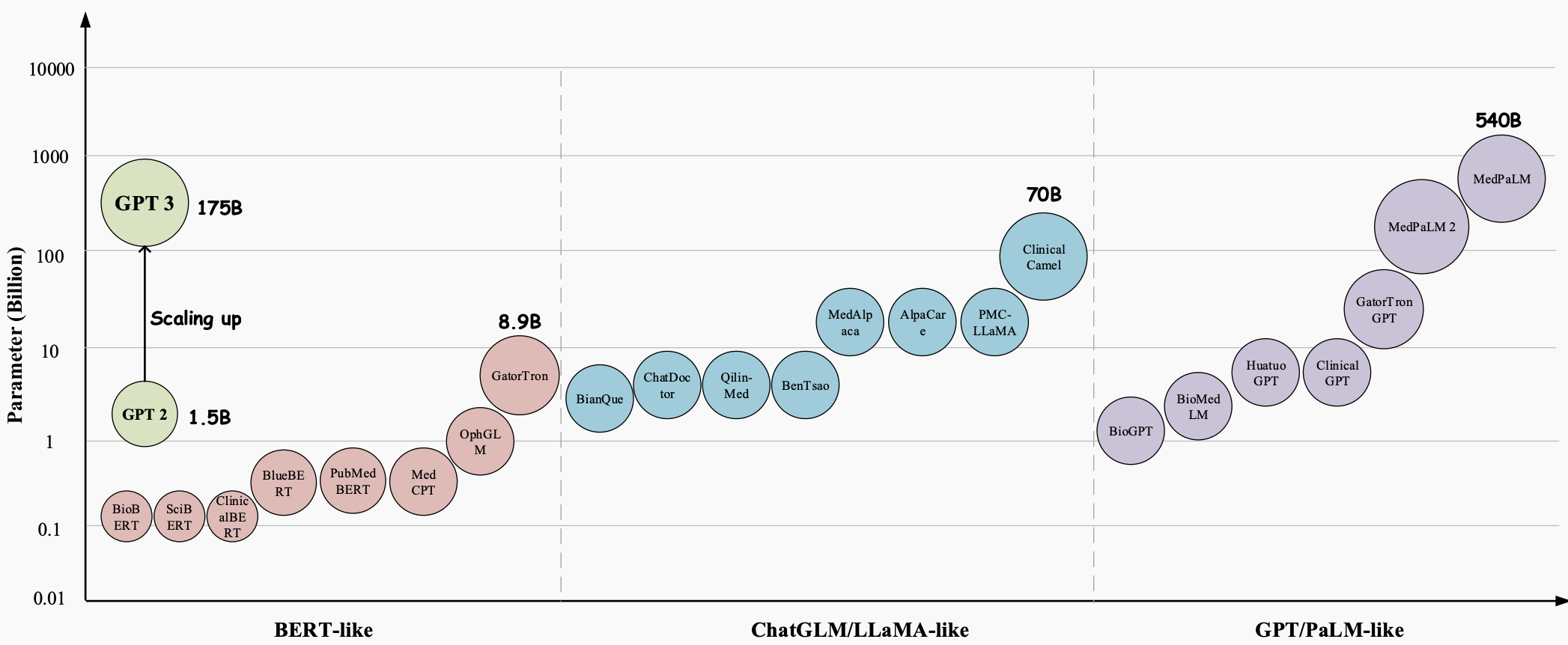
수년에 걸쳐 LLM(대형 언어 모델)은 의료 산업의 모든 측면에 혁명을 일으킬 엄청난 잠재력을 지닌 획기적인 기술로 발전해 왔습니다. GPT-3 , GPT-4 및 Med-PaLM 2 와 같은 이러한 모델은 인간과 유사한 텍스트를 이해하고 생성하는 탁월한 기능을 입증하여 복잡한 의료 업무를 처리하고 환자 치료를 개선하는 데 유용한 도구가 되었습니다. 의료 질문 답변(QA), 대화 시스템, 텍스트 생성 등 다양한 의료 응용 분야에서 큰 가능성을 보여줍니다. 또한 전자 건강 기록(EHR), 의학 문헌, 환자 생성 데이터가 기하급수적으로 증가함에 따라 LLM은 의료 전문가가 귀중한 통찰력을 추출하고 정보에 입각한 결정을 내리는 데 도움을 줄 수 있습니다.
그러나 의료 분야에서 LLM(대형 언어 모델)의 엄청난 잠재력에도 불구하고 여전히 해결해야 할 중요하고 구체적인 과제가 몇 가지 있습니다.
모델이 엔터테인먼트 대화의 맥락에서 사용될 때 오류의 영향은 최소화됩니다. 그러나 잘못된 해석과 답변이 환자 치료 및 결과에 심각한 결과를 초래할 수 있는 의료 분야에서는 그렇지 않습니다. 언어 모델이 제공하는 정보의 정확성과 신뢰성은 의학적 결정, 진단 및 치료 계획에 영향을 미칠 수 있으므로 생사의 문제가 될 수 있습니다.
예를 들어, GPT-3가 임산부가 사용할 수 있는 약물에 대해 질문했을 때, GPT-3는 테트라사이클린이 태아에게 해롭고 임산부가 사용해서는 안 된다고 올바르게 명시했음에도 불구하고 테트라사이클린을 잘못 권장했습니다. 정말 이 잘못된 조언을 따라 임산부에게 약을 먹이면 나중에 아이의 뼈가 잘 자라지 않을 수도 있습니다.

이러한 대규모 언어 모델을 의료 분야에서 잘 활용하기 위해서는 이러한 모델을 의료 산업의 특성에 맞게 설계하고 벤치마킹해야 합니다. 의료 데이터와 애플리케이션에는 고유한 특징이 있으므로 이러한 점을 고려해야 합니다. 그리고 이러한 모델을 연구뿐만 아니라 실제 의료 작업에서 잘못 사용할 경우 위험을 초래할 수 있기 때문에 의료용으로 이러한 모델을 평가하는 방법을 개발하는 것이 실제로 중요합니다.
오픈 소스 의료 대형 모델 순위는 다양한 의료 작업 및 데이터 세트에서 다양한 대형 언어 모델의 성능을 평가하고 비교할 수 있는 표준화된 플랫폼을 제공함으로써 이러한 과제와 한계를 해결하는 것을 목표로 합니다. 각 모델의 의학 지식과 질문 답변 능력에 대한 종합적인 평가를 제공함으로써 순위는 보다 효과적이고 신뢰할 수 있는 의료 모델의 개발을 촉진합니다.
이 플랫폼을 통해 연구자와 실무자는 다양한 접근법의 강점과 약점을 식별하고 해당 분야의 추가 개발을 추진하며 궁극적으로 환자 결과를 개선하는 데 도움을 줄 수 있습니다.
데이터 세트, 작업 및 평가 설정
의료 대형 모델 순위에는 다양한 작업이 포함되어 있으며 정확도를 주요 평가 지표로 사용합니다(정확도는 다양한 의료 질문 및 답변 데이터 세트에서 언어 모델이 제공하는 정답의 비율을 측정합니다).
MedQA
MedQA 데이터 세트에는 USMLE(미국 의료 면허 시험)의 객관식 질문이 포함되어 있습니다. 광범위한 의학 지식을 다루며 11,450개의 훈련 세트 질문과 1,273개의 테스트 세트 질문을 포함합니다. 질문당 4~5개의 답변 옵션이 있는 이 데이터 세트는 미국에서 의료 면허를 취득하는 데 필요한 의학 지식과 추론 기술을 평가하도록 설계되었습니다.

MedMCQA
MedMCQA는 인도 의료 입학 시험(AIIMS/NEET)에서 파생된 대규모 객관식 질문 및 답변 데이터 세트입니다. 이는 2400개의 의학 분야 주제와 21개의 의학 주제를 다루며, 훈련 세트에 187,000개 이상의 질문이 있고 테스트 세트에 6,100개 이상의 질문이 있습니다. 각 질문에는 설명과 함께 4가지 답변 옵션이 있습니다. MedMCQA는 모델의 일반적인 의학 지식과 추론 능력을 평가합니다.

PubMedQA
PubMedQA는 관련 컨텍스트(PubMub 요약)를 살펴봄으로써 각 질문에 답할 수 있는 폐쇄형 질문 답변 데이터세트입니다. 여기에는 전문가가 라벨을 붙인 질문-답변 쌍 1,000개가 포함되어 있습니다. 각 질문에는 맥락에 대한 PubMed 요약이 함께 제공되며, 작업은 요약 정보를 기반으로 예/아니오/아마도 답변을 제공하는 것입니다. 데이터 세트는 500개의 훈련 문제와 500개의 시험 문제로 나뉩니다. PubMedQA는 과학적인 생물의학 문헌을 이해하고 추론하는 모델의 능력을 평가합니다.

MMLU 하위 집합(의학 및 생물학)
MMLU 벤치마크 (Measuring Large-Scale Multi-Task Language Understanding)에는 다양한 도메인의 객관식 질문이 포함되어 있습니다. 오픈 소스 의료 대형 모델 순위의 경우 의학 지식과 가장 관련성이 높은 하위 집합에 중점을 둡니다.
- 임상 지식: 임상 지식과 의사 결정 기술을 평가하는 265개 질문입니다.
- 의료 유전학: 의료 유전학과 관련된 주제를 다루는 100개의 질문입니다.
- 해부학: 인체 해부학에 대한 지식을 평가하는 135개 질문.
- 전문 의학: 의료 전문가에게 필요한 지식을 평가하는 272개의 질문입니다.
- 대학 생물학: 대학 수준의 생물학 개념을 다루는 144개 질문.
- 대학 의학: 대학 수준의 의학 지식을 평가하는 173개 질문. 각 MMLU 하위 집합에는 특정 의학 및 생물학적 영역에 대한 모델의 이해를 평가하도록 설계된 4가지 답변 옵션이 있는 객관식 질문이 포함되어 있습니다.

오픈 소스 의료 대형 모델 순위는 의학 지식 및 추론의 다양한 측면에서 모델 성능에 대한 강력한 평가를 제공합니다.
통찰력과 분석
오픈 소스 의료 대형 모델 순위(Open Source Medical Large Model Ranking)는 다양한 의료 질문 답변 작업에서 다양한 LLM(대형 언어 모델)의 성능을 평가합니다. 주요 조사 결과는 다음과 같습니다.
- GPT-4-base 및 Med-PaLM-2와 같은 상용 모델은 다양한 의료 데이터 세트에서 지속적으로 높은 정확도 점수를 달성하여 다양한 의료 분야에서 강력한 성능을 보여줍니다.
- Starling-LM-7B , gemma-7b , Mistral-7B-v0.1 및 Hermes-2-Pro-Mistral-7B 와 같은 오픈 소스 모델은 매개변수 수가 약 70억 개에 불과하지만 특정 데이터에서 좋은 성능을 발휘합니다. 세트와 작업을 통해 경쟁력 있는 성능을 제공했습니다.
- 상업용 및 오픈 소스 모델은 과학 생물 의학 문헌(PubMedQA)에 대한 이해 및 추론, 임상 지식 및 의사 결정 기술 적용(MMLU 임상 지식 하위 집합)과 같은 작업에서 잘 수행됩니다.

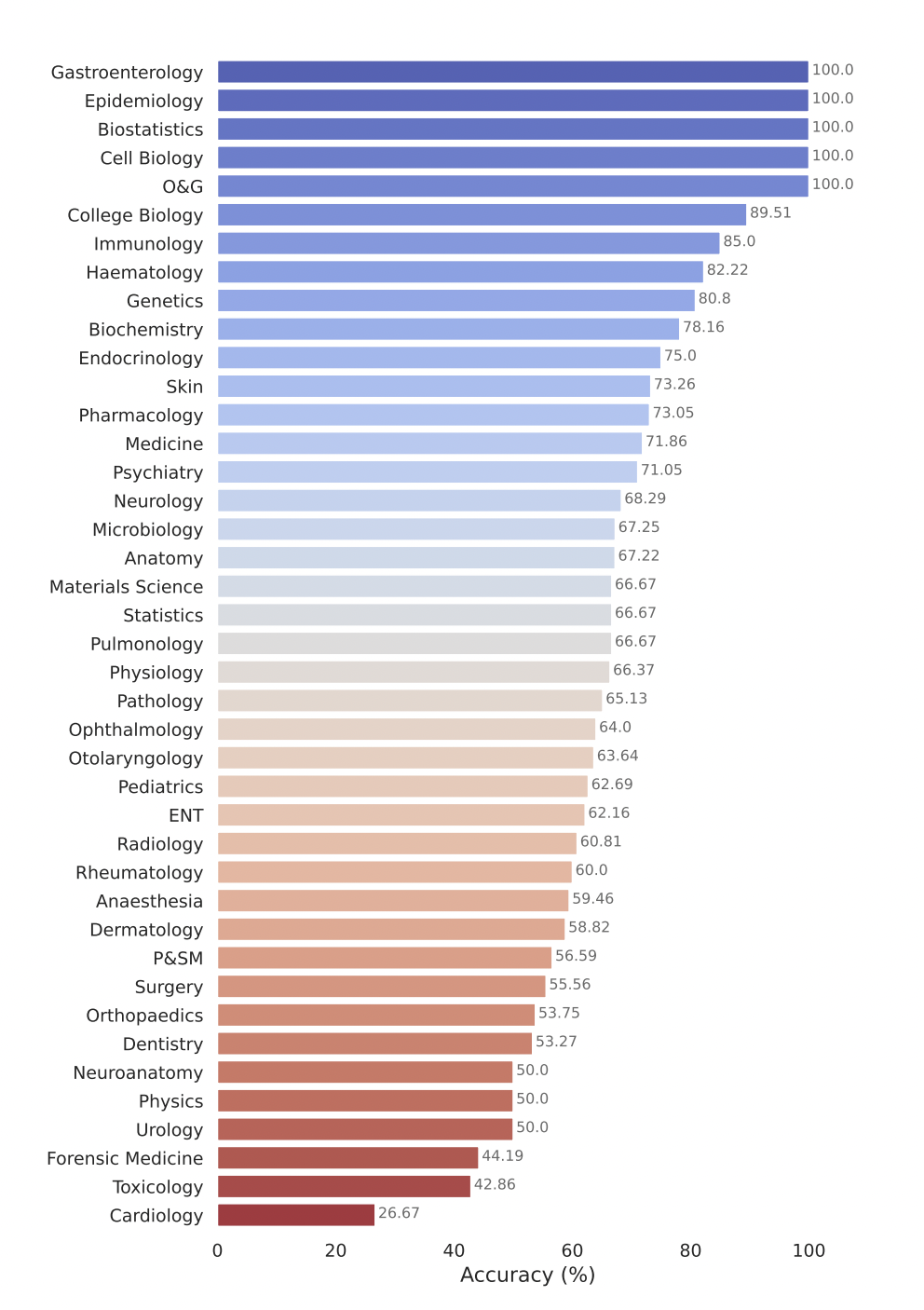
Google의 모델인 Gemini Pro는 다양한 의료 분야, 특히 생물통계학, 세포 생물학, 산부인과 등 데이터 집약적이고 절차적인 작업에서 강력한 성능을 입증했습니다. 그러나 해부학, 심장학, 피부과 등 핵심 분야에서는 중간에서 낮은 성과를 보여 보다 포괄적인 의학에 적용하려면 추가 개선이 필요한 격차가 드러났습니다.
평가를 위해 모델 제출
오픈 소스 헬스케어 대형 모델 순위 평가를 위해 모델을 제출하려면 다음 단계를 따르세요.
1. 모델 가중치를 Safetensor 형식으로 변환
먼저 모델 가중치를 safetensors 형식으로 변환합니다. Safetensors는 더 안전하고 더 빠르게 로드하고 사용할 수 있는 가중치를 저장하기 위한 새로운 형식입니다. 모델을 이 형식으로 변환하면 리더보드의 기본 테이블에 모델에 대한 매개변수 수가 표시될 수도 있습니다.
2. AutoClasses와의 호환성 보장
모델을 제출하기 전에 Transformers 라이브러리의 AutoClasses를 사용하여 모델과 토크나이저를 로드할 수 있는지 확인하세요. 호환성을 테스트하려면 다음 코드 조각을 사용하십시오.
from transformers import AutoConfig, AutoModel, AutoTokenizer
config = AutoConfig.from_pretrained(MODEL_HUB_ID)
model = AutoModel.from_pretrained("your model name")
tokenizer = AutoTokenizer.from_pretrained("your model name")
이 단계에서 실패하면 제출하기 전에 오류 메시지에 따라 모델을 디버그하세요. 모델이 부적절하게 업로드되었을 가능성이 높습니다.
3. 모델을 공개하세요
모델이 공개적으로 액세스 가능한지 확인하세요. 순위표는 비공개 모델이나 특별한 액세스가 필요한 모델을 평가할 수 없습니다.
4. 원격 코드 실행(제공 예정)
현재 오픈소스 의료용 대형 모델 순위에서는 필수 use_remote_code=True모델을 지원하지 않습니다. 그러나 리더보드 팀에서는 이 기능을 적극적으로 추가하고 있으므로 업데이트를 계속 지켜봐 주시기 바랍니다.
5. 리더보드 웹사이트를 통해 모델을 제출하세요.
모델이 safetensors 형식으로 변환되고 AutoClasses와 호환되며 공개적으로 액세스 가능하면 오픈 소스 의료 대형 모델 순위 웹사이트의 여기 제출 패널을 사용하여 평가할 수 있습니다. 모델명, 설명, 추가 세부정보 등 필수 정보를 입력한 후 제출 버튼을 클릭하세요. 리더보드 팀은 귀하의 제출을 처리하고 다양한 의료 Q&A 데이터세트에 대한 모델 성능을 평가합니다. 평가가 완료되면 모델의 점수가 리더보드에 추가되며 해당 모델의 성능을 다른 모델과 비교할 수 있습니다.
무엇 향후 계획? 오픈소스 의료용 대형모델 순위 확대
오픈 소스 의료 대형 모델 순위는 연구 커뮤니티와 의료 산업의 변화하는 요구 사항을 충족하기 위해 확장하고 적응하는 데 최선을 다하고 있습니다. 주요 영역은 다음과 같습니다:
- 연구원, 의료 기관 및 업계 파트너와의 협력을 통해 방사선학, 병리학, 유전체학 등 치료의 모든 측면을 포괄하는 광범위한 의료 데이터 세트를 통합합니다.
- 의료 애플리케이션의 고유한 요구 사항을 포착하는 지점별 점수 및 도메인별 측정항목과 같이 정확성을 넘어 추가적인 성능 측정을 탐색하여 평가 측정항목 및 보고 기능을 향상합니다.
- 이 방향으로 이미 일부 작업이 진행 중입니다. 우리가 제안할 다음 벤치마크에 대한 공동 작업에 관심이 있다면 Discord 커뮤니티에 가입하여 자세히 알아보고 참여해 보세요. 우리는 협력하고 브레인스토밍하고 싶습니다!
AI와 헬스케어의 교차점, 헬스케어 모델 구축, 대규모 의료 모델의 안전 및 환각 문제에 관심이 있다면 Discord의 활발한 커뮤니티에 참여하도록 초대합니다 .
감사의 말

Clémentine Fourrier와 Hugging Face 팀을 포함하여 이를 가능하게 해주신 모든 분들께 특별히 감사드립니다. 리더보드 개발 과정에서 토론과 피드백을 주신 Andreas Motzfeldt, Aryo Gema, Logesh Kumar Umapathi에게 감사의 말씀을 전하고 싶습니다. 시간을 내어 기술 지원과 GPU 지원을 해주신 에든버러 대학의 Pasquale Minervini 교수님께 진심으로 감사드립니다.
오픈라이프사이언스 AI 소개
오픈 라이프 사이언스 AI(Open Life Sciences AI)는 생명과학 및 의료 분야에 인공지능을 적용하는 혁명을 목표로 하는 프로젝트입니다. 의료 모델, 데이터세트, 벤치마크를 나열하고 컨퍼런스 마감일을 추적하는 중앙 허브 역할을 하여 AI 지원 의료 분야의 협업, 혁신 및 발전을 촉진합니다. 우리는 AI와 의료의 교차점에 관심이 있는 모든 사람을 위한 최고의 목적지로 Open Life Sciences AI를 구축하기 위해 노력하고 있습니다. 우리는 연구자, 임상의, 정책 입안자 및 업계 전문가가 대화에 참여하고 통찰력을 공유하며 해당 분야의 최신 개발을 탐색할 수 있는 플랫폼을 제공합니다.

인용하다
우리의 평가가 유용하다고 생각되면 우리의 연구 결과를 인용하는 것을 고려해 보십시오.
의료용 대형모델 랭킹
@misc{Medical-LLM Leaderboard,
author = {Ankit Pal, Pasquale Minervini, Andreas Geert Motzfeldt, Aryo Pradipta Gema and Beatrice Alex},
title = {openlifescienceai/open_medical_llm_leaderboard},
year = {2024},
publisher = {Hugging Face},
howpublished = "\url{https://huggingface.co/spaces/openlifescienceai/open_medical_llm_leaderboard}"
}
> 영문 원문: https://hf.co/blog/leaderboard-medicalllm > 원저자: Aaditya Ura(박사 학위 취득 중), Pasquale Minervini, Clémentine Fourrier > 번역자: Innovation64
1990년대에 태어난 프로그래머가 비디오 포팅 소프트웨어를 개발하여 1년도 안 되어 700만 개 이상의 수익을 올렸습니다. 결말은 매우 처참했습니다! 고등학생들이 성인식으로 자신만의 오픈소스 프로그래밍 언어 만든다 - 네티즌 날카로운 지적: 만연한 사기로 러스트데스크 의존, 가사 서비스 타오바오(taobao.com)가 가사 서비스를 중단하고 웹 버전 최적화 작업 재개 자바 17은 가장 일반적으로 사용되는 Java LTS 버전입니다. Windows 10 시장 점유율 70%에 도달, Windows 11은 계속해서 Open Source Daily를 지원합니다. Google은 Docker가 지원하는 오픈 소스 Rabbit R1을 지원합니다. Electric, 개방형 플랫폼 종료 Apple, M4 칩 출시 Google, Android 범용 커널(ACK) 삭제 RISC-V 아키텍처 지원 Yunfeng은 Alibaba에서 사임하고 향후 Windows 플랫폼에서 독립 게임을 제작할 계획